







目录
一、朴素模式匹配
主串S长度为n,子串T长度为m。
具体代码没啥可说,可以用数组实现,依次比较,不对就后移,直接暴力破解,时间复杂度最差为O((n-m+1) * m),即O(nm)。

二、KMP算法
(1)基本思想
基于朴素模式匹配进行改进。
朴素模式匹配是一旦发现这个子串中某个字符不匹配,就只能从头开始转而匹配下一个子串,指针只移动一个位置。图中是如果发现子串(2-7)不匹配时,将会移动到子串(3-8),继续匹配。
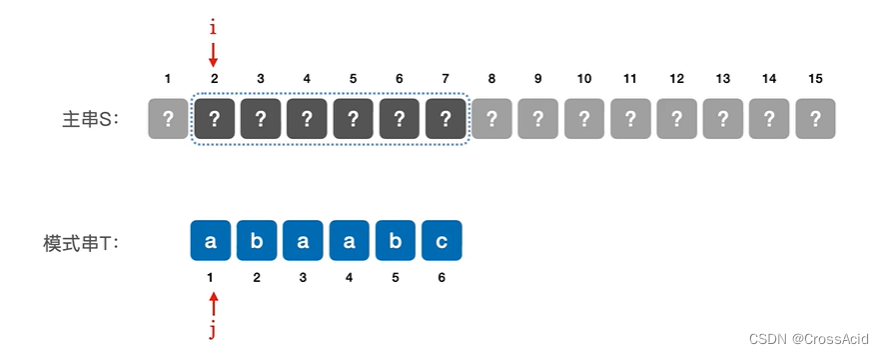
图 1
此处的缺点是即使匹配到第6个字符时才发现不匹配,即前5个字符都匹配时,仍然要回到最开始进行下一个子串(3-8)和模式串的匹配,从而对已知的信息利用不充分。
图 2
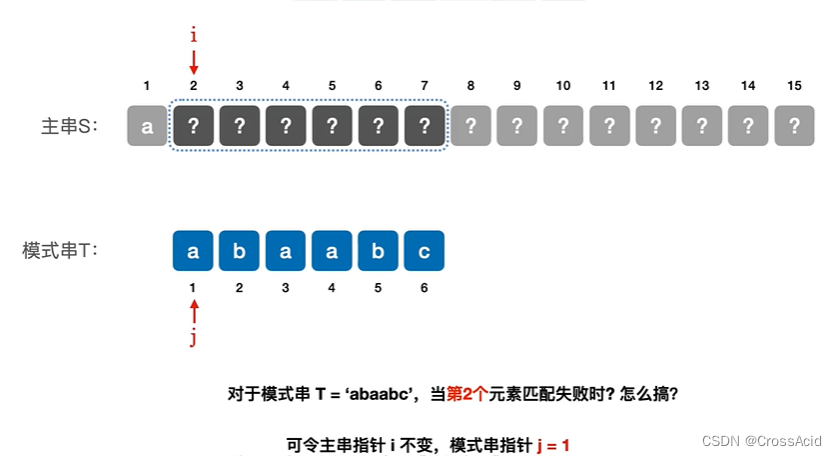
因此,提出一个观点,不匹配的字符之前,一定是和模式串一致的。
如图2所示,图中进行第一轮匹配时,已经发现前5个字符是匹配的,也已知了主串S的前5个个字符,因此,如果利用好着些信息,我们可以得到如下结论:
① 不用从2、3位置开始匹配,从2开始,前两个字符是ba,与模式串不匹配,3开始是aa,也显然不匹配
② 也不用从4、5位置开始匹配,因为已知4、5位置的字符ab和模式串前两个是匹配的(在第一次匹配时获得的信息),无需再次比较。
③ 以4为子串的开始位置,直接从6的位置开始比较,因为4、5位置匹配正确,而6位置不知道主串中的字符是什么,需要继续跟模式串进行匹配。
如图3所示

图 3
图中结论对模式串具有通用性,与子串在主串中的位置无关,只要主串和模式串匹配的情况相同,即可直接直接进行同样的操作,即令主串指针i不变,模式串指针j=3。
如上即为KMP算法的基本思想。
(2)各种情况讨论
情况 a(第6个元素失配):
abaab? 与abaabc匹配,匹配失败后令主串指针i不变,模式串指针j=3
情况 b(第5个元素失配):
abaa?与abaabc匹配,匹配失败后i不变,j=2


情况 c(第4个元素失配):
aba?与abaabc匹配,匹配失败后i不变,j=2


情况 d(第3个元素失配):
ab?与abaabc匹配,匹配失败后i不变,j=1


情况 e(第2个元素失配):
a?与abaabc匹配,匹配失败后i不变,j=1

情况 f(第1个元素失配):
?与abaabc匹配,直接匹配下一个子串


(3)初步结论(第(2)小点中各种情况的总结)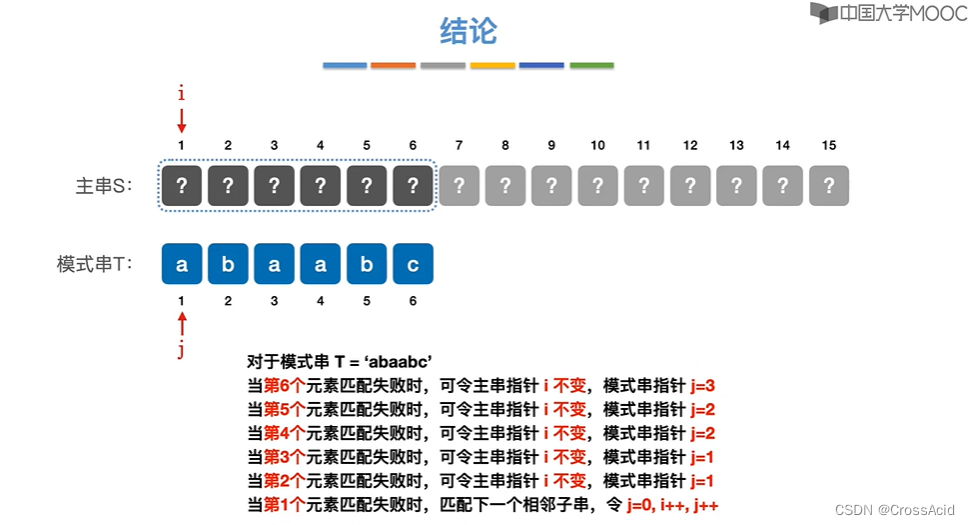
可见,针对最初的例子,可以直接进入第一种情况,直接跳到i=5,j=3进行匹配。经过对朴素模式匹配优化后,主串指针将不再回溯,即充分的利用了上一次匹配的所有信息。
注意:以上结论是针对模式串T = ‘abaabc’的,KMP算法就是对对应的模式串进行处理,得到如上的类似结论,从而优化了字符串模式匹配的效率。
从而,我们可以将结论简化为一个数组来表示,

对应的代码为:
if(S[i] != T[j]){
j = next[i];
if(j == 0){
i++;
j++;
}
}因此,我们将问题提炼为:根据模式串T,求取next数组,从而完成字符串匹配,从而匹配流程如下所示:

对应的,匹配的全部代码如下所示:
int Index_KMP(SString S, SString T, int next[]){
int i = 1, j = 1;
while(S <= i.length && j <= T.length){
if(j == 0 || S.ch[i] == T.ch[j]){
i++;
j++; //继续比较后继字符
}else{
j = next[j]; //模式串指针移动
}
}
if(j > T.length)
return i -T.length; //匹配成功
else
return 0;
}因此,最坏时间复杂度O(m+n),其中,求解next数组的时间复杂度为O(m),匹配的时间辅助度为O(n)。
(4)求取next数组
(考研中会手动模拟即可,一般不考代码实现求next数组)
首先,我们显然可以知道,对于任何模式串,第一个字符不匹配时,只能匹配下一个子串,因此,next[1]恒为 0;
同理,我们也可以知道,第二个字符不匹配时,下一次应尝试匹配模式串的第一个字符,即从头开始匹配,故next[2] = 1;


如图,在不匹配的位置前,画一个分界线, 让模式串一步一步后退,直到分界线前面(左边)能对上,或者模式串完全跨过分界线,此时 j 指向哪儿,next数组的值就是多少(注意,在移动模式串时,j 的位置不变,变的只是模式串的位置)。
从而依次完成next数组的填写。
值得注意的是,此处只需关注不匹配的是第几个位置的元素,无需在意用来匹配的主串的内容,只需不匹配的是第n个元素时,前n-1个都匹配即可。如当需要计算第4个位置不匹配时next数组的值,即next[4]的值时,前三个位置的主串中子串与模式串前三个位置相同即可。
图中对于google这个字符串,根据以上规则,对应的next数组的值应为:

三、KMP算法优化
(1)例一
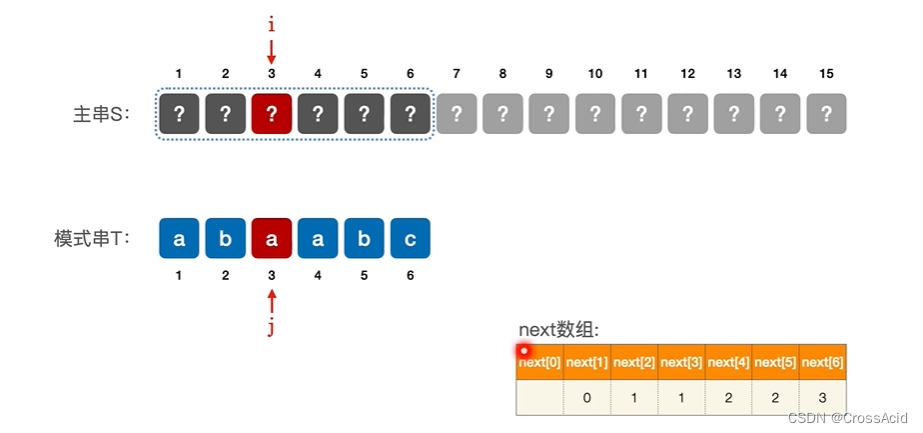
如图可知 ,当使用传统KMP时,当abaabc模式串进行匹配,第三个位置匹配不上时,根据next数组,j 将指向1,即从主串的3位置和模式串的1位置开始匹配。
但我们可以知道,因为第三个位置匹配不上时,显然S[3]的值不等于T[3],即不为a,此时,如果继续跟 j = 1位置的模式串进行匹配,那显然也会失败,因为模式串1位置的值也为a,而这些都是我们已知的信息,因此这种情况下,KMP做了一次没有必要的比较。所以,这就是可以优化的点。
这种情况下,当匹配失败时,下一次匹配为第一个位置匹配失败,next数组中next[1]为0,故我们可以让next[3]的值直接变为0,跳过一次无必要的比较,即直接进行下一个子串的比较。
(2)例二
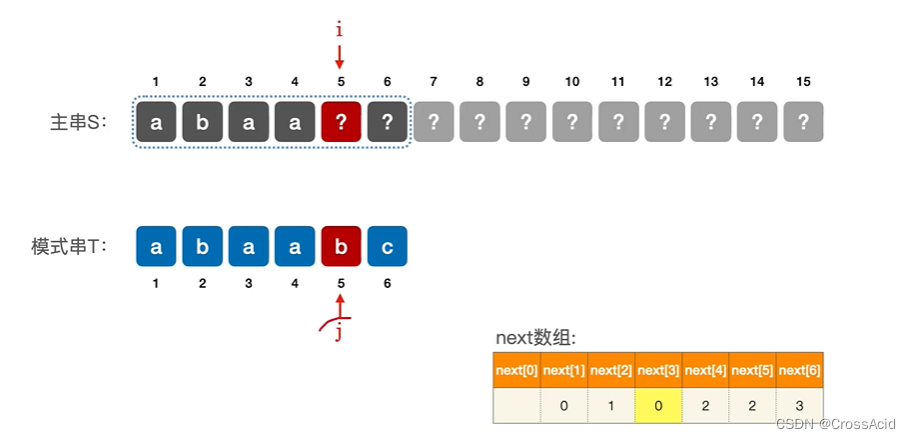

同例一,我们同样可以看到,此时第5个位置不匹配,根据next数组,j = 2 ,跳到该位置进行匹配,但此时我们看到T[2]的值同样为不匹配的T[5]的值,即b,故此次匹配必然失败。
同理,匹配失败后,下一次匹配为第2个位置匹配失败,需要让 j = 1,故可以直接将next[5]的值写为next[2]的值,即1。当第5个位置匹配失败,直接 j = 1,继续匹配。
(3)结论
需要确定next数组对应位置失配时,它指向的 j 位置,对应的字符是否与失配的字符相等,如果相等,则可以直接将next[n](n为失配的位置)的值,等于next[next[j]],如例二中,5失配,对应的next[5] = 2,next[next[5]] = next[2] = 1,即让next[5] = 1。否则,不进行修改。
总结可知,优化KMP算法,实质上就是优化next数组。
可以自行比较一下aaaab的KMP优化前后优化后的效果加深记忆。
(4)优化next数组代码
nextval[1] = 0; //优化后的数组nextval
for(int j = 2; j <= T.length; j++){
if(T.ch[next[j]] == T.ch[j]){
nextval[j] = nextval[next[j]];
}else{
nextval[j] = next[j];
}
}














 964
964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









