









一、语言篇
01.C语言基础
01.static关键字作用
控制变量和函数的生命周期、限制作用域、实现文件内的私有性以及定义类的静态成员。
1.函数内的静态变量:在函数内部定义的变量可以使用 static 修饰符进行声明,使其成为静态变量。静态变量的生命周期延长到整个程序运行期间,而不是只在函数调用时存在。
void test()
{
static int i = 0;//对于static修饰的变量,如果未初始化默认为0
//static int i=0; static int i;int i;三种结果一致
//但是对于int i=0;结果全为0
printf("%d ", i);
i++;
}
int main(int argc, char *argv[])
{
for (int i = 0; i < 5; i++)
{
test();
}
printf("\n");
return 0;
}
//输出 0 1 2 3 42.文件内的静态变量和函数:在文件中定义的变量和函数可以使用 static 修饰符进行声明,使其成为文件内的私有变量或函数,限制外部链接性。被 static 修饰的变量或函数只能在当前文件内访问,无法被其他文件引用。
3.类的静态成员变量和静态成员函数:在类中定义的静态成员变量和静态成员函数属于整个类,而不是类对象的一部分。静态成员变量只有一个副本,被所有类对象共享;静态成员函数可以直接通过类名访问,而无需创建类对象。
#include <iostream>
class MyClass {
public:
static int count; // 静态成员变量
int id;
MyClass() {
count++; // 在构造函数中对静态成员变量进行自增操作
id = count;
}
static void printCount() { // 静态成员函数
std::cout << "Total objects created: " << count << std::endl;
}
};
int MyClass::count = 0; // 静态成员变量的定义和初始化
int main() {
MyClass obj1;
MyClass obj2;
MyClass obj3;
MyClass::printCount(); // 直接通过类名调用静态成员函数
return 0;
}
//输出结果为: Total objects created: 3 02.extern
extern 关键字在 C 和 C++ 中有不同的用法和作用。
在 C 中,extern 关键字用于声明一个全局变量或函数,表示该变量或函数是在其他文件中定义的。通过使用 extern 关键字,可以在当前文件中引用其他文件中定义的全局变量或函数。
示例: 假设我们有两个文件:main.c 和 utils.c。
utils.c 文件中定义了一个全局变量 int globalVar = 10;,以及一个函数 void utilsFunc();。
现在我们想在 main.c 文件中使用 globalVar 和 utilsFunc(),那么可以在 main.c 文件中使用 extern 关键字进行声明:
// main.c
extern int globalVar;
extern void utilsFunc();
int main() {
utilsFunc(); // 调用 utilsFunc 函数
printf("Global variable: %d\n", globalVar); // 使用 globalVar 变量
return 0;
}这样,在 main.c 文件中就能够引用 utils.c 文件中定义的全局变量和函数。
在 C++ 中,extern 关键字的用法与 C 中类似,但还可以用于声明外部链接的变量和函数,以及显式实例化模板。
示例:
// utils.cpp
int globalVar = 10;
void utilsFunc() {
// 函数实现
}
// main.cpp
extern int globalVar;
extern void utilsFunc();
int main() {
utilsFunc(); // 调用 utilsFunc 函数
cout << "Global variable: " << globalVar << endl; // 使用 globalVar 变量
return 0;
}在这个示例中,我们使用 extern 关键字声明了 globalVar 和 utilsFunc(),使得在 main.cpp 文件中可以引用 utils.cpp 文件中定义的全局变量和函数。
总结一下,extern 关键字的作用是在当前文件中声明一个全局变量或函数,表明它是在其他文件中定义的。通过使用 extern 关键字,可以在当前文件中引用其他文件中定义的全局变量或函数。
03.extern "C"
extern "C" 是一个用于 C++ 中的关键字,用于指示编译器按照 C 语言的约定进行函数的命名和调用约定,实现类C和C++的混合编程。在C++源文件中的语句前面加上extern "C",表明它按照类C的编译和连接规约来编译和连接,而不是C++的编译的连接规约。这样在类C
在 C 中,函数的名称和参数列表会经过一种称为名称修饰(name mangling)的过程,以支持函数重载和其他特性。这使得 C 函数无法直接与 C 语言中的函数进行链接。
使用 extern "C" 关键字可以告诉编译器将某个函数的链接规范设置为 C 语言的规范,从而使得该函数能够与 C 语言代码进行兼容。
示例:
// C++ 源文件
#include <iostream>
extern "C" {
void func(); // 使用 extern "C" 关键字声明函数
}
void func() {
std::cout << "Hello from C++!" << std::endl;
}
int main() {
func(); // 调用 func 函数
return 0;
}在上面的示例中,我们在 C++ 源文件中使用 extern "C" 关键字声明了一个函数 func()。此时编译器会按照 C 语言的函数命名和调用约定来处理该函数。
这样,在 C++ 中定义的函数 func() 就可以被其他使用 C 语言编写的代码所链接和调用。
需要注意的是,extern "C" 只适用于函数的声明,而不适用于函数的定义。因此,我们通常将 extern "C" 的声明放在头文件中,并将函数的定义放在源文件中。
04.const关键字
1.修饰局部变量 用const修饰变量时,一定要给变脸初始化,否则之后就不能再进行赋值了。
2.常量指针与指针常量(const 后面的整体不能变)
a.常量指针:指针指向的内容是常量。
const int *p
int const *p
#include<stdio.h>
int main()
{
int a=5,b=10;
const int*p=&a;
//*p=20;//错误,不能通过这个指针改变变量的值
a=20;
printf("%p %d\n",p,*p);//0x7ffe6f512b98 20
p=&b;//常量指针指向的值不能改变,但是常量指针可以指向其他的地址
printf("%p %d\n",p,*p);//0x7ffe6f512b9c 10
return 0;
}b.指针常量:是指指针本身是个常量,不能在指向其他的地址
int* const p需要注意的是,指针常量指向的地址不能改变,但是地址中保存的数值是可以改变的,可以通过其他指向改地址的指针来修改。
int a=5;
int* const p=&a;
a=6;c.指向常量的常指针
是以上两种的结合,指针指向的位置不能改变并且也不能通过这个指针改变变量的值,但是依然可以通过其他的普通指针改变变量的值。
const int* const p3.修饰函数参数
1、防止修改指针指向的内容
void strcpy(char *strDestination, const char *strSource);其中 strSource 是输入参数,strDestination 是输出参数。给 strSource 加上 const 修饰后,如果函数体内的语句试图改动 strSource 的内容,编译器将指出错误。
2、防止修改指针指向的地址
void swap ( int * const p1 , int * const p2 )指针p1和指针p2指向的地址都不能修改。
4.修饰函数返回值
如果给以“指针传递”方式的函数返回值加 const 修饰,那么函数返回值(即指针)的内容不能被修改,该返回值只能被赋给加const 修饰的同类型指针。
const char * GetString(void);
如下语句将出现编译错误:
char *str = GetString();
正确的用法是
const char *str = GetString();05.const与define区别
-
#define 宏是在预处理阶段展开; const 常量是编译运行阶段使用。
-
#define 宏没有类型,不做任何类型检查,仅仅是展开。const 常量有具体的类型,在编译阶段会执行类型检查。
-
宏定义不分配内存,变量定义分配内存。const 常量会在内存中分配(可以是堆中也可以是栈中)。
-
const 可以节省空间,避免不必要的内存分配。 例如:
#define NUM 3.14159 //常量宏
const doulbe Num = 3.14159; //此时并未将Pi放入ROM中 ......
double i = num; //此时为Pi分配内存,以后不再分配!
double I = NUM; //编译期间进行宏替换,分配内存
double j = num; //没有内存分配
double J = NUM; //再进行宏替换,又一次分配内存!(5)宏替换只作替换,不做计算,不做表达式求解。
06.voliate
voliate的作用是作为指令关键字,用voliate 声明的变量表示该变量随时可能发生变化(因为编译器优化时可能将其放入寄存器中)告诉编译器不做任何优化,每次从内存中直接读取值,而不是使用寄存器中的副本 因为访问寄存器要比访问内存单元快的多,所以编译器一般都会作减少存取内存的优化,但有可能会读脏数据。当要求使用volatile声明变量值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。
主要用途:
-
多任务环境下各任务间共享的标志:在多线程程序中,某些变量可能会被多个线程同时访问和修改,为了确保变量的可见性和一致性,可以使用
volatile关键字修饰这些变量。 -
中断处理:当一个变量在断服务程序中被修改,而在程序的其它位置被检测,就需要考虑加volatile
-
读硬件寄存器时(如某传感器的端口/裸机程序编写时)并行设备的硬件寄存器。存储器映射的硬件寄存器通常加volatile,因为寄存器随时可以被外设硬件修改。当声明指向设备寄存器的指针时一定要用volatile,告诉编译器不要对存储在这个地址的数据进行假设。
07.手写str相关函数
-
strlen用于计算字符串的长度,即该字符串中非空字符的个数,不包括结尾符号\0。int strlen(const char*str){ if(str==NULL)return NULL; int len=0; while ((*str)!='\0') { len++; str++; } return len; } -
strcpy用于将一个字符串复制到另一个字符串中。char *strcpy(char *dest, const char *src){ assert(dest&&src); char*ret=dest;//用于保存目标字符串的起始位置,并将其作为最终的返回值。 while((*dest++=*src++)!='\0'); return ret; } -
strcat用于将源字符串追加到目标字符串的末尾。char *strcat(char *dest, const char *src){ assert(dest&&src); char*ret=dest; while((*dest++)!='\0'); dest--; while ((*dest++=*src++)!='\0'); return ret; } -
strcmp函数在C语言中是用来比较两个字符串的函数int strcmp(const char *str1, const char *str2){ assert(str1&&str2); int ret=0; while(*str1==*str2){ if(*str1=='\0') return 0; str1++; str2++; } ret=*str1-*str2; if(ret>0)return 1; else if(ret<0)return -1; return 0; } -
strstr用于在一个字符串中查找另一个字符串。
08.malloc/calloc/realloc/mem*
//在堆区上申请size大小的空间,返回堆区上这个空间的起始地址,开辟失败会返回一个空指针
void* malloc (size_t size);//并不会对内存进行初始化,所以它分配的内存块中的内容是未定义的(即垃圾值)
//在堆区上申请num个size大小的空间,返回堆区上这个空间的起始地址,并且把所有元素初始化成0
void* calloc (size_t num, size_t size);
//调整动态内存空间大小,返回值为调整之后的内存起始位置
void* realloc (void* ptr, size_t size);在 C 语言中,有四个常用的内存操作函数,它们分别是:
-
memcpy():用于在内存块之间进行复制。它的原型如下:void* memcpy(void* dest, const void* src, size_t n);其中
dest是目标内存块的指针,src是源内存块的指针,n是要复制的字节数。该函数将从源内存块复制n字节的数据到目标内存块中。 -
memset():用于在内存块中设置指定值。它的原型如下:void* memset(void* ptr, int value, size_t n);其中
ptr是要设置值的内存块的指针,value是要设置的值(通常是一个无符号字符),n是要设置的字节数。该函数将内存块的前n个字节设置为指定值。 -
memcmp():用于比较两个内存块的内容。它的原型如下:int memcmp(const void* ptr1, const void* ptr2, size_t n);其中
ptr1和ptr2分别是要比较的两个内存块的指针,n是要比较的字节数。该函数按字节比较两个内存块的内容,如果两个内存块相等,则返回 0;如果ptr1指向的内容小于ptr2指向的内容,则返回一个负值;如果ptr1指向的内容大于ptr2指向的内容,则返回一个正值。 -
memmove():与memcpy()类似,也用于在内存块之间进行复制,但memmove()能够处理重叠的内存块。它的原型如下:void* memmove(void* dest, const void* src, size_t n);其中
dest是目标内存块的指针,src是源内存块的指针,n是要复制的字节数。与memcpy()不同的是,memmove()能够处理源内存块和目标内存块重叠的情况,因此更加安全。
09.手写atoi()和atof()
-
atoi()将字符串转换成一个 32 位有符号整数,atoi()会扫描参数字符串,跳过前面的空格字符,直到遇上数字或正负号才开始做转换,而再遇到非数字或字符串时(“0”)才结束转化,并将结果返回(返回转换后的整型数)int atoi(char* str) { assert(str); while (*str == ' ') { str++; //跳过字符串开头的空格字符 } long long ans = 0; int sign = 1; if (*str == '-') { sign = -1; str++; } else if (*str == '+') { str++; } while (*str >= '0' && *str <= '9') { ans = ans * 10 + sign * (*str - '0'); str++; if (ans > 0 && ans > INT_MAX) ans = INT_MAX;//2147483647 else if (ans < 0 && ans < INT_MIN) ans = INT_MIN;//-2147483648 } return ans; } -
atof函数用于将字符串转换为对应的浮点数。
10.宏定义
-
用宏来实现比较两个值的大小并返回较小值
#define MIN(a, b) ((a) < (b) ? (a) : (b))-
写一个宏定义,不用中间变量,实现两变量的交换
#define swap(a,b) a+=b;b=a-b;a=a-b;
#define swap(a,b) a=a^b;b=a^b;a=a^b;//连续跟同一个数异或两次则得到它本身-
C语言自定义寄存器操作
//寄存器地址的定义
#define UART_BASE_ADRS (0x10000000) /* 串口的基地址 */
#define UART_RHR *(volatile unsigned char *)(UART_BASE_ADRS + 0) /* 数据接受寄存器 */
#define UART_THR *(volatile unsigned char *)(UART_BASE_ADRS + 0) /* 数据发送寄存器 */
//寄存器读写操作
UART_THR = ch; /* 发送数据 */
ch = UART_RHR; /* 接收数据 */
#define WRITE_REG(addr, ch) *(volatile unsigned char *)(addr) = ch
#define READ_REG(addr, ch) ch = *(volatile unsigned char *)(addr)11.定义和声明
变量的声明和定义: 声明是仅仅告诉编译器,有个某类型的变量会被使用,但是编译器并不会为它分配任何内存。而定义就是分配了内存。 函数的声明和定义:声明一般在头文件里,对编译器说:这里我有一个函数叫function() 让编译器知道这个函数的存在。定义:一般在源文件里,具体就是函数的实现过程写明函数体。
-
变量和函数未声明的错误产生于编译阶段,编译阶段检查的是语法错误
-
变量和函数未定义的错误产生于链接阶段,链接阶段关心的是怎么实现
12.位操作
-
指定位反转
#define REVERSE_BIT(num, pos) ((num) ^ (1 << (pos)))
//用于反转给定数字 num 的第 pos 位。
//和0异或等于本身,和1异或等于取反
unsigned int reverse_bit(unsigned int num, int pos) {
return num ^ (1 << pos);//具体实现是将 1 左移 pos 位,然后与 num 进行异或操作,即可实现指定位的反转。
}-
指定位清零
unsigned int clear_bit(unsigned int num, int pos) {
return num & ~(1 << pos);
}-
提取某一位
unsigned int get_bit(unsigned int num, int pos) { return (num & (1 << pos)) >> pos; } -
一个整数的每个比特是0还是1
void checkBits(int num) { for (int i = 31; i >= 0; i--) { int bit = (num >> i) & 1; printf("%d", bit); } printf("\n"); } -
指定位置1
unsigned int set_bit(unsigned int num, int pos) {
return num | (1 << pos);
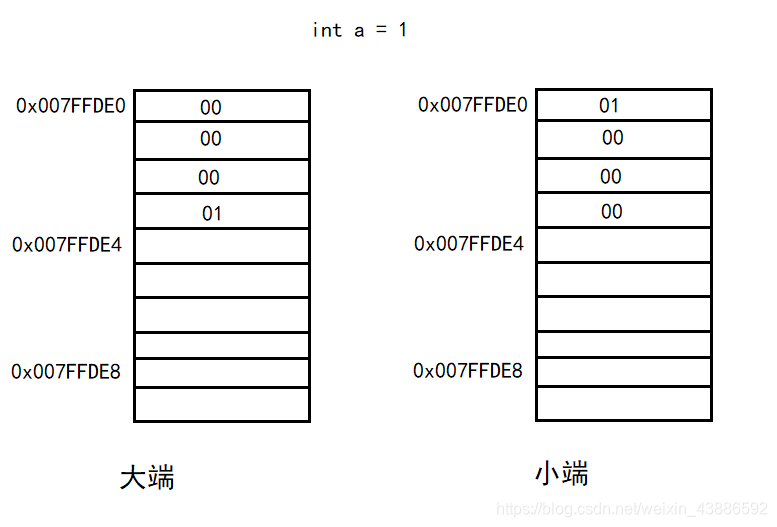
}13.大小端
大端存储模式:数据的低位保存在内存中的高地址中,数据的高位保存在内存中的低地址中; 小端存储模式:数据的低位保存在内存中的低地址中,数据的高位保存在内存中的高地址中;
14.如何判断大小端存储
使用字节
int check_endianness() {
int n=0x11223344;
char a=n;
// 如果最低地址存放的是最低有效位,则为小端存储
if (a==68) {
return 1; // 小端存储
} else {
return 0; // 大端存储
}
}使用指针,类型强转
#include <stdio.h>
int check_endianness() {
unsigned int num = 1;
char *ptr = (char *)#
// 如果最低地址存放的是最低有效位,则为小端存储
if (*ptr) {
return 1; // 小端存储
} else {
return 0; // 大端存储
}
}使用union
#include <stdio.h>
//联合体变量中的成员是共用一个首地址,共占同一段内存空间,所以在任意时刻只能存放其中一个成员的值。
union {
int i;
char c;
} test;
int main() {
test.i = 1;
if (test.c == 1) {
printf("This system is little endian.\n");
} else {
printf("This system is big endian.\n");
}
return 0;
}15.函数栈帧
C语言之函数栈帧(动图详解)_函数调用栈帧过程(带图详解)-CSDN博客
CPU眼里的:{函数括号} | 栈帧 | 堆栈 | 栈变量哔哩哔哩bilibili
1.函数正式调用(call)前会进行形参实例化,分配存储空间,形参实例化的顺序是从右向左。
2.临时空间的开辟,是在对应函数栈帧的内部通过mov命令的方式开辟的。
3.函数调用完毕,栈帧结构被释放。
4.临时变量具有临时性的本质是:栈帧具有临时性。
5.调动函数是有成本的,体现在时间和空间上,本质是形成和释放栈帧有成本。
6.函数调用,因拷贝而形成的临时变量,变量和变量之间的位置关系是有规律的。
7.函数的栈帧是自己形成的,esp减多少是由编译器决定的。即栈帧的大小是由编译器决定的。编译器有能力知道所有类型对应定义变量的大小。
1.相关寄存器 eax 通用寄存器,保存临时数据,常用于返回值 ebx 通用寄存器,保存临时数据 ebp 栈底寄存器 esp 栈顶寄存器 eip 指令寄存器,保存当前指令的下一条指令的地址
2.部分汇编指令 push 数据入栈,同时esp栈顶寄存器也要发生改变 pop 数据弹出至指定位置,同时esp栈顶寄存器也要发生改变 call 函数调用,1.压入返回地址 2.转入目标函数 jump 通过修改eip,转入目标函数,进行调用 ret 恢复返回地址,压入eip,类似于pop eip指令
16.递归
函数递归指的是在函数内部调用自身的过程。
递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因
优缺点:
-
简洁性:递归可以用较少的代码实现复杂的功能
-
灵活性:递归可以应对未知深度的数据结构,因为它不需要提前知道要处理的嵌套层级
-
栈溢出:如果递归深度过大或者没有正确的终止条件,递归函数可能会导致栈溢出,从而导致程序崩溃。
-
隐式堆栈:递归调用会创建隐式的函数调用堆栈,其中保存了每个递归调用的状态。如果递归层数很深,堆栈可能会占用大量内存空间,从而增加程序的内存消耗。
17.strlen和sizeof
-
sizeof 是C 语言的一种单目运算符,sizeof以字节的形式给出操作数的存储空间的大小,在字符数组中会统计‘\0’所占空间,sizeof 也可以对一个函数调用求值,其结果是函数返回类型的大小。sizeof不能计算动态分配空间的大小。对于整数常量,如
sizeof(1),它并不是表示 1 的大小,而是表示 1 所属的数据类型的大小。 -
strlen 是一个库函数。strlen 计算的是字符串的长度。
int main()
{
char arr[] = "123456789";
printf("%ld\n", strlen(arr));//9
printf("%ld\n", sizeof(arr));//10
//因为不是字符串,所以末尾没有\0;没有\0,当使用strlen函数进行计算是就不知道在哪里结束;计算结果就是我们想不到的随机值(
char arr1[] = {'1','2','3','4','5','6','7','8','9'};
printf("%ld\n", strlen(arr1));//18
printf("%ld\n", sizeof(arr1));//9
printf("%ld\n", sizeof(1)); //4
printf("%ld\n", sizeof(1.1)); //8
return 0;
}18.字符串库函数
-
sprintf//sprintf() 函数会根据 format 字符串中的格式说明符,将可变参数列表中的数据转换为字符串,并将结果写入到 str 指向的字符串中。 返回值:字符串长度 int sprintf(char *str, const char *format, ...); int main() { char buffer[50] = ""; // 存储输出字符串的缓冲区 int value = 255; float floatValue = 3.14; // Integer: 123, Float: 3.14 sprintf(buffer, "Integer: %d, Float: %.2f", value, floatValue); // 打印输出的字符串 printf("%s\n", buffer); sprintf(buffer, "Hex value:%x,%X,%4X,%04X", value,value,255,255); // 输出为 "Hex value:ff,FF, FF,00FF" printf("%s\n", buffer); return 0; } -
sscanf//用于按照指定的格式从字符串中读取数据并存储到变量中 int sscanf(const char *str, const char *format, ...); #include <stdio.h> #include <string.h> int main() { char str[] = "$AZCT,P,ACQU,38.77V,45.05mA,120.02GB*hh"; char header[10] = "", tail[10] = "", state[10] = ""; float voltage = 0, current = 0, memory_free = 0; /* %[^,]:表示提取一个不包含逗号的字符串,直到遇到逗号为止。逗号是作为分隔符来使用的。 %*[^,]:表示跳过一个不包含逗号的字符串,即不保存其值。*/ sscanf(str, "%[^,],P,%[^,],%fV,%fmA,%fGB%s", header, state, &voltage, ¤t, &memory_free, tail); return 0; } -
strchr//strchr() 函数用于在字符串中查找指定字符的第一次出现的位置,并返回该字符在字符串中的地址。如果找到了指定字符,则返回该字符的地址;如果没有找到,则返回 NULL。 char *strchr(const char *str, int c); -
strtok//strtok() 函数用于将字符串分割成一个个标记(token)。该函数会在字符串中找到指定的分隔符(delimiter)出现的位置,并将字符串分割成两部分,返回第一个分割出来的标记,并在内部维护一个静态指针指向剩余的未处理部分。 //delim为分隔符字符(如果传入字符串,则传入的字符串中每个字符均为分割符) char *strtok(char *str, const char *delim); #include <stdio.h> #include <string.h> int main() { char str[] = "Hello,world;how-are:you"; char *token; const char *delim = ",;-:"; // 字符串形式的分隔符,包含多个字符 // 第一次调用 strtok(),传入待分割的字符串 token = strtok(str, delim); // 循环调用 strtok() 获取分割出的标记,直到返回 NULL while (token != NULL) { printf("Token: %s\n", token); // 继续调用 strtok(),传入 NULL,获取下一个分割出的标记 token = strtok(NULL, delim); } return 0; }
-
ato*//将字符串转换为整数 int atoi(const char *str); //将字符串转换为长整型整数(long类型) long atol(const char* nptr); //将字符串转换为长长整型整数(long long类型) long long atoll(const char* nptr); //将字符串转换为浮点数(float类型) double atof(const char *nptr);
19.malloc底层实现原理
malloc 背后的虚拟内存 和 malloc实现原理-CSDN博客
malloc申请内存,当申请内存小于128K则由brk分配,大于128K,mmap系统调用,不在推_edata指针,并且可以直接free,完成单独释放。
-
malloc_init()初始化:将分配程序标识为已经初始化,
sbrk找到操作系统中最后一个有效的内存地址,然后建立起指向需要管理的内存的指针 -
内存块结构
typedef struct s_block *t_block; struct s_block { size_t size; /* 数据区大小 */ t_block next; /* 指向下个块的指针 */ int free; /* 是否是空闲块 */ int padding; /* 填充4字节,保证meta块长度为8的倍数 */ char data[1] /* 这是一个虚拟字段,表示数据块的第一个字节,长度不应计入meta */ }; //为了完全地管理内存,我们需要能够追踪要分配和回收哪些内存,malloc 返回的每块内存的起始处首先要有这个结构: struct mem_control_block { int is_available; // 是否空闲 int size; // 内存块大小 }; -
获取内存块:所要申请的内存是由多个内存块构成的链表。如何在block链中查找合适的block
-
First fit:从头开始,使用第一个数据区大小大于要求size的块所谓此次分配的块
-
Best fit:从头开始,遍历所有块,使用数据区大小大于size且差值最小的块作为此次分配的块
-
如果现有block都不能满足size的要求,则需要在链表最后开辟一个新的block
-
-
程序需要内存时,malloc() 首先遍历空闲区域,看是否有大小合适的内存块,如果有,就分配,如果没有,就向操作系统申请(发生系统调用)。为了保证分配给程序的内存的连续性,malloc() 只会在一个空闲区域中分配,而不能将多个空闲区域联合起来。
-
malloc() 和 free() 所做的工作主要是对已有内存块的分拆和合并,并没有频繁地向操作系统申请内存,这大大提高了内存分配的效率。
-
进程第一次读写malloc分配的内存时候,发生缺页中断,这个时候,内核才分配这块内存对应的物理页。也就是说,如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。
void *malloc(long numbytes)
{
void *current_location;
struct mem_control_block *current_location_mcb;
void *memory_location;
/*1:将分配程序标识为已经初始化,找到操作系统中最后一个有效的内存地址,然后建立起指向需要管理的内存的指针*/
if (!has_initialized)
{
malloc_init();
}
numbytes = numbytes + sizeof(struct mem_control_block);
memory_location = 0;
current_location = managed_memory_start;
while (current_location ! = last_valid_address)
{
current_location_mcb = (struct mem_control_block *)current_location;
if (current_location_mcb->is_available)
{
if (current_location_mcb->size >= numbytes)
{
current_location_mcb->is_available = 0;
memory_location = current_location;
break;
}
}
current_location = current_location + current_location_mcb->size;
}
if (!memory_location)
{
sbrk(numbytes);
memory_location = last_valid_address;
last_valid_address = last_valid_address + numbytes;
current_location_mcb = memory_location;
current_location_mcb->is_available = 0;
current_location_mcb->size = numbytes;
}
memory_location = memory_location + sizeof(struct mem_control_block);
return memory_location;
}20.内存碎片
02.内存分配
01.C内存分区
C代码经过预处理、编译、汇编、链接4步后生成一个二进制可执行程序。
在没有运行程序前,也就是说程序没有加载到内存前,可执行程序内部已经分好3段信息,分别为代码区(text)、数据区(data)和未初始化数据区(bss)3 个部分(有些人直接把 data 和 bss 合起来叫做静态区或全局区)。
-
代码区(text segment)
加载的是可执行文件代码段,所有的可执行代码都加载到代码区,这块内存是不可以在运行期间修改的。
-
未初始化数据区(BSS)
加载的是可执行文件BSS段,位置可以分开亦可以紧靠数据段,存储于数据段的数据(全局未初始化,静态未初始化数据)的生存周期为整个程序运行过程。
-
已初始化数据区(data segment)
加载的是可执行文件数据段,存储于数据段(全局初始化,静态初始化数据,文字常量(只读))的数据的生存周期为整个程序运行过程。
-
栈区(stack)
栈是一种
先进后出的内存结构,由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。 -
堆区(heap)
堆是一个大容器,它的容量要远远大于栈,但没有栈那样先进后出的顺序。用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收。
类型 作用域 生命周期 存储位置 局部变量 一对{}内 当前函数 栈区 static局部变量 一对{}内 整个程序运行期 初始化在data段,未初始化在BSS段 extern变量 整个程序 整个程序运行期 初始化在data段,未初始化在BSS段 static全局变量 当前文件 整个程序运行期 初始化在data段,未初始化在BSS段 extern函数 整个程序 整个程序运行期 代码区 static函数 当前文件 整个程序运行期 代码区 register变量 一对{}内 当前函数 运行时存储在CPU寄存器 字符串常量 当前文件 整个程序运行期 data段
02.堆与栈的区别
堆与栈实际上是操作系统对进程占用的内存空间的两种管理方式,主要有如下几种区别:
(1)管理方式不同。
栈由操作系统自动分配释放,用于存放函数的参数值、局部变量等,无需我们手动控制;堆的申请和释放工作由程序员控制,容易产生内存泄漏;
(2)空间大小不同。
每个进程拥有的栈大小要远远小于堆大小。理论上,进程可申请的堆大小为虚拟内存大小,对于 x86 和 x64 计算机,默认堆栈大小为 1 MB。在 Itanium 芯片组上,默认大小为 4 MB。linux下默认的堆栈空间大小是8M或10M,不同的发行版本可能不太一样。可以使用ulimit指令查看栈空间大小,指令ulimit -s或者ulimit -a:
(3)生长方向不同。
堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
(4)分配方式不同。
堆都是动态分配的,没有静态分配的堆。栈有 2 种分配方式:静态分配和动态分配。静态分配是由操作系统完成的,比如局部变量的分配。动态分配由alloca()函数分配,但是栈的动态分配和堆是不同的,它的动态分配是由操作系统进行释放,无需我们手工实现。
(5)分配效率不同。
栈由操作系统自动分配,会在硬件层级对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是由C/C++提供的库函数或运算符来完成申请与管理,实现机制较为复杂,频繁的内存申请容易产生内存碎片。显然,堆的效率比栈要低得多。
(6)存放内容不同。
栈存放的内容,函数返回地址、相关参数、局部变量和寄存器内容等。当主函数调用另外一个函数的时候,要对当前函数执行断点进行保存,需要使用栈来实现,首先入栈的是主函数下一条语句的地址,即扩展指针寄存器的内容(EIP),然后是当前栈帧的底部地址,即扩展基址指针寄存器内容(EBP),再然后是被调函数的实参等,一般情况下是按照从右向左的顺序入栈,之后是被调函数的局部变量,注意静态变量是存放在数据段或者 BSS 段,是不入栈的。出栈的顺序正好相反,最终栈顶指向主函数下一条语句的地址,主程序又从该地址开始执行。堆,一般情况堆顶使用一个字节的空间来存放堆的大小,而堆中具体存放内容是由程序员来填充的。
堆和栈相比,由于大量 malloc()/free() 或 new/delete 的使用,容易造成大量的内存碎片,并且可能引发用户态和核心态的切换,效率较低。栈相比于堆,在程序中应用较为广泛,最常见的是函数的调用过程由栈来实现,函数返回地址、EBP、实参和局部变量都采用栈的方式存放。虽然栈有众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,主要还是用堆。
无论是堆还是栈,在内存使用时都要防止非法越界,越界导致的非法内存访问可能会摧毁程序的堆、栈数据,轻则导致程序运行处于不确定状态,获取不到预期结果,重则导致程序异常崩溃,这些都是我们编程时与内存打交道时应该注意的问题。
03.在局部数组中定义一个大数组可以吗?很大的数组,比如2048
不可以,会爆栈,栈溢出 在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,例如,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数,在VC6下面,默认的栈空间大小是1M。当然,这个值可以修改。如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从获得的空间较小。 局部数组,具有局部作用域,当函数调用结束之后,数组也就被操作系统销毁了,即回收了他的内存空间
解决方法,(解决局部大数组爆栈和局部作用域的问题)
-
定义成全局数组
-
加static放在静态存储区
-
数组用malloc申请空间放在堆区定义一个指针指向这个数组,栈中只占用一个指针的大小
04.在1G内存的计算机中能否通过malloc申请大于1G的内存?为什么?
可以 因为malloc函数是在程序的虚拟地址空间申请的内存,与物理内存没有直接的关系。虚拟地址与物理地址之间的映射是由操作系统完成的,操作系统可通过虚拟内存技术扩大内存。
嵌入式面经大全(6/30)--C/C++常见面试题(一)_牛客博客 (nowcoder.net)
05.malloc和new的区别
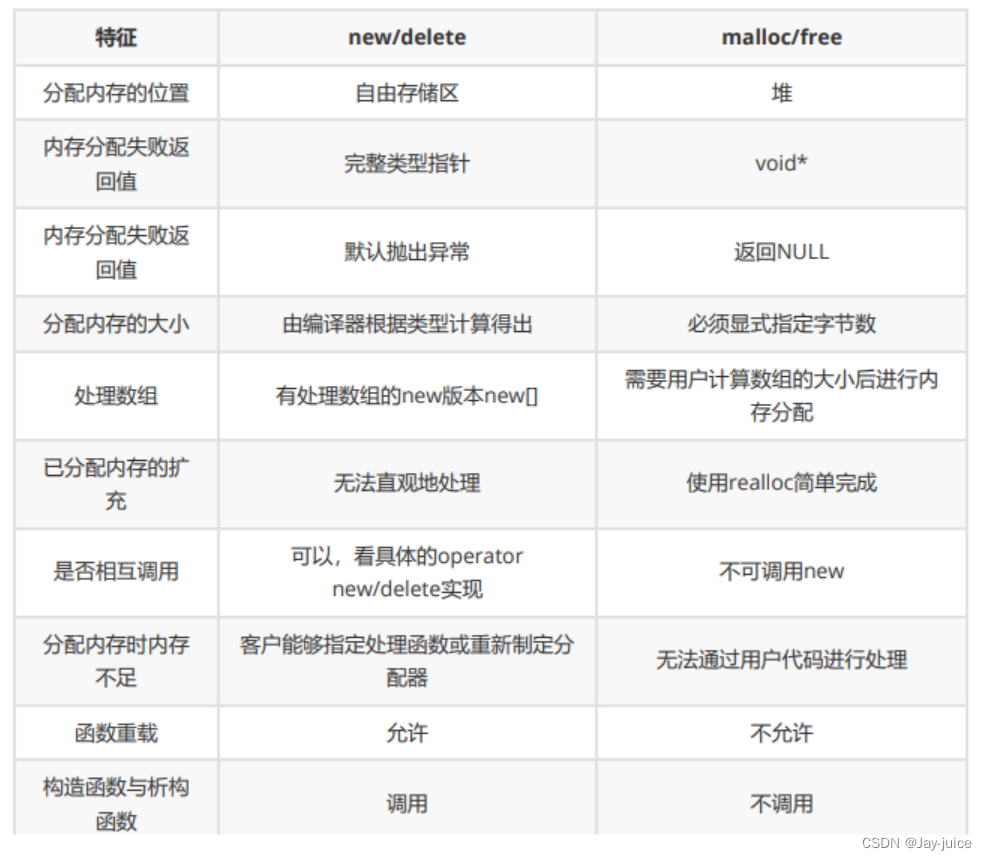 在 C++ 中,
在 C++ 中,new 和 delete 用于动态分配和释放内存。下面是它们的基本用法:
使用 new 动态分配内存:
// 分配单个对象的内存并初始化
int *ptr = new int(10);
// 分配数组内存
int *arr = new int[5];
// 分配自定义类型对象内存并初始化
MyClass *obj = new MyClass();使用 delete 释放动态分配的内存:
// 释放单个对象内存
delete ptr;
// 释放数组内存
delete[] arr;
// 释放自定义类型对象内存
delete obj;需要注意的是,在使用 new 和 delete 时应该遵循以下原则:
-
对于使用
new分配的内存,务必使用delete来释放,对于使用new[]分配的数组内存,务必使用delete[]来释放。 -
避免对未分配的内存使用
delete或delete[],否则会导致未定义行为。 -
避免内存泄漏,即确保在不再需要动态分配的内存时及时释放。
-
对于自定义类型,需要正确实现析构函数来释放对象可能持有的资源。
06.malloc与free
在 C 语言中,malloc 和 free 用于动态分配和释放内存。下面是它们的基本用法:
// 分配 10 个整数大小的内存空间
int *ptr = (int*)malloc(10 * sizeof(int));
// 分配指定大小的内存空间
void *mem = malloc(100);
int main() {
// 分配 5 个整数大小的内存空间
int *ptr = (int*)malloc(5 * sizeof(int));
if (ptr == NULL) {
printf("内存分配失败\n");
return 1;
}
// 使用 memset 设置内存内容为 0
memset(ptr, 0, 5 * sizeof(int));
// 打印设置后的内容
for (int i = 0; i < 5; i++) {
printf("%d ", ptr[i]);
}
// 释放内存
free(ptr);
return 0;
}需要注意的是,在使用 malloc 和 free 时应该遵循以下原则:
-
使用
malloc分配内存后,需要进行类型转换来匹配所需的指针类型。 -
对于使用
malloc分配的内存,务必使用free来释放,确保释放的是正确的内存地址。 -
避免对未分配的内存使用
free,否则会导致未定义行为。 -
避免多次释放同一块内存,以避免出现内存错误。
07.new和delete的实现原理,delete是如何知道释放内存的大小的?
new 的实现原理:当程序使用 new 操作符时,编译器会生成一段代码来执行以下操作:
-
调用 operator new 函数,该函数会在堆中分配一块内存。
-
调用对象的构造函数,初始化对象。
-
返回指向该对象的指针。
delete 的实现原理:当程序使用 delete 操作符时,编译器会生成一段代码来执行以下操作:
-
调用对象的析构函数,释放对象占用的资源,
-
调用 operator delete 函数,将内存释放回堆。
-
delete 如何知道释放内存的大小:delete 操作符并不知道要释放的内存大小,它只需要知道要释放的指针地址。当对象被 new 分配内存时,编译器会在堆中存储有关对象大小的信息,包括对象的长度和其他元数据。当使用 delete 操作符释放对象时,编译器使用这些元数据来确定要释放的内存块的大小。因此,如果在使用 new 时使用了错误的长度,可能会导致 delete 操作符释放错误的内存块,从而引起程序错误或崩溃。
08.什么是内存泄露,如何检测与避免
内存泄露:是指在程序运行过程中,动态分配的内存没有被正确释放或者释放的时机不当,导致这部分内存无法再被程序访问和利用,从而造成系统内存资源的浪费。
避免内存泄露的几种方式
-
显式释放内存:有
new就有delete,有malloc就有free,保证它们一定成对出现 -
避免重复分配内存:程序在使用动态分配的内存时,应该避免重复分配内存,特别是在循环中。如果需要多次分配内存,可以使用realloc函数重新调整内存块的大小,以减少内存碎片的产生。
-
使用智能指针:智能指针是一种自动管理内存的工具,可以避免手动释放内存的繁琐操作。智能指针会在对象不再被使用时自动释放内存,并且可以避免内存泄漏和悬空指针等问题。
03.指针
01.数组名和指针
-
数组名是一个常量指针,它在程序执行过程中不会改变,指向的地址是数组的首地址。而指向数组首元素的指针可以被重新赋值,可以指向其他元素或者其他数组。
-
数组名不能进行指针运算,而指向数组首元素的指针可以进行指针运算,例如加减操作。这是因为数组名是一个常量指针,它指向的地址是不可修改的。
int main() { int arr[10]={0,1,2,3,4,5,6,7,8,9}; int*p=arr; printf("%p %d\t%p %d\n", p,*p,arr,*arr);//0x7ffc5bb44a50 0 0x7ffc5bb44a50 0 p++; //arr++;//error: lvalue required as increment operand 是一个右值,不能进行自增操作 //arr+=1;//error: assignment to expression with array type 不能对数组名进行赋值操作 printf("%p %d\t%p %d\n",p, *p,(arr+1),*(arr+1));//0x7ffc5bb44a54 1 0x7ffc5bb44a54 1 return 0; } -
对数组名使用
sizeof操作符时,返回的是整个数组占用内存的大小。对指向数组首元素的指针使用sizeof操作符时,返回的是指针类型的大小。int main() { int arr[10]={0,1,2,3,4,5,6,7,8,9}; int*p=arr; //对数组名使用sizeof操作符时,返回的是整个数组占用内存的大小(以字节为单位),而对指向数组首元素的指针使用sizeof操作符时,返回的是指针类型的大小。 printf("sizeof(arr)=%lu sizeof(p)=%lu\n", sizeof(arr),sizeof(p));//sizeof(arr)=40 sizeof(p)=8 return 0; } -
在函数调用时,数组名作为参数传递给函数时,它实际上是传递给函数的一个指针,即指向数组首元素的指针。因此,数组名和指向数组首元素的指针在作为函数参数传递时,可以互换使用。
-
数组名在声明时必须指定数组的大小,而指向数组首元素的指针在声明时可以不指定数组的大小。
02.数组指针和指针数组
-
指针数组:指针数组是数组,用来存放指针的。
int* arr1[10]; //整型指针的数组(arr1数组里面有10个元素,每个元素是int*类型) char* arr2[4]; //一级字符指针的数组(arr2数组里面有4个元素,每个元素是char*类型) char* *arr3[5]; //二级字符指针数组(arr3数组里面有5个元素,每个元素是char**类型) int arr1[]={1,2,3,4,5}; int arr2[]={2,3,4,5,6}; int arr3[]={3,4,5,6,7}; //parr数组里面,存了三个数组名(arr1,arr2,arr3),类型都是int* //通过三个数组名,可以分别找到该数组名对应的首元素地址 int* parr[]={arr1,arr2,arr3}; for (int i=0; i<3; i++){ for (int j=0; j<5; j++){ //通过parr[i]找到存储的每个数组首元素地址,通过parr[i]+j找到每个元素的地址,解引用找到每个元素。 printf("%d ",*(parr[i]+j)); } printf("\n"); } -
数组指针是指向数组的指针 ,用来存放数组的地址。
-
arr + 1以后跳过了4个字节,&arr +1以后跳过了40个字节,40是个字节归刚好是,arr数组十个元素的总大小,又因为数组在内存中是连续存放的。所以&arr + 1 就跳过了整个数组。所以这里&arr 代表的就是整个数组的地址。如果需要一个指针来存储这个数组地址,那就会用到我们的数组指针。int arr[10] = { 0 }; printf("arr = %p\n", arr); //arr = 0x7ffdd1460ab0 printf("arr+1 = %p\n", arr + 1); //arr+1 = 0x7ffdd1460ab4 printf("&arr= %p\n", &arr); //&arr= 0x7ffdd1460ab0 printf("&arr+1= %p\n", &arr + 1); //&arr+1= 0x7ffdd1460ad8int arr[10] = { 0 }; //arr=&arr[0] -- 首元素地址 int(*p)[10]=&arr;//数组的地址,定义了一个指向包含 10 个整型元素的数组的指针 #include <iostream> int main() { int arr[5] = {1, 2, 3, 4, 5}; int (*p)[5] = &arr; // 声明一个指向含有5个整型元素的数组的指针,并将其指向 arr 数组 //p是数组指针,指向arr数组 //数组名*p,数组的地址解引用,就拿到了这个数组 //(*p)[0]; 数组的第一个元素 std::cout << "arr[0]: " << (*p)[0] << std::endl; // 输出 arr[0] 的值 std::cout << "arr[3]: " << (*p)[3] << std::endl; // 输出 arr[3] 的值 return 0; } #include <stdio.h> #include <unistd.h> #include <stdio.h> int main() { /* 0 1 2 3 4 5 6 7 8 9 10 11 */ int a[3][4] = {{0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9, 10, 11}}; int(*p)[4]; p = a; printf("%ld\n", sizeof(*(p)));//16 *p指向a[0] printf("p=%p a[0]=%p\n", p,a[0]); //p=0x7ffd740986e0 a[0]=0x7ffd740986e0 printf("**p=%d a[0][0]=%d\n",**p,a[0][0]);//**p=0 a[0][0]=0 printf("*(*p+1)=%d a[0][1]=%d\n",*(*p+1),a[0][1]);//*(*p+1)=1 a[0][1]=1 p++; printf("p=%p a[1]=%p\n",p,a[1]); //p=0x7ffd740986f0 a[1]=0x7ffd740986f0 printf("**p=%d a[1][0]=%d\n",**p,a[1][0]);//**p=4 a[1][0]=4 printf("*(*p+1)=%d a[1][1]=%d\n",*(*p+1),a[1][1]);//*(*p+1)=5 a[1][1]=5 return (0); }*二维数组数组名:一维数组的数组名是首元素的地址,二维数组的数组名也是首元素的地址,这里二维数组的首元素是第一个维数组,因为二维数组也可以看作是由数个一维数组组成的,二维数组的数组名就代表了第一个一维数组的地址。*
在 C 语言中,二维数组名实际上也是一个指向数组的指针。具体来说,二维数组名代表了数组的首地址,也就是第一个元素的地址。这个地址可以被解释为指向包含一维数组的指针。
举例来说,如果有这样一个二维数组:
int arr[3][4];
那么
arr就代表了整个二维数组的首地址。你可以将它看作一个指向包含 4 个整型元素的一维数组的指针。在内存中,二维数组以行优先的顺序存储,因此arr所指向的一维数组就是第一行的数组。需要注意的是,由于二维数组在内存中是连续存储的,因此可以使用一维数组的方式来处理二维数组。比如,可以通过
arr[i][j]或者*(*(arr + i) + j)来访问二维数组中的元素
03.函数指针和指针函数的区别
函数指针和指针函数是两个不同的概念:
-
函数指针(Function Pointer):
-
函数指针的定义: 函数的返回值类型(*指针名)(函数的参数列表类型)
-
函数指针是指向函数的指针变量。在 C 语言中,函数名实际上就是指向函数代码块首地址的指针,因此可以将函数名赋值给函数指针变量。
-
通过函数指针,可以动态地调用不同的函数,实现函数指针的多态性。函数指针可以作为函数的参数传递,也可以作为函数的返回值。
-
函数指针的声明方式类似于指针,例如
void (*funcPtr)(int);表示一个指向参数为整型、返回类型为 void 的函数的函数指针。#include <stdio.h> int max(int a, int b) { return a > b ? a : b; } int main() { int(*funcPtr)(int,int);//定义一个函数指针 funcPtr = max;//函数名是指向函数代码块首地址的指针,funcPtr指向max函数 int ans=(*funcPtr)(10,20);//指针调用函数 int ans1 = funcPtr(10, 20);//这种写法省略了解引用操作,直接通过函数指针调用函数,效果是一样的。 printf("ans=%d,ans1=%d\n", ans,ans1); return 0; } typedef struct DispOpr{ char* name; int (*DeviceInit)(void); int (*DeviceExit)(void); int(*GetDispBufferInfo)(PDispBuff); int(*FlushRegion)(PRegion ,PDispBuff); struct DispOpr*ptNext; }DispOpr,*PDispOpr; static DispOpr g_tFramebufferOpr = { .name="fb", .DeviceInit=FbDeviceInit, .DeviceExit=FbDeviceExit, .GetDispBufferInfo=FbGetDispBufferInfo, .FlushRegion=FbFlushRegion, };
-
指针函数(Pointer to Function):
-
指针函数是一个返回指针的函数,即函数的返回类型是指针类型。
-
由于函数返回值是地址,故传递方式为地址传递,地址传递需要保证地址是有效的,需要没有被回收或释放掉的地址,否则会段错误,非法访问内存
-
指针函数可以动态地分配内存空间,并返回指向该内存空间的指针,常用于动态内存管理和数据结构中。
-
例如,
int* createArray(int size);是一个返回指向整型数组的指针的指针函数,用于动态创建一个整型数组并返回指向该数组的指针。
04.指针和引用
引用不是新定义一个变量,而是给已存在的变量取一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
int a = 10,b=20;
// int& ra; // 引用在定义时必须初始化,该条语句编译时会出错
int& ra = a;//一个变量可以有多个引用
int& rra = a;
printf("%d %d %d\n", a, ra, rra);//10 10 10
printf("%p %p %p\n", &a, &ra, &rra);//0x7ffccb52cc30 0x7ffccb52cc30 0x7ffccb52cc30
a=b; 错误!这不是改变引用对象,而是改变了引用对象所指向的值
printf("%d %d %d\n", a, ra, rra);//20 20 20
printf("%p %p %p\n", &a, &ra, &rra);//0x7ffccb52cc30 0x7ffccb52cc30 0x7ffccb52cc30指针(Pointers):
-
定义和声明:指针是一个包含变量地址的特殊类型的变量。通过在变量名前面加上
*符号来声明指针,例如int *ptr;。 -
空指针:指针可以为空,即指向空地址或者没有指向任何有效的内存单元。
-
指针运算:指针可以进行运算,比如加法、减法等,以便访问数组中的元素或者直接修改地址。
-
指针的重新赋值:可以将指针重新赋值为另外的地址。
-
指针的指向可以改变:指针可以在运行时指向不同的变量或对象。
引用(References):
-
定义和声明:引用是一个已存在对象的别名,通过在变量名前面加上
&符号来声明引用,例如int &ref = var;。 -
不能为空:引用在声明时必须初始化,且一旦引用绑定了对象,就不能再绑定到其他对象。
-
引用本质上是对象:引用在底层实现上通常是一个指针,但语法上看起来更像是对对象的直接访问。
-
不需要解引用操作:使用引用时不需要显式地进行解引用操作,而指针需要使用
*运算符来解引用。
相同点:
-
间接访问:指针和引用都可以用于间接访问变量,可以通过它们来修改变量的值。
-
传递参数:指针和引用都可以用作函数的参数,从而实现对函数外部变量的引用传递。
05.野指针和悬空指针
野指针:是没有被初始化过的指针,所以不确定指针具体指向。因为“野指针”可能指向任意内存段,因此它可能会损坏正常的数据,也有可能引发其他未知错误。
int *p;//未初始化,野指针
悬空指针:指针最初指向的内存已经被释放了的一种指针。指针指向的内存已释放,但指针的值没有被清零,对悬空指针操作的结果不可预知。
#include <iostream>
using namespace std;
int main()
{
int *p = new int(5);
cout<<"*p = "<<*p<<endl;
free(p); // p 在释放后成为悬空指针
p = NULL; // 非悬空指针
return 0;
}
int main()
{
int *p;
{
int tmp = 10;
p = &tmp;
}
//超出了变量的作用范围,p 在此处成为悬空指针
return 0;
}
//指向了函数局部变量
int* getVal() {
int tmp = 10;
return &tmp;
}
int main()
{
int *p = getVal(); //悬空指针
cout<<"*p = "<<*p<<endl;
return 0;
}
06.智能指针智能指针是一种用于管理动态分配内存的工具,它能够在对象不再需要时自动释放内存,从而避免内存泄漏问题。智能指针通过封装原始指针,并在其析构函数中调用 delete 或 free 来释放内存,从而确保在对象生命周期结束时内存得到正确释放。
在C++中,标准库提供了两种常用的智能指针:std::unique_ptr 和 std::shared_ptr。
-
std::unique_ptr:
std::unique_ptr是一种独占所有权的智能指针,它确保同一时间只有一个std::unique_ptr可以指向给定的资源。当std::unique_ptr被销毁时,它所管理的资源会被自动释放。示例:
#include <iostream> #include <memory> int main() { std::unique_ptr<int> ptr(new int(10)); std::cout << *ptr << std::endl; // 不需要手动调用 delete,当 ptr 超出作用域时会自动释放内存 return 0; } -
std::shared_ptr:
std::shared_ptr允许多个智能指针共享同一份资源,它使用引用计数来管理内存。只有当最后一个指向资源的std::shared_ptr被销毁时,资源才会被释放。示例:
#include <iostream> #include <memory> int main() { std::shared_ptr<int> ptr1 = std::make_shared<int>(10); std::shared_ptr<int> ptr2 = ptr1; // ptr1 和 ptr2 共享同一份资源 std::cout << *ptr1 << " " << *ptr2 << std::endl; // 不需要手动调用 delete,当所有指向资源的 shared_ptr 都超出作用域时会自动释放内存 return 0; }
使用智能指针可以简化内存管理,避免手动管理内存带来的潜在错误,提高代码的可读性和可维护性。但需要注意的是,智能指针并不能解决所有的内存管理问题,例如循环引用问题,因此在使用智能指针时仍需谨慎。
07.指针大小
在C语言中,指针的大小取决于系统架构和编译器的位数。一般情况下,指针的大小为系统的地址总线宽度的大小,即指针的大小通常等于机器字长。在大多数现代系统中,指针的大小为4字节(32位系统)或8字节(64位系统)。
指针类型决定了指针进行解引用操作时能够访问的空间大小(能操作几个字节)。int可以访问4个字节,char可以访问1个字节,double*可以访问8个字节
数据类型大小
短整型:short (2字节) (-32768~32767) 整型: int (4字节) 长整型:long (4/8字节)(-2147483648~2147483647) 长长整型:long long (8字节)-9223372036854775808~+9223372036854775807(约九百亿亿) 字符型:char (1字节) (-128~127) 字符型:unsigned char (1字节) (0~255) 单精度型:float (4字节)(3.4E-38~3.4E+38)(7位有效数字) 双精度型:double (8字节)(1.7E-308~1.7E+308)(16位有效数字) 长双精度型:long double (16字节)
04.C++
01.面向对象的基本特征有哪些
面向对象编程是一种以对象为基本单位,通过封装、继承和多态等机制来组织和管理代码的编程范式。它具有以下基本特征:
-
封装(Encapsulation):封装是将数据和对数据的操作封装在一个单独的实体中,即类。通过封装,类可以隐藏其内部实现细节,只提供对外部可见的接口,从而保护数据的安全性和完整性。其他对象只能通过类的接口来访问和操作数据,而无法直接访问类的内部实现。
-
继承(Inheritance):继承是指一个类可以派生出子类,子类会继承父类的属性和方法。通过继承,子类可以重用父类的代码,并且可以在不修改父类的情况下添加新的属性和方法,实现代码的扩展和复用。继承还允许通过多态来实现基于父类的统一接口对不同子类进行操作。
-
多态(Polymorphism):多态是指同一种操作或函数可以作用于不同类型的对象,并且可以根据对象的实际类型执行不同的行为。多态可以提高代码的灵活性和可扩展性,使得程序可以根据实际需要处理不同类型的对象,而无需显式判断对象的类型。
-
抽象(Abstraction):抽象是指通过对类的建模,将具体的对象归纳为更高层次的概念和类型。抽象可以忽略不必要的细节,只关注对象的一些关键属性和行为,从而提高代码的可理解性和可维护性。抽象可以通过接口、抽象类和纯虚函数等方式来实现。
这些基本特征共同构成了面向对象编程的核心思想和方法,使得程序可以更加模块化、可扩展和易于理解。通过合理地运用这些特征,可以设计出清晰、灵活且易于维护的面向对象程序。
02.C++中重载和覆盖的区别
重载(overload)
-
重载指的是函数具有的不同的参数列表,而函数名相同的函数。重载要求参数列表必须不同,比如参数的类型不同、参数的个数不同、参数的顺序不同。
-
如果仅仅是函数的返回值不同是没办法重载的,因为重载要求参数列表必须不同。
-
程序是根据参数列表来确定具体要调用哪个函数的
void Fun(int a); void Fun(double a); void Fun(int a, int b); void Fun(double a, int b); //上面四个函数都可以构成函数重载 int Fun(int a) void Fun(int a) //上面两个是无法构成函数重载的,参数列表必须不同
覆盖(重写override)
-
覆盖是存在类中,子类重写从基类继承过来的虚函数。在基类中,将虚函数声明为
virtual,子类函数名、返回值、参数列表都必须和基类相同。class Animal { public: virtual void makeSound() { cout << "Animal makes a sound" << endl; } }; class Dog : public Animal { public: void makeSound() override { cout << "Dog barks" << endl; } }; -
当子类的对象调用成员函数的时候,如果成员函数有被覆盖则调用子类中覆盖的版本,否则调用从基类继承过来的函数
-
如果子类覆盖的是基类的虚函数,可以用来实现多态。
03.C++有几种构造函数
在C++中,构造函数是一种特殊类型的成员函数,用于在对象创建时对其进行初始化。C++中的构造函数有以下几种类型:
-
默认构造函数:
-
如果类没有显式地定义构造函数,则编译器会生成一个默认构造函数。
-
默认构造函数不带任何参数,且不执行任何操作。
-
-
有参构造函数:
-
带参构造函数接受一个或多个参数,用于在对象创建时初始化成员变量。
-
可以定义多个带参构造函数,每个构造函数可以接受不同的参数。
-
-
拷贝构造函数:
-
拷贝构造函数用于将一个对象的值复制到另一个对象中。
-
它通常接受一个引用类型的参数,用于指定要复制的对象。
-
-
移动构造函数:
-
移动构造函数用于在对象之间转移资源所有权。
-
它通常接受一个右值引用类型的参数。
-
示例:
class Person {
public:
// 默认构造函数
Person() {
name = "";
age = 0;
}
// 带参构造函数
Person(string n, int a) {
name = n;
age = a;
}
// 拷贝构造函数
Person(const Person& other) {
name = other.name;
age = other.age;
}
// 移动构造函数
Person(Person&& other) noexcept {
name = std::move(other.name);
age = other.age;
}
private:
string name;
int age;
};构造函数是C++中一种重要的特殊成员函数,它们允许在创建对象时对其进行初始化。通过合理设计构造函数,可以使代码更加清晰、可读性更高,并提高程序的可维护性。
04.为什么一个类作为基类被继承,其析构函数必须是虚函数?
当一个类作为基类被继承时,如果其析构函数不是虚函数,则可能会导致派生类的内存泄漏问题。这是因为当一个指向派生类对象的基类指针或引用被删除时,如果基类的析构函数不是虚函数,那么只会调用基类的析构函数,而不会调用派生类的析构函数。这样就会导致派生类中的动态分配的资源无法被释放,从而造成内存泄漏。
通过将基类的析构函数声明为虚函数,可以确保在删除基类指针时,派生类的析构函数也会被正确调用,从而可以释放派生类中的动态分配的资源。
示例:
#include <iostream>
using namespace std;
class Base {
public:
Base(){
cout << "Base construct" << endl;
};
~Base() {
cout << "Base destructor" << endl;
}
};
class Derived : public Base {
public:
Derived(){
cout << "Derived construct" << endl;
};
~Derived() {
cout << "Derived destructor" << endl;
}
};
int main() {
Base* ptr = new Derived();
delete ptr; // 调用派生类的析构函数
return 0;
}
// Base construct
// Derived construct
// Base destructor将基类析构函数声明为虚函数
#include <iostream>
using namespace std;
class Base {
public:
Base(){
cout << "Base construct" << endl;
};
virtual ~Base() {
cout << "Base destructor" << endl;
}
};
class Derived : public Base {
public:
Derived(){
cout << "Derived construct" << endl;
};
~Derived() override {
cout << "Derived destructor" << endl;
}
};
int main() {
Base* ptr = new Derived();
delete ptr; // 调用派生类的析构函数
return 0;
}
// Base construct
// Derived construct
// Derived destructor //子类先释放
// Base destructor //然后基类05.构造函数、析构函数的执行顺序?构造函数和拷贝构造的内部都干了啥?
在C++中,构造函数和析构函数的执行顺序如下:
-
构造函数执行顺序:
-
在创建一个对象时,先执行基类的构造函数
-
然后按照成员变量在类中的声明顺序依次执行各个成员变量的构造函数
-
最后执行派生类的构造函数。
-
-
析构函数执行顺序:
-
在一个对象被销毁时,析构函数的执行顺序与构造函数相反。即先执行派生类的析构函数
-
然后按照成员变量的声明顺序依次执行各个成员变量的析构函数
-
最后执行基类的析构函数。
-
关于构造函数和拷贝构造函数的内部工作:
-
构造函数:
-
构造函数用于初始化对象的数据成员。在构造函数内部,可以对对象的成员变量进行赋值、分配内存、调用其他函数等操作,以确保对象被正确初始化。
-
构造函数的目的是在对象创建时执行必要的初始化操作,使得对象处于一个合法的状态。
-
-
拷贝构造函数:
-
拷贝构造函数是一种特殊的构造函数,用于将一个对象的值复制到另一个对象中。通常在对象初始化或对象传递过程中调用。
-
拷贝构造函数的主要作用是执行深拷贝(deep copy)操作,确保在拷贝对象时所有资源都能正确复制,避免浅拷贝(shallow copy)导致的问题。
-
拷贝构造函数的形参通常是一个引用类型的参数,以便接受要复制的对象。在拷贝构造函数内部,需要将传入对象的数据复制到当前对象中,以实现对象的复制。
-
06.深拷贝和浅拷贝
-
浅拷贝:
-
浅拷贝是指仅复制对象本身的成员变量值,而不复制对象所引用的资源。这意味着多个对象会共享同一份资源,当其中一个对象对资源进行修改时,会影响到其他对象。
-
浅拷贝通常是通过默认的拷贝构造函数或赋值运算符实现的。它仅复制指针或引用,而不复制指针或引用所指向的内容。
-
-
深拷贝:
-
深拷贝是指在对象拷贝过程中,不仅复制对象本身的成员变量值,还复制对象所引用的资源。这样每个对象都有自己独立的资源副本,互不影响。
-
深拷贝通常需要自定义拷贝构造函数和赋值运算符重载,确保对象的资源被正确地复制。
-
示例:
#include <iostream>
class MyClass {
public:
int* data;
// 构造函数
MyClass(int value) {
data = new int(value);
}
// 拷贝构造函数(浅拷贝)
MyClass(const MyClass& other) {
data = other.data; // 仅复制指针,共享同一个资源
}
// 深拷贝构造函数
MyClass(const MyClass& other) {
data = new int(*other.data); // 深拷贝资源,创建新的副本
}
~MyClass() {
delete data; // 释放动态分配的内存
}
};
int main() {
MyClass obj1(10);
MyClass obj2 = obj1; // 浅拷贝,obj1和obj2共享同一个资源
obj2.data = new int(20); // 修改obj2的资源,不影响obj1
std::cout << *obj1.data << std::endl; // 输出:10
std::cout << *obj2.data << std::endl; // 输出:20
return 0;
}在上面的示例中,MyClass 类包含了一个动态分配的整型数据 data。其中,浅拷贝构造函数仅复制指针,导致多个对象共享同一个资源;而深拷贝构造函数通过重新分配内存并复制资源,使每个对象都有独立的资源副本。
在 main 函数中,创建了两个对象 obj1 和 obj2,并通过浅拷贝将 obj1 的值复制给 obj2。修改 obj2 的资源并不会影响到 obj1,因为它们共享同一个资源。最终输出结果显示了这一点。
07.this指针
对于成员函数中的this指针,它的类型是 类类型* const,即指向当前类类型的非常量指针常量,即成员函数中,不能给this指针赋值。
在C++中,this指针是一个特殊的指针,它指向当前对象。this指针可以在类的成员函数中使用,用于指代调用该成员函数的对象。
当调用一个对象的成员函数时,编译器会隐式地将对象的地址作为参数传递给成员函数,这个参数就是this指针。因此,在成员函数内部,可以使用this指针来访问对象的成员变量和成员函数。
this指针在C++中主要用于以下几个方面的功能:
-
访问对象的成员变量和成员函数:通过this指针可以在类的成员函数中访问当前对象的成员变量和成员函数。
#include <iostream> class MyClass { public: int data; MyClass(int data) : data(data) {} void setData(int data) { this->data = data; // 使用this指针访问成员变量 } void showData() { std::cout << "Data: " << this->data << std::endl; // 使用this指针访问成员变量 } void callAnotherMemberFunction() { this->showData(); // 使用this指针调用另一个成员函数 } }; -
区分参数和成员变量:当成员变量和成员函数的参数名字相同时,可以使用this指针来区分它们,以便访问成员变量。
#include <iostream> class MyClass { public: int data; MyClass(int data) : data(data) {} void setData(int data) { this->data = data; // 使用this指针访问成员变量 } void printData(int data) { std::cout << "Parameter value: " << data << std::endl; std::cout << "Member variable value: " << this->data << std::endl; // 使用this指针访问成员变量 } }; int main() { MyClass obj(10); obj.setData(20); // 设置成员变量的值 obj.printData(30); // 显示参数和成员变量的值 return 0; } -
返回对象本身:在成员函数中可以使用this指针来返回对象本身,实现链式调用。
#include <iostream> class MyClass { public: int data; MyClass(int data) : data(data) {} MyClass& setData(int data) { this->data = data; // 使用this指针访问成员变量 return *this; // 返回对象本身的引用 } MyClass& addData(int value) { this->data += value; // 使用this指针访问成员变量 return *this; // 返回对象本身的引用 } void displayData() { std::cout << "Data: " << this->data << std::endl; } }; int main() { MyClass obj(10); obj.setData(20).addData(5).displayData(); // 链式调用 return 0; } -
传递当前对象给其他函数:在某些情况下,可以使用this指针将当前对象作为参数传递给其他函数。
#include <iostream> class MyClass { public: int data; MyClass(int data) : data(data) {} void processObject() { // 将当前对象作为参数传递给其他函数 someOtherFunction(this); } }; void someOtherFunction(MyClass* obj) { std::cout << "Received object with data: " << obj->data << std::endl; } int main() { MyClass obj(10); obj.processObject(); // 调用成员函数,将当前对象传递给其他函数进行处理 return 0; }
08.什么是虚函数
在C++中,虚函数是一种允许在派生类中重写(override)的基类函数。通过将基类函数声明为虚函数,可以实现多态性(polymorphism),使程序在运行时能够根据对象的实际类型来调用相应的函数。
当基类中的成员函数被声明为虚函数时,在派生类中对该函数进行重写时,如果对象是通过基类指针或引用访问的,那么在运行时将会根据对象的实际类型来调用相应的重写函数,而不是根据指针或引用的类型来决定调用哪个函数,这就是多态性的体现。
要将一个函数声明为虚函数,只需在函数声明前面加上关键字virtual即可。子类中重写该虚函数时不需要再使用virtual关键字,但最好保持一致以增强可读性。
以下是一个简单的示例代码,演示了虚函数的用法:
#include <iostream>
class Base {
public:
virtual void display() {
std::cout << "Base::display() called" << std::endl;
}
};
class Derived : public Base {
public:
void display() override {
std::cout << "Derived::display() called" << std::endl;
}
};
int main() {
Base* basePtr = new Derived(); // 通过基类指针访问派生类对象
Base* basePtr1 = new Base();
// 调用虚函数,会根据对象的实际类型调用相应的函数
basePtr->display(); // Derived::display() called
basePtr1->display(); // Base::display() called
delete basePtr;
delete basePtr1;
return 0;
}在这个示例中,Base类中的display函数被声明为虚函数,并在Derived类中进行了重写。在main函数中,我们通过基类指针basePtr访问了Derived类对象,并调用了display函数。由于display函数是虚函数,因此程序在运行时会根据对象的实际类型来调用Derived类中的display函数,从而实现多态性的效果。
09.纯虚函数
在C++中,纯虚函数是一种在基类中声明但没有定义的虚函数。通过将一个虚函数声明为纯虚函数,可以使得包含该纯虚函数的类称为抽象类,而抽象类不能被实例化,只能被用作基类,需要在派生类中实现(override)这些纯虚函数。
声明一个纯虚函数的语法是在函数声明的结尾处加上= 0,例如:
class AbstractClass {
public:
virtual void pureVirtualFunction() = 0;
};由于AbstractClass中包含了一个纯虚函数pureVirtualFunction,因此AbstractClass成为了一个抽象类,不能被直接实例化。任何继承自AbstractClass的派生类都必须实现pureVirtualFunction,否则派生类也会成为抽象类。
以下是一个示例代码,演示了如何使用纯虚函数和抽象类:
#include <iostream>
class AbstractClass {
public:
virtual void pureVirtualFunction() = 0;
};
class ConcreteClass : public AbstractClass {
public:
void pureVirtualFunction() override {
std::cout << "ConcreteClass::pureVirtualFunction() called" << std::endl;
}
};
int main() {
// AbstractClass abstractObj; // 无法实例化抽象类
ConcreteClass concreteObj;
concreteObj.pureVirtualFunction(); // 调用重写的纯虚函数
return 0;
}10.C++的struct和class的区别
| 差异特性 | struct | class |
|---|---|---|
| 成员访问范围 | 默认public | 默认private |
| 继承关系访问范围 | 默认public | 默认private |
| 类型 | struct 是值类型 | class 是引用类型 |
| {}初始化 | 1、纯数据或纯数据+普通方法的结构体支持;2、带构造函数或虚方法的结构体不支持 | 不支持 |
在C++中,类中的成员和继承的访问权限有三种:public、protected和private。这些关键字控制了类的成员对外部代码和派生类的可见性和可访问性。下面是它们的作用:
-
public:
-
公有成员对外部代码和派生类都是可见和可访问的。
-
可以在类的外部和派生类中直接访问公有成员。
-
-
protected:
-
保护成员对外部代码不可见,但对派生类可见。
-
可以在派生类的成员函数中直接访问保护成员。
-
不能在类的外部直接访问保护成员。
-
-
private:
-
私有成员对外部代码和派生类都不可见。
-
不能在类的外部和派生类中直接访问私有成员。
-
下面是一个示例,演示了这三种访问权限的用法:
#include <iostream>
using namespace std;
class Base {
public:
int publicVar; // 公有成员
protected:
int protectedVar; // 保护成员
private:
int privateVar; // 私有成员
public:
void display() {
cout << "Public member: " << publicVar << endl;
cout << "Protected member: " << protectedVar << endl;
cout << "Private member: " << privateVar << endl;
}
};
class Derived : public Base {
public:
void accessBaseMembers() {
cout << "Derived accessing base members:" << endl;
cout << "Public member in derived: " << publicVar << endl; // 可以访问
cout << "Protected member in derived: " << protectedVar << endl; // 可以访问
// cout << "Private member in derived: " << privateVar << endl; // 错误,不能访问
}
};
int main() {
Base obj;
obj.publicVar = 10; // 可以访问
// obj.protectedVar = 20; // 错误,不能访问
// obj.privateVar = 30; // 错误,不能访问
obj.display(); // 可以访问
Derived derivedObj;
derivedObj.accessBaseMembers(); // 可以访问基类的公有和保护成员
return 0;
}在这个示例中,Base 类有三种类型的成员变量,分别是 publicVar、protectedVar 和 privateVar。然后,Derived 类通过 public 继承方式继承了 Base 类,因此在 Derived 类中可以访问 Base 类的公有和保护成员。
11.NULL和nullptr
C++中NULL和nullptr的区别_nullptr和null区别-CSDN博客
NULL在C++中就是0,这是因为在C++中void* 类型是不允许隐式转换成其他类型的,所以之前C++中用0来代表空指针,但是在重载整形的情况下,会出现上述的问题。所以,C++11加入了nullptr,可以保证在任何情况下都代表空指针,而不会出现上述的情况,因此,建议以后还是都用nullptr替代NULL吧,而NULL就当做0使用。
12.vector/list
std::vector 是一个动态数组容器,可以在运行时动态增加或减少元素的数量。它的内部实现是基于连续的内存空间,元素在内存中是连续存储的。由于元素的连续存储,std::vector 支持通过索引快速访问元素,时间复杂度为 O(1),并且支持随机访问迭代器。
主要特点包括:
-
支持动态增长:当元素数量超过容量时,
std::vector会自动重新分配更大的内存空间。 -
随机访问:可以通过索引在常数时间内访问任何元素。
-
不支持在中间位置高效地插入或删除元素:插入或删除元素可能需要移动后续元素。
std::list 是一个双向链表容器,它的内部实现是通过指针将元素串联起来的。每个元素都包含了指向前一个元素和后一个元素的指针。由于元素的非连续存储,std::list 不支持随机访问,但支持在任意位置高效地插入或删除元素。
主要特点包括:
-
高效的插入和删除操作:在任意位置插入或删除元素的时间复杂度为 O(1)。
-
不支持随机访问
-
每个元素占用额外的内存空间:除了存储元素本身的数据外,还需要存储指向前一个和后一个元素的指针。
选择使用场景
-
如果需要频繁地在容器的末尾进行插入或删除操作,并且不需要频繁地访问中间位置的元素,那么
std::list可能更适合。 -
如果需要频繁地在容器中进行随机访问,并且插入或删除操作相对较少,那么
std::vector可能更适合。 -
对于其他情况,可以根据具体需求和性能要求选择合适的容器类型。
std::map 是 C++ 标准库提供的一种关联容器,它以键-值对(key-value pair)的形式存储数据,并根据键进行有序存储。std::map 内部基于红黑树(Red-Black Tree)实现,这使得插入、删除和查找操作的时间复杂度都是 O(log n),其中 n 是元素的数量。
二、Linux
01.Linux系统编程
01.Linux系统文件类型: 7/8 种
-
普通文件:-
-
目录文件:d
-
字符设备文件:c
-
块设备文件:b
-
软连接:l
-
管道文件:p
-
套接字:s
-
未知文件
文件权限说明
chmod 操作码 filename 直接用操作码修改文件权限rwx-->421 -rwxrw-r-- .421421421 普通文件所有者读写执行权限(7),同组用户读写权限(6),其他人读权限(4)
02.Linux常用命令
-
find:在特定的目录下 搜索 符合条件的文件//按名字查找 -name find . -name "*.c*" //在当前目录(包括子目录)中查找所有以 .c 或 .c 开头的文件 //find按文件大小查找 -size find /path/to/directory -size 100c //查找大小为 100 字节的文件 find /path/to/directory -size +1M //查找大于 1M 的文件 find /path/to/directory -size -100k //查找小于 100k 的文件 //按文件类型查找 -type d:目录 find . -type f //在当前目录(包括子目录)中查找所有的普通文件,并输出符合条件的文件路径 -
tar是 Linux 中最常用的 备份工具,此命令可以 把一系列文件 打包到 一个大文件中,也可以把一个 打包的大文件恢复成一系列文件# 打包文件 tar -cvf archive.tar *.c directory/ # 解包文件 tar -xvf archive.tar #列出归档文件中的内容 tar -tf archive.tar #解压归档文件到指定目录 tar -xvf archive.tar -C /target/directory -
tar与gzip命令结合可以使用实现文件 打包和压缩。tar 只负责打包文件,但不压缩,用 gzip 压缩 tar 打包后的文件,其扩展名一般用 xxx.tar.gz# 压缩文件 tar -zcvf 打包文件.tar.gz 被压缩的文件/路径... # 解压缩文件 tar -zxvf 打包文件.tar.gz # 解压缩到指定路径 tar -zxvf 打包文件.tar.gz -C 目标路径 #tar 与 bzip2 命令结合可以使用实现文件 打包和压缩(用法和 gzip 一样) # 压缩文件 tar -jcvf 打包文件.tar.bz2 被压缩的文件/路径... # 解压缩文件 tar -jxvf 打包文件.tar.bz2 -
grep允许对文本文件进行 模式查找,所谓模式查找,又被称为正则表达式#在多个文件中搜索指定字符串 grep "pattern" file1.txt file2.txt #忽略大小写进行搜索 grep -i "pattern" file.txt #使用"-o"选项, 可以值显示被匹配到的关键字, 而不是讲整行的内容都输出. #-n 显示所在行数 #显示出文章中有多少行有a grep "a" test.txt -c -
管道 |:将 一个命令的输出 可以通过管道 做为 另一个命令的输入#查找包含 "main" 关键字的进程 ps aux | grep main
-
tail是一个在 Unix/Linux 系统中常用的命令行工具,用于显示文件的末尾内容。通常用于查看日志文件或其他可能在文件末尾持续更新的文本文件。tail命令默认显示文件的末尾 10 行,但也可以通过参数来指定显示的行数或其他选项。基本用法是在终端中输入
tail命令,后跟要查看的文件名,例如:tail filename.txt
如果你想查看文件末尾的 20 行,可以使用
-n选项:tail -n 20 filename.txt
tail还可以与f选项结合使用,实现实时监视文件内容的功能。例如:tail -f filename.txt
这会持续输出文件的末尾内容,并在文件有更新时实时显示新内容。
-
netstat 是一款命令行工具,可用于列出系统上所有的网络套接字连接情况,包括 tcp, udp 以及 unix 套接字,另外它还能列出处于监听状态(即等待接入请求)的套接字。
-
netstat -tuln:显示所有 TCP 连接和监听端口。 -
netstat -rn:显示路由表。 -
netstat -i:显示网络接口信息。
-
-
nc是一个简单而强大的网络工具,也称为 netcat。它可以在网络上读取和写入数据,因此可以用于多种目的,包括端口扫描、端口监听、文件传输等。在不同的操作系统中,nc的用法略有不同。
-
监听端口: 使用
nc -l <port>命令可以监听指定的端口,等待连接。 -
连接到远程主机: 使用
nc <host> <port>命令可以连接到指定的主机和端口。 -
文件传输:
nc可以用于简单的文件传输,例如nc -l <port> > file.txt可以接收文件,而nc <host> <port> < file.txt则可以发送文件。 -
端口扫描:
nc可以用于快速进行端口扫描,例如nc -zv <host> <start-port>-<end-port>。
在Linux系统中,route命令用于显示和操作IP路由表。它允许你查看系统当前的路由信息,并且可以用于添加、删除和修改路由。
以下是一些常用的route命令选项及其功能:
-
显示当前路由表:
route -n
或者
route -rn
这会以数字形式显示当前系统的路由表,包括目标网络、网关、接口和其他相关信息。
-
添加路由:
route add -net 目标网络 netmask 子网掩码 gw 网关
这个命令将指定的目标网络添加到路由表中,通过指定的网关进行访问。
-
删除路由:
route del -net 目标网络 netmask 子网掩码 gw 网关
这个命令将从路由表中删除指定的目标网络。
-
修改默认网关:
route add default gw 网关
这个命令将系统的默认网关设置为指定的网关地址。
-
临时改变路由:
route add -net 目标网络 netmask 子网掩码 gw 网关 metric 数值
这个命令可以在不修改配置文件的情况下,临时修改某个路由的优先级(metric值越小,优先级越高)。
-
清空所有路由:
route flush
这个命令会清空系统的所有路由表项。
以上只是route命令的一些常见用法,你也可以通过man route命令来查看更详细的帮助信息。
03.Linux查看内存使用情况
-
free命令用于显示系统的内存使用情况,包括物理内存和交换空间的情况。下面是free命令的输出示例:
free
total used free shared buff/cache available
Mem: 32825356 1821324 29717784 221628 1275248 30482484
Swap: 2097148 0 2097148
free -h
total used free shared buff/cache available
Mem: 3.8G 1.5G 523M 3.3M 1.8G 2.0G
Swap: 8.4G 0B 8.4G
-
top用于实时监视系统的运行情况,包括 CPU 使用率、内存使用情况、进程状态等
 TOP命令参数详解---10分钟学会top用法_top详解-CSDN博客
TOP命令参数详解---10分钟学会top用法_top详解-CSDN博客
-
cat /proc/meminfo命令用于查看系统中有关内存的详细信息,包括内存总量、空闲内存、缓冲区和缓存等。/proc目录是一个特殊的虚拟文件系统,它提供了关于当前运行中的 Linux 内核和进程的信息。这个目录中包含了大量的文件和子目录,每个文件和子目录都代表着不同的系统信息。下面是一些/proc目录中常见的内容:Linux下的/proc目录介绍 - 头痛不头痛 - 博客园 (cnblogs.com)
-
/proc/cpuinfo: 包含有关 CPU 的信息,如型号、频率等。 -
/proc/meminfo: 包含有关内存的信息,如总内存、空闲内存等。 -
/proc/loadavg: 包含系统负载平均值的信息。 -
/proc/PID: 包含有关进程 PID 的信息,每个运行中的进程都有一个对应的目录,其中包含有关该进程的各种信息,如命令行参数、状态等。
-
-
ps命令用于查看当前系统中运行的进程信息
-
显示当前用户的所有进程:
# 查看系统中所有进程,使用BSD操作系统格式 ps aux 选项: a:显示一个终端的所有进程,除了会话引线 u:显示进程的归属用户及内存的使用情况 x:显示没有控制终端的进程
04.gcc编译四步骤
使用 GCC 编译 C 语言程序通常需要四个步骤,包括预处理、编译、汇编和链接。下面是 GCC 编译 C 语言程序的四个步骤:

-
预处理(Preprocessing): 在这个阶段,预处理器会处理源文件,包括展开宏定义、处理条件编译指令等。预处理后的代码通常保存在一个中间文件中(通常以
.i结尾),我们可以使用-E选项告诉 GCC 只执行预处理步骤,并输出预处理后的代码,例如:
gcc -E main.c -o main.i
-
编译(Compiling): 在这个阶段,编译器会将预处理后的代码翻译成汇编代码。编译后的代码通常保存在一个汇编文件中(通常以
.s结尾),我们可以使用-S选项告诉 GCC 只执行编译步骤,并输出汇编代码,例如:
gcc -S main.i -o main.s
-
汇编(Assembling): 在这个阶段,汇编器将汇编代码翻译成机器可执行的目标代码。汇编后的对象文件通常保存在一个目标文件中(通常以
.o结尾),我们可以使用-c选项告诉 GCC 只执行汇编步骤,并输出目标文件,(汇编过程是将汇编代码转化成目标文件同时生成符号表,方便链接器的运行。)例如:
gcc -c main.s -o main.o
-
链接(Linking): 在这个阶段,链接器将目标文件及其依赖的库文件链接在一起,生成最终的可执行文件。我们可以直接调用 GCC 来完成整个编译过程,例如:
gcc main.c -o main
程序的运行过程(详解)_写出程序的解释执行过程-CSDN博客
链接过程中会进行合并段表和符号表的合并和重定位。
在系统上运行程序的链接过程(详细)_程序链接阶段使用的技术-CSDN博客
-
相似段合并:对于输入的多个目标文件,链接器一般采用“相似段合并”的方法将相同性质的段合并到一起
-
符号地址的确定:当合并相似段之后,链接器开始计算各个符号的虚拟地址,由于各个符号在段内的相对位置是固定的,所以链接器只需要给每一个符号加上一个偏移量,使得它们能够调整到正确的虚拟地址上。
-
链接器解析多重定义的全局符号
05.静态库和动态库
Linux 静态库和动态库 | 爱编程的大丙 (subingwen.cn)
静态库
-
ar rcs命令用于创建静态库(archive),将一组目标文件(.o文件)打包成一个静态库文件(.a文件)。例如,如果要将一组目标文件
file1.o、file2.o和file3.o打包成一个名为libexample.a的静态库,可以使用以下命令:ar rcs libexample.a file1.o file2.o file3.o
这将创建一个名为
libexample.a的静态库文件,并将file1.o、file2.o和file3.o这三个目标文件添加到该静态库中。 -
在Linux中静态库以
lib作为前缀, 以.a作为后缀, 中间是库的名字自己指定即可, 即:libxxx.a -
在Windows中静态库一般以
lib作为前缀, 以lib作为后缀, 中间是库的名字需要自己指定, 即:libxxx.lib -
发布和使用静态库
# 发布静态库 1. 提供头文件 **.h 2. 提供制作出来的静态库 libxxx.a # 4. 编译的时候指定库信息 -L: 指定库所在的目录(相对或者绝对路径) -l: 指定库的名字, 掐头(lib)去尾(.a) ==> calc # -L -l, 参数和参数值之间可以有空格, 也可以没有 -L./ -lcalc $ gcc main.c -o app -L ./ -l calc # 查看目录信息, 发现可执行程序已经生成了 $ tree . ├── app # 生成的可执行程序 ├── head.h ├── libcalc.a └── main.c
动态库
-
将源文件进行汇编操作, 需要使用参数 -c, 还需要添加额外参数 -fpic / -fPIC
# 得到若干个 .o文件 #表示生成位置无关代码(Position Independent Code),通常用于动态链接库的编译 $ gcc 源文件(*.c) -c -fpic #-shared 指定生成动态库 gcc -shared 与位置无关的目标文件(*.o) -o 动态库(libxxx.so)
-
在Linux中动态库以
lib作为前缀, 以.so作为后缀, 中间是库的名字自己指定即可, 即:libxxx.so -
在Windows中动态库一般以
lib作为前缀, 以dll作为后缀, 中间是库的名字需要自己指定, 即:libxxx.dll
静态库优缺点
-
优点:
-
静态库被打包到应用程序中加载速度快
-
发布程序无需提供静态库,移植方便
-
-
缺点:
-
相同的库文件数据可能在内存中被加载多份, 消耗系统资源,浪费内存
-
库文件更新需要重新编译项目文件, 生成新的可执行程序, 浪费时间。
-
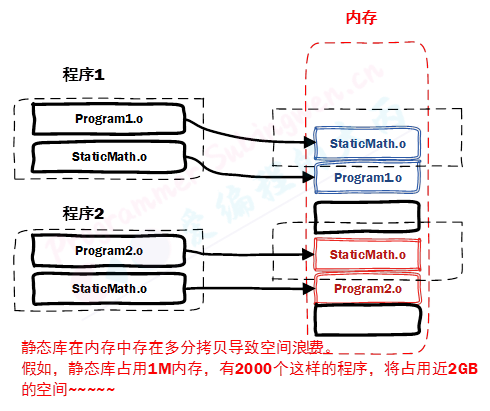
动态库优缺点
-
优点:
-
可实现不同进程间的资源共享
-
动态库升级简单, 只需要替换库文件, 无需重新编译应用程序
-
程序猿可以控制何时加载动态库, 不调用库函数动态库不会被加载
-
-
缺点:
-
加载速度比静态库慢, 以现在计算机的性能可以忽略
-
发布程序需要提供依赖的动态库
-
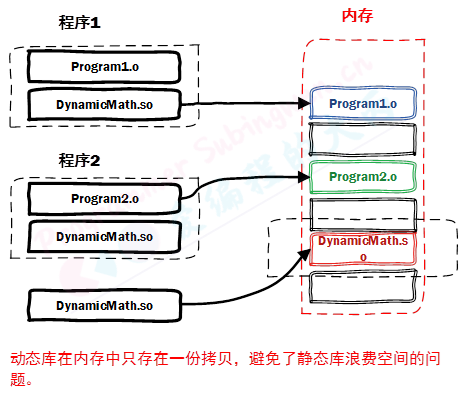
06.软连接和硬链接
#创建硬链接,创建硬链接后,文件的硬链接计数+1
ln /home/book/Desktop/test.txt hard_link
#创建软链接
ln -s /home/book/Desktop/test.txt soft_link
book@100ask:~/Desktop$ ls -l test.txt
-rw-rw-r-- 2 book book 11 Feb 26 16:38 test.txt
book@100ask:~/Desktop/linuxCMD$ ls -l
total 4
-rw-rw-r-- 2 book book 11 Feb 26 16:38 hard_link
lrwxrwxrwx 1 book book 27 Feb 26 16:39 soft_link -> /home/book/Desktop/test.txt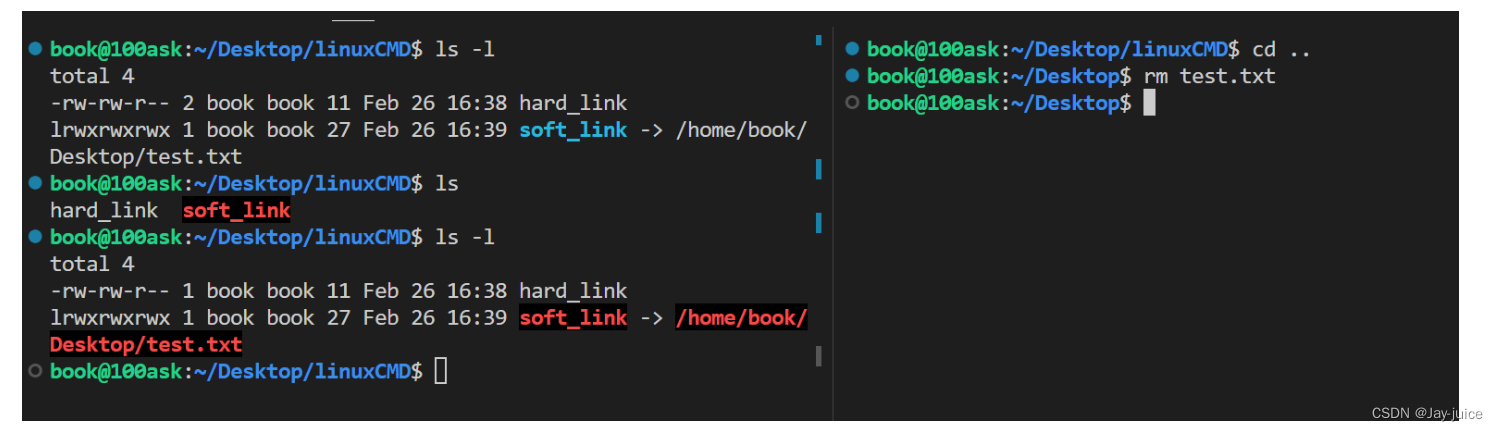
链接:是给系统中已有的某个文件指定另外一个可用于访问它的名称,链接也可以指向目录。即使我们删除这个链接,也不会破坏原来的文件或目录。 硬链接是指多个文件名指向同一个物理文件。当创建硬链接时,不会在磁盘上创建新的数据块,而是将已有文件的索引节点(inode)复制一份,新文件名指向该索引节点。因此,多个硬链接文件实际上是同一个文件,它们在磁盘上占用的空间是相同的。硬链接只能针对文件,不能针对目录。 软链接又称符号链接,是指一个文件名指向另一个文件名,而不是物理文件。创建软链接时,在磁盘上创建一个新的数据块,其中包含指向目标文件名的路径信息。因此,软链接实际上是一个文件,它的内容是目标文件的路径,软链接可以针对文件或目录。 与硬链接不同,软链接是一个新文件,在磁盘上占用的空间比较小,但是因为需要额外的寻址操作,访问速度相对较慢。同时,当目标文件被删除或移动时,软链接会失效。
硬链接不是一个独立文件,他和目标文件使用的是同一个inode
软连接是一个独立文件,有自己独立的inode和inode编号
07.目录项和inode
目录项、inode、数据块 - Dazzling! - 博客园 (cnblogs.com)
大部分的Linux文件系统(如ext2、ext3)规定,一个文件由目录项、inode和数据块组成:
-
目录项:包括文件名和inode节点号,用于建立文件名和文件的
inode号之间的映射关系 -
inode:又称文件索引节点,包含文件的基础信息(如文件类型、权限、所有者、所属组、大小、创建时间、修改时间等)以及数据块的指针。
-
数据块:包含文件的具体内容。
inode和硬链接:一般情况下,文件名和inode号码是"一一对应"关系,每个inode号码对应一个文件名。但是,Unix/Linux系统允许,多个文件名指向同一个inode号码。这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为"硬链接"(hard link)。
inode和软连接:文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的"软链接"(soft link)或者"符号链接(symbolic link)。这意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错:"No such file or directory"。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode"链接数"不会因此发生变化。
在 Linux 中,文件的删除是通过删除该文件的目录项实现的。当一个文件被删除时,文件系统会将其对应的目录项从目录中删除,并将该文件的链接数减少 1。只有在该文件的链接数降为 0 之后,操作系统才会将该文件的数据块从磁盘上彻底清除。所谓的删除文件,就是删除inode,但是数据其实还是在硬盘上,以后会覆盖掉。

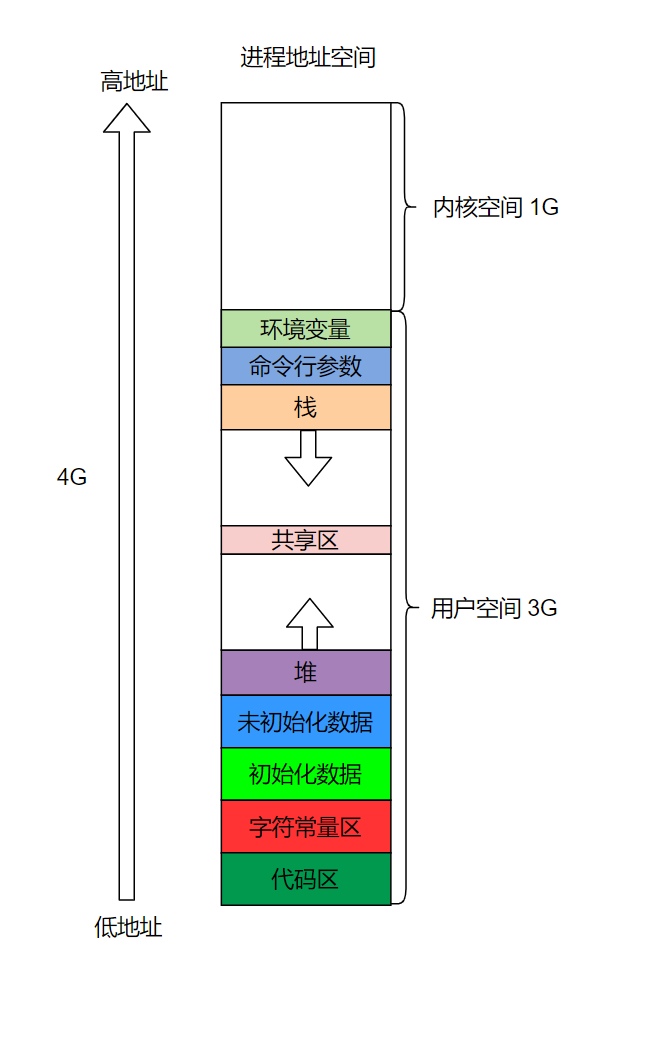
08.进程地址空间
09.进程之父子进程的关系
在 Unix/Linux 系统编程中,fork() 函数是一个创建新进程的系统调用。调用 fork() 函数时,操作系统会复制当前进程(称为父进程),并创建一个新的子进程。父进程和子进程在调用 fork() 函数后会继续执行下面的代码,但是它们各自拥有自己独立的内存空间和资源。
具体来说,fork() 函数的行为如下:
-
在父进程中,
fork()返回新创建子进程的进程 ID(PID),这个 PID 是一个正整数; -
在子进程中,
fork()返回 0; -
如果
fork()失败,则返回一个负值。
父子进程相同处: 全局变量、.data、.text、栈、堆、环境变量、用户ID、宿主目录、进程工作目录、信号处理方式 父子进程不同之处: 进程ID、fork返回值、父进程ID,进程运行时间、定时器、未决槽信号 父子进程间遵循读时共享写时复制的原则,节省内存开销。
#include <stdio.h>
#include <unistd.h>
int main() {
int x = 10;
pid_t pid = fork();
if (pid == 0) {
// 子进程
printf("Child process: x = %d\n", x);
x = 20;
printf("Child process: Modified x = %d\n", x);
} else if (pid > 0) {
// 父进程
printf("Parent process: x = %d\n", x);
x = 30;
printf("Parent process: Modified x = %d\n", x);
} else {
// fork() 失败
fprintf(stderr, "Fork failed.\n");
return 1;
}
return 0;
}
/*
Parent process: x = 10
Parent process: Modified x = 30
Child process: x = 10
Child process: Modified x = 20
*/10.孤儿进程、僵尸进程和守护进程
孤儿进程、僵尸进程和守护进程是操作系统中常见的进程状态,它们分别具有不同的特征和含义。
-
孤儿进程:当一个子进程的父进程退出或者意外终止,而子进程本身还在运行,此时子进程就成为孤儿进程。孤儿进程会被 init 进程(在 Unix 系统中通常是 PID 为 1 的进程)接管,并由 init 进程负责回收其所占用的系统资源。
-
僵尸进程:所谓僵尸进程,就是当子进程退出时,父进程尚未结束,而父进程又没有对已经结束的子进程进行回收。此时,这样的子进程就成了僵尸进程。僵尸进程会占用系统资源,因此需要及时被回收。父进程可以通过 wait() 或 waitpid() 等系统调用来等待子进程退出并回收其资源,防止子进程成为僵尸进程。
-
守护进程:守护进程是在后台运行的一种特殊进程,通常用于在系统启动时就开始运行,并在系统关闭时停止运行。守护进程通常脱离终端控制,以避免受用户登录或注销的影响。经典的例子包括网络服务进程、系统监控进程等。
11.wait()/waitpid()
wait() 和 waitpid() 是用于等待子进程结束并获取其终止状态的系统调用。它们可以避免僵尸进程的产生,确保子进程的资源得到正确回收。
wait() 是最简单的等待子进程结束的系统调用,其原型如下:
pid_t wait(int *status);
-
参数
status是一个指向整型的指针,用于存储子进程的终止状态信息。如果不关心子进程的终止状态,可以将status设置为 NULL。 -
返回值是终止的子进程的进程 ID,如果没有子进程或者出错,则返回 -1。
当调用 wait() 后,如果有一个或多个子进程已经终止,那么它会立即返回并回收其中一个已终止子进程的资源,并将子进程的终止状态存储在 status 中。如果没有已终止的子进程,那么调用进程会被阻塞,直到有一个子进程终止为止。
waitpid() 具有比 wait() 更灵活的特性,可以指定等待的子进程和等待的选项,其原型如下:
pid_t waitpid(pid_t pid, int *status, int options);
-
参数
pid指定要等待的子进程的进程 ID,具体取值意义如下:-
pid > 0:等待进程 ID 为 pid 的子进程。
-
pid == -1:等待任意子进程。
-
pid == 0:等待与调用进程属于同一进程组的任意子进程。
-
pid < -1:等待进程组 ID 等于 pid 绝对值的任意子进程。
-
-
参数
status用于存储子进程的终止状态信息。 -
参数
options可以指定一些附加选项,如 WNOHANG(非阻塞)、WUNTRACED(包括被暂停的子进程)等。 -
返回值与
wait()类似,为终止的子进程的进程 ID。
waitpid() 提供了更细粒度的控制,可以选择等待特定的子进程,也可以设置非阻塞模式,以及等待被暂停的子进程等。
12.线程与进程
线程和进程之间的主要区别是,进程是资源分配的最小单位,线程是操作系统调度执行的最小单位。。进程可以包含多个线程,但每个线程都有自己的执行上下文和调用栈,使得它们可以并行执行不同的任务。这使得线程更加轻量级和高效,因为它们不需要像进程那样在内存中维护独立的地址空间和系统资源。
-
进程有自己独立的地址空间, 有独立的 pcb,多个线程共用同一个地址空间
-
在一个地址空间中多个线程独享: 每个线程都有属于自己的栈区, 寄存器(内核中管理的)
-
在一个地址空间中多个线程共享: 代码段, 堆区, 全局数据区, 打开的文件(文件描述符表)都是线程共享的
进程与线程的选择取决以下几点: 1、需要频繁创建销毁的优先使用线程;因为对进程来说创建和销毁一个进程代价是很大的。 2、线程的切换速度快,所以在需要大量计算,切换频繁时用线程,还有耗时的操作使用线程可提高应用程序的响应。 3、多进程可以使用在多机分布式系统,需要扩展到其他机器上,使用多进程,多线程适用于多核处理机。 4、需要更稳定安全时,适合选择进程;需要速度时,选择线程更好
进程有独立的堆区和栈区,线程共享进程的堆区但拥有独立的栈区,协程是一种用户态的轻量级线程。在一个用户线程上可以跑多个协程,这样就提高了单核的利用率。协程不是被操作系统内核所管理,而完全是由程序所控制。
为什么有了进程还需要线程和协程?
尽管进程提供了资源隔离和独立的执行环境,但它们的创建和管理相对较重,不适用于需要频繁交互或共享状态的场景。线程作为轻量级的进程,提供了更快的上下文切换和高效的资源共享,使得在同一进程内可以有多个并发执行流。然而,线程的调度仍然受操作系统控制,可能涉及到用户态和内核态的切换开销。
协程进一步降低了并发编程的复杂度和开销,因为它完全是在用户态下使用的,尤其在 I/O 密集型任务和微服务架构中表现出色,它们提供了更细粒度的操作和更高效的CPU利用率。由于这些优势,现代编程语言和框架越来越多地采用协程来处理并行和异步任务。
14.什么是 inode、block、sector
Sector(扇区):文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
block(块):操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector 组成一个 block。
inode(索引):文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做 inode,中文译名为"索引节点"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
15.linux内核同步方式
在 Linux 内核中,为了实现多个进程或线程之间的同步,以及对共享资源的访问控制,提供了多种同步方式。以下是一些常见的 Linux 内核同步方式:
-
互斥锁(Mutex):互斥锁是最基本的同步原语之一,用于保护共享资源免受并发访问的影响。只有一个进程或线程可以持有互斥锁,其他进程或线程必须等待锁的释放才能访问共享资源。在 Linux 内核中,互斥锁由
mutex结构体表示,可以使用mutex_lock()和mutex_unlock()函数来获取和释放锁。 -
读写锁(ReadWrite Lock):读写锁允许多个读操作同时进行,但只允许一个写操作进行。这样可以提高读操作的并发性能。在 Linux 内核中,读写锁由
rwlock_t结构体表示,可以使用read_lock()、read_unlock()、write_lock()和write_unlock()函数来获取和释放锁。 -
自旋锁(Spin Lock):自旋锁是一种忙等待的锁,当无法获取锁时,进程或线程会一直循环尝试获取锁,而不会睡眠。自旋锁适用于锁的持有时间很短的情况下。在 Linux 内核中,自旋锁由
spinlock_t结构体表示,可以使用spin_lock()和spin_unlock()函数来获取和释放锁。 -
信号量(Semaphore):信号量是一种计数器,用于控制对共享资源的并发访问。在 Linux 内核中,信号量由
struct semaphore结构体表示,可以使用sema_init()、down()和up()函数来初始化、获取和释放信号量。 -
睡眠与唤醒机制:内核中的进程或线程可以通过调用
sleep()或者等待某个条件满足来睡眠,然后通过调用wake_up()或者满足条件时唤醒其他进程或线程。这种方式适用于需要等待某个事件发生的场景。
16.进程间通信方式
-
管道 (Pipe):
-
无名管道(匿名管道):主要用于有亲缘关系的进程之间的通信(例如,父子进程)。数据是单向流动的。
-
命名管道(FIFO):允许无亲缘关系的进程之间通信,它在文件系统中有一个名字。
-
-
信号 (Signal):一种用于通知接收进程某个事件已经发生的简单机制。
-
消息队列 (Message Queue):允许一个或多个进程向另一个进程发送格式化的数据块。数据块在消息队列中按照一定的顺序排列。
-
共享内存 (Shared Memory):让多个进程共享一个给定的存储区,是最快的IPC方式,因为数据不需要在进程间复制。
-
信号量 (Semaphore):主要用于同步进程间的操作,而不是传递数据,但通过控制资源的访问,它可以作为通信的一种手段。
-
套接字 (Socket):提供网络通信的机制,可用于不同机器上的进程间通信,也可以在同一台机器上的进程之间进行通信。
17.线程间通信方式
-
共享内存:线程可以直接访问进程的内存空间。共享数据的访问通常需要同步机制来防止出现竞态条件。
-
互斥锁:用于控制对共享资源的访问,保证在同一时间只有一个线程访问共享资源。
-
读写锁:允许多个线程同时读取一个资源,但写入时需要独占访问。
-
条件变量:允许一个或多个线程在某个条件发生前处于睡眠状态,等待另一个线程在该条件上发出通知或广播。
-
信号量:可以用于限制对共享资源的访问,也用于线程间的同步。
18.Linux信号
Linux操作系统中常见的信号有
-
SIGHUP:挂起进程
-
SIGINT:中断进程
-
SIGQUIT:退出进程和生成核心文件
-
SIGILL:非法指令
-
SIGTRAP:跟踪/断点陷阱
-
SIGABRT:异常终止
-
SIGBUS:总线错误
-
SIGFPE:浮点异常
-
SIGKILL:ss进程,该信号不能被阻塞,处理或忽略,一旦接收就会ss进程
-
SIGUSR1、SIGUSR2:用户自定义信号
-
SIGSEGV:无效内存引用
-
SIGPIPE:管道破碎:写到一个没有读者的管道
-
SIGALRM:实时定时器超时
-
SIGTERM:终止进程
-
SIGCHLD:子进程已经停止或终止
-
SIGCONT:如果进程已经停止,那么继续运行进程
-
SIGSTOP:停止执行进程
-
SIGTSTP、SIGTTIN、SIGTTOU:停止进程的运行
一个进程接收到一个信号后,可以有三种方式处理
-
忽略这个信号。
-
捕捉这个信号。一旦一个进程决定要捕捉某种信号,就需要提供一个函数,这个函数被称为信号处理程序。当这种信号发给该进程时,内核就运行该信号处理程序。
-
执行默认操作。
系统如何将一个信号通知到进程
-
内核会修改进程上下文信息,并设置标识表明收到信号。
-
当进程再次被调度执行时,它会先检查是否有未处理的信号,如果有,就调用相应的信号处理函数。
-
如果没有为该信号指定处理函数或者信号被阻塞,那么就执行系统默认的操作,可能是忽略、停止进程或者终止进程等。
19.标准库和系统调用
-
来源:
-
系统调用:这些函数来自操作系统内核。它们是操作系统提供给应用程序直接访问硬件和系统资源的基础界面,例如读写文件、发送网络数据、创建进程等。
-
标准库函数:这些函数是由C语言(或其他语言)运行时环境提供的,例如printf、strcpy、malloc等。
-
-
实现:
-
系统调用:由操作系统内核代码实现,当一个进程执行系统调用时,它需要切换到内核模式来运行特权代码。
-
标准库函数:通常使用用户模式下的普通代码实现,并且可能在其内部使用系统调用以提供其功能。
-
-
性能:
-
系统调用:因为涉及用户空间到内核空间的上下文切换,所以相比于标准库函数,系统调用通常会有更高的开销。
-
标准库函数:也可能引入一定的性能开销,如果它们内部使用了系统调用,但如果只是在用户空间进行计算,那么它们的开销就会小得多。
-
-
可移植性:
-
系统调用:通常依赖于特定的操作系统,所以在不同操作系统之间的可移植性较差。
-
标准库函数:大多数情况下,标准库函数在各种平台上的行为都是一致的,所以具有更好的可移植性。
-
库函数在用户地址空间执行,系统调用是在内核地址空间执行,库函数运行时间属于用户时间,系统调用属于系统时间,库函数开销较小,系统调用开销较大
-
库函数是有缓冲的,系统调用是无缓冲的
-
库函数并不依赖平台,库函数调用与系统无关,不同的系统,调用库函数,库函数会调用不同的底层函数实现,因此可移植性好。系统调用依赖平台
-
20.什么是PCB
PCB 它是操作系统中用于存储关于进程信息的一个重要数据结构。PCB 是操作系统用来管理和跟踪进程状态的一种方式,确保进程能够有序地执行和切换。
通常包含以下信息:
-
进程标识符(PID):一个唯一的标识号,用于区分不同的进程。
-
进程状态:如就绪、运行、等待、终止)等。
-
程序计数器:指向进程下一个要执行的指令地址。
-
CPU 寄存器信息:保存进程被中断或切换时,CPU 寄存器中的数据,以便恢复时可以继续执行。
-
CPU 调度信息:包括进程优先级、调度队列指针和其他调度参数。
21.进程终止方式
进程终止通常有以下几种方式:
-
正常退出(自愿):当进程完成其任务后,它会自动结束并释放其占用的资源。这是最常见的进程结束方式。
-
错误退出(自愿):如果进程在执行过程中遇到无法处理的错误情况,比如除零操作、访问非法内存地址等,它可能会选择主动终止。
-
致命错误(强制):当进程发生严重错误,如段错误(segmentation fault),或者操作系统检测到一个不能允许进程继续运行的状态(例如保护性错误)时,操作系统将强制结束这个进程。
-
被其他进程杀死(强制):在UNIX/Linux系统中,进程可以接收到来自其他进程的信号,其中一些信号可以导致进程结束,如SIGKILL和SIGTERM。管理员或具有足够权限的用户可以使用kill命令发送这样的信号以结束进程。
-
父进程终止(强制):在某些系统中,如果父进程结束,那么它的所有子进程也将被终止
22.什么是线程池
线程池是一种常见的多线程并发编程技术,它是一组线程的集合,这些线程预先创建并初始化,并被放入一个队列中等待任务。当有新任务到来时,线程池中的某个线程会被唤醒并处理该任务,任务处理完后,线程又会回到线程池中等待下一次任务。通过线程池技术,我们可以实现高效、可伸缩的并发处理,提高系统的并发处理能力,降低系统的开销和复杂度。 线程池的主要组成部分包括任务队列、线程池管理器和工作线程。任务队列用于存储所有需要处理的任务,线程池管理器用于管理线程池的创建、销毁和线程的调度等操作,工作线程则是线程池中的执行单位,它们从任务队列中取出任务并执行任务。线程池通常采用预创建线程的方式,通过线程复用的方式避免了线程频繁创建和销毁所带来的开销。
23.分页和分段、内存碎片
Linux 内存管理 | 地址映射:分段、分页、段页_地址映射,分页式-CSDN博客
-
目标:分页的设计目的主要是为了简化内存管理和消除外部碎片;而分段则旨在反映程序的逻辑结构,使之与物理内存分配相匹配。
-
灵活性:分段提供了更多的灵活性,允许程序自然地划分为意义不同的部分;分页则主要关注于内存的有效利用。
-
易用性:分页对于程序员来说是透明的,更易于使用;分段则要求程序员有更多的内存管理责任。
-
分段:内存碎片以及交换效率低。
内存碎片:是指分布在内存中的未被充分利用的零散内存块。它可能出现在动态内存分配过程中,导致内存利用率降低,甚至影响系统性能。内存碎片分为两种类型:外部碎片和内部碎片。
外部碎片:是指由于动态内存分配和释放过程中,导致剩余的未分配内存块被零散占据,无法满足大块内存的需求。虽然总的空闲内存足够,但无法分配连续的内存空间。
内部碎片:是指已经分配给进程的内存块中,存在着未被充分利用的空间。
内存碎片的产生原因:
-
频繁的内存分配和释放:过度频繁的内存分配和释放操作会导致内存块的零散分布,增加外部碎片的概率。
-
内存对齐要求:某些系统和硬件要求内存地址对齐,导致分配的内存块大小超过实际需要,产生内部碎片。
-
内存泄漏:未释放的内存占用会导致内存的不连续分布,增加外部碎片。
预防和处理内存碎片
-
使用对象池或内存池:对象池是一种预分配一定数量的对象并重复使用的技术。通过避免频繁的内存分配和释放,可以降低内存碎片的产生。
-
合理选择内存分配策略:根据应用场景和数据特点,选择合适的内存分配策略,例如使用固定大小的内存块或动态调整内存块大小。
-
避免频繁的内存分配和释放:尽量减少不必要的内存分配和释放操作,可以通过对象复用、对象缓存等方式来减少内存碎片的产生。
-
使用内存池和自定义内存管理器:通过自定义内存管理器,可以实现更加灵活和高效的内存分配和释放策略,从而降低内存碎片的风险
-
解决外部内存碎片的问题就是内存交换。可以把音乐程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里。不过再读回的时候,我们不能装载回原来的位置,而是紧紧跟着那已经被占用了的 512MB 内存后面。这样就能空缺出连续的 256MB 空间,于是新的 200MB 程序就可以装载进来。硬盘的访问速度要比内存慢太多
24.Linux虚拟内存管理
Linux 内存管理 详解(虚拟内存、物理内存,进程地址空间)_linux内存管理-CSDN博客
Linux内核学习笔记3——分段机制和分页机制 - LOSER Z - 博客园 (cnblogs.com)
在Linux中,通过分段和分页的机制,将物理内存划分为4k大小的内存页(page),并且将页作为物理内存分配与回收的基本单位。通过分页机制我们可以灵活的对内存进行管理。
如果直接使用物理内存,通常都会面临以下几种问题
-
内存缺乏访问控制,安全性不足
-
各进程同时访问物理内存,可能会互相产生影响,没有独立性
-
物理内存极小,而并发执行进程所需又大,容易导致内存不足
-
进程所需空间不一,容易导致内存碎片化问题。
基于以上几种原因,Linux通过mm_struct结构体来描述了一个虚拟的,连续的,独立的地址空间,也就是我们所说的虚拟地址空间。
在内存管理中,常见的几种技术包括内存分页、内存分段以及它们的结合形式——段页式。
25.GDB
-
GDB 编译
gcc -g program.c -o program
-
GDB 启动、退出
#启动语法: gdb + 可执行文件 gdb program #退出 quit/q
-
GDB 调试命令
start #程序停在第一行
run #遇到断点才停
c/continue #继续运行
n/next #逐行运行(不会进入函数体)
#逐行调试(遇函数进入函数体),在 GDB 中,step 命令用于执行程序的下一步,并且如果当前行是一个函数调用,则会进入到该函数内部执行。与 next 命令不同,step 命令会进入到函数内部执行,并逐行执行其中的代码。
s/step
finish(跳出函数体)
list: 显示当前执行点周围的代码。
list <function_name>: 显示指定函数的代码。
list <line_number>: 显示指定行号的代码
b <line_number>: 在指定行号处设置断点。
b <function_name>: 在指定函数的入口处设置断点。
b <file_name>:<line_number>: 在指定文件的指定行号处设置断点。
info breakpoints 命令(简写为 i b)用于显示当前设置的所有断点信息,包括断点号、断点位置、断点类型、是否启用、条件等。
#使用 GDB 调试 core 文件
#确保生成了 core 文件: 在程序崩溃时,通常会生成一个 core 文件,其中包含了程序崩溃时的内存状态。确保你的程序生成了 core 文件,否则你将无法使用 GDB 进行调试。你可以通过设置 ulimit -c unlimited 来确保生成 core 文件,或者在程序中使用 setrlimit 函数进行设置
#启动 GDB: 在终端中启动 GDB,并指定要调试的可执行文件和 core 文件,例如:
gdb /path/to/your/executable /path/to/corefile
#gdb调试正在运行的程序
#1、获取正在运行程序的进程ID(PID)
#2、启动 GDB 并附加到进程:gdb -p PID。
#3、开始调试: 一旦 GDB 附加到了正在运行的程序的进程上,你就可以像平常一样使用 GDB 进行调试了。你可以设置断点、查看变量、单步执行等操作,来分析程序的行为和调试问题。
#4、分离 GDB: 在调试结束后,你可以使用 detach 命令将 GDB 从正在运行的程序的进程上分离出来,让程序继续正常运行。命令格式为 detach。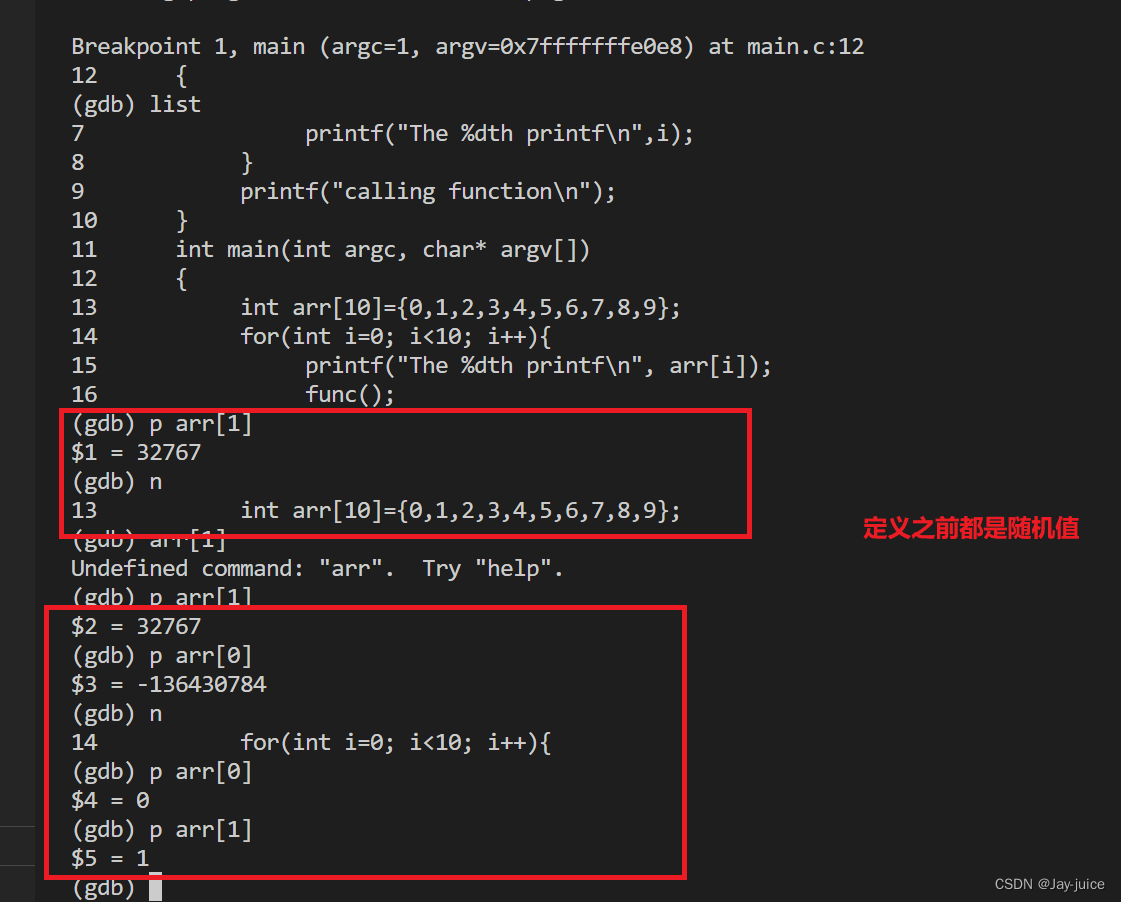
26.grep/sed/awk
-
grep
#在文件中搜索包含指定字符串的行 grep "pattern" file.txt #忽略大小写进行搜索 grep -i "pattern" file.txt #显示匹配行的行号 grep -n "pattern" file.txt #统计匹配的行数 grep -c "pattern" file.txt #-e :实现多个选项间的逻辑or 关系 - -A<显示行数>:除了显示符合范本样式的那一列之外,并显示该行之后的内容。 - -B<显示行数>:除了显示符合样式的那一行之外,并显示该行之前的内容。 - -C<显示行数>:除了显示符合样式的那一行之外,并显示该行之前后的内容。
-
sed
sed是一个流编辑器,用于对文本进行处理和转换。它主要用于对文件中的文本进行替换、删除、插入等操作。以下是一些sed命令的常见用法示例:-
替换文本:
sed 's/pattern/replacement/g' file.txt
这将在文件
file.txt中查找匹配字符串 "pattern" 的所有实例,并用 "replacement" 替换它们。 -
删除行:
sed '/pattern/d' file.txt
这将删除文件
file.txt中包含字符串 "pattern" 的所有行。 -
插入行:
sed '3i\new_line' file.txt
这将在第三行之前插入新行 "new_line"。
-
打印指定行:
sed -n '5p' file.txt
这将打印文件
file.txt中的第五行。 -
批量处理多个文件:
sed -i 's/pattern/replacement/g' *.txt
这将在当前目录下的所有
.txt文件中查找匹配字符串 "pattern" 的所有实例,并用 "replacement" 替换它们。
-
-
awk
awk的基本语法结构如下:awk 'pattern { action }' input-file-
pattern模式部分用于筛选要处理的行,类似于条件语句。如果省略模式部分,则所有行都会被匹配。 -
{ action }动作部分定义了对匹配行执行的操作,包括打印、计算、赋值等。 -
input-file是要处理的输入文件名。
在
awk中,还可以使用以下特殊变量:-
$0:代表整个当前行。 -
$1,$2, ...:代表当前行的第一个、第二个字段,依此类推。 -
NR:代表当前处理的行号。 -
NF:代表当前行的字段数量。
除了基本语法外,
awk还支持各种内置函数和运算符,可以进行字符串操作、数学计算等。例如:-
字符串连接:
$1 $2 -
算术操作:
$1 + $2 -
内置函数:
length($1)(返回字段$1的长度)
#!/bin/bash # 获取本地 IP 地址 ip_address=$(hostname -I | awk '{print $1}') search_text="local_ip =" replace_text="local_ip = "$ip_address file_path="/home/pi/frp_0.24.1_linux_arm/frpc.ini" echo $file_path # 使用 sed 命令替换文件中包含指定字符的一行 sed -i "s/.*$search_text.*/$replace_text/g" $file_path current_time=$(date +"%Y-%m-%d %H:%M:%S") echo "#"$current_time >> $file_path -
27.shell
Shell 脚本是一种用来编写一系列 Shell 命令的脚本文件,通常以 .sh 为扩展名。Shell 脚本可以在命令行中执行,用于自动化完成各种任务。下面是一些 Shell 脚本的基本语法要点:
-
指定 Shell 解释器
在 Shell 脚本的第一行通常需要指定要使用的 Shell 解释器,例如:
#!/bin/bash
这行代码告诉系统使用 Bash 解释器来执行该脚本。
-
环境变量
可以使用 # 符号开始的行来添加注释,这些注释会被解释器忽略。例如:
# Shell常见的变量之一系统变量,主要是用于对参数判断和命令返回值判断时使用,系统变量详解如下: $0 当前脚本的名称; $n 当前脚本的第n个参数,n=1,2,…9; $* 当前脚本的所有参数(不包括程序本身); $# 当前脚本的参数个数(不包括程序本身); $? 令或程序执行完后的状态,返回0表示执行成功; $$ 程序本身的PID号。 #Shell常见的变量之二环境变量,主要是在程序运行时需要设置,环境变量详解如下: PATH 命令所示路径,以冒号为分割; HOME 打印用户家目录; SHELL 显示当前Shell类型; USER 打印当前用户名; ID 打印当前用户id信息; PWD 显示当前所在路径; TERM 打印当前终端类型; HOSTNAME 显示当前主机名; PS1 定义主机命令提示符的; HISTSIZE 历史命令大小,可通过 HISTTIMEFORMAT 变量设置命令执行时间; RANDOM 随机生成一个 0 至 32767 的整数; HOSTNAME 主机名
#!/bin/bash
#""和''都可以
echo 'hello world'
#可以使用 '$'符号来引用变量的值
num=8848
#相当于字符串拼接
echo "num="$num
#可以使用反引号'' 或 $() 来执行命令并获取其输出
cur_time=$(date +"%Y-%m-%d %H:%M:%S")
echo $cur_time
#当前脚本的名称
echo 'cur shell name: '$0
#环境变量,必须大写
echo 'cur pwd:'$PWD
echo 'cur user:'$USER
echo 'cur hostname:'$HOSTNAME
echo 'cur shell:'$SHELL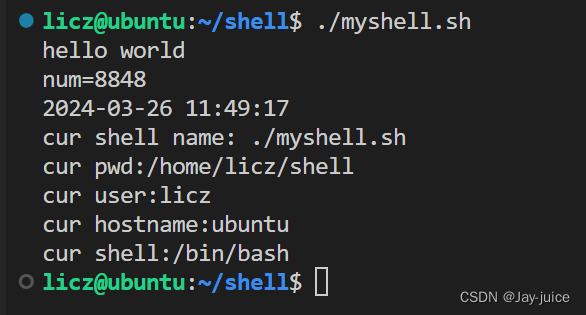
if语句
#!/bin/bash
SCORE=85
# If条件判断语句,通常以if开头,fi结尾。也可加入else或者elif进行多条件的判断
if [ $SCORE -ge 90 ]
then
echo "excellent"
elif [ $SCORE -ge 80 ]
then
echo "good"
elif [ $SCORE -ge 60 ]
then
echo "pass"
else
echo "fail"
fifor语句
#!/bin/bash
#1到10 步长为2
for i in {1..10..2}
do
echo "Number:$i"
done
#1到10 步长为2
for i in $(seq 1 2 10)
do
echo "Number: $i"
donewhile
#!/bin/bash
i=1
while [ $i -le 10 ]
do
echo "Number: $i"
#let 命令用于执行算术运算,并更新变量的值
let i=i+1
done28.vim
#打开文件,并将光标置于第 n 行的首部
vim +n a.c
#打幵文件,并将光标置于第一个与 pattern 匹配的位置
vim +/pattern a.c
#快速格式化代码
gg=G
#复制光标所在行,此命令前可以加数字 n,可复制多行
n yy
#以光标所在行为准(包含当前行),向下剪切指定行数
n dd
#p 将剪贴板中的内容粘贴到光标后
#P(大写) 将剪贴板中的内容粘贴到光标前
#查找:“/关键词”
/abc #从光标所在位置向前查找字符串 abc
/^abc #查找以 abc 为行首的行
/abc$ #查找以 abc 为行尾的行29.快表
快表,又称联想寄存器(TLB),是一种访问速度比内存快很多的高速缓冲存储器,用来存放当前访问的若干页表项,以加速地址变换的过程。
多级页表虽然解决了空间占用大的问题,但是由于其复杂化了地址的转换,因此也带来了大量的时间开销,使得地址转换速度减慢。我们将最常访问的几个页表项存储到TLB中,在之后进行寻址时,CPU就会先到TLB中进行查找,如果没有找到,这时才会去查询页表。
30.dup/dup2
dup函数的原型为int dup(int oldfd);
该函数的作用是,返回一个新的文件描述符(可用文件描述符的最小值)newfd,并且新的文件描述符newfd指向oldfd所指向的文件表项。如以下调用形式:int newfd = dup(oldfd)
up2函数原型为int dup2(int oldfd,int newfd);
dup函数是返回一个最小可用文件描述符newfd,并让其与传入的文件描述符oldfd指向同一文件表项;
而dup2则是直接让传入的参数newfd与参数oldfd指向同一文件表项,如果newfd已经被open过,那么就会先将newfd关闭,然后让newfd指向oldfd所指向的文件表项,如果newfd本身就等于oldfd,那么就直接返回newfd。因此,传入的newfd既可以是open过的,也可以是一个任意非负整数,总之,dup2函数的作用就是让newfd重定向到oldfd所指的文件表项上,如果出错就返回-1,否则返回的就是newfd。
31.锁
互斥锁(Mutex Lock)是一种用于保护共享资源不被并发访问的同步机制。当线程需要访问共享资源时,首先会尝试获取互斥锁。如果该互斥锁已被其他线程获取,则线程会被阻塞,直到该互斥锁被释放为止。一旦线程获取到了互斥锁,就可以访问共享资源,并在完成操作后释放互斥锁,以允许其他线程访问该资源。
读写锁(Read-Write Lock)是一种特殊的锁机制,它允许多个线程同时读取共享资源,但在有线程写入时会进行排他性访问。这种锁的目的是提高并发性能,因为在大多数情况下,数据被读取的频率远远高于被写入的频率。读写锁分为读锁和写锁两种状态,多个线程可以同时持有读锁,但只有一个线程能够持有写锁。
自旋锁(Spin Lock)是一种基于忙等待的同步机制,在尝试获取锁时,线程会反复检查锁是否可用,而不是立即进入睡眠状态。这样可以避免线程进入睡眠状态带来的上下文切换开销,适用于临界区很小且线程持有锁的时间很短的情况。然而,如果临界区很大或者锁被长时间占用,自旋锁会造成大量的CPU资源浪费。
总结一下:
-
互斥锁适用于临界区较大的情况,它可以确保同时只有一个线程访问共享资源。
-
读写锁适用于读取操作远远多于写入操作的场景,它允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。
-
自旋锁适用于临界区很小,且线程持有锁的时间很短的情况,它可以避免线程进入睡眠状态所带来的开销。
32.原子操作
单核,多核CPU的原子操作 - LeonGo - 博客园 (cnblogs.com)
33.匿名管道
-
管道是半双工通信
-
管道生命随进程而终止
-
命名管道任意多个进程间通信
-
管道提供的是流式数据传输服务
-
管道自带 同步与互斥 机制
在C语言中,pipe() 函数用于创建一个管道,并返回两个文件描述符。这个函数的原型如下:
#include <unistd.h> int pipe(int pipefd[2]);// 其本质是一个伪文件(实为内核缓冲区)
pipefd[0] 将会指向管道的读取端,而 pipefd[1] 将会指向管道的写入端。如果 pipe() 函数成功执行,它将返回0,并将管道的文件描述符保存在 pipefd 数组中;否则,它将返回-1,并设置适当的错误码来指示错误的原因。
以下是一个简单的示例,演示如何使用 pipe() 函数创建一个管道:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
//这个示例中,父进程向子进程发送了一条消息,并等待子进程读取并处理该消息。
int main() {
int pipefd[2];
char buf[20];
pid_t pid;
// 创建管道
if (pipe(pipefd) == -1) {
perror("pipe");
exit(EXIT_FAILURE);
}
// 创建子进程
pid = fork();
if (pid == -1) {
perror("fork");
exit(EXIT_FAILURE);
}
if (pid == 0) { // 子进程
close(pipefd[1]); // 关闭写入端
read(pipefd[0], buf, sizeof(buf)); // 从管道读取数据
printf("Child process received: %s\n", buf);
close(pipefd[0]); // 关闭读取端
exit(EXIT_SUCCESS);
} else { // 父进程
close(pipefd[0]); // 关闭读取端
write(pipefd[1], "Hello, child process!", 22); // 向管道写入数据
close(pipefd[1]); // 关闭写入端
wait(NULL); // 等待子进程结束
exit(EXIT_SUCCESS);
}
return 0;
}管道的局限性:
① 数据自己读不能自己写。
② 数据一旦被读走,便不在管道中存在,不可反复读取。
③ 由于管道采用半双工通信方式。因此,数据只能在一个方向上流动。
④ 只能在有公共祖先的进程间使用管道。
34.有名管道
有名管道(named pipe),也称为FIFO(First In, First Out),是一种特殊类型的文件,用于进程间通信。相对于匿名管道,有名管道具有以下特点:
-
可以用于无血缘关系的进程间通信。
-
自带同步与互斥机制、数据单向流通
使用有名管道的基本步骤如下:
-
创建有名管道:使用
mkfifo()函数创建一个有名管道,并指定一个文件路径作为参数。 -
打开管道:使用
open()函数打开有名管道。打开管道时需要指定读取模式或写入模式。 -
读取和写入数据:对于读取端,使用
read()函数从管道中读取数据;对于写入端,使用write()函数向管道中写入数据。 -
关闭管道:使用
close()函数关闭管道。
以下是一个简单的示例,展示了如何使用有名管道进行进程间通信:
进程A:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
// 创建有名管道
mkfifo("/tmp/myfifo", 0666);
// 打开管道进行写入
int fd = open("/tmp/myfifo", O_WRONLY);
// 写入数据
char *message = "Hello from Process A";
write(fd, message, sizeof(message));
close(fd);
return 0;
}进程B:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
#define BUFFER_SIZE 1024
int main() {
// 打开管道进行读取
int fd = open("/tmp/myfifo", O_RDONLY);
// 读取数据
char buffer[BUFFER_SIZE];
read(fd, buffer, BUFFER_SIZE);
printf("Received message: %s\n", buffer);
close(fd);
return 0;
}在这个示例中,进程A创建了一个名为 "/tmp/myfifo" 的有名管道,并向管道中写入一条消息。进程B打开同样的管道,并从管道中读取并打印这条消息。
需要注意的是,有名管道的读取和写入是阻塞的操作。如果没有数据可读,读取操作将会被阻塞,直到有数据可读取。类似地,如果管道已满,写入操作将会被阻塞,直到有空间可以写入数据。因此,在实际使用中,需要合理处理管道的读取和写入操作,以避免阻塞导致的问题。
35.mmap
mmap 是一种在内存和文件之间创建映射的系统调用,它允许程序直接使用文件的内容,而无需进行显式的读取和写入操作。mmap 函数将文件映射到调用进程的地址空间,使得文件中的数据可以像访问内存一样被访问。这样做的好处是可以提高文件的访问效率,特别是对于大文件或需要随机访问的文件而言。
在使用 mmap 函数时,需要指定文件描述符、映射区域的大小、映射区域的权限和映射区域在进程地址空间中的位置等参数。mmap 函数的原型如下:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
-
addr:指定映射区域在进程地址空间中的起始地址,通常设置为NULL,由系统自动选择合适的地址。 -
length:指定映射区域的大小,以字节为单位。 -
prot:指定映射区域的保护方式,包括PROT_READ(可读)、PROT_WRITE(可写)、PROT_EXEC(可执行)等。 -
flags:指定映射的类型和其他标志,通常设置为MAP_SHARED(修改会反映到磁盘上,多个进程可以通过共享映射的方式,来共享同一个文件。这样一来,一个进程对该文件的修改,其他进程也可以观察到,这就实现了数据的通讯。)或MAP_PRIVATE(修改不反映到磁盘上)。 -
fd:指定要映射的文件描述符。 -
offset:指定文件中的偏移量,从该偏移量开始映射,必须是 4096 的整数倍。(MMU 映射的最小单位 4k )。
调用成功时,mmap 函数返回映射区域的起始地址;失败时,返回 MAP_FAILED。
下面是一个简单的示例,展示了如何使用 mmap 函数将文件映射到内存中,并对文件进行读取操作:
#include <stdio.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd;
struct stat sb;
char *file_data;
// 打开文件
fd = open("example.txt", O_RDONLY);
if (fd == -1) {
perror("open");
return 1;
}
// 获取文件信息
if (fstat(fd, &sb) == -1) {
perror("fstat");
return 1;
}
// 将文件映射到内存
file_data = mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
if (file_data == MAP_FAILED) {
perror("mmap");
return 1;
}
// 输出文件内容
printf("File content:\n%s\n", file_data);
// 释放映射区域
if (munmap(file_data, sb.st_size) == -1) {
perror("munmap");
return 1;
}
// 关闭文件
if (close(fd) == -1) {
perror("close");
return 1;
}
return 0;
}在这个示例中,程序打开名为 "example.txt" 的文件,使用 mmap 函数将文件映射到内存中,并输出文件的内容。最后,程序使用 munmap 函数释放映射区域,并关闭文件。
02.Linux网络编程
01.网络字节序
在计算机内部,数据的表示可以使用两种字节序,即大端字节序和小端字节序。大端字节序是指数据的高位字节存放在内存的低地址中,而小端字节序是指数据的低位字节存放在内存的低地址中。为了在网络上传输时保证数据的正确性,所有计算机都必须使用相同的字节序。在网络编程中,网络字节序被规定为大端字节序,无论计算机的实际字节序是大端还是小端,都必须将数据转换为网络字节序后再进行传输。
在网络编程中,常用的网络字节序是大端存储(Big Endian),也被称为网络字节序(Network Byte Order)。为了在不同字节序的系统之间进行通信,可以使用一些函数来进行字节序转换。
在C语言中,可以使用以下函数将本地字节序和网络字节序相互转换:
-
htons():将一个无符号短整型(16位)从主机字节序转换为网络字节序。 -
htonl():将一个无符号长整型(32位)从主机字节序转换为网络字节序。 -
ntohs():将一个无符号短整型从网络字节序转换为主机字节序。 -
ntohl():将一个无符号长整型从网络字节序转换为主机字节序。
以下是一个简单的示例代码,演示如何使用这些函数进行字节序转换:
#include <stdio.h>
#include <arpa/inet.h>
int main() {
unsigned short host_short = 0x1234;
unsigned long host_long = 0x12345678;
unsigned short network_short;
unsigned long network_long;
network_short = htons(host_short);
network_long = htonl(host_long);
printf("Host short: 0x%x\n", host_short);
printf("Network short: 0x%x\n", network_short);
printf("Host long: 0x%lx\n", host_long);
printf("Network long: 0x%lx\n", network_long);
return 0;
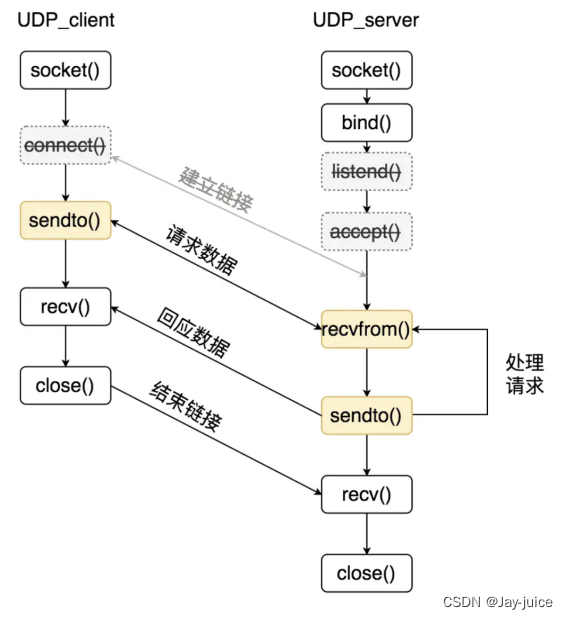
}02.socket编程
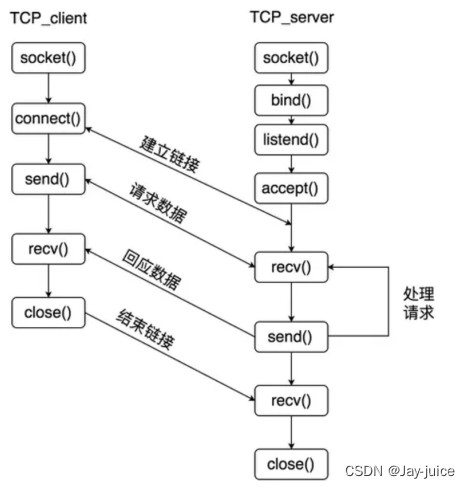
TCP编程流程
TCP客户端编程流程 1、cfd=socket(); 2、connect(cfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));//连接服务器 3、send()/recv() 4、close()TCP服务器编程流程 1、lfd=socket()//创建套接字 2、bind(lfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));//给服务器socket绑定地址结构(IP+port) 3、listen(lfd,128)//监听套接字 创建连接队列 4、cfd = accept(lfd, (struct sockaddr *)&clit_addr, &clit_addr_len); // 阻塞等待客户端连接请求 5、send()/recv() 6、close
//server.c
#define SERV_PORT 9527
#define BUF_SIZE 1024
int main(int argc, char *argv[])
{
struct sockaddr_in serv_addr, clit_addr; // 定义服务器地址结构 和 客户端地址结构
serv_addr.sin_family = AF_INET; // IPv4
serv_addr.sin_port = htons(SERV_PORT); // 转为网络字节序的 端口号
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY); // 获取本机任意有效IP
int lfd = socket(AF_INET, SOCK_STREAM, 0); //创建一个 socket
bind(lfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));//给服务器socket绑定地址结构(IP+port)
listen(lfd, 128); // 设置监听上限
socklen_t clit_addr_len = sizeof(clit_addr); // 获取客户端地址结构大小
int cfd = accept(lfd, (struct sockaddr *)&clit_addr, &clit_addr_len); // 阻塞等待客户端连接请求
char buf[BUF_SIZE];
printf("client ip:%s port:%d\n",
inet_ntop(AF_INET, &clit_addr.sin_addr.s_addr, buf, sizeof(buf)),
ntohs(clit_addr.sin_port)); // 根据accept传出参数,获取客户端 ip 和 port
while (1) {
memset(buf,0,sizeof(buf));
int ret = read(cfd, buf, sizeof(buf)); // 读客户端数据
printf("recv len=%d:",ret,buf); // 写到屏幕查看
}
close(lfd);
close(cfd);
return 0;
}//client.c
#define SERV_PORT 9527
#define BUF_SIZE 1024
#define SERV_ADDR 127.0.0.1
int main(int argc, char *argv[])
{
struct sockaddr_in serv_addr; //服务器地址结构
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(SERV_PORT);
//inet_pton(AF_INET, "127.0.0.1", &serv_addr.sin_addr.s_addr);
inet_pton(AF_INET,SERV_ADDR, &serv_addr.sin_addr);
int cfd = socket(AF_INET, SOCK_STREAM, 0);
connect(cfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
while (1) {
write(cfd, "hello\n", 6);
sleep(1);
}
close(cfd);
return 0;
}
多进程并发服务器:每个客户端请求都将创建一个新的进程,这个进程负责处理该客户端的请求。因为每个进程都是独立的,所以它们之间的内存空间是隔离的。这意味着在进程间共享数据需要使用进程间通信(IPC)技术,如管道、信号、共享内存、套接字等。由于进程切换的开销比较大因此多进程并发服务器的性能通常比多线程并发服务器要差。
多线程并发服务器:在多线程并发服务器中,每个客户端请求都将创建一个新的线程,这个线程负责处理该客户端的请求。由于所有线程都属于同一个进程,它们共享同一个地址空间,可以轻松地共享数据,不需要进行进程间通信。由于线程切换的开销比进程切换的开销小得多,因此多线程并发服务器的性能通常比多进程并发服务器要好。但是,多线程编程需要注意线程安全问题,例如数据共享、竞态条件、死锁等。
04.IO多路复用
IO多路复用是一种高效的IO操作方式,它可以同时监听多个文件描述符(socket)的可读、可写、异常等事件,并在有事件发生时通知应用程序进行处理。常见的IO多路复用机制有select、poll、epoll等。 在传统的IO模型中,每个文件描述符都需要对应一个线程来处理,这会导致系统资源的浪费和线程切换的开销。而使用IO多路复用机制,可以将多个文件描述符的IO事件集中到一个线程中处理,减少了系统调用和线程切换的次数,提高了系统的吞吐量和响应性能。
05.select()/poll()/epoll()
I/O 多路复用之select()、poll()、epoll()详解_io多路复用select poll epoll-CSDN博客
select/poll/epoll的相关面试题_select/poll/epoll面试题-CSDN博客
-
select模型:这是最古老的一种IO多路复用模型。它的主要功能是监视多个文件描述符(在网络编程中,文件描述符通常代表一个socket连接),直到其中一个文件描述符准备好进行某种IO操作(如读或写)为止。使用select模型的优点是跨平台性好,基本上所有的操作系统都支持。但是它有一些明显的缺点,如单个进程能够监视的文件描述符数量有限(通常是1024),处理效率较低(每次调用select都需要遍历所有的文件描述符),以及它不能随着连接数的增加而线性扩展。
-
poll模型:poll模型和select模型非常相似,但它没有最大文件描述符数量的限制。和select一样,poll每次调用时也需要遍历所有的文件描述符,同样不能随着连接数的增加而线性扩展。
-
epoll模型:这是一个在Linux 2.6及以后版本中引入的新型IO多路复用模型。与select和poll相比,epoll在处理大量并发连接时更高效。它默认使用了一个事件驱动的方式(ET),以红黑树作为底层的数据结构,只有当某个文件描述符准备好进行IO操作时,它才会将这个文件描述符添加到就绪列表中,这避免了遍历所有文件描述符的开销。另外,epoll没有最大文件描述符数量的限制,因此它可以处理更多的并发连接。
epoll相关函数
epoll 是 Linux 下一种高性能的事件通知机制,通常用于处理大量的文件描述符,比如网络套接字。它相比于传统的 select 和 poll 等方法,在处理大量文件描述符时有更好的性能表现。
以下是 epoll 相关的主要函数:
-
int epoll_create(int size):-
创建一个
epoll实例,并返回一个文件描述符用于后续操作。 -
size参数表示要监听的文件描述符数量的一个建议值,它并不是一个严格的限制。
-
-
int epoll_create1(int flags):-
类似于
epoll_create,但可以通过flags参数来设置一些额外的选项。 -
目前主要用于设置
EPOLL_CLOEXEC标志,以在执行exec系列函数时自动关闭文件描述符。
-
-
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event):-
对
epfd所指代的epoll实例进行控制操作,例如添加、修改或删除要监听的文件描述符。 -
op参数表示操作类型,可以是EPOLL_CTL_ADD、EPOLL_CTL_MOD或EPOLL_CTL_DEL。 -
fd参数是要操作的文件描述符。 -
event参数是一个struct epoll_event结构体指针,用于指定要监听的事件类型。
-
-
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout):-
等待
epfd所指代的epoll实例上的事件发生,并将发生的事件填充到events数组中。 -
maxevents参数表示events数组的最大容量,即最多可以返回多少个事件。 -
timeout参数表示等待事件的超时时间,单位为毫秒,传入-1表示无限等待。 -
函数返回发生事件的文件描述符数量,或者在超时时返回 0,出错时返回 -1。
-
-
struct epoll_event结构体:-
用于描述一个事件,定义如下:
struct epoll_event { uint32_t events; // 表示要监听的事件类型,如 EPOLLIN、EPOLLOUT 等 epoll_data_t data; // 与事件相关的数据,是一个联合体,可以是文件描述符或指针 };
-
在使用 epoll 的时候,有两种工作模式:水平触发(LT,Level-Triggered)和边缘触发(ET,Edge-Triggered)。
-
水平触发(LT):
-
在水平触发模式下,如果文件描述符上有数据可读或可写,
epoll_wait将会返回并报告这个事件。 -
如果文件描述符还有数据未读取完,或者还有缓冲区可写,则下次调用
epoll_wait时会再次返回就绪事件。 -
水平触发模式下,只要文件描述符处于就绪状态,
epoll_wait就会返回就绪事件,即使应用程序没有处理完就绪事件。
-
-
边缘触发(ET):
-
在边缘触发模式下,只有当文件描述符状态变化时,
epoll_wait才会返回并报告这个事件。 -
一旦文件描述符处于就绪状态并且应用程序已经对这个就绪事件进行了处理,下次调用
epoll_wait时,不会再次返回这个就绪事件,直到文件描述符状态再次发生变化。 -
边缘触发模式要求应用程序在处理就绪事件时必须尽快将文件描述符的数据读取完毕,或者将需要写入的数据写入完毕,否则下次调用
epoll_wait时可能不会再次返回就绪事件。
-
通常情况下,边缘触发模式比水平触发模式效率更高,因为它可以减少不必要的事件通知。但是,边缘触发模式要求应用程序对就绪事件进行更为及时和精确的处理,因为它不会保留就绪事件,而是只在状态变化时通知应用程序。
03.Linux内核
01.Linux内核5大功能
1、管理进程:内核负责创建和销毁进程, 并处理它们与外部世界的联系(输入和输出),不同进程间通讯(通过信号,管道,或者进程间通讯原语)对整个系统功能来说是基本的,也由内核处理。 另外, 调度器, 控制进程如何共享CPU,是进程管理的一部分。更通常地,内核的进程管理活动实现了多个进程在一个单个或者几个CPU 之上的抽象。
2、管理内存:计算机的内存是主要的资源, 处理它所用的策略对系统性能是至关重要的。内核为所有进程的每一个都在有限的可用资源上建立了一个虚拟地址空间。内核的不同部分与内存管理子系统通过一套函数调用交互,从简单的malloc/free对到更多更复杂的功能。
3、文件系统:Unix 在很大程度上基于文件系统的概念;几乎Unix中的任何东西都可看作一个文件。内核在非结构化的硬件之上建立了一个结构化的文件系统,结果是文件的抽象非常多地在整个系统中应用。另外,Linux 支持多个文件系统类型,就是说,物理介质上不同的数据组织方式。例如,磁盘可被格式化成标准Linux的ext3文件系统,普遍使用的FAT文件系统,或者其他几个文件系统。
4、设备控制:几乎每个系统操作终都映射到一个物理设备上,除了处理器,内存和非常少的别的实体之外,全部中的任何设备控制操作都由特定于要寻址的设备相关的代码来进行。这些代码称为设备驱动。内核中必须嵌入系统中出现的每个外设的驱动,从硬盘驱动到键盘和磁带驱动器。内核功能的这个方面是本书中的我们主要感兴趣的地方。
5、网络管理:网络必须由操作系统来管理,因为大部分网络操作不是特定于某一个进程: 进入系统的报文是异步事件。报文在某一个进程接手之前必须被收集,识别,分发,系统负责在程序和网络接口之间递送数据报文,它必须根据程序的网络活动来控制程序的执行。另外,所有的路由和地址解析问题都在内核中实现。
02.linux内核态和用户态
一、内核态、用户态概念
内核态:也叫内核空间,是内核进程/线程所在的区域。主要负责运行系统、硬件交互。
用户态:也叫用户空间,是用户进程/线程所在的区域。主要用于执行用户程序。
二、内核态和用户态的区别 内核态:运行的代码不受任何限制,CPU可以执行任何指令。
用户态:运行的代码需要受到CPU的很多检查,不能直接访问内核数据和程序,也就是说不可以像内核态线程一样访问任何有效地址。
操作系统在执行用户程序时,主要工作在用户态,只有在其执行没有权限完成的任务时才会切换到内核态。
三、为什么要区分内核态和用户态 保护机制。防止用户进程误操作或者是恶意破坏系统。内核态类似于C++的私有成员,只能在类内访问,用户态类似于公有成员,可以随意访问。
四、用户态切换到内核态的方式 1、系统调用(主动)
由于用户态无法完成某些任务,用户态会请求切换到内核态,内核态通过为用户专门开放的中断完成切换。
2、异常(被动)
在执行用户程序时出现某些不可知的异常,会从用户程序切换到内核中处理该异常的程序,也就是切换到了内核态。
3、外围设备中断(被动)
外围设备发出中断信号,当中断发生后,当前运行的进程暂停运行,并由操作系统内核对中断进程处理,如果中断之前CPU执行的是用户态程序,就相当于从用户态向内核态的切换。
03.什么是MMU?为什么要用MMU?
MMU(Memory Management Unit)是一种硬件设备,主要用于实现虚拟内存管理。它的作用是将进程所使用的虚拟地址转换成对应的物理地址,并进行内存保护。
在没有MMU的系统中,所有进程共享同一块物理内存,因此进程间需要通过约定好的内存地址来进行通信,容易导致地址冲突和安全问题。而有了MMU之后,每个进程都有自己的虚拟地址空间,不会互相干扰。MMU还可以根据进程的访问权限,对虚拟地址空间进行访问控制和内存保护。此外,MMU还可以通过虚拟地址和物理地址的映射关系,实现了虚拟内存技术,使得进程能够访问大于物理内存的虚拟地址空间,从而提高了内存利用率和系统性能。
04.交叉编译
交叉编译是指将源代码从一种计算机架构编译为另一种计算机架构的过程,在一个操作系统上编译针对另一个操作系统或硬件平台的程序。 需要进行交叉编译的原因通常是: 1.目标平台和开发平台不同:在开发软件时,开发者可能需要将软件运行在一个与其开发机器不同的目标平台上,如编写针对嵌入式设备的应用程序时,开发者通常需要在 PC 上编译,然后将其部署到嵌入式设备中。 2.硬件架构不同:在不同的硬件架构之间进行编译时需要进行交叉编译。例如,将 ARM 架构的应用程序编译为 x86 架构的应用程序。 3.系统库不同:不同的操作系统有不同的系统库,编译程序时需要使用适当的系统库。交叉编译可以使开发者在开发机器上使用开发者熟悉的库,在目标平台上使用目标平台的库。 交叉编译需要考虑多种因素,例如处理器架构、操作系统、编译器版本和编译选项等。因此,需要仔细配置编译工具链,以确保生成的可执行文件或库能够在目标平台上运行。
05.Linux驱动编译两种方法
-
编译成模块.ko文件
使用
insmod加载驱动,rmmod移除驱动 -
编译进内核
做成镜像
06.设备驱动分类
-
字符设备驱动:字符设备指那些必须按字节流传输,以串行顺序依次进行访问的设备。它们是我们日常最常见的驱动了,像鼠标、键盘、打印机、触摸屏,还有点灯以及I2C、SPI、音视频都属于字符设备驱动。
-
块设备驱动:存储器设备的驱动,eMMC、NAND、SD
-
网络设备驱动
07.字符设备框架
//1.定义自己的file_operations结构体
static struct file_operations led_drv = {
.owner = THIS_MODULE,
.open = led_drv_open,
.read = led_drv_read,
.write = led_drv_write,
.release = led_drv_close,
};
//2.实现对应的open/read/write等函数,填入file_operations结构体
static ssize_t led_drv_read (struct file *file, char __user *buf, size_t size, loff_t *offset)
{
printk("%s %s line %d\n", __FILE__, __FUNCTION__, __LINE__);
return 0;
}
//3.把file_operations结构体告诉内核:注册驱动程序
//4.谁来注册驱动程序啊?得有一个入口函数:安装驱动程序时,就会去调用这个入口函数
static int __init led_init(void)
{
//注册字符设备驱动,它会返回一个主设备号 major
major = register_chrdev(0, "100ask_led", &led_drv); /* /dev/led */
led_class = class_create(THIS_MODULE, "100ask_led_class");
device_create(led_class, NULL, MKDEV(major, 0), NULL, "100ask_led0"); //* /dev/100ask_led0
return 0;
}
/* 5. 有入口函数就应该有出口函数:卸载驱动程序时,就会去调用这个出口函数 */
static void __exit led_exit(void)
{
int i;
printk("%s %s line %d\n", __FILE__, __FUNCTION__, __LINE__);
for (i = 0; i < LED_NUM; i++)
device_destroy(led_class, MKDEV(major, i)); /* /dev/100ask_led0,1,... */
device_destroy(led_class, MKDEV(major, 0));
class_destroy(led_class);
unregister_chrdev(major, "100ask_led");
}
/* 6. 其他完善:提供设备信息,自动创建设备节点 */
module_init(led_init);
module_exit(led_exit);
MODULE_LICENSE("GPL");08.Linux启动流程
【Linux基础】1. Linux 启动过程_linux关机流程会先后停什么服务-CSDN博客
Linux系统的启动过程分为 5个阶段:
-
内核的引导:当计算机打开电源后,首先是 BIOS(Basic Input Output System,基本输入输出系统)开机自检,按照 BIOS 中设置的启动设备(通常是硬盘),操作系统接管硬件以后,首先 读入 /boot 目录下的内核文件
-
运行 init:读取配置文件 /etc/inittab,去运行需要开机启动的程序。Linux系统有7个运行级别 0-6
-
系统初始化:用执行了/etc/rc.d/rc.sysinit,而 rc.sysinit 是一个bash shell的脚本,它主要是完成一些系统初始化的工作,rc.sysinit 也是 每一个运行级别都要首先运行的重要脚本,它主要完成的工作有:激活交换分区,检查磁盘,加载硬件模块以及其它一些需要优先执行任务。
-
建立终端 :init接下来会 打开6个终端
-
用户登录系统。
三、计算机基础
01.操作系统
01.进程几种状态
互斥锁:互斥锁是一种用于线程同步的工具,能够保证同一时刻只有一个线程可以访问共享资源。如果一个线程已经取得了互斥锁,其他尝试获得该锁的线程将会被阻塞,直到第一个线程释放了该锁。
乐观锁:乐观锁假定冲突发生的几率很小,因此在数据操作前并不会加锁,但会在进行更新等操作时检查是否有其他线程对数据进行了修改。如果有,则操作失败;没有,则操作成功。乐观锁一般适用于读多写少的场景。
悲观锁:悲观锁假设冲突发生的几率很大,所以在每次读写数据前都会先加锁。这种方式虽然保证了数据的一致性,但也可能造成资源的浪费。悲观锁主要通过数据库提供的锁机制实现,例如行级锁、表级锁等。
03.并发和并行
-
并发:两个或多个事件在同一时间间隔内发生,这些事件在宏观上是同时发生的,在微观上是交替发生的, 操作系统的并发性指系统中同时存在着多个运行的程序
-
并行:两个或多个事件在同一时刻发生
-
一个单核(CPU)同一时刻只能执行一个程序,因此操作系统会协调多个程序使他们交替进行(这些程序在宏观上是同时发生的,在微观上是交替进行的)
-
操作系统是伴随着“多道程序技术出现的”,因此操作系统和并发是一同诞生的
-
在如今的计算机中,一般都是多核cpu的,即在同一时刻可以并行执行多个程序,比如我的计算机是8核的,我的计算机可以在同一时刻并行执行8个程序,但是事实上我们计算机执行的程序并不止8个,因此并发技术是必须存在的,并发性必不可少。
04.内核态和用户态
CPU 中有一个寄存器叫 程序状态字寄存器(PSW),其中有个二进制位,1表示“内核态”,0表示“用户态”。
内核态→用户态:执行一条特权指令——修改 PSW 的标志位为“用户态”,这个动作意味着操作系统将主动让出CPU使用权
用户态→内核态:由“中断”引发,硬件自动完成变态过程,触发中断信号意味着操作系统将强行夺回CPU的使用权。
05.操作系统常用的调度算法
操作系统中几种最最最常见的调度算法(适用于软件设计师考试与期末考试复习)_循环扫描算法-CSDN博客
在进程调度算法常见的算法有:
-
先来先服务(FirstComeFirstServed,FCFS):即按作业到来或进程变为就绪状态的先后次序分派处理机,属于非抢占方式,当前作业或进程直到执行完或阻塞,才出让处理机。
-
短作业优先(Shortest Job First, SIF):短进程优先是从就绪队列中选择估计运行时间最短的进程,将处理机分配给它,使之执行直到完成或因发生某事件而阻塞放弃处理机时,再重新调度。
-
轮转法(Round Robin):将处理机的时间分成固定大小的时间片,不能取得过大或者过小,通常为10~100ms数量级。处理机调度程序按照FCFS原则,轮流地把处理机分给就绪队列中的每个进程,时间长度都是一个时间片。
-
优先级算法(Priority Scheduling):统按一定规则赋予每个进程一个调度优先级,把处理机分配给就绪队列中具有最高优先级的进程。
02.计算机网络
01.OSI七层模型
简记:物联网叔会使用
-
物理层:传输单位bit
-
数据链路层:传输单位帧。如:串口通信中使用到的 115200、8、N、1
-
网络层:传输单位数据报
-
传输层:传输单位报文。定义了一些传输数据的协议和端口号
-
会话层
-
表示层
-
应用层
02.TCP/IP四层模型
TCP/IP 网络协议栈分为应用层(Application)、传输层(Transport)、网络层(Network)和链路层(Link)四层。

-
HTTP(Hypertext Transfer Protocol)- 端口号:80
-
用于在Web浏览器和Web服务器之间传输超文本文档。是一种明文传输协议,数据在客户端和服务器之间以纯文本形式传输,容易被窃听和篡改。
-
-
HTTPS(Hypertext Transfer Protocol Secure)- 端口号:443
-
通过SSL/TLS加密的HTTP通信,用于安全地传输数据。
-
-
FTP(File Transfer Protocol)- 端口号:20和21
-
用于在客户端和服务器之间传输文件。在 FTP 中,端口 21 用于控制连接,端口 20 用于数据连接。当客户端建立与服务器的 FTP 连接时,首先会在端口 21 上进行控制连接,然后根据需要在端口 20 上建立数据连接进行文件传输。
-
-
SSH(Secure Shell)- 端口号:22
-
用于在网络中提供加密的通信会话。
-
-
SMTP(Simple Mail Transfer Protocol)- 端口号:25
-
用于在邮件服务器之间传输电子邮件。
-
-
POP3(Post Office Protocol version 3)- 端口号:110
-
用于从邮件服务器上收取电子邮件。
-
-
IMAP(Internet Message Access Protocol)- 端口号:143
-
用于在客户端与邮件服务器之间传输邮件。
-
-
DNS(Domain Name System)- 端口号:53
-
用于将域名解析为对应的IP地址。
-
-
SNMP(Simple Network Management Protocol)- 端口号:161
-
用于网络设备之间的管理和监控。
-
-
RDP(Remote Desktop Protocol)- 端口号:3389
-
用于远程桌面连接。
-
-
DHCP(Dynamic Host Configuration Protocol):用于自动分配IP地址。默认端口号为67和68,分别用于客户端和服务器。
这些是一些常见的应用层协议及其默认端口号,实际应用中也可能会使用非标准端口或根据需要进行自定义配置。
04.TCP三次握手
TCP的运输连接管理之三次握手四次挥手_第三次握手是可以携带数据的,前两次握手是不可以携带数据的-CSDN博客
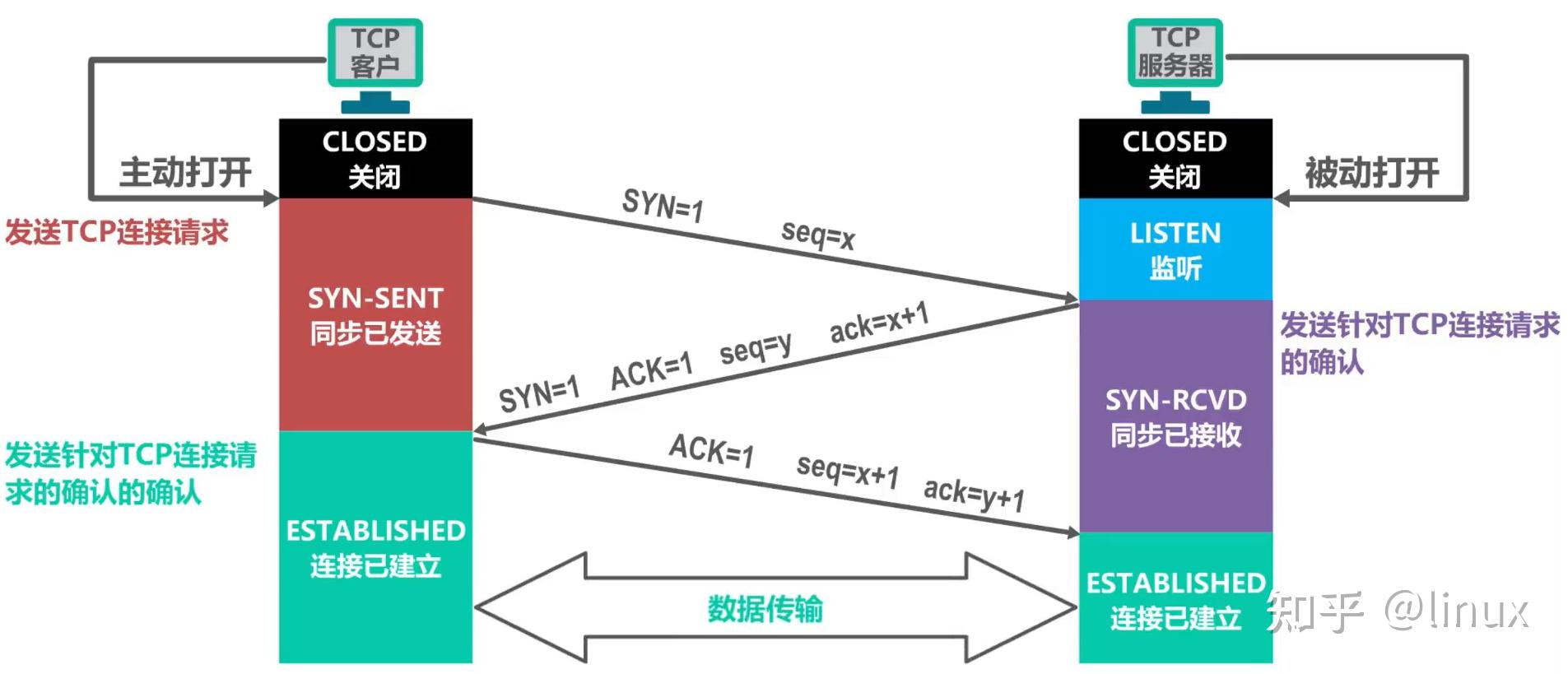
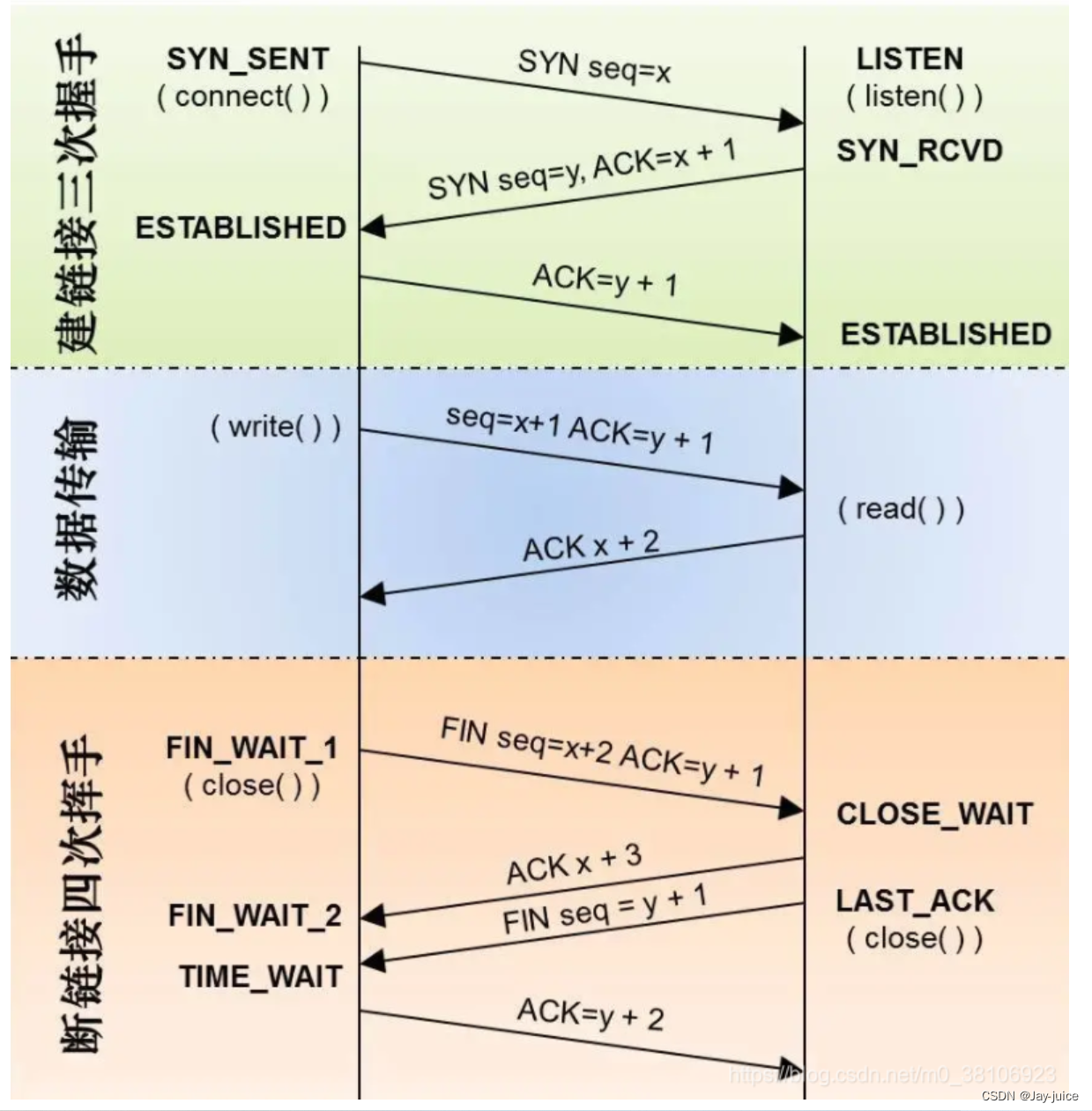
05.四次挥手
TCP三次握手和四次挥手详解_tcp三次握手和4次挥手的过程-CSDN博客
因为服务端在接收到FIN, 往往不会立即返回FIN ,必须等到服务端所有的报文都发送完毕了,才能发FIN。为了防止客户端等待时间过长触发FIN重传,因此先发一个ACK表示已经收到客户端的FIN,等服务器发送完了数据,再发送FIN包进行第三次挥手。
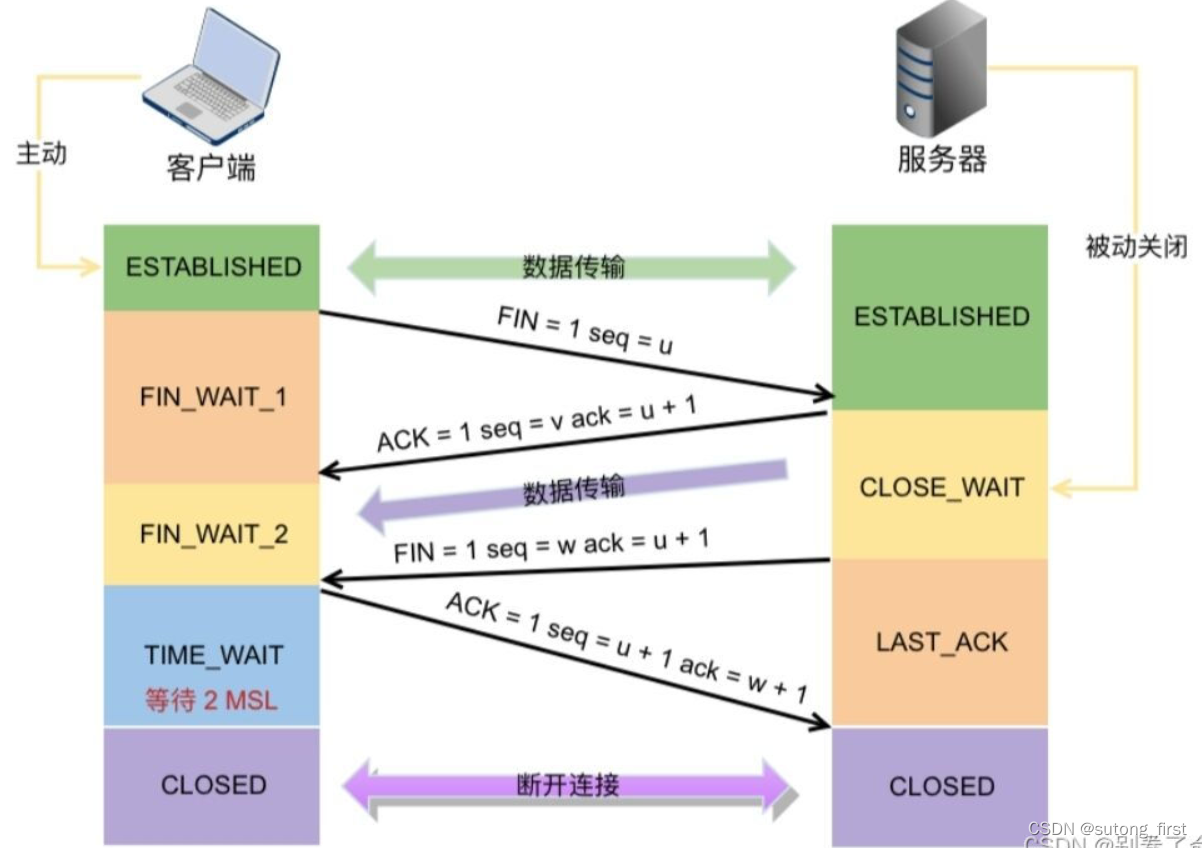
-
刚开始客户端和服务器端都处于ESTABLISHED状态,假如客户端发起关闭请求;
-
第一次挥手:客户端向服务器发送FIN报文(FIN=1,seq=u),发完后进入FIN_WAIT_1状态,即主动关闭TCP连接,不再发送数据,但可以接收服务器发来的报文,等待服务器回复;
-
第二次挥手:服务器接到FIN报文后,返回一个ACK报文(ACK=1,ack=u+1,seq=v),表明自己接收到此报文,服务器进入CLOSE_WAIT关闭等待状态,此时客户端就知道服务端接到自己的断开连接请求,进入到FIN_WAIT_2状态,TCP处于半关闭状态,但服务器端可能还有数据要传输。
-
第三次挥手:服务器关闭客户端连接,发送FIN报文(FIN=1,seq=w,ack=u+1)给客户端,此时服务器处于LAST_ACK状态,等待客户端回应。
-
第四次挥手:客户端收到FIN报文后,发送一个ACK(ACK=1,ack=w+1,seq=u+1)给服务器作为应答,此时客户端处于TIME_WAIT状态,这个状态是为了等待足够的时间以确保TCP接收到连接中断请求的确认
等待2MSL的原因
-
防⽌客户端最后⼀次发给服务器的确认在⽹络中丢失以⾄于客户端关闭,⽽服务端并未关闭,导致资源的浪费。
-
等待最⼤的2msl可以让本次连接的所有的⽹络包在链路上消失,以防造成不必要的⼲扰。
-
如果客户端直接closed,然后⼜向服务端发起了⼀个新连接,我们不能保证这个新连接和刚关闭的连接的端⼝号是不同的。假设新连接和已经关闭的⽼端⼝号是⼀样的,如果前⼀次滞留的某些数据仍然在⽹络中,这些延迟数据会在新连接建⽴后到达服务端,所以socket就认为那个延迟的数据是属于新连接的,数据包就会发⽣混淆。所以客户端要在TIME_WAIT状态等待2倍的MSL,这样保证本次连接的所有数据都从⽹络中消失。
为什么三次挥手不行 因为服务端在接收到FIN, 往往不会立即返回FIN ,必须等到服务端所有的报文都发送完毕了,才能发FIN。因此先发一个ACK表示已经收到客户端的FIN,延迟一段时间才发FIN。这就造成了四次挥手。
如果是三次挥手会造成: 如果将服务端的两次挥手合为一次,等于说服务端将ACK和FIN的发送合并为一次挥手,这个时候长时间的延迟可能会导致客户端误以为FIN没有到达客户端,从而让客户端不断的重发FIN。所有只能第二次握手先发送ACK确认接收到了客户端的数据,等服务器发送完了数据,再发送FIN包进行第三次挥手。
06.TCP和UDP区别
TCP和UDP都是在网络通信中使用的协议,它们都位于网络模型的第四层(传输层)。但它们之间有一些关键的区别:
-
连接类型:
-
TCP是一种面向连接的协议。在数据传输之前,它需要建立一个连接,这就像是打电话,你需要先拨号建立连接,然后才能通话。
-
UDP是一种无连接的协议。它不需要预先建立连接,就可以直接发送数据,这就像是寄信,你直接投递到邮筒,不需要先与对方建立联系。
-
-
数据传输的可靠性:
-
TCP提供了一种可靠的数据传输服务。它有确认、重传和拥塞控制机制,可以保证数据的正确性和顺序性。
-
UDP则不提供数据传输的可靠性保证,它只是简单地将数据包发送出去,不关心数据包是否到达目的地,因此可能会出现数据丢失的情况。
-
-
传输速度:
-
由于TCP需要进行连接建立、确认和重传等操作,所以相对来说,其传输速度比UDP慢。
-
UDP由于没有复杂的控制机制,所以其传输速度通常比TCP要快。
-
-
使用场景:
-
TCP常用于需要高可靠性的应用,如网页浏览(HTTP、HTTPS)、邮件发送(SMTP)等。
-
UDP则适合对实时性要求较高,可容忍少量数据丢失的应用,如视频会议、语音通话、直播等。
-
-
头部开销:
-
TCP的头部开销较大,最小20字节,提供了许多选项,如错误检测,序列号,确认号等。
-
UDP的头部开销小,只有8字节,只提供了最基本的功能。
-
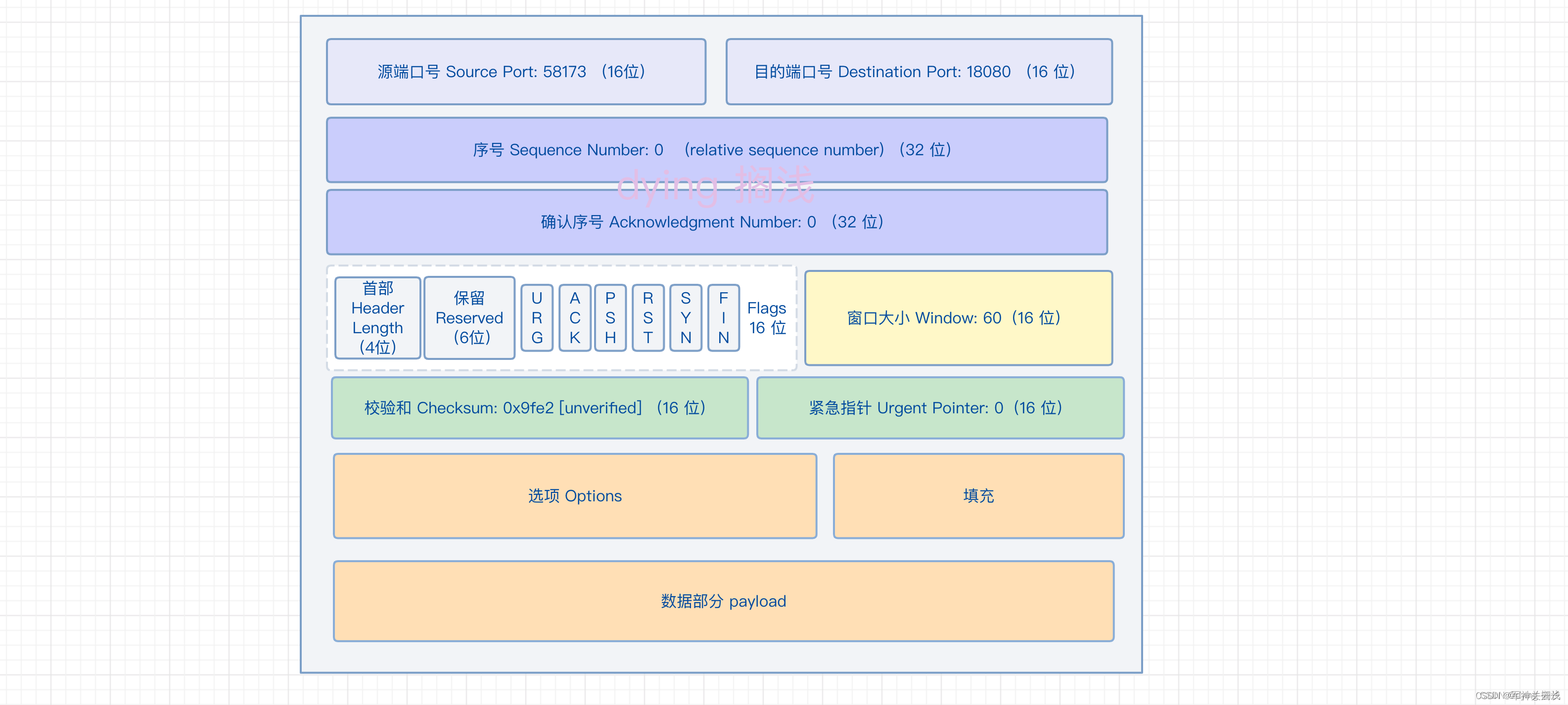
-
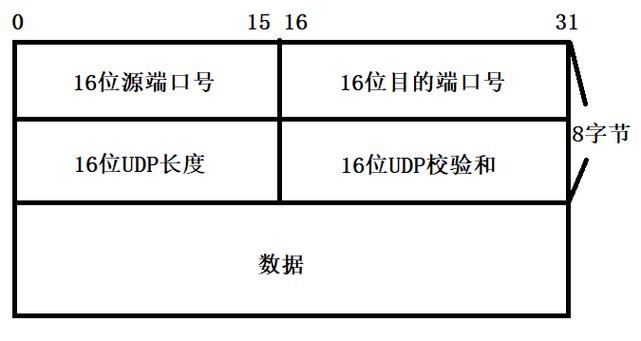
-
07.滑动窗口和超时重传
滑动窗口
滑动窗口是TCP和其他网络协议中用于控制数据传输的一种技术。它的主要目的是防止发送方发送过多数据,从而导致接收方无法处理。
在TCP中,滑动窗口由发送窗口和接收窗口组成,它们分别代表了发送方可以发出的数据量和接收方可以接受的数据量。每次数据传输后,窗口会“滑动”以适应新的数据流。滑动窗口的大小根据网络拥塞情况、接收方处理能力等因素动态调整,从而实现TCP的流量控制和拥塞控制。
超时重传
超时重传是TCP中用于保证数据可靠传输的一种机制。当发送方发出一个数据包后,它会启动一个定时器等待接收方的确认。如果在定时器超时之前接收到确认,则表示数据包已成功传送;否则发送方会认为该数据包在网络中丢失,需要进行重传。
超时重传能够确保即使在网络环境不理想的情况下,数据也能最终被接收到。这是TCP提供可靠传输服务的关键机制之一。然而,由于超时重传可能增加网络拥塞,所以TCP还配备了拥塞控制机制来避免过度重传。
需要注意的是,TCP的超时时间并非固定,而是根据Round-Trip Time(往返时间)动态调整。这样可以更好地适应不同的网络条件,提高效率。
08.TCP粘包
TCP数据粘包的处理 | 爱编程的大丙 (subingwen.cn)
TCP粘包指的是接收方在一次读取数据时,将多个发送方发送的数据包合并成一个或者少于原始数据包数量的现象。TCP粘包通常发生在基于流式传输(如TCP)的网络通信中,其主要原因有以下几点:
-
TCP为面向流的协议:TCP是面向流的传输协议,发送方可以将数据划分为任意大小的数据块发送,接收方可能一次性接收到多个数据包,导致多个数据包被合并成一个大的数据块。
-
接收方缓冲区未及时读取:如果接收方没有及时从缓冲区中读取数据,而发送方持续发送数据,则多个数据包可能会在接收方的缓冲区中累积,从而造成粘包现象。
-
网络延迟和拥塞:网络延迟、拥塞等因素也可能导致数据包在传输过程中聚集在一起,形成粘包现象。
-
操作系统对数据处理方式不同:不同操作系统对于接收数据的处理方式可能不同,有些操作系统会尽量将接收到的数据进行合并,从而可能导致粘包现象。
为避免TCP粘包问题,可以采用以下方法:
-
在数据包中增加长度字段,让接收方根据长度字段来正确解析数据包。
-
使用特殊标记或分隔符来标识数据包的边界。
-
对数据进行序列化和反序列化处理,确保数据的完整性和正确性。
-
合理设计应用层协议,规范数据的传输方式,避免产生粘包问题。
09.DNS
DNS(域名系统):
过程总结: 浏览器缓存,系统缓存,路由器缓存,ISP服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。
-
DNS是一个分布式的服务,它将人类可读的域名(如 www.example.com)转换为机器可读的IP地址(如 192.0.2.1),使得用户能够通过域名访问网站而无需记住复杂的IP地址。
-
当你输入一个网址时,你的设备会使用DNS来查找对应的IP地址,从而能够连接到正确的服务器。
-
DNS查询通常在用户感知不到的情况下在后台进行,并且百度一下,你就知道大多使用UDP协议进行通信,因为它比TCP更快,而DNS查询需要速度。
10.DNS域名缓存
缓存目的和好处
DNS域名缓存的主要目的是减少对远端DNS服务器的查询次数,加快域名解析速度,减轻DNS服务器的负担,从而提高整个互联网的效率和性能。具体来说,DNS缓存带来的好处包括:
-
提高解析速度:通过从缓存中直接获取解析结果,避免了每次都进行完整的DNS解析流程,大大加快了域名到IP地址的转换速度。
-
减少网络延迟:由于减少了对远端DNS服务器的查询,从而降低了网络延迟。
-
减轻DNS服务器负担:缓存可以显著减少DNS服务器接收的请求数量,有助于缓解服务器负载。
缓存位置
-
浏览器缓存:现代Web浏览器都会维护自己的DNS缓存,以便重复访问的网站可以更快加载。
-
操作系统缓存:操作系统也会缓存DNS查询结果,当应用程序请求DNS解析时,首先会检查操作系统的DNS缓存。
-
递归DNS服务器缓存:当用户的查询请求发送到递归DNS服务器时,这些服务器也会缓存一份DNS查询结果,供后续相同的查询请求使用。
-
权威DNS服务器:虽然权威DNS服务器本身不缓存外部域名的解析结果,但它们会为自己负责的域名提供TTL(生存时间),告诉其他DNS服务器和客户端可以缓存解析结果的时间长度。
11.常见协议与功能
-
ARP(Address Resolution Protocol)是一种用于将IP地址解析为MAC地址的协议。在计算机网络中,每个网络接口都有一个唯一的MAC地址(物理地址),而IP地址用于标识网络中的主机。当一台主机需要发送数据包到另一台主机时,它需要知道目标主机的MAC地址,而不仅仅是IP地址。
-
NAT(Network Address Translation,网络地址转换)是一种网络技术,用于将私有网络内部的IP地址转换为公共网络(如Internet)上的IP地址,以实现私有网络内部主机与公共网络之间的通信。
-
DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)是一种用于自动分配IP地址和其他网络配置参数的协议。它允许网络管理员集中管理和分配IP地址,而无需手动配置每个主机的网络参数。
-
DNS(Domain Name System,域名系统)是互联网中用于将域名(例如example.com)转换为与之相关联的IP地址(例如192.0.2.1)的分布式命名系统。它充当了互联网的电话簿,使得用户可以通过易记的域名访问网站,而不必记住复杂的IP地址。
12.长连接和短连接
在计算机网络和通信中,"长连接"和"短连接"是指客户端和服务器之间的连接持续时间的两种不同模式。
短连接:
-
每次通信都需要建立一个新的连接。
-
客户端向服务器发送请求后,服务器响应请求,数据发送完成之后,立即断开连接。
-
短连接适用于请求-响应模式,常见于HTTP/1.0协议的交互。
-
短连接由于频繁地进行TCP三次握手和四次挥手过程,对于服务器资源消耗较大,但可以较好地释放资源,适用于轻量级的、偶尔的数据交换。
-
短连接通常用于处理瞬间高并发的场景。
长连接:
-
一旦建立,连接会保持开放,直到客户端或服务器明确地关闭它。
-
客户端与服务器建立连接后,可以进行多次的数据传输,直到任一方主动关闭连接。
-
长连接减少了因为建立和关闭连接而产生的额外开销,适用于需要频繁交换数据的应用。
-
在HTTP/1.1协议中,默认使用长连接,通过
Connection: keep-alive头部实现。 -
长连接适用于需要维持持久状态或频繁通信的场景,如数据库连接、文件传输、实时通信等。
-
心跳机制常用于维护长连接,确保连接的活性,并能及时发现异常断开。
如何选择:
-
应用场景:如果客户端与服务器之间的交云频繁且持续,长连接可以减少因建立和关闭连接而产生的开销。如果交互是偶尔的,可能短连接更合适。
-
资源消耗:长连接可以减少CPU和网络的消耗,但会占用更多的内存资源,因为连接需要保持状态。短连接会增加
03.计算机组成原理
01.冯·诺依曼架构&哈佛架构
冯·诺依曼架构和哈佛架构是计算机系统中两种常见的指令和数据存储方式。
冯·诺依曼架构:将指令和数据存储在同一个存储器中,并使用同一套总线进行数据传输。指令和数据必须按顺序在存储器中存储,并且通过共享的数据总线进行传输,指令必须按照严格的顺序执行,无法并行执行多条指令。优势在于其简洁性、通用性和灵活性,使得计算机能够执行不同类型的任务,并支持存储程序的概念,使得程序可以被修改和更新。
哈佛架构:指令存储器和数据存储器是物理上分开的,使用不同的总线进行数据传输。哈佛架构对硬件的要求更高,因为需要独立的指令和数据存储器。哈佛架构的优势在于其并行性和高效性。由于指令存储器和数据存储器分开,指令和数据可以同时进行读取和存储。这种并行访问使得计算机系统能够更高效地执行指令和处理数据,从而提高了系统的性能和吞吐量。
02.存储器分类
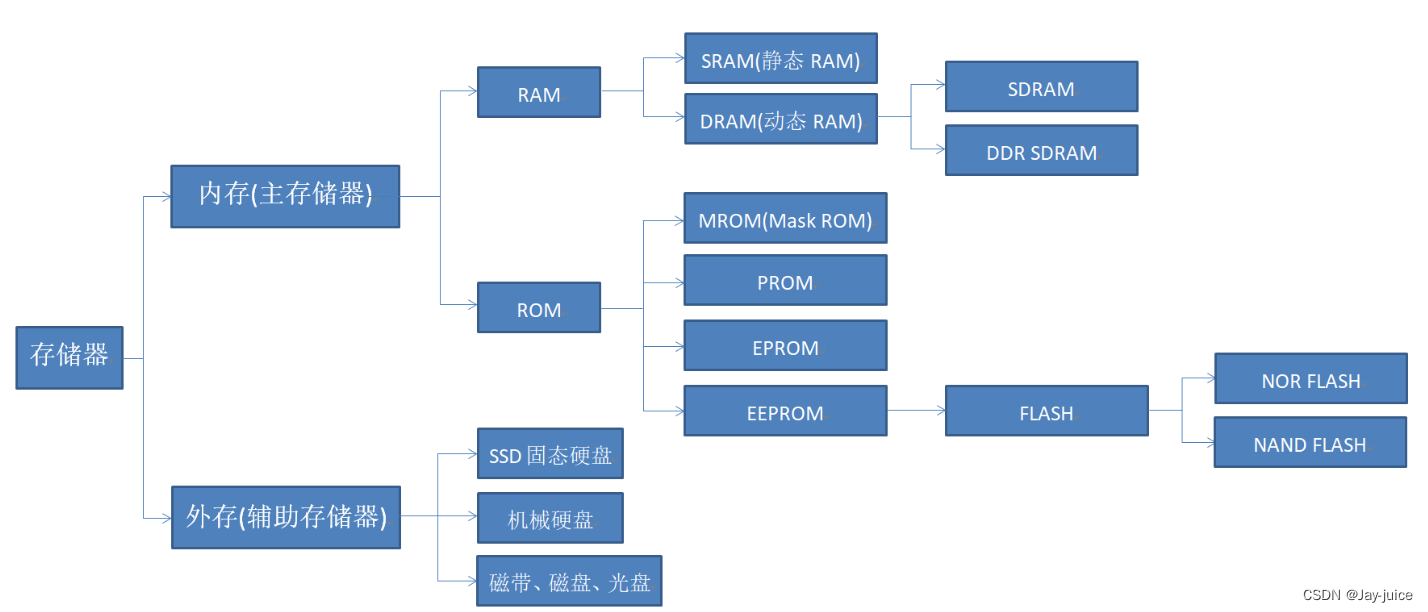
03.寄存器(Register)和内存(Memory)
-
寄存器:通常是一个非常快速的、特殊的存储器,用于在CPU内部存储数据和指令。它位于CPU芯片内部,是CPU的一部分。寄存器的容量很小,通常只有几十个字节,因此它只能存储少量的数据。寄存器中存储的数据是二进制格式的,即由0和1组成的数字序列。这种格式非常适合CPU内部的处理,因为它可以直接传递给CPU中的算术逻辑单元(ALU)进行计算。
-
内存:通常是一个较慢的、可扩展的存储器,用于在计算机系统中存储大量的数据和程序。内存的容量很大,通常可以存储几GB的数据。内存中存储的数据可以是多种格式,包括文本、数字、图像、音频和视频等,这些数据格式不一定是二进制的。
04.Cache一致性问题
当系统中的多个处理器私有Cache存在共享数据的副本时,可能出现副本内容不一致的情况,即:在系统运行的某个时刻,相同的存储器位置(物理地址)在不同的处理器视图中具有不同的值。多个处理器或多个核心的计算机系统中,它们共享同一个内存区域时,保证每个处理器或核心的缓存中存储的数据是一致的。当一个处理器或核心修改共享内存中的数据时,它必须通知其他处理器或核心,以便它们更新自己的缓存。
05.SRAM、DRAM、SDRAM
(1)SRAM:静态的随机存储器,加电情况下,不需要刷新,数据不会丢失,CPU的缓存就是SRAM。 (2)DRAM:动态随机存储器,加电情况下,也需要不断刷新,才能保存数据,最为常见的系统内存。 (3)SDRAM:同步动态随机存储器,即数据的读取需要时钟来同步,也可用作内存。
06.存储单位
1B=8bit 2^10B=1024B=1KB 2^20B=1024KB=1MB 2^30B=1024MB=1GB
04.数据结构
01.顺序表和链表
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
| 不同点 | 顺序表 | 链表 |
|---|---|---|
| 存储空间 | 物理上一定连续 | 逻辑上连续,物理上不一定连续 |
| 随机访问 | 可以顺序也可以随机 | 只能从头顺序存取 |
| 任意位置插入或者删除 | 可能移动元素,效率低 | 修改指针指向 |
| 插入 | 动态顺序表,空间不够增容 | 没有容量概念 |
| 应用场景 | 高效存储+频繁访问 | 任意位置插入删除频繁 |
| 缓存利用率 | 高 | 低 |
02.链表有环
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode* fast = head;
ListNode* slow = head;
while(fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
// 快慢指针相遇,此时从head 和 相遇点,同时查找直至相遇
if (slow == fast) {
ListNode* index1 = fast;
ListNode* index2 = head;
while (index1 != index2) {
index1 = index1->next;
index2 = index2->next;
}
return index2; // 返回环的入口
}
}
return NULL;
}
};
03.循环队列FIFO
C语言构建环形缓冲区_环形缓冲区 c语言 实现-CSDN博客
循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。
我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。而对于循环队列来说,可以重复利用使用过的空间。解决了普通队列的问题。
typedef struct
{
void *buffer;
int front; // 队头指针
int rear; // 队尾指针
int capacity; // 队列容量
int elementSize; // 元素大小
} FIFO;
void initFIFO(FIFO* fifo, int capacity, int elementSize) {
fifo->buffer = malloc(capacity * elementSize);
fifo->front = 0;
fifo->rear = 0;
fifo->capacity = capacity;
fifo->elementSize = elementSize;
}
//队头指针(front)和队尾指针(rear)指向同一个位置时,表示队列中没有元素
int isFIFOEmpty(FIFO* fifo) {
return (fifo->front == fifo->rear);
}
/*当队列已满时,即队尾指针(rear)下一个位置是队头指针(front)时,表示队列中已经存满了元素。*/
int isFIFOFull(FIFO* fifo) {
return ((fifo->rear + 1) % fifo->capacity == fifo->front);
}
void enqueueFIFO(FIFO* fifo, void* data) {
if (isFIFOFull(fifo)) {
// printf("FIFO is full. Cannot enqueue.\n");
return;
}
void* dest = (char*)fifo->buffer + fifo->rear * fifo->elementSize;//计算出队列队尾的地址
memcpy(dest, data, fifo->elementSize);//将数据复制到该地址处
fifo->rear = (fifo->rear + 1) % fifo->capacity; // 更新队尾指针
}
int dequeueFIFO(FIFO* fifo, void* data) {
if (isFIFOEmpty(fifo)) {
// printf("FIFO is empty. Cannot dequeue.\n");
return 0;
}
void* src = (char*)fifo->buffer + fifo->front * fifo->elementSize;
memcpy(data, src, fifo->elementSize);
fifo->front = (fifo->front + 1) % fifo->capacity; // 更新队头指针
return 1;
}03.二叉树分类
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
-
二叉树:每个节点最多有两个子树的树状结构,是n个节点的集合;度<=2;左子树和右子树是有顺序的,次序不能任意颠倒;
-
完全二叉树:除最后一层外,其余层节点数均达到最大值,并且最后一层的节点都集中在左侧;如果结点度为1,则该结点只有左孩子,没有右子树;同样结点数目的二叉树,完全二叉树深度最小;
-
满二叉树:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树;叶子只能出现在最下一层;非叶子结点的度(
结点拥有的子树数目称为结点的度)一定是2; -
二叉搜索树:若它的左子树不空,则左子树上的所有结点的值均小于根节点的值;若它的右子树不空,则右子树上的所有结点的值均大于根节点的值,左右子树分别为二叉排序树。
-
平衡二叉树:是二叉查找树的一个进化体,它有几种实现方式:
红黑树、AVL树,它是一个空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是平衡二叉树,如果插入或者删除一个节点使得高度之差大于1,就要进行节点之间的旋转,将二叉树重新维持在一个平衡状态。插入,查找,删除的时间复杂度最好情况和最坏情况都维持在O(logN)
04.二叉树的性质
-
二叉树第
i层最多有2^(i-1)个节点(i>=1) -
深度为
k的二叉树节点数最多为(2^k)-1个 -
度为
i的节点数为ni,则n0=n2+1 -
具有
n个节点的完全二叉树深为log(2x+1)(其中x表示不大于n的最大整数)。 -
如果对一颗有n个结点的完全二叉树(其深度为[log2n]+1)的结点按层序编号(从第一层到[log2n]+1层,每层从左到右),对任一结点i(1<=i<=n)
(1)如果i=1,则结点i是二叉树的根,无双亲,如果i>1,则其双亲结点是结点[i/2] (2)如果2i>n,则结点i无左孩子(结点i为叶子结点)否则左孩子是结点2i。 (3)如果2i+1>n,则结点i无右孩子,否则其右孩子是结点2i+1.
-
二叉树的查找时间复杂度取决于树的类型和其平衡性。在平衡二叉树(如 AVL 树、红黑树等)中,查找的时间复杂度通常为 O(log n),其中 n 是树中节点的数量。这是因为平衡二叉树保持了树的平衡,使得树的高度保持在较低的水平上,从而保证了较快的查找时间。
然而,在非平衡的二叉树中,查找时间的复杂度可能会达到 O(n),其中 n 是树中节点的数量。在最坏情况下,非平衡二叉树可能会退化成链表,导致每次查找都需要遍历整个链表,时间复杂度为 O(n)。
05.什么是二叉树的退化
二叉树的退化指的是一棵二叉树变成类似链表的情况,也称为二叉树的退化为链表(Degenerate Binary Tree)。在这种情况下,二叉树的每个非叶子节点都只有一个子节点(要么左子节点,要么右子节点),而且所有的节点都沿着同一个方向排列,形成了一条线性结构。
二叉树的退化可能会导致树的高度(深度)变得很大,接近于节点的数量,这样会增加在树上进行搜索、插入、删除等操作的时间复杂度,使得树的性能下降。退化的二叉树失去了二叉树本身的优势,无法充分利用二叉树的快速查找和插入特性,甚至变得和单链表一样效率低下。
二叉树退化为链表的情况通常发生在以下情况下:
-
在插入节点时不平衡地选择节点的位置。
-
在特定的插入顺序下,比如按照升序或降序插入节点。
-
在某些特殊情况下,比如树的平衡性受到破坏时。
为了避免二叉树的退化,可以采取一些措施,如使用平衡二叉树(如 AVL 树、红黑树)或者在构建二叉树时保持平衡,以确保树的高度尽可能小,提高树的性能和效率。
二叉树遍历
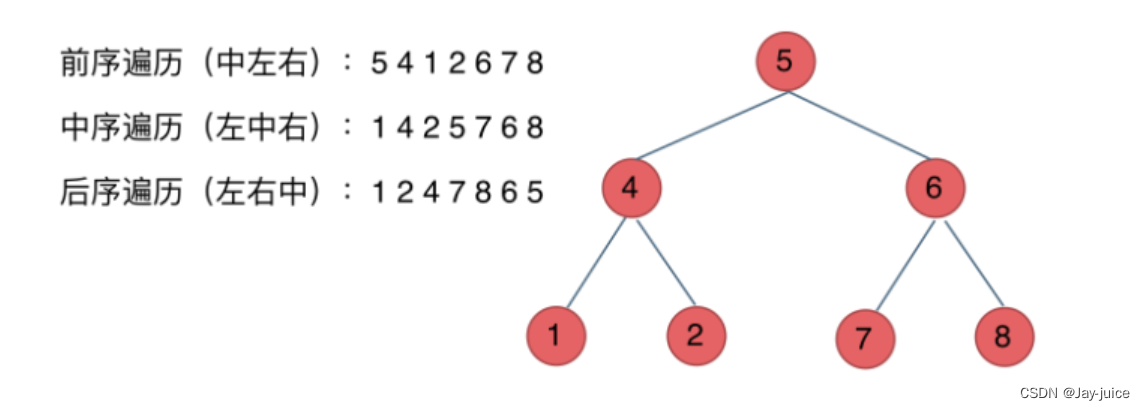
图(Graph)——图G是由顶点的有穷非空集合和顶点之间边的集合组成,其中:V(G)是顶点的非空有限集,E(G)是边的有限集合,边是顶点的无序对或有序对
数据结构——图的五种种类【无向图-有向图-简单图-完全无向图-有向完全图】_有向图和无向图的区别-CSDN博客
07.图的存储结构
邻接矩阵法——表示顶点间相联关系的矩阵,矩阵的第i行第j列表示i到j是否连接。
-
无向图的邻接矩阵对称,可压缩存储;有n个顶点的无向图需存储空间为n(n+1)/2;
-
有向图邻接矩阵不一定对称;有n个顶点的有向图需存储空间为n²;
-
无向图中顶点Vi的度TD(Vi)是邻接矩阵A中第i行元素之和;
-
有向图中, 顶点Vi的出度是A中第i行元素之和; 顶点Vi的入度是A中第i列元素之和;
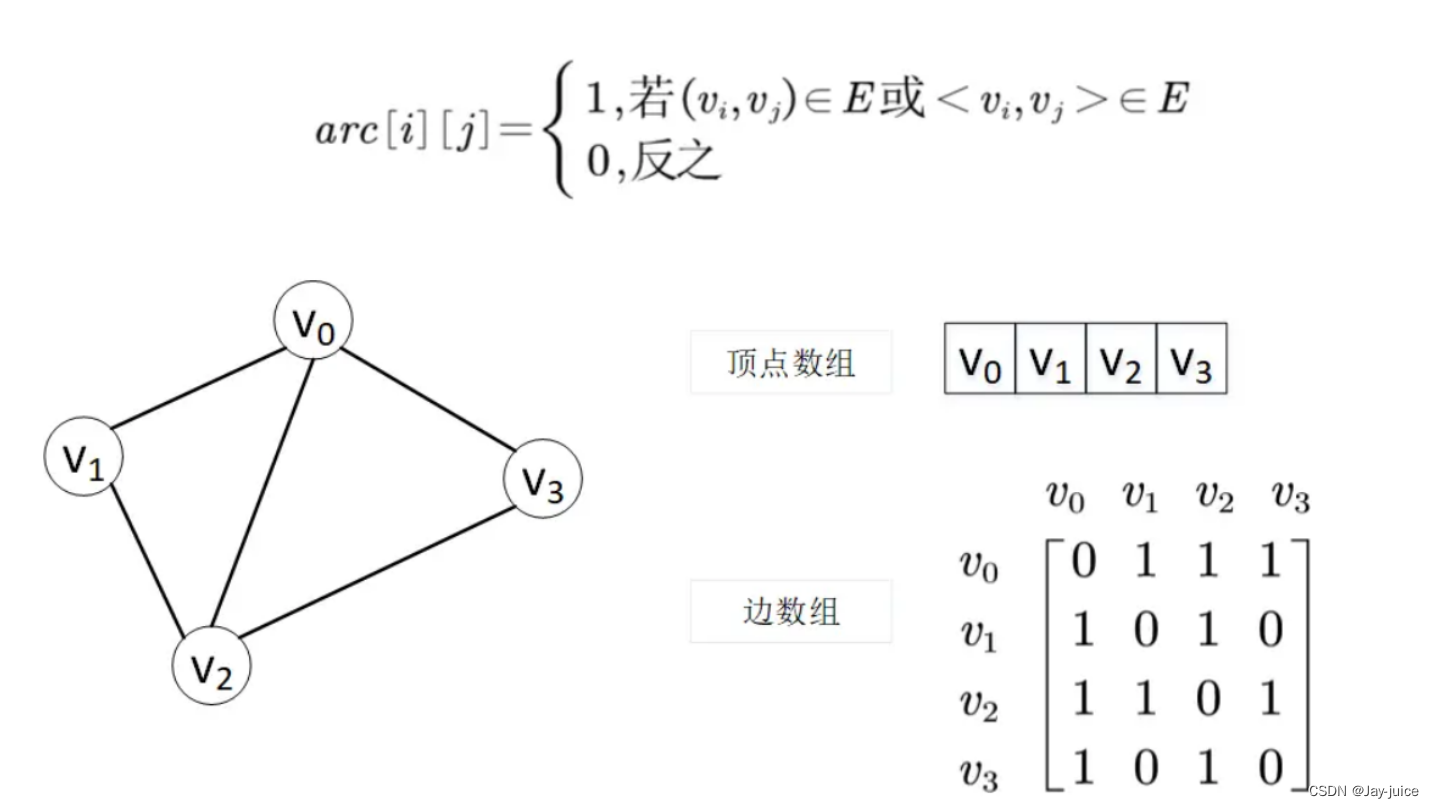
08.求最短路径算法
-
Floyd
-
Dijkstra 算法
09.排序算法
六大排序算法:插入排序、希尔排序、选择排序、冒泡排序、堆排序、快速排序_冒泡排序,快速排序,希儿排序,堆排序 需要额外辅助空间-CSDN博客
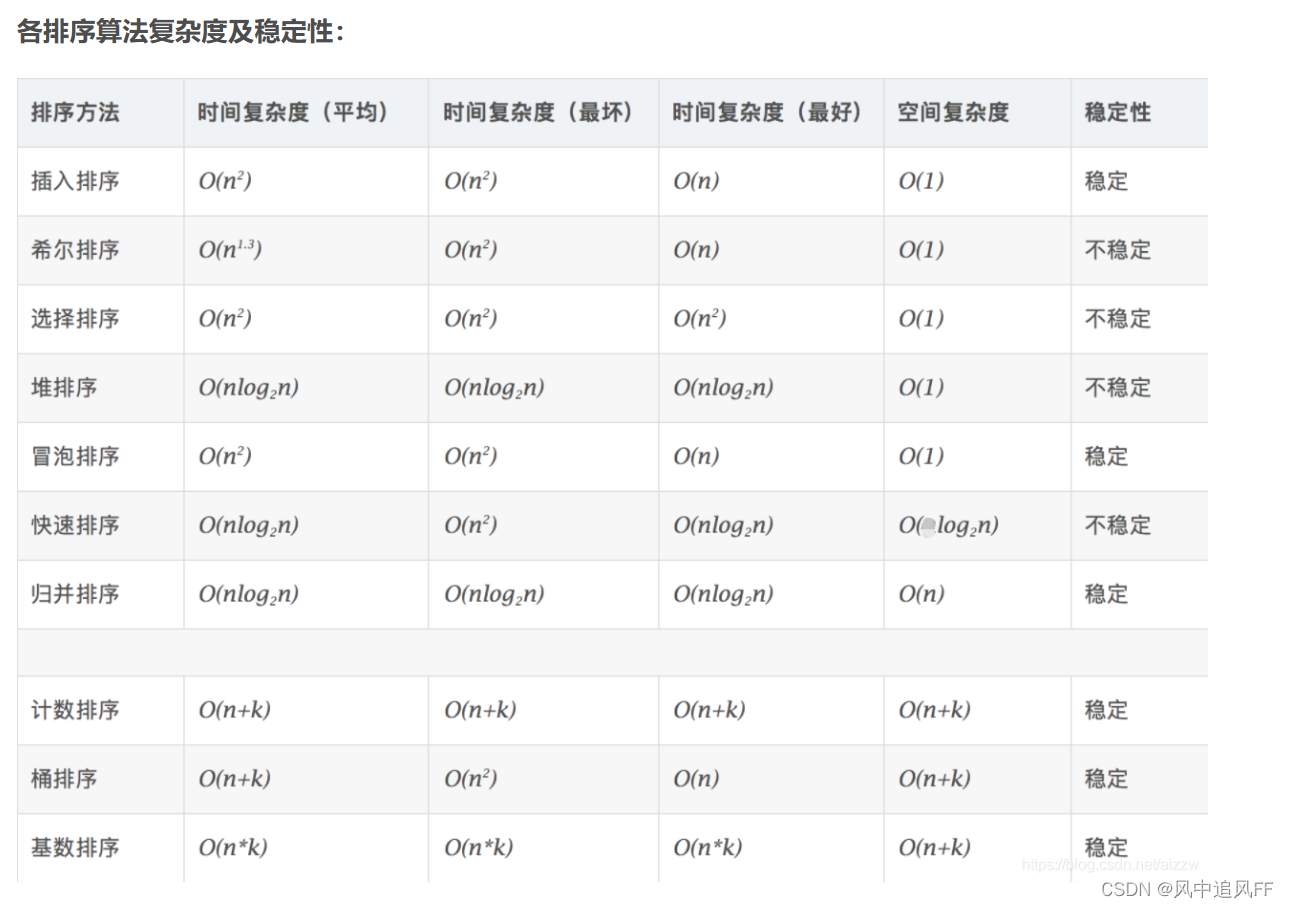
/*
O(N^2):冒泡,插入,选择
O(N^1.3):希尔
O(NlogN):快排,堆排
*/
void BubbleSort(int*arr,int size){
for(int i=0;i<size-1;i++){//size-1是因为不用与自己比较,所以比的数就少一个
for(int j=0;j<size-i-1;j++){//size-1-i是因为每一趟就会少一个数比较
if(arr[j]>arr[j+1]){//这是升序排法,所有数中最大的那个数就会浮到最右边
swap(arr[j],arr[j+1]);
}
}
}
}
//最坏情况下为O(N^2),此时待排序列为逆序,或者说接近逆序;最好情况下为O(N),此时待排序列为升序,或者说接近升序。
void insertionSort(int arr[], int n) {
int i, j, key;
for (i = 1; i < n; i++) {
key = arr[i];
j = i - 1;
// 将比key大的元素向后移动
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}
//选择排序算法是通过遍历数组,选择出数组的最小或最大值,与指定位置交换数据,遍历完整个数组的所有位置就完成排序
void selectionSort(int arr[], int n) {
int i, j, min_index;
for (i = 0; i < n-1; i++) {
min_index = i;
// 寻找最小元素的下标
for (j = i+1; j < n; j++) {
if (arr[j] < arr[min_index]) {
min_index = j;
}
}
// 将最小元素与当前位置交换
int temp = arr[i];
arr[i] = arr[min_index];
arr[min_index] = temp;
}
}
/*希尔排序实质上是一种分组插入方法。它的基本思想是:对于 n 个待排序的数列,取一个小于 n 的整数 gap ( gap 被称为步长)将待排序元素分成若干个组子序列,所有距离为 gap 的倍数的记录放在同个一组中;然后,对各组内的元素进行直接插入排序。这一趟排序完成之后,每一个组的元素都是有序的。然后减小 gap 的值,并重复执行上述的分组和排序。重复这样的操作,当 gap =1时,整个数列就是有序的。
时间复杂度平均:O(N^1.3)
*/
void shellSort(int arr[], int n) {
int gap, i, j, temp;
for (gap = n/2; gap > 0; gap /= 2) {
// 对每个分组进行插入排序
for (i = gap; i < n; i++) {
temp = arr[i];
j = i;
// 对分组中的元素进行插入排序
while (j >= gap && arr[j-gap] > temp) {
arr[j] = arr[j-gap];
j -= gap;
}
arr[j] = temp;
}
}
}
10.哈希表
其通过建立键 key 与值 value 之间的映射,实现高效的元素查询。
哈希表是根据关键码的值而直接进行访问的数据结构。一般哈希表都是用来快速判断一个元素是否出现集合里。
std::set 适用于需要存储唯一元素且无序的场景,而 std::map 则适用于存储键值对且需要根据键排序的场景。
在C++中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(log n) | O(log n) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)。
11.哈希冲突
指多个输入对应同一输出的情况,哈希函数的输入空间远大于输出空间,因此理论上哈希冲突是不可避免的
解决办法
-
扩容哈希表:需将所有键值对从原哈希表迁移至新哈希表,非常耗时
-
改良哈希表数据结构:链式地址 和 开放寻址
-
仅在必要时,即当哈希冲突比较严重时,才执行扩容操作。
四、硬件
01.简述处理器中断产生和处理的过程
在处理器中断处理的过程中,一般可以分为以下几个步骤:
-
中断请求:
-
外部设备或软件向处理器发送中断请求信号,通知处理器发生了某种事件需要处理。
-
-
中断响应:
-
处理器接收到中断请求后,在合适的时机(通常是在指令执行完毕后)会作出响应,即立即停止当前正在执行的任务,保存当前的执行现场,并开始处理中断。
-
-
保护现场:
-
处理器会将当前程序计数器、标志寄存器和其他相关寄存器的值保存到堆栈或特定的存储区域,以便在中断处理完成后能够恢复现场。
-
-
中断服务:
-
处理器跳转到预先定义的中断处理程序(中断服务例程)的入口地址开始执行中断服务程序,处理中断请求,执行相应的操作。
-
-
恢复现场:
-
在中断服务程序执行完成后,处理器会从保存的现场信息中还原之前被暂停的程序状态,包括恢复程序计数器、标志寄存器和其他相关寄存器的值。
-
-
中断返回:
-
处理器执行完中断服务程序后,会继续执行被中断的程序,即从保存的现场信息中恢复执行现场,使程序能够在中断处理后继续正常执行。
-
这些步骤确保了处理器在处理中断时能够正确保存和恢复现场,保证系统能够对异步事件做出及时响应,并在处理完中断后能够无缝地返回到之前的执行状态。
02.中断向量和中断嵌套
中断向量是中断服务例程的入口地址,从而开始执行相应的中断处理程序。
中断嵌套是指在处理一个中断过程中,又发生了一个更高优先级的中断请求,导致当前正在处理的中断被打断,处理器需要立即响应更高优先级的中断请求。处理器会保存当前中断的现场信息,并转而处理更高优先级的中断请求,直到所有中断请求都得到处理后,按照优先级逐个恢复现场并返回到之前的执行状态。
03.通信协议

04.UART
UART(Universal Asynchronous Receiver/Transmitter,通用异步收发器)是一种双向、串行、异步的通信总线,3根线分别是:发送线(TX)、接收线(RX)和地线(GND)。
UART 接口不使用时钟信号来同步发送器和接收器设备,而是以异步方式传输数据,同步点是通过两个设备的相同波特率。
协议帧:起始位、数据帧、奇偶校验位和停止位组成,数据位的发送是先发送低位,后发送高位
空闲:高电平。为了开始数据传输,发送UART将传输线从高电平拉到低电平一个时钟周期。当接收UART检测到从高到低的电压转换时,它开始以波特率的频率读取数据帧中的位。


05.IIC
IIC总线总共只有两条信号线,一条是双向的串行数据线SDA,另一条是串行时钟线SCL。
优点:允许多主器件:一主多从或多主多从。任何能够进行发送和接收的设备都可以成为主总线。一个主控能够控制信号的传输和时钟频率,在任何时间点上只能有一个主控。
缺点:总线上的扩展的期间数量是有限制的, 每个连接到IIC总线上的器件都有一个唯一的地址,每个字节长必须为8位长
IIC 总线在传送数据过程中一共有三种类型的信号,它们分别是:开始信号(S)、结束信号(P)和应答信号。
SDA线上的数据在SCL时钟“高”期间必须是稳定的,只有当SCL线上的时钟信号为低时,数据线上的“高”或“低”状态才可以改变。


06.SPI
SPI总线包括4条逻辑线:
MISO:Master input slave output 主机输入,从机输出(数据来自从机);
MOSI:Master output slave input 主机输出,从机输入(数据来自主机);
SCLK : Serial Clock 串行时钟信号,由主机产生发送给从机;
SS:Slave Select 片选信号,由主机发送,以控制与哪个从机通信,通常是低电平有效信号。
在每个SPI时钟周期内,都会发生全双工数据传输。主机在MOSI线上发送一位数据,从机读取它,而从机在MISO线上发送一位数据,主机读取它。就算只进行单向的数据传输,也要保持这样的顺序。这就意味着无论接收任何数据,必须实际发送一些东西!在这种情况下,我们称其为虚拟数据。
SPI的连接方式:“多NSS形式”和”菊花链形式”。
CPOL和CPHA组合出四种情况:00 01 10 11
07.AD/DA
分辨率:是指ADC能够分辨量化的最小信号的能力,用二进制位数表示。要计算ADC的分辨率,需要考虑其位数、参考电压、信号噪声等因素。以一个12位的ADC为例,如果使用5V的参考电压,首先需要确定2的位数次方,即2的12次方等于4096。
采样速率:ADC的采样速率必须小于转换速率,ADC采样频率必须位被测信号频率的两倍
转换时间:将一个模拟信号值转换成一个数字量不能瞬间完成,这个过程需要一定的时间。
量程:指的是允许输入的模拟信号范围
最低有效位(LSB):又称最小分辨率,满量程值除以ADC的分辨率就是LSB
08.DMA
DMA,全称Direct Memory Access,即直接存储器访问。
DMA用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。无须CPU的干预,通过DMA数据可以快速地移动。这就节省了CPU的资源来做其他操作。
09.STM32
STM32F103C8T6:ARM Cortex-M3,主频是72MHz,它的RAM大小是20K,ROM大小是64K,这里的RAM就是运行内存,实际的存储介质是SRAM;这里的ROM就是程序存储器,实际的存储介质是Flash闪存
STM32F413/423 MCU基于支持浮点运算单元的Cortex®-M4内核,它的工作频率可达到100 MHz
五、项目
01.AUV
01.Makefile
Makefile | 爱编程的大丙 (subingwen.cn)
-
语法规则
#每条规则由三个部分组成分别是目标(target), 依赖(depend)和命令(command)。 # 每条规则的语法格式: target1,target2...: depend1, depend2, ... command#每个命令前必须有一个Tab缩进并且独占占一行 ......
-
执行规则
# 规则之间的嵌套 # 规则1 app:a.o b.o c.o gcc a.o b.o c.o -o app # 规则2 a.o:a.c gcc -c a.c # 规则3 b.o:b.c gcc -c b.c # 规则4 c.o:c.c gcc -c c.c #直接make默认执行第一条规则,make target才可以指定哪条规则 #make-->执行第一条规则-->检查依赖是否存在-->不存在则不执行第一条规则-->调用其他规则生成所有的依赖-->执行第一条规则 #make 命令执行的时候会根据文件的时间戳判定是否执行makefile文件中相关规则中的命令 # 目标时间戳 > 所有依赖的时间戳 不执行;反之执行
-
基本语法
#定义变量 #1、自定义变量:变量名=变量值 # 定义变量并赋值 obj=add.o div.o main.o mult.o sub.o # 取变量的值 $(obj) #2、预定义变量 #3、自动变量:自动变量用来代表这些规则中的目标文件和依赖文件,并且它们只能在规则的命令中使用 # 这是一个规则,里边使用了自定义变量,使用自动变量, 替换相关的内容 calc:add.o div.o main.o mult.o sub.o gcc $^ -o $@ # 自动变量只能在规则的命令中使用
变 量 含 义 $* 表示目标文件的名称,不包含目标文件的扩展名 $+ 表示所有的依赖文件,这些依赖文件之间以空格分开,按照出现的先后为顺序,其中可能 包含重复的依赖文件 $< 表示依赖项中第一个依赖文件的名称 $? 依赖项中,所有比目标文件时间戳晚的依赖文件,依赖文件之间以空格分开 $@ 表示目标文件的名称,包含文件扩展名 $^ 依赖项中,所有不重复的依赖文件,这些文件之间以空格分开 -
函数
# $(函数名 参数1, 参数2, 参数3, ...) #wildcard:获取指定目录下指定类型的文件名,其返回值是以空格分割的、指定目录下的所有符合条件的文件名列表 # 使用举例: 分别搜索三个不同目录下的 .c 格式的源文件 src = $(wildcard /home/robin/a/*.c /home/robin/b/*.c *.c) # *.c == ./*.c #patsubst:按照指定的模式替换指定的文件名的后缀 src = a.cpp b.cpp c.cpp e.cpp # 把变量 src 中的所有文件名的后缀从 .cpp 替换为 .o obj = $(patsubst %.cpp, %.o, $(src)) # obj 的值为: a.o b.o c.o e.o
02.CMake
分类: CMake | 爱编程的大丙 (subingwen.cn)
CMAKE_MINIMUM_REQUIRED(VERSION 3.10)
#定义工程名称
PROJECT(client)
#使用树莓派交叉编译工具链来编译你的项目
#set(CMAKE_C_COMPILER /usr/bin/arm-linux-gnueabihf-gcc)
#set(CMAKE_CXX_COMPILER /usr/bin/arm-linux-gnueabihf-g++)
#在 src/device/ 目录下搜索所有的 .c 文件,并将它们保存到名为 SRC_LIST_DEVICE 的变量中。
#GLOB: 将指定目录下搜索到的满足条件的所有文件名生成一个列表,并将其存储到变量中。
#GLOB_RECURSE:递归搜索指定目录,将搜索到的满足条件的文件名生成一个列表,并将其存储到变量中
#CMAKE_CURRENT_SOURCE_DIR 是 CMake 中一个预定义的变量,用于表示当前处理的 CMakeLists.txt 文件所在的目录的绝对路径。
#${PROJECT_SOURCE_DIR}:表示 CMakeLists.txt 文件所在的项目根目录
FILE(GLOB SRC_LIST_DEVICE ${PROJECT_SOURCE_DIR}/src/device/*.c)
#定义变量 各个源文件之间使用分号 ; 间隔或者空格
SET(SOURCE ${PROJECT_SOURCE_DIR}/main.c ;
${SRC_LIST_DEVICE};
${SRC_NETWORK};
${SRC_JSON};
${SRC_MQQT};
${SRC_MQQT_PACKAGE}
)
# 指定头文件目录
INCLUDE_DIRECTORIES(${PROJECT_SOURCE_DIR}/inc;
${PROJECT_SOURCE_DIR}/inc/device;
${PROJECT_SOURCE_DIR}/inc/network;
${PROJECT_SOURCE_DIR}/inc/cjson;
${PROJECT_SOURCE_DIR}/inc/mqtt;
${PROJECT_SOURCE_DIR}/inc/mqtt/MQTTPacket)
# 指定生成库文件的目录
#SET(LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/lib)
#LINK_DIRECTORIES(${PROJECT_SOURCE_DIR}/lib)
#ADD_LIBRARY(myprint SHARED ${SRC_LIST_CPP} ${SRC_LIST_C})
#在这个命令中,main 是可执行文件的名称,${SOURCE} 是一个变量,它包含了该可执行文件所需要的所有源文件的列表。
#这个变量通常是在 CMakeLists.txt 文件中定义的。
#当 CMake 生成 Makefile 后,执行 make 命令即可编译和链接所有源文件,生成名为 main 的可执行文件。
ADD_EXECUTABLE(main ${SOURCE})
#m 是数学库
TARGET_LINK_LIBRARIES(main pthread;m)
#指定可执行程序输出的路径
#第一行:定义一个变量用于存储一个绝对路径;第二行:将拼接好的路径值设置给EXECUTABLE_OUTPUT_PATH宏
set(HOME ${PROJECT_SOURCE_DIR})
set(EXECUTABLE_OUTPUT_PATH ${HOME})
# 输出一般日志信息
message(STATUS "source path: ${PROJECT_SOURCE_DIR}")
# 输出警告信息
message(WARNING "source path: ${PROJECT_SOURCE_DIR}")
# 输出错误信息
message(FATAL_ERROR "source path: ${PROJECT_SOURCE_DIR}")
03.MQTT
MQTT是一个基于客户端-服务器的消息发布/订阅的传输协议。MQTT协议是轻量、简单、开放和易于实现的,这些特点使它适用范围非常广泛。MQTT 与 HTTP 一样,MQTT 运行在传输控制协议/互联网协议 (TCP/IP) 堆栈之上。
-
客户端连接服务端
int mqtt_device_connect(Cloud_MQTT_t *piot_mqtt) { int ret = 0; NewNetwork(&piot_mqtt->Network); ret = ConnectNetwork(&piot_mqtt->Network, MQTT_HOST, (int)MQTT_PORT); if (ret != 0) { printf("mqtt connect network fail \n"); ret = CONNECT_NET_ERROR; goto error; } MQTTClient(&piot_mqtt->Client, &piot_mqtt->Network, 1000, piot_mqtt->mqtt_buffer, MQTT_BUF_SIZE, piot_mqtt->mqtt_read_buffer, MQTT_BUF_SIZE); //CONNECT 报文:固定头(Fixed header)、可变头(Variable header)以及有效载荷(Payload,消息体)。 MQTTPacket_connectData data = MQTTPacket_connectData_initializer; if (piot_mqtt->willFlag) { data.willFlag = 1;//表示如果连接请求被接受了, 遗嘱( Will Message) 消息必须被存储在服务端并且与这个网络连接关联。 之后网络连接关闭时, 服务端必须发布这个遗嘱消息, 除非服务端收到DISCONNECT报文时删除了这个遗嘱消息。 memcpy(&data.will, &piot_mqtt->will, sizeof(MQTTPacket_willOptions)); } else { data.willFlag = 0; } data.MQTTVersion = 3; data.clientID.cstring = MQTT_CLIENT_ID; data.username.cstring = MQTT_USER; data.password.cstring = MQTT_PASS; data.keepAliveInterval = 30;//设置保持连接的时间间隔,以秒为单位。每30S客户端将发送心跳包以保持与服务器的连接。 data.cleansession = 1;//设置清理会话标志。表示客户端断开连接后再次上线时,离线期间发给客户端的所有消息一律接收不到 ret = MQTTConnect(&piot_mqtt->Client, &data);//与 MQTT 代理服务器建立连接 if (ret) { printf("mqtt connect broker fail \n"); ret = MQTT_CONNECT_ERROR; goto error; } // ret = MQTTSubscribe(&piot_mqtt->Client, piot_mqtt->sub_topic, opts.qos, MQTTMessageArrived_Cb); // if (ret) { // printf("mqtt subscribe fail \n"); // ret = MQTTSUBSCRIBE_ERROR; // goto error; // } Iot_mqtt.iotstatus = IOT_STATUS_CONNECT; printf("connect %s %s\n", MQTT_HOST,ret == 0 ? "Success" : "failure"); return CONNECT_SUCCESS; error: return ret; } -
发布消息、订阅主题与取消订阅主题
int mqtt_data_write(char *pbuf, int len, char retain) { Cloud_MQTT_t *piot_mqtt = &Iot_mqtt; int ret = 0; MQTTMessage message; char my_topic[128] = {0}; strcpy(my_topic, piot_mqtt->pub_topic); message.payload = (void *)pbuf; message.payloadlen = len; message.dup = 0; message.qos = QOS0; if (retain) { message.retained = 1;//客户端在订阅了某一主题后马上接收到一条该主题的信息 } else { message.retained = 0; } ret = MQTTPublish(&piot_mqtt->Client, my_topic, &message); //发布一个主题 return ret; }
04.Dijkstra
05.多线程
在没有人为干预的情况下,虚拟地址空间的生命周期和主线程是一样的,与子线程无关。
-
void pthread_exit(void *retval);在编写多线程程序的时候,如果想要让线程退出,但是不会导致虚拟地址空间的释放。只要调用该函数当前线程就马上退出了,并且不会影响到其他线程的正常运行,不管是在子线程或者主线程中都可以使用。
-
int pthread_join(pthread_t thread, void **retval);// 这是一个阻塞函数, 子线程在运行这个函数就阻塞,函数被调用一次,只能回收一个子线程 // 子线程退出, 函数解除阻塞, 回收对应的子线程资源, 类似于回收进程使用的函数 wait() // 已经退出的线程,其空间没有被释放,仍然在进程的地址空间内。创建新的线程不会复用刚才退出线程的地址空间。
-
int pthread_detach(pthread_t thread);调用这个函数之后指定的
子线程就可以和主线程分离,当子线程退出的时候,其占用的内核资源就被系统的其他进程接管并回收了。线程分离之后在主线程中使用pthread_join()就回收不到子线程资源了。但是如果不调用pthread_exit主线程一旦退出子线程也会退出 -
int pthread_cancel(pthread_t thread);在线程A中调用线程取消函数
pthread_cancel,指定杀死线程B,这时候线程B是死不了的,在线程B中进程一次系统调用(从用户区切换到内核区),否则线程B可以一直运行。关于系统调用有两种方式:
-
直接调用Linux系统函数
-
调用标准C库函数,为了实现某些功能,在Linux平台下标准C库函数会调用相关的系统函数
-
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
// 子线程的处理代码
void* working(void* arg)
{
printf("我是子线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<9; ++i)
{
printf("child == i: = %d\n", i);
}
return NULL;
}
int main()
{
// 1. 创建一个子线程
pthread_t tid;
pthread_create(&tid, NULL, working, NULL);
printf("子线程创建成功, 线程ID: %ld\n", tid);
// 2. 子线程不会执行下边的代码, 主线程执行
printf("我是主线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<3; ++i)
{
printf("i = %d\n", i);
}
// 设置子线程和主线程分离
pthread_detach(tid);//无需再调用pthread_join()
// 让主线程自己退出即可
pthread_exit(NULL);//如果不加这行子线程无法执行
return 0;
}
06.线程同步
所谓的同步并不是多个线程同时对内存进行访问,而是按照先后顺序依次进行的。
对于多个线程访问共享资源出现数据混乱的问题,需要进行线程同步。常用的线程同步方式有四种:互斥锁、读写锁、条件变量、信号量。比如如果线程A执行这个过程期间就失去了CPU时间片,线程A被挂起了最新的数据没能更新到物理内存。线程B变成运行态之后从物理内存读数据,很显然它没有拿到最新数据,只能基于旧的数据往后数,然后失去CPU时间片挂起。线程A得到CPU时间片变成运行态,第一件事儿就是将上次没更新到内存的数据更新到内存,但是这样会导致线程B已经更新到内存的数据被覆盖,活儿白干了,最终导致有些数据会被重复数很多次。
-
互斥锁
pthread_mutex_t mutex; // 初始化互斥锁 // restrict: 是一个关键字, 用来修饰指针, 只有这个关键字修饰的指针可以访问指向的内存地址, 其他指针是不行的 int pthread_mutex_init(pthread_mutex_t *restrict mutex,const pthread_mutexattr_t *restrict attr); // 释放互斥锁资源 int pthread_mutex_destroy(pthread_mutex_t *mutex); /* 这个函数被调用, 首先会判断参数 mutex 互斥锁中的状态是不是锁定状态: 没有被锁定, 是打开的, 这个线程可以加锁成功, 这个这个锁中会记录是哪个线程加锁成功了 如果被锁定了, 其他线程加锁就失败了, 这些线程都会阻塞在这把锁上 当这把锁被解开之后, 这些阻塞在锁上的线程就解除阻塞了,并且这些线程是通过竞争的方式对这把锁加锁,没抢到锁的线程继续阻塞 */ int pthread_mutex_lock(pthread_mutex_t *mutex); // 对互斥锁解锁;不是所有的线程都可以对互斥锁解锁,哪个线程加的锁, 哪个线程才能解锁成功。 int pthread_mutex_unlock(pthread_mutex_t *mutex);
-
读写锁
//读写锁是互斥锁的升级版, 在做读操作的时候可以提高程序的执行效率,如果所有的线程都是做读操作, 那么读是并行的,但是使用互斥锁,读操作是串行的。 /* 使用读写锁的读锁锁定了临界区,线程对临界区的访问是并行的,读锁是共享的。 使用读写锁的写锁锁定了临界区,线程对临界区的访问是串行的,写锁是独占的。 写锁比读锁的优先级高,如果说程序中所有的线程都对共享资源有写也有读操作,并且对共享资源读的操作越多,读写锁更有优势 */ pthread_rwlock_t rwlock; // 初始化读写锁 int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,const pthread_rwlockattr_t *restrict attr); // 释放读写锁占用的系统资源 int pthread_rwlock_destroy(pthread_rwlock_t *rwlock); // 在程序中对读写锁加读锁, 锁定的是读操作调用这个函数,如果读写锁是打开的,那么加锁成功;如果读写锁已经锁定了读操作,调用这个函数依然可以加锁成功,因为读锁是共享的;如果读写锁已经锁定了写操作,调用这个函数的线程会被阻塞。 int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock); // 在程序中对读写锁加写锁, 锁定的是写操作。调用这个函数,如果读写锁是打开的,那么加锁成功;如果读写锁已经锁定了读操作或者锁定了写操作,调用这个函数的线程会被阻塞。 int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
-
条件变量
//条件变量只有在满足指定条件下才会阻塞线程,如果条件不满足,多个线程可以同时进入临界区,同时读写临界资源,这种情况下还是会出现共享资源中数据的混乱。 pthread_cond_t cond; // 初始化 int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict attr); // 销毁释放资源 int pthread_cond_destroy(pthread_cond_t *cond); // 线程阻塞函数, 哪个线程调用这个函数, 哪个线程就会被阻塞 //在阻塞线程时候,如果线程已经对互斥锁mutex上锁,那么会将这把锁打开,这样做是为了避免死锁;当线程解除阻塞的时候,函数内部会帮助这个线程再次将这个mutex互斥锁锁上,继续向下访问临界区 int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex); // 唤醒阻塞在条件变量上的线程, 至少有一个被解除阻塞(总个数不定) int pthread_cond_signal(pthread_cond_t *cond); // 唤醒阻塞在条件变量上的线程, 被阻塞的线程全部解除阻塞 int pthread_cond_broadcast(pthread_cond_t *cond);
-
信号量
/* 信号量和条件变量一样用于处理生产者和消费者模型,用于阻塞生产者线程或者消费者线程的运行 信号量优点是无需手动判断条件是否满足,代码简洁 */ #include <semaphore.h> // 初始化信号量/信号灯 /* sem:信号量变量地址 pshared:0:线程同步 非0:进程同步 value:初始化当前信号量拥有的资源数(>=0),如果资源数为0,线程就会被阻塞了。 */ int sem_init(sem_t *sem, int pshared, unsigned int value); // 资源释放, 线程销毁之后调用这个函数即可 // 参数 sem 就是 sem_init() 的第一个参数 int sem_destroy(sem_t *sem); // 当线程调用这个函数,并且sem中的资源数>0,线程不会阻塞,线程会占用sem中的一个资源,因此资源数-1,直到sem中的资源数减为0时,资源被耗尽,因此线程也就被阻塞了。 int sem_wait(sem_t *sem); //调用该函数会将sem中的资源数+1,如果有线程在调用sem_wait、sem_trywait、sem_timedwait时因为sem中的资源数为0被阻塞了,这时这些线程会解除阻塞,获取到资源之后继续向下运行。 int sem_post(sem_t *sem); //通过这个函数可以查看sem中现在拥有的资源个数,通过第二个参数sval将数据传出,也就是说第二个参数的作用和返回值是一样的。 int sem_getvalue(sem_t *sem, int *sval);
//如果生产者和消费者线程使用的信号量对应的总资源数为大于1,需要使用互斥锁进行线程同步 void* producer(void* arg) { // 一直生产 while(1) { // 生产者拿一个信号灯 sem_wait(&psem); // 加锁, 这句代码放到 sem_wait()上边, 有可能会造成死锁 pthread_mutex_lock(&mutex); ...... ...... pthread_mutex_unlock(&mutex); // 通知消费者消费 sem_post(&csem); // 生产慢一点 sleep(rand() % 3); } return NULL; } // 消费者的回调函数 void* consumer(void* arg) { while(1) { sem_wait(&csem); pthread_mutex_lock(&mutex); ...... ...... pthread_mutex_unlock(&mutex); // 通知生产者生成, 给生产者加信号灯 sem_post(&psem); sleep(rand() % 3); } return NULL; }
死锁:所有的线程都被阻塞,并且线程的阻塞是无法解开的(因为可以解锁的线程也被阻塞了)。造成死锁的场景有如下几种:
-
加锁之后忘记解锁(提前
return) -
重复加锁(函数嵌套,两个函数共用一把锁)
-
在程序中有多个共享资源, 因此有很多把锁,随意加锁,导致相互被阻塞
场景描述: 1. 有两个共享资源:X, Y,X对应锁A, Y对应锁B - 线程A访问资源X, 加锁A - 线程B访问资源Y, 加锁B 2. 线程A要访问资源Y, 线程B要访问资源X,因为资源X和Y已经被对应的锁锁住了,因此这个两个线程被阻塞 - 线程A被锁B阻塞了, 无法打开A锁 - 线程B被锁A阻塞了, 无法打开B锁
07.git
#设置用户签名 git config --global user.name licz git config --global user.email chengzhi_li@tju.edu.cn #版本回退 git reset --hard 版本号 #分支的操作 git branch feature #创建分支 git branch -v #查看分支 git checkout feature #切换分支 git merge feature #把指定的分支合并到当前分支上 #解决冲突 #1、提交者的版本库<远程库,修改的地方内容不一样 git pull#同步本地仓库 git push #2、内容冲突 #两个用户修改了同一个文件的同一块区域,git会报告内容冲突 a123 <<<<<<< HEAD b789 ======= b45678910 >>>>>>> 6853e5ff961e684d3a6c02d4d06183b5ff330dcc c #其中:冲突标记<<<<<<< (7个<)与=======之间的内容是我的修改,=======与>>>>>>>之间的内容是别人的修改。 #最简单的编辑冲突的办法,就是直接编辑冲突了的文件(test.txt),把冲突标记删掉,把冲突解决正确。
02.QT
01.窗口类
-
QWidget
-
所有窗口类的基类
-
Qt中的控件(按钮, 输入框, 单选框…)也属于窗口, 基类都是
QWidget -
可以内嵌到其他窗口中: 没有边框
-
可以不内嵌单独显示: 独立的窗口, 有边框
-
-
QDialog
-
对话框类, 后边的章节会具体介绍这个窗口
-
不能内嵌到其他窗口中
-
-
QMainWindow
-
有工具栏, 状态栏, 菜单栏, 后边的章节会具体介绍这个窗口
-
不能内嵌到其他窗口中
-
02.信号槽
所谓信号槽,实际就是观察者模式(发布-订阅模式)。当某个事件发生之后,比如,按钮检测到自己被点击了一下,它就会发出一个信号(signal)。这种发出是没有目的的,类似广播。如果有对象对这个信号感兴趣,它就会使用连接(connect)函数,意思是,将想要处理的信号和自己的一个函数(称为槽(slot))绑定来处理这个信号。也就是说,当信号发出时,被连接的槽函数会自动被回调。这就类似观察者模式:当发生了感兴趣的事件,某一个操作就会被自动触发。
槽函数可以与一个信号关联,当信号被发射时,关联的槽函数被自动执行。信号的本质就是事件。在Qt中我们需要使用QOjbect类中的connect函数进二者的关联。
QMetaObject::Connection QObject::connect(
const QObject *sender, PointerToMemberFunction signal,
const QObject *receiver, PointerToMemberFunction method,
Qt::ConnectionType type = Qt::AutoConnection);
参数:
- sender: 发出信号的对象
- signal: 属于sender对象, 信号是一个函数, 这个参数的类型是函数
指针, 信号函数地址
- receiver: 信号接收者
- method: 属于receiver对象, 当检测到sender发出了signal信号,
receiver对象调用method方法,信号发出之后的处理动作
//Qt4的信号槽连接方式因为使用了宏函数, 宏函数对用户传递的信号槽不会做错误检测, 容易出bug
//Qt5的信号槽连接方式, 传递的是信号槽函数的地址, 编译器会做错误检测, 减少了bug的产生
// 参数 signal 和 method 都是函数地址, 因此简化之后的 connect() 如下:
connect(const QObject *sender, &QObject::signal,
const QObject *receiver, &QObject::method);
connect(const QObject *sender,SIGNAL(信号函数名(参数1, 参数2, ...)),
const QObject *receiver,SLOT(槽函数名(参数1, 参数2, ...)));
connect(&m, SIGNAL(eat(QString)), &m, SLOT(hungury(QString)));
如果想要在QT类中自定义信号槽, 需要满足一些条件, 并且有些事项也需要注意: 要编写新的类并且让其继承Qt的某些标准类 这个新的子类必须从QObject类或者是QObject子类进行派生 在定义类的头文件中加入 Q_OBJECT 宏
自定义信号的要求和注意事项:
信号是类的成员函数
返回值必须是 void 类型
信号的名字可以根据实际情况进行指定
参数可以随意指定, 信号也支持重载
信号需要使用 signals 关键字进行声明, 使用方法类似于public等关键字
信号函数只需要声明, 不需要定义(没有函数体实现)
在程序中发射自定义信号: 发送信号的本质就是调用信号函数
习惯性在信号函数前加关键字: emit, 但是可以省略不写,emit只是显示的声明一下信号要被发射了, 没有特殊含义,底层 emit == #define emit
自定义槽的要求和注意事项:
返回值必须是 void 类型
槽也是函数, 因此也支持重载
槽函数需要指定多少个参数, 需要看连接的信号的参数个数
槽函数的参数是用来接收信号传递的数据的, 信号传递的数据就是信号的参数
Qt中的槽函数可以是类的成员函数、全局函数、静态函数、Lambda表达式(匿名函数)
槽函数可以使用关键字进行声明: slots (Qt5中slots可以省略不写)
一个信号可以连接多个槽函数, 发送一个信号有多个处理动作
需要写多个connect()连接
槽函数的执行顺序是随机的, 和connect函数的调用顺序没有关系
信号的接收者可以是一个对象, 也可以是多个对象
一个槽函数可以连接多个信号, 多个不同的信号, 处理动作是相同的
需要写多个connect()连接
信号可以连接信号

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











