










七大排序
目录
排序
排序概念
排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
平时的上下文中,如果提到排序,通常指的是排升序(非降序)。
通常意义上的排序,都是指的原地排序(in place sort)。
排序稳定性
两个相等的数据,如果经过排序后,排序算法能保证其相对位置不发生变化,则我们称该算法是具备稳定性的排序算法。

七大排序总览

时间复杂度
直接插入排序:O(n^2) — 稳定
希尔排序:O(n^1.3-1.5)
选择排序:O(n^2)
堆排序:O(nlogn)
冒泡排序:O(n^2) — 稳定
快速排序:O(nlogn)
归并排序:O(nlogn) — 稳定
拓展
内部排序:
一次性将所有待排序数据放入内存中进行排序,基于元素之间比较的排序。七大排序都属于内部排序。
外部排序
依赖硬盘(外部存储器)进行的排序算法,对于数据集合的要求非常高,只能在特定的场合下使用。
桶排序,基数排序,计数排序三个时间复杂度都为O(n)
注意:
写排序的代码,一定要注意变量是如何定义的,以及未排序区间和已排序区间的定义。
选择排序
直接选择排序
原理
每一次从无序区间选出最大(或最小)的一个元素,存放在无序区间的最后(或最前),直到全部待排序的数据元素排完。
已知区间[ ],未排序空间[0…n] — >. 从未排序空间中选择最小值放在未排序空间的最前 — > 已排序空间[0],未排序空间[1…n]
排序演示
代码实现(以最小值为例)
/**
* 选择排序
* @param arr 待排序数组
*/
public static void selectionSort(int[] arr) {
// 最开始,无序区间[0...n] 有序空间[]
// 当无序区间只剩下一个元素时,整个集合已经有序
for (int i = 0; i < arr.length - 1; i++) {
// min变量存储了当前的最小值索引
int min = i;
//从剩下的元素中选择最小值
for (int j = i + 1; j < arr.length; j++) {
if (arr[min] > arr[j]) {
min = j;
}
}
// min这个索引一定对应了当前无序区间中找到的最小值,换到无序区间最前面i
swap(arr,i,min);
}
}复杂度

双向选择排序(拓展了解)
原理
在原有的基础上,一次排序过程中选出最大和最小值,放在无序区间的最后和最前。
代码实现
//双向选择排序
public static void selectionSortOP(int[] arr) {
int low = 0;
int high = arr.length - 1;
// low = high,无序区间只剩下一个元素,此时数组已经有序
while (low <= high) {
int min = low;
int max = low;
for (int i = low + 1; i <= high; i++) {
if (arr[min] > arr[i]) {
min = i;
}
if (arr[max] < arr[i]) {
max = i;
}
}
//此时min索引一定是无序空间内最小值索引,与low交换
swap(arr, low, min);
if (max == low) {
//此时最大值的位置已经被替换到索引为min的位置
max = min;
}
swap(arr, max, high);
low++;
high--;
}
}插入排序
直接插入排序
基本原理
整个区间被分为:
已经排序的区间[0…i)
待排序的区间[i…n]
每次选择无序区间的第一个元素,在有序区间内选择合适的位置插入。
排序演示
代码实现
/**
* 直接插入排序
* 每次从无序区间中拿一个值插入到已经排序好的区间的合适位置,直到整个数组有序
*
* @param arr
*/
public static void insertionSort(int[] arr) {
//刚开始默认第一个元素为有序区间
for (int i = 1; i < arr.length; i++) {
for (int j = i; j > 0; j--) {
if (arr[j] < arr[j - 1]) {
swap(arr, j, j - 1);
} else {
//此时说明arr[j] >= arr[j - 1]说明已经找到位置,arr[j]已经有序 -- 直接下一次循环
break;
}
}
//内部循环也可写为
// for (int j = i; j > 0 && arr[j] < arr[j - 1]; j--) {
// swap(arr, j, j - 1);
// }
}
}插入排序和选择排序最大的不同在于:
当插入排序当前遍历的元素 > 前驱元素时,此时可以提前结束内层循环。
在极端场景下,当集合是一个完全有序的集合,插入排序内层循环一次都不走 -- 插入排序变为O(n)。
插入排序经常用作高阶排序算法的优化手段之一。
复杂度

折半插入排序
因为插入排序中,每次都是在有序区间中选择插入位置,因此我们可以使用二分查找来定位元素的插入位置。
代码实现
//折半插入查找
public static void insertionSortBS(int[] arr) {
for (int i = 1; i < arr.length; i++) {
int val = arr[i];
int left = 0;
int right = i;
while (left < right) {
int mid = left + (right - left) / 2;
if (arr[mid] > val) {
right = mid;
}
if (arr[mid] < val) {
left = mid + 1;
}
}
//搬移比待插入元素大的元素--left...i的元素
for (int j = i; j > left; j--) {
arr[j] = arr[j - 1];
}
arr[left] = val;
}
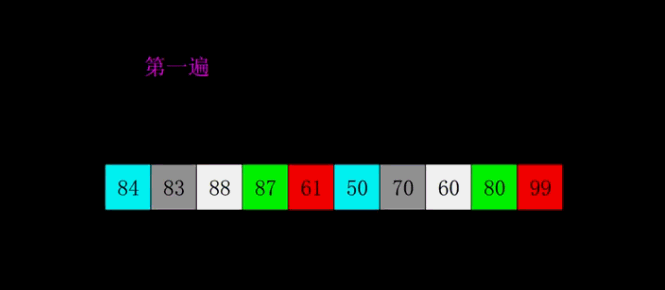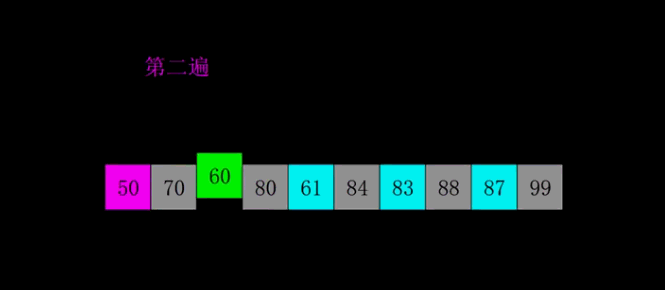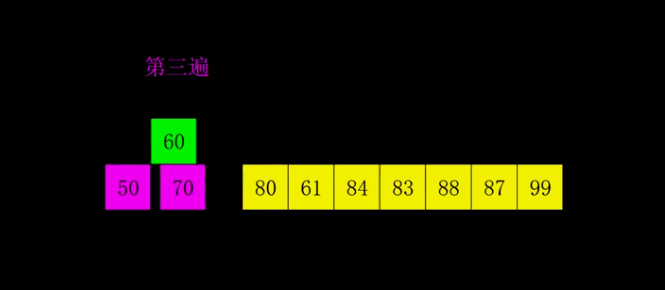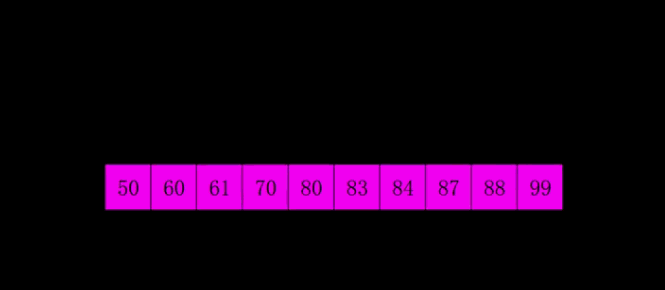
}希尔排序(缩小增量排序)
基本原理
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数,把待排序文件中所有记录分成个组,所有 距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重复上述分组和排序的工作。当到达=1时, 所有记录在统一组内排好序。
1. 希尔排序是对直接插入排序的优化。
2. 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
gap一般都选取数组长度的一半或者三分之一。
核心思路:
将原先很大的数组先按照gap进行拆分,拆分后的数组长度就会不断变小(元素比较少的集合上,插入排序的性能是很高的),当小数组不断调整有序之后,整个大数组就接近有序
排序演示

代码实现
/**
* 希尔排序
*
* @param arr
*/
public static void shellSort(int[] arr) {
int gap = arr.length >> 1;
while (gap > 1) {
insertionSortBygap(arr, gap);
gap >>= 1;
}
//gap == 1的情况
insertionSortBygap(arr,1);
}
/**
* 按照gap分组进行插入排序
*
* @param arr
* @param gap
*/
private static void insertionSortBygap(int[] arr, int gap) {
for (int i = gap; i < arr.length; i++) {
// 不断向前扫描相同gap的元素
// j - gap 从j位置开始向前还有相同步数的元素
for (int j = i; j - gap >= 0 && arr[j] < arr[j - gap]; j -= gap) {
swap(arr, j, j - gap);
}
}
}复杂度

堆排序
基本原理
基本原理也是选择排序,只是不在使用遍历的方式查找无序区间的最大的数,而是通过堆来选择无序区间的最大的
数。(排升序要建大堆,排降序要建小堆)
时间复杂度:O(n*log(n))
空间复杂度:O(1)
排序演示

以最大堆为例:
依次取出最大值直到堆为空,得到一个降序数组,无法在原数组上进行排序,还得创建一个和当前数组大小相同的堆,空间复杂度为O(N)
1.任意数组都可以heapify,调整为最大堆。
2.再次遍历这个最大堆,swap(0,i),每当进行一次swap操作,就把当前堆的最大值交换到最后位置。
代码实现
/**
* 堆排序
*
* @param arr
*/
public static void heapSort(int[] arr) {
// 1.先将arr进行heapify调整为最大堆
// 从最后一个非叶子节点开始进行siftDown操作
for (int i = ((arr.length - 1 - 1) / 2); i >= 0; i--) {
siftDown(arr, i, arr.length);
}
//此时arr变为最大堆
for (int i = (arr.length - 1); i > 0; i--) {
//arr[0] 堆顶元素,就是当前堆的最大值
swap(arr, 0, i);
//下沉操作长度根据i变换是因为,通过循环不断将最大值依次倒着放入数组末尾,所以不再对操作过的末尾进行操作
siftDown(arr, 0, i);
}
}
/**
* 元素下沉操作
*
* @param arr 操作数组
* @param i 当前要下沉的索引
* @param length 数组长度
*/
private static void siftDown(int[] arr, int i, int length) {
while (2 * i + 1 < length) {
int j = 2 * i + 1;
if (j + 1 < length && arr[j] < arr[j + 1]) {
j = j + 1;
}
//此时j是i的左右子树最大值
if (arr[i] > arr[j]) {
break;
} else {
swap(arr, i, j);
i = j;
}
}
}
/**
* 数组元素交换操作
*
* @param arr 交换数组
* @param i 交换位置
* @param j 交换位置
*/
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}冒泡排序
基本原理
在无序区间,通过相邻数的比较,将最大的数冒泡到无序区间的最后,持续这个过程,直到数组整体有序。
图示
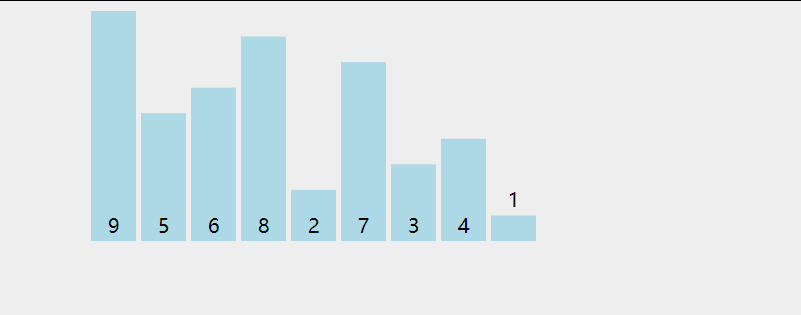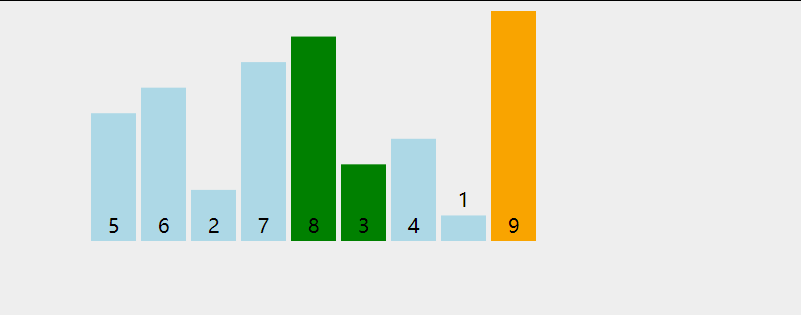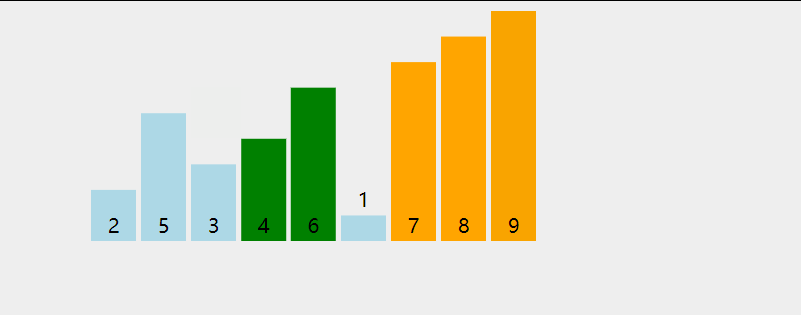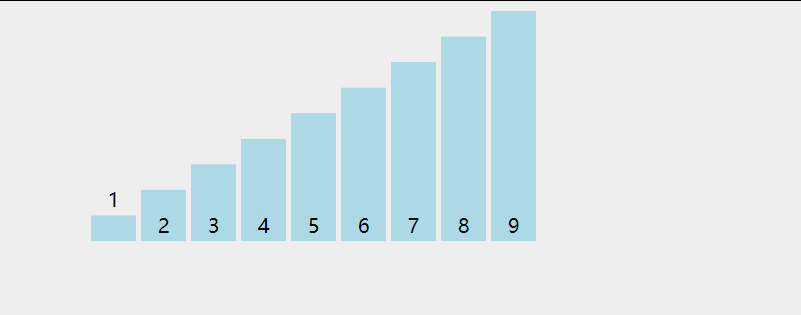
复杂度

代码实现
/**
* 冒牌排序
*
* @param arr 待排序数组
*/
public static void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
boolean isSwaped = true;
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
swap(arr, j, j + 1);
isSwaped = false;
}
}
if (isSwaped) break;
}
}归并排序
基本原理
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子 序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归:将原数组不断拆分,一直拆到每个子数组只有一个元素时,第一个阶段结束,归而为一这个阶段结束。
并:将相邻的两个数组合并为一个有序的数组,直到整个数组有序。
排序演示


代码实现
/**
* 归并排序
*
* @param arr
*/
public static void mergeSort(int[] arr) {
mergeSortInternal(arr, 0, arr.length - 1);
}
/**
* 在arr[r...l]上进行归并排序
*
* @param arr
* @param l
* @param r
*/
private static void mergeSortInternal(int[] arr, int l, int r) {
if (l >= r) {
//当前数组只剩一个元素,归过程结束
return;
}
int mid = l + ((r - l) >> 1);
// 将原数组拆分为左右两个小区间,分别递归进行
mergeSortInternal(arr, l, mid);
mergeSortInternal(arr, mid + 1, r);
//merge并数组
merge(arr, l, mid, r);
}
/**
* 合并两个子数组arr[l...mid] 和 arr[mid + 1 ... r]
* 为一个大的有序数组arr[l...r]
*
* @param arr
* @param l
* @param mid
* @param r
*/
private static void merge(int[] arr, int l, int mid, int r) {
//先创建一个新的临时数组aux
int[] aux = new int[r - l + 1];
//将arr元素值拷贝到aux上
for (int i = 0; i < aux.length; i++) {
//加l是因为实际数组偏移量
aux[i] = arr[i + l];
}
//左侧数组开始索引
int i = l;
//右侧数组开始索引
int j = mid + 1;
//k表示当前正在合并的原数组的索引下表
for (int k = l; k <= r; k++) {
if (i > mid) {
// 左侧区间已经处理完毕,只需要将右侧区间值拷贝到原数组即可
arr[k] = aux[j - l];
j++;
} else if (j > r) {
// 右侧区间已经处理完毕,只需要将左侧区间值拷贝到原数组即可
arr[k] = aux[i - l];
i++;
} else if (aux[i - l] <= aux[j - l]) {
//此时左侧区间的元素较小,相等元素放在左区间,保证稳定性
arr[k] = aux[i - l];
i++;
}else {
// 右侧区间元素较小
arr[k] = aux[j - l];
j++;
}
}
}复杂度

归并排序的两点优化
1.当左右两个子区间走完子函数后,左右两个区间已经有序了。
如果此时arr[mid] < arr[mid + 1]
arr[mid] 已经是最左区间的最大值
arr[mid + 1] 已经是右区间的最小值
此时整个区间已经有序了,没必要再执行merge过程!
2.在小区间上,我们可以直接使用插入排序来优化,没必要元素一直拆分到1位置
通常为当 r - l <= 15时使用插入排序,这样就可以减小递归的次数。
优化代码
private static void mergeSortInternal(int[] arr, int l, int r) {
//未优化
// if (l >= r) {
// //当前数组只剩一个元素,归过程结束
// return;
// }
//优化2
if (r - l <= 15) {
//小区间使用插入排序
insertionSortOfmerge(arr, l, r);
return;
}
int mid = l + ((r - l) >> 1);
// 将原数组拆分为左右两个小区间,分别递归进行
//走完这个函数之后arr的左区间已经有序
mergeSortInternal(arr, l, mid);
//走完这个函数之后arr的右区间已经有序
mergeSortInternal(arr, mid + 1, r);
//优化1
//只有当两个左右子区间还有先后顺序不同时merge并
if (arr[mid] > arr[mid + 1]) {
merge(arr, l, mid, r);
}
}
//服务于归并的插入排序
private static void insertionSortOfmerge(int[] arr, int l, int r) {
for (int i = l + 1; i <= r; i++) {
for (int j = i; j > l && arr[j] < arr[j - 1]; j--) {
swap(arr, j, j - 1);
}
}
}
非递归代码
public static void mergeSortNonRecursion(int[] arr) {
// 最外层循环表示每次合并的子数组的元素个数
for (int sz = 1; sz <= arr.length; sz += sz) {
// 内层循环的变量i表示每次合并的开始索引
// i + sz 就是右区间的开始索引,i + sz < arr.length说明还存在右区间
for (int i = 0; i + sz < arr.length; i += sz + sz) {
merge(arr, i, i + sz - 1, Math.min(i + sz + sz - 1, arr.length - 1));
}
}
}海量数据的排序问题
外部排序:排序过程需要在磁盘等外部存储进行的排序
前提:内存只有 1G,需要排序的数据有 100G 因为内存中因为无法把所有数据全部放下,所以需要外部排序,而归并排序是最常用的外部排序
1. 先把文件切分成 200 份,每个 512 M
2. 分别对 512 M 排序,因为内存已经可以放的下,所以任意排序方式都可以 3. 进行 200 路归并,同时对 200 份有序文件做归并过程,最终结果就有序了
快速排序
基本原理
基于《算法导论》的思想实现
1. 从待排序区间选择一个数,作为基准值(pivot);
2. Partition: 遍历整个待排序区间,将比基准值小的(可以包含相等的)放到基准值的左边,将比基准值大的(可以包含相等的)放到基准值的右边;
3. 采用分治思想,对左右两个小区间按照同样的方式处理,直到小区间的长度 == 1,代表已经有序,或者小区间的长度 == 0,代表没有数据。
基准值的选择
在数组趋近有序的情况下,普通排序会退化,所以可以对基准值通过不同的方法选择来改善
1. 选择边上(左或者右)
2. 随机选择(推荐使用,代码实现也是采用的该方法)
3. 几数取中(例如三数取中):array[left], array[mid], array[right] 大小是中间的为基准值
排序演示
普通优化快排代码
private static final ThreadLocalRandom random = ThreadLocalRandom.current();
public static void quickSort(int[] arr) {
quickSortInternal(arr, 0, arr.length - 1);
}
/**
* 在arr[l...r]上进行快速排序
*
* @param arr
* @param l
* @param r
*/
private static void quickSortInternal(int[] arr, int l, int r) {
if (r - l <= 15) {
insertionSort(arr, l, r);
return;
}
//先获取分区点
//分区点就是经过函数分区后,某个元素落在了最终的位置
//分区点左侧小于该元素的区间,右侧大与该元素的区间
int p = partition(arr, l, r);
quickSortInternal(arr, l, p - 1);
quickSortInternal(arr, p + 1, r);
}
/**
* 在arr[l..r]上的分区函数,返回分区点的索引
*
* @param arr
* @param l
* @param r
* @return
*/
private static int partition(int[] arr, int l, int r) {
//随机在当前数组中选一个数
int randomIndex = random.nextInt(l, r);
swap(arr, l, randomIndex);
int v = arr[l];
// arr[l + 1..j] < v
// arr[j + 1..i) >= v
// i表示当前正在扫描的元素
// j指向的是比v小的元素,j + 1指向的是第一个比v大或等于的元素
int j = l;
for (int i = l + 1; i <= r; i++) {
if (arr[i] < v) {
swap(arr, i, j + 1);
j++;
}
}
swap(arr, j, l);
return j;
}非递归实现
public static void quickSortNonRecursion(int[] arr) {
Deque<Integer> stack = new ArrayDeque<>();
//栈中保存当前集合的开始位置和终止位置
int l = 0;
int r = arr.length - 1;
stack.push(r);
stack.push(l);
while (!stack.isEmpty()) {
//栈不为空时,说明子区间还没有处理完毕
int left = stack.pop();
int right = stack.pop();
if (left >= right) {
continue;
}
int p = partition(arr,left,right);
//依次将右区间的开始和结束位置入栈
stack.push(right);
stack.push(p + 1);
stack.push(p - 1);
stack.push(left);
}
}挖坑法
基本思路普通快排一致,只是不再进行交换,而是进行赋值(填坑+挖坑),必须先从后向前扫描,再从前向后扫描,如果先从前向后会丢失数据
private static int partition(int[] array, int left, int right) {
int i = left;
int j = right;
int pivot = array[left];
while (i < j) {
while (i < j && array[j] >= pivot) {
j--;
}
array[i] = array[j];
while (i < j && array[i] <= pivot) {
i++;
}
array[j] = array[i];
}
array[i] = pivot;
return I;
}数组元素重复问题
在极端情况下,当100w个元素全都是一个值的时候,分区之后,< v的元素就没有,全都在 >= v的集合中!二叉树退化为单支树,退化为O(N^2)
二路快排
将相等的元素均分到左右两个字区间:使用两个变量i和j
i从前向后扫描碰到第一个arr[i] >= v的元素停止
J从后向前扫描碰到第一个arr[j] <=v的元素停止
交换i和j对应的元素,这样就可以把相等元素平均到左右两个子区间。
当I>=j时,整个集合就扫描结束。
二路快排代码实现
//二路快排
public static void quickSort2(int[] arr) {
quickSortInternal2(arr, 0, arr.length - 1);
}
private static void quickSortInternal2(int[] arr, int l, int r) {
if (r - l <= 15) {
insertionSort(arr, l, r);
return;
}
int p = partition2(arr, l, r);
quickSortInternal2(arr, l, p - 1);
quickSortInternal2(arr, p + 1, r);
}
/**
* 二路快排的分区
* 在arr[l..r]上进行分区处理
*
* @param arr
* @param l
* @param r
* @return
*/
private static int partition2(int[] arr, int l, int r) {
int randomIndex = random.nextInt(l, r);
swap(arr, l, randomIndex);
int v = arr[l];
int i = l + 1;
int j = r;
while (true) {
while (i <= j && arr[i] < v) {
i++;
}
while (i <= j && arr[j] > v) {
j--;
}
if (i >= j) {
break;
}
swap(arr, i, j);
i++;
j--;
}
swap(arr, l, j);
return j;
}三路快排(了解)
原理
在一次分区函数的操作中,将所有相等的元素都放在最终位置,只需要在小于v和大于v的子区间上进行快排,所有相等的元素就不再处理了。
思路
定义三个变量lt,i,gt —— lt指向的是<v的最后一个元素,i指向的是当前扫描元素,gt指向>v的第一个元素。
在交换时,区间arr[l + 1…lt] < v,arr[lt + 1…i] = v,arr[gt…r] > v
1.当前扫描元素e < v - - > swap(arr, i ,lt + 1);i++;lt++;
2.当前扫描元素e = v - - > i++;
3.当前扫描元素e > v - - > swap(arr, gt - 1 , i);gt—;
4.最后交换swap(arr , l , lt)
三路快排代码实现
//三路快排
public static void quickSort3(int[] arr) {
quickSortInternal3(arr, 0, arr.length - 1);
}
private static void quickSortInternal3(int[] arr, int l, int r) {
if (r - l <= 15) {
insertionSort(arr, l, r);
return;
}
int randomIndex = random.nextInt(l, r);
swap(arr, l, randomIndex);
int v = arr[l];
// 这些变量的取值,一定是满足区间的定义,最开始的时候,所有区间都是空
// arr[l + 1..lt] < v
// lt是指向最后一个<v的元素
int lt = l;
// arr[lt + 1..i) == v
// i - 1是最后一个 = v的元素
int i = l + 1;
// arr[gt..r] > v
// gt是第一个 > v的元素
int gt = r + 1;
// i从前向后扫描和gt重合时,所有元素就处理完毕
while (i < gt) {
if (arr[i] < v) {
// arr[l + 1..lt] < v
// arr[lt + 1..i) == v
swap(arr, i, lt + 1);
lt++;
i++;
} else if (arr[i] > v) {
// 交换到gt - 1
swap(arr, i, gt - 1);
gt--;
// 此处i不++,交换来的gt - 1还没有处理
} else {
// 此时arr[i] = v
i++;
}
}
// lt落在最后一个 < v的索引处
swap(arr, l, lt);
// arr[l..lt - 1] < v
quickSortInternal3(arr, l, lt - 1);
// arr[gt..r] > v
quickSortInternal3(arr, gt, r);
}复杂度

快速排序的nlogn,其中logN就是递归函数的调用次数,n是数组遍历。
几种快排的总结
1.当待排序的集合重复元素并不多时,随机化快排已经可以解决问题,甚至性能比2路和3路快排还要好(2路和3路快排主要是为了解决重复元素引入了很多变量和分支)。
2.当待排序集合中有大量重复元素时,使用2路或3路快排优化重复元素的处理,能理解清楚思路即可。
3.如果待排序集合是一个接近有序的集合,我们分区点的选择就不能单纯的选择最左侧或最右侧元素,可以采用随机化选择和三数取中。
排序总结


排序测试截图
因为测试长度为一千万,所以没有测试插入,冒泡,选择排序,(需要测试类代码的朋友可以留言)。

















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











