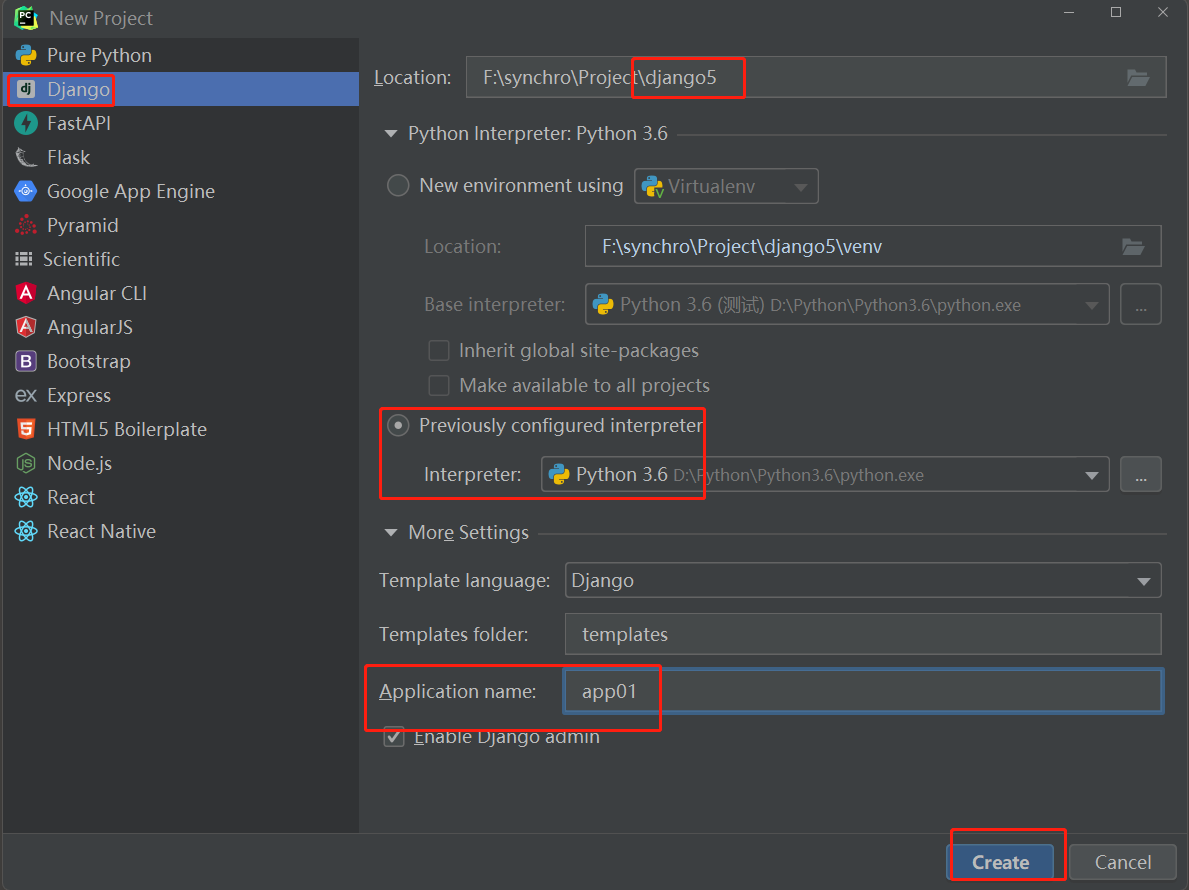
0. 解决templates 路径拼接问题
1. 注释csrf中间键
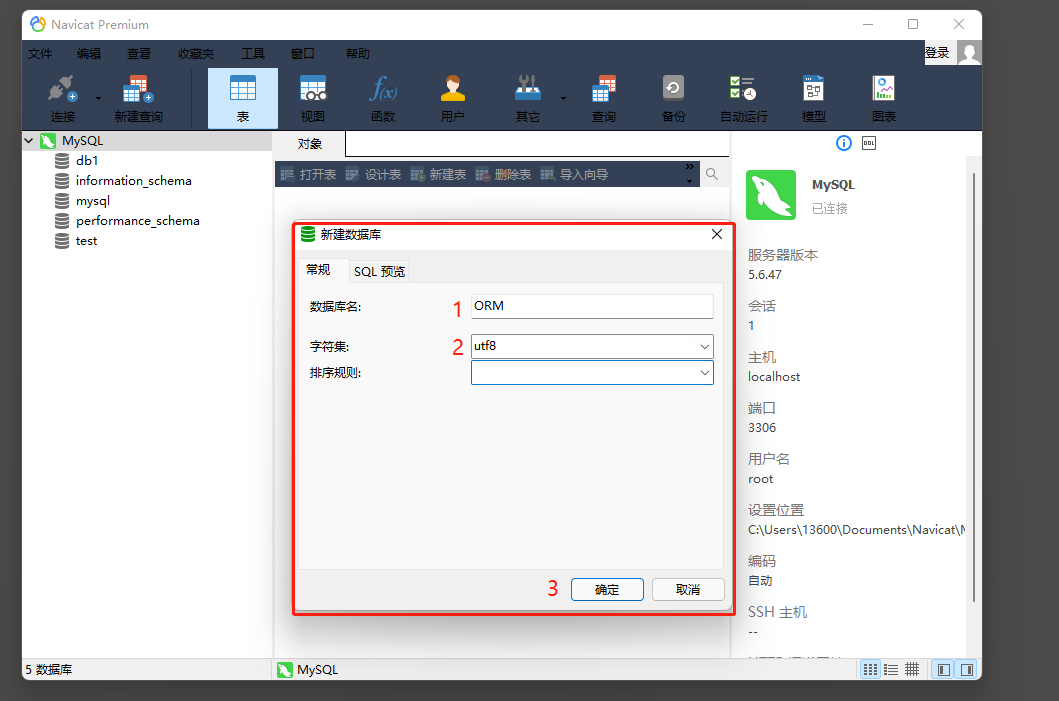
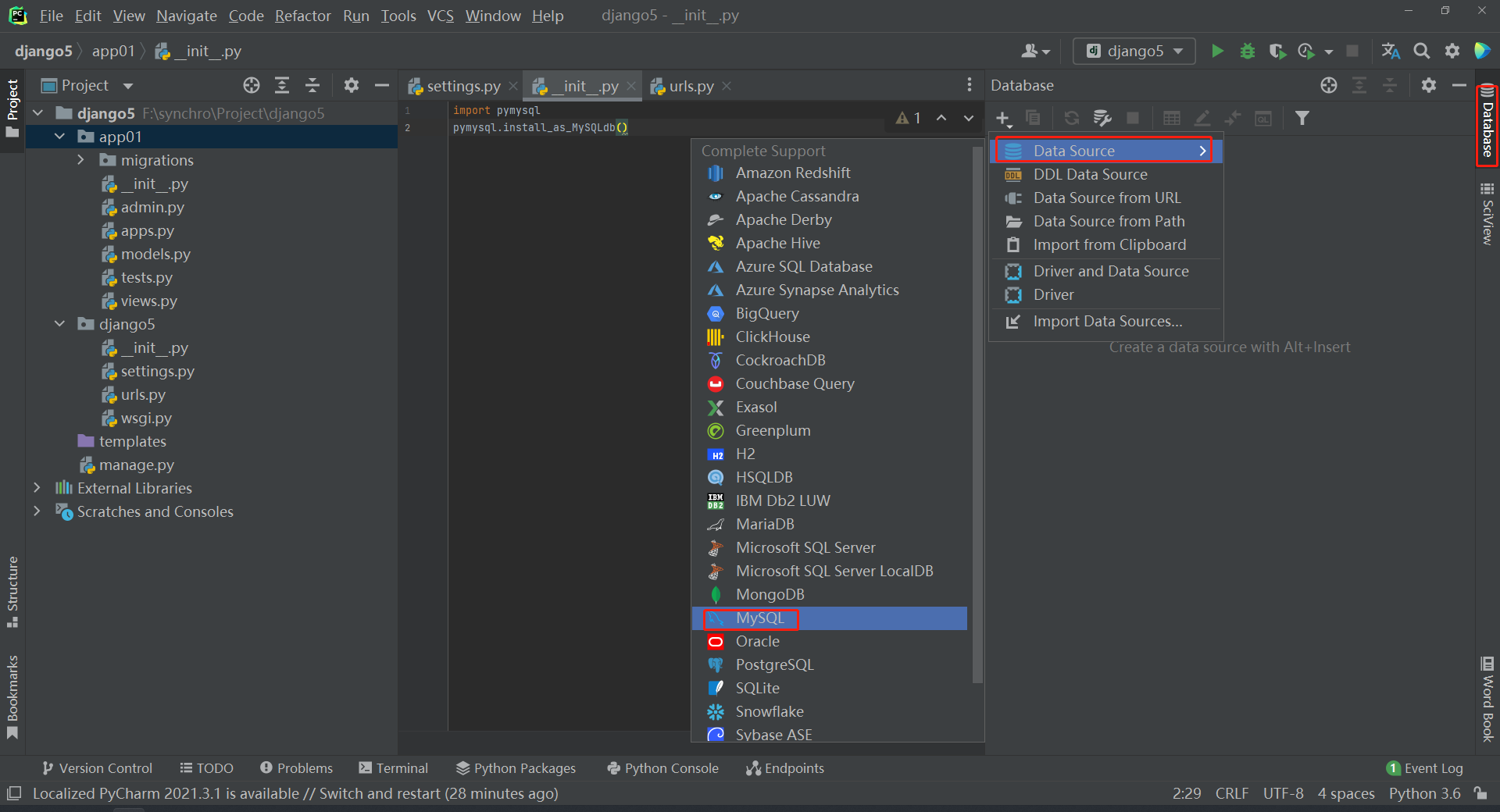
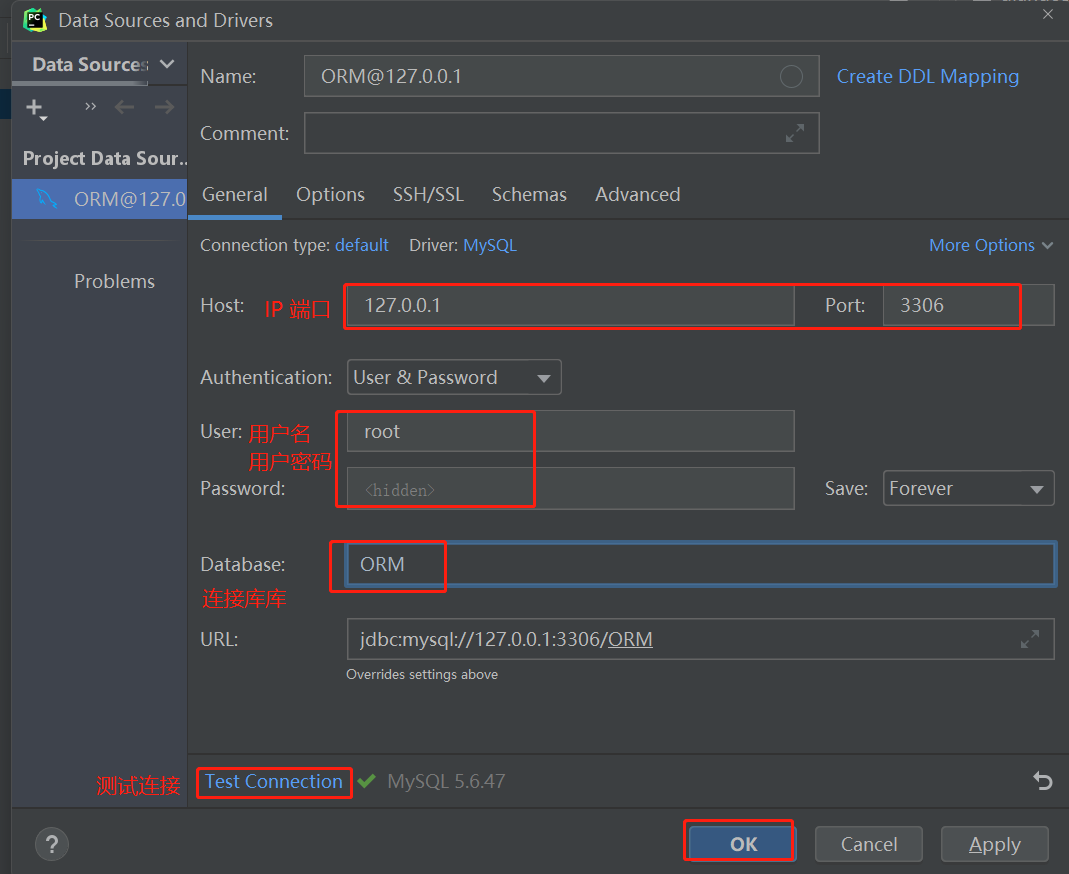
* 连接以及存在的MySQL数据库
0. Navicat 中创建 一个 OMR 库 .
1. settings 配置文件中第 75 行中 设置 mysql数据的连接信息
2. 导入pymysql模块 , 设置pymysql 连接 mysql .
DATABASES = {
'default' : {
'ENGINE' : 'django.db.backends.mysql' ,
'NAME' : 'ORM' ,
'HOST' : '127.0.0.1' ,
'POST' : '3306' ,
'USER' : 'root' ,
'PASSWORD' : '123' ,
'CHARSET' : 'utf8' ,
}
}
import pymysql
pymysql. install_as_MySQLdb( )
先测试成功在连接 .
将下面代码复制到app01 应用下的tests . py 文件中 .
from django. test import TestCase
import os
import sys
if __name__ == "__main__" :
os. environ. setdefault( "DJANGO_SETTINGS_MODULE" , "day64.settings" )
import django
django. setup( )
from app01 import models
在app01下的model . py创建User表。
models . DateField ( ) 日期字段 年月日
register_time = models . DateTimeField ( ) # 日期字段 年月日 时分秒
时间字段参数 :
auto_now : 每次操作数据的时候 , 该字段会自动将当前的时间更新 , 操作数据的时间 .
auto_now_add:创建数据的时候会自动将创建的时间记录下来 , 不认为修改就不会改变 .
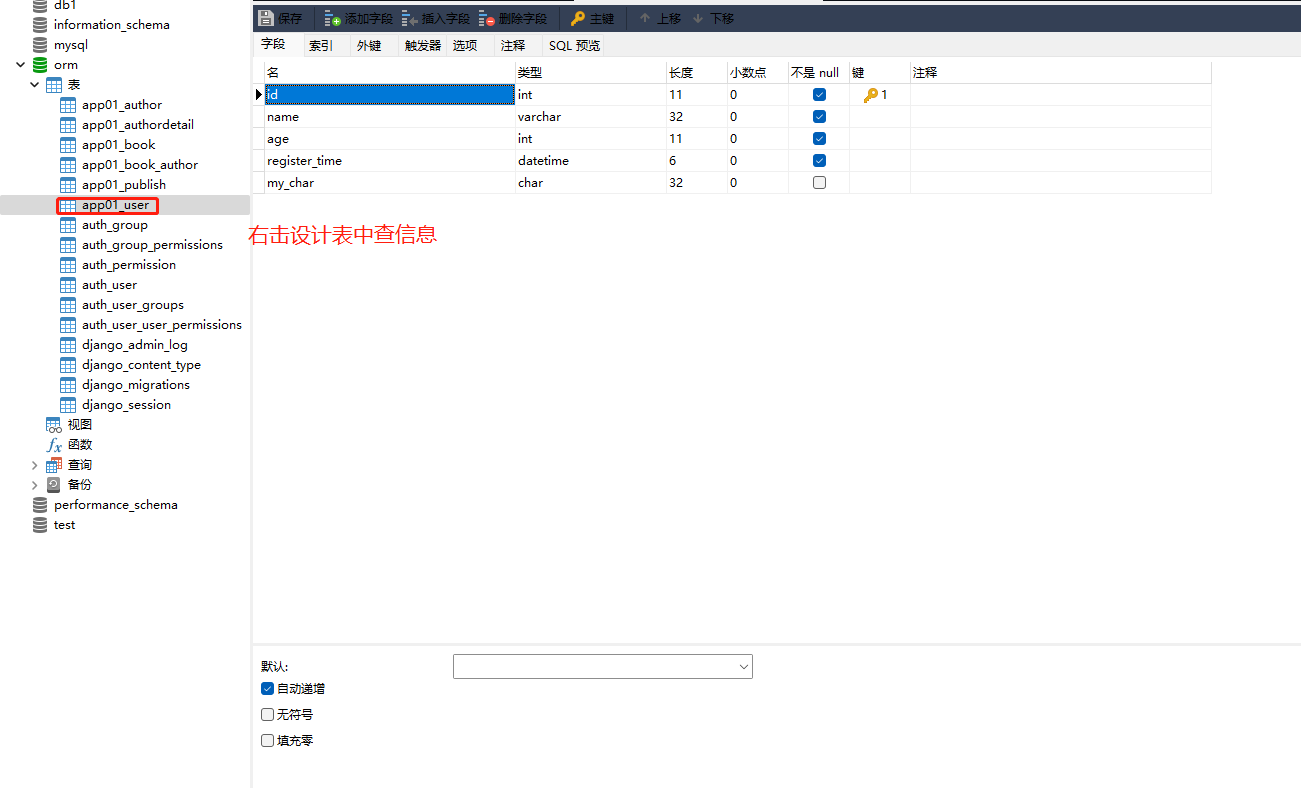
class User ( models. Model) :
name = models. CharField( max_length= 32 , verbose_name= '用户名' )
age = models. IntegerField( )
register_time = models. DateTimeField( auto_now_add= True )
在终端输入:
python manage . py makemigrations
python manage . py migrate
在测试文件tests . py 中写
res1 = models. User. objects. create( name= 'kid' , age= 18 )
import datetime
ctime = datetime. datetime. now( )
user_obj = models. User( name= 'qz' , age= 18 , register_time= ctime)
user_obj. save( )
一般使用主键作为查询依据。
res2 = models. User. objects. filter ( id = 1 ) . delete( )
res3 = models. User. objects. filter ( pk= 2 ) . delete( )
pk会自动查找当前表的主键字段 , 不需要指代当前表的主键字段到底叫什么 uid pid sid .
user_obj = models. User. objects. filter ( pk= 3 ) . first( )
user_obj. delete( )
models. User. objects. filter ( pk= 4 ) . update( name= 'qaz' )
user_obj = models. User. objects. filter ( pk= 4 )
user_obj. update( name= 'qqq' )
user_obj = models. User. objects. get( pk= 4 )
print ( user_obj)
user_obj. name = 'xxxx'
user_onj. save( )
filter 取不存在的值为空 , 不会报错
get 取不存在的值会报错 用户匹配查询不存在。
app . models . DoesNotExist : User matching query does not exist .
QuerySet对象内部封装的sql语句。
querset对象 . query
res1 = models. User. objects. all ( )
print ( res1, type ( res1) )
print ( res1. query)
将下面代码复制到settings . py配置文件中。随便找个位置放。
所有的ORM语句都能自动触发打印sql语句。
LOGGING = {
'version' : 1 ,
'disable_existing_loggers' : False ,
'handlers' : {
'console' : {
'level' : 'DEBUG' ,
'class' : 'logging.StreamHandler' ,
} ,
} ,
'loggers' : {
'django.db.backends' : {
'handlers' : [ 'console' ] ,
'propagate' : True ,
'level' : 'DEBUG' ,
} ,
}
}
0. objects是Manager类型的对象 , 是Model和数据库进行查询的接口 .
1. all ( ) 查询所有数据 , 结果是queryset对象 , 列表套套字典 .
2. get_queryset ( ) 获取所有queryset对象数据 , 结果是queryset对象 , 列表套套元组 .
* 结果一样的
3. filter ( ) 过滤条件查询 , 结果是queryset对象 , 列表套数据对象 .
4. get ( ) 直接拿数据对象 , 但是条件不存在直接报错 .
5. first ( ) 表中第一条数据 , 结果是一个queryset对象 .
6. last ( ) 表中最后一个数据 , 结果是一个queryset对象 .
7. values ( ) 指定获取的字段 , 返回该字段所有的值 , 结果是列表套字典 .
8. valuce_list ( ) 指定获取的字段 , 返回该字段所有的值 , 是列表套元组 .
9. distinct ( ) 去重
10. order_by ( ) 排序
11. reverse ( ) 倒序
12. count ( ) 统计
13. exclude ( ) 排除
14. excsts ( ) 判断值是否存在
def __str__ ( self) :
return '%s %s %s' % ( self. name, self. age, self. register_time)
为表添加几条数据用于测试 .
objects是Manager类型的对象 .
user_obj = models. User. objects
print ( user_obj, type ( user_obj) )
all ( ) get_queryset ( )
查询所有数据 , 结果是列表套queryset对象 .
user_obj = models. User. objects. all ( )
print ( user_obj, type ( user_obj) )
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` LIMIT 21 ; args= ( )
user_obj = models. User. objects. get_queryset( )
print ( user_obj, type ( user_obj) )
( 0.001 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` LIMIT 21 ; args= ( )
filter ( ) 过滤条件查询 , 结果是queryset .
get ( ) 直接拿数据对象 , 但是条件不存在直接报错 .
user_obj = models. User. objects. filter ( )
print ( user_obj, type ( user_obj) )
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` LIMIT 21 ; args= ( )
user_obj = models. User. objects. filter ( pk= 5 )
print ( user_obj, type ( user_obj) )
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE ` app01_user` . ` id` = 5 LIMIT 21 ; args= ( 5 , )
user_obj = models. User. objects. get( pk= 5 )
print ( user_obj, type ( user_obj) )
( 0.001 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE ` app01_user` . ` id` = 5 ; args= ( 5 , )
first ( ) 表单中第一条数据 , 元素queryset对象的值 , 结果是表的数据对象 .
last ( ) 表单中最后一个元素 , 结果是表的数据对象 .
user_obj = models. User. objects. first( )
print ( user_obj, type ( user_obj) )
( 0.001 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` ORDER BY ` app01_user` . ` id` ASC LIMIT 1 ; args= ( )
user_obj = models. User. objects. last( )
print ( user_obj, type ( user_obj) )
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` ORDER BY ` app01_user` . ` id` DESC LIMIT 1 ; args= ( )
values ( ) : 指定获取的字段 , 返回该字段所有的值 , 结果是列表套字典 .
values_list ( ) : 指定获取的字段 , 返回该字段所有的值 , 是列表套元组 .
* 不指定字段获取所有字段的数据
user_obj = models. User. objects. values( 'name' )
print ( user_obj, type ( user_obj) )
( 0.001 ) SELECT ` app01_user` . ` name` FROM ` app01_user` LIMIT 21 ; args= ( )
user_obj = models. User. objects. values_list( 'name' , 'age' )
print ( user_obj, type ( user_obj) )
( 0.001 ) SELECT ` app01_user` . ` name` , ` app01_user` . ` age` FROM ` app01_user` LIMIT 21 ; args= ( )
* 不指定字段获取所有字段的数据
user_obj = models. User. objects. values( )
print ( user_obj)
user_obj = models. User. objects. values_list( )
print ( user_obj)
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` LIMIT 21 ; args= ( )
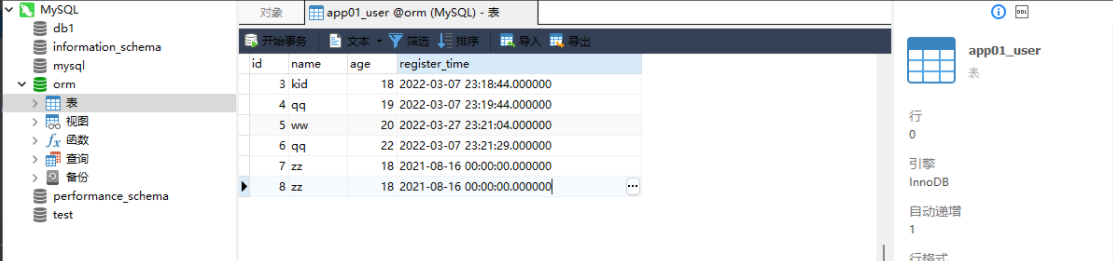
先准备下相同的数据 , id不要设置成一样的 , 这张表的id是唯一的 .
id name age register_time
7 kid 18 2021 - 08 - 16 00 : 00 : 00.000000
8 kid 18 2021 - 08 - 16 00 : 00 : 00.000000
去重一定要是一模一样的数据 ,
如果带有主键那么肯定是不一样的 , 在查询中注意主键。
user_obj = models. User. objects. values( ) . distinct( )
print ( user_obj, type ( user_obj) )
( 0.001 ) SELECT DISTINCT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` LIMIT 21 ; args= ( )
user_obj = models. User. objects. values( 'name' ) . distinct( )
print ( user_obj, type ( user_obj) )
( 0.000 ) SELECT DISTINCT ` app01_user` . ` name` FROM ` app01_user` LIMIT 21 ; args= ( )
user_obj = models. User. objects. values( 'name' , 'age' ) . distinct( )
print ( user_obj, type ( user_obj) )
( 0.000 ) SELECT DISTINCT ` app01_user` . ` name` , ` app01_user` . ` age` FROM ` app01_user` LIMIT 21 ; args= ( )
如果id不是唯一的可以这样测试下 .
models . User . objects . distinct ( )
. order_by ( ) 指定排序的字典 不指定就以主键
默认为升序
降序 在字段前面加上-负号
数字按从小到大排序
字符按子母表排序
user_obj = models. User. objects. order_by( 'age' )
print ( user_obj, type ( user_obj) )
< QuerySet [ < User : kid 18 2022 - 03 - 07 23 : 18 : 44 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ,
< User : qq 19 2022 - 03 - 07 23 : 19 : 44 + 00 : 00 > ,
< User : ww 20 2022 - 03 - 27 23 : 21 : 04 + 00 : 00 > ,
< User : qq 22 2022 - 03 - 07 23 : 21 : 29 + 00 : 00 > ] >
< class 'django.db.models.query.QuerySet' >
( 0.001 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` ORDER BY ` app01_user` . ` age` ASC LIMIT 21 ; args= ( )
user_obj = models. User. objects. order_by( '-age' )
print ( user_obj, type ( user_obj) )
< QuerySet [ < User : qq 22 2022 - 03 - 07 23 : 21 : 29 + 00 : 00 > ,
< User : ww 20 2022 - 03 - 27 23 : 21 : 04 + 00 : 00 > ,
< User : qq 19 2022 - 03 - 07 23 : 19 : 44 + 00 : 00 > ,
< User : kid 18 2022 - 03 - 07 23 : 18 : 44 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ] >
< class 'django.db.models.query.QuerySet' >
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` ORDER BY ` app01_user` . ` age` DESC LIMIT 21 ; args= ( )
. order_by ( ) . reverse ( ) 数据必须是排过序的。
user_obj = models. User. objects. order_by( 'age' ) . reverse( )
print ( user_obj, type ( user_obj) )
< QuerySet [ < User : qq 22 2022 - 03 - 07 23 : 21 : 29 + 00 : 00 > ,
< User : ww 20 2022 - 03 - 27 23 : 21 : 04 + 00 : 00 > ,
< User : qq 19 2022 - 03 - 07 23 : 19 : 44 + 00 : 00 > ,
< User : kid 18 2022 - 03 - 07 23 : 18 : 44 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ] >
< class 'django.db.models.query.QuerySet' >
count ( ) 统计当前数据的个数。
user_obj = models. User. objects. count( )
print ( user_obj)
( 0.000 ) SELECT COUNT ( * ) AS ` __count` FROM ` app01_user` ; args= ( )
. exclude ( ) 排除指定的条件
user_obj = models. User. objects. exclude( name= 'kid' )
print ( user_obj)
# < QuerySet [ < User : qq 19 2022 - 03 - 07 23 : 19 : 44 + 00 : 00 > ,
< User : ww 20 2022 - 03 - 27 23 : 21 : 04 + 00 : 00 > ,
< User : qq 22 2022 - 03 - 07 23 : 21 : 29 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ] >
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE NOT ( ` app01_user` . ` name` = 'kid' ) LIMIT 21 ; args= ( 'kid' , )
. exists ( ) 返回值为布尔值。
user_obj = models. User. objects. filter ( name= 'kid' ) . exists( )
print ( user_obj)
( 0.000 ) SELECT ( 1 ) AS ` a` FROM ` app01_user` WHERE ` app01_user` . ` name` = 'kid' LIMIT 1 ; args= ( 'kid' , )
搭配字段使用 字段__xx
1. __gt 大于
2. ——lt 小于
3. __gte 大于等于
4. __lte 小于等于
5. __in [ x1, x2 ] 查询多个值x1 和x2
6. ——range [ x1, x9 ] 查询x1 - x9 之间所有值
7. __contains = ' ' 模糊查询 , 区分大小写
8. __icontains = ' ' 模糊查询 , 不区分大小写
9. __starswith = ' ' 以什么开头
10. __endwith = ' ' 以什么结尾
11. __day = 天
12. __month = 月
13. __year = 年
14. __week_day = 星期几
1. 查询年龄大于 20 岁的数据
user_obj = models. User. objects. filter ( age__gt= 20 )
print ( user_obj)
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE ` app01_user` . ` age` > 20 LIMIT 21 ; args= ( 20 , )
2. 查询年龄小于 20 岁的数据
user_obj = models. User. objects. filter ( age__lt= 20 )
print ( user_obj)
< QuerySet [ < User : kid 18 2022 - 03 - 07 23 : 18 : 44 + 00 : 00 > ,
< User : qq 19 2022 - 03 - 07 23 : 19 : 44 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ] >
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE ` app01_user` . ` age` < 20 LIMIT 21 ; args= ( 20 , )
3. 查询年龄在 18 、 20 岁的数据
user_obj = models. User. objects. filter ( age__in= [ 18 , 20 ] )
print ( user_obj)
< QuerySet [ < User : kid 18 2022 - 03 - 07 23 : 18 : 44 + 00 : 00 > ,
< User : ww 20 2022 - 03 - 27 23 : 21 : 04 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ] >
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE ` app01_user` . ` age` IN ( 18 , 20 ) LIMIT 21 ; args= ( 18 , 20 )
4. 查询 18 岁到 22 岁的数据
user_obj = models. User. objects. filter ( age__range= [ 18 , 22 ] )
print ( user_obj)
< QuerySet [ < User : kid 18 2022 - 03 - 07 23 : 18 : 44 + 00 : 00 > ,
< User : qq 19 2022 - 03 - 07 23 : 19 : 44 + 00 : 00 > ,
< User : ww 20 2022 - 03 - 27 23 : 21 : 04 + 00 : 00 > ,
< User : qq 22 2022 - 03 - 07 23 : 21 : 29 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ,
< User : zz 18 2021 - 08 - 16 00 : 00 : 00 + 00 : 00 > ] >
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE ` app01_user` . ` age` BETWEEN 18 AND 22 LIMIT 21 ; args= ( 18 , 22 )
5. 查询名字中有k的数据
user_obj = models. User. objects. filter ( name__contains= 'k' )
print ( user_obj)
( 0.008 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE ` app01_user` . ` name` LIKE BINARY '%k%' LIMIT 21 ; args= ( '%k%' , )
6. 查询名字中有k的数据 ( 忽略大小写 )
user_obj = models. User. objects. filter ( name__icontains= 'K' )
print ( user_obj)
( 0.000 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE ` app01_user` . ` name` LIKE '%K%' LIMIT 21 ; args= ( '%K%' , )
7. 查询注册时间是 2022 年的数据
user_obj = models. User. objects. filter ( register_time__year= 2022 )
print ( user_obj)
user_obj = models. User. objects. filter ( register_time__year= '2022' )
print ( user_obj)
< QuerySet [ < User : kid 18 2022 - 03 - 07 23 : 18 : 44 + 00 : 00 > ,
< User : qq 19 2022 - 03 - 07 23 : 19 : 44 + 00 : 00 > ,
< User : ww 20 2022 - 03 - 27 23 : 21 : 04 + 00 : 00 > ,
< User : qq 22 2022 - 03 - 07 23 : 21 : 29 + 00 : 00 > ] >
( 0.000 ) SELECT `app01_user`. `id `, `app01_user`. `name`, `app01_user`. `age`, `app01_user`. `register_time` FROM `app01_user` WHERE `app01_user`. `register_time` BETWEEN '2022-01-01 00:00:00' AND '2022-12-31 23:59:59.999999' LIMIT 21 ; args= ( '2022-01-01 00:00:00' , '2022-12-31 23:59:59.999999' )
8. 查询注册时间是 3 月的数据
user_obj = models. User. objects. filter ( register_time__month= 3 )
print ( user_obj)
< QuerySet [ < User : kid 18 2022 - 03 - 07 00 : 00 : 00 > ,
< User : qq 19 2022 - 03 - 07 00 : 00 : 00 > ,
< User : ww 20 2022 - 03 - 27 00 : 00 : 00 > ,
< User : qq 22 2022 - 03 - 07 00 : 00 : 00 > ] >
( 0.001 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE EXTRACT( MONTH FROM ` app01_user` . ` register_time` ) = 3 LIMIT 21 ; args= ( 3 , )
如果查不出来直接在setting . py文件中设置:USE_TZ = False
9. 查询注册时间是 27 号的数据
user_obj = models. User. objects. filter ( register_time__day= 27 )
print ( user_obj)
( 0.001 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE EXTRACT( DAY FROM ` app01_user` . ` register_time` ) = 27 LIMIT 21 ; args= ( 27 , )
10. 查询注册时间是星期天的数据
星期天是 1 星期一是 2
user_obj = models. User. objects. filter ( register_time__week_day= 1 )
print ( user_obj)
( 0.001 ) SELECT ` app01_user` . ` id` , ` app01_user` . ` name` , ` app01_user` . ` age` , ` app01_user` . ` register_time` FROM ` app01_user` WHERE DAYOFWEEK( ` app01_user` . ` register_time` ) = 1 LIMIT 21 ; args= ( 1 , )
* 一对多 , 一对一 和普通一张表的增删改是一样的
* 多对多 , 通过虚拟字段使用 . add ( ) . set ( [ ] ) . remove ( ) . clear ( ) 这几个方法
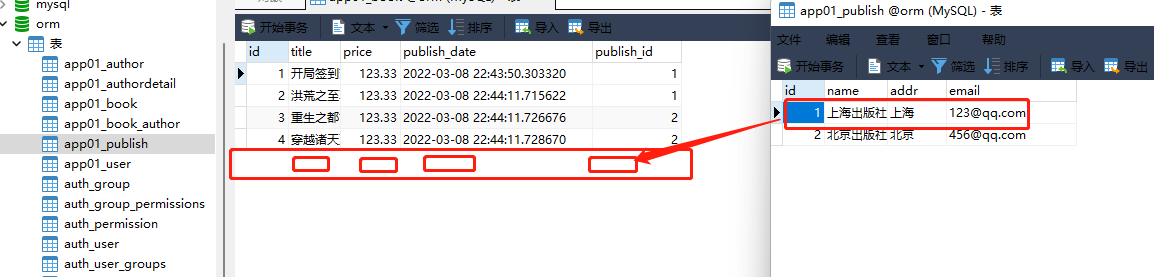
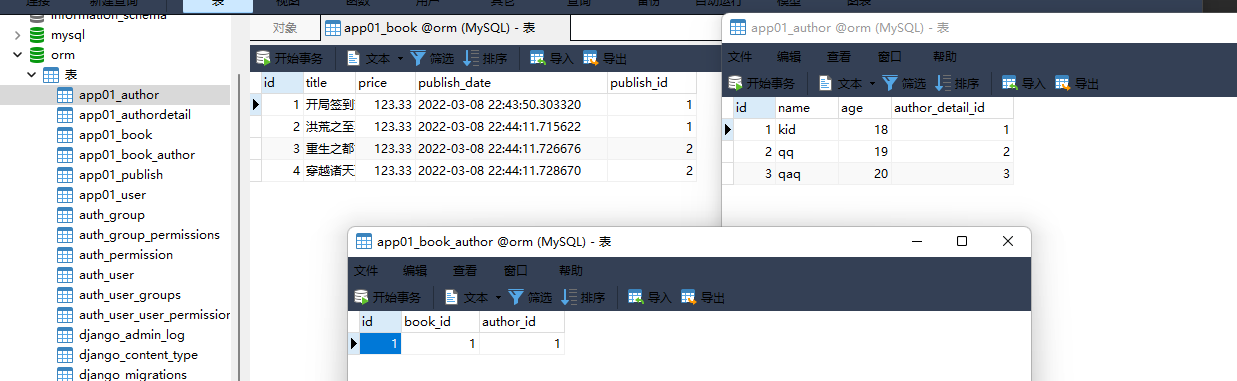
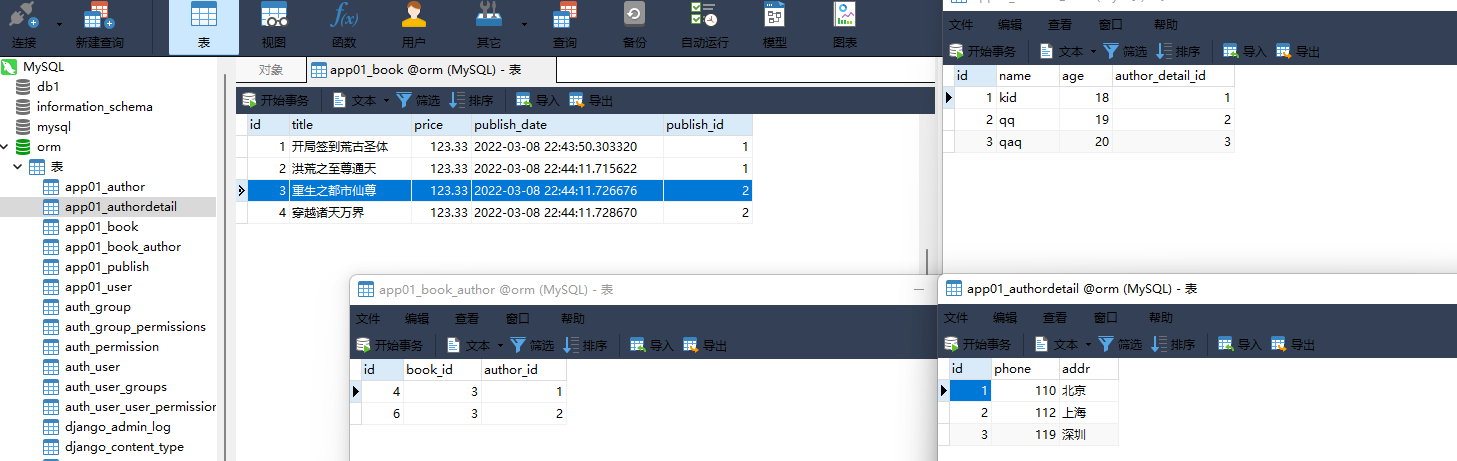
1. 书籍表 :
id title price publish_date
. . . . . . . . . . . .
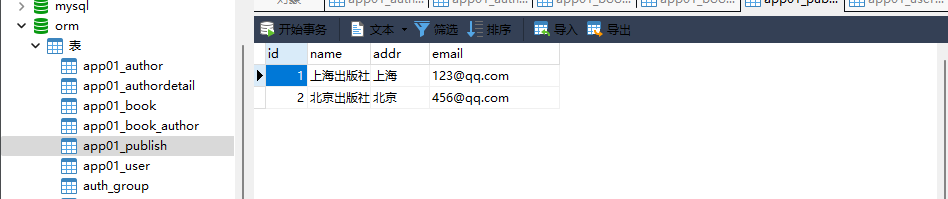
2. 出版社表:
id name addr email
1 上海出版社 上海 123 @ qq . com
2 北京出版社 北京 456 @ qq . com
. . . . .
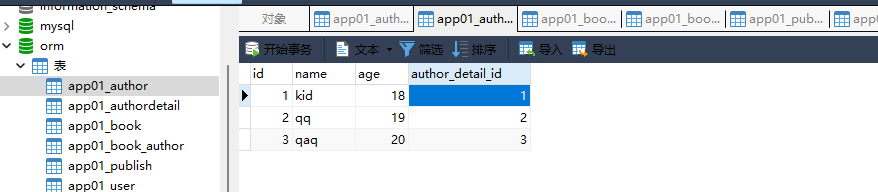
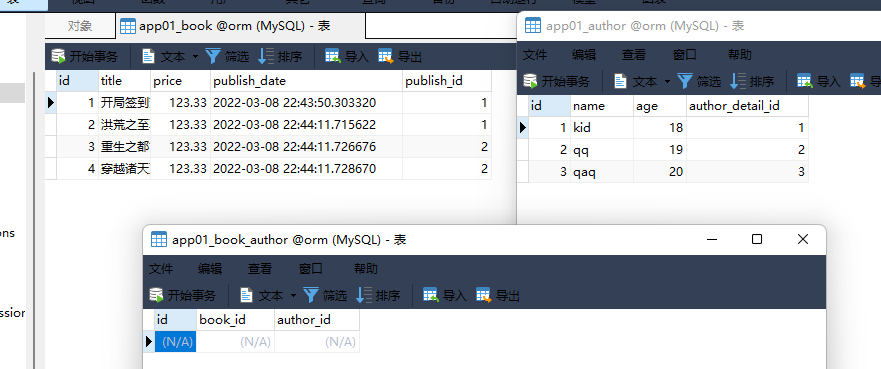
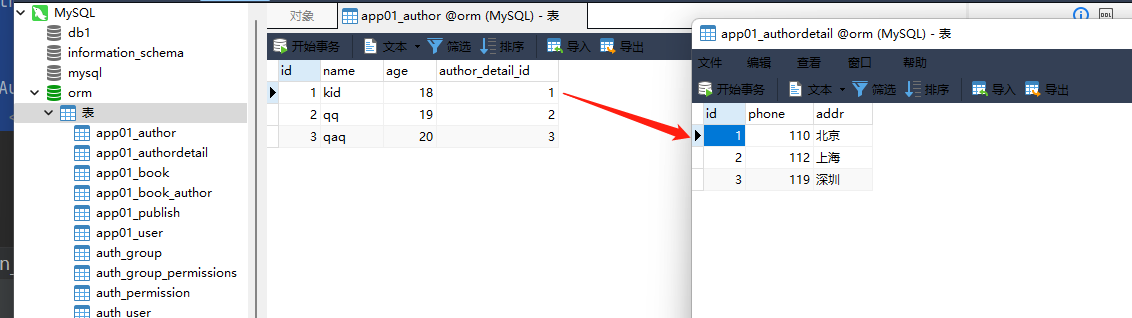
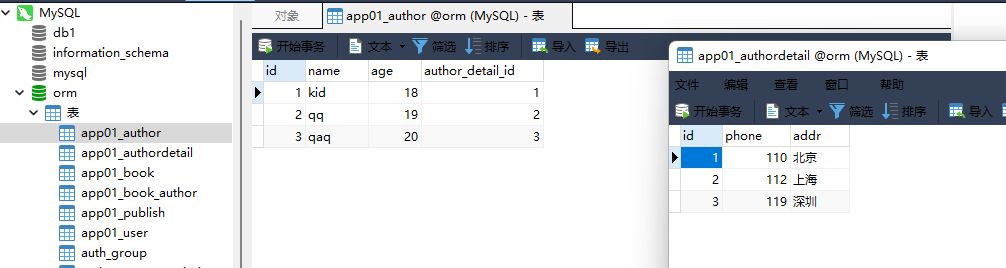
3. 作者表
id name age author_datail_id
1 kid 18 1
2 qq 19 2
3 qaq 20 3
. . . . .
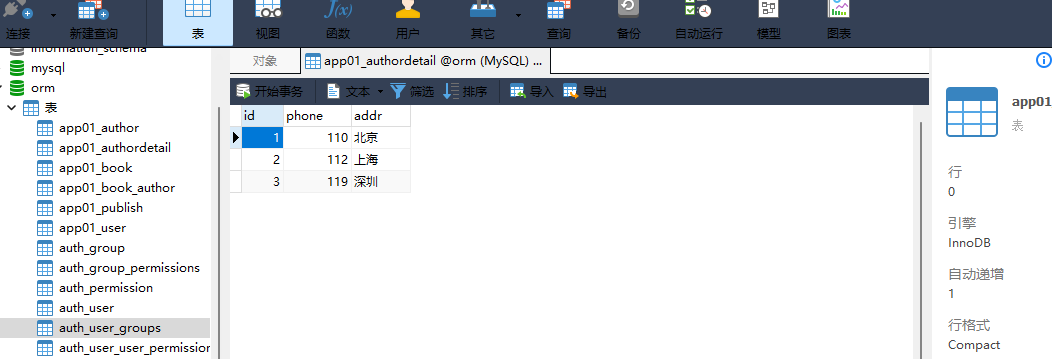
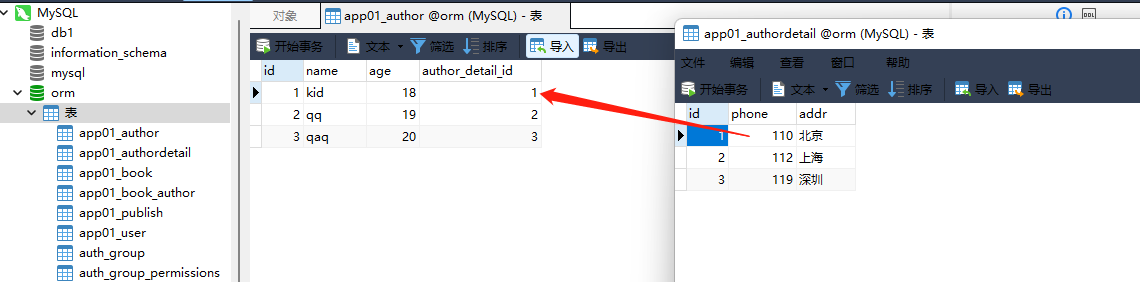
4. 作者详情表:
id phone a ddr
1 110 北京
2 112 上海
3 119 深圳
. . . . .
class Book ( models. Model) :
title = models. CharField( max_length= 32 , verbose_name= '书名' )
price = models. DecimalField( max_digits= 8 , decimal_places= 2 , verbose_name= '价格' )
publish_date = models. DateTimeField( auto_now_add= True , verbose_name= '出版时间' )
class Publish ( models. Model) :
name = models. CharField( max_length= 32 , verbose_name= '出版社名字' )
addr = models. CharField( max_length= 32 , verbose_name= '出版社地址' )
email = models. EmailField( verbose_name= '邮箱' )
class Author ( models. Model) :
name = models. CharField( max_length= 32 , verbose_name= '作者名字' )
age = models. IntegerField( verbose_name= '作者年龄' )
class AuthorDetail ( models. Model) :
phone = models. BigIntegerField( )
addr = models. CharField( max_length= 32 , verbose_name= '作者地址' )
* 创建的字段会自动加_id
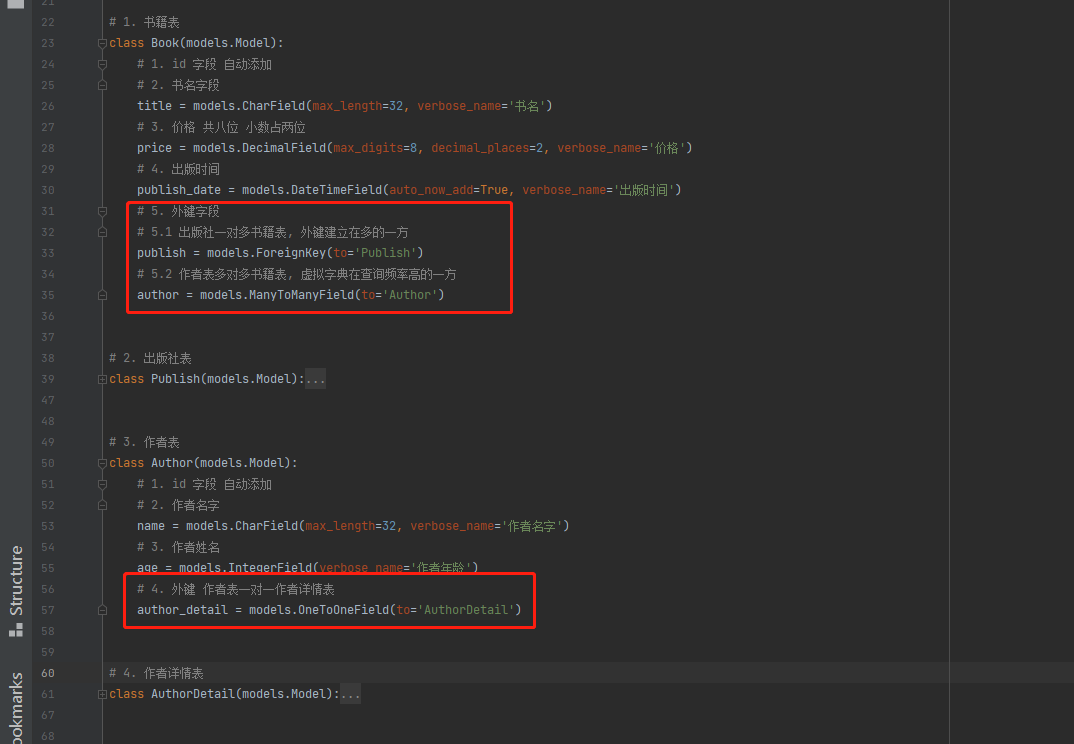
class Book ( models. Model) :
title = models. CharField( max_length= 32 , verbose_name= '书名' )
price = models. DecimalField( max_digits= 8 , decimal_places= 2 , verbose_name= '价格' )
publish_date = models. DateTimeField( auto_now_add= True , verbose_name= '出版时间' )
publish = models. ForeignKey( to= 'Publish' )
author = models. ManyToManyField( to= 'Author' )
class Publish ( models. Model) :
name = models. CharField( max_length= 32 , verbose_name= '出版社名字' )
addr = models. CharField( max_length= 32 , verbose_name= '出版社地址' )
email = models. EmailField( verbose_name= '邮箱' )
class Author ( models. Model) :
name = models. CharField( max_length= 32 , verbose_name= '作者名字' )
age = models. IntegerField( verbose_name= '作者年龄' )
author_detail_id = models. OneToOneField( to= 'AuthorDetail' )
class AuthorDetail ( models. Model) :
phone = models. BigIntegerField( )
addr = models. CharField( max_length= 32 , verbose_name= '作者地址' )
为每个表设置__str__ 方法 .
class Book ( models. Model) :
title = models. CharField( max_length= 32 , verbose_name= '书名' )
price = models. DecimalField( max_digits= 8 , decimal_places= 2 , verbose_name= '价格' )
publish_date = models. DateTimeField( auto_now_add= True , verbose_name= '出版时间' )
publish = models. ForeignKey( to= 'Publish' )
author = models. ManyToManyField( to= 'Author' )
def __str__ ( self) :
return '%s %s %s %s %s %s' % ( self. id , self. title, self. price, self. publish_date, self. publish, self. author)
class Publish ( models. Model) :
name = models. CharField( max_length= 32 , verbose_name= '出版社名字' )
addr = models. CharField( max_length= 32 , verbose_name= '出版社地址' )
email = models. EmailField( verbose_name= '邮箱' )
def __str__ ( self) :
return '%s %s %s %s' % ( self. id , self. name, self. addr, self. email)
class Author ( models. Model) :
name = models. CharField( max_length= 32 , verbose_name= '作者名字' )
age = models. IntegerField( verbose_name= '作者年龄' )
author_detail = models. OneToOneField( to= 'AuthorDetail' )
def __str__ ( self) :
return '%s %s %s %s' % ( self. id , self. name, self. age, self. author_detail)
class AuthorDetail ( models. Model) :
phone = models. BigIntegerField( )
addr = models. CharField( max_length= 32 , verbose_name= '作者地址' )
def __str__ ( self) :
return '%s %s %s' % ( self. id , self. phone, self. addr)
python manage . py makemigrations
python manage . py migrate
在tests . py 中录数据
4. 作者详情表:
id phone addr
1 110 北京
2 112 上海
3 119 深圳
models . AuthorDetail . objects . create ( phone = 110 , addr = '北京' )
models . AuthorDetail . objects . create ( phone = 112 , addr = '上海' )
models . AuthorDetail . objects . create ( phone = 119 , addr = '深圳' )
3. 作者表
id name age author_detail_id
1 kid 18 1
2 qq 19 2
3 qaq 20 3
models. Author. objects. create( name= 'kid' , age= 18 , author_detail_id= 1 )
models. Author. objects. create( name= 'qq' , age= 19 , author_detail_id= 2 )
models. Author. objects. create( name= 'qaq' , age= 20 , author_detail_id= 3 )
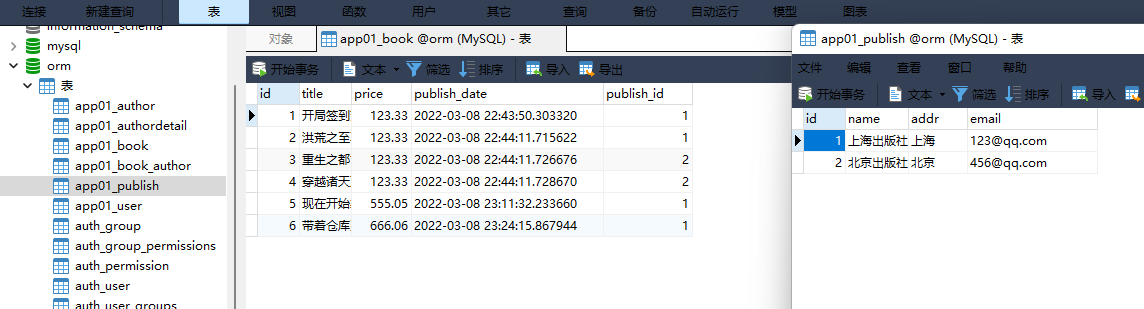
2. 出版社表:
id name addr email
1 上海出版社 上海 123 @ qq . com
2 北京出版社 北京 456 @ qq . com
models. Publish. objects. create( name= '上海出版社' , addr= '上海' , email= '123@qq.com' )
models. Publish. objects. create( name= '北京出版社' , addr= '北京' , email= '456@qq.com' )
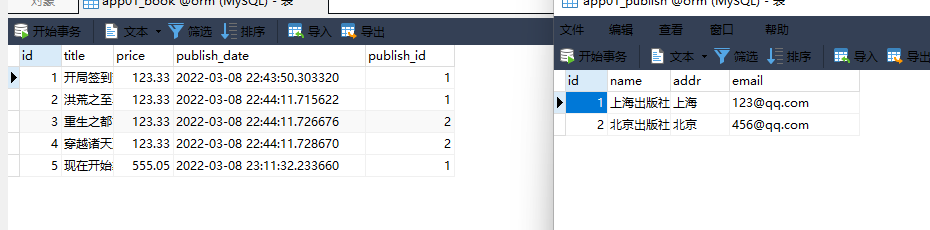
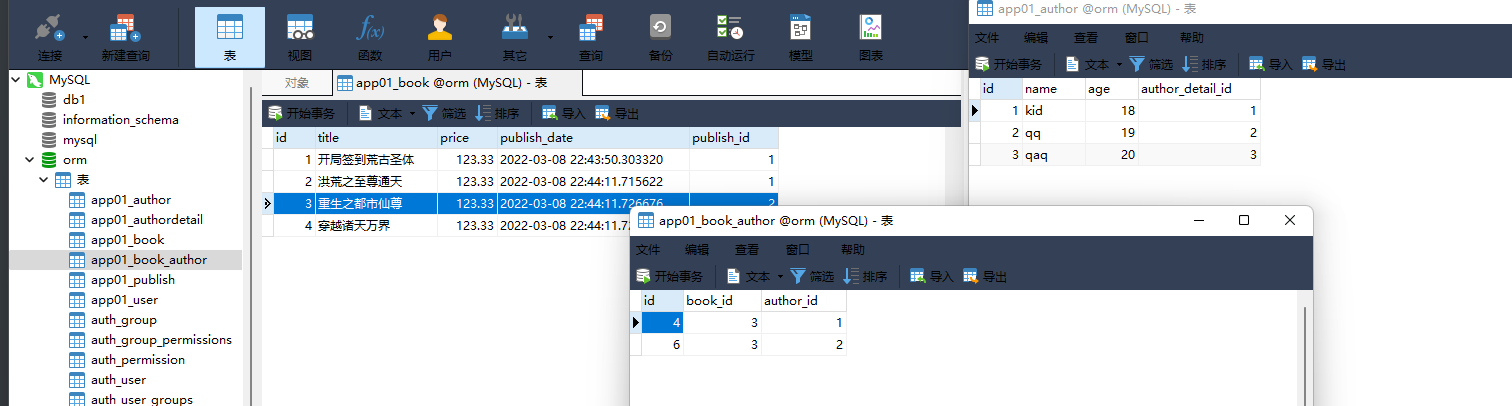
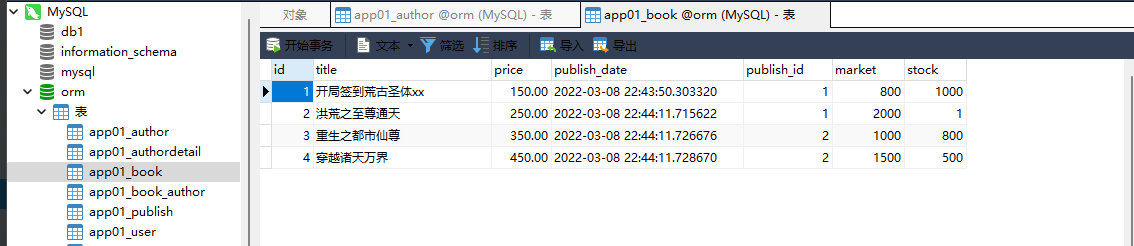
1. 书籍表 :
id title price publish_deta publish_id
1 开局签到荒古圣体 123.33 创建表的时候自动添加 1
2 洪荒之至尊通天 123.33 1
3 重生之都市仙尊 123.33 2
4 穿越诸天万界 123.33 2
models. Book. objects. create( title= '开局签到荒古圣体' , price= 123.33 , publish_id= 1 )
models. Book. objects. create( title= '洪荒之至尊通天' , price= 123.33 , publish_id= 1 )
models. Book. objects. create( title= '重生之都市仙尊' , price= 123.33 , publish_id= 2 )
models. Book. objects. create( title= '穿越诸天万界' , price= 123.33 , publish_id= 2 )
一对一 与 一对多的操作和普通的表操作是一样的。
查 objects . 各种方法
增 objects . create ( 字段 = 值 )
删 object . 各种方法 . delete ( )
改 objects . 各种方法 . update ( )
objects . filter查的结果是一个queryset对象 是一个列表套字典 , 字典中是一个数据对象 .
objects . filter . first ( ) 将这个数据对象取出来 .
外键字段不带_id 它的值可以是一个对象 , 也可以是一个表的之间值 .
外键字段带_id = 表的主键值 , publish不带_id 它的值不能就是表的主键值 .
添加书籍数据 并设置外键 绑定出版社 .
models. Book. objects. create( title= '现在开始梁山我说了算' , price= 555.05 , publish_id= 1 )
publish_obj = models. Publish. objects. filter ( pk= 1 ) . first( )
print ( publish_obj)
models. Book. objects. create( title= '带着仓库到大明' , price= '666.06' , publish= publish_obj)
publish = publish_obj publish不带_id 它的值可以是一个对象 , 也可以是一个表的之间值 .
publish_id = 表的主键值 , publish不带_id 它的值不能就是表的主键值 .
* 默认是级联更新和级联删除的
删除 书籍表的数据
models. Book. objects. filter ( pk= 6 ) . delete( )
book_obj = models. Book. objects. filter ( pk= 5 )
book_obj. delete( )
方式 1 将书籍表id为 1 的出版社信息改为 北京出版社的
方式 2 在改回上海出版社
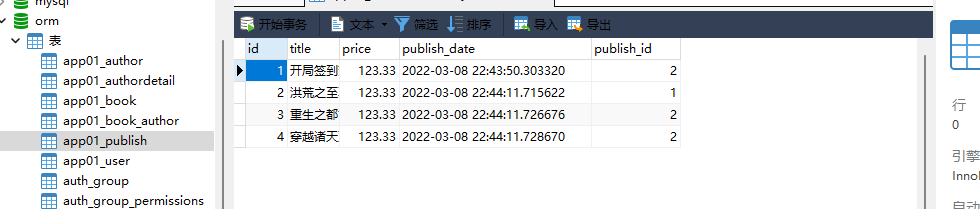
models. Book. objects. filter ( pk= 1 ) . update( publish= 2 )
publish_obj = models. Publish. objects. filter ( pk= 1 ) . first( )
models. Book. objects. filter ( pk= 1 ) . update( publish= publish_obj)
多对多的操作就是对第三张虚拟表进行操作。
. add ( ) 给第三张关系表添加数据
虚拟字段 . add ( )
括号内既可以传入数字也可以传入对象 , 并且都支持多个。
数字则是被关联表的id之间 , 对象是被关联表的数据对象 .
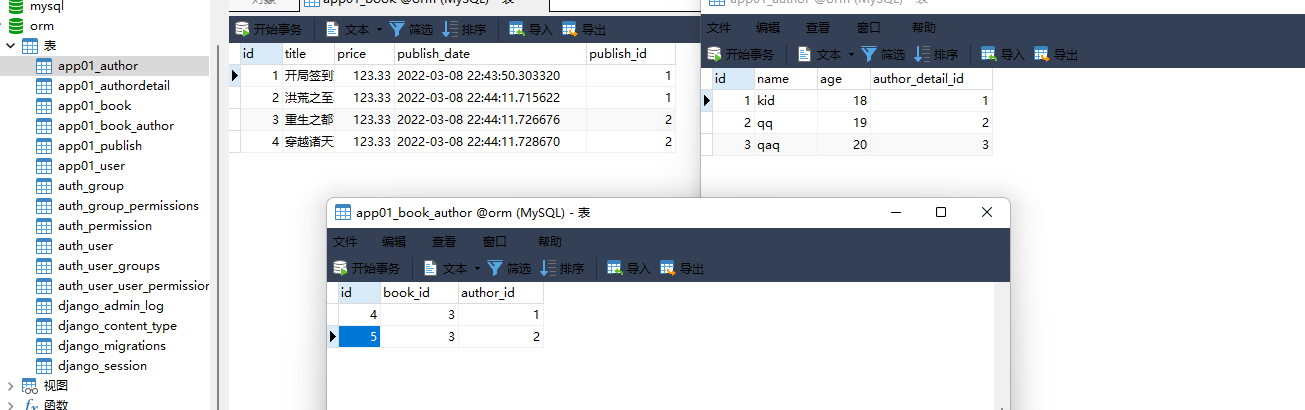
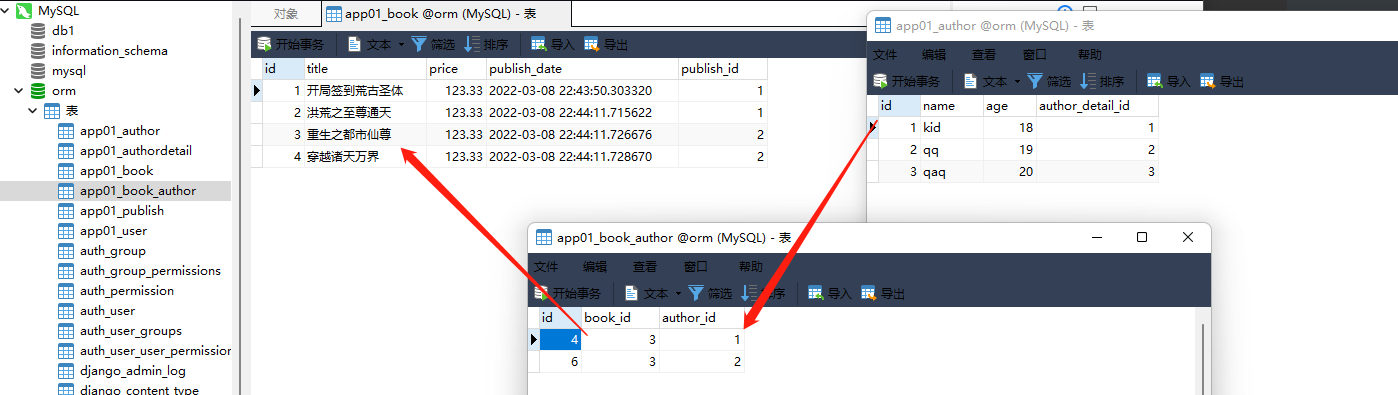
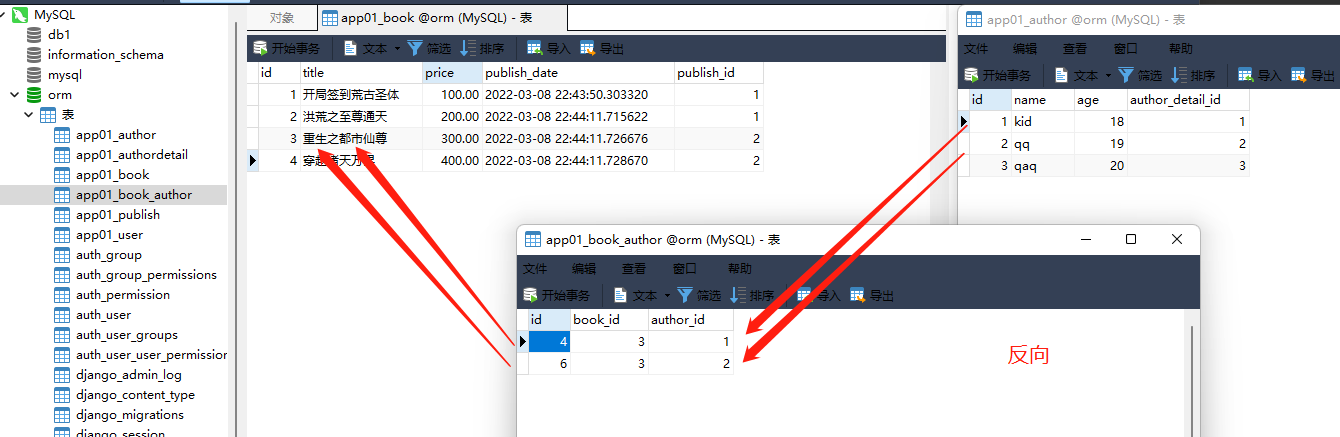
book_obj = models. Book. objects. filter ( pk= 1 ) . first( )
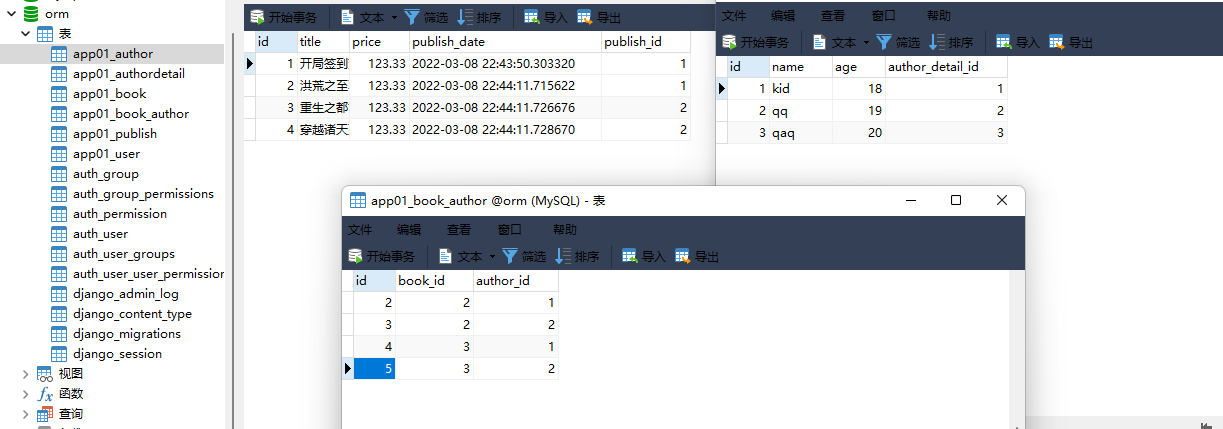
book_obj. author. add( 1 )
book_obj = models. Book. objects. filter ( pk= 2 ) . first( )
book_obj. author. add( 1 , 2 )
book_obj = models. Book. objects. filter ( pk= 3 ) . first( )
author_obj_1 = models. Author. objects. filter ( pk= 1 ) . first( )
author_obj_2 = models. Author. objects. filter ( pk= 2 ) . first( )
book_obj. author. add( author_obj_1, author_obj_2)
. remove ( ) 给第三张关系表删除数据。
虚拟字段 . remove ( )
括号内既可以传入数字也可以传入对象 , 并且都支持多个。
数字则是被关联表的id之间 , 对象是被关联表的数据对象 .
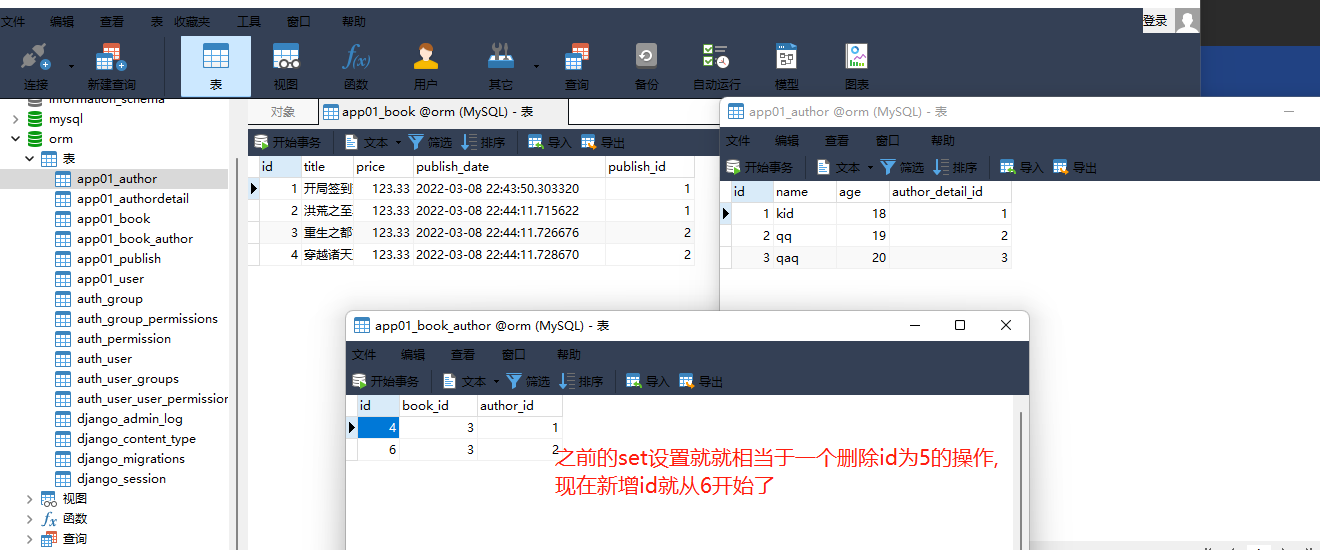
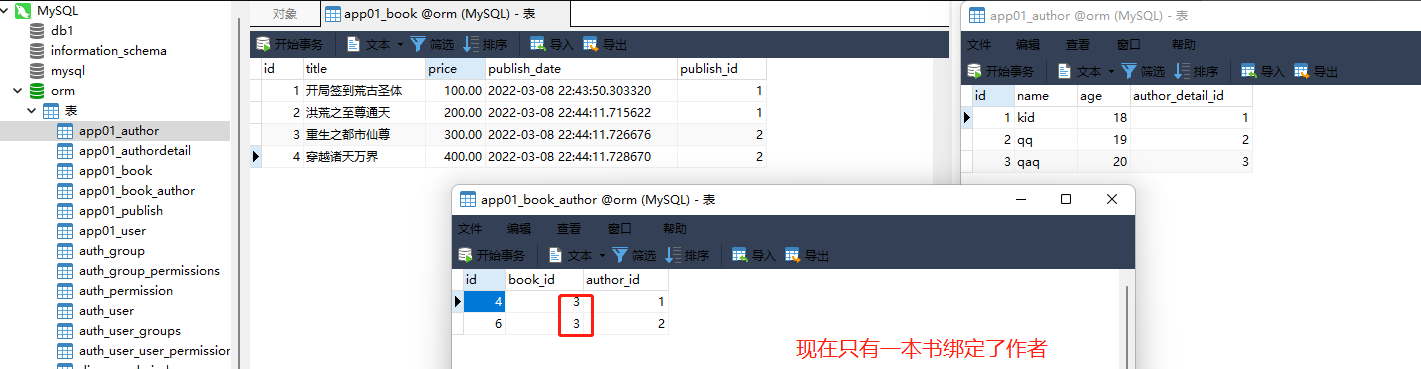
book_obj = models. Book. objects. filter ( pk= 1 ) . first( ) . author. remove( 1 )
book_obj. author. remove( 1 )
book_obj = models . Book . objects . filter ( pk = 1 ) . first ( ) . author . remove ( 1 )
可以一步完成推荐写两步 .
book_obj = models. Book. objects. filter ( pk= 2 ) . first( )
author_obj_1 = models. Author. objects. filter ( pk= 1 ) . first( )
author_obj_2 = models. Author. objects. filter ( pk= 2 ) . first( )
book_obj. author. remove( author_obj_1, author_obj_2)
. set ( [ ] ) 括号内必须传可迭代对象。
虚拟字段 . add . set ( [ ] )
该对象内既可以是数字也可以是对象并且都支持多个。
数字则是被关联表的id之间 , 对象是被关联表的数据对象 .
先删除在新增。id值会变。
book_obj = models. Book. objects. filter ( pk= 3 ) . first( )
book_obj. author. set ( [ 1 ] )
book_obj = models. Book. objects. filter ( pk= 3 ) . first( )
author_obj_1 = models. Author. objects. filter ( pk= 1 ) . first( )
author_obj_2 = models. Author. objects. filter ( pk= 2 ) . first( )
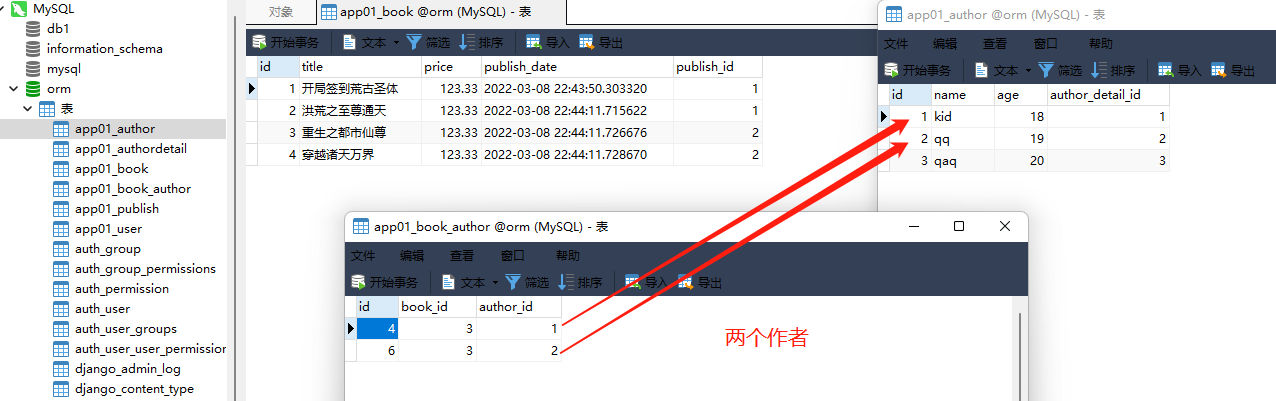
book_obj. author. set ( [ author_obj_1, author_obj_2] )
在第三张表中清空某个书籍与作者的绑定关系。
. clear ( ) 括号内不要加任何参数。
虚拟字段 . clear ( )
book_obj = models. Book. objects. filter ( pk= 6 ) . first( )
book_obj. author. clear( )
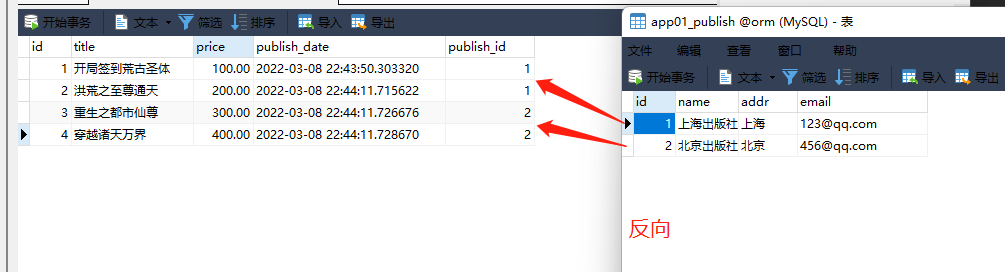
正向查询: 通过外键去查询外键所关联的表 .
反向查询 : 被一个外键关联的表 , 去查询绑定绑定这个外键的表 .
例:出版社表一对多书籍表 , 外键字段建多的一方书籍表中 .
通过 书籍表 -- > 查找 出版社 , 就是正向。
通过 出版社 -- > 查找 书籍表 就是反向向。
一对一 , 多对多也是同样判断的。
正向查询 数据对象按 . 外键字段
反向查询 数据对象 . 表名小写_set
查询结果是数据对象 .
子查询 -- > 基于数据对象跨表查询。只能正向查询 , 不支持反向查询 ,
ORM子查询方法 :
数据对象 . 外键字段 获取被关联的数据对象 数据对象 . 字段 获取值
数据对象 . 虚拟字段 获取被关联的数据对象 数据对象 . 字段 获取值
在书写ORM语句的时候跟写sql语句是一样的 , 如果语句复杂可以分段写。
* 要分清楚查询的结果是一个值还是多个值 .
是一个则值直接数据对象。
结果有多个值的时候就需要加上 . all ( ) 来获取值 , 不加获取不到数据 .
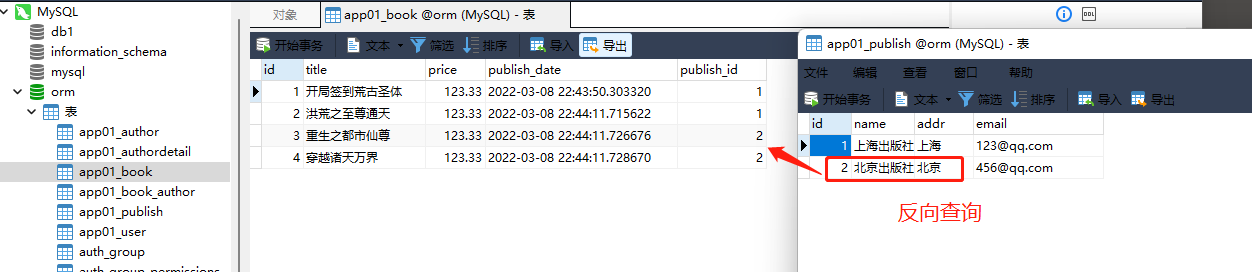
1. 查询书籍主键为 1 的出版社名称
book_obj = models. Book. objects. filter ( pk= 1 ) . first( )
print ( book_obj)
* 关联信息直接被查出来 . app01 . xxx . None 表示后面没有关联的表了
* app01 . xxx . None 只会出现在外键关联的表中 . 一对一被关联表也不会出现 .
1 开局签到荒古圣体 123.33 2022 - 03 - 08 22 : 43 : 50 1 上海出版社 上海 123 @ qq . com app01 . Author . None
print ( book_obj. publish)
print ( book_obj. publish. name)
2. 查询书籍主键为 3 的作者名字
book_obj = models. Book. objects. filter ( pk= 3 ) . first( )
print ( book_obj. author)
print ( book_obj. author. all ( ) )
data_obj = book_obj. author. all ( )
for obj in data_obj:
print ( obj. name)
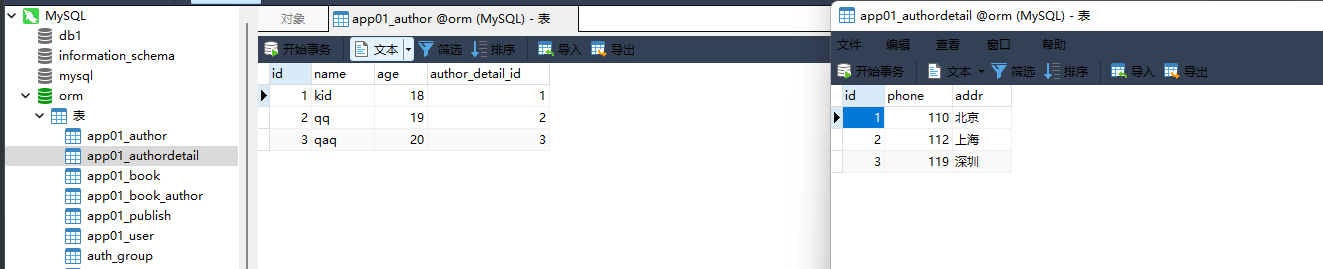
3. 拿到作者kid的电话号码
author_obj = models. Author. objects. filter ( name= 'kid' ) . first( )
print ( author_obj)
print ( author_obj. author_detail)
print ( author_obj. author_detail. phone)
联表查询 -- > 基于数据对象 . 表名_set跨表查询。
( 表名指定的表中 外键需要绑定这个数据对象的某个字段 )
ORM反向查询:
数据对象 . 表名_set 结果是单个值
数据对象 . 表名_set . all ( ) 结果是多个值
* 一对一就直接 . 表名 不需要_set
在书写ORM语句的时候跟写sql语句是一样的 , 如果语句复杂可以分段写。
* 要分清楚查询的结果是一个值还是多个值 .
是一个则值直接数据对象。
结果有多个值的时候就需要加上_set . all ( ) 来获取值 , 不加获取不到数据 .
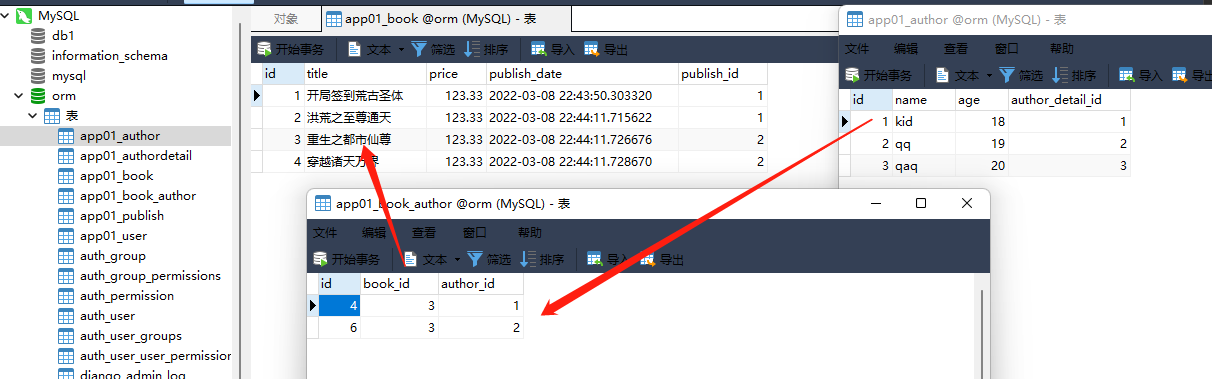
1. 查询北京出版社出版的书
publish_obj = models. Publish. objects. filter ( name= '北京出版社' ) . first( )
print ( publish_obj)
print ( publish_obj. book_set)
print ( publish_obj. book_set. all ( ) )
< QuerySet [ < Book : 3 重生之都市仙尊 123.33 2022 - 03 - 08 22 : 44 : 11.726676 2 北京出版社 北京 456 @ qq . com app01 . Author . None > ,
< Book : 4 穿越诸天万界 123.33 2022 - 03 - 08 22 : 44 : 11.728670 2 北京出版社 北京 456 @ qq . com app01 . Author . None > ] >
book_obj = publish_obj. book_set. all ( )
for obj in book_obj:
print ( obj. title)
2. 查询作者kid写的书
author_obj = models. Author. objects. filter ( name= 'kid' ) . first( )
print ( author_obj)
book_msg = models. Book. objects. filter ( title= '重生之都市仙尊' ) . first( )
print ( book_msg)
print ( author_obj. book_set)
print ( author_obj. book_set. all ( ) )
print ( author_obj. book_set. all ( ) . first( ) . title)
book_obj = author_obj. book_set. all ( )
for obj in book_obj:
print ( obj. title)
3. 查询手机号是 110 的作者名字。
* 一对一就直接 . 表名 不需要_set
authordetail_obj = models. AuthorDetail. objects. filter ( phone= 110 ) . first( )
print ( authordetail_obj)
print ( authordetail_obj. author)
print ( authordetail_obj. author. name)
print ( authordetail_obj. author_set)
子查询和联表查询的QuerySet对象中是列表套数据对象 通过点取值
< QuerySet [ <表名:数据对象>,.... ] 双下方法查询的QuerySet对象中是列表套字典 , 字典的取值方式取值
< QuerySet [ { '字段' : 110 } ]
跨表的时候可以使用双下方式便捷查询 .
直接通过 queryset对象 . values ( ) 获取指定字段的值
正向查询
queryset对象 . values ( '外键__字段' )
反向查询
queryset对象 . values ( '表名__字段' )
获取的数据格式是queryset对象列表套字典 , 字典的键是values中指定的参数 , 值是匹配出来的值 .
queryset对象列表中的字典键可以重复出现 .
1. 查询kid的手机号
author_obj = models. Author. objects. filter ( name= 'kid' ) . first( )
print ( author_obj)
print ( author_obj. author_detail)
print ( author_obj. author_detail. phone)
phone_obj = models. Author. objects. filter ( name= 'kid' ) . values( 'author_detail__phone' )
print ( phone_obj)
print ( phone_obj. first( ) )
2. 查询书籍主键为 1 的书名和出版社名字
book_obj = models. Book. objects. filter ( pk= 1 ) . first( )
print ( book_obj)
print ( book_obj. title)
print ( book_obj. publish. name)
book_obj = models. Book. objects. filter ( pk= 1 ) . values( 'title' , 'publish__name' )
print ( book_obj)
print ( book_obj. first( ) )
3. 查询书籍主键为 3 的作者姓名
book_obj = models. Book. objects. filter ( pk= 3 ) . first( )
print ( book_obj)
print ( book_obj. author. all ( ) )
author_obj = book_obj. author. all ( )
for obj in author_obj:
print ( obj. name)
book_obj = models. Book. objects. filter ( pk= 3 ) . values( 'author__name' )
print ( book_obj)
for obj in book_obj:
print ( obj. get( 'author__name' ) )
4. 查询书籍主键是 3 的作者的手机号
book_obj = models. Book. objects. filter ( pk= 3 ) . first( )
print ( book_obj. author. all ( ) )
author_obj = book_obj. author. all ( )
for obj in author_obj:
print ( obj)
print ( obj. author_detail)
print ( obj. author_detail. phone)
phone_obj = models. Book. objects. filter ( pk= 3 ) . values( 'author__author_detail__phone' )
print ( phone_obj)
for obj in phone_obj:
print ( obj. get( 'author__author_detail__phone' ) )
1. 查询手机号 110 的作者姓名
author_detail_obj = models. AuthorDetail. objects. filter ( phone= 110 ) . first( )
print ( author_detail_obj)
print ( author_detail_obj. author)
print ( author_detail_obj. author. name)
author_detail_obj = models. AuthorDetail. objects. filter ( phone= 110 ) . values( 'author__name' , 'phone' )
print ( author_detail_obj)
print ( author_detail_obj. first( ) )
2. 查询上海出版社出版的书
publish_obj = models. Publish. objects. filter ( name= '上海出版社' ) . first( )
print ( publish_obj)
print ( publish_obj. book_set. all ( ) )
book_obj = publish_obj. book_set. all ( )
for obj in book_obj:
print ( obj. title)
publish_obj = models. Publish. objects. filter ( name= '上海出版社' ) . values( 'book__title' )
print ( publish_obj)
print ( publish_obj. first( ) )
3. 查询kid写的书
book_obj = models. Author. objects. filter ( name= 'kid' ) . first( )
print ( book_obj)
print ( book_obj. book_set. all ( ) )
print ( book_obj. book_set. all ( ) . first( ) )
print ( book_obj. book_set. all ( ) . first( ) . title)
book_obj = models. Author. objects. filter ( name= 'kid' ) . values( 'book__title' )
print ( book_obj)
print ( book_obj. first( ) )
聚合查询通常都是配合分组一起使用的。
需要导入导入模块 , 只要更数据相关的模块基本上都在django . dbmodels或者django . db中。
from django . db . models import Max , Min , Sum , Count , Avg
聚合查询直接使用需要在aggregate方法中使用 .
objects . aggregate ( 聚合函数 ( ) )
聚合查询的结果是一个字典
键的名字是聚合函数中写的参数 + 聚合函数的名称
{ '参数__聚合函数' : xx }
* 先手动修改一个价格
1. 获取图书的平均价格
from django. db. models import Max, Min, Sum, Count, Avg
price__avg = models. Book. objects. aggregate( Avg( 'price' ) )
print ( price__avg)
2. 最贵的书
from django. db. models import Max, Min, Sum, Count, Avg
price__max = models. Book. objects. aggregate( Max( 'price' ) )
print ( price__max)
3. 最便宜的书
from django. db. models import Max, Min, Sum, Count, Avg
price__min = models. Book. objects. aggregate( Min( 'price' ) )
print ( price__min)
4. 所有书籍的价格
from django. db. models import Max, Min, Sum, Count, Avg
price__sum = models. Book. objects. aggregate( Sum( 'price' ) )
print ( price__sum)
5. 数图的数量
写pk自动找主键
from django. db. models import Max, Min, Sum, Count, Avg
price__count = models. Book. objects. aggregate( Count( 'pk' ) )
print ( price__count)
MySQL分组查询特点 :
分组之后 , 开了严格模式组内其他字段都无法直接获取了 , 只能获取分组的依据 .
ORM所有字段都可以获取 .
ORM 的 分组关键字 annotate ( ) 括号内写聚合函数
annotate ( '别名' = 聚合函数 ( 操作的字段 ) ) . values ( '别名' )
操作的字段可以 表名__字段 跨表正反向查询 .
. values ( 写需要展示的字段 , select 要展示的字段 )
xxx表 . objects . annotate ( ) , 就以这个xxx表的主键作为分组的依据 .
在跨表操作的时候会自动拼接表 .
一般都会为聚合函数的结果起一个别名 . 在配合values ( '别名' ) 使用 .
聚合函数操作的字段是一个表的主键的话可以只写表名 ,
xxx表__id 省略__id 就写xxx表
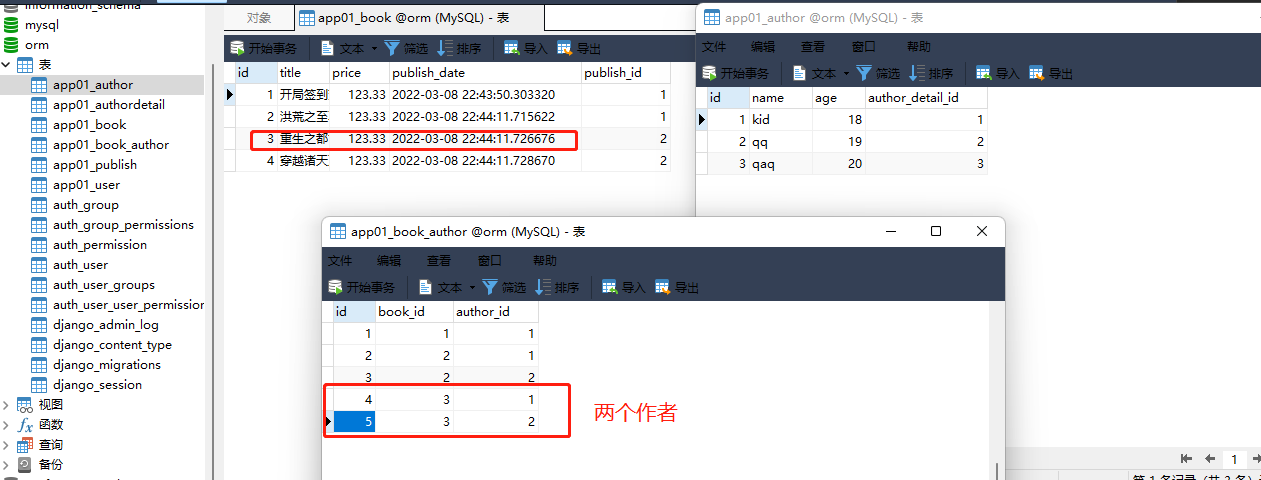
1. 统计每一本书的作者个数
以book_id最为依据 , 去统计 author_id 的数量
book_obj = models. Book. objects. annotate( Count_num= Count( 'author' ) ) . values( 'title' , 'Count_num' )
print ( book_obj)
< QuerySet [ { 'title' : '开局签到荒古圣体' , 'Count_num' : 0 } , { 'title' : '洪荒之至尊通天' , 'Count_num' : 0 } , { 'title' : '重生之都市仙尊' , 'Count_num' : 2 } , { 'title' : '穿越诸天万界' , 'Count_num' : 0 } ] >
( 0.000 ) SELECT ` app01_book` . ` title` , COUNT ( ` app01_book_author` . ` author_id` ) AS ` Count_num` FROM ` app01_book` LEFT OUTER JOIN ` app01_book_author` ON ( ` app01_book` . ` id` = ` app01_book_author` . ` book_id` ) GROUP BY ` app01_book` . ` id` ORDER BY NULL LIMIT 21 ; args= ( )
2. 统计每个出版社卖的最便宜的书的价格
以出版社的id为依据 , 求最低的价格
publish_obj = models. Publish. objects. annotate( min_price= Min( 'book__price' ) ) . values( 'name' , 'min_price' )
print ( publish_obj)
( 0.000 ) SELECT ` app01_publish` . ` name` , MIN ( ` app01_book` . ` price` ) AS ` price__min` FROM ` app01_publish` LEFT OUTER JOIN ` app01_book` ON ( ` app01_publish` . ` id` = ` app01_book` . ` publish_id` ) GROUP BY ` app01_publish` . ` id` ORDER BY NULL LIMIT 21 ; args= ( )
3. 统计书籍作者不为 1 的数量
先按图书表的主键分组 , 在统计每本书的作者数量 , 最后过滤一个作者的图书
from django. db. models import Max, Min, Sum, Count, Avg
book_obj = models. Book. objects. annotate( author_count= Count( 'author__id' ) ) . filter ( author_count__gt= 1 ) . values( 'title' , 'author_count' )
print ( book_obj)
只要ORM语句得出的结果还是一个queryset对象 , 那么就可以继续无限制的点queryset对象封装的方法。
( 0.000 ) SELECT ` app01_book` . ` title` , COUNT ( ` app01_book_author` . ` author_id` ) AS ` author_count` FROM ` app01_book` LEFT OUTER JOIN ` app01_book_author` ON ( ` app01_book` . ` id` = ` app01_book_author` . ` book_id` ) GROUP BY ` app01_book` . ` id` HAVING COUNT ( ` app01_book_author` . ` author_id` ) > 1 ORDER BY NULL LIMIT 21 ; args= ( 1 , )
4. 查询每个作者出的书的总价格
先按作者id分组 , 在统计所有书籍的价格
from django. db. models import Max, Min, Sum, Count, Avg
author_obj = models. Author. objects. annotate( count_sum= Sum( 'book__price' ) ) . values( 'name' , 'count_sum' )
print ( author_obj)
# < QuerySet [ { 'name' : 'kid' , 'count_sum' : Decimal ( '300.00' ) } , { 'name' : 'qq' , 'count_sum' : Decimal ( '300.00' ) } , { 'name' : 'qaq' , 'count_sum' : None } ] >
( 0.000 ) SELECT ` app01_author` . ` name` , SUM ( ` app01_book` . ` price` ) AS ` count_sum` FROM ` app01_author` LEFT OUTER JOIN ` app01_book_author` ON ( ` app01_author` . ` id` = ` app01_book_author` . ` author_id` ) LEFT OUTER JOIN ` app01_book` ON ( ` app01_book_author` . ` book_id` = ` app01_book` . ` id` ) GROUP BY ` app01_author` . ` id` ORDER BY NULL LIMIT 21 ; args= ( )
F 查询可以取到表中某个字段对应的值 , 当作筛选条件 , 还支持一般的数学运算 .
导入模块 from django . db . models import F
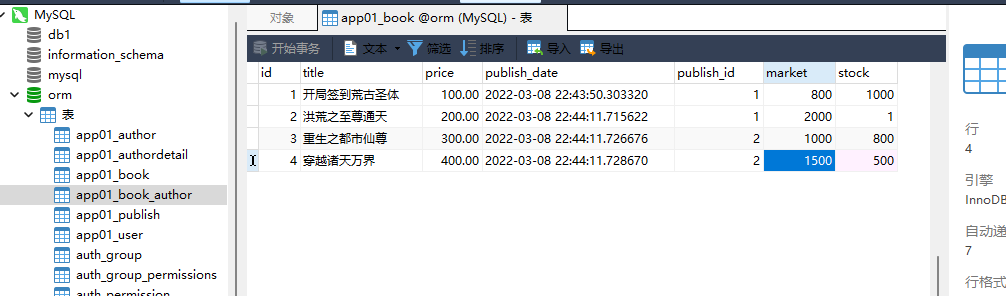
先为书表添加字段
库存的字段 stock
卖出的字段 market
class Book ( models. Model) :
······
stock = models. IntegerField( default= 1000 )
market = models. IntegerField( default= 1000 )
def __str__ ( self) :
return '%s %s %s %s %s %s %s %s' % (
self. id , self. title, self. price, self. publish_date, self. publish, self. author, self. stock, self. market)
执行数据库迁移命令 :
python manage . py makemigrations
python manage . py migrate
再修改数据(数据不够用自己多添加几个)
1. 查询卖出数大于库存数的书籍名称
from django. db. models import F
book_obj = models. Book. objects. filter ( market__gt= F( 'stock' ) )
print ( book_obj. values( 'title' , 'market' , 'stock' ) )
< QuerySet [ { 'title' : '洪荒之至尊通天' , 'market' : 2000 , 'stock' : 1 } , { 'title' : '重生之都市仙尊' , 'market' : 1000 , 'stock' : 800 } , {
'title' : '穿越诸天万界' , 'market' : 1500 , 'stock' : 500 } ] >
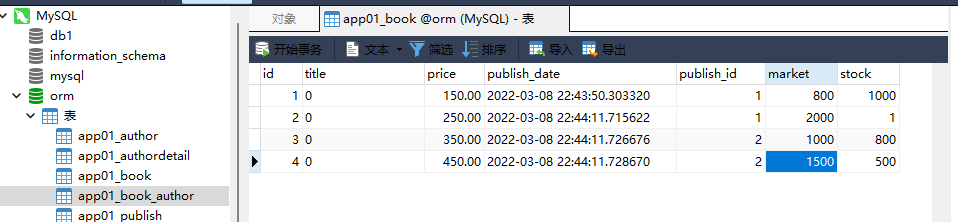
2. 将所有书籍的价格提升 50 块
from django. db. models import F
models. Book. objects. update( price= F( 'price' ) + 50 )
3. 将所有书的名称后面加上 劲爆 两个字 需要Concat函数 和 Value函数
Concat用于字符串的拼接操作,参数位置决定了拼接是在头部拼接还是尾部拼接,Value里面是拼接的值
from django . db . models . functions import Concat
from django . db . models import Value
from django. db. models import F
from django. db. models import Value
from django. db. models. functions import Concat
models. Book. objects. update( title= Concat( F( 'title' ) , Value( '劲爆' ) ) )
from django. db. models import F
from django. db. models import Value
from django. db. models. functions import Concat
book_obj = models. Book. objects. filter ( pk= 1 )
book_obj. update( title= Concat( F( 'title' ) , Value( 'xx' ) ) )
models. Book. objects. update( title= F( 'title' ) + '劲爆' )
删除后缀还不知道 , 先手改吧 .
from django . db . models import Q
在filter()括号中默认是and关系。
导入Q模块之后可以使用 | ( or 运输算法 ) 和 ~ (not 运算符)
1. 查看卖出数大于 100 或者价格小于 200 的书籍
from django. db. models import Q
book_obj = models. Book. objects. filter ( Q( stock__gt= 100 ) | Q( price__lt= 200 ) )
print ( book_obj. values( 'title' , 'stock' , 'price' ) )
< QuerySet [ { 'title' : '开局签到荒古圣体xx' , 'stock' : 1000 , 'price' : Decimal ( '150.00' ) } , { 'title' : '重生之都市仙尊' , 'stock' : 800 , 'price' : Decimal ( '350.00' ) } , { 'title' : '穿越诸天万界' , 'stock' : 500 , 'price' : Decimal ( '450.00' ) } ] >
写成一个模板使用 .
from django. db. models import Q
q = Q( )
print ( q)
q. connector = 'or'
print ( q)
q. children. append( ( 'stock__gt' , 100 ) )
print ( q)
q. children. append( ( 'price__lt' , 200 ) )
print ( q)
book_obj = models. Book. objects. filter ( q) . values( 'title' , 'stock' , 'price' )
print ( book_obj)
QuerySet [ { 'title' : '开局签到荒古圣体xx' , 'stock' : 1000 , 'price' : Decimal ( '150.00' ) } , { 'title' : '重生之都市仙尊' , 'stock' : 800 , 'price' : Decimal ( '350.00' ) } , { 'title' : '穿越诸天万界' , 'stock' : 500 , 'price' : Decimal ( '450.00' ) } ] >
事务四个特性:
ACID
原子性:不可分割的最新单位。
一致性:更原子性是相辅相成的。
隔离性:事务之间互相不干扰。
持久性:事务一旦确认永久生效。
事务的回滚:rellback
事务的确认:commit
from django. db import transaction
try :
with transaction. atomic( ) :
pass
except Exception as e:
print ( e)
verbose_name 字段注释
AutoField 自增
主键字段 必须设置 primary_key = True
null 字段可以为 空
IntegerField int整型
BigInegerField bigint
DecimalField 十进制字段
max_digits = 8 共 8 位
decimal_places = 2 小数部分 2 位
CharField 字符 -- > 对应数据库中的varchar
max_length 长度 必须设置
EmailFiled -- > varchar ( 254 ) 邮件
DateFiled 日期格式
date
DateTimeFiled
auto_now : auto_now = True每次修改数据的时候都会自动跟新当前时间。
auto_now_add : auto_now_add = True之在创建数据的时候记录创建的时候 , 后续不会自动更改。
BooleanField 布尔值
该字段存布尔值(False / True) 数据库中存 0 / 1
TextField 文本类型
存大段文本内容 , 没有字数限制
FileField
upload = '/date一个路径'
该字段传一个文件对象 , 会自动将文件保存到 / date目录下然后将文件路径保存到数据库中
ForeignKey ( unique = True ) 等价于 OneToOneField ( )
一对多 与 一对一的区别就在与unique = True
使用ForeignKey ( unique = True ) 创建一对一是可以的但是不推荐这样去使用 .
to 设置要关联的表
to_field 设置要关联的字段 不写默认为主键字段 , 一般不写 .
on_delere 当删除表中的数据时 , 当前表与起关联的行的行为。
django2 . x以上版本需要自己指定外键字段的级联更新级联删除。
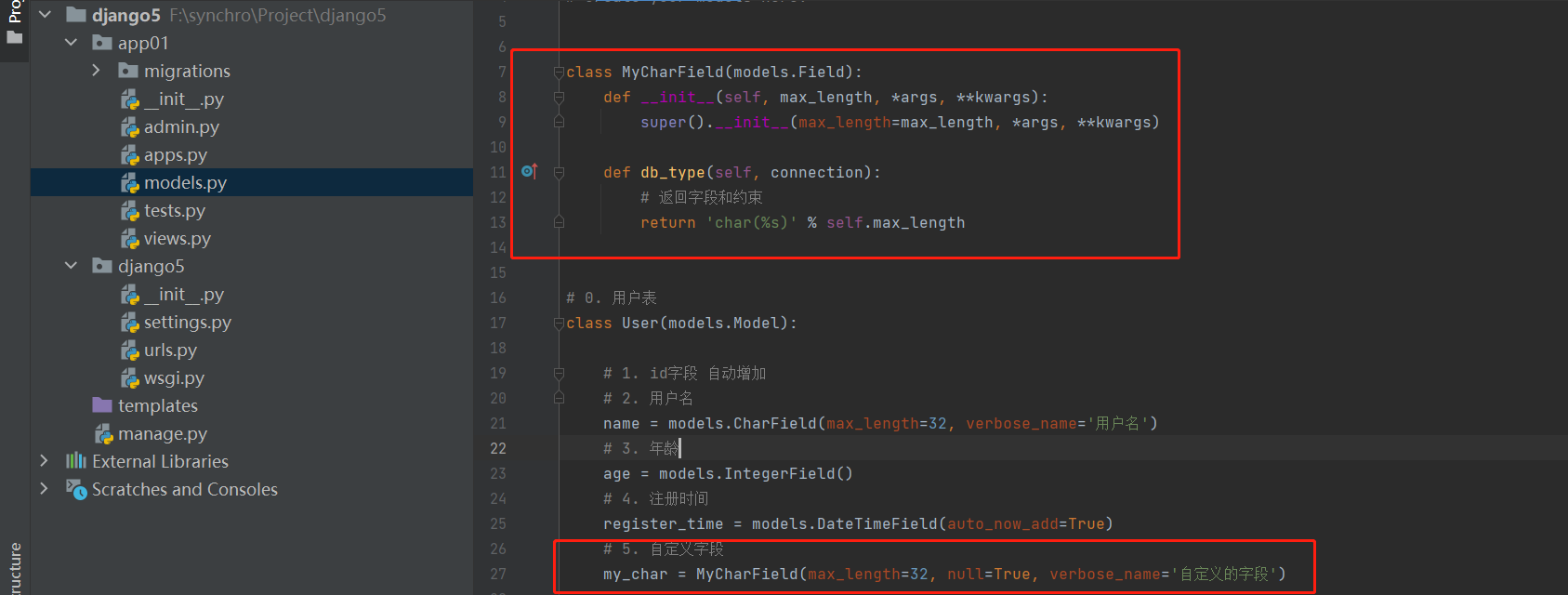
class MyCharField ( models. Field) :
def __init__ ( self, max_length, * args, ** kwargs) :
super ( ) . __init__( max_length= max_length, * args, ** kwargs)
def db_type ( self, connection) :
return 'char(%s)' % self. max_length
my_char = models. MyCharField( max_length= 32 , verbose_name= '自定义的字段' )
存储一个可枚举的字段。
xx字段 = models . InergerField ( choice = 一个列表或元组 )
字段存储的是Integer类型 , 但是可以通过数字获取对应的真正信息 .
( ( , ) , ( , ) ) 其中元素的值相对应
保证字段类型跟列举出来的元组的第一个数据类型一致即可
使用choices 参数的字段取值的对应信息 搭配固定的语法 get_字段名_display ( )
如果没有对应关系,直接展示字段的值。
class UserTwo ( models. Model) :
name = models. CharField( max_length= 32 , verbose_name= '用户名' )
age = models. IntegerField( verbose_name= '年龄' )
gender_tuple = (
( 1 , '男' ) ,
( 2 , '女' ) ,
( 3 , '保密' )
)
gender = models. IntegerField( choices= gender_tuple, verbose_name= '性别' )
score_tuple = ( ( 'A' , '优秀' ) , ( 'B' , None ) )
score = models. IntegerField( choices= score_tuple, verbose_name= '成绩' )
执行数据库迁移命令。
models. User2. objects. create( name= 'kid1' , age= 18 , gender= 1 , score= 'A' )
models. User2. objects. create( name= 'kid2' , age= 19 , gender= 2 , score= 'B' )
models. User2. objects. create( name= 'kid1' , age= 18 , gender= 5 , score= 'A' )
user2_obj = models. User2. objects. all ( )
for obj in user2_obj:
print ( obj. get_gender_display( ) , obj. get_score_display( ) )
男 优秀
女 None
5 优秀
↑ 5 没有对应的值 , 就直接显示 5
orm自动创建第三张表
class Book ( models. Model) :
name = models. CharField( max_length= 32 )
author = models. ManyToManyField( to= 'Author' )
class Author ( models. Model) :
name = models. CharField( max_length= 32 )
优点:自动,支持orm操作第三表的方法,add ( ) remove ( ) clear ( ) ···正方向查询···
缺点:第三张拓展性差,没法添加额外的字段。
几乎不会去使用 .
class Book ( models. Model) :
name = models. CharField( max_length= 32 )
class Author ( models. Model) :
name = models. CharField( max_length= 32 )
class BookToAuthor ( models. Model) :
book_id = models. ForeignKey( to= 'Book' )
author_id = models. ForeignKey( to= 'Author' )
优点:第三表完全可以自己拓展。
缺点:add ( ) remove ( ) clear ( ) ···正方向查询···不能用。
0. 写法与全自动一样 , 不需要ORM自动创建第三张表 , 而是自己创建 .
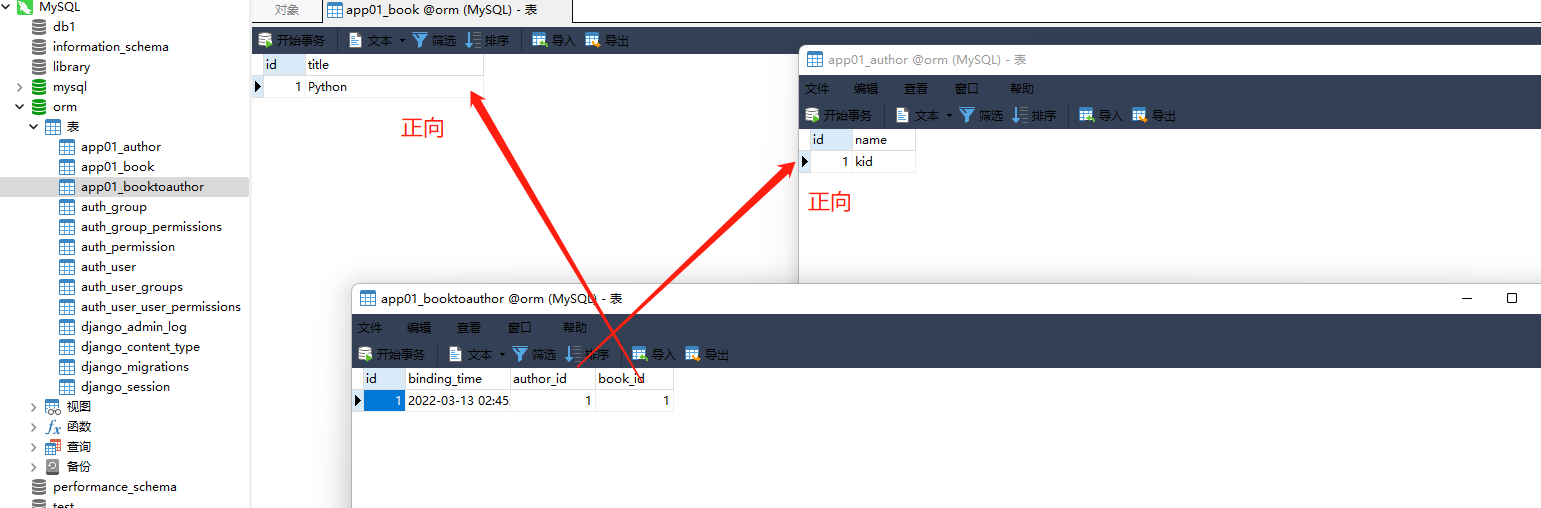
1. through指定第三张表的名字 , through_fields指定关联的字端 . 经过这一步之后可以使用正方向查询 .
2. through_fields的第一个参数 , 写当前表的表名 , 会自动加_id .
* 第三张表的字段是普通的字段 , 直接操作第三张 . 字段 无法到另一张表中去 .
class Book ( models. Model) :
title = models. CharField( max_length= 32 )
author = models. ManyToManyField( to= 'Author' ,
through= 'BookToAuthor' ,
through_fields= ( 'book' , 'author' )
)
class Author ( models. Model) :
name = models. CharField( max_length= 32 )
class BookToAuthor ( models. Model) :
book = models. ForeignKey( to= 'Book' )
author = models. ForeignKey( to= 'Author' )
binding_time = models. DateTimeField( auto_now_add= True )
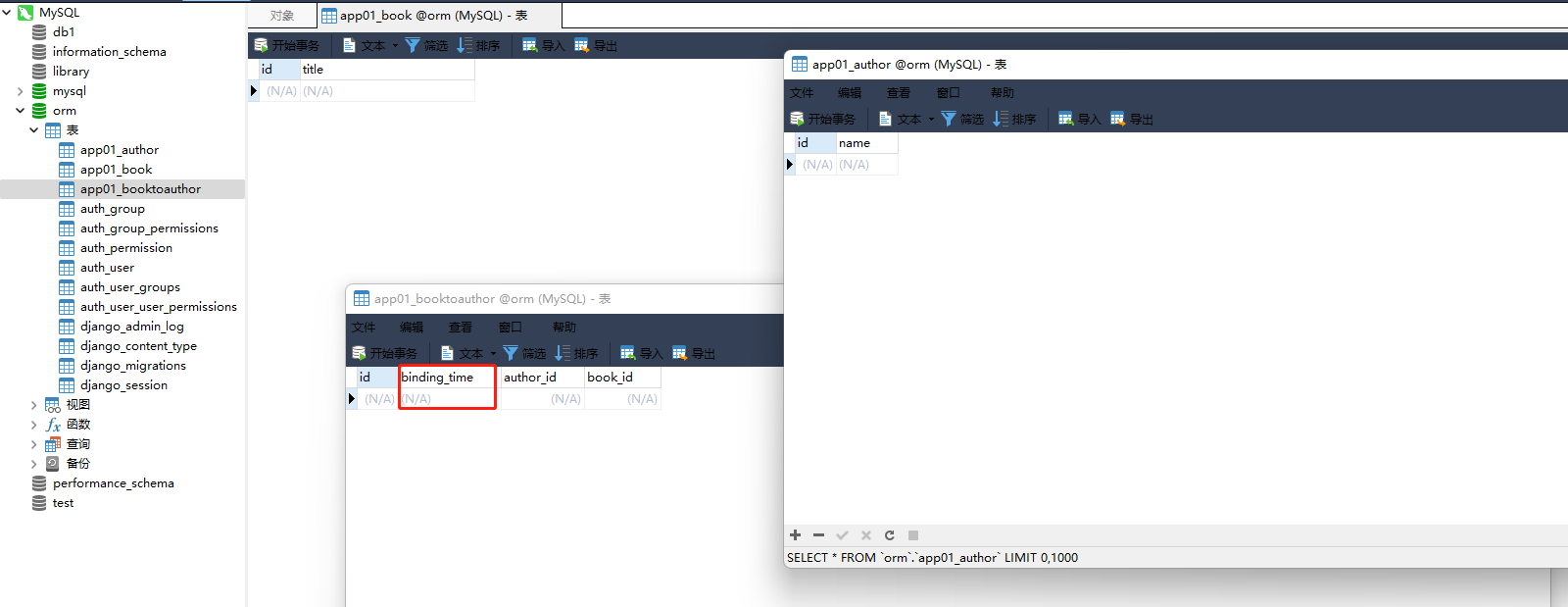
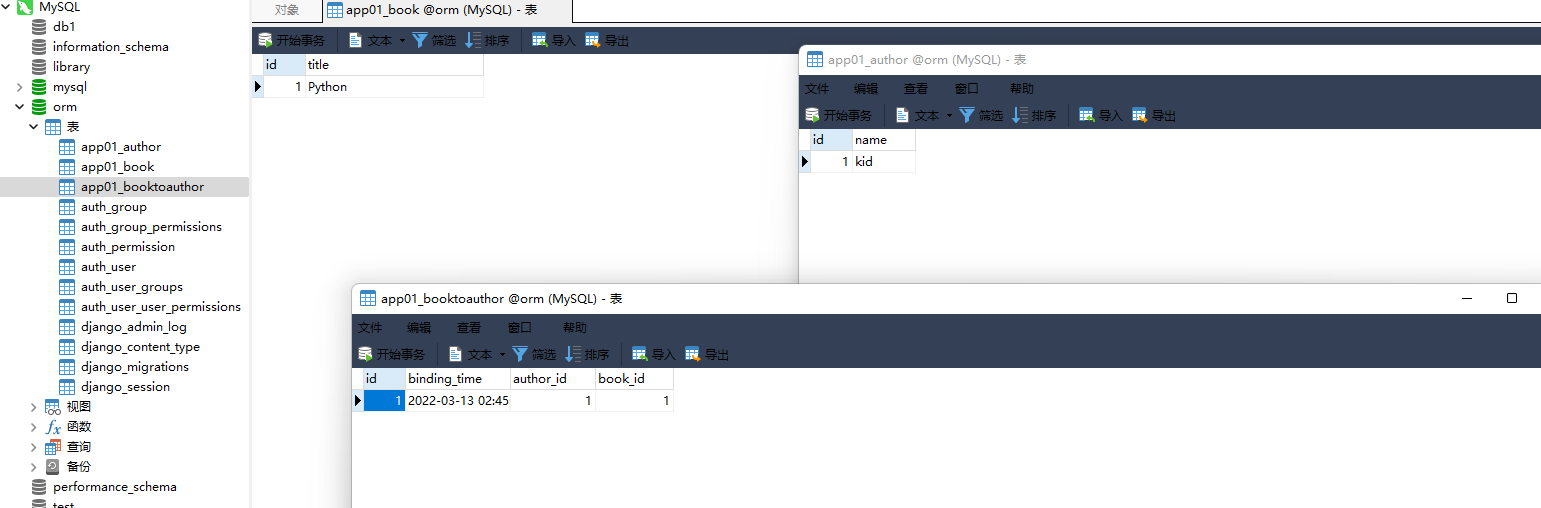
models. Book. objects. create( title= 'Python' )
models. Author. objects. create( name= 'kid' )
models. BookToAuthor. objects. create( book_id= 1 , author_id= 1 )
可是使用 正方向查询,不能使用:add ( ) remove ( ) clear ( ) ···
拓展性高
为每个表添加__str__ 方法在打印对象时触发 .
class Book ( models. Model) :
title = models. CharField( max_length= 32 )
author = models. ManyToManyField( to= 'Author' ,
through= 'BookToAuthor' ,
through_fields= ( 'book' , 'author' )
)
def __str__ ( self) :
return f' { self. pk} { self. title} { self. author} ' class Author ( models. Model) :
name = models. CharField( max_length= 32 )
def __str__ ( self) :
return f' { self. pk} { self. name} ' class BookToAuthor ( models. Model) :
book = models. ForeignKey( to= 'Book' )
author = models. ForeignKey( to= 'Author' )
binding_time = models. DateTimeField( auto_now_add= True )
def __str__ ( self) :
return f' { self. pk} { self. book_id} { self. author_id} { self. binding_time} '
book_obj = models. Book. objects. filter ( pk= 1 ) . first( )
print ( book_obj. author. all ( ) )
print ( book_obj. booktoauthor_set. all ( ) )
author_obj = models. Author. objects. filter ( pk= 1 ) . first( )
print ( author_obj. book_set. all ( ) )
print ( author_obj. booktoauthor_set. all ( ) )
book_author_obj = models. BookToAuthor. objects. filter ( pk= 1 )
print ( book_author_obj)
print ( book_author_obj. values( 'book_id__pk' ) )
print ( book_author_obj. first( ) )
print ( book_author_obj. first( ) . book_id)
研究对象查询数据的时候 , 还需不需要走数据库去查询 .
优化 : 走的少 , 或者不走 , 数据库 .
将应用下的models . py 中 book类的__str__ 方法注释 .
orm语句的特点:
惰性查询:
仅仅只是书写orm语句 , 后面根本没有使用到该语句查询出来的参数 ,
那么orm会自动识别到 , 不用就直接不执行。
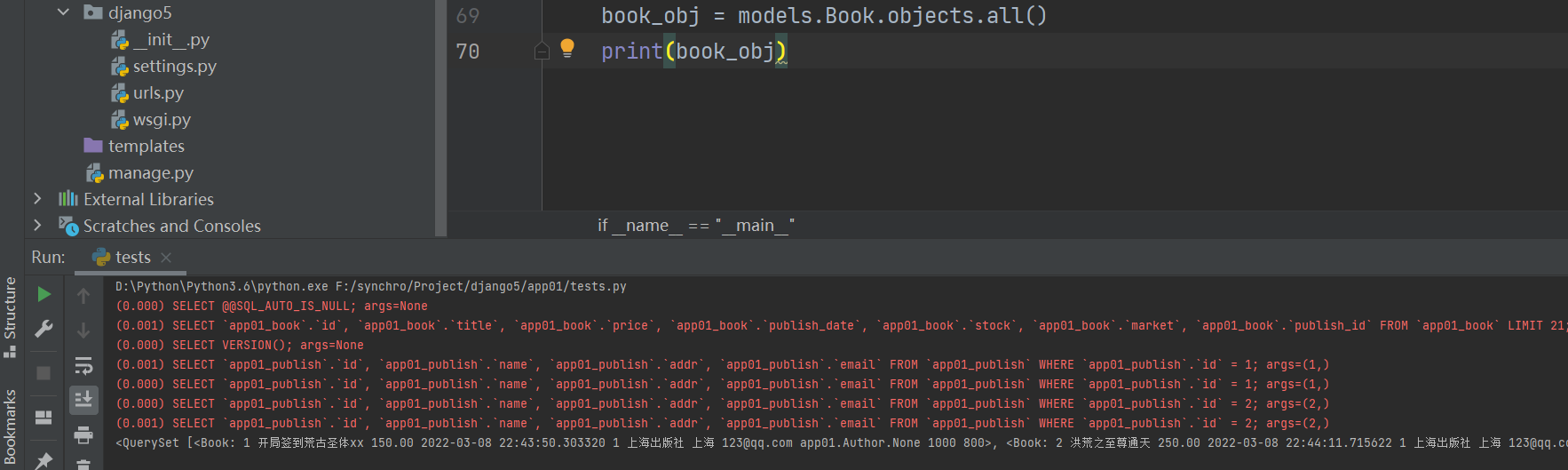
boolk_obj = models. Book. objects. all ( )
book_obj = models. Book. objects. all ( )
print ( book_obj)
all ( ) 拿表中所有的数据
only ( ) 拿指定字段的数据
book_obj = models. Book. objects. all ( )
print ( book_obj)
for obj in book_obj:
print ( obj. title)
for obj in book_obj:
print ( obj. price)
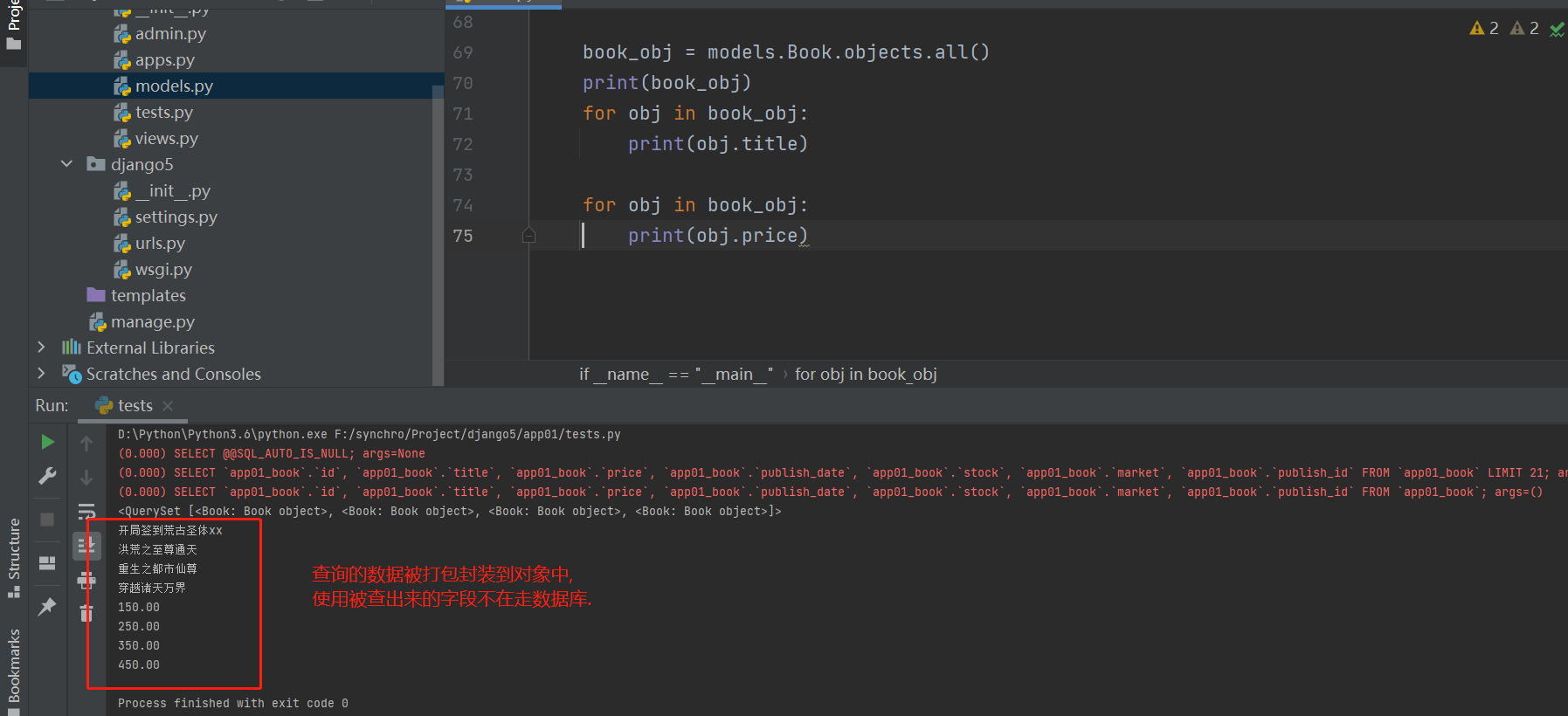
book_obj = models. Book. objects. all ( ) . values( 'title' )
print ( book_obj)
for obj in book_obj:
print ( obj)
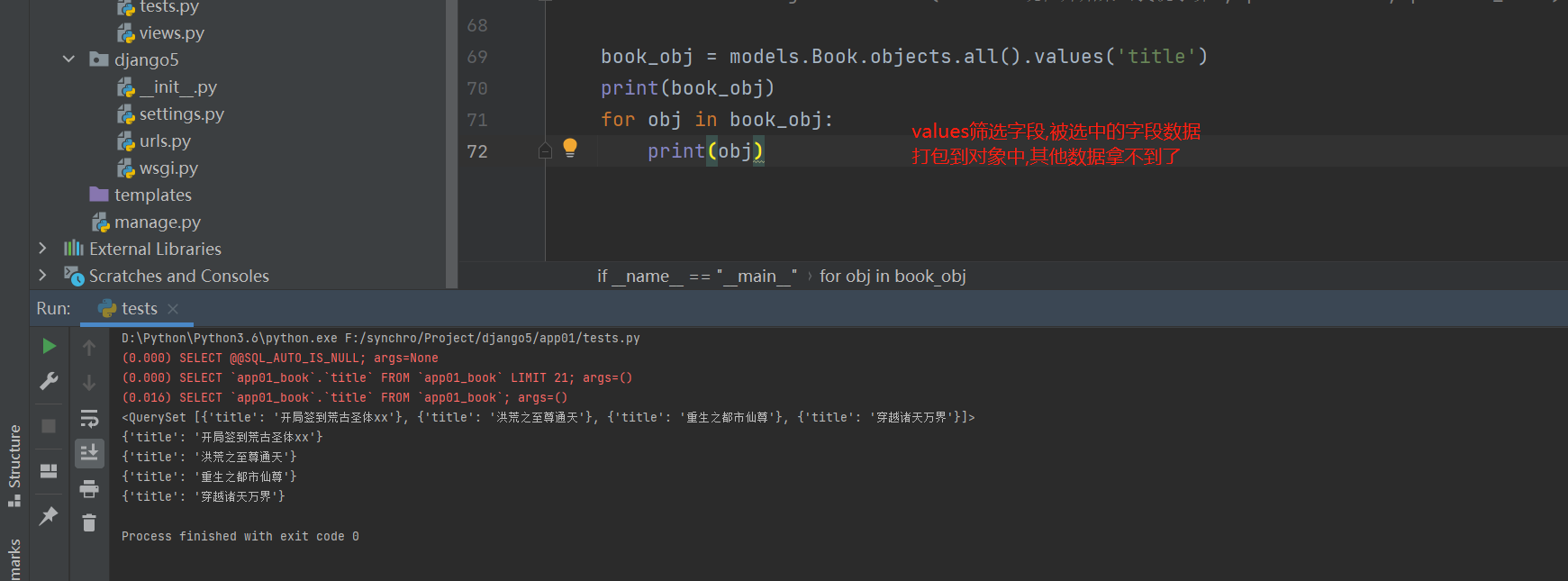
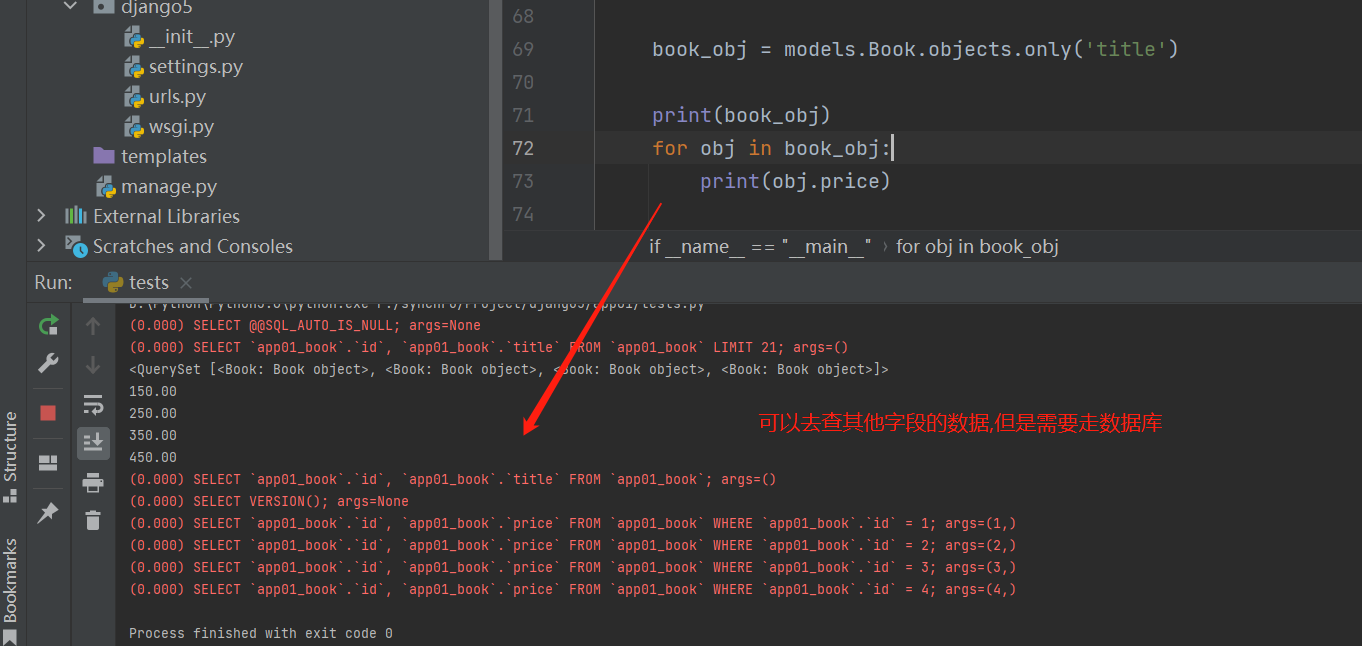
book_obj = models. Book. objects. only( 'title' )
print ( book_obj)
for obj in book_obj:
print ( obj. title)
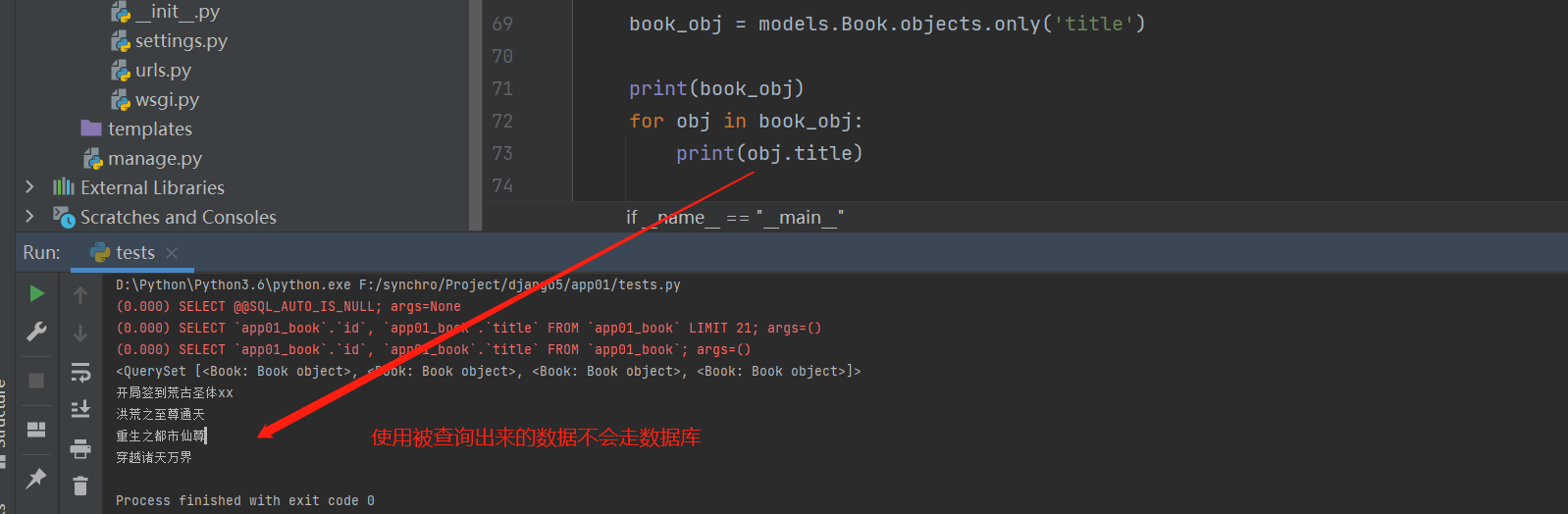
book_obj = models. Book. objects. only( 'title' )
print ( book_obj)
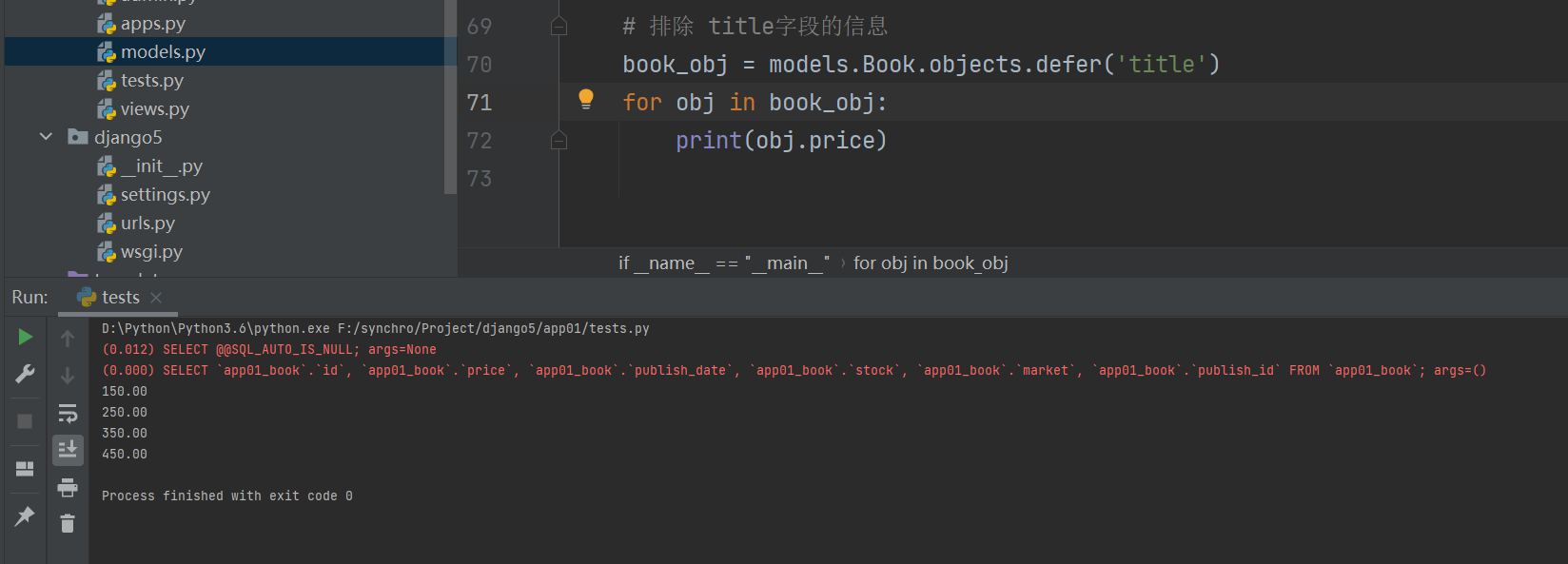
defer与only相反
defer查询指定字段外的字段 .
book_obj = models. Book. objects. defer( 'title' )
for obj in book_obj:
print ( obj. title)
查询没有被查出来的字段需要重新走数据库
for obj in book_obj:
print ( obj. price)
而查询查出来的的字段则不需要走数据库。
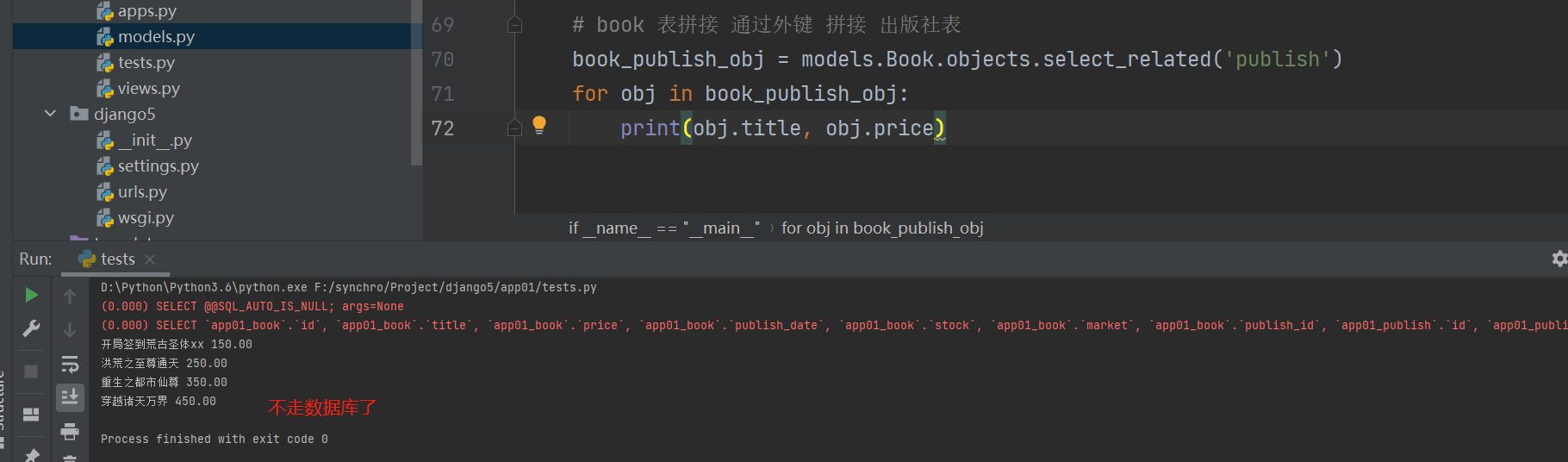
联表查询
select_related内部直接先将关联表与被关联表连接起来 , ( 拼表操作 )
select_related ( ) 括号内只能放 一对多 一对一 外键字段 。
拼接后的表中所有数据全部封装给查询出来的对象。
这个时候对象无论点击关联表的数据还是被关联表的数据都无需在走数据库查询。
给了多对多的虚拟字段会报错
django . core . exceptions . FieldError:select_related 中给出的字段名称无效
book_publish_obj = models. Book. objects. select_related( 'publish' )
for obj in book_publish_obj:
print ( obj. title, obj. price)
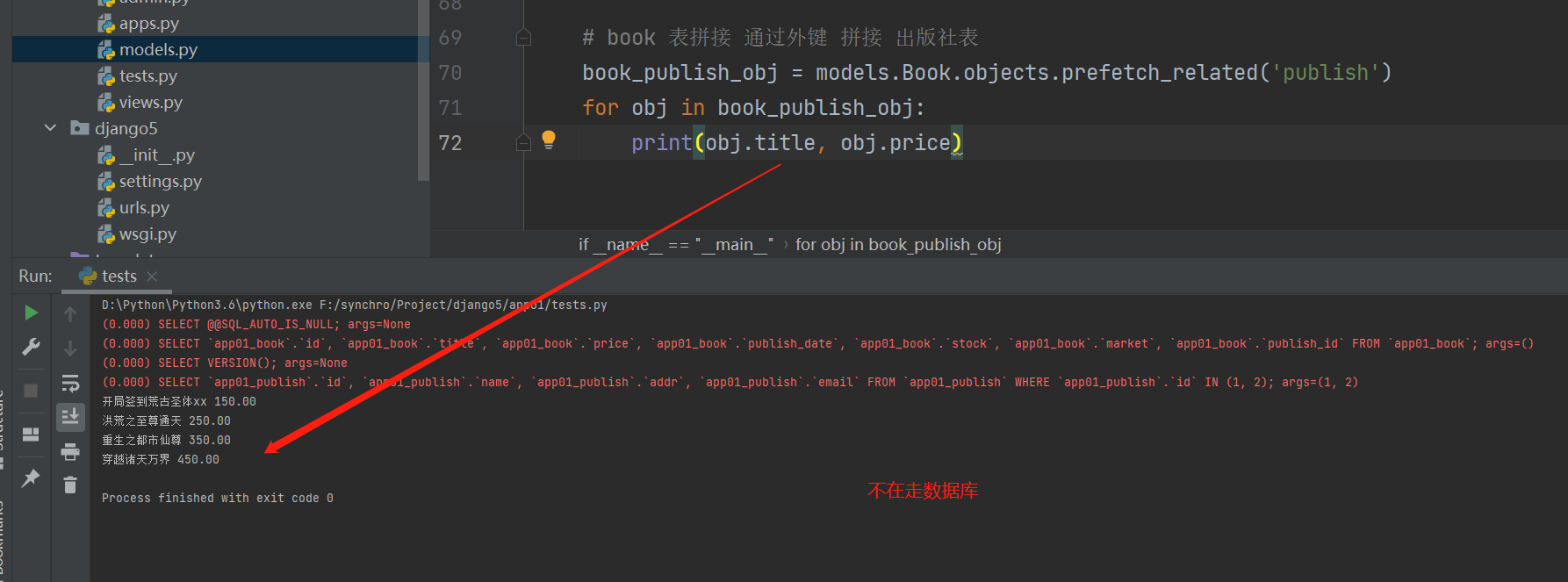
子查询
将子查询出来的所有结果封装到对象中 .
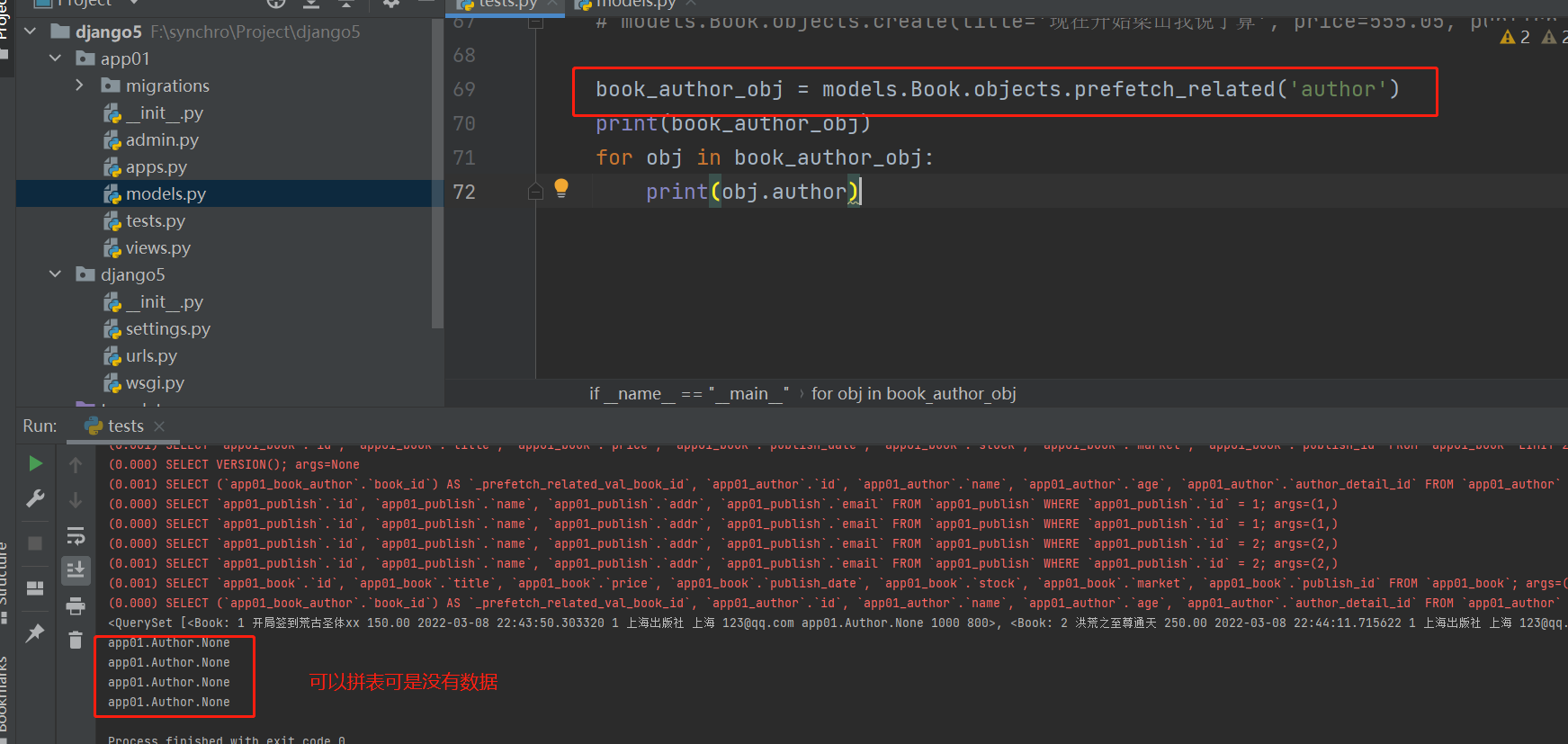
book_publish_obj = models. Book. objects. prefetch_related( 'publish' )
for obj in book_publish_obj:
print ( obj. title, obj. price)
select_related ( ) 只能为一对一 和 一对多 使用
多对多使用 , 拼接虚拟表没有数据 . ( Book类中的__str__方法打开 )











































 1935
1935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









