






 本文介绍了如何使用Python和PyPDF2库来获取PDF文件的页数,并实现按需裁剪PDF,只保留指定页面。方法包括读取文件、创建PdfReader和PdfWriter对象,以及实现文件页数校验和裁剪功能。
本文介绍了如何使用Python和PyPDF2库来获取PDF文件的页数,并实现按需裁剪PDF,只保留指定页面。方法包括读取文件、创建PdfReader和PdfWriter对象,以及实现文件页数校验和裁剪功能。
使用python对pdf文件进行按页裁剪
- 获取PDF文件页数
PyPDF2库使得获取PDF文件页数变得轻而易举。以下简单的方法获取页数。
def get_file_pages(file_path: str) -> int:
""" 获取文件页数 """
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
return len(pdf_reader.pages)
- 文件页数校验与裁剪
在某些情况下,你可能需要裁剪PDF文件以满足特定需求。PyPDF2库为此提供了方便的功能,你只需指定要保留的页面数量即可。
def crop_pdf(self, input_file_path, output_file_path, num_pages_to_keep):
"""
文件裁剪
input_file_path : 带转化文件path(包含文件名)
output_file_path : 转化后文件path(包含文件名)
num_pages_to_keep:保留的页数
"""
with open(input_file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
# 创建一个新的PDF写入器
pdf_writer = PyPDF2.PdfWriter()
# 循环遍历要保留的页面并将其添加到新的PDF中
for page_num in range(num_pages_to_keep):
if page_num < len(pdf_reader.pages):
pdf_writer.add_page(pdf_reader.pages[page_num])
# 将新的PDF写入输出文件
with open(output_file_path, 'wb') as output_file:
pdf_writer.write(output_file)
- 完整代码
import os
import PyPDF2
class FileProcessing:
"""
功能:
1:文件格式转化为pdf
2:获取pdf文件页数服务
3:文件页数校验,文件裁剪
"""
def __init__(self):
super(FileProcessing, self).__init__()
def check_file_exist(self, file_path):
if os.path.exists(file_path):
return True
else:
return False
def get_file_pages(self, file_path: str) -> int:
""" 获取文件页数 """
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
return len(pdf_reader.pages)
def crop_pdf(self, input_file_path, output_file_path, num_pages_to_keep):
"""
文件裁剪
input_file_path : 带转化文件path(包含文件名)
output_file_path : 转化后文件path(包含文件名)
num_pages_to_keep:保留的页数
"""
with open(input_file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
# 创建一个新的PDF写入器
pdf_writer = PyPDF2.PdfWriter()
# 循环遍历要保留的页面并将其添加到新的PDF中
for page_num in range(num_pages_to_keep):
if page_num < len(pdf_reader.pages):
pdf_writer.add_page(pdf_reader.pages[page_num])
# 将新的PDF写入输出文件
with open(output_file_path, 'wb') as output_file:
pdf_writer.write(output_file)
- 使用示例
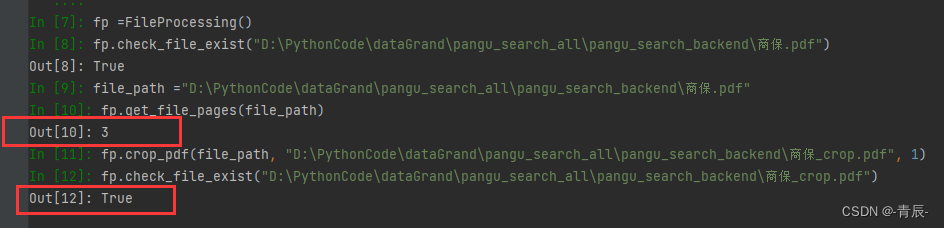

以上便是pdf文件处理的全部代码了!
【文章编写不易,如需转发请联系作者!】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









