







目录
人脸关键点检测是一个非常核心的算法业务,其在许多场景中都有应用。比如我们常用的换脸、换妆、人脸识别等2C APP中的功能,都需要先进行人脸关键点的检测,然后再进行其他的算法业务处理;在一些2B的业务场景中,如疲劳驾驶中对人脸姿态的估计,也可以先进行人脸关键点的检测,然后再通过2D到3D的估计,最后算出人脸相对相机的姿态角。
如图所示,PFLD算法可以以很小的网络模型,在常见的人脸关键点检测数据集上得出不错的结果(300W数据集中nme为0.0453,在WFLW数据集上nme为0.0693)。

如果你对MindSpore感兴趣,可以关注昇思MindSpore社区


一、环境准备
1.进入ModelArts官网
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,获取安装命令,安装MindSpore2.0.0-alpha版本,可以在昇思教程中进入ModelArts官网

选择下方CodeLab立即体验

等待环境搭建完成

2.使用CodeLab体验Notebook实例
下载NoteBook样例代码,PFLD:实时人脸关键点检测算法 ,.ipynb为样例代码
打开一个terminal,将项目clone下来
git clone https://github.com/mindspore-courses/applications.git
找到plfd.ipynb
选择Kernel环境

切换至GPU环境,切换成第一个限时免费

进入昇思MindSpore官网,点击上方的安装

获取安装命令

回到Notebook中,在第一块代码前加入命令

conda update -n base -c defaults conda

安装MindSpore 2.0 GPU版本
conda install mindspore=2.0.0a0 -c mindspore -c conda-forge

安装mindvision
pip install mindvision

安装下载download
pip install download

二、案例实现
数据处理
开始实验之前,请确保本地已经安装了Python环境并安装了MindSpore Vision套件。
数据准备
本案例使用300W数据集作为训练集和验证集。请在官网https://ibug.doc.ic.ac.uk/resources/300-W/下载afw,helen,ibug,ifpw这四个文件。
300W数据集简介
300W数据集是一个非常通用的人脸对齐数据集,也是近年来凡paper,都要出指标比对的必然数据集。下载链接:https://ibug.doc.ic.ac.uk/resources/300-W/
该数据集共计3148+689张图像,每个图像上包含不止一张人脸,但是对于每张图像只标注一张人脸。
该数据集包含的文件目录为:
afw(train 337) https://ibug.doc.ic.ac.uk/download/annotations/afw.zip
helen(train 2000 + test 330)
https://ibug.doc.ic.ac.uk/download/annotations/helen.zipibug(test 135)
https://ibug.doc.ic.ac.uk/download/annotations/ibug.ziplfpw(train 811 + test 224)
https://ibug.doc.ic.ac.uk/download/annotations/lfpw.zip该数据集训练集共计3148张图像,测试集共计689张图像
其中每个图像上包含不止一张人脸,但是对于每张图像只标注一张人脸。由以上4个文件夹组成的训练集共计3148张图像,测试集有689张图像。
请将解压后的数据集放到./datasets/300W/300W_images/下,文件目录如下所示:
.datasets/
└── 300W
├── 300W_annotations
└── Mirrors68.txt
└── 300W_images
├── afw
├── helen
├── ibug
└── ifpw
数据预处理
原始数据集中并没有将训练集的图片和关键点进行汇总,而是存储在pts文件中,非常分散,不利于数据集加载。
因此,运行以下代码对数据中的关键点和样本路径进行收集汇总以便后续的训练和评估过程。
import os
from src.datasets.get_annotations import get_annotation
# 300W数据集的根路径
root_dir = os.path.dirname(os.path.abspath('./') + '/datasets/300W/')
# 定义训练数据和测试数据的注释文件的存储路径
fw_path_train = os.path.join(
root_dir,
'300W_annotations/list_68pt_rect_attr_train.txt')
fw_path_test = os.path.join(
root_dir,
'300W_annotations/list_68pt_rect_attr_test.txt')
# 将注释信息保存值注释文件中
get_annotation(root_dir, fw_path_train, fw_path_test)
运行成功后,将生成list_68pt_rect_attr_train.txt和list_68pt_rect_attr_test.txt两个文件。
数据增强
在300W数据集中,尽管已经重新标注了四个数据集并统一为68个坐标点,但是对于网络而言数据量仍然不大,因此使用旋转、平移等操作将训练数据进行数据增强。
import shutil
import os
from src.datasets.augmentation import get_dataset_list
# 数据集的根路径
root_dir = os.path.dirname(os.path.abspath('./') + '/datasets/300W/')
# 图片文件的路径
image_dirs = 'datasets/300W/300W_images'
# 注释文件的路径,包括训练和测试集
landmark_dirs = ['datasets/300W/300W_annotations/list_68pt_rect_attr_train.txt',
'datasets/300W/300W_annotations/list_68pt_rect_attr_test.txt']
# 训练集和数据集处理之后的保存路径
out_dirs = ['train_data', 'test_data']
for landmark_dir, out_dir in zip(landmark_dirs, out_dirs):
# 得到保存路径
out_dir = os.path.join(root_dir, out_dir)
# 如果没有此文件夹,就创建
if os.path.exists(out_dir):
shutil.rmtree(out_dir)
os.mkdir(out_dir)
# 只对训练数据做增强
if 'list_68pt_rect_attr_test.txt' in landmark_dir:
is_train = False
else:
is_train = True
# 保存图像(3*112*112)及注释文件
get_dataset_list(image_dirs, out_dir, landmark_dir, is_train)

数据加载
通过数据集加载接口加载数据集,并转换为Tensor以备输入模型。
import mindspore.dataset as ds
from mindspore.dataset import vision
from src.datasets.data_loader import Datasets300W
from src.pfld_utils.utils import map_func
# 定义数据集图片中的通道转换及归一化操作
transform = vision.py_transforms.ToTensor()
# 生成指定batch的数据集
dataset_generator = Datasets300W('datasets/300W/train_data/list.txt', transform)
dataset = ds.GeneratorDataset(source=list(dataset_generator),
column_names=["img", "landmark", "attributes", "angle"],
shuffle=True)
dataset = dataset.batch(batch_size=256,
input_columns=["attributes"],
output_columns=["weight_attribute"],
per_batch_map=map_func)
训练集可视化
运行以下代码观察数据增强后的图片。可以发现图片经过了旋转处理,并且图片的shape也已经转换为待输入网络的(N,C,H,W)格式,其中N代表样本数量,C代表图片通道,H和W代表图片的高和宽。
import numpy as np
import matplotlib.pyplot as plt
show_data = next(dataset.create_dict_iterator())
show_images = show_data["img"].asnumpy()
print(f'Image shape: {show_images.shape}')
plt.figure()
# 展示图片供参考
for i in range(1, 9):
plt.subplot(2, 4, i)
# 将图片转换HWC格式
image_trans = np.transpose(show_images[i - 1], (1, 2, 0))
image_trans = np.clip(image_trans, 0, 1)
plt.imshow(image_trans[:, :, [2, 1, 0]])
plt.axis("off")
plt.subplots_adjust(wspace=0.05, hspace=0)

网络结构
前文提到过PFLD模型的骨干网络采用了MobileNet网络,其中采用了大量的卷积层用于提取面部特征,由于人脸除了丰富的细节特征,还包含不同器官间之间的结构特征。所以,在主干网络的最后将多个尺度的特征结合起来以增强关键点的检测效果。
图中黄色框的部分代表了网络的骨干部分,主要由MobileNet构成用于提取特征,在骨干网络的后半部分有明显大小不同的三组特征图,这代表了不同尺度的特征图,通过对不同尺度特征图的组合利用来进行关键点的检测。
骨干网络中还有一条分支指向了绿色框代表的辅助网络,辅助网络接受骨干网络其中一层的特征图用于进行偏航角、俯仰角和横滚角的预测,以此来增强模型的泛化能力,提高预测准确率。
骨干网络
主干网络主要用于提取特征和预测关键点。结构如所示,先采用了mobilenet v2 的多个bottleneck 层, 然后采用多尺度,再通过全连接层把多个尺度的特征连接起来。
from mindspore import nn
from mindspore import ops
from mindvision.classification.models.blocks import ConvNormActivation
from mindvision.classification.models.backbones import InvertedResidual
class PFLDBackbone(nn.Cell):
def __init__(self,
channel_num: tuple = (3, 64, 64, 64, 64, 128, 128, 128, 16, 32, 128)):
super(PFLDBackbone, self).__init__()
# Input channel, output channel, stride, expansion rate
self.block1 = ConvNormActivation(channel_num[0], channel_num[1], 3, 2)
self.block2 = ConvNormActivation(channel_num[1], channel_num[2], 3, 1)
self.conv3 = InvertedResidual(channel_num[2], channel_num[3], 2, 2)
self.block3 = self.make_layer(InvertedResidual, 4, channel_num[3], channel_num[4], 1, 2)
self.conv4 = InvertedResidual(channel_num[4], channel_num[5], 2, 2)
self.conv5 = nn.SequentialCell(
ConvNormActivation(channel_num[5], channel_num[5] * 4, 1),
ConvNormActivation(channel_num[5] * 4, channel_num[5] * 4),
ConvNormActivation(channel_num[5] * 4, channel_num[6], 1, activation=None))
self.block5 = self.make_layer(InvertedResidual, 5, channel_num[6], channel_num[7], 1, 4)
self.conv6 = InvertedResidual(channel_num[7], channel_num[8], 1, 2)
self.avg_pool1 = nn.AvgPool2d(14)
self.conv7 = ConvNormActivation(channel_num[8], channel_num[9], 3, 2)
self.avg_pool2 = nn.AvgPool2d(7)
self.conv8 = nn.Conv2d(channel_num[9], channel_num[10], 7, 1, pad_mode="pad")
self.relu = nn.ReLU()
self.concat_op = ops.Concat(1)
def make_layer(self,
block: nn.Cell,
layer_num: int,
in_channel: int,
out_channel: int,
stride: int,
expand_ratio: int):
layers = []
for _ in range(layer_num):
pfld_aux_blk = block(in_channel, out_channel, stride, expand_ratio)
layers.append(pfld_aux_blk)
return nn.SequentialCell(layers)
def construct(self, x):
""" build network """
x = self.block1(x)
x = self.block2(x)
x = self.conv3(x)
features1 = self.block3(x)
x = self.conv4(features1)
x = self.conv5(x)
x = self.block5(x)
x = self.conv6(x)
x1 = self.avg_pool1(x)
x1 = x1.view((x1.shape[0], -1))
x = self.conv7(x)
x2 = self.avg_pool2(x)
x2 = x2.view((x2.shape[0], -1))
x3 = self.conv8(x)
x3 = self.relu(x3)
x3 = x3.view((x3.shape[0], -1))
multi_scale = self.concat_op((x1, x2, x3))
return features1, multi_scale
检测器
定义检测器的目的是为了更好的适应不同数量坐标点的情况。feature_num默认为176,如果使用0.25X版本需要改为44,具体计算方式可查看论文[1]。landmark_num常见取值为21,68,98,这主要取决于使用的数据集。
class LandmarkHead(nn.Cell):
def __init__(self,
feature_num: int = 176,
landmark_num: int = 68):
super(LandmarkHead, self).__init__()
self.fc = nn.Dense(feature_num, landmark_num * 2)
def construct(self, x):
""" build network """
landmark = self.fc(x)
return landmark
辅助网络
辅助网络是PFLD网络中一个非常重要的结构,前文提到人脸的器官结构信息是非常重要的,而该信息在头部发生扭动,俯仰等情况时,关键点会变形。此时,如果加入偏航角,俯仰角等信息会增强模型的预测能力。
class AuxiliaryNet(nn.Cell):
def __init__(self,
channel_num: tuple = (64, 128, 128, 32, 128, 32)):
super(AuxiliaryNet, self).__init__()
self.conv1 = ConvNormActivation(channel_num[0], channel_num[1], 3, 2)
self.conv2 = ConvNormActivation(channel_num[1], channel_num[2], 3, 1)
self.conv3 = ConvNormActivation(channel_num[2], channel_num[3], 3, 2)
self.conv4 = ConvNormActivation(channel_num[3], channel_num[4], 2, 2)
self.max_pool1 = nn.MaxPool2d(3, 2)
self.fc1 = nn.Dense(channel_num[4], channel_num[5])
self.fc2 = nn.Dense(channel_num[5], 3)
def construct(self, x):
""" build network """
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.max_pool1(x)
x = x.view((x.shape[0], -1))
x = self.fc1(x)
x = self.fc2(x)
return x
损失函数
训练的质量极大程度上取决于损失函数的设计,常用的 𝐿1 和 𝐿2损失对于小规模训练数据不十分友好,给定两点在图像空间中的偏差,将两点的投影从3D真实面孔应用到2D图像,真实面孔的内在距离可能明显不同,因此将几何信息即偏航角、俯仰角和横滚角整合到惩罚中可缓解此问题。
class PFLDLoss(nn.Cell):
def __init__(self):
super(PFLDLoss, self).__init__()
self.sum = ops.ReduceSum(keep_dims=False)
self.cos = ops.Cos()
self.mean = ops.ReduceMean(keep_dims=False)
# TODO:代码格式对齐
def construct(
self,
angle,
landmark,
landmark_gt,
weight_attribute,
euler_angle_gt):
"""Constructing the forward calculation process."""
weight_angle = self.sum(1 - self.cos(angle - euler_angle_gt), 1)
l2_distant = self.sum((landmark_gt - landmark) *
(landmark_gt - landmark), 1)
loss = weight_angle * weight_attribute * l2_distant
return self.mean(loss)
模型实现
在之前的工作中,我们已经将300W数据集进行了训练集和测试集的划分、定义了网络结构,完成了针对不同数据进行不同程度惩罚的损失函数。在midspore中提供了训练的接口,但是直接使用此接口必须满足每条数据只有两列,例如一张图片和对应的类别等,的数据集不能满足此要求,因此在定义训练流程之前,需要自定义封装了损失函数和模型网络的类。
具体代码如下:
class CustomWithLossCell(nn.Cell):
def __init__(self,
net: nn.Cell,
net_auxiliary: nn.Cell,
loss_fn: nn.Cell):
super(CustomWithLossCell, self).__init__()
self.net = net
self.net_auxiliary = net_auxiliary
self._loss_fn = loss_fn
def construct(self, img, landmark_gt, weight_attribute, euler_angle):
""" build network """
feature1, landmark = self.net(img)
angle = self.net_auxiliary(feature1)
return self._loss_fn(angle,
landmark,
landmark_gt,
weight_attribute,
euler_angle)
模型训练
实例化损失函数,优化器,使用Model接口编译网络。本案例训练的是PFLD1X网络,论文中也提到了0.25X网络,其网络的每层参数为1X网络的四分之一。
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig
from mindspore import Model
from mindvision.engine.callback import LossMonitor
from src.model.auxiliarynet import AuxiliaryNet
from src.pfld_utils.loss_cell import CustomWithLossCell
from src.model.pfld import pfld_1x_68
from src.pfld_utils.loss import PFLDLoss
# 初始化模型结构
net_auxiliary = AuxiliaryNet()
net = pfld_1x_68()
# 计算学习率
lr = nn.inverse_decay_lr(learning_rate=0.0001,
decay_rate=0.4,
total_step=12900,
step_per_epoch=129,
decay_epoch=1)
# 优化器
optimizer = nn.Adam(params=net.get_parameters(),
learning_rate=lr,
weight_decay=1e-6)
# 自定义损失函数
loss = PFLDLoss()
# 联合损失函数的网络,适用于数据集中有多列的情况
net_with_loss = CustomWithLossCell(net, net_auxiliary, loss)
# 初始化模型
model = Model(network=net_with_loss, optimizer=optimizer)
# 设置ckpt文件保存的参数
config_ck = CheckpointConfig(save_checkpoint_steps=129,
keep_checkpoint_max=100)
ckpoint = ModelCheckpoint(prefix="checkpoint_300W",
directory='./checkpoint_300w',
config=config_ck)
# 训练
model.train(1, dataset, callbacks=[ckpoint, LossMonitor(lr)], dataset_sink_mode=False)


模型评估
在300W数据集的验证集上进行评估。
from mindvision.utils.load_pretrained_model import LoadPretrainedModel
from src.pfld_utils.metric import validate
# 初始化网络并将训练好的模型加载置网络中
net = pfld_1x_68()
LoadPretrainedModel(net, 'https://download.mindspore.cn/vision/pfld/PFLD1X_300W.ckpt').run()
# 加载评估所用的数据集
transform = vision.py_transforms.ToTensor()
dataset_generator = Datasets300W('./datasets/300W/test_data/list.txt', transform)
wlfw_dataset_val = ds.GeneratorDataset(list(dataset_generator),
["img", "landmark", "attributes", "angle"])
wlfw_dataset_val = wlfw_dataset_val.batch(batch_size=1,
input_columns=["attributes"],
output_columns=["weight_attribute"],
per_batch_map=map_func)
# 验证模型效果
net.set_train(False)
validate(wlfw_dataset_val, net)

模型推理
import cv2
from mindspore import Tensor
net = pfld_1x_68()
LoadPretrainedModel(net, 'https://download.mindspore.cn/vision/pfld/PFLD1X_300W.ckpt').run()
transform = vision.py_transforms.ToTensor()
# 读取图片
origin_img = cv2.imread('images/infer_image.png')
origin_h, origin_w, _ = origin_img.shape
# 将图片修正为(112,112)的尺寸并归一化
img = cv2.resize(origin_img, (112, 112))
img = transform(img)
# 网络输入为(1,3,112,112),对图片进行转换
img = np.expand_dims(img, axis=0)
img = Tensor(img)
# 得到预测的坐标点
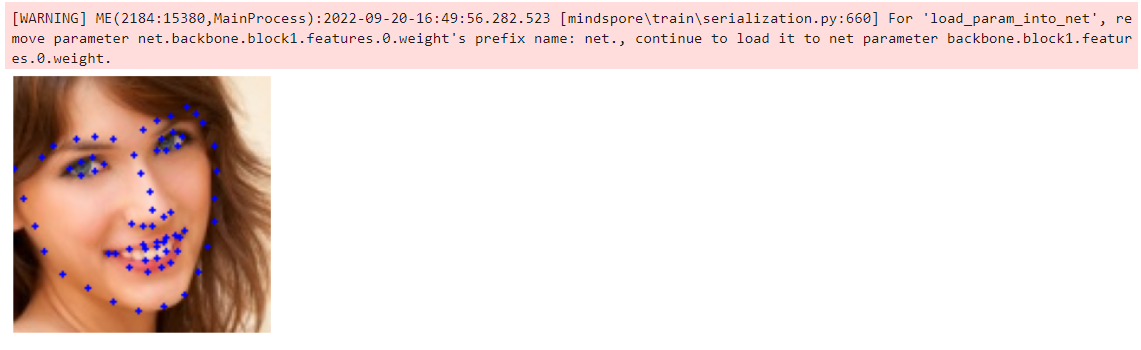
_, landmarks = net(img)
# 处理坐标点及展示图片
landmarks = landmarks.asnumpy()
landmarks = landmarks.reshape(landmarks.shape[0], -1, 2)
pre_landmark = landmarks[0] * [origin_w, origin_h]
img_clone = cv2.imread("images/infer_image.png")
for (x, y) in pre_landmark.astype(np.int32):
cv2.circle(img_clone, (x, y), 1, (255, 0, 0), -1)
plt.figure()
plt.imshow(img_clone[:, :, [2, 1, 0]])
plt.axis(False)
plt.show()

流程与总结




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











