








论文介绍:
该论文提供了一组夜间低光照短曝光数据集和长曝光数据集,并提出了一种基于U-Net的全卷积(FCN)端到端处理网络,可以直接将原始RAW图放进网络进行处理。
对于低光照图像可以增大ISO,但是随之而来噪声也会加强。论文提出的端到端网络直接对原始RAW数据进行处理,包括颜色转换、去噪、颜色插值和图像增强,避免了传统ISP Pipeline对于噪声的放大和积累。论文中低光照图像可以被放大到300倍(超过2^8),且最小化噪声对于图像影响。
传统total variation、wavelet-domain processing(小波变换域处理)、sparse coding(稀疏编码)、3D transform-domain filtering (BM3D)等算法通常是基于特定的图像先验特征,例如平滑度、稀疏性、低秩矩阵或自相似性等。
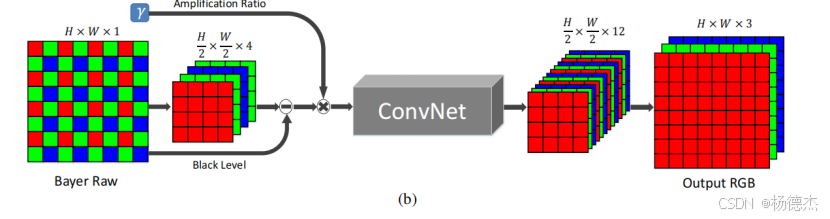
论文提出的ISP框架
首先对Bayer阵列的RAW图像拆分打包到四个通道,并减去黑电平值,根据所需要的放大比值来缩放数据,然后将该预处理的数据输入到一个全卷积网络中,输出12个通道的数据最后组合成RGB图像。
基于Pytorch的源码解读:
参考GitHub链接:https://github.com/lavi135246/pytorch-Learning-to-See-in-the-Dark.git
神经网络模型
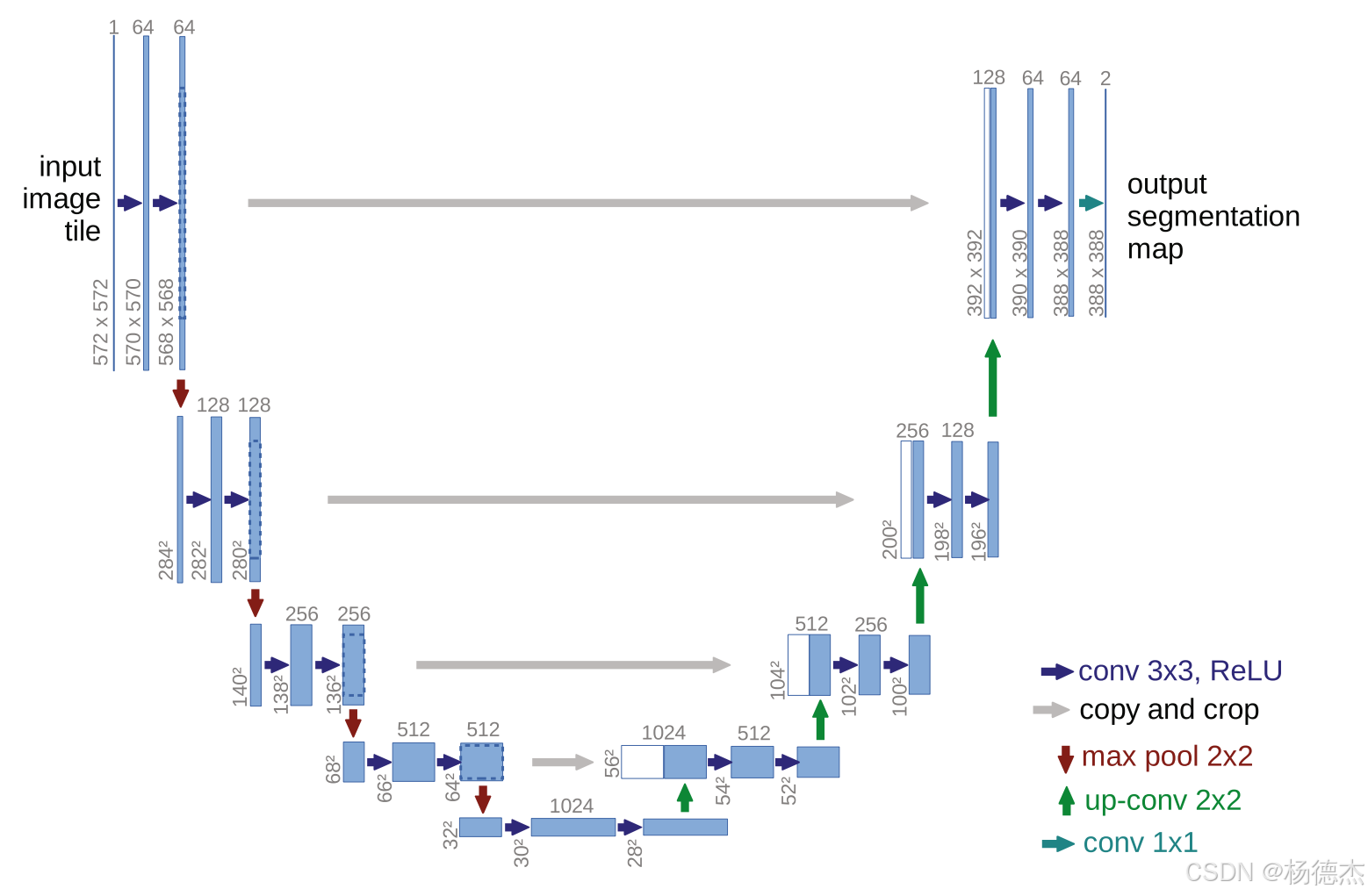
论文使用的框架为U-Net作为基础框架:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SeeInDark(nn.Module):
def __init__(self, num_classes=10):
super(SeeInDark, self).__init__()
#device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# ==================卷积下采样层 ========================================
self.conv1_1 = nn.Conv2d(4, 32, kernel_size=3, stride=1, padding=1) # 输入是4个chenel对应RGGB的拆分
self.conv1_2 = nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1) # 卷积过程:卷积核大小为3,步长为1,填充为1,尺寸不变
self.pool1 = nn.MaxPool2d(kernel_size=2) # 最大池化:通道不变,图像尺寸缩小一半
self.conv2_1 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.conv2_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.pool2 = nn.MaxPool2d(kernel_size=2)
self.conv3_1 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.conv3_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1)
self.pool3 = nn.MaxPool2d(kernel_size=2)
self.conv4_1 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)
self.conv4_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.pool4 = nn.MaxPool2d(kernel_size=2)
self.conv5_1 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
# =================以下为反卷积上采样层===================================
self.upv6 = nn.ConvTranspose2d(512, 256, 2, stride=2) # 通道数变少,尺寸增加一倍
self.conv6_1 = nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=1)
self.conv6_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.upv7 = nn.ConvTranspose2d(256, 128, 2, stride=2)
self.conv7_1 = nn.Conv2d(256, 128, kernel_size=3, stride=1, padding=1)
self.conv7_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1)
self.upv8 = nn.ConvTranspose2d(128, 64, 2, stride=2)
self.conv8_1 = nn.Conv2d(128, 64, kernel_size=3, stride=1, padding=1)
self.conv8_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.upv9 = nn.ConvTranspose2d(64, 32, 2, stride=2)
self.conv9_1 = nn.Conv2d(64, 32, kernel_size=3, stride=1, padding=1)
self.conv9_2 = nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1)
self.conv10_1 = nn.Conv2d(32, 12, kernel_size=1, stride=1) # 输出为12个通道,重组对应RGB
# 具体前向传播网络
def forward(self, x):
# =============U-Net下采样 ===================
conv1 = self.lrelu(self.conv1_1(x))
conv1 = self.lrelu(self.conv1_2(conv1))
pool1 = self.pool1(conv1)
conv2 = self.lrelu(self.conv2_1(pool1))
conv2 = self.lrelu(self.conv2_2(conv2))
pool2 = self.pool1(conv2)
conv3 = self.lrelu(self.conv3_1(pool2))
conv3 = self.lrelu(self.conv3_2(conv3))
pool3 = self.pool1(conv3)
conv4 = self.lrelu(self.conv4_1(pool3))
conv4 = self.lrelu(self.conv4_2(conv4))
pool4 = self.pool1(conv4)
conv5 = self.lrelu(self.conv5_1(pool4))
conv5 = self.lrelu(self.conv5_2(conv5))
# =============U-Net上采样 ====================
up6 = self.upv6(conv5)
up6 = torch.cat([up6, conv4], 1) # 在第一个维度上拼接:即chennel上
conv6 = self.lrelu(self.conv6_1(up6))
conv6 = self.lrelu(self.conv6_2(conv6))
up7 = self.upv7(conv6)
up7 = torch.cat([up7, conv3], 1)
conv7 = self.lrelu(self.conv7_1(up7))
conv7 = self.lrelu(self.conv7_2(conv7))
up8 = self.upv8(conv7)
up8 = torch.cat([up8, conv2], 1)
conv8 = self.lrelu(self.conv8_1(up8))
conv8 = self.lrelu(self.conv8_2(conv8))
up9 = self.upv9(conv8)
up9 = torch.cat([up9, conv1], 1)
conv9 = self.lrelu(self.conv9_1(up9))
conv9 = self.lrelu(self.conv9_2(conv9))
conv10= self.conv10_1(conv9)
# 像素洗牌操作不会增加新的信息,只是重新排列现有的信息,因此适用于需要高效上采样的场景
out = nn.functional.pixel_shuffle(conv10, 2) # 像素洗牌,高效的上采样方法,常用于超分辨率 12/(2^2)=3 ,height*2 width*2
return out
# 使用均值为0,标准差为0.02的正态分布初始化权重
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0.0, 0.02)
if m.bias is not None:
m.bias.data.normal_(0.0, 0.02)
if isinstance(m, nn.ConvTranspose2d):
m.weight.data.normal_(0.0, 0.02)
# 自定义激活函数
def lrelu(self, x):
outt = torch.max(0.2*x, x)
return outt
U-Net是高度对称的网络模型架构参考:U-Net卷积神经网络_u-net神经网络-CSDN博客
特别注意一个点:self.conv10_1这一层输出的是12通道,最后输出的时候使用了
out = nn.functional.pixel_shuffle(conv10, 2) 函数将图像重组为RGB三通道图像,将原本(H/2,W/2,12)重组为(H,W,3)
其他部分除了需要关注每层的输入输出通道以外和U-Net并无两样。
训练过程
损失函数:使用L1
迭代优化器:Adam
数据增强:对于取的每一张图像,随机裁剪一个512x512的块并随机应用翻转和转置
学习率:初始值为10^(-4),2000次epoch后减小为10^(-5),训练4000个epoch结束
import os
import time
import numpy as np
import rawpy
import glob
import torch
import torch.nn as nn
import torch.optim as optim
from PIL import Image
from model import SeeInDark
input_dir = './dataset/Sony/short/'
gt_dir = './dataset/Sony/long/'
result_dir = './result_Sony/'
model_dir = './saved_model/'
# [batch_size, channels, height, width]
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') # 训练设备
print(f"Device: {device}")
# get train and test IDs
train_fns = glob.glob(gt_dir + '0*.ARW') # 以0开头的文件名是训练数据
train_ids = []
for i in range(len(train_fns)):
_, train_fn = os.path.split(train_fns[i])
train_ids.append(int(train_fn[0:5]))
test_fns = glob.glob(gt_dir + '/1*.ARW') # 以1开头的文件名是测试数据
test_ids = []
for i in range(len(test_fns)):
_, test_fn = os.path.split(test_fns[i])
test_ids.append(int(test_fn[0:5]))
ps = 512 # patch size for training
save_freq = 500 # 设置保存图像和模型间隔
DEBUG = 0
if DEBUG == 1:
save_freq = 100
train_ids = train_ids[0:5]
test_ids = test_ids[0:5]
# 图像预处理
def pack_raw(raw):
# pack Bayer image to 4 channels
imtmp = raw.raw_image_visible.astype(np.float32)
imtmp = np.maximum(imtmp - 512, 0) / (16383 - 512) # subtract the black level
imtmp = np.expand_dims(imtmp, axis=2) # 增加维度变为(H,W,C)
img_shape = imtmp.shape
H = img_shape[0] # 行
W = img_shape[1] # 列
# 在chennel维度上进行拼接RGGB
out = np.concatenate((imtmp[0:H:2, 0:W:2, :], imtmp[0:H:2, 1:W:2, :], imtmp[1:H:2, 1:W:2, :], imtmp[1:H:2, 0:W:2, :]),axis=2)
return out
def reduce_mean(out_im, gt_im):
return torch.abs(out_im - gt_im).mean()
# Raw data takes long time to load. Keep them in memory after loaded.
gt_images = [None] * 6000
input_images = {}
# 由于输入图像只有0.1s和0.04s曝光的图像,而长曝光gt图像是10s,这里将输入图像按曝光比值作为键保存在集合中
input_images['300'] = [None] * len(train_ids)
input_images['250'] = [None] * len(train_ids)
input_images['100'] = [None] * len(train_ids)
g_loss = np.zeros((5000, 1))
allfolders = glob.glob('./result/*0')
lastepoch = 0
for folder in allfolders:
lastepoch = np.maximum(lastepoch, int(folder[-4:]))
learning_rate = 1e-4 # 设置初始学习率
model = SeeInDark().to(device) # 构建基于U-Net的网络模型
model._initialize_weights() # 初始化模型权重
opt = optim.Adam(model.parameters(), lr=learning_rate) # 创建优化器
for epoch in range(lastepoch, 4001): # 至多训练4000轮次
if os.path.isdir("result/%04d" % epoch):
continue
cnt = 0
if epoch > 2000: # 2000轮后,学习率降低为1e-5
for g in opt.param_groups:
g['lr'] = 1e-5
# 遍历随机排列的文件索引
for ind in np.random.permutation(len(train_ids)):
# get the path from image id
train_id = train_ids[ind]
in_files = glob.glob(input_dir + '%05d_00*.ARW' % train_id) # 获取特定id开头的所有图像,这里是不同曝光时长的图片
in_path = in_files[np.random.randint(0, len(in_files))] # 随机选择一张图片
_, in_fn = os.path.split(in_path) # 获取随机图片的文件名
gt_files = glob.glob(gt_dir + '%05d_00*.ARW' % train_id) # 通过id获取对应的GT图片
gt_path = gt_files[0] # 对于每个id的GT图片只有一张,获取路径和文件名
_, gt_fn = os.path.split(gt_path) # 提取出文件名
in_exposure = float(in_fn[9:-5]) # 提取从第 10 个字符到倒数第 6 个字符并转换为浮点数,表示的是曝光时长
gt_exposure = float(gt_fn[9:-5])
ratio = min(gt_exposure / in_exposure, 300) # 计算输出图像与标签之间的曝光时间比值
st = time.time()
cnt += 1
if input_images[str(ratio)[0:3]][ind] is None:
raw = rawpy.imread(in_path)
input_images[str(ratio)[0:3]][ind] = np.expand_dims(pack_raw(raw), axis=0) * ratio
gt_raw = rawpy.imread(gt_path)
# gt raw图像经过处理后成为16bit的RGB图像
im = gt_raw.postprocess(use_camera_wb=True, half_size=False, no_auto_bright=True, output_bps=16)
gt_images[ind] = np.expand_dims(np.float32(im / 65535.0), axis=0)
# crop
H = input_images[str(ratio)[0:3]][ind].shape[1]
W = input_images[str(ratio)[0:3]][ind].shape[2]
xx = np.random.randint(0, W - ps) # 在宽度方向上的随机起始位置
yy = np.random.randint(0, H - ps) # 在高度方向上的随机起始位置
# 在图像中随机裁剪521x512的块
input_patch = input_images[str(ratio)[0:3]][ind][:, yy:yy + ps, xx:xx + ps, :] # 对于RGGB图像
gt_patch = gt_images[ind][:, yy * 2:yy * 2 + ps * 2, xx * 2:xx * 2 + ps * 2, :] # 对于参考图像尺寸是输入图像大小的两倍(没有拆分通道)
# 数据增强处理:随机翻转和转置
if np.random.randint(2, size=1)[0] == 1: # 水平翻转
input_patch = np.flip(input_patch, axis=1)
gt_patch = np.flip(gt_patch, axis=1)
if np.random.randint(2, size=1)[0] == 1: # 垂直翻转
input_patch = np.flip(input_patch, axis=2)
gt_patch = np.flip(gt_patch, axis=2)
if np.random.randint(2, size=1)[0] == 1: # 转置
input_patch = np.transpose(input_patch, (0, 2, 1, 3))
gt_patch = np.transpose(gt_patch, (0, 2, 1, 3))
input_patch = np.minimum(input_patch, 1.0)
gt_patch = np.maximum(gt_patch, 0.0)
in_img = torch.from_numpy(input_patch).permute(0, 3, 1, 2).to(device) # 将输入图像转换为tensor放到GPU中
gt_img = torch.from_numpy(gt_patch).permute(0, 3, 1, 2).to(device) # 将标签转换为tensor放到GPU中
model.zero_grad() # 梯度清零
out_img = model(in_img) # 前向传播
loss = reduce_mean(out_img, gt_img) # L1 损失
loss.backward() # 反向传播
opt.step() # 更新参数
g_loss[ind] = loss.data.cpu() # 保存每一轮的损失
mean_loss = np.mean(g_loss[np.where(g_loss)]) # 计算平均损失
print(f"Epoch: {epoch} \t Count: {cnt} \t Loss={mean_loss:.3} \t Time={time.time() - st:.3}")
# 保存图像和模型
if epoch % save_freq == 0:
epoch_result_dir = result_dir + f'{epoch:04}/'
if not os.path.isdir(epoch_result_dir):
os.makedirs(epoch_result_dir)
output = out_img.permute(0, 2, 3, 1).cpu().data.numpy()
output = np.minimum(np.maximum(output, 0), 1) # 限制输出在0-1之间
temp = np.concatenate((gt_patch[0, :, :, :], output[0, :, :, :]), axis=1) # 拼接网络输出和gt
Image.fromarray((temp * 255).astype('uint8')).save(epoch_result_dir + f'{train_id:05}_00_train_{ratio}.jpg') # 保存对比图像
torch.save(model.state_dict(), model_dir + 'checkpoint_sony_e%04d.pth' % epoch) # 保存模型
模型预测:
这里我直接使用网络上训练好的模型权重,加载进去进行测试
# ===================================Modified By JAY===================================
import os
import time
import numpy as np
import rawpy
import glob
import torch
import torch.nn as nn
import torch.optim as optim
from PIL import Image
from model import SeeInDark
input_dir = './dataset/Sony/short/'
gt_dir = './dataset/Sony/Sony/long/'
m_path = './saved_model/'
m_name = 'checkpoint_sony_e4000.pth'
result_dir = './test_result_Sony/'
device = torch.device('cuda')
# device = torch.device('cuda')
def pack_raw(raw):
# pack Bayer image to 4 channels
# 16384 = 2^14
# im_tmp = np.maximum(raw - 512, 0) / (16383 - 512) # subtract the black level
im_tmp = np.maximum(raw, 0) / 4096 # 针对不同摄像头进行处理 12bit图像,假设黑电平为0
im_tmp = np.expand_dims(im_tmp, axis=2) # 增加维度变为(H,W,C)
img_shape = im_tmp.shape
H = img_shape[0]
W = img_shape[1]
# 将图像拆开为四个通道然后在第三个轴上(axis=2)拼接 RGGB
out = np.concatenate((im_tmp[0:H:2, 0:W:2, :], im_tmp[0:H:2, 1:W:2, :], im_tmp[1:H:2, 1:W:2, :], im_tmp[1:H:2, 0:W:2, :]), axis=2)
return out
model = SeeInDark() # 创建神经网络
model.load_state_dict(torch.load(m_path + m_name, map_location={'cuda:1': 'cuda:0'})) # 加载训练好的模型
model.to(device) # 将模型放到GPU上
#创建存放结果的文件夹
if not os.path.isdir(result_dir):
os.makedirs(result_dir)
# =================针对一些通用的 raw图像:内部保存了一些参数 ====
# test_file_path= "./dataset/Sony/short/00001_00_0.1s.ARW"
# raw = rawpy.imread(test_file_path) # 读取.ARW格式的图像(2848, 4256)
# im = raw.raw_image_visible.astype(np.float32) # 获取图像可见部分
# ================== 针对 纯raw二进制Bayer图像 ================
test_file_path= "./MyImage/padded_image.raw"
with open(test_file_path, "rb") as f:
raw_data = np.fromfile(f, dtype=np.uint16)
im = raw_data.reshape((2848, 4256))
im = im.astype(np.float32)
# =============================================================
ratio = 20 # 目前该参数针对不同摄像头需要进行不同调整
input_full = np.expand_dims(pack_raw(im), axis=0) * ratio # 增加一个维度(1, H, W, C)
input_full = np.minimum(input_full, 1.0) # 将值限制在[0,1]之间
# 将数据转化为tensor,并将(N, H, W, C)转成(N, C, H, W)放置在GPU上
in_img = torch.from_numpy(input_full).permute(0, 3, 1, 2).to(device)
out_img = model(in_img)
output = out_img.permute(0, 2, 3, 1).cpu().data.numpy() # 转回numpy
output = np.minimum(np.maximum(output, 0), 1) # 限制值在[0,1]之间
output = output[0, :, :, :] # 提取图像
Image.fromarray((output * 255).astype('uint8')).save(result_dir + 'test_out.png') #保存为png图像
对于提供的测试集里面图片进行测试效果非常不错,我这里在网络上随便找了一张12bit 4032x3024尺寸的图像,将其裁剪和填充成数据集里面的图片尺寸大小一致后后放入网络中得到的图片如下:

以下是该RAW图像仅经过传统ISP的Dgain、AWB、Demosaic、Gamma模块后出的效果:

可见该网络完全替代了传统的ISP Pipeline,甚至优于传统ISP。唯一不足的是ratio这个参数需要自己设置,不同的设置效果差异会有点大,由于该图像是12bit的,与所给数据集的位宽(应该是14bit)不同,因此在归一化和减去黑电平那个步骤需要简单修改一下。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









