子查询 ( Subquery ) : 是SQL查询语句中的一个重要概念 , 它允许在一个查询语句 ( 主查询 ) 中嵌套另一个查询语句 ( 子查询 ) .
这意味着一个查询可以作为另一个查询的输入或条件 , 子查询可以出现在SQL语句的多个位置 , 例如SELECT , FROM , WHERE等子句中 .
子查询通常用于以下几种情况 :
* 1. WHERE子句中 : 子查询可以用作WHERE子句的条件 , 以过滤外部查询的结果 .
SELECT column1 , column2
FROM table1
WHERE column1 IN ( SELECT columnA FROM table2 WHERE condition ) ;
* 2. FROM子句中 : 子查询可以用作FROM子句中的一个表 , 通常与别名一起使用 .
SELECT alias . column1 , alias . column2
FROM ( SELECT columnA AS column1 , columnB AS column2 FROM table1 WHERE condition ) AS alias ;
* 3. SELECT子句中 : 子查询可以用作SELECT子句的一部分 , 以返回计算结果 .
SELECT column1 , ( SELECT COUNT ( * ) FROM table2 WHERE table2 . columnB = table1 . column1 ) AS count
FROM table1 ;
注意 :
* 1. 子查询在SQL语句中必须被括在圆括号 ( ) 内 ,
这是因为子查询作为一个独立的查询语句被嵌套在主查询中 , 而圆括号用于明确界定子查询的范围 .
* 2. 嵌套的子句不需要以分号 ( ; ) 结尾 .
* 3. 一般将来时将子查询放在比较条件的右侧 .
* 4. 子查询 ( 内查询 ) 在主查询之前一次执行完成 .
* 5. 子查询的结果被主查询 ( 外查询 ) 使用 .
* 6. 子查询不能在GROUP BY与LIMIT中使用 .
子查询可以使查询更加灵活和强 , 但它们也可能导致性能问题 , 因为每一行外部查询都可能执行一次完整的子查询 .
因此 , 在编写包含子查询的查询时 , 应该考虑到查询的性能 , 并尝试优化查询语句 .
子查询和外查询是SQL查询中的两个重要概念 :
* 1. 子查询 ( 也称内查询 ) : 是嵌套在其他SQL语句 ( 如SELECT , INSERT , UPDATE或DELETE ) 中的SELECT语句 .
子查询的结果可以作为外部查询的条件或数据源 .
子查询可以根据其出现的位置和功能进行分类 , 例如 , 它们可以出现在SELECT语句的后面作为标量子查询 ,
或者出现在FROM子句后面作为表子查询 .
* 2. 外查询 ( 也称主查询 ) : 是包含子查询的外部SQL语句 .
当子查询嵌套在另一个查询中时 , 外部的查询语句就是外查询 .
外查询负责处理子查询返回的结果 , 并基于这些结果进行进一步的筛选 , 排序或其他操作 .
在使用子查询和外查询时 , 需要注意查询的执行顺序 .
一般来说 , 子查询会先于外查询执行 , 其结果会被外查询使用 .
然而 , 在某些情况下 , 如使用EXISTS子查询时 , 外查询会先执行 , 然后再执行子查询 .
typora中多行子查手动分行后使用shuift + tab对齐代码好看一些 .
问 : 员工表中谁的工资比Ellen高?
mysql> SELECT salary FROM employees WHERE first_name = 'Ellen' ;
+
| salary |
+
| 11000.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT first_name, salary FROM employees WHERE salary > 11000 ORDER BY salary;
+
| first_name | salary |
+
| Lisa | 11500.00 |
| Nancy | 12000.00 |
| Alberto | 12000.00 |
| Shelley | 12000.00 |
| Michael | 13000.00 |
| Karen | 13500.00 |
| John | 14000.00 |
| Neena | 17000.00 |
| Lex | 17000.00 |
| Steven | 24000.00 |
+
10 rows in set ( 0.00 sec)
SELECT emp2. first_name, emp2. salary
FROM employees AS ` emp1` JOIN employees AS ` emp2` ON emp1. first_name = 'Ellen'
AND emp1. salary < emp2. salary;
+
| first_name | salary |
+
| Steven | 24000.00 |
| Neena | 17000.00 |
| Lex | 17000.00 |
| Nancy | 12000.00 |
| John | 14000.00 |
| Karen | 13500.00 |
| Alberto | 12000.00 |
| Lisa | 11500.00 |
| Michael | 13000.00 |
| Shelley | 12000.00 |
+
10 rows in set ( 0.00 sec)
SELECT
emp1. first_name AS ` emp1_name` , emp1. salary AS ` emp1,_salary` ,
emp2. first_name AS ` emp2_name` , emp2. salary AS ` emp2_salary` FROM employees AS ` emp1` JOIN employees AS ` emp2` ON emp1. first_name = 'Ellen'
ORDER BY emp2_salary;
问题 : 以上方式有好坏之分吗??
解答 : 自连接方式好 !
题目中可以使用子查询 , 也可以使用自连接 .
一般情况建议你使用自连接 , 因为在许多DBMS的处理过程中 , 对于自连接的处理速度要比子查询快得多 .
可以这样理解 : 子查询实际上是通过未知表进行查询后的条件判断 ,
而自连接是通过已知的自身数据表进行条件判断 , 因此在大部分DBMS中都对自连接处理进行了优化 .
* 在后面的子查询示例中 , 使用子查询不一定是最好的解题方式 , 这里只是为了学习子查询 . . .
分步查询和子查询的主要区别在于执行方式 : 分步查询是分步骤执行 , 而子查询是在一个查询语句中同时执行 .
然而 , 它们的目的都是将复杂的查询分解为更小的部分 , 以提高查询的可读性和可管理性 .
例 : 查询名字为 'Jack' 的工作的城市 .
分步查询方法 : 可以通过一张表一张表分步查询 .
* 1. 先从员工表中获取获取jack的部门id .
* 2. 拿着部门id去部门表获取地址id .
* 3. 最后通过地址id获取城市的名字 .
子查询方式 : 最后将三步写成一条sql语句 , 前一步操作被后一步操作嵌套 .
mysql>
select department_id from employees where first_name = 'jack' ;
+
| department_id |
+
| 80 |
+
1 row in set ( 0.00 sec)
mysql>
SELECT location_id FROM departments WHERE department_id =
( SELECT department_id FROM employees WHERE first_name = 'jack' ) ;
+
| location_id |
+
| 2500 |
+
mysql>
SELECT location_id, city FROM locations WHERE location_id =
( SELECT location_id FROM departments WHERE department_id =
( SELECT department_id FROM employees WHERE first_name = 'jack' ) ) ;
+
| location_id | city |
+
| 2500 | Oxford |
+
1 row in set ( 0.00 sec)
常见的子查询写法 :
* 1. 子查询从内往外的写法 : 先写内部查询 , 然后将其结果用于外部查询 .
这种写法在逻辑上更直观 , 因为它首先定义了内部查询 , 然后外部查询基于内部查询的结果来执行 .
* 2. 子查询从外往内的写法 : 先写外部查询 , 然后在外部查询的某个位置 ( 如WHERE子句或SELECT列表中 ) 嵌入内部查询 .
内部查询根据外部查询的需要来定义 , 并返回外部查询所需的数据 .
通过示例 , 展示了如何从外到内和从内到外使用子查询 .
例 : 查询部门员工数超过 30 号部门员工数的所有部门名称 .
mysql> SELECT COUNT ( * ) FROM employees WHERE department_id = 30 ;
+
| COUNT ( * ) |
+
| 6 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id FROM employees GROUP BY department_id HAVING COUNT ( department_id) >
( SELECT COUNT ( department_id) FROM employees WHERE department_id = 30 ) ;
+
| department_id |
+
| 50 |
| 80 |
+
2 rows in set ( 0.00 sec)
mysql> SELECT department_name FROM departments WHERE department_id IN
( SELECT department_id FROM employees GROUP BY department_id HAVING COUNT ( department_id) >
( SELECT COUNT ( department_id) FROM employees WHERE department_id = 30 ) ) ;
+
| department_name |
+
| Shipping |
| Sales |
+
2 rows in set ( 0.00 sec)
SELECT department_name FROM departments;
SELECT department_name FROM departments
WHERE department_id IN ( ) ;
SELECT department_name FROM departments
WHERE department_id IN (
SELECT department_id FROM employees GROUP BY department_id
) ;
SELECT department_name FROM departments
WHERE department_id IN (
SELECT department_id FROM employees GROUP BY department_id
HAVING COUNT ( * ) > ( )
) ;
SELECT department_name FROM departments
WHERE department_id IN (
SELECT department_id FROM employees GROUP BY department_id
HAVING COUNT ( * ) > (
SELECT COUNT ( * ) FROM employees WHERE department_id = 30 )
) ;
+
| department_name |
+
| Shipping |
| Sales |
+
2 rows in set ( 0.00 sec)
从内往外写可以一步步的去验证 , 而从外往内写中间过程无法验证需要一气呵成 , 这就需要多加练习 .
按结果集的行列数 , 子查询可以分为 :
* 1. 标量子查询 ( 结果集只有一行一列 ) .
* 2. 列子查询 ( 结果集为一列多行 ) .
* 3. 表子查询 ( 结果集一般为多行多列 ) .
按子查询是否被执行多次 , 将子查询划分为 :
* 1. 不相关子查询 ( 也称非关联子查询或独立子查询 ) : 在执行时与外部查询是独立的 .
首先执行内部查询 , 然后将内部查询的结果作为固定条件或数据源传递给外部查询进行执行 .
由于内部查询无法引用外部查询的表或字段 , 且其执行与外部查询无关 , 因此不相关子查询的执行效率通常较高 .
当查询数量较小时 , 非相关子查询往往比相关子查询更为高效 .
然而 , 由于其无法动态引用外部查询的数据 , 不相关子查询在处理某些复杂的查询需求时可能不如相关子查询灵活 .
* 2. 相关子查询 ( 也称关联子查询或嵌套子查询 ) : 在执行时与外部查询紧密相关 .
首先执行外部查询 , 然后根据外部查询的每一行数据 , 为内部查询提供条件并执行内部查询 .
因此 , 相关子查询会针对外部查询的每一行数据重复执行 .
由于内部查询可以引用外部查询的表或字段 , 并根据外部查询的结果动态地改变条件 ,
这使得相关子查询在处理某些复杂的查询需求时非常有用 .
然而 , 由于需要重复执行内部查询 , 当查询数量较大时 , 相关子查询的效率可能会受到影响 .
* 简单来说 :
子查询从数据表中查询了数据结果 , 如果这个数据结果只执行一次
然后这个数据结果作为主查询的条件进行执行 , 那么这样的子查询叫做不相关子查询 .
如果子查询需要执行多次 , 即采用循环的方式 , 先从外部查询开始 , 每次都传入子查询进行查询 ,
然后再将结果反馈给外部 , 这种嵌套的执行方式就称为相关子查询 .
它们在执行顺序 , 引用外部查询的方式以及嵌套层级等方面存在显著的差异 .
单行子查询 ( Single-Row Subquery ) : 是SQL查询中的一种特定类型 , 它返回的结果集仅包含一行数据 .
这种子查询通常用于在外部查询中作为条件或值来引用 .
当你知道子查询将只返回一行数据 , 并且你需要这行数据来完成外部查询时 , 单行子查询是非常有用的 .
单行子查询通常用在SELECT , INSERT , UPDATE或DELETE语句中 , 作为WHERE子句或SET子句的一部分 .
由于它们只返回一行数据 , 所以可以使用比较运算符来比较子查询的结果与外部查询的列值 .
操作符描述示例=等于WHERE column1 = value>大于WHERE column1 > value>=大于或等于WHERE column1 >= value<小于WHERE column1 < value<=小于或等于WHERE column1 <= value<> 或 !=不等于WHERE column1 <> value 或 WHERE column1 != value
在这个表格中 , column1代表表中的某个列名 , value是与该列进行比较的值 .
单行比较操作符通常用于WHERE子句中 , 来过滤满足特定条件的行 .
注意 : 单行比较操作符只适用于单行子查询 .
mysql> SELECT salary FROM employees WHERE employee_id = 149 ;
+
| salary |
+
| 10500.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT first_name, salary FROM employees WHERE salary > (
SELECT salary FROM employees WHERE employee_id = 149 ) ;
+
| first_name | salary |
+
| Steven | 24000.00 |
| Neena | 17000.00 |
| Lex | 17000.00 |
| Nancy | 12000.00 |
| Den | 11000.00 |
| John | 14000.00 |
| Karen | 13500.00 |
| Alberto | 12000.00 |
| Gerald | 11000.00 |
| Lisa | 11500.00 |
| Ellen | 11000.00 |
| Michael | 13000.00 |
| Shelley | 12000.00 |
+
13 rows in set ( 0.00 sec)
mysql> SELECT job_id FROM employees WHERE employee_id = 141 ;
+
| job_id |
+
| ST_CLERK |
+
1 row in set ( 0.00 sec)
mysql> SELECT salary FROM employees WHERE employee_id = 143 ;
+
| salary |
+
| 2600.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT first_name, job_id, salary FROM employees
WHERE job_id = ( SELECT job_id FROM employees WHERE employee_id = 141 )
AND salary > ( SELECT salary FROM employees WHERE employee_id = 143 )
ORDER BY salary;
+
| first_name | job_id | salary |
+
| Irene | ST_CLERK | 2700.00 |
| John | ST_CLERK | 2700.00 |
| Mozhe | ST_CLERK | 2800.00 |
| Michael | ST_CLERK | 2900.00 |
| Curtis | ST_CLERK | 3100.00 |
| Julia | ST_CLERK | 3200.00 |
| Stephen | ST_CLERK | 3200.00 |
| Laura | ST_CLERK | 3300.00 |
| Jason | ST_CLERK | 3300.00 |
| Trenna | ST_CLERK | 3500.00 |
| Renske | ST_CLERK | 3600.00 |
+
11 rows in set ( 0.00 sec) )
mysql> SELECT MIN ( salary) FROM employees;
+
| MIN ( salary) |
+
| 2100.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT first_name, job_id, salary FROM employees
WHERE salary = ( SELECT MIN ( salary) FROM employees ) ;
+
| first_name | job_id | salary |
+
| TJ | ST_CLERK | 2100.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id FROM employees WHERE employee_id IN ( 141 , 174 ) ;
+
| department_id |
+
| 50 |
| 80 |
+
2 rows in set ( 0.00 sec)
mysql> SELECT manager_id FROM employees WHERE employee_id IN ( 141 , 174 ) ;
+
| manager_id |
+
| 124 |
| 149 |
+
2 rows in set ( 0.00 sec)
mysql> SELECT manager_id, manager_id, department_id FROM employees
WHERE department_id IN ( SELECT department_id FROM employees WHERE employee_id IN ( 141 , 174 ) )
AND manager_id IN ( SELECT manager_id FROM employees WHERE employee_id IN ( 141 , 174 ) ) ;
+
| manager_id | manager_id | department_id |
+
| 124 | 124 | 50 |
| 124 | 124 | 50 |
| 124 | 124 | 50 |
| 124 | 124 | 50 |
| 124 | 124 | 50 |
| 124 | 124 | 50 |
| 124 | 124 | 50 |
| 124 | 124 | 50 |
| 149 | 149 | 80 |
| 149 | 149 | 80 |
| 149 | 149 | 80 |
| 149 | 149 | 80 |
| 149 | 149 | 80 |
+
13 rows in set ( 0.00 sec)
mysql> SELECT employee_id, manager_id, department_id FROM employees
WHERE department_id IN ( SELECT department_id FROM employees WHERE employee_id IN ( 141 , 174 ) )
AND manager_id IN ( SELECT manager_id FROM employees WHERE employee_id IN ( 141 , 174 ) )
AND employee_id NOT IN ( 141 , 174 ) ;
+
| employee_id | manager_id | department_id |
+
| 142 | 124 | 50 |
| 143 | 124 | 50 |
| 144 | 124 | 50 |
| 196 | 124 | 50 |
| 197 | 124 | 50 |
| 198 | 124 | 50 |
| 199 | 124 | 50 |
| 175 | 149 | 80 |
| 176 | 149 | 80 |
| 177 | 149 | 80 |
| 179 | 149 | 80 |
+
11 rows in set ( 0.00 sec)
mysql> SELECT department_id, manager_id FROM employees WHERE employee_id IN ( 141 , 174 ) ;
+
| department_id | manager_id |
+
| 50 | 124 |
| 80 | 149 |
+
2 rows in set ( 0.00 sec)
mysql> SELECT employee_id, manager_id, department_id FROM employees
WHERE ( department_id, manager_id) IN (
SELECT department_id, manager_id FROM employees WHERE employee_id IN ( 141 , 174 ) ) ;
+
| employee_id | manager_id | department_id |
+
| 141 | 124 | 50 |
| 142 | 124 | 50 |
| 143 | 124 | 50 |
| 144 | 124 | 50 |
| 196 | 124 | 50 |
| 197 | 124 | 50 |
| 198 | 124 | 50 |
| 199 | 124 | 50 |
| 174 | 149 | 80 |
| 175 | 149 | 80 |
| 176 | 149 | 80 |
| 177 | 149 | 80 |
| 179 | 149 | 80 |
+
13 rows in set ( 0.00 sec)
mysql> SELECT employee_id, manager_id, department_id FROM employees
WHERE ( department_id, manager_id) IN (
SELECT department_id, manager_id FROM employees WHERE employee_id IN ( 141 , 174 ) )
AND employee_id NOT IN ( 141 , 174 ) ;
+
| employee_id | manager_id | department_id |
+
| 142 | 124 | 50 |
| 143 | 124 | 50 |
| 144 | 124 | 50 |
| 196 | 124 | 50 |
| 197 | 124 | 50 |
| 198 | 124 | 50 |
| 199 | 124 | 50 |
| 175 | 149 | 80 |
| 176 | 149 | 80 |
| 177 | 149 | 80 |
| 179 | 149 | 80 |
+
11 rows in set ( 0.00 sec)
mysql> SELECT department_id, MIN ( salary) FROM employees GROUP BY department_id;
+
| department_id | MIN ( salary) |
+
| NULL | 7000.00 |
| 10 | 4400.00 |
| 20 | 6000.00 |
| 30 | 2500.00 |
| 40 | 6500.00 |
| 50 | 2100.00 |
| 60 | 4200.00 |
| 70 | 10000.00 |
| 80 | 6100.00 |
| 90 | 17000.00 |
| 100 | 6900.00 |
| 110 | 8300.00 |
+
12 rows in set ( 0.00 sec)
mysql> SELECT MIN ( salary) FROM employees WHERE department_id = 50 ;
+
| MIN ( salary) |
+
| 2100.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id, MIN ( salary) AS ` min_salary` FROM employees GROUP BY department_id
HAVING min_salary > ( SELECT MIN ( salary) FROM employees WHERE department_id = 50 )
ORDER BY min_salary;
+
| department_id | min_salary |
+
| 30 | 2500.00 |
| 60 | 4200.00 |
| 10 | 4400.00 |
| 20 | 6000.00 |
| 80 | 6100.00 |
| 40 | 6500.00 |
| 100 | 6900.00 |
| NULL | 7000.00 |
| 110 | 8300.00 |
| 70 | 10000.00 |
| 90 | 17000.00 |
+
11 rows in set ( 0.00 sec)
mysql> SELECT department_id FROM departments WHERE location_id = 1800 ;
+
| department_id |
+
| 20 |
+
1 row in set ( 0.00 sec)
SELECT employee_id, first_name,
CASE department_id
WHEN ( SELECT department_id FROM departments WHERE location_id = 1800 ) THEN 'Canada'
ELSE 'USA'
END 'location'
FROM employees;
+
| employee_id | first_name | location |
+
| . . . | . . . | . . . |
| 101 | Neena | USA |
| 102 | Lex | USA |
| 199 | Douglas | USA |
| 200 | Jennifer | USA |
| 201 | Michael | Canada |
| 202 | Pat | Canada |
| 203 | Susan | USA |
| 204 | Hermann | USA |
| 205 | Shelley | USA |
| 206 | William | USA |
+
107 rows in set ( 0.00 sec)
子查询中的空值与空行问题是在数据库查询中经常遇到的挑战 .
它们可能导致查询结果不准确或返回不期望的结果集 .
下面将分别讨论这两个问题及其处理方法 :
* 1. 子查询中的空值问题 .
空值 ( NULL ) 在数据库中表示缺失或未知的数据 . 在子查询中 , 空值可能导致以下问题 :
1. 比较操作失败 : 当使用等于 ( = ) 或不等于 ( < > ) 操作符与NULL进行比较时 , 结果总是未知的 ( 即NULL ) ,
因为无法确定NULL与任何值的比较结果 .
2. 聚合函数的影响 : 某些聚合函数 ( 如COUNT , SUM等 ) 在处理NULL值时会有特定的行为 .
例如 , COUNT ( 字段 ) 函数会忽略NULL值 , 而SUM函数则会将NULL视为 0.
3. 连接操作的问题 : 在使用子查询进行连接操作时 , 如果子查询返回NULL值 , 可能会影响连接的结果 .
特别是当使用内连接 ( INNER JOIN ) 时 , 如果连接条件中包含NULL值 , 则不会返回任何匹配的行 .
为了处理子查询中的空值问题 , 可以采取以下策略 :
1. 使用IS NULL或IS NOT NULL来检查空值 , 而不是使用等于或不等于操作符 .
2. 在子查询中使用COALESCE函数或其他空值处理函数来替换或转换空值 .
3. 确保主查询和子查询中的逻辑能够正确处理NULL值 , 避免因为空值而导致查询失败或返回不准确的结果 .
* 2. 子查询返回空行的问题 .
当子查询没有返回任何行 ( 即返回空行 ) 时 , 这通常意味着子查询的条件没有匹配到任何记录 .
这可能导致主查询不返回任何结果或返回不完整的结果集 .
处理子查询返回空行的问题的方法取决于具体的查询需求和场景 :
1. 检查子查询条件 : 首先 , 确保子查询的条件是正确的 , 并且确实应该返回数据 .
如果条件太严格或存在逻辑错误 , 可能会导致子查询返回空行 .
2. 使用LEFT JOIN或RIGHT JOIN : 如果子查询用于连接操作 , 并且返回空行导致主查询结果不完整 .
可以考虑使用LEFT JOIN或RIGHT JOIN来替代子查询 . 这样即使子查询没有返回匹配的行 , 主查询也可以返回部分结果 .
3. 处理NULL值 : 如果子查询返回空行是因为某些字段的值为NULL , 并且这些NULL值影响了查询结果 ,
可以在子查询或主查询中使用相应的空值处理策略 .
4. 使用EXISTS或NOT EXISTS : 如果只需要检查子查询是否存在结果而不关心具体的返回值 , 可以使用EXISTS或NOT EXISTS操作符 .
这些操作符会在子查询返回任何行时返回真或假 , 而不受返回行数的影响 .
综上所述 , 处理子查询中的空值与空行问题需要仔细分析查询逻辑和数据结构 , 并采取适当的策略来确保查询结果的准确性和可靠性 .
通过合理的空值处理和逻辑设计 , 可以避免这些问题对查询结果的影响 .
mysql> SELECT first_name, job_id
FROM employees
WHERE job_id =
( SELECT job_id
FROM employees
WHERE first_name = 'Haas' ) ;
Empty set ( 0.00 sec)
mysql> SELECT job_id FROM employees WHERE first_name = 'Haas' ;
Empty set ( 0.00 sec)
在MySQL中 , 非法使用单行比较操作符会导致错误的行为 .
mysql> SELECT employee_id, first_name
FROM employees
WHERE salary =
( SELECT MIN ( salary)
FROM employees
GROUP BY department_id ) ;
ERROR 1242 ( 21000 ) : Subquery returns more than 1 row
mysql> SELECT MIN ( salary) FROM employees GROUP BY department_id;
+
| MIN ( salary) |
+
| 7000.00 |
| 4400.00 |
| 6000.00 |
| 2500.00 |
| 6500.00 |
| 2100.00 |
| 4200.00 |
| 10000.00 |
| 6100.00 |
| 17000.00 |
| 6900.00 |
| 8300.00 |
+
12 rows in set ( 0.00 sec)
错误的原因 : 由于子查询返回了多行结果 , 而主查询的WHERE子句期望子查询返回一个单一值来进行比较 .
单行比较操作符只适用于单行子查询 , 不能被多行子查询使用 .
表子查询 ( 也称为多行子查询或多列子查询 ) : 是指子查询返回的结果集是一个包含多行多列的表数据 .
这种子查询的结果相当于一个表 , 可以直接当作一个表来使用 .
在SQL查询中 , 表子查询通常用在主查询的FROM子句中 , 作为一个 '数据源' 供主查询使用 .
派生表 : 又称为子查询表或虚拟表 , 是SQL查询中的一个临时结果集 .
它通过子查询创建 , 并在查询执行期间存在 , 一旦查询完成 , 派生表就会被销毁 .
派生表允许你将复杂的查询逻辑封装在子查询中 , 从而使主查询更加简洁和清晰 .
SELECT column1, column2, . . .
FROM (
SELECT columnA, columnB, . . .
FROM your_table
WHERE conditions
GROUP BY columnC
HAVING conditions
) AS derived_table_name
WHERE conditions
使用派生表的注意事项 :
* 1. 性能考虑 : 虽然派生表可以简化查询逻辑 , 但过度使用或在不必要的情况下使用可能会导致性能下降 .
因此 , 在使用派生表之前 , 应评估其对查询性能的影响 , 并根据实际情况进行选择 .
* 2. 可读性 : 复杂的派生表结构可能会降低查询的可读性 .
为了保持代码清晰和易于维护 , 建议尽量简化派生表的逻辑 , 并避免过度嵌套 .
* 3. 列名唯一性 : 派生表中的列名必须是唯一的 , 不能有重复的列名 .
确保为每个列指定一个明确的名称 , 以避免混淆和错误 .
* 4. 避免在派生表中使用ORDER BY : 除非在派生表中使用TOP关键字来限制返回的记录数 ,
否则通常不允许在派生表的定义中使用ORDER BY子句进行排序 .
这是因为排序操作通常是在查询的最终结果集上进行的 , 而不是在派生表的中间结果集上 .
* 5. 派生表在SQL查询中一定要有别名 .
这是因为派生表是通过子查询生成的临时结果集 , 而在SQL查询中 , 每个表 ( 包括派生表 ) 都需要一个唯一的标识符来引用其列和数据 .
这个唯一的标识符就是别名 .
MySQL数据库管理系统明确要求为每个派生表提供别名 . 如果在查询中没有为派生表指定别名 ,
MySQL会报错并提示 'Every derived table must have its own alias' ( 每个派生表必须具有自己的别名 ) .
因此 , 为了避免错误并提高查询的清晰度 , 应该始终为派生表指定别名 .
mysql> SELECT department_id, AVG ( salary) AS ` avg_salary` FROM employees GROUP BY department_id
ORDER BY avg_salary;
+
| department_id | avg_salary |
+
| 50 | 3475.555556 |
| 30 | 4150.000000 |
| 10 | 4400.000000 |
| 60 | 5760.000000 |
| 40 | 6500.000000 |
| NULL | 7000.000000 |
| 100 | 8600.000000 |
| 80 | 8955.882353 |
| 20 | 9500.000000 |
| 70 | 10000.000000 |
| 110 | 10150.000000 |
| 90 | 19333.333333 |
+
12 rows in set ( 0.00 sec)
mysql> SELECT * FROM (
SELECT department_id, AVG ( salary) AS ` avg_salary` FROM employees GROUP BY department_id
ORDER BY avg_salary
) AS ` avg_salary_table` ;
+
| department_id | avg_salary |
+
| 50 | 3475.555556 |
| 30 | 4150.000000 |
| 10 | 4400.000000 |
| 60 | 5760.000000 |
| 40 | 6500.000000 |
| NULL | 7000.000000 |
| 100 | 8600.000000 |
| 80 | 8955.882353 |
| 20 | 9500.000000 |
| 70 | 10000.000000 |
| 110 | 10150.000000 |
| 90 | 19333.333333 |
+
12 rows in set ( 0.00 sec)
SELECT * FROM (
SELECT department_id, AVG ( salary) AS ` avg_salary` FROM employees GROUP BY department_id
ORDER BY avg_salary
) AS ` avg_salary_table` WHERE avg_salary > 10000 ;
+
| department_id | avg_salary |
+
| 110 | 10150.000000 |
| 90 | 19333.333333 |
+
2 rows in set ( 0.00 sec)
多行子查询 ( Multi-Row Subquery ) : 是SQL查询中的一种特定类型 , 它指的是子查询返回多行结果的查询 .
子查询是嵌套在主查询中的查询 , 可以作为主查询的一部分 , 用于返回需要的数据结果 .
多行子查询在数据库查询中非常有用 , 因为它允许我们在一个查询中结合多个条件和数据集 .
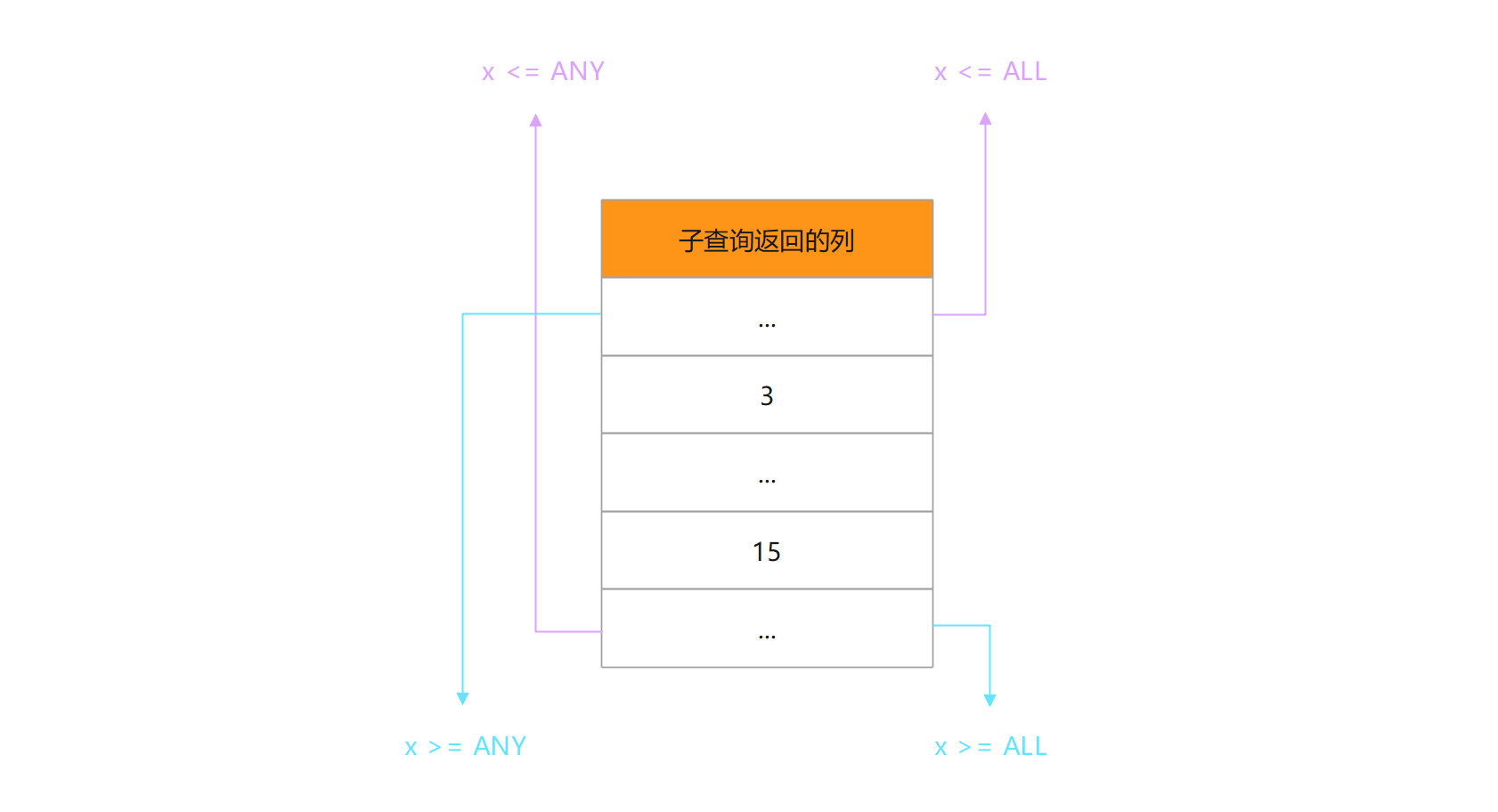
操作符描述 IN用于判断某个值是否存在于子查询返回的结果集中.ANY或SOME与子查询返回的每一个值进行比较, 只需匹配任一结果.ALL与子查询返回的所有值进行比较, 必须匹配所有结果.
注意 : ANY和ALL操作符必须与单行比较运算符 ( 如 = , < , > 等 ) 结合使用 , 并且子查询必须返回多行数据 .
此外 , 当使用这些多行子查询操作符时 , 应确保子查询的性能优化 , 以避免对数据库性能产生负面影响 .
IN操作符 : 用于判断某个值是否存在于子查询返回的结果集中 .
如果子查询返回多行数据 , 并且主查询中的某个值与子查询返回的任何一行数据匹配 , 则IN操作符返回TRUE .
* 当你不确定子查询返回的数据条目数时 , 使用IN通常比使用等号 ( = ) 更安全 .
等号只能用于比较单个值 , 而IN允许子查询返回多个值 ( 包含单个值的情况 ) .
mysql> SELECT MIN ( salary) FROM employees GROUP BY department_id;
+
| MIN ( salary) |
+
| 7000.00 |
| . . . |
| 6100.00 |
| 17000.00 |
| 6900.00 |
| 8300.00 |
+
12 rows in set ( 0.00 sec)
SELECT employee_id, first_name, salary FROM employees
WHERE salary IN ( SELECT MIN ( salary) FROM employees GROUP BY department_id ) ;
+
| employee_id | first_name | salary |
+
| 101 | Neena | 17000.00 |
| 102 | Lex | 17000.00 |
| 104 | Bruce | 6000.00 |
| . . . | . . . | . . . |
| 203 | Susan | 6500.00 |
| 204 | Hermann | 10000.00 |
| 206 | William | 8300.00 |
+
26 rows in set ( 0.00 sec)
ANY操作符 : 用于与子查询返回的每一个值进行比较 .
如果主查询中的某个值与子查询返回的任何一个值满足比较条件 ( 如大于 , 小于 , 等于等 ) , 则ANY操作符返回TRUE .
mysql> SELECT salary FROM employees WHERE department_id = 20 ;
+
| salary |
+
| 13000.00 |
| 6000.00 |
+
2 rows in set ( 0.01 sec)
mysql> SELECT employee_id, first_name, salary FROM employees
WHERE salary > ANY ( SELECT salary FROM employees WHERE department_id = 20 )
ORDER BY salary;
+
| employee_id | first_name | salary |
+
| 173 | Sundita | 6100.00 |
| 179 | Charles | 6200.00 |
| . . . | . . . | . . . |
| 145 | John | 14000.00 |
| 101 | Neena | 17000.00 |
| 102 | Lex | 17000.00 |
| 100 | Steven | 24000.00 |
+
55 rows in set ( 0.00 sec)
ALL操作符 : 用于与子查询返回的所有值进行比较 .
只有当主查询中的某个值与子查询返回的所有值都满足比较条件时 , ALL操作符才返回TRUE .
mysql> SELECT salary FROM employees WHERE job_id = 'IT_PROG' ;
+
| salary |
+
| 9000.00 |
| 6000.00 |
| 4800.00 |
| 4800.00 |
| 4200.00 |
+
5 rows in set ( 0.01 sec)
SELECT employee_id, first_name, salary FROM employees
WHERE salary < ALL ( SELECT salary FROM employees WHERE job_id = 'IT_PROG' )
ORDER BY salary;
+
| employee_id | first_name | salary |
+
| 132 | TJ | 2100.00 |
| 128 | Steven | 2200.00 |
| . . . | . . . | . . . |
| 137 | Renske | 3600.00 |
| 189 | Jennifer | 3600.00 |
| 188 | Kelly | 3800.00 |
| 193 | Britney | 3900.00 |
| 192 | Sarah | 4000.00 |
| 185 | Alexis | 4100.00 |
+
44 rows in set ( 0.00 sec)
mysql> SELECT salary FROM employees WHERE job_id = 'IT_PROG' ;
+
| salary |
+
| 9000.00 |
| 6000.00 |
| 4800.00 |
| 4800.00 |
| 4200.00 |
+
5 rows in set ( 0.00 sec)
SELECT employee_id, first_name, job_id, salary FROM employees
WHERE job_id != 'IT_PROG'
AND salary < any ( SELECT salary FROM employees WHERE job_id = 'IT_PROG' )
ORDER BY salary;
+
| employee_id | first_name | job_id | salary |
+
| 132 | TJ | ST_CLERK | 2100.00 |
| 128 | Steven | ST_CLERK | 2200.00 |
| . . . | . . . | . . . | . . . |
| 159 | Lindsey | SA_REP | 8000.00 |
| 153 | Christopher | SA_REP | 8000.00 |
| 110 | John | FI_ACCOUNT | 8200.00 |
| 121 | Adam | ST_MAN | 8200.00 |
| 206 | William | AC_ACCOUNT | 8300.00 |
| 177 | Jack | SA_REP | 8400.00 |
| 176 | Jonathon | SA_REP | 8600.00 |
| 175 | Alyssa | SA_REP | 8800.00 |
+
76 rows in set ( 0.00 sec)
mysql> SELECT AVG ( salary) FROM employees GROUP BY department_id;
+
| AVG ( salary) |
+
| 7000.000000 |
| 4400.000000 |
| 9500.000000 |
| 4150.000000 |
| 6500.000000 |
| 3475.555556 |
| 5760.000000 |
| 10000.000000 |
| 8955.882353 |
| 19333.333333 |
| 8600.000000 |
| 10150.000000 |
+
12 rows in set ( 0.00 sec)
mysql> SELECT MIN ( avg_salary) FROM (
SELECT AVG ( salary) AS ` avg_salary` FROM employees GROUP BY department_id
) AS ` avg_salary_table` ;
+
| MIN ( avg_salary) |
+
| 3475.555556 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id, AVG ( salary) AS ` avg_salary` FROM employees GROUP BY department_id
HAVING avg_salary = (
SELECT MIN ( avg_salary) FROM (
SELECT AVG ( salary) AS ` avg_salary` FROM employees GROUP BY department_id
) AS ` avg_salary_table` ) ;
+
| department_id | avg_salary |
+
| 50 | 3475.555556 |
+
1 row in set ( 0.01 sec)
mysql> SELECT AVG ( salary) FROM employees GROUP BY department_id;
+
| AVG ( salary) |
+
| 7000.000000 |
| 4400.000000 |
| 9500.000000 |
| 4150.000000 |
| 6500.000000 |
| 3475.555556 |
| 5760.000000 |
| 10000.000000 |
| 8955.882353 |
| 19333.333333 |
| 8600.000000 |
| 10150.000000 |
+
12 rows in set ( 0.00 sec)
SELECT department_id, AVG ( salary) AS ` avg_salary` FROM employees
GROUP BY department_id HAVING avg_salary <= ALL (
SELECT AVG ( salary) FROM employees GROUP BY department_id) ;
+
| department_id | avg_salary |
+
| 50 | 3475.555556 |
+
1 row in set ( 0.00 sec)
多行子查询空值问题主要出现在使用NOT IN操作符时 :
如果子查询返回的结果中包含NULL值 , 那么整个NOT IN表达式的结果将会是空值 ( NULL ) , 而不是预期的非匹配结果 .
这是因为NULL在SQL中代表未知或缺失的值 , 与任何值的比较 ( 包括自身 ) 结果都是未知 ( NULL ) .
解决方式 :
* 1. 使用IS NULL和IS NOT NULL排除子查询中的NULL值 .
* 2. 使用LEFT JOIN代替NOT IN , 并通过检查连接键是否为NULL来找到非匹配的行 .
* 3. 使用EXISTS或ANY代替NOT IN避免NULL值的问题。
mysql> SELECT manager_id FROM employees GROUP BY manager_id;
+
| manager_id |
+
| NULL |
| 100 |
| . . . |
| 147 |
| 148 |
| 149 |
| 201 |
| 205 |
+
19 rows in set ( 0.00 sec)
SELECT first_name FROM employees
WHERE employee_id NOT IN ( SELECT manager_id FROM employees GROUP BY manager_id) ;
Empty set ( 0.01 sec)
SELECT first_name FROM employees
WHERE employee_id NOT IN (
SELECT manager_id FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id ) ;
+
| first_name |
+
| Bruce |
| David |
| Valli |
| . . . |
| Douglas |
| Jennifer |
| Pat |
| Susan |
| Hermann |
| William |
+
89 rows in set ( 0.00 sec)
SELECT first_name
FROM employees
WHERE employee_id NOT IN (
SELECT manager_id FROM employees
WHERE manager_id IS NOT NULL ) ;
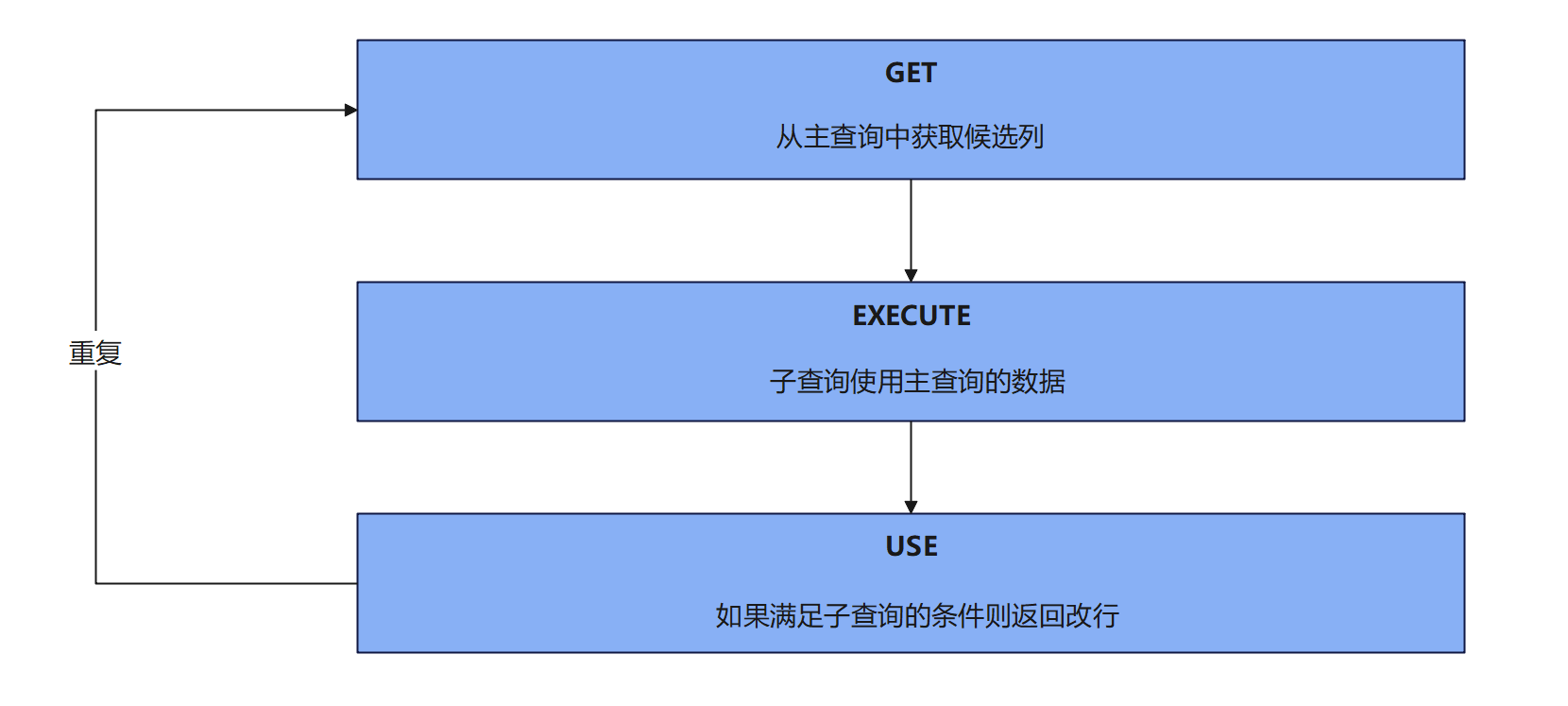
关联子查询是SQL中一种特殊的子查询类型 , 它的执行依赖于外部查询的结果 .
这是因为子查询中引用了外部查询的列或表 , 并且它们之间通过某种条件进行了关联 .
当执行一个包含关联子查询的SQL语句时 , 数据库管理系统会按照以下步骤进行 :
* 1. 外部查询初始化 : 首先 , 外部查询开始执行 , 并准备获取数据 .
* 2. 逐行处理 : 对于外部查询的每一行 , 都会执行一次关联子查询 .
这意味着 , 如果外部查询返回 10 行数据 , 那么关联子查询将至少执行 10 次 .
* 3. 子查询执行 : 在每次执行关联子查询时 , 它都会引用当前外部查询行的相关列值 , 并根据这些值来过滤或计算子查询的结果 .
* 4. 结果返回 : 一旦子查询执行完毕并得出结果 , 这个结果就会用于外部查询的当前行 , 以确定该行是否满足外部查询的条件 .
* 5. 继续处理 : 然后 , 外部查询会移到下一行 , 并重复上述步骤 , 直到所有行都被处理完毕 .
相关子查询是与外部查询的每一行都相关联的 , 它会根据外部查询的每一行数据动态地执行子查询 .
对于外部查询表中的每一行 , 都会执行一次子查询 , 以基于该行的数据来获取相关信息或计算结果 .
因此 , 外查询表中有多少条数据 , 相关子查询就会执行多少次 , 如果外部查询表中有N条数据 , 那么相关子查询就会执行N次 .
这种执行方式虽然可以灵活地处理每一行数据的特定需求 , 但在处理大量数据时可能会导致性能问题 .
因此 , 在编写涉及相关子查询的SQL语句时 , 需要仔细考虑查询的性能 , 并考虑是否可以通过其他方式 ( 如JOIN操作 ) 来优化查询 .
常见的相关子查询的语法格式示例 :
SELECT column1 , column2 , . . .
FROM table1
WHERE columnX operator (
SELECT columnY
FROM table2
WHERE table1 . common_column = table2 . common_column -- 子查询中的关联条件 , 它连接了外部查询和子查询 .
) ;
子查询中的table1 . common_column引用了外部查询的表table1的列 , 这使得子查询的执行依赖于外部查询的当前行 .
SELECT department_id, department_name
FROM departments as ` dep` WHERE (
SELECT COUNT ( * )
FROM employees AS ` emp` WHERE emp. department_id = dep. department_id
) > 10 ;
+
| department_id | department_name |
+
| 50 | Shipping |
| 80 | Sales |
+
2 rows in set ( 0.00 sec)
执行步骤说明 :
数据库管理系统会遍历departments表的每一行 .
对于每一行 , 它都会执行内部的SELECT COUNT ( * ) 子查询 , 来计算当前部门在employees表中的员工数量 .
然后 , 它会检查这个计数是否大于 10.
如果是 , 那么它就会将当前部门的department_id和department_name添加到结果集中 .
这个过程会一直持续到departments表的所有行都被处理完毕 .
最后 , 数据库管理系统会返回满足条件的部门列表 .
SELECT AVG ( salary) FROM employees AS ` sub_emp` ;
SELECT AVG ( salary) FROM employees AS ` sub_emp` WHERE sub_empemp. department_id = main_emp. department_id;
SELECT employee_id, salary, department_id FROM employees AS ` main_emp` ;
SELECT employee_id, salary, department_id FROM employees AS ` main_emp` WHERE salary > ( ) ;
SELECT employee_id, salary, department_id FROM employees AS ` main_emp` WHERE salary > (
SELECT AVG ( salary) FROM employees AS ` sub_emp` WHERE sub_emp. department_id = main_emp. department_id
) ORDER BY department_id, salary;
+
| employee_id | salary | department_id |
+
| 201 | 13000.00 | 20 |
| 114 | 11000.00 | 30 |
| 141 | 3500.00 | 50 |
| 189 | 3600.00 | 50 |
| 137 | 3600.00 | 50 |
| 188 | 3800.00 | 50 |
| . . . | . . . | . . . |
| 145 | 14000.00 | 80 |
| 100 | 24000.00 | 90 |
| 109 | 9000.00 | 100 |
| 108 | 12000.00 | 100 |
| 205 | 12000.00 | 110 |
+
38 rows in set ( 0.01 sec)
SELECT employee_id, department_id, salary, avg_salary
FROM employees AS ` main_emp` INNER JOIN (
SELECT department_id, AVG ( salary) AS ` avg_salary` FROM employees GROUP BY department_id) AS ` avg_salary_table` USING ( department_id)
WHERE salary > avg_salary;
. . .
38 rows in set ( 0.00 sec)
SELECT department_name FROM departments AS ` sub_dep` ;
SELECT department_name FROM departments AS ` sub_dep` WHERE sub_dep. department_id = main_emp. department_id;
SELECT employee_id, salary FROM employees AS ` main_emp` ;
SELECT employee_id, salary FROM employees AS ` main_emp` ORDER BY ( ) ;
SELECT employee_id, salary FROM employees AS ` main_emp` ORDER BY (
SELECT department_name FROM departments AS ` sub_dep` WHERE sub_dep. department_id = main_emp. department_id ) ;
+
| employee_id | salary |
+
| 178 | 7000.00 |
| 205 | 12000.00 |
| 206 | 8300.00 |
| 200 | 4400.00 |
| . . . | . . . |
| 196 | 3100.00 |
| 197 | 3000.00 |
| 198 | 2600.00 |
| 199 | 2600.00 |
+
107 rows in set ( 0.00 sec)
SELECT employee_id, salary, department_name
FROM employees
LEFT JOIN departments
USING ( department_id)
ORDER BY department_name;
+
| employee_id | salary | department_name |
+
| 178 | 7000.00 | NULL |
| 205 | 12000.00 | Accounting |
| 206 | 8300.00 | Accounting |
| 200 | 4400.00 | Administration |
| . . . | . . . | . . . |
| 196 | 3100.00 | Shipping |
| 197 | 3000.00 | Shipping |
| 198 | 2600.00 | Shipping |
| 199 | 2600.00 | Shipping |
+
107 rows in set ( 0.00 sec)
mysql> SELECT * FROM job_history;
+
| employee_id | start_date | end_date | job_id | department_id |
+
| 101 | 1989 - 09 - 21 | 1993 - 10 - 27 | AC_ACCOUNT | 110 |
| 101 | 1993 - 10 - 28 | 1997 - 03 - 15 | AC_MGR | 110 |
| 102 | 1993 - 01 - 13 | 1998 - 07 - 24 | IT_PROG | 60 |
| 114 | 1998 - 03 - 24 | 1999 - 12 - 31 | ST_CLERK | 50 |
| 122 | 1999 - 01 - 01 | 1999 - 12 - 31 | ST_CLERK | 50 |
| 176 | 1998 - 03 - 24 | 1998 - 12 - 31 | SA_REP | 80 |
| 176 | 1999 - 01 - 01 | 1999 - 12 - 31 | SA_MAN | 80 |
| 200 | 1987 - 09 - 17 | 1993 - 06 - 17 | AD_ASST | 90 |
| 200 | 1994 - 07 - 01 | 1998 - 12 - 31 | AC_ACCOUNT | 90 |
| 201 | 1996 - 02 - 17 | 1999 - 12 - 19 | MK_REP | 20 |
+
10 rows in set ( 0.02 sec)
SELECT COUNT ( * ) FROM job_history AS ` sub_job` ;
SELECT COUNT ( * ) FROM job_history AS ` sub_job` WHERE sub_job. employee_id = main_emp. employee_id;
SELECT employee_id, first_name, job_id FROM employees AS ` main_emp` ;
SELECT employee_id, first_name, job_id FROM employees AS ` main_emp` WHERE 2 <= ( ) ;
SELECT employee_id, first_name, job_id FROM employees AS ` main_emp` WHERE 2 <= (
SELECT COUNT ( * ) FROM job_history AS ` sub_job` WHERE sub_job. employee_id = main_emp. employee_id
) ;
+
| employee_id | first_name | job_id |
+
| 101 | Neena | AD_VP |
| 176 | Jonathon | SA_REP |
| 200 | Jennifer | AD_ASST |
+
3 rows in set ( 0.01 sec)
在SQL中 , 当使用相关子查询时 , 如果主查询中的某个值在子查询中没有对应的值 , 那么子查询的返回结果将为NULL .
mysql> SELECT department_id, department_name, (
SELECT AVG ( salary) FROM employees AS ` sub_emp` WHERE sub_emp. department_id = main_dep. department_id
) AS ` avg_salary` FROM departments AS ` main_dep` ;
+
| department_id | department_name | avg_salary |
+
| 10 | Administration | 4400.000000 |
| 20 | Marketing | 9500.000000 |
| 30 | Purchasing | 4150.000000 |
| 200 | . . . | . . . |
| 210 | IT Support | NULL |
| 220 | NOC | NULL |
| 230 | IT Helpdesk | NULL |
| 240 | Government Sales | NULL |
| 250 | Retail Sales | NULL |
| 260 | Recruiting | NULL |
| 270 | Payroll | NULL |
+
27 rows in set ( 0.00 sec)
出现NULL值的原因是在sub_emp子查询中 , 对于某些department_id在employees表中没有对应的记录 ,
因此子查询没有返回任何值 , 导致avg_salary列的值为NULL .
这种行为是由SQL的查询处理模型决定的 .
SELECT department_id, department_name, (
SELECT AVG ( salary) FROM employees AS ` sub_emp` WHERE sub_emp. department_id = main_dep. department_id
) AS ` avg_salary` FROM departments AS ` main_dep` WHERE department_id IN ( SELECT department_id FROM employees ) ;
+
| department_id | department_name | avg_salary |
+
| 10 | Administration | 4400.000000 |
| 20 | Marketing | 9500.000000 |
| 30 | Purchasing | 4150.000000 |
| 40 | Human Resources | 6500.000000 |
| 50 | Shipping | 3475.555556 |
| 60 | IT | 5760.000000 |
| 70 | Public Relations | 10000.000000 |
| 80 | Sales | 8955.882353 |
| 90 | Executive | 19333.333333 |
| 100 | Finance | 8600.000000 |
| 110 | Accounting | 10150.000000 |
+
11 rows in set ( 0.00 sec)
EXISTS和NOT EXISTS是SQL中用于检查子查询是否返回任何结果的关键字 .
这两个关键字常用于WHERE子句中 , 以基于子查询的结果来过滤外部查询的行 .
EXISTS关键字 : 用于检查子查询是否至少返回一行数据 .
如果子查询至少返回一行 , EXISTS的结果为TRUE ; 如果子查询没有返回任何行 , EXISTS的结果为FALSE .
NOT EXISTS关键字 : 用于检查子查询是否不返回任何行 .
如果子查询没有返回任何行 , NOT EXISTS 的结果为 TRUE ; 如果子查询返回了至少一行 , NOT EXISTS的结果为FALSE .
注意事项 :
* 1. 在EXISTS和NOT EXISTS的子查询中 , 通常使用 SELECT 1 ,
因为实际上我们并不关心子查询返回的具体数据 , 只关心它是否返回了数据 .
* 2. 使用EXISTS和NOT EXISTS通常比使用IN或NOT IN在性能上更优 , 特别是在处理大量数据时 ,
因为一旦子查询找到匹配的行 , 它就会立即停止搜索并返回结果 .
* 3. 当使用这些关键字时 , 确保子查询的逻辑是正确的 , 以避免返回不期望的结果 .
* 在MySQL中 , 某些情况下可以使用EXISTS和NOT EXISTS关键字来代替IN或NOT IN的查询语句 .
SELECT DISTINCT emp1. employee_id, emp1. first_name, emp1. job_id, emp1. department_id
FROM employees AS ` emp1` INNER JOIN employees AS ` emp2` ON emp1. employee_id = emp2. manager_id;
+
| employee_id | first_name | job_id | department_id |
+
| 100 | Steven | AD_PRES | 90 |
| 101 | Neena | AD_VP | 90 |
| 102 | Lex | AD_VP | 90 |
| 103 | Alexander | IT_PROG | 60 |
| 108 | Nancy | FI_MGR | 100 |
| 114 | Den | PU_MAN | 30 |
| 120 | Matthew | ST_MAN | 50 |
| 121 | Adam | ST_MAN | 50 |
| 122 | Payam | ST_MAN | 50 |
| 123 | Shanta | ST_MAN | 50 |
| 124 | Kevin | ST_MAN | 50 |
| 145 | John | SA_MAN | 80 |
| 146 | Karen | SA_MAN | 80 |
| 147 | Alberto | SA_MAN | 80 |
| 148 | Gerald | SA_MAN | 80 |
| 149 | Eleni | SA_MAN | 80 |
| 201 | Michael | MK_MAN | 20 |
| 205 | Shelley | AC_MGR | 110 |
+
18 rows in set ( 0.01 sec)
SELECT employee_id, first_name, job_id, department_id FROM employees
WHERE employee_id IN ( SELECT DISTINCT manager_id FROM employees ) ;
SELECT employee_id, first_name, job_id, department_id
FROM employees AS ` main_emp` WHERE EXISTS (
SELECT 1 FROM employees AS ` sub_emp` WHERE sub_emp. manager_id = main_emp. employee_id ) ;
+
| employee_id | first_name | job_id | department_id |
+
| 100 | Steven | AD_PRES | 90 |
| 101 | Neena | AD_VP | 90 |
| 102 | Lex | AD_VP | 90 |
| 103 | Alexander | IT_PROG | 60 |
| 108 | Nancy | FI_MGR | 100 |
| 114 | Den | PU_MAN | 30 |
| 120 | Matthew | ST_MAN | 50 |
| 121 | Adam | ST_MAN | 50 |
| 122 | Payam | ST_MAN | 50 |
| 123 | Shanta | ST_MAN | 50 |
| 124 | Kevin | ST_MAN | 50 |
| 145 | John | SA_MAN | 80 |
| 146 | Karen | SA_MAN | 80 |
| 147 | Alberto | SA_MAN | 80 |
| 148 | Gerald | SA_MAN | 80 |
| 149 | Eleni | SA_MAN | 80 |
| 201 | Michael | MK_MAN | 20 |
| 205 | Shelley | AC_MGR | 110 |
+
18 rows in set ( 0.00 sec)
SELECT department_id, department_name FROM departments AS ` main_dep` WHERE NOT EXISTS (
SELECT 1 FROM employees AS ` sub_emp` WHERE sub_emp. department_id = main_dep. department_id ) ;
+
| department_id | department_name |
+
| 120 | Treasury |
| 130 | Corporate Tax |
| 140 | Control And Credit |
| 150 | Shareholder Services |
| 160 | Benefits |
| 170 | Manufacturing |
| 180 | Construction |
| 190 | Contracting |
| 200 | Operations |
| 210 | IT Support |
| 220 | NOC |
| 230 | IT Helpdesk |
| 240 | Government Sales |
| 250 | Retail Sales |
| 260 | Recruiting |
| 270 | Payroll |
+
16 rows in set ( 0.01 sec)
使用相关子查询依据一个表中的数据更新另一个表的数据 .
UPDATE table1 alias1
SET column = ( SELECT expression
FROM table2 alias2
WHERE alias1. column = alias2. column ) ;
ALTER TABLE employees
ADD ( department_name VARCHAR ( 24 ) ) ;
Query OK, 0 rows affected ( 0.03 sec)
Records: 0 Duplicates: 0 Warnings : 0
UPDATE employees AS ` emp` SET department_name = ( SELECT department_name
FROM departments AS ` dep` WHERE emp. department_id = dep. department_id ) ;
Query OK, 106 rows affected ( 0.01 sec)
Rows matched : 107 Changed: 106 Warnings : 0
SELECT employee_id, first_name, department_id, department_name FROM employees;
+
| employee_id | first_name | department_id | department_name |
+
| 100 | Steven | 90 | Executive |
| 101 | Neena | 90 | Executive |
| 102 | Lex | 90 | Executive |
| 103 | Alexander | 60 | IT |
| 104 | Bruce | 60 | IT |
| 105 | David | 60 | IT |
+
107 rows in set ( 0.00 sec)
使用相关子查询依据一个表中的数据删除另一个表的数据 .
DELETE FROM table1 alias1
WHERE column operator ( SELECT expression
FROM table2 alias2
WHERE alias1. column = alias2. column ) ;
DELETE FROM employees AS ` main_emp` WHERE EXISTS (
SELECT employee_id FROM job_history AS ` sub_history` WHERE main_emp. employee_id = sub_history. employee_id
) ;
SELECT employee_id FROM employees AS ` main_emp` WHERE EXISTS (
SELECT employee_id FROM job_history AS ` sub_history` WHERE sub_history. employee_id = main_emp. employee_id ) ;
+
| employee_id |
+
| 101 |
| 102 |
| 114 |
| 122 |
| 176 |
| 200 |
| 201 |
+
7 rows in set ( 0.00 sec)
SELECT department_id FROM employees AS ` main_emp` WHERE employee_id = (
SELECT employee_id FROM job_history AS ` sub_history` WHERE sub_history. employee_id = main_emp. employee_id ) ;
ERROR 1242 ( 21000 ) : Subquery returns more than 1 row
+
| department_id |
+
| 20 |
| 30 |
| 50 |
| 90 |
| 80 |
| 10 |
| 90 |
+
7 rows in set ( 0.00 sec)
很多题目读起来很变扭 , 思来想去为什么? 哦 , 是为了锻炼小朋友 .
mysql> SELECT department_id from employees WHERE first_name = 'Eleni' ;
+
| department_id |
+
| 80 |
+
1 row in set ( 0.00 sec)
SELECT first_name, salary, department_id FROM employees
WHERE department_id = (
SELECT department_id from employees WHERE first_name = 'Eleni'
) ;
+
| first_name | salary | department_id |
+
| John | 14000.00 | 80 |
| Karen | 13500.00 | 80 |
| Elizabeth | 7300.00 | 80 |
| Sundita | 6100.00 | 80 |
| . . . | . . . | . . . |
| Alyssa | 8800.00 | 80 |
| Jonathon | 8600.00 | 80 |
| Jack | 8400.00 | 80 |
| Charles | 6200.00 | 80 |
+
34 rows in set ( 0.00 sec)
mysql> SELECT AVG ( salary) FROM employees;
+
| AVG ( salary) |
+
| 6461.682243 |
+
1 row in set ( 0.00 sec)
SELECT employee_id, first_name, salary FROM employees
WHERE salary > (
SELECT AVG ( salary) FROM employees
) ORDER BY salary;
+
| employee_id | first_name | salary |
+
| 203 | Susan | 6500.00 |
| 123 | Shanta | 6500.00 |
| . . . | . . . | . . . |
| 146 | Karen | 13500.00 |
| 145 | John | 14000.00 |
| 101 | Neena | 17000.00 |
| 102 | Lex | 17000.00 |
| 100 | Steven | 24000.00 |
+
51 rows in set ( 0.00 sec)
mysql> SELECT salary FROM employees WHERE job_id = 'SA_MAN' ;
+
| salary |
+
| 14000.00 |
| 13500.00 |
| 12000.00 |
| 11000.00 |
| 10500.00 |
+
5 rows in set ( 0.00 sec)
SELECT first_name, job_id, salary FROM employees
WHERE salary > ALL (
SELECT salary FROM employees WHERE job_id = 'SA_MAN'
) ;
+
| first_name | job_id | salary |
+
| Steven | AD_PRES | 24000.00 |
| Neena | AD_VP | 17000.00 |
| Lex | AD_VP | 17000.00 |
+
3 rows in set ( 0.00 sec)
mysql> SELECT department_id FROM employees WHERE last_name LIKE '%u%' ;
+
| department_id |
+
| 60 |
| 60 |
| . . . |
| 30 |
| 50 |
| 50 |
| 50 |
+
19 rows in set ( 0.00 sec)
mysql> SELECT employee_id, salary, department_id FROM employees
WHERE department_id IN (
SELECT DISTINCT department_id FROM employees WHERE last_name LIKE '%u%'
) ;
+
| employee_id | salary | department_id |
+
| 103 | 9000.00 | 60 |
| 104 | 6000.00 | 60 |
| 105 | 4800.00 | 60 |
| . . . | . . . | . . . |
| 175 | 8800.00 | 80 |
| 176 | 8600.00 | 80 |
| 177 | 8400.00 | 80 |
| 179 | 6200.00 | 80 |
+
96 rows in set ( 0.00 sec)
mysql> SELECT department_id FROM departments WHERE location_id = '1700' ;
+
| department_id |
+
| 10 |
| 30 |
| 90 |
| . . . |
| 240 |
| 250 |
| 260 |
| 270 |
+
21 rows in set ( 0.00 sec)
mysql> SELECT employee_id FROM employees
WHERE department_id IN (
SELECT department_id FROM departments WHERE location_id = '1700'
) ;
+
| employee_id |
+
| 200 |
| 114 |
| . . . |
| 112 |
| 113 |
| 205 |
| 206 |
+
18 rows in set ( 0.00 sec)
mysql> SELECT employee_id FROM employees WHERE last_name = 'King' ;
+
| employee_id |
+
| 100 |
| 156 |
+
2 rows in set ( 0.00 sec)
mysql> SELECT first_name, salary FROM employees
WHERE manager_id IN (
SELECT employee_id FROM employees WHERE last_name = 'King'
) ;
+
| first_name | salary |
+
| Neena | 17000.00 |
| Lex | 17000.00 |
| . . . | . . . |
| Alberto | 12000.00 |
| Gerald | 11000.00 |
| Eleni | 10500.00 |
| Michael | 13000.00 |
+
14 rows in set ( 0.00 sec)
mysql> SELECT MIN ( salary) FROM employees;
+
| MIN ( salary) |
+
| 2100.00 |
+
1 row in set ( 0.00 sec)
SELECT first_name, salary FROM employees
WHERE salary = (
SELECT MIN ( salary) FROM employees
) ;
+
| first_name | salary |
+
| TJ | 2100.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT first_name, salary FROM employees
ORDER BY salary LIMIT 1 ;
+
| first_name | salary |
+
| TJ | 2100.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT AVG ( salary) AS ` avg_salary` FROM employees GROUP BY department_id;
+
| avg_salary |
+
| 7000.000000 |
| 4400.000000 |
| . . . |
| 10150.000000 |
+
12 rows in set ( 0.00 sec)
mysql> SELECT MIN ( avg_salary) FROM (
SELECT AVG ( salary) AS ` avg_salary` FROM employees GROUP BY department_id
) AS ` avg_salary_table` ;
+
| MIN ( avg_salary) |
+
| 3475.555556 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id FROM employees
GROUP BY department_id
HAVING AVG ( salary) = (
SELECT MIN ( avg_salary) FROM (
SELECT AVG ( salary) AS ` avg_salary` FROM employees GROUP BY department_id
) AS ` avg_salary_table` ) ;
+
| department_id |
+
| 50 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id, department_name FROM departments
WHERE department_id = (
SELECT department_id FROM employees
GROUP BY department_id
HAVING AVG ( salary) = (
SELECT MIN ( avg_salary) FROM (
SELECT AVG ( salary) AS ` avg_salary` FROM employees GROUP BY department_id
) AS ` avg_salary_table` )
) ;
+
| department_id | department_name |
+
| 50 | Shipping |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id, AVG ( salary) AS ` avg_salary` FROM employees
GROUP BY department_id
ORDER BY avg_salary
LIMIT 1 ;
+
| department_id | avg_salary |
+
| 50 | 3475.555556 |
+
1 row in set ( 0.00 sec)
SELECT department_id FROM (
SELECT department_id, AVG ( salary) AS ` avg_salary` FROM employees
GROUP BY department_id
ORDER BY avg_salary
LIMIT 1
) AS ` min_avg_salary_table` ;
+
| department_id |
+
| 50 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id, department_name FROM departments
WHERE department_id = (
SELECT department_id FROM (
SELECT department_id, AVG ( salary) AS ` avg_salary` FROM employees
GROUP BY department_id
ORDER BY avg_salary
LIMIT 1
) AS ` min_avg_salary_table` ) ;
+
| department_id | department_name |
+
| 50 | Shipping |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id, AVG ( salary) AS ` avg_salary` FROM employees AS ` sub_emp` GROUP BY department_id;
+
| department_id | avg_salary |
+
| NULL | 7000.000000 |
| 10 | 4400.000000 |
| 90 | 19333.333333 |
| . . . | . . . |
| 110 | 10150.000000 |
+
12 rows in set ( 0.00 sec)
mysql> SELECT department_id, (
SELECT AVG ( salary) AS ` avg_salary` FROM employees AS ` sub_emp` WHERE sub_emp. department_id = main_dep. department_id
) AS ` avg_salary` FROM departments AS main_dep;
+
| department_id | avg_salary |
+
| 10 | 4400.000000 |
| 20 | 9500.000000 |
| 30 | 4150.000000 |
| . . . | . . . |
| 130 | NULL |
| 140 | NULL |
| 150 | NULL |
| 160 | NULL |
| 170 | NULL |
+
mysql> SELECT department_id, department_name, (
SELECT AVG ( salary) FROM employees AS ` sub_emp` WHERE sub_emp. department_id = main_dep. department_id
) AS ` avg_salary` FROM departments AS ` main_dep` WHERE department_id IN ( SELECT department_id FROM employees ) ;
+
| department_id | department_name | avg_salary |
+
| 10 | Administration | 4400.000000 |
| 20 | Marketing | 9500.000000 |
| 30 | Purchasing | 4150.000000 |
| 40 | Human Resources | 6500.000000 |
| 50 | Shipping | 3475.555556 |
| 60 | IT | 5760.000000 |
| 70 | Public Relations | 10000.000000 |
| 80 | Sales | 8955.882353 |
| 90 | Executive | 19333.333333 |
| 100 | Finance | 8600.000000 |
| 110 | Accounting | 10150.000000 |
+
11 rows in set ( 0.00 sec)
mysql> SELECT department_id, department_name, (
SELECT AVG ( salary) FROM employees AS ` sub_emp` WHERE sub_emp. department_id = main_dep. department_id
) AS ` avg_salary` FROM departments AS ` main_dep` WHERE department_id IN ( SELECT department_id FROM employees )
ORDER BY avg_salary
LIMIT 1 ;
+
| department_id | department_name | avg_salary |
+
| 50 | Shipping | 3475.555556 |
+
1 row in set ( 0.00 sec)
mysql> SELECT * FROM jobs;
+
| job_id | job_title | min_salary | max_salary |
+
| AC_ACCOUNT | Public Accountant | 4200 | 9000 |
| . . . | . . . | . . . | . . . |
+
mysql> SELECT job_id, AVG ( salary) FROM employees GROUP BY job_id;
+
| job_id | AVG ( salary) |
+
| AC_ACCOUNT | 8300.000000 |
| AC_MGR | 12000.000000 |
| . . . | . . . |
| SH_CLERK | 3215.000000 |
| ST_CLERK | 2785.000000 |
| ST_MAN | 7280.000000 |
+
19 rows in set ( 0.00 sec)
mysql> SELECT job_id, AVG ( salary) as ` avg_salary` FROM employees
GROUP BY job_id
ORDER BY avg_salary DESC
LIMIT 1 ;
+
| job_id | avg_salary |
+
| AD_PRES | 24000.000000 |
+
1 row in set ( 0.00 sec)
mysql> SELECT job_id FROM (
SELECT job_id, AVG ( salary) as ` avg_salary` FROM employees
GROUP BY job_id
ORDER BY avg_salary DESC
LIMIT 1
) AS ` max_salary_table` ;
+
| job_id |
+
| AD_PRES |
+
1 row in set ( 0.00 sec)
mysql> SELECT * FROM jobs
WHERE job_id = (
SELECT job_id FROM (
SELECT job_id, AVG ( salary) as ` avg_salary` FROM employees
GROUP BY job_id
ORDER BY avg_salary DESC
LIMIT 1
) AS ` max_salary_table` ) ;
+
| job_id | job_title | min_salary | max_salary |
+
| AD_PRES | President | 20000 | 40000 |
+
mysql> SELECT * , (
SELECT AVG ( salary) FROM employees AS ` sub_emp` WHERE sub_emp. job_id = main_jobs. job_id
) AS ` avg_salary` FROM jobs AS ` main_jobs` ORDER BY avg_salary DESC
LIMIT 1 ;
+
| job_id | job_title | min_salary | max_salary | avg_salary |
+
| AD_PRES | President | 20000 | 40000 | 24000.000000 |
+
1 row in set ( 0.00 sec)
mysql> SELECT AVG ( salary) AS ` avg_salary` FROM employees;
+
| avg_salary |
+
| 6461.682243 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id, AVG ( salary) FROM employees
GROUP BY department_id;
+
| department_id | AVG ( salary) |
+
| NULL | 7000.000000 |
| 10 | 4400.000000 |
| 20 | 9500.000000 |
| 90 | 19333.333333 |
| . . . | . . . |
| 110 | 10150.000000 |
+
12 rows in set ( 0.00 sec)
SELECT department_id, AVG ( salary) AS ` dep_avg_salary` FROM employees
GROUP BY department_id
HAVING dep_avg_salary > (
SELECT AVG ( salary) AS ` avg_salary` FROM employees
) ;
+
| department_id | dep_avg_salary |
+
| NULL | 7000.000000 |
| 20 | 9500.000000 |
| 40 | 6500.000000 |
| 70 | 10000.000000 |
| 80 | 8955.882353 |
| 90 | 19333.333333 |
| 100 | 8600.000000 |
| 110 | 10150.000000 |
+
8 rows in set ( 0.00 sec)
SELECT department_id, department_name FROM departments AS ` main_dep` WHERE EXISTS (
SELECT 1 FROM (
SELECT department_id, AVG ( salary) AS ` dep_avg_salary` FROM employees
GROUP BY department_id
HAVING dep_avg_salary > (
SELECT AVG ( salary) AS ` avg_salary` FROM employees
)
) AS ` sub_emp` WHERE sub_emp. department_id = main_dep. department_id
) ;
+
| department_id | department_name |
+
| 20 | Marketing |
| 40 | Human Resources |
| 70 | Public Relations |
| 80 | Sales |
| 90 | Executive |
| 100 | Finance |
| 110 | Accounting |
+
7 rows in set ( 0.00 sec)
mysql> SELECT DISTINCT manager_id FROM employees;
+
| manager_id |
+
| NULL |
| 100 |
| . . . |
| 201 |
| 205 |
+
19 rows in set ( 0.00 sec)
mysql> SELECT DISTINCT manager_id FROM employees
WHERE manager_id IS NOT NULL ;
+
| manager_id |
+
| 100 |
| . . . |
| 201 |
| 205 |
+
18 rows in set ( 0.00 sec)
mysql> SELECT employee_id, first_name, salary, manager_id FROM employees
WHERE employee_id IN (
SELECT DISTINCT manager_id FROM employees
WHERE manager_id IS NOT NULL
) ;
+
| employee_id | first_name | salary | manager_id |
+
| 100 | Steven | 24000.00 | NULL |
| 101 | Neena | 17000.00 | 100 |
| . . . | . . . | . . . | . . . |
| 103 | Alexander | 9000.00 | 102 |
| 149 | Eleni | 10500.00 | 100 |
| 201 | Michael | 13000.00 | 100 |
| 205 | Shelley | 12000.00 | 101 |
+
18 rows in set ( 0.00 sec)
SELECT employee_id, first_name, salary, manager_id
FROM employees AS ` main_emp` WHERE EXISTS (
SELECT 1 FROM employees AS ` sub_emp` WHERE sub_emp. manager_id = main_emp. employee_id
) ;
mysql> SELECT department_id, MAX ( salary) FROM employees
GROUP BY department_id;
+
| department_id | MAX ( salary) |
+
| NULL | 7000.00 |
| 10 | 4400.00 |
| . . . | . . . |
| 110 | 12000.00 |
+
12 rows in set ( 0.00 sec)
mysql> SELECT department_id, MAX ( salary) FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id;
+
| department_id | MAX ( salary) |
+
| 10 | 4400.00 |
| . . . | . . . |
| 110 | 12000.00 |
+
11 rows in set ( 0.00 sec)
mysql> SELECT department_id, MAX ( salary) AS ` max_salary` FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
ORDER BY max_salary
LIMIT 1 ;
+
| department_id | max_salary |
+
| 10 | 4400.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id FROM (
SELECT department_id, MAX ( salary) AS ` max_salary` FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
ORDER BY max_salary
LIMIT 1
) AS ` dep_id_table` ;
+
| department_id |
+
| 10 |
+
1 row in set ( 0.00 sec)
mysql> SELECT MIN ( salary) AS ` min_salary` FROM employees
WHERE department_id = (
SELECT department_id FROM (
SELECT department_id, MAX ( salary) AS ` max_salary` FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
ORDER BY max_salary
LIMIT 1
) AS ` dep_id_table` ) ;
+
| min_salary |
+
| 4400.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id, MAX ( salary) FROM employees
GROUP BY department_id;
+
| department_id | MAX ( salary) |
+
| NULL | 7000.00 |
| 10 | 4400.00 |
| . . . | . . . |
| 110 | 12000.00 |
+
12 rows in set ( 0.00 sec)
mysql> SELECT department_id, MAX ( salary) FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id;
+
| department_id | MAX ( salary) |
+
| 10 | 4400.00 |
| . . . | . . . |
| 110 | 12000.00 |
+
11 rows in set ( 0.00 sec)
mysql> SELECT department_id, MAX ( salary) AS ` max_salary` FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
ORDER BY max_salary DESC
LIMIT 1 ;
+
| department_id | max_salary |
+
| 90 | 24000.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id FROM (
SELECT department_id, MAX ( salary) AS ` max_salary` FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
ORDER BY max_salary DESC
LIMIT 1
) AS ` dep_id_table` ;
+
| department_id |
+
| 90 |
+
1 row in set ( 0.00 sec)
mysql> SELECT manager_id FROM departments
WHERE department_id = (
SELECT department_id FROM (
SELECT department_id, MAX ( salary) AS ` max_salary` FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
ORDER BY max_salary DESC
LIMIT 1
) AS ` dep_id_table` ) ;
+
| manager_id |
+
| 100 |
+
1 row in set ( 0.00 sec)
mysql> SELECT employee_id, first_name, email, salary, department_id FROM employees
WHERE employee_id = (
SELECT manager_id FROM departments
WHERE department_id = (
SELECT department_id FROM (
SELECT department_id, MAX ( salary) AS ` max_salary` FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
ORDER BY max_salary DESC
LIMIT 1
) AS ` dep_id_table` )
) ;
+
| employee_id | first_name | email | salary | department_id |
+
| 100 | Steven | SKING | 24000.00 | 90 |
+
1 row in set ( 0.00 sec)
mysql> SELECT department_id FROM employees
WHERE job_id = 'ST_CLERK' ;
+
| department_id |
+
| 50 |
| . . . |
| 50 |
+
20 rows in set ( 0.00 sec)
mysql> SELECT department_id FROM departments
WHERE department_id NOT IN (
SELECT department_id FROM employees
WHERE job_id = 'ST_CLERK'
) ;
+
| department_id |
+
| 10 |
| 20 |
| 30 |
| 40 |
| 60 |
| . . . |
+
26 rows in set ( 0.00 sec)
mysql> SELECT department_id FROM departments AS ` main_dep` WHERE NOT EXISTS (
SELECT 1 FROM employees AS ` sub_emp` WHERE job_id = 'ST_CLERK'
AND sub_emp. department_id = main_dep. department_id
) ;
+
| department_id |
+
| 10 |
| 20 |
| 30 |
| 40 |
| 60 |
| . . . |
+
26 rows in set ( 0.00 sec)
mysql> SELECT first_name FROM employees
WHERE manager_id IN (
SELECT employee_id FROM employees
) ;
+
| first_name |
+
| Neena |
| Lex |
| . . . |
| Hermann |
| Shelley |
| William |
+
106 rows in set ( 0.00 sec)
mysql> SELECT first_name FROM employees
WHERE manager_id NOT IN (
SELECT employee_id FROM employees )
OR manager_id IS NULL ;
+
| first_name |
+
| Steven |
+
1 row in set ( 0.00 sec)
mysql> SELECT first_name FROM employees AS ` main_emp` WHERE NOT EXISTS (
SELECT 1 FROM employees AS ` sub_emp` WHERE sub_emp. employee_id = main_emp. manager_id ) ;
+
| first_name |
+
| Steven |
+
1 row in set ( 0.00 sec)
mysql> SELECT employee_id FROM employees WHERE first_name = 'Lex' ;
+
| employee_id |
+
| 102 |
+
1 row in set ( 0.00 sec)
mysql> SELECT employee_id, first_name, hire_date, salary FROM employees
WHERE manager_id = (
SELECT employee_id FROM employees WHERE first_name = 'Lex'
) ;
+
| employee_id | first_name | hire_date | salary |
+
| 103 | Alexander | 1990 - 01 - 03 | 9000.00 |
+
1 row in set ( 0.00 sec)
mysql> SELECT AVG ( salary) FROM employees AS ` sub_emp` WHERE sub_emp. department_id = main_emp. department_id;
mysql> SELECT employee_id, first_name, salary FROM employees AS ` main_emp` WHERE salary > (
SELECT AVG ( salary) FROM employees AS ` sub_emp` WHERE sub_emp. department_id = main_emp. department_id
) ;
+
| employee_id | first_name | salary |
+
| 100 | Steven | 24000.00 |
| 103 | Alexander | 9000.00 |
| . . . | . . . | . . . |
| 201 | Michael | 13000.00 |
| 205 | Shelley | 12000.00 |
+
38 rows in set ( 0.01 sec)
mysql> SELECT COUNT ( * ) FROM employees AS ` sub_emp` WHERE sub_emp. department_id = main_emp. department_id;
mysql> SELECT department_name FROM departments AS ` main_emp` WHERE 5 < (
SELECT COUNT ( * ) FROM employees AS ` sub_emp` WHERE sub_emp. department_id = main_emp. department_id
) ;
+
| department_name |
+
| Purchasing |
| Shipping |
| Sales |
| Finance |
+
4 rows in set ( 0.00 sec)
mysql> SELECT location_id, COUNT ( * ) AS ` location_num` FROM departments
GROUP BY location_id;
+
| location_id | location_num |
+
| 1400 | 1 |
| 1500 | 1 |
| 1700 | 21 |
| 1800 | 1 |
| 2400 | 1 |
| 2500 | 1 |
| 2700 | 1 |
+
7 rows in set ( 0.00 sec)
mysql> SELECT location_id, COUNT ( * ) AS ` location_num` FROM departments
GROUP BY location_id
HAVING location_num > 2 ;
+
| location_id | location_num |
+
| 1700 | 21 |
+
1 row in set ( 0.00 sec)
SELECT location_id FROM (
SELECT location_id, COUNT ( * ) AS ` location_num` FROM departments
GROUP BY location_id
HAVING location_num > 2
) AS ` location_num_table` ;
+
| location_id |
+
| 1700 |
+
1 row in set ( 0.00 sec)
SELECT country_id FROM locations
WHERE location_id = (
SELECT location_id FROM (
SELECT location_id, COUNT ( * ) AS ` location_num` FROM departments
GROUP BY location_id
HAVING location_num > 2
) AS ` location_num_table` ) ;
+
| country_id |
+
| US |
+
1 row in set ( 0.00 sec)
mysql> SELECT country_id FROM locations AS ` main_loc` WHERE 2 < (
SELECT COUNT ( * ) FROM departments AS ` sub_dep` WHERE sub_dep. location_id = main_loc. location_id
) ;
+
| country_id |
+
| US |
+
1 row in set ( 0.00 sec)



























 1381
1381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









