






线程和进程的区别
- 一个进程有一个或者多个线程,共享同一进程的资源。
- 进程是资源分配的单位,线程是任务调度和执行的单元。
- 进程间切换大,线程切换小。
- 一个进程崩死,对其他线程没有影响。
一个线程崩死,整个线程也会崩死
创建线程的四种方式的对比?
- 通过继承Thread类:
-
- 创建一个继承自Thread类的自定义线程类,并重写Thread类的run()方法,将线程要执行的代码逻辑放在run()方法中。然后创建该自定义线程类的实例并调用start()方法来启动线程。
class MyThread extends Thread {
@Override
public void run() {
// 线程要执行的代码逻辑
System.out.println("线程正在执行");
}
}
public class Main {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}
}
- 通过实现Runnable接口:
-
- 创建一个实现Runnable接口的类,该类需要实现run()方法,将线程要执行的代码逻辑放在run()方法中。然后创建该Runnable实现类的实例,将它作为参数传递给Thread类的构造方法,并调用start()方法来启动线程。
class MyRunnable implements Runnable {
@Override
public void run() {
// 线程要执行的代码逻辑
System.out.println("线程正在执行");
}
}
public class Main {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
}
}
- 通过实现Callable接口:
-
- 创建一个实现Callable接口的类,该类需要实现call()方法,将线程要执行的代码逻辑放在call()方法中。然后创建该Callable实现类的实例,并使用ExecutorService提交任务来执行线程。
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
// 线程要执行的代码逻辑
return "线程正在执行";
}
}
public class Main {
public static void main(String[] args) throws Exception {
MyCallable myCallable = new MyCallable();
ExecutorService executorService = Executors.newFixedThreadPool(1);
Future<String> future = executorService.submit(myCallable);
String result = future.get();
System.out.println(result);
executorService.shutdown();
}
}
- 通过使用Executor框架:
-
- 使用Executor框架可以更加方便地管理线程池,执行异步任务。可以通过Executors工厂类来创建不同类型的线程池,然后将Runnable或Callable任务提交给线程池执行。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(1);
executorService.execute(() -> {
// 线程要执行的代码逻辑
System.out.println("线程正在执行");
});
executorService.shutdown();
}
}
上述四种方式都可以用来创建线程,但推荐使用实现Runnable接口或使用Executor框架的方式,因为它们在线程的管理和资源的利用上更加灵活和高效。同时,通过实现Callable接口还可以获取线程执行结果,从而实现更加复杂的并发控制。
Runnable和Callable的区别
Runnable和Callable是Java中两种用于多线程编程的接口,它们之间有以下几点区别:
- 返回值类型:
-
- Runnable:run()方法没有返回值,因此不能直接返回执行结果。
- Callable:call()方法有返回值,可以通过Future对象获取线程执行的结果。
- 异常抛出:
-
- Runnable:run()方法不能抛出受检查异常(checked exception),只能通过try-catch块处理异常。
- Callable:call()方法可以抛出受检查异常,调用时需要进行异常处理。
- 线程执行结果:
-
- Runnable:线程执行完毕后无法直接获取执行结果。
- Callable:线程执行完毕后,可以通过Future对象的get()方法来获取线程的执行结果。
- 使用方式:
-
- Runnable:通常用于需要在多线程环境中执行一些任务,但不需要返回结果的场景。
- Callable:通常用于需要在多线程环境中执行一些任务,并且需要获取执行结果的场景。
示例代码如下:
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("Runnable: 线程正在执行");
}
}
class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
return "Callable: 线程正在执行";
}
}
public class Main {
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 使用Runnable
Runnable runnable = new MyRunnable();
Thread thread1 = new Thread(runnable);
thread1.start();
// 使用Callable
Callable<String> callable = new MyCallable();
FutureTask<String> futureTask = new FutureTask<>(callable);
Thread thread2 = new Thread(futureTask);
thread2.start();
// 获取Callable线程的执行结果
String result = futureTask.get();
System.out.println(result);
}
}
综上所述,Runnable适用于不需要返回结果的场景,而Callable适用于需要返回结果的场景,并且允许抛出受检查异常。在实际开发中,可以根据需求选择合适的接口来实现多线程任务。
线程的状态流转
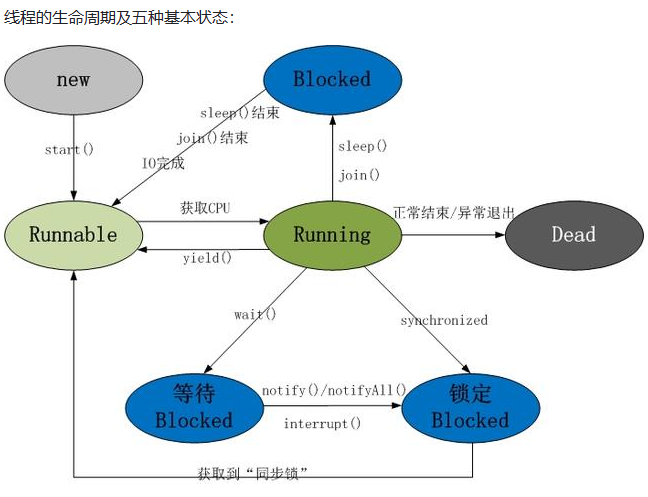
1)新建状态(New):当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread();
2)就绪状态(Runnable):当调用线程对象的start()方法(t.start();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行;
3)运行状态(Running):当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就 绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
4)阻塞状态(Blocked):处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才 有机会再次被CPU调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
1.等待阻塞:运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
2.同步阻塞 — 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
3.其他阻塞 — 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时. join()等待线程终止或者超时. 或者I/O处理完毕时,线程重新转入就绪状态。
5)死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
start
对于Java线程,start()方法是用于启动一个线程的关键方法。在创建一个线程对象后,如果想要该线程开始执行,就必须调用start()方法。
重要的是要理解,直接调用run()方法并不会启动一个新的线程,而只是在当前线程上执行run()方法的代码块。为了在新的线程中执行run()方法,必须使用start()方法。
以下是start()方法的主要作用和用法:
- 启动新线程:调用start()方法会在新的线程上执行run()方法,而不会阻塞当前线程。
- 并发执行:通过多次调用不同线程对象的start()方法,可以实现多线程并发执行,提高程序的执行效率。
- 线程状态转换:在调用start()方法后,新线程会进入就绪状态,等待系统调度并获得CPU执行时间,然后进入运行状态执行run()方法。
示例代码如下:
public class MyThread extends Thread {
public void run() {
// 线程要执行的代码逻辑
}
public static void main(String[] args) {
MyThread thread = new MyThread(); // 创建线程对象
thread.start(); // 启动线程,线程进入就绪状态并等待系统调度
}
}
需要注意的是,一个线程对象的start()方法只能调用一次。如果试图多次调用start()方法,会抛出IllegalThreadStateException异常。此外,如果在调用start()方法之前对线程对象的属性进行修改,可能会导致不可预料的结果。因此,在调用start()方法之后,应避免对线程对象做任何修改。
什么是线程死锁,怎么避免死锁
线程死锁是指在多线程编程中,两个或多个线程因相互持有对方所需要的资源而互相等待,导致程序无法继续执行的情况。简单来说,就是每个线程都在等待其他线程释放资源,从而形成了一个死循环,最终导致程序无法继续执行下去。
线程死锁通常涉及多个锁对象,而且发生死锁的情况可能比较复杂,难以直接察觉。一般死锁发生的条件有以下四个:
- 互斥条件:线程请求的资源是排他性的,即一次只能被一个线程持有。
- 请求与保持条件:线程在持有资源的同时,又请求其他资源。
- 不可剥夺条件:线程持有的资源不能被其他线程抢占,只能由持有资源的线程自行释放。
- 循环等待条件:多个线程形成一个循环等待其他线程释放资源的链条。
为了避免线程死锁,可以采取以下一些常用的策略:
- 破坏互斥条件: 此条件通常是无法破坏的,因为资源本身就是排他性的,一次只能由一个线程使用。因此,解除死锁不能通过破坏互斥条件来实现。
- 破坏请求与保持条件: 当一个线程需要多个资源时,要求它一次性获取所有资源,而不是一个一个地申请。如果某个线程无法同时获取所有需要的资源,就释放已经获取的资源,等待重新获取全部资源。这样可以避免死锁。
- 破坏不可剥夺条件: 当线程已经获取了一些资源,并且正在等待获取其他资源时,如果发现它所等待的资源被其他线程持有,那么它必须释放已经持有的资源,避免形成不可剥夺的状态。
- 破坏循环等待条件: 引入资源的层级顺序,按照顺序申请资源,避免循环等待。例如,对资源进行编号,线程按照编号的顺序申请资源,从而避免形成循环等待的链条。
- 锁排序法:(必须回答出来的点) 指定获取锁的顺序,比如某个线程只有获得A锁和B锁,才能对某资源进行操作,在多线程条件下,如何避免死锁? 通过指定锁的获取顺序,比如规定,只有获得A锁的线程才有资格获取B锁,按顺序获取锁就可以避免死锁。这通常被认为是解决死锁很好的一种方法
sleep()和wait()区别和共同点
区别
- sleep方法:是Thread类的静态方法,当前线程将睡眠n毫秒,线程进入阻塞状态。当睡眠时间到了,会解除阻塞,进入可运行状态,等待CPU的到来。睡眠不释放锁(如果有的话)。
- wait方法:是Object的方法,必须与synchronized关键字一起使用,线程进入阻塞状态,当notify或者notifyall被调用后,会解除阻塞。但是,只有重新占用互斥锁之后才会进入可运行状态。睡眠时,会释放互斥锁。
- sleep 方法没有释放锁,而 wait 方法释放了锁 。
- sleep 通常被用于暂停执行Wait 通常被用于线程间交互/通信
- sleep() 方法执行完成后,线程会自动苏醒。或者可以使用 wait(long timeout)超时后线程会自动苏醒。wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法
相同
两者都可以暂停线程的执行。
为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法
- new 一个 Thread,线程进入了新建状态; 调用start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,(调用 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。)这是真正的多线程工作。
- 直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。 调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。
谈谈volatile的使用及其原理 上代码讲解
volatile是Java中的一个关键字,用于确保线程之间对变量的可见性和禁止指令重排序。在多线程编程中,当一个变量被声明为volatile时,它具有以下特性:
- 可见性:一个线程修改了volatile变量的值,其他线程能够立即看到最新的值。这样可以确保线程之间的通信和数据同步。
- 禁止指令重排序:JVM会禁止对volatile变量的读写指令进行重排序,从而确保在多线程环境下,变量的读写操作按照程序的顺序执行。
下面是一个简单的代码示例,展示了volatile的使用及其原理:
public class VolatileExample {
private volatile boolean flag = false; // 声明一个volatile变量
public void writeFlag() {
flag = true; // 写操作,修改flag的值为true
}
public void readFlag() {
if (flag) {
System.out.println("Flag is true."); // 读操作,检查flag的值是否为true
} else {
System.out.println("Flag is false.");
}
}
public static void main(String[] args) {
VolatileExample example = new VolatileExample();
// 创建一个线程写flag
Thread writeThread = new Thread(() -> {
example.writeFlag();
});
// 创建一个线程读flag
Thread readThread = new Thread(() -> {
example.readFlag();
});
writeThread.start(); // 启动写线程
readThread.start(); // 启动读线程
// 等待两个线程执行完毕
try {
writeThread.join();
readThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
在这个示例中,flag是一个volatile变量。在writeFlag()方法中,我们将flag的值设置为true,表示写操作。在readFlag()方法中,我们读取flag的值并输出结果,表示读操作。
由于flag是volatile变量,写操作对其他线程是可见的,所以当写线程修改了flag的值为true后,读线程会立即看到这个变化,并输出 “Flag is true.”。如果不使用volatile修饰flag变量,可能会出现线程之间的数据不一致问题,因为读线程可能缓存了flag的旧值而不会看到最新的修改。
总结: volatile关键字确保了对变量的写操作对其他线程是可见的,并且禁止了指令重排序,从而提供了一种简单的线程同步机制,用于在多线程编程中实现线程之间的通信和数据同步。但是需要注意,volatile不能替代synchronized关键字,它只能用于简单的场景,对于复杂的线程同步问题,仍然需要使用synchronized等更强大的同步机制。
谈谈yield的使用及其原理 上代码讲解
yield是Java中的一个方法,用于提示调度器当前线程愿意放弃当前的CPU执行时间,让其他具有相同优先级的线程有机会执行。它的使用可以帮助在某些情况下改善多线程的执行效率和公平性。
yield方法的主要特点是它只是一个提示,调度器可以选择忽略它,继续让当前线程执行。因此,yield方法不能保证一定会让出CPU执行时间,它的效果依赖于具体的操作系统和Java虚拟机的实现。
下面是一个简单的代码示例,展示了yield方法的使用及其原理:
public class YieldExample {
public static void main(String[] args) {
Thread t1 = new Thread(new MyRunnable(), "Thread-1");
Thread t2 = new Thread(new MyRunnable(), "Thread-2");
t1.start();
t2.start();
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println(Thread.currentThread().getName() + " is running.");
// 使用yield方法提示调度器放弃当前的CPU执行时间
Thread.yield();
}
}
}
在这个示例中,我们创建了两个线程(t1和t2),它们共享一个MyRunnable对象作为任务,每个线程执行任务时会打印出自己的线程名并提示调度器放弃CPU执行时间。在执行过程中,由于使用了yield()方法,可能会导致线程之间的执行顺序发生变化。
需要注意的是,yield方法主要用于提示调度器,适用于一些特定场景,例如当线程的执行任务比较轻量级且频繁地被调用时,可以使用yield方法让其他线程有机会执行,提高程序的效率。但在大多数情况下,使用yield方法并不能提供明显的性能改进,而且其效果是不确定的,因此在实际开发中较少使用。如果需要更加精确的线程调度控制,通常会使用Thread.sleep()或者更高级的同步机制(如Lock或Semaphore)来实现。
线程阻塞的三种情况
- 等待阻塞(Wait Blocking):
public class WaitBlockingExample {
public static void main(String[] args) {
final Object lock = new Object();
Thread waitingThread = new Thread(() -> {
synchronized (lock) {
try {
System.out.println("Waiting Thread is waiting...");
lock.wait(); // 等待其他线程唤醒
System.out.println("Waiting Thread is woken up!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread notifyingThread = new Thread(() -> {
synchronized (lock) {
System.out.println("Notifying Thread is notifying...");
lock.notify(); // 唤醒等待中的线程
}
});
waitingThread.start(); // 启动等待线程
notifyingThread.start(); // 启动唤醒线程
try {
waitingThread.join();
notifyingThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
在这个示例中,我们创建了一个等待线程(waitingThread)和一个唤醒线程(notifyingThread)。等待线程在同步块内调用wait()方法进入等待状态,唤醒线程在同步块内调用notify()方法唤醒等待中的线程。通过wait()和notify()的配合,实现了线程之间的协调和通信。
- 同步阻塞(Synchronized Blocking):
public class SynchronizedBlockingExample {
public static void main(String[] args) {
final Object lock = new Object();
Thread blockingThread = new Thread(() -> {
synchronized (lock) {
System.out.println("Blocking Thread acquired the lock.");
try {
Thread.sleep(2000); // 模拟耗时操作
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread competingThread = new Thread(() -> {
synchronized (lock) {
System.out.println("Competing Thread acquired the lock.");
}
});
blockingThread.start(); // 启动阻塞线程
try {
Thread.sleep(100); // 等待一段时间,确保阻塞线程先获取到锁
} catch (InterruptedException e) {
e.printStackTrace();
}
competingThread.start(); // 启动竞争线程
try {
blockingThread.join();
competingThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
在这个示例中,我们创建了一个阻塞线程(blockingThread)和一个竞争线程(competingThread)。阻塞线程在同步块内执行耗时操作(使用Thread.sleep()模拟),竞争线程试图获取相同的锁。由于阻塞线程持有锁的时间较长,竞争线程需要等待阻塞线程释放锁才能继续执行。
- 等待超时阻塞(Timed Waiting Blocking):
public class TimedWaitingBlockingExample {
public static void main(String[] args) {
Thread timedWaitingThread = new Thread(() -> {
try {
System.out.println("Timed Waiting Thread is sleeping...");
Thread.sleep(2000); // 等待一段时间
System.out.println("Timed Waiting Thread is awake.");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
timedWaitingThread.start(); // 启动线程
try {
timedWaitingThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
在这个示例中,我们创建了一个线程(timedWaitingThread),它在执行过程中调用Thread.sleep()方法进行等待。线程会等待指定的时间后自动唤醒,然后继续执行。这里的等待时间为2秒,过程中线程处于等待超时阻塞状态。
CAS原理 缺陷
CAS原理:
- CAS操作包含三个参数:内存地址V、预期值A和新值B。
- 当前线程读取内存地址V的值,如果与预期值A相等,则认为当前线程持有了这个值,并将新值B写入内存地址V。
- 如果内存地址V的值与预期值A不相等,说明在此期间有其他线程修改了V的值,CAS操作失败,当前线程需要重新读取V的值并重试CAS操作,直至CAS成功。
优点:
- 无锁:CAS是一种无锁的操作,不会引起线程的阻塞,避免了线程切换和上下文切换的开销。
- 高并发性:由于没有锁的竞争,CAS可以在高并发环境下实现更好的性能表现。
- 避免死锁:由于CAS不涉及锁的概念,因此不会出现死锁问题。
缺陷:
- ABA问题:CAS是基于内存值是否发生变化来判断是否更新的。如果线程A读取了值为A的内存地址,然后线程B将值改为了B,然后又改回A,此时线程A使用CAS操作比较内存值与预期值A相等,然后进行更新。但实际上,期间该内存值已经经历了A到B再到A的变化,这样的更新可能会引起数据不一致问题。
- 循环开销:CAS操作失败时,线程会进行自旋重试,如果一直无法成功,会造成不必要的CPU资源浪费。
- 只能保证一个共享变量的原子操作:CAS只能针对一个共享变量进行原子操作,无法实现多个共享变量的复合操作。
针对ABA问题,可以使用版本号或标记位等方式来解决。针对自旋开销,可以设置自旋次数限制,避免无限制的自旋。针对只能保证一个共享变量的原子操作,可以使用锁等其他同步机制来解决。
尽管CAS存在一些缺陷,但在某些场景下它仍然是一种高效的同步手段,特别是对于只涉及一个共享变量的简单操作。在实际开发中,需要根据具体情况选择合适的同步方式来保证线程安全。
synchronized 和 volatile 的区别是什么?
- 作用范围:
-
- volatile:用于修饰变量,保证变量的可见性,即当一个线程修改了被volatile修饰的变量时,其他线程可以立即看到修改后的值。
- synchronized:用于修饰代码块或方法,实现多线程之间的互斥同步,确保在同一时刻只有一个线程可以执行被synchronized修饰的代码块或方法。
- 实现机制:
-
- volatile:通过内存屏障(memory barrier)和禁止指令重排序的方式来确保变量的可见性,但不能保证原子性。
- synchronized:通过获取锁来实现互斥同步,保证了代码块或方法的原子性和可见性。
下面通过代码示例来说明volatile和synchronized的区别:
public class VolatileVsSynchronizedExample {
private volatile int volatileCounter = 0;
private int synchronizedCounter = 0;
// 使用volatile修饰的变量进行自增操作
public void volatileIncrement() {
volatileCounter++;
}
// 使用synchronized关键字修饰的方法进行自增操作
public synchronized void synchronizedIncrement() {
synchronizedCounter++;
}
public static void main(String[] args) {
VolatileVsSynchronizedExample example = new VolatileVsSynchronizedExample();
// 创建多个线程进行自增操作
for (int i = 0; i < 5; i++) {
new Thread(() -> {
for (int j = 0; j < 10000; j++) {
example.volatileIncrement();
example.synchronizedIncrement();
}
}).start();
}
// 等待所有线程执行完毕
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("volatileCounter: " + example.volatileCounter);
System.out.println("synchronizedCounter: " + example.synchronizedCounter);
}
}
在上述代码中,我们创建了多个线程进行自增操作,其中volatileIncrement()方法使用了volatile修饰的变量进行自增,而synchronizedIncrement()方法使用synchronized关键字修饰进行自增。
运行这段代码,你会发现:
- volatileCounter使用volatile修饰,虽然保证了变量的可见性,但由于没有保证原子性,因此结果可能是不确定的。多个线程同时对volatileCounter进行自增操作,可能会导致竞争条件和结果不准确。
- synchronizedCounter使用synchronized关键字进行互斥同步,保证了线程安全和原子性,因此结果是可预测的,每次运行的结果都是正确的。
综上所述,volatile适用于保证变量的可见性,而synchronized适用于实现多线程之间的互斥同步,保证线程安全和原子性。根据具体的需求选择合适的关键字来确保多线程程序的正确性和性能。
synchronized 原理 作用范围 用法
\1. 底层原理:
- synchronized 的底层原理是基于 Java 对象的内置锁(也称为监视器锁或互斥锁)实现的。
- 每个 Java 对象都与一个监视器关联,该监视器就是内置锁。当一个线程进入 synchronized 代码块或方法时,它会尝试获取该对象的内置锁。
- 如果锁没有被其他线程占用,当前线程就会获得该锁,进入 synchronized 块执行操作。
- 如果锁已被其他线程占用,当前线程会被阻塞等待,直到获取到锁后才能进入 synchronized 块。
\2. 作用范围:
- synchronized 可以用于实例方法、静态方法和代码块。作用范围如下:
- 实例方法:synchronized 修饰的实例方法在同一对象实例上获取锁,使得同一时间内只能有一个线程调用该实例方法。
- 静态方法:synchronized 修饰的静态方法在类级别上获取锁,使得同一时间内只能有一个线程调用该静态方法。因为静态方法属于类级别,所以获取的是类对象的锁。
- 代码块:synchronized 修饰的代码块需要指定一个对象作为锁,该代码块在同一时间内只能有一个线程执行。多个线程可以在不同的代码块上并发执行,只要它们使用的锁对象不同。
\3. 用法:
- 使用 synchronized 关键字有两种方式:同步代码块和同步方法。
a. 同步代码块:
public class SynchronizedExample {
private int count = 0;
private Object lock = new Object(); // 锁对象
public void increment() {
synchronized (lock) { // 同步代码块
count++;
}
}
}
b. 同步方法:
public class SynchronizedExample {
private int count = 0;
public synchronized void increment() { // 同步方法
count++;
}
}
- 同步代码块需要手动指定锁对象,可以是任意对象。多个线程需要使用相同的锁对象才能保证同步效果。
- 同步方法则自动使用当前实例(实例方法)或类对象(静态方法)作为锁。
- 在使用 synchronized 时,要避免锁定粒度过大或过小,过大可能导致性能问题,过小可能失去同步效果。
- 注意在多线程环境下修改共享数据时,需要全部使用 synchronized 来保证数据一致性,避免部分代码忘记加锁而引发问题。
代码讲解: 上面的示例代码演示了 synchronized 的两种用法:
- 同步代码块:在 increment() 方法中,使用 synchronized 关键字修饰一个代码块,该代码块使用 lock 对象作为锁。这样在执行 increment() 方法时,同一时间内只能有一个线程执行该代码块,保证了 count 的正确增加。
- 同步方法:在第二个示例中,直接在 increment() 方法上使用 synchronized 关键字,这样该方法默认使用当前对象实例作为锁。因为是实例方法,所以同一时间只能有一个线程执行该方法。
无论是使用同步代码块还是同步方法,都能确保多线程环境下 count 的自增操作是线程安全的,不会产生竞态条件。
ThreadLocal 是什么 底层原理 内存泄漏
ThreadLocal 是什么:
- ThreadLocal 是 Java 中的一个线程级别的变量副本保存机制。
- 它允许每个线程在使用时都拥有独立的变量副本,线程之间的变量互不干扰,是实现线程安全的一种方式。
- 主要用于在多线程环境中,为每个线程维护一个独立的变量副本,以避免共享变量导致的线程安全问题。
底层原理:
- ThreadLocal 是通过 ThreadLocalMap 实现的。
- 每个 ThreadLocal 对象都有一个与之对应的 ThreadLocalMap。
- 在多线程环境中,每个线程通过 ThreadLocal 对象的引用来操作自己的 ThreadLocalMap。
- 每个线程在 ThreadLocalMap 中维护一组键值对,其中键是 ThreadLocal 对象,值是线程持有的变量副本。
内存泄漏问题:
- ThreadLocal 可能导致内存泄漏问题,主要是因为线程在使用完 ThreadLocal 后没有进行垃圾回收,而 ThreadLocalMap 中仍然持有对 ThreadLocal 对象的引用。
- 如果线程一直存在,并且不停地创建 ThreadLocal 对象,那么 ThreadLocalMap 就会持有越来越多的 ThreadLocal 引用,导致内存泄漏。
弱引用:只要垃圾回收机制一运行,不管JVM的内存空间是否充足,都会回收该对象占用的内存。
弱引用比较容易被回收。因此,如果ThreadLocal(ThreadLocalMap的Key)被垃圾回收器回收了,但是因为ThreadLocalMap生命周期和Thread是一样的,它这时候如果不被回收,就会出现这种情况:ThreadLocalMap的key没了,value还在,这就会**「造成了内存泄漏问题」**。
如何**「解决内存泄漏问题」**?使用完ThreadLocal后,及时调用remove()方法释放内存空间。
代码讲解: 下面我们来演示一个可能导致内存泄漏的 ThreadLocal 代码:
import java.util.concurrent.TimeUnit;
public class ThreadLocalLeakExample {
private static ThreadLocal<byte[]> threadLocal = new ThreadLocal<>();
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
threadLocal.set(new byte[1024 * 1024]); // 每个线程设置一个1MB的数组到 ThreadLocal
// threadLocal.remove(); // 可以通过 remove 方法手动清理 ThreadLocal
System.out.println(Thread.currentThread().getName() + " set 1MB");
}).start();
}
TimeUnit.SECONDS.sleep(5); // 等待所有线程执行完毕
// 手动清理 ThreadLocal
threadLocal.remove();
}
}
运行上述代码后,会看到内存中的占用不断增加,并且线程执行完毕后,内存并没有释放。这是因为每个线程创建的 ThreadLocal 引用没有得到释放,导致内存泄漏。
为避免 ThreadLocal 内存泄漏,我们可以在每个线程使用完 ThreadLocal 后,调用 threadLocal.remove() 方法手动清理 ThreadLocal。这样就能释放线程所持有的 ThreadLocal 引用,使得相关内存能够被回收。
线程池Demo
下面是一个简单的 Java 线程池示例代码:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolDemo {
public static void main(String[] args) {
// 创建一个固定大小为 3 的线程池
ExecutorService executor = Executors.newFixedThreadPool(3);
// 提交 5 个任务给线程池处理
for (int i = 0; i < 5; i++) {
RunnableTask task = new RunnableTask(i);
executor.execute(task);
}
// 关闭线程池
executor.shutdown();
}
}
class RunnableTask implements Runnable {
private int taskId;
public RunnableTask(int taskId) {
this.taskId = taskId;
}
@Override
public void run() {
System.out.println("Task " + taskId + " is running on Thread " + Thread.currentThread().getName());
try {
// 模拟任务执行时间
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Task " + taskId + " is done on Thread " + Thread.currentThread().getName());
}
}
这个示例创建了一个固定大小为 3 的线程池,并提交了 5 个任务给线程池处理。每个任务都是一个实现了 Runnable 接口的 RunnableTask 对象。每个任务打印了任务编号和当前执行任务的线程名,并模拟了任务执行时间为 2 秒。
输出结果可能类似于:
arduinoCopy code
Task 0 is running on Thread pool-1-thread-1
Task 1 is running on Thread pool-1-thread-2
Task 2 is running on Thread pool-1-thread-3
Task 0 is done on Thread pool-1-thread-1
Task 3 is running on Thread pool-1-thread-1
Task 1 is done on Thread pool-1-thread-2
Task 4 is running on Thread pool-1-thread-2
Task 2 is done on Thread pool-1-thread-3
Task 3 is done on Thread pool-1-thread-1
Task 4 is done on Thread pool-1-thread-2
从输出可以看出,线程池中的三个线程分别处理了五个任务,线程在处理完一个任务后又处理了另一个任务,实现了线程的重用。同时,由于线程池大小为 3,所以只有三个任务可以同时执行,其余的任务等待线程池中的线程空闲后再处理。
线程池的特点 怎么使用
线程池的特点:
- 线程重用: 线程池中的线程可以被重复利用,避免了频繁地创建和销毁线程,节省了系统资源。
- 线程数量控制: 线程池可以限制线程的数量,避免因为线程过多导致系统资源耗尽或性能下降。
- 任务队列: 线程池通常有一个任务队列,用于存储等待执行的任务。线程池中的线程从任务队列中获取任务进行处理。
- 线程管理: 线程池负责线程的创建、销毁和管理,简化了线程的管理工作。
- 线程复用: 线程池中的线程可以被重复利用,避免了频繁地创建和销毁线程,节省了系统资源。
如何使用线程池:
Java 提供了 Executor 框架用于创建和管理线程池。通常可以通过以下步骤来使用线程池:
- 创建线程池: 使用 Executors 工厂类中的静态方法创建线程池。例如:
ExecutorService executor = Executors.newFixedThreadPool(5); // 创建一个固定大小的线程池,线程数量为 5
- 提交任务: 使用线程池的 execute() 或 submit() 方法提交任务。例如:
executor.execute(new RunnableTask()); // 提交一个实现了 Runnable 接口的任务
executor.submit(new CallableTask()); // 提交一个实现了 Callable 接口的任务
- 关闭线程池: 在不再需要使用线程池时,应该显式地关闭它,释放资源。使用 shutdown() 方法平缓地关闭线程池,等待所有任务执行完成后关闭。
executor.shutdown();
- 处理结果(可选): 如果提交的任务是 Callable 类型,可以通过 Future 对象获取任务执行的结果。例如:
Future<String> futureResult = executor.submit(new CallableTask());
String result = futureResult.get(); // 获取任务执行结果,get() 方法会阻塞直到任务完成并返回结果
需要根据实际业务需求和系统负载情况来选择合适的线程池类型(例如 FixedThreadPool、CachedThreadPool、SingleThreadExecutor 等)以及合理的线程池大小,避免线程池过大或过小导致性能问题。正确使用线程池可以提高系统的稳定性和性能。
execute和submit方法的区别
在 Java 的线程池中,execute() 和 submit() 是用于提交任务的两种方法。它们之间有以下主要区别:
- 返回值:
-
- execute() 方法没有返回值,因此无法获取任务执行的结果。
- submit() 方法返回一个 Future 对象,通过这个 Future 对象可以获取任务执行的结果。
- 异常处理:
-
- execute() 方法无法捕获任务抛出的异常。如果任务在执行过程中发生异常,异常将会被线程池内部捕获并记录下来,但不会传递给调用者。
- submit() 方法可以通过 Future 对象的 get() 方法获取任务执行结果,并且在获取结果时会抛出异常,因此可以捕获任务执行过程中抛出的异常。
- 接收任务类型:
-
- execute() 方法只接收 Runnable 类型的任务,即无返回结果的任务。
- submit() 方法既可以接收 Runnable 类型的任务,也可以接收 Callable 类型的任务,即可以处理有返回结果的任务。
- 异常包装:
-
- execute() 方法将任务抛出的异常封装到 java.util.concurrent.ExecutionException 中,并在任务执行异常时通过内部的 UncaughtExceptionHandler 进行处理。
- submit() 方法也将任务抛出的异常封装到 java.util.concurrent.ExecutionException 中,但是通过 Future 的 get() 方法获取任务执行结果时,会将异常重新抛出,由调用者处理。
- 适用场景:
-
- execute() 适用于不关心任务执行结果的场景,只需要执行任务,而不关心任务是否成功或返回结果。
- submit() 适用于需要获取任务执行结果的场景,可以通过 Future 对象来获取任务执行结果,并处理可能的异常。
示例代码:
importjava.util.concurrent.*;import java.util.concurrent.*;
public class ExecuteVsSubmitDemo {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(2);
// 使用 execute() 提交任务
executor.execute(() -> {
System.out.println("Executing task using execute()");
});
// 使用 submit() 提交任务
Future<String> futureResult = executor.submit(() -> {
System.out.println("Executing task using submit()");
return "Task Result";
});
// 关闭线程池
executor.shutdown();
try {
// 获取 submit() 方法提交的任务执行结果
String result = futureResult.get();
System.out.println("Result from submit() method: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
运行上述代码,输出可能类似于:
sqlCopy code
Executing task using execute()
Executing task using submit()
Result from submit() method: Task Result
从输出可以看出,使用 execute() 方法提交的任务没有返回结果,而使用 submit() 方法提交的任务可以通过 Future 对象获取任务的执行结果
线程池核心参数
- corePoolSize(核心线程数):
-
- 核心线程数是线程池中的基本线程数量,即线程池保持的最小线程数量。
- 在没有任务需要执行时,核心线程也会一直存活,除非设置了 allowCoreThreadTimeOut 参数。
- 核心线程数的数量通常是根据应用程序的负载和硬件配置来决定的。
- maximumPoolSize(最大线程数):
-
- 最大线程数是线程池中允许的最大线程数量,包括核心线程和非核心线程。
- 在队列满了且正在运行的线程数小于最大线程数时,线程池会创建新的线程处理任务。
- 最大线程数的设置应该根据系统资源和负载情况来调整,避免线程数过多导致性能下降。
- keepAliveTime(线程空闲时间):
-
- 当线程池中的线程数量超过核心线程数时,多余的空闲线程会被销毁,直到线程池的大小等于核心线程数。
- keepAliveTime 是非核心线程在空闲状态下存活的时间。超过这个时间,非核心线程会被销毁。
- allowCoreThreadTimeOut 参数可以决定是否对核心线程也进行空闲时间的处理。
- unit(时间单位):
-
- keepAliveTime 参数的时间单位。可以是秒、毫秒、分钟等。
- workQueue(任务队列):
-
- 任务队列是用于存储待执行任务的队列,当线程池中的线程数达到核心线程数时,多余的任务会被放入队列中等待执行。
- 线程池提供了多种任务队列的实现,如无界队列(LinkedBlockingQueue)和有界队列(ArrayBlockingQueue、LinkedBlockingQueue)等。
- threadFactory(线程工厂):
-
- 线程工厂用于创建新的线程。可以自定义线程工厂,以便为线程池中的线程命名、设置优先级等。
- rejectedExecutionHandler(拒绝策略):
-
- 当线程池无法处理新提交的任务时,拒绝策略定义了应该如何处理这些任务。
- JDK 提供了几种默认的拒绝策略,如 AbortPolicy(默认)、CallerRunsPolicy、DiscardPolicy 和 DiscardOldestPolicy
线程池拒绝策略
- AbortPolicy(默认):
-
- 这是线程池的默认拒绝策略,当线程池无法处理新提交的任务时,会抛出一个 RejectedExecutionException 异常,通知调用者任务被拒绝。
- 使用这个策略时,任务会被立即拒绝,不会进行重试或者等待。
- CallerRunsPolicy:
-
- 使用这个策略时,当线程池无法处理新提交的任务时,会把任务交给提交任务的线程来执行。
- 这样做的效果是,提交任务的线程会暂时阻塞等待任务执行完成,以便为线程池腾出资源。
- DiscardPolicy:
-
- 这个策略直接将被拒绝的任务丢弃,不做任何处理。
- 使用这个策略时,任务被提交后会被默默地抛弃掉,不会有任何提示或者记录。
- DiscardOldestPolicy:
-
- 这个策略会将线程池队列中最早的未处理任务删除,然后尝试再次提交当前任务。
- 使用这个策略时,线程池会优先处理最新提交的任务,最早的任务会被丢弃。
自定义拒绝策略: 除了使用上述默认的拒绝策略,你还可以通过实现 RejectedExecutionHandler 接口来定义自己的拒绝策略。实现自定义的拒绝策略时,需要实现 RejectedExecutionHandler 接口的 rejectedExecution() 方法,该方法在任务被拒绝时会被调用。你可以在这个方法中实现自己的拒绝逻辑,例如记录日志、发送告警等操作。
示例代码:
import java.util.concurrent.*;
public class CustomRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 自定义拒绝策略:记录日志并打印错误信息
System.err.println("Task " + r.toString() + " rejected from " + executor.toString());
}
}
public class ThreadPoolDemo {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(
2, // corePoolSize
4, // maximumPoolSize
60, TimeUnit.SECONDS, // keepAliveTime
new ArrayBlockingQueue<>(10), // workQueue
new CustomRejectedExecutionHandler()); // 自定义拒绝策略
// 提交多个任务给线程池处理
for (int i = 0; i < 15; i++) {
RunnableTask task = new RunnableTask(i);
executor.execute(task);
}
// 关闭线程池
executor.shutdown();
}
}
class RunnableTask implements Runnable {
private int taskId;
public RunnableTask(int taskId) {
this.taskId = taskId;
}
@Override
public void run() {
System.out.println("Task " + taskId + " is running on Thread " + Thread.currentThread().getName());
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Task " + taskId + " is done on Thread " + Thread.currentThread().getName());
}
}
在上述代码中,我们自定义了一个实现了 RejectedExecutionHandler 接口的 CustomRejectedExecutionHandler 类,用于自定义拒绝策略。然后将这个自定义拒绝策略传递给线程池构造函数,这样线程池在无法接受新的任务时,就会调用我们自定义的拒绝策略来处理被拒绝的任务。在 CustomRejectedExecutionHandler 类中,我们简单地将被拒绝的任务信息输出到标准错误流。
线程池执行任务流程
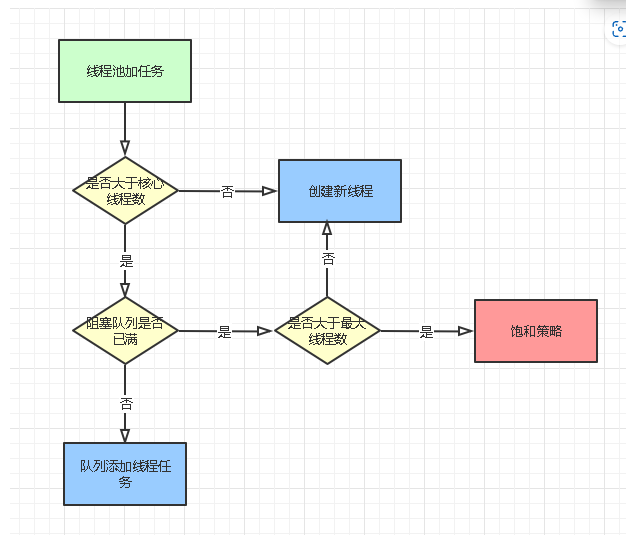
- 线程池执行execute/submit方法向线程池添加任务,当任务小于核心线程数corePoolSize,线程池中可以创建新的线程。
- 当任务大于核心线程数corePoolSize,就向阻塞队列添加任务。
- 如果阻塞队列已满,需要通过比较参数maximumPoolSize,在线程池创建新的线程,当线程数量大于maximumPoolSize,说明当前设置线程池中线程已经处理不了了,就会执行饱和策略。















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









