







商品上架
在商城中搜索商品,只能搜索到已上架的商品。
而商品上架时,需要把数据也同步到elasticsearch中以供搜索。
但是肯定不能把完整的数据全部存到es中,因为es中的数据是存储在内存中的,就算es是分布式的,理论上可以存储非常多的数据,但是内存产品终究是比硬盘贵的。所以考虑到经济效益,我们是要取某些数据存到es中,而不是完整数据都存进去。
哪些数据存储在es中?
sku在es中存储模型分析
es中应存储能够被检索的条件。

比如这个商城能够用于检索的条件就有:
分类、品牌、综合、销量、价格区间、CPU型号,运行内存,机身内存(这些应该是每种分类特有的属性)、等等
分析:商品上架在 es 中是存 sku 还是 spu?
答:搜索一般是搜索sku的信息,因为一个spu中包含多个sku,每个sku的情况都不一样,搜索的时候可能一个spu里的某几个sku符合条件,几个sku不符合条件。(我的理解)
-
检索的时候输入名字,是需要按照 sku 的 title 进行全文检索的
-
检索使用商品规格,规格是 spu 的公共属性,每个 spu 是一样的
-
按照分类 id 进去的都是直接列出 spu 的,还可以切换。
-
我们如果将 sku 的全量信息保存到 es 中(包括 spu 属性)就太多量字段了。
-
我们如果将 spu 以及他包含的 sku 信息保存到 es 中,也可以方便检索。但是 sku 属于spu 的级联对象,在 es 中需要 nested 模型,这种性能差点。
-
但是存储与检索我们必须性能折中。
-
如果我们分拆存储,spu 和 attr 一个索引,sku 单独一个索引可能涉及的问题。检索商品的名字,如“手机”,对应的 spu 有很多,我们要分析出这些 spu 的所有关联属性,再做一次查询,就必须将所有 spu_id 都发出去。假设有 1 万个数据,数据传输一次就10000*4=4MB;并发情况下假设 1000 检索请求,那就是 4GB 的数据,,传输阻塞时间会很长,业务更加无法继续。
PUT product
{
"mappings": {
"properties": {
"skuId": {
"type": "long"
},
"spuId": {
"type": "keyword"
},
"skuTitle": {
"type": "text",
"analyzer": "ik_smart"
},
"skuPrice": {
"type": "keyword"
},
"skuImg": {
"type": "keyword",
"index": false,
"doc_values": false
},
"saleCount": {
"type": "long"
},
"hasStock": {
"type": "boolean"
},
"hotScore": {
"type": "long"
},
"brandId": {
"type": "long"
},
"catalogId": {
"type": "long"
},
"brandName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"brandImg": {
"type": "keyword",
"index": false,
"doc_values": false
},
"catalogName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrs": {
"type": "nested",
"properties": {
"attrId": {
"type": "long"
},
"attrName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrValue": {
"type": "keyword"
}
}
}
}
}
}
text类型和keyword类型的区别:
text:会分词,然后进行索引
支持模糊、精确查询
不支持聚合
keyword:不进行分词,直接索引
支持模糊、精确查询
支持聚合
| 字段 | 含义 |
|---|---|
| index | 默认 true,如果为 false,表示该字段不会被索引,但是检索结果里面有,但字段本身不能 |
| doc_values | 默认 true,设置为 false,表示不可以做排序、聚合以及脚本操作,这样更节省磁盘空间。还可以通过设定 doc_values 为 true,index 为 false 来让字段不能被搜索但可以用于排序、聚合以及脚本操作 |
es的扁平化处理
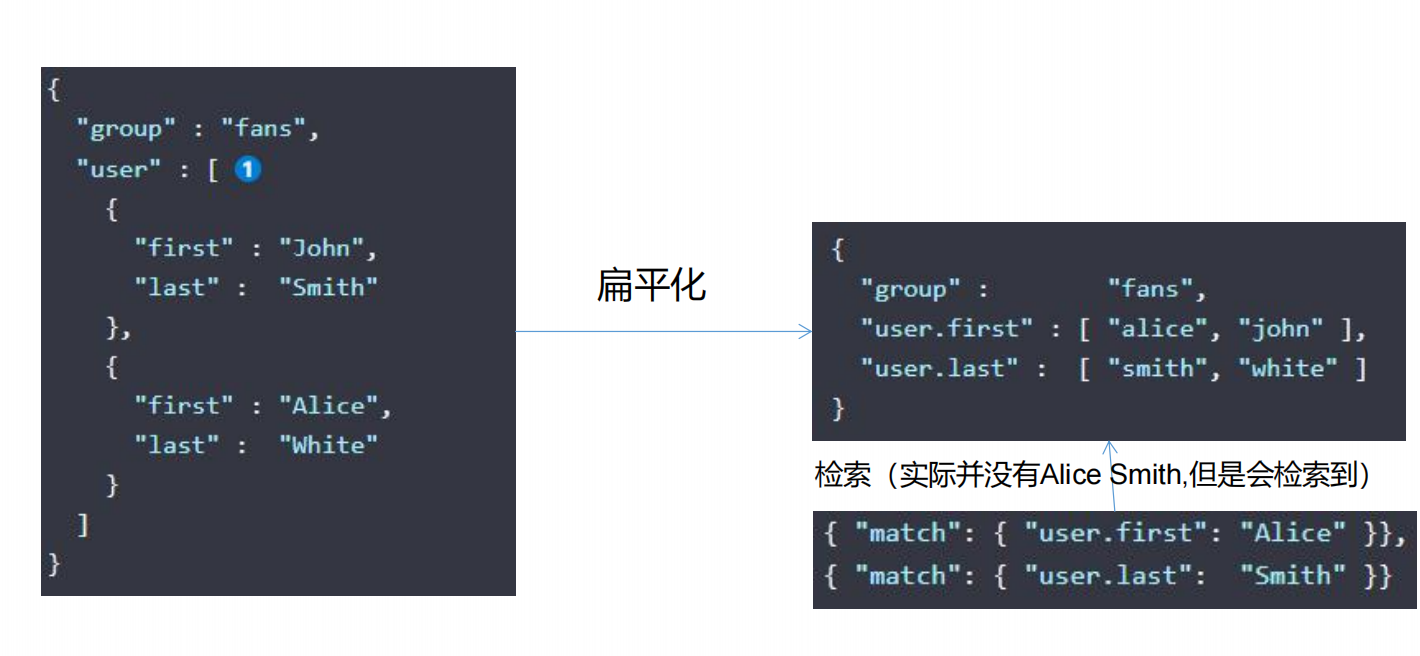
| 字段 | 含义 |
|---|---|
| nested | 嵌入式的字段,就可以不使用es的扁平化处理了。 |
构造数据实体类
由于这些数据是要在多个服务之间进行传输的,所以定义为to类型。为了方便每一个服务调用,我们直接创建在common模块中。
// 根据分析出来的模型构建
@Data
public class SkuEsTo {
private Long skuId;
private Long spuId;
private String skuTitle;
private BigDecimal skuPrice;
private String skuImg;
private Long saleCount;
private Boolean hasStock;
private Long hotScore;
private Long brandId;
private Long catalogId;
private String brandName;
private String brandImg;
private String catalogName;
private List<Attr> attrs;
@Data
public static class Attr {
private Long attrId;
private String attrName;
private String attrValue;
}
}
商品上架功能实现
具体步骤
- 获取
spu下的所有所属sku - 获取每一个
sku中的需要使用的信息- 库存信息
- 可检索属性
- …
- 组装
SkuEsTo的数据到集合中。 - 将
List<SkuEsTo>发送给es,让es保存,达到上架的状态。 - 修改数据库中
spu的发布状态(1-上架)
具体实现
- 因为可检索属性是每一个sku都相同的,所以能在一开始直接获取,不要在循环内获取。
- 库存信息需要调用其他服务,这种操作速度应该会比较慢,所以也在循环外一次性获取,需要新建一个存储库存信息的TO实体类。
以下列出部分代码。(因为代码太多了,只列出一些关键的)
- 商品上架的逻辑处理层
@Override
public void up(Long spuId) {
// 1.获取该spu的所有可检索属性。
// attrs;因为spu的属性是每个sku共享的,用空间换时间,所以在每一个sku里面都存一遍!!过滤出需要检索的属性,0为不需要检索,1为需要检索
List<ProductAttrValueEntity> productAttrValueList = productAttrValueService.getAttrsBySpuId(spuId);
// 获取spu下所有属性id
List<Long> attrIds = productAttrValueList.stream().map(ProductAttrValueEntity::getAttrId).collect(Collectors.toList());
// 得到spu下所有的可检索属性id
List<Long> searchAttrIds = attrService.selectSearchAttrIds(attrIds);
// 过滤出所有可检索的属性信息
List<SkuEsTo.Attr> searchAttrList = productAttrValueList.stream()
.filter(attr -> searchAttrIds.contains(attr.getAttrId()))
// 组装skuEsTo中的attrs
.map(searchAttrItem -> {
SkuEsTo.Attr attr = new SkuEsTo.Attr();
attr.setAttrId(searchAttrItem.getAttrId());
attr.setAttrName(searchAttrItem.getAttrName());
attr.setAttrValue(searchAttrItem.getAttrValue());
return attr;
}).collect(Collectors.toList());
// 2.获取sku库存信息
List<SkuInfoEntity> skuInfoEntityList = skuInfoService.getInfoBySpuId(spuId);
// 得到所有的skuId,调用远程服务,获取库存信息
List<Long> skuIds = skuInfoEntityList.stream().map(SkuInfoEntity::getSkuId).collect(Collectors.toList());
Object skuStockInfoList = null;
try {
R r = wareFeignService.hasStock(skuIds);
skuStockInfoList = r.get("skuStockToList");
}catch (Exception e){
log.error("库存服务查询失败,原因:{}", e.getMessage());
}
Object finalSkuStockInfoList = skuStockInfoList;
List<SkuEsTo> esProductList = skuInfoEntityList.stream().map(skuInfoEntity -> {
SkuEsTo skuEsTo = new SkuEsTo();
BeanUtils.copyProperties(skuInfoEntity, skuEsTo);
// skuPrice;skuImg;
skuEsTo.setSkuPrice(skuInfoEntity.getPrice());
skuEsTo.setSkuImg(skuInfoEntity.getSkuDefaultImg());
// hasStock;hotScore;
if (finalSkuStockInfoList != null){
// 做一个类型转换,把list中的数据放到map中,map<skuId, 是否有库存>
Map<Long, Boolean> stockInfoMap = TypeConversion.objListToMapOfLongBoolean(finalSkuStockInfoList);
Boolean hasStock = stockInfoMap.get(skuInfoEntity.getSkuId());
skuEsTo.setHasStock(hasStock);
} else {
skuEsTo.setHasStock(true);
}
// todo:热度评分,默认新上架的商品评分为0,给钱就高分
skuEsTo.setHotScore(0L);
// brandName;brandImg;
BrandEntity brandEntity = brandService.getById(skuInfoEntity.getBrandId());
skuEsTo.setBrandName(brandEntity.getName());
skuEsTo.setBrandImg(brandEntity.getLogo());
// catalogName;
CategoryEntity categoryEntity = categoryService.getById(skuInfoEntity.getCatalogId());
skuEsTo.setCatalogName(categoryEntity.getName());
// attrs;
skuEsTo.setAttrs(searchAttrList);
return skuEsTo;
}).collect(Collectors.toList());
// 3.将数据发给es,让es做一个保存
R r = searchFeignService.productStatusUp(esProductList);
if (r.getCode() == 0){
boolean status = (boolean) r.get("status");
// 4.上架成功,修改数据库中的上架状态
spuInfoDao.updateSpuPublishStatus(spuId, ProductConstant.StatusEnum.SPU_UP.getCode());
}else {
log.error("商品上架失败");
// TODO: 重复调用?接口幂等性?重试机制?
}
}
- 在common模块中再新建一个存储库存信息的TO实体类。
@Data
public class SkuStockTo {
/**
* skuId
*/
private Long skuId;
/**
* 是否有库存
*/
private Boolean hasStock;
}
- 批量将数据存储到
es中
@Override
public boolean productStatusUp(List<SkuEsTo> skuEsToList) {
boolean success = true;
// 1.给es中建立索引。product,建立好映射关系。
// 2.在es中保存这些数据。数据多,不可能一个一个组装,使用bulk批量处理
// BulkRequest bulkRequest, RequestOptions options
BulkRequest bulkRequest = new BulkRequest();
for (SkuEsTo skuEsTo : skuEsToList) {
// 3.组装数据
IndexRequest request = new IndexRequest(SearchConstant.IndexEnum.PRODUCT_INDEX.getIndex());
// 指定id
request.id(String.valueOf(skuEsTo.getSkuId()));
String skuEsToJson = JSON.toJSONString(skuEsTo);
// 指定json数据
System.out.println(skuEsTo);
request.source(skuEsToJson, XContentType.JSON);
bulkRequest.add(request);
}
try {
// 4.执行
BulkResponse response = client.bulk(bulkRequest, GulimallElasticsearchConfig.COMMON_OPTIONS);
if (response.hasFailures()){
success = false;
List<String> failureList = Arrays.stream(response.getItems()).filter(item -> item.getFailure() != null).map(BulkItemResponse::getId).collect(Collectors.toList());
log.error("批量操作错误项:{}", failureList);
}
} catch (IOException e) {
log.error("批量操作遇到错误,原因:{}", e.getMessage());
}
return success;
}














 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









