







join 连接查询的一些问题;
对于内连接:
以下写法是等价的:
SELECT * FROM t1 JOIN t2;
SELECT * FROM t1 INNER JOIN t2;
SELECT * FROM t1 CROSS JOIN t2;
SELECT * FROM t1, t2;
由于在内连接中ON子句和WHERE子句是等价的,所以内连接中不要求强制写明ON子句。
mysql中,join 有两种算法
- NLJ( Nested-Loop Join) 嵌套循环连接
select * from t1 join t2 on t1.a=t2.a;
算法流程如下:
先从 t1(假设这里 t1 被选为驱动表)中取出一行数据 X;
从 X 中取出关联字段 a 值,去 t2 中进行(根据索引)查找,满足条件的行取出;
重复1、2步骤,直到表 t1 最后一行循环结束。
若没有索引则用到BNL 算法:
- BNL(Block Nested Loop) 块嵌套循环
BNL是从t1表中批量取出数据(查询的字段和比较字段)放入一个join buffer 缓冲区中,在批量与t2进行比对;重复上述步骤,直至t1表循环结束; 虽然BNL是批量数据操作,但没有使用索引,查询效率大不如NLJ;
在选择驱动表时,我们尽量选择小表做驱动表;BNL(小表数据少,不用多次存入join buffer 减少io)NLJ(由于被驱动表使用了索引,主要的时间花在驱动表扫描上)
所以在join连接查询时,以下操作可提高效率:
被驱动表使用索引
小表做驱动表
扩大join buffer
mysql中,join 查询,驱动表只被查询一次,被驱动表查询次数会是多次,取决于驱动表满足条件的行数;
mysql行记录会额外维护一些隐藏列:
| 列名 | 是否必须 | 占用空间 | 描述 |
|---|---|---|---|
| row_id | 否 | 6字节 | 行ID,唯一标识一条记录 |
| transaction_id | 是 | 6字节 | 事务ID |
| roll_pointer | 是 | 7字节 | 回滚指针 |
InnoDB 对主键的生成策略:
优先使用用户自定义主键作为主键,如果用户没有定义主键,则
选取一个 Unique 键作为主键,如果表中连 Unique 键都没有定义的话,则 InnoDB 会为表默认添加一个名为
row_id 的隐藏列作为主键
delete_mask :mysql 行记录删除标记位,即使delete过后,行记录可能还在磁盘中;
这些被删除的记录之所以不立即从磁盘上移除,是因为移除 它们之后把其他的记录在磁盘上重新排列需要性能消耗,所以只是打一个删除标记而已,所有被删除掉的记 录都会组成一个所谓的 垃圾链表 ,在这个链表中的记录占用的空间称之为所谓的 可重用空间 ,之后如果有 新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉。
InnoDB 数据存储格式

数据页通过双向链表连接,数据页中各行数据通过单向链表(按照主键从小到大)连接,并且在数据页中会生成一个数据页目录,数据页目录会将数据分组,并记录每组的最大主键记录,和该组的行数;通过主键查找时,可访问数据页目录,利用二分查找的方式,快速定位数据所在的组,每组最多8行数据,所以查询代价小;一个数据页默认16KB;
以上查找是通过主键,但若查询条件不是主键列,则需要一行一行遍历数据;而且根据主键只能定位所在的分组,不能定位所在的数据页,(数据页在逻辑上连续,在物理上不连续)
数据页在逻辑上连续,并不是数据连续,也就是数据页a 和数据页b的数据没有任何规律;
那么我们可不可以给数据页也建立一个目录,当然可以,这个目录就是我们的index
在插入数据页只保证了数据页内部的有序(主键从小到大),数据页之间的有序需要通过页分裂来完成,也就说下图的数据页是通过调整得到的;
那么通过主键建立的索引,称主键索引;
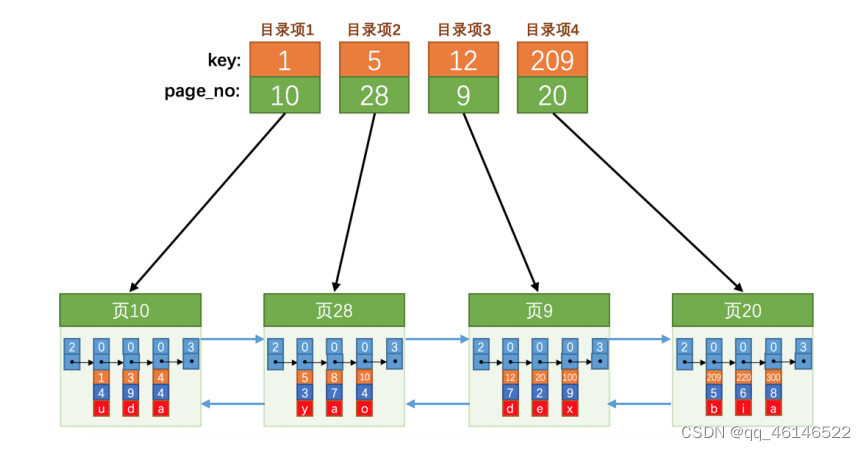
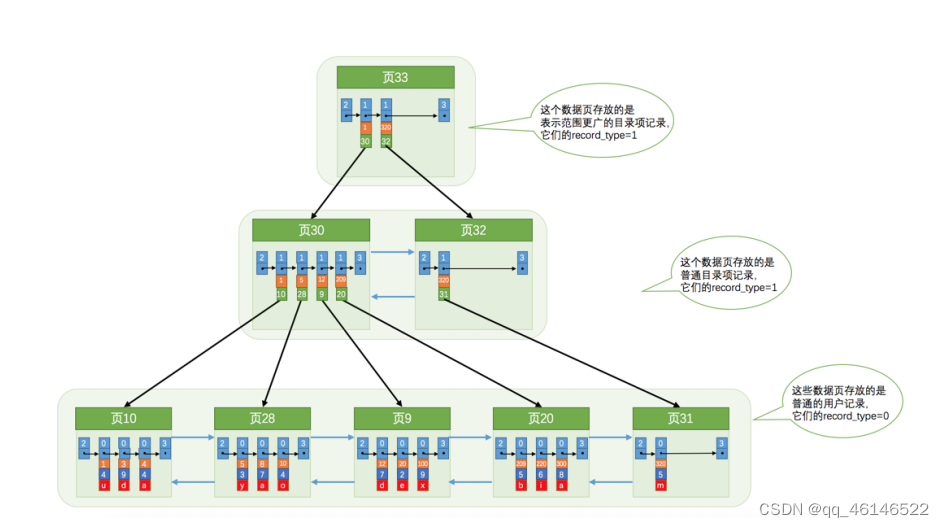
在InnoDB 中,索引目录项也存放在数据页中,当数据量太多时,一个数据页存不下索引目录项时,咋办?
采用B+树存储:
[外链图片转存中…(img-5vQ5SPGQ-1662607518068)]














 1062
1062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









