







CTF攻防世界题
(一)baby_web
首先拿到这道题,进入场景我们看到只有简单的页面,输出了我们都是知道的“HELLO WORLD”
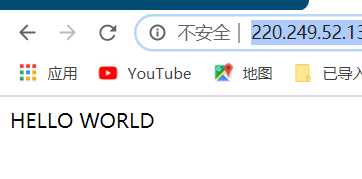
然后第一反应看源码,但是源码只有简单地输出。
懵了几秒,返回题目页面找提示,题目描述:想想初始页面是哪个
回顾一下,第一次接触web,第一个网站是localhost,但是显然不对。
想到了第一个网页编辑时输出自己的学号姓名,文件名称为index.php,,哦,!原来是这样,与网页link联系起来,直接把1.php改为index.php,还是显示HELlO WORLD。
那就用火狐看一下,F12打开,终于找到了flag

顺利完成!(题目描述很重要)
(二)Training-WWW-Robots
没有一点提示,继续查看源码是否有提示,没有任何提示,翻译英语
In this little training challenge, you are going to learn about the Robots_exclusion_standard.
The robots.txt file is used by web crawlers to check if they are allowed to crawl and index your website or only parts of it.
Sometimes these files reveal the directory structure instead protecting the content from being crawled.
Enjoy!
在这个小小的培训挑战中,您将了解Robots_Exclusion_Standard。
网络爬虫使用robots.txt文件检查是否允许他们抓取和索引您的网站或只允许部分内容。
有时,这些文件会暴露目录结构,而不是保护内容不被抓取。
好好享受吧!
有提示,robots.txt,知道robots是网页协议后,试着访问这个文本,看到提示

继续访问fl0g.php
出现flag,成功拿到。
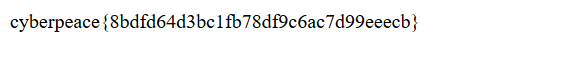
第一周 2020/7/22
















 4408
4408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











