






做web安全相关一般都会接触到子域名收集,这篇文章主要介绍如何利用python脚本进行子域名收集,当然,关于子域名收集网络上有很多现成的很好用的网站和工具。不过当你亲自动手去用python写出一个子域名收集的脚本时,你会发现......还是现成的网站好用(不是
总之这里提供几个用python脚本实现子域名收集的思路,可以python练手用,而且写出来是自己的东西用着总归有成就感一点,好不好用不知道但对写python脚本的能力应该能有一定的提高。
一、子域名爆破
子域名爆破在原理上是非常简单的,说白了就是在主域名前面加上字典里的字符串自己拼一个域名出来,然后测试能不能连接这个域名,连得上就说明这个域名是存在的。字典越强大得到的域名就越多。
首先我们有这样一个字典:

我们将字典里的字符与要查的主域名进行拼接,然后使用python的第三方库requests库来连接网站:
import requests
site = 'baidu.com' #要查询的主域名
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
"Connection": "close"
} //请求头
with open('C:/Users/11931/Desktop/domain.txt') as f: //with open 打开字典
for line in f.readlines(): #按行读取
line = line.strip() #去掉末尾的换行符号
url = 'http://'+line+'.'+site #拼接url
try:
response = requests.get(url, headers=headers, timeout=2) #尝试连接,设置超时时间
if(response.status_code==200):
print(url)
except: print("连接失败")大概结构就是这样,看运行结果可以查到对应子域名:

不过这个脚本用起来速度感人,总体不算特别使用,还有待改进,这里只是提供一种最简单的思路以供参考。
二、通过搜索引擎搜集子域名
众所周知我们可以通过类似site:域名这样的命令在百度谷歌这样的搜索网站找到对应域名的各个子域名,这里我们尝试用python查询并把结果爬下来:
主要用到requests库来连接搜索网站,beautifulsoup来解析搜索结果网页,这两都是第三方库,需要自行安装,安装教程网上很多,这里不再赘述,我们以bing搜索引擎为例:
正常搜索:

我们把网址拿出来观察:
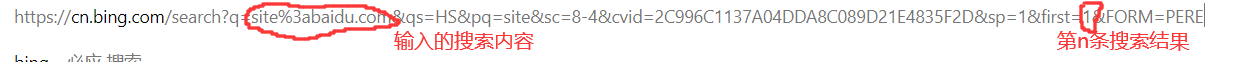
所以我们在程序里就可以把这两块扣掉,前者用来放我们要搜索的域名,后面用来控制搜索条数。然后f12找到我们要爬取的目标:

发现网关子域名都在h2标签下,所以我们可以借助beautifulsoup把h2标签里的内容找出来,再进一步从标签里找到想要的子域名,代码如下:
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
'cookie': 'MUID=32957CB67A1A615722B972087B656099'
} #请求头
site = 'baidu.com' #要爬取的子域名
n = 1 #爬取条目数
page = 2 #爬取页数
for i in range(1,page+1):
url = 'https://cn.bing.com/search?q=site%3a' + site + '&qs=HS&sc=1-0&cvid=B33D93EA99F749288C1313C7BB33BE61&sp=1&ensearch=1&first=' + str(n) + '&FORM=PERE'
print(url)
response = requests.get(url, headers=headers)
print(response.status_code)
response.encoding = 'GBK'
response.encoding = 'utf-8' #设置编码方式
soup = BeautifulSoup(response.text,'lxml') #解析网页
# print(soup.prettify())
li = soup.findAll('h2') #找到h2标签
# print(li)
for j in li:
try:
u = j.a.get('href') #找到网址
print(u) #输出
n = n+1 #条目计数+1
except: print("None")运行结果:

可以看到借助搜索引擎爬取子域名效率还是比较高的,这只是基本思路,结果中还有一些重复的,有待改进。
总之这里提供两个python爬取子域名脚本的写法以供参考,主要是试一试,帮助熟悉爬虫和简单python脚本的编写。















 647
647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









