






autonomy和automation
“Autonomy”和“automation”都是与技术和系统控制相关的术语,但它们的含义和应用有显著区别。以下是对两者的详细解释和对比:
一、Autonomy(自主性、自主控制)
定义:
Autonomy指的是系统或个体具备自主决策与执行任务的能力,不需要持续的人类干预。它通常涉及对环境的感知、判断、选择行动方案并执行的全过程。
特点:
- 自主感知与理解环境: 能够感知外部变化(如自动驾驶汽车识别交通标志、行人等)。
- 自主决策: 能分析当前情况,选择最优行动策略(如选择绕路或刹车)。
- 自主行动: 在没有人类直接操作的情况下完成任务。
- 有适应性和学习能力: 能根据经验优化行为。
应用举例:
- 自动驾驶汽车(如特斯拉的全自动驾驶)
- 军事无人机执行自主侦查或打击任务
- 智能机器人(如波士顿动力的机器人)执行复杂任务
二、Automation(自动化)
定义:
Automation指的是系统或过程在预设规则下自动执行某些任务,通常基于程序、算法或控制逻辑,不具备真正的“自主”判断能力。
特点:
- 程序化控制: 根据人类设定好的规则和流程执行任务。
- 重复性强: 通常适合稳定、可预测的任务。
- 不具备自我决策能力: 无法“判断”,只能在设定范围内工作。
应用举例:
- 工厂生产线上的自动机械臂
- 银行系统的自动转账
- Excel中的自动公式计算
- 智能家居中定时开关灯
三、对比:Autonomy vs. Automation
| 特征 | Autonomy(自主) | Automation(自动化) |
|---|---|---|
| 控制方式 | 自主感知、判断和决策 | 依赖预设规则或脚本 |
| 是否需要人类介入 | 最小甚至不需要 | 通常需要人类设定流程 |
| 应对复杂环境能力 | 强,能适应变化环境 | 弱,只适合固定流程 |
| 典型应用场景 | 自动驾驶、AI机器人、军事无人系统等 | 工业生产线、自动门、软件脚本等 |
| 是否能学习 | 通常具备学习能力 | 一般不具备 |
小结:
- Automation 更适用于规则明确、重复性强的任务。
- Autonomy 更适用于复杂、动态、需要智能判断的环境。
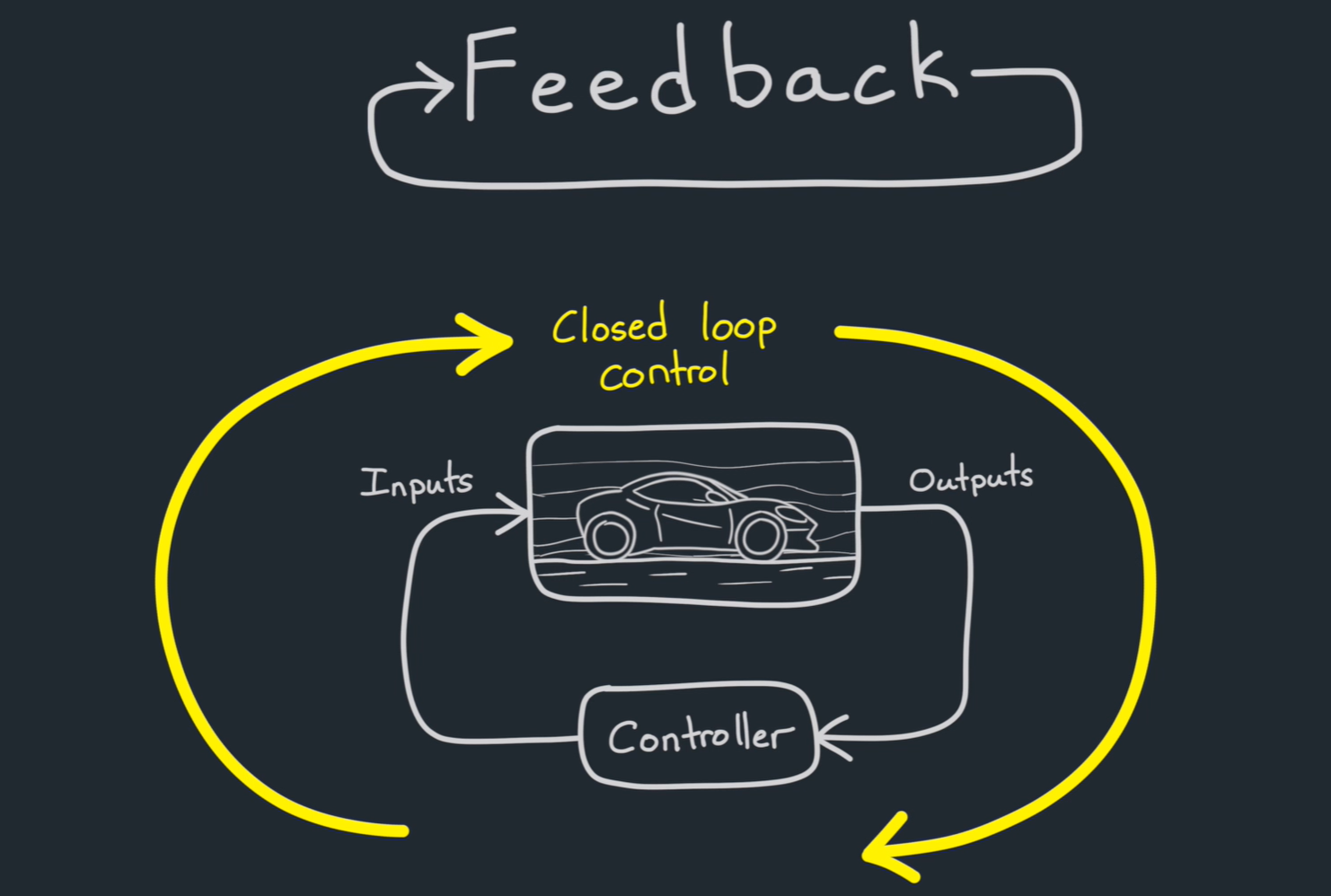
反馈
“反馈”(Feedback)是一个广泛应用于多个学科(如心理学、教育学、系统工程、控制理论、组织管理等)的核心概念,指的是系统或个体在完成某项行为或输出后,接收到来自环境、他人或自身的信息,用以调整未来行为或改进结果。
一、反馈的基本定义
反馈是一个信息回流的过程,通过这个过程,行为的结果被感知、评价,并用于调整接下来的行为,从而实现学习、控制或优化。
简单来说:
行为 → 结果 → 信息返回(反馈)→ 行为调整
二、反馈的类型
-
按信息性质划分:
-
正反馈(Positive Feedback):
增强原有行为或趋势。
例:老师表扬学生的努力,学生更愿意继续努力。 -
负反馈(Negative Feedback):
抑制或纠正偏离目标的行为,使系统回归稳定。
例:空调检测到温度过高,自动制冷降温。
-
-
按来源划分:
-
外部反馈(External Feedback):
来自他人或外部环境的信息,如老师的评价、客户的意见。 -
内部反馈(Internal Feedback):
个体自身对行为结果的判断或身体感受,如运动员感受到动作不协调。
-
-
按时间性划分:
-
即时反馈(Immediate Feedback):
行为后立刻给出的反馈,更利于学习和调整。
如电子游戏中的分数系统、及时点评。 -
延迟反馈(Delayed Feedback):
在行为结束一段时间后提供,有时可促进更深层次反思。
如考试后的成绩分析。
-
三、反馈的作用
-
调节行为:
帮助个体修正错误或保持正确方向。 -
促进学习:
在教育中,有效反馈有助于学生认清问题并提升学习效果。 -
提高效率:
在组织管理中,反馈机制可增强沟通、优化流程。 -
实现控制:
在工程系统中,反馈是自动控制的基础,如恒温器、自动驾驶。
四、典型应用场景
| 场景 | 反馈形式与功能 |
|---|---|
| 教育 | 教师批改作业、课堂点评,帮助学生查漏补缺 |
| 企业管理 | 员工绩效反馈、客户满意度调查,优化产品和服务 |
| 控制系统 | 自动调节温度、电压、水位等保持系统平衡 |
| 交互设计 | 手机震动、按钮动画提示用户操作结果 |
| 社交网络 | 点赞、评论、转发等机制,激励用户参与 |
五、有效反馈的特征
- 具体明确:指出问题或优点的具体表现;
- 及时性:越接近行为发生时越有效;
- 可操作性:提出可执行的改进建议;
- 尊重与支持性:鼓励改进而非打击积极性;
- 基于目标:反馈需指向既定目标或标准。
六、总结
反馈是一种信息回流机制,核心目的是实现“修正”与“强化”。无论是在控制系统、教育教学、还是人际交往中,建立良好的反馈机制都是提高效率、促进成长与优化系统的关键。
闭环控制系统
闭环控制系统(Closed-Loop Control System)是一种自动化控制系统,通过反馈机制调节系统的输出,以实现对目标状态的精确控制。与开环控制系统不同,闭环控制系统不仅根据输入信号来决定输出,还会根据系统的实际输出进行反馈调整,以消除偏差并实现更稳定的控制。
一、闭环控制系统的基本原理
闭环控制系统的核心思想是通过监测系统输出,并将其反馈给控制器,控制器根据反馈调整控制量,从而使系统输出更接近目标值。这种反馈过程能够不断修正系统的误差,确保系统的稳定性与准确性。
闭环控制系统的工作流程可以概括为:
输入 → 控制器 → 执行器 → 系统输出 → 传感器(反馈) → 控制器
主要组成部分:
-
控制器(Controller):
控制器是闭环系统的核心部分,它根据输入信号和反馈信号来计算调整量(控制信号),并将调整信号传递给执行器。控制器的任务是确保系统按照预定的目标运行,并进行适时的调整。 -
执行器(Actuators):
执行器负责根据控制器的指令,执行物理动作。例如,在自动驾驶汽车中,执行器会控制车辆的方向盘、油门和刹车等。 -
传感器(Sensors):
传感器用于监测系统的实际输出(例如,温度、速度、位置等),并将反馈信号传递给控制器。这些信息使得控制器能够了解系统当前的状态。 -
反馈(Feedback):
反馈是闭环系统的关键组成部分,它能够将实际输出与期望输出进行比较。控制器利用反馈信息来判断系统是否按预期运行,并根据需要调整输出。 -
目标值(Setpoint):
系统希望达到的理想状态或目标值。控制器的任务是通过调整系统的输入,使输出尽可能接近目标值。
二、闭环控制的工作过程
-
设定目标值(Setpoint):
系统会预先设定一个目标值,例如温控系统中的设定温度或自动驾驶中的行驶速度。 -
输入信号:
控制系统接收来自外部或内部的输入信号,这些信号是系统希望达到或需要进行调整的目标。 -
执行器作用:
控制器计算出所需的调整量,并将控制信号发送给执行器,后者根据控制信号改变系统的物理行为。 -
反馈信息:
系统中的传感器持续监控输出,生成实时反馈信号,并将其送回控制器。 -
误差计算与调整:
控制器将反馈信号与目标值进行比较,计算出误差。根据误差,控制器会调整执行器的动作,直到误差达到可接受的范围。 -
输出与稳定:
系统的输出最终会稳定在接近目标值的位置,反馈控制使得系统保持稳定和准确。
三、闭环控制系统的优点
-
高精度控制:
闭环控制能够实时修正系统误差,使系统输出保持在接近目标值的状态,能够更好地适应变化的环境和负载条件。 -
抗干扰能力强:
闭环控制系统能够对外部干扰和系统内部的不稳定因素做出反应,并进行补偿,从而提高系统的稳定性。 -
适应性强:
随着环境或输入变化,闭环控制系统可以根据实时反馈自动调整,适应不同的工作条件。 -
自我修正功能:
通过反馈,系统可以识别并修正错误或异常,防止系统输出过度偏离目标,保证系统运行的稳定性。
四、闭环控制系统的缺点
-
复杂性高:
闭环系统的设计和实现相对较复杂,需要处理传感器、控制器、执行器之间的精确配合。 -
响应时间:
虽然闭环控制能够实时调整系统输出,但它通常需要一定的时间来获取反馈并作出反应,因此可能存在一定的延迟。 -
成本较高:
闭环控制系统需要更多的硬件和软件支持,包括传感器、执行器、控制器和反馈回路,这些增加了系统的成本。
五、闭环控制系统的应用实例
-
自动驾驶汽车:
在自动驾驶汽车中,闭环控制系统利用传感器(如雷达、摄像头)实时反馈车辆的速度、位置、障碍物等信息,控制系统根据这些反馈来调整车辆的行驶路线、速度和刹车等。 -
温度控制系统:
温控系统(如空调、恒温器)是经典的闭环控制系统。当房间温度偏离设定值时,传感器将当前温度反馈给控制器,控制器调整制冷或制热系统以调节温度,直到达到目标温度。 -
工业自动化:
在自动化生产线中,闭环控制用于调节机器人臂的动作、生产设备的运转速度等,确保生产过程中的精确控制和高效性。 -
飞行控制系统:
飞机的飞行控制系统使用闭环控制来保持飞行姿态和轨迹,传感器持续反馈飞行状态,飞行控制器根据反馈调整操控面。
六、总结
闭环控制系统通过实时反馈和调整,能够在动态环境中保持高精度的控制。尽管其设计和实施相对复杂,但它为许多领域提供了高效、稳定和适应性强的解决方案,广泛应用于自动化、机器人、航空、汽车等行业。
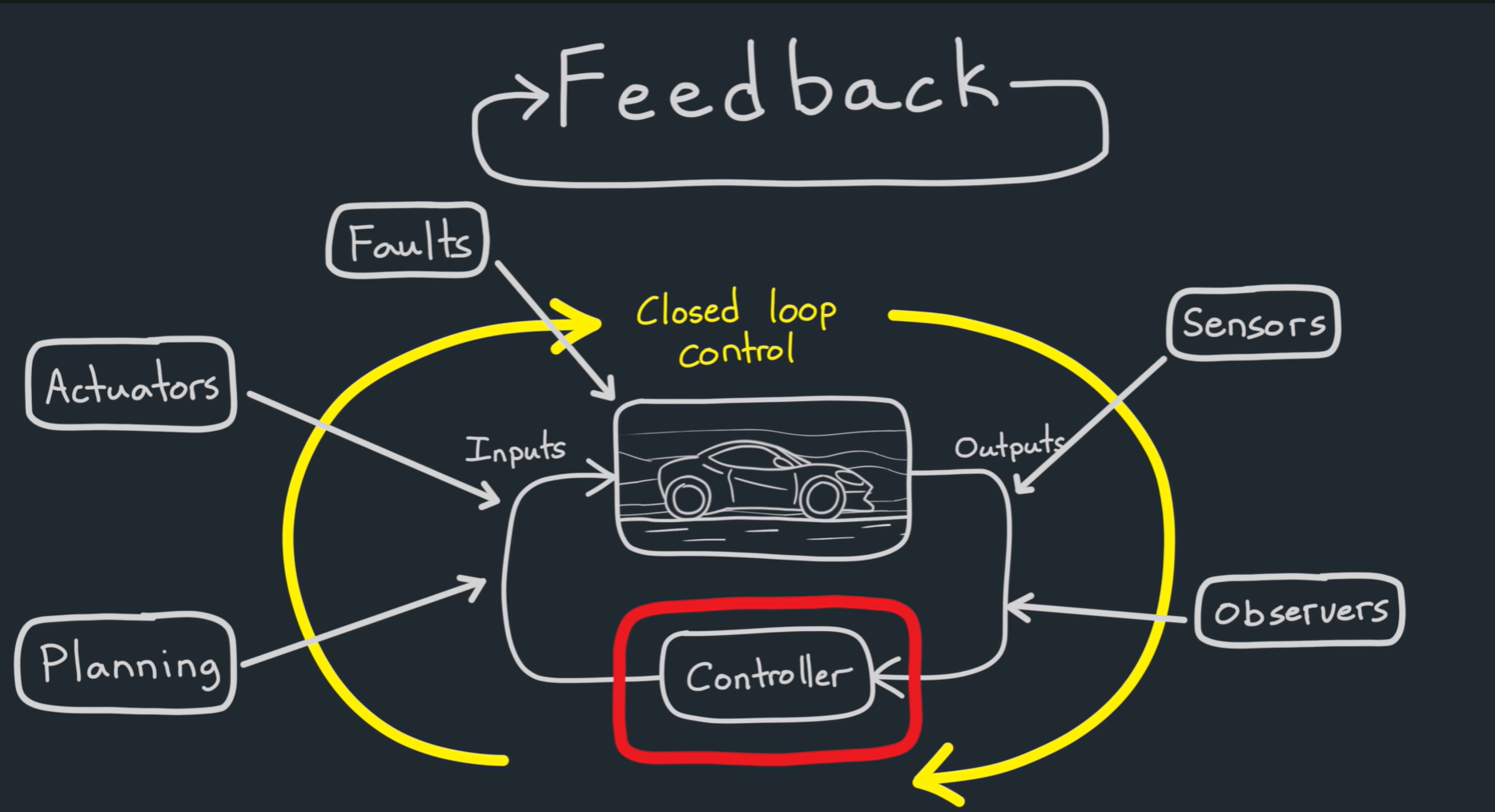
您上传的图片展示了闭环控制系统中的反馈回路,这种系统通常应用于自动化、机器人技术和控制工程等领域。以下是图示中各组成部分的详细解释:
-
控制器(红色高亮部分):反馈系统的核心部分。控制器处理来自传感器的输入信息,并利用这些信息控制执行器以产生期望的输出。控制器通过不断调整操作,确保系统按预定方式运行。
-
输入(Inputs):系统在运行时需要考虑的变量或参数。例如,在自动驾驶汽车中,输入可以是速度、位置或道路状况的传感器数据。
-
执行器(Actuators):根据控制器的决策执行物理动作的部件。在汽车中,执行器可能是方向盘、刹车或油门。
-
传感器(Sensors):用于监测系统状态的设备,如速度、位置或障碍物,并将这些数据发送给控制器。
-
输出(Outputs):在执行器激活后产生的结果或状态。例如,汽车可能调整其速度或改变方向。
-
观察器(Observers):用于跟踪系统状态并估计未测量的变量。它们提供有关系统行为的额外见解或预测。
-
故障(Faults):系统中可能出现的任何意外偏差或错误,这些偏差可能需要采取纠正措施。例如,机械故障、传感器不准确等。
-
闭环控制(Closed-Loop Control):反馈回路使系统能够监控其输出,并相应地调整输入。系统不断适应,确保达到预期的行为。
总结来说,这张图描述了一个闭环控制系统,在这个系统中,控制器根据传感器反馈和系统输出动态地调整行为,确保系统性能准确,并进行误差修正。这是现代自动化系统中的一个基础概念,广泛应用于自动驾驶汽车、机器人技术和工业过程等领域。
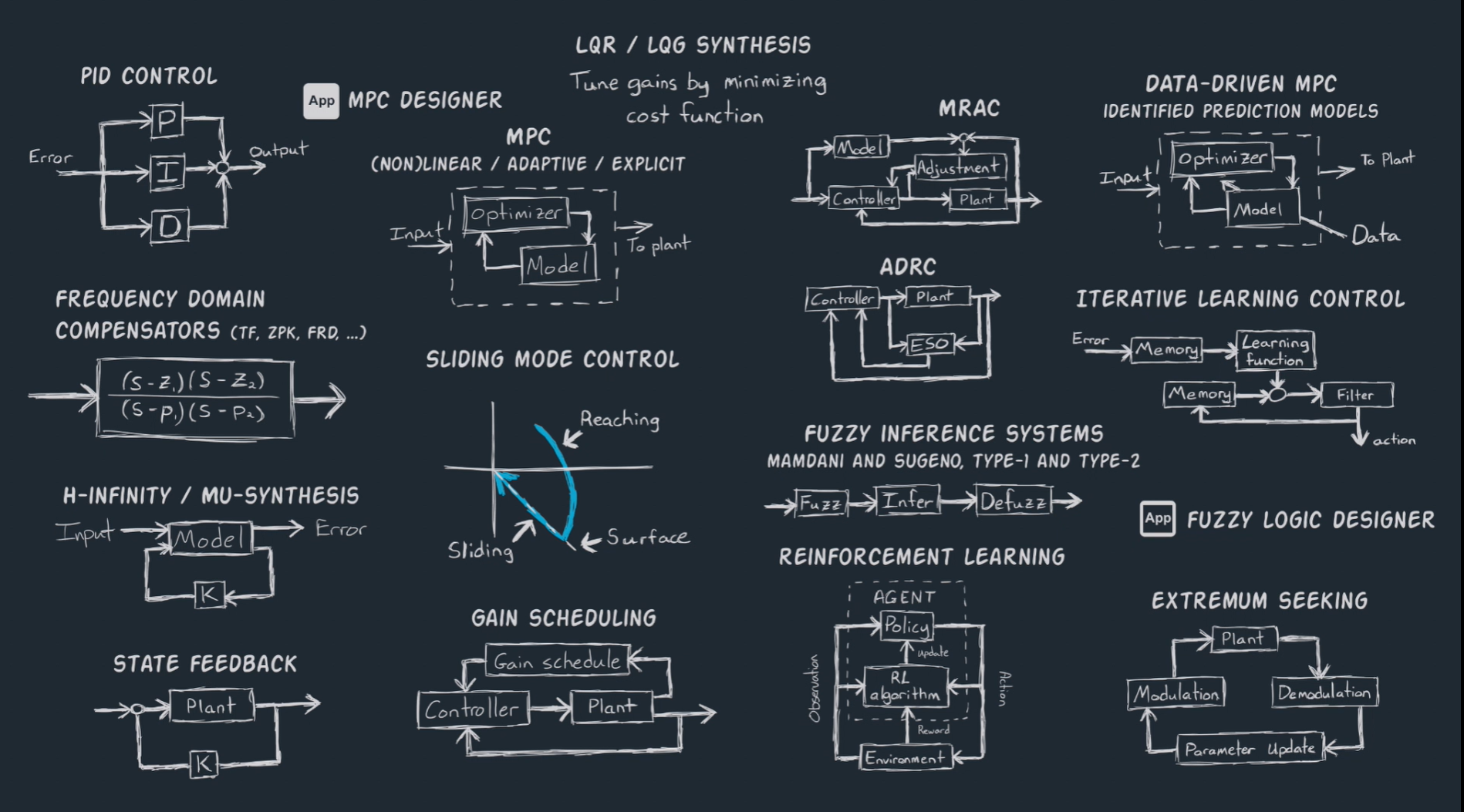
您上传的图片展示了各种控制系统技术和方法,包括多个先进的控制策略。以下是这些方法的简要说明:
-
PID控制(Proportional-Integral-Derivative Control):常见的反馈控制方法,利用比例(P)、积分(I)和微分(D)来调节系统输出,使其稳定在目标值。
-
MPC设计(Model Predictive Control,模型预测控制):基于系统模型和优化算法来预测未来的控制输入,以最小化成本函数,适用于线性、非线性或自适应控制系统。
-
MRAC(Model Reference Adaptive Control,模型参考自适应控制):通过调整控制器参数,使系统的输出跟随参考模型,常用于动态系统的自适应控制。
-
滑模控制(Sliding Mode Control):一种非线性控制方法,通过将系统状态强制性地推向并保持在预定的滑模面上来控制系统的动态行为。
-
数据驱动的MPC(Data-Driven MPC):采用数据识别预测模型的模型预测控制方法,通过数据来提高控制系统的性能,减少对模型的依赖。
-
ADRC(Active Disturbance Rejection Control,主动干扰拒绝控制):通过动态估计系统的干扰并实时调整控制输入,广泛应用于复杂的非线性系统中。
-
迭代学习控制(Iterative Learning Control):通过从每次迭代中学习并改进控制策略,使得系统在重复操作中逐步优化,通常用于批处理或重复性任务。
-
模糊逻辑系统(Fuzzy Logic Systems):使用模糊逻辑规则来进行决策和控制,适用于不确定或复杂环境中的控制问题,如模糊控制器设计。
-
强化学习(Reinforcement Learning):通过智能体与环境的交互,智能体根据奖励学习最优的控制策略,广泛应用于自动化控制和决策问题中。
-
极值寻求(Extremum Seeking):通过调节系统参数,自动寻找最佳操作点(如最大效率或最优性能),用于系统优化。
-
H-无穷/μ-综合(H-infinity / Mu-Synthesis):一种鲁棒控制方法,用于设计能抵抗外部扰动和系统不确定性的控制器。
-
频域补偿器(Frequency Domain Compensators):使用频率响应方法设计控制器,通常涉及传递函数、零极点增益(ZPK)等技术。
这些方法涉及广泛的控制策略,适用于不同类型的控制系统,从简单的PID控制到更为复杂的自适应控制和基于数据的控制。
PID
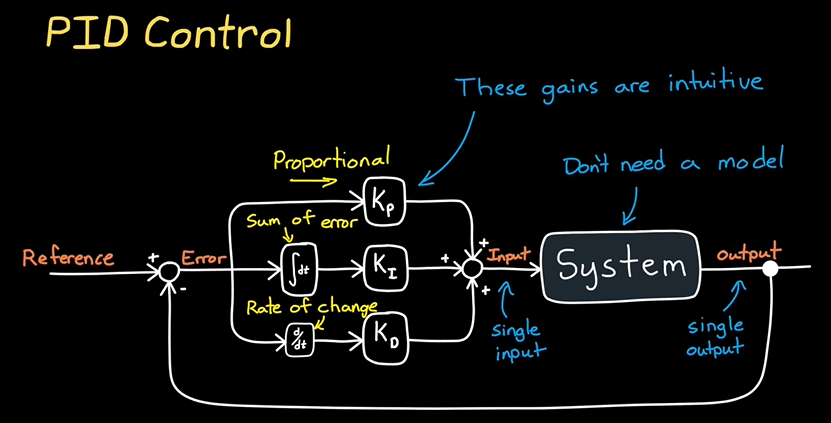
PID控制(Proportional-Integral-Derivative Control)是最常见的反馈控制方法之一,广泛应用于各类自动化控制系统中。PID控制器通过三个基本的调节器(比例、积分和微分)来调整系统输出,以使其尽可能接近设定目标值。下面我将详细讲解PID控制的原理、组成部分、特点和应用。
一、PID控制的基本原理
PID控制器通过比较系统的实际输出(反馈值)与目标值(设定点)之间的误差,并根据误差大小采取不同的控制动作。PID控制的目标是消除或减少误差,并维持系统稳定。
PID控制器的控制输出 ( u(t) ) 是由以下三部分组成:
[
u(t) = K_p \cdot e(t) + K_i \cdot \int e(t) dt + K_d \cdot \frac{de(t)}{dt}
]
其中:
- ( e(t) ) 是当前的误差,即目标值与实际输出之间的差:( e(t) = setpoint - output )。
- ( K_p )、( K_i )、( K_d ) 分别是比例增益、积分增益和微分增益。
- ( \int e(t) dt ) 表示误差的累积(积分),用于消除稳态误差。
- ( \frac{de(t)}{dt} ) 表示误差的变化率(微分),用于预测未来误差的趋势。
二、PID控制的三个组成部分
-
比例控制(P):
- 比例控制是控制器的基础部分,其作用是根据当前误差 ( e(t) ) 进行调整。比例项会根据误差的大小来调整输出,误差越大,控制量越大。
- 公式:( P = K_p \cdot e(t) )
- 优点:比例控制可以快速响应误差。
- 缺点:如果只依赖比例控制,系统可能会存在稳态误差(如温度控制系统可能无法完全达到设定值)。
-
积分控制(I):
- 积分控制用于消除稳态误差,尤其是在系统存在持续小误差时,积分项会通过累计误差来增加控制量,直到误差被完全消除。
- 公式:( I = K_i \cdot \int e(t) dt )
- 优点:消除系统中的稳态误差。
- 缺点:如果积分增益过大,可能会导致系统过度调整(即超调),甚至出现振荡。
-
微分控制(D):
- 微分控制通过预测误差的变化趋势,提前做出调整。它对误差变化率敏感,能够有效减少系统的过冲和振荡。
- 公式:( D = K_d \cdot \frac{de(t)}{dt} )
- 优点:微分项能抑制误差的快速变化,有助于减小系统的过度反应。
- 缺点:微分控制对噪声敏感,容易引入不必要的调整,尤其是在测量信号中有噪声时。
三、PID控制的工作过程
PID控制器的工作过程分为以下几个步骤:
-
误差计算:首先,控制器会计算出当前的误差 ( e(t) ),即目标值与实际输出之间的差。
-
调整输出:控制器根据比例项、积分项和微分项的计算结果,对系统的控制输出进行调整。
-
输出执行:根据计算得到的控制输出,控制器向系统的执行器(如电动机、加热器等)发送控制信号,调整系统状态。
-
反馈调整:系统输出会反馈到控制器,重新计算新的误差,进行下一次调整。
通过这一循环过程,PID控制器能够不断地调整系统的输入,逐步减少误差,直到系统稳定在目标值附近。
四、PID控制的优缺点
优点:
- 简单易懂:PID控制器结构简单,易于实现,是经典的控制策略。
- 稳定性好:对于大多数线性系统,PID控制器能够有效地保持系统稳定。
- 响应速度快:比例项能够迅速响应系统的误差变化。
- 无模型依赖:PID控制器不需要精确的系统模型,因此广泛适用于许多实际系统。
缺点:
- 调参困难:PID控制器需要手动调节比例、积分、微分增益((K_p), (K_i), (K_d)),如果参数设置不当,可能导致系统过调或不稳定。
- 对噪声敏感:微分项对高频噪声非常敏感,在实际应用中可能导致系统震荡。
- 无法应对非线性系统:PID控制主要适用于线性系统,对于非线性或动态特性变化较大的系统,效果可能不佳。
五、PID调节的常用方法
-
经验法则:
- 最常用的调参方法是Ziegler-Nichols法则,这是一种基于经验的调节方法,通过设置比例增益 ( K_p ),然后逐步调整积分和微分增益来获得最佳性能。
-
自动调节算法:
- 现代PID控制器常采用自动调节算法,如自整定PID控制器,根据系统动态自动调整参数。
-
优化方法:
- 例如遗传算法、粒子群优化(PSO)等优化算法可以用来自动调整PID参数,尤其适用于复杂系统。
六、PID控制的应用
PID控制器被广泛应用于许多工业自动化系统,包括:
- 温度控制系统:如空调、热水器、工业加热炉等,PID控制确保系统稳定在设定温度。
- 速度控制系统:如电动机、风扇等,通过调整电机的速度来实现稳定运行。
- 过程控制:如化工过程中的流量、压力、浓度等控制。
- 机器人控制:PID控制用于精确控制机器人运动,确保其按预定路径运行。
七、总结
PID控制是一种简单有效的控制方法,适用于许多需要精确控制的系统。通过调整比例、积分和微分增益,PID控制器能够在不同的动态条件下优化系统性能。然而,正确调节PID参数是实现良好控制效果的关键,且在面对非线性和时变系统时,PID控制可能需要与其他控制策略结合使用。
state feedback
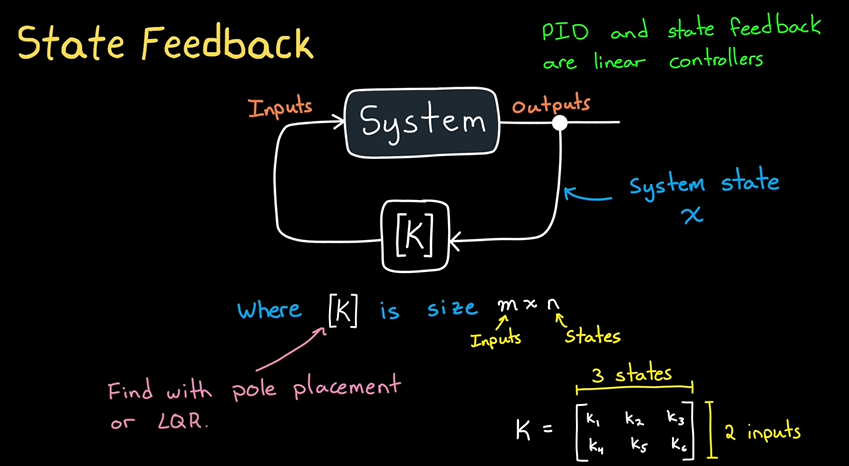
状态反馈控制(State Feedback Control)是一种通过利用系统的状态信息来设计控制器的控制方法。与PID控制不同,状态反馈控制不单纯依赖于输出的误差,而是直接利用整个系统的状态变量(如位置、速度、电流等)来进行反馈控制。其目的是通过选择适当的控制输入,驱动系统的状态向期望的目标状态或轨迹趋近。
一、状态反馈的基本原理
状态反馈控制的基本思想是通过实时反馈系统的状态信息,并利用控制输入来调整系统的行为。数学上,状态反馈控制通常表示为:
[
\dot{x}(t) = A x(t) + B u(t)
]
其中:
- (x(t)) 是系统的状态向量,包含了系统的所有必要信息,如位置、速度、电流等。
- (\dot{x}(t)) 是状态向量的导数(即状态的变化率)。
- (A) 是系统的状态矩阵,描述了系统状态的动态行为。
- (B) 是输入矩阵,表示输入 (u(t)) 对状态的影响。
- (u(t)) 是控制输入,即控制器的输出,它是通过状态反馈计算得到的。
在状态反馈控制中,控制输入通常设计为:
[
u(t) = -K x(t) + r(t)
]
其中:
- (K) 是反馈增益矩阵,决定了反馈的强度。
- (r(t)) 是参考输入或外部扰动,通常用于设计参考轨迹。
- (x(t)) 是系统的状态,反馈控制器通过调整控制输入来驱动系统向期望的目标状态靠近。
二、状态反馈控制的步骤
-
定义状态空间模型:
首先,需要得到系统的状态空间模型。状态空间模型通常由两部分组成:- 状态方程:描述系统的动态行为。
- 输出方程:描述系统的输出与状态之间的关系。
典型的状态空间模型形式为:
[
\dot{x}(t) = A x(t) + B u(t)
]
[
y(t) = C x(t) + D u(t)
]其中 (y(t)) 是系统的输出,(C) 和 (D) 分别是输出矩阵和直接传递矩阵。
-
选择反馈增益矩阵 (K):
为了设计状态反馈控制器,需要确定反馈增益矩阵 (K)。选择适当的 (K) 可以确保系统具有良好的动态性能,包括快速响应、无振荡和良好的稳定性。通常,可以通过以下方法来设计 (K):
- 极点配置法(Pole Placement):通过调整增益矩阵 (K) 来设置系统的闭环极点,以确保系统的稳定性和响应速度。
- 线性二次调节(LQR):通过优化一个代价函数来最小化状态偏差和控制输入的消耗,计算出最优的反馈增益矩阵。
-
反馈控制器的实现:
将设计好的反馈增益矩阵 (K) 应用到系统中,并通过计算 (u(t) = -K x(t) + r(t)) 来控制系统,调整系统的状态。
三、状态反馈的优点与挑战
优点:
-
系统稳定性:
状态反馈控制能够通过精确调整反馈增益来确保系统的稳定性,并可通过极点配置来控制系统的响应速度和稳定性。 -
更高的控制精度:
与仅依赖输出反馈的控制方法(如PID控制)相比,状态反馈可以利用系统的所有状态变量(如速度、位置、电流等),因此能够提供更精确的控制。 -
适用于多输入多输出(MIMO)系统:
状态反馈控制非常适合用于多输入多输出的系统,能够同时控制多个状态变量,进行复杂的协调控制。 -
鲁棒性强:
状态反馈控制能够有效应对系统参数的变化和外部扰动,具有较强的鲁棒性。
挑战:
-
状态变量的获取:
状态反馈控制的一个主要挑战是需要完全了解系统的状态。在实际应用中,很多系统的状态变量并不是直接可测量的,可能需要通过观测器(如卡尔曼滤波器)来估算系统状态。 -
设计复杂性:
对于高维系统(即状态变量很多的系统),设计合适的反馈增益矩阵 (K) 可能需要复杂的计算,尤其是在非线性系统中,设计过程可能更加困难。 -
控制输入的限制:
在一些实际应用中,控制输入(如电机电流、阀门开度等)可能受到物理限制,如何将状态反馈控制与这些限制结合起来,是一个需要解决的问题。
四、状态反馈的设计方法
-
极点配置法(Pole Placement):
极点配置法通过调整系统的闭环极点来设计状态反馈控制器。极点的位置直接影响系统的稳定性和响应速度。通过选择合适的极点,可以使系统在最短的时间内达到稳态,并且避免振荡。例如,在一个二阶系统中,选择较小的负实数极点可以使系统响应快速,避免超调和振荡。
-
线性二次调节(LQR):
LQR是一种通过最小化代价函数来优化状态反馈的方法。代价函数通常包括状态偏差的平方和控制输入的平方。LQR通过求解代数黎卡提方程(ARE)来得到最优的反馈增益矩阵 (K)。代价函数形式:
[
J = \int_0^\infty \left( x(t)^T Q x(t) + u(t)^T R u(t) \right) dt
]
其中 (Q) 和 (R) 分别是状态权重矩阵和控制输入权重矩阵,调整这些权重可以优化系统的性能。
五、状态反馈的应用
状态反馈控制广泛应用于以下领域:
- 机器人控制:在机器人控制中,状态反馈控制用于精确控制机器人各个关节的位置和速度。
- 自动驾驶:在自动驾驶汽车中,状态反馈控制用于调节车辆的速度、方向等,以确保车辆稳定、安全地行驶。
- 飞行控制:飞行器的飞行控制系统通过状态反馈控制来维持飞行姿态、速度等,确保飞行稳定。
- 电力系统:电力系统的稳定性控制通常采用状态反馈方法,以应对负载变化、设备故障等扰动。
- 机械系统:如悬架系统、振动控制等,通过状态反馈来减少机械系统的振动和不稳定性。
六、总结
状态反馈控制是一种强大的控制方法,能够通过全状态信息来设计精确的控制器。它具有较强的控制精度和系统稳定性,尤其适用于多输入多输出的复杂系统。然而,实际应用中,状态反馈控制面临着状态估计和控制输入限制等挑战。随着现代控制理论的发展,状态反馈控制已经成为许多自动化系统中的核心技术。
gain scheduling
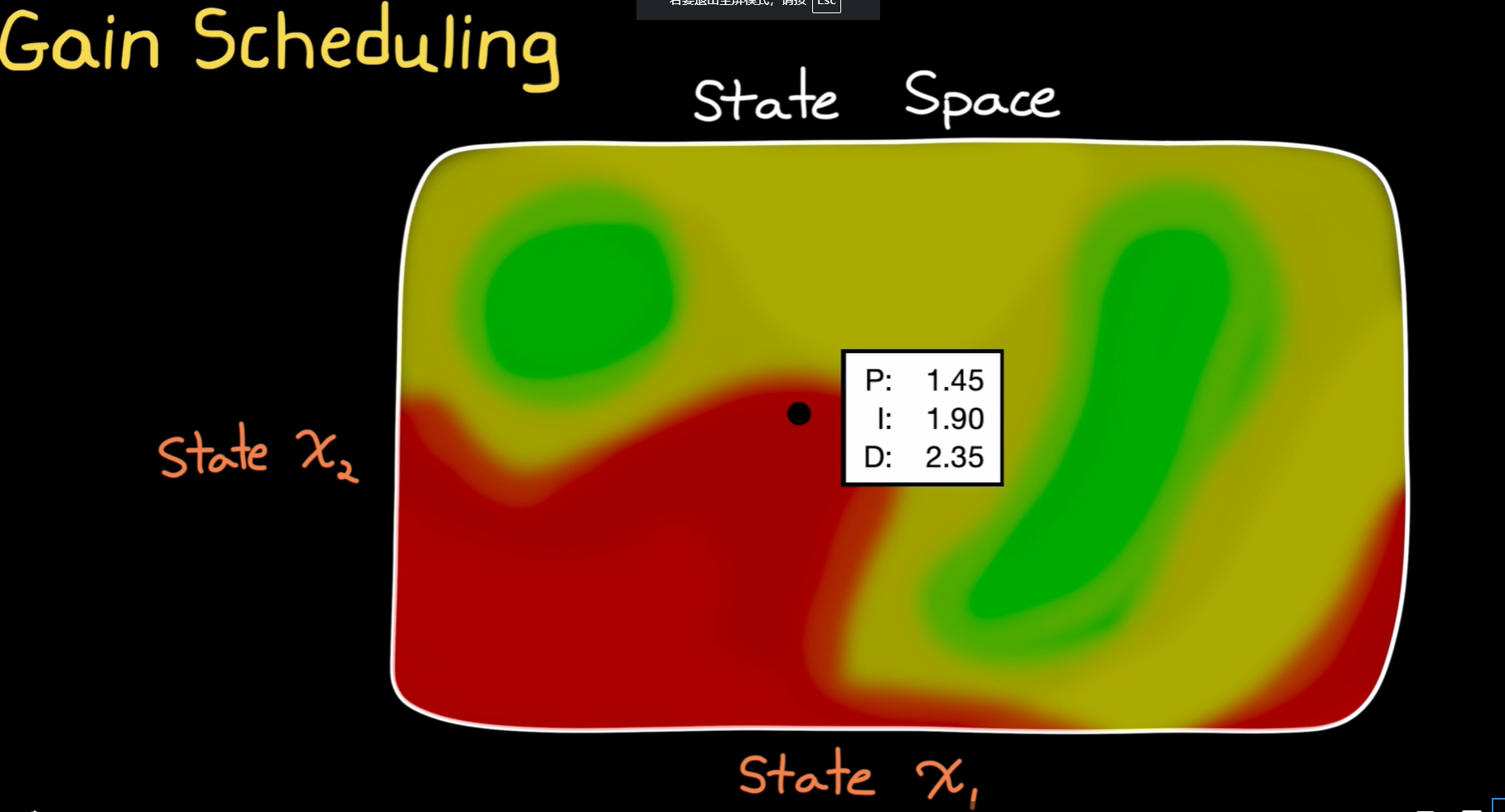
增益调度(Gain Scheduling)是一种用于控制系统的技术,主要用于处理系统参数随操作条件变化而变化的情况。在增益调度方法中,控制器的增益参数会根据系统的工作点(或操作条件)动态调整。它通常应用于非线性系统或系统参数不确定的情况下,以保证系统在不同工况下都能维持良好的性能。
一、增益调度的基本原理
增益调度的核心思想是根据系统的工作点选择合适的控制增益。系统的工作点通常是由一组“调度变量”来表示的,这些调度变量决定了系统的操作状态或工作区域。增益调度控制器根据这些调度变量的值动态地选择一组最适合的增益值,从而保持系统的稳定性和控制性能。
简单来说,增益调度是通过预先设计一组不同的增益来应对系统在不同工作点下的变化,然后根据当前的状态来选择最合适的增益。
二、增益调度的工作过程
-
定义调度变量:
增益调度控制器的第一步是选择一组调度变量。调度变量通常是与系统状态或操作条件相关的量,比如温度、压力、速度、位置等。例如,在飞机控制中,飞行的高度、速度、俯仰角度等都可以作为调度变量。 -
设计增益表或增益映射:
对于每一组可能的调度变量值,设计一组对应的控制增益。这些增益可能是通过实验、建模或优化方法得出的。例如,系统在不同的速度范围或负载条件下可能需要不同的比例、积分和微分增益。 -
实时计算控制增益:
在实际操作中,增益调度控制器会实时测量调度变量的值,并根据这些值查找最合适的控制增益。控制器将采用这些增益来计算控制输入,确保系统的稳定性和性能。 -
应用控制器输出:
最后,控制器根据选择的增益计算控制输入,并将其应用于系统,调整系统的行为。通过这种方式,增益调度可以保证系统在各种操作条件下都有良好的控制效果。
三、增益调度的优点
-
适应性强:
增益调度能够根据系统的工作状态动态调整控制参数,适应系统参数变化或操作条件的变化。例如,在发动机的不同转速下,增益调度能够提供最佳的控制效果。 -
应用广泛:
增益调度特别适用于那些具有显著非线性特性或者系统参数随工作条件变化的控制系统。例如,在飞机飞行控制系统中,飞行的速度、姿态等条件会不断变化,增益调度能够应对这种变化,提供稳定的控制。 -
避免复杂的非线性控制设计:
对于复杂的非线性系统,设计一个完全的非线性控制器可能非常困难。增益调度通过线性化不同的工作点,并为每个工作点选择最适合的增益,从而避免了完全非线性控制器的复杂性。 -
简化设计过程:
增益调度控制器的设计通常是通过为每个操作点设计一个线性控制器来实现的,而非要求为整个系统设计一个非线性控制器。这使得设计过程相对简单且可行。
四、增益调度的缺点
-
需要精确的调度变量:
增益调度依赖于调度变量,因此需要对调度变量的选择非常谨慎。如果调度变量选择不当,可能会导致系统性能下降或控制失效。 -
可能存在突跳现象:
如果增益表的设计不够平滑,增益调度的切换可能会出现不连续或突跳现象,导致系统的性能不稳定。为避免这种情况,设计时应确保增益变化的平滑性。 -
依赖于系统建模:
增益调度方法通常需要根据系统在不同工作点下的表现来设计增益,这要求对系统有较好的建模能力。如果系统模型不准确,可能会导致增益调度的失效。 -
无法处理所有类型的非线性系统:
尽管增益调度能应对很多非线性问题,但对于一些高度非线性或不可预测的系统,增益调度可能不足以提供理想的控制效果。
五、增益调度的设计方法
增益调度的设计过程通常包括以下几个步骤:
-
选择调度变量:
根据系统的特性选择适当的调度变量。调度变量通常是与系统性能或操作状态密切相关的量。例如,电动机控制中的转速,飞机控制中的飞行高度和速度等。 -
生成增益表:
对于每个调度变量值范围,设计相应的增益表。增益表可以通过实验、建模或优化算法得到。在某些情况下,也可以使用数学优化方法来确定每个调度点的最优增益。 -
平滑增益表:
为了避免增益调度时的突跳现象,需要对增益表进行平滑处理。常见的方法包括插值、最小二乘法等,以保证增益在不同工作点之间的过渡平滑。 -
实时调度和控制:
在实际运行中,控制器根据实时测量的调度变量值从增益表中选择合适的控制增益,并将其应用于系统。
六、增益调度的应用
增益调度在许多实际控制系统中得到了广泛应用,尤其是在那些系统参数随操作条件变化的场合。常见的应用包括:
-
飞机控制系统:
飞机的飞行状态(如速度、姿态、航向等)会随着飞行条件变化,因此增益调度广泛应用于飞行控制系统中,以确保飞机在不同飞行状态下都能稳定运行。 -
汽车动力系统:
在现代汽车中,增益调度用于发动机控制系统,根据不同的转速、负载等条件,调整发动机的燃油喷射、点火时刻等参数,优化燃油效率和性能。 -
电机控制系统:
在电动机控制中,增益调度可以根据电动机的负载、转速等条件,动态调整控制增益,以实现最佳的动力输出和效率。 -
化工过程控制:
在化工过程中,温度、压力、流量等参数通常会随时间变化,增益调度可用于根据这些参数调整控制器的增益,以保持稳定的化学反应过程。 -
机器人控制:
在机器人控制中,增益调度根据机器人的运动速度、位置等条件调整控制增益,以确保机器人的精确运动和稳定性。
七、总结
增益调度是一种强大且灵活的控制方法,能够处理那些具有显著非线性特征或系统参数随操作条件变化的复杂系统。它能够提供适应性强、响应迅速的控制效果,避免了为每种操作条件设计单独的非线性控制器。然而,增益调度也需要精确选择调度变量,并且设计增益表时需要避免突跳现象。它在许多领域中得到了广泛应用,特别是在航空、汽车、电机和机器人等行业。
H-infinity
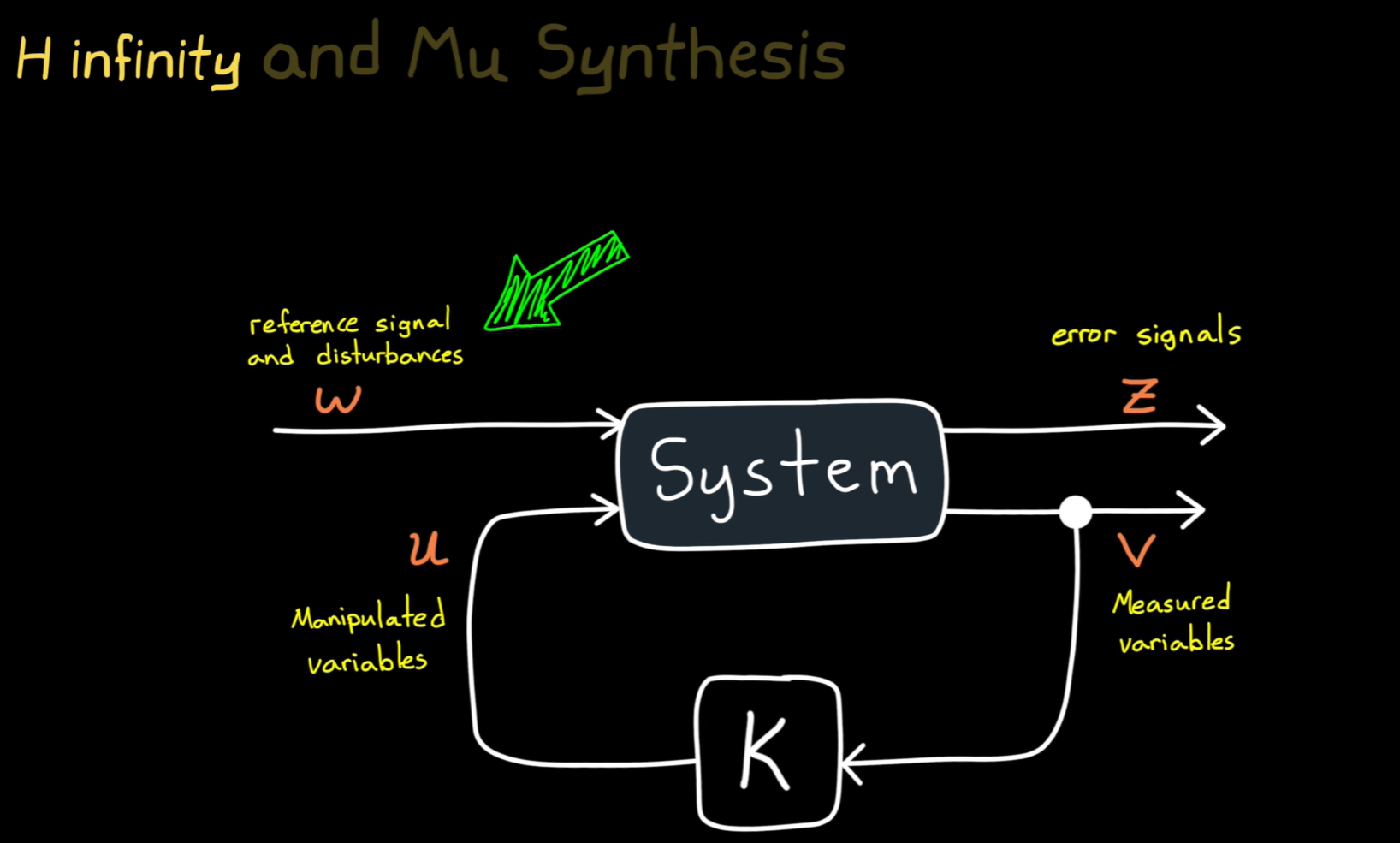
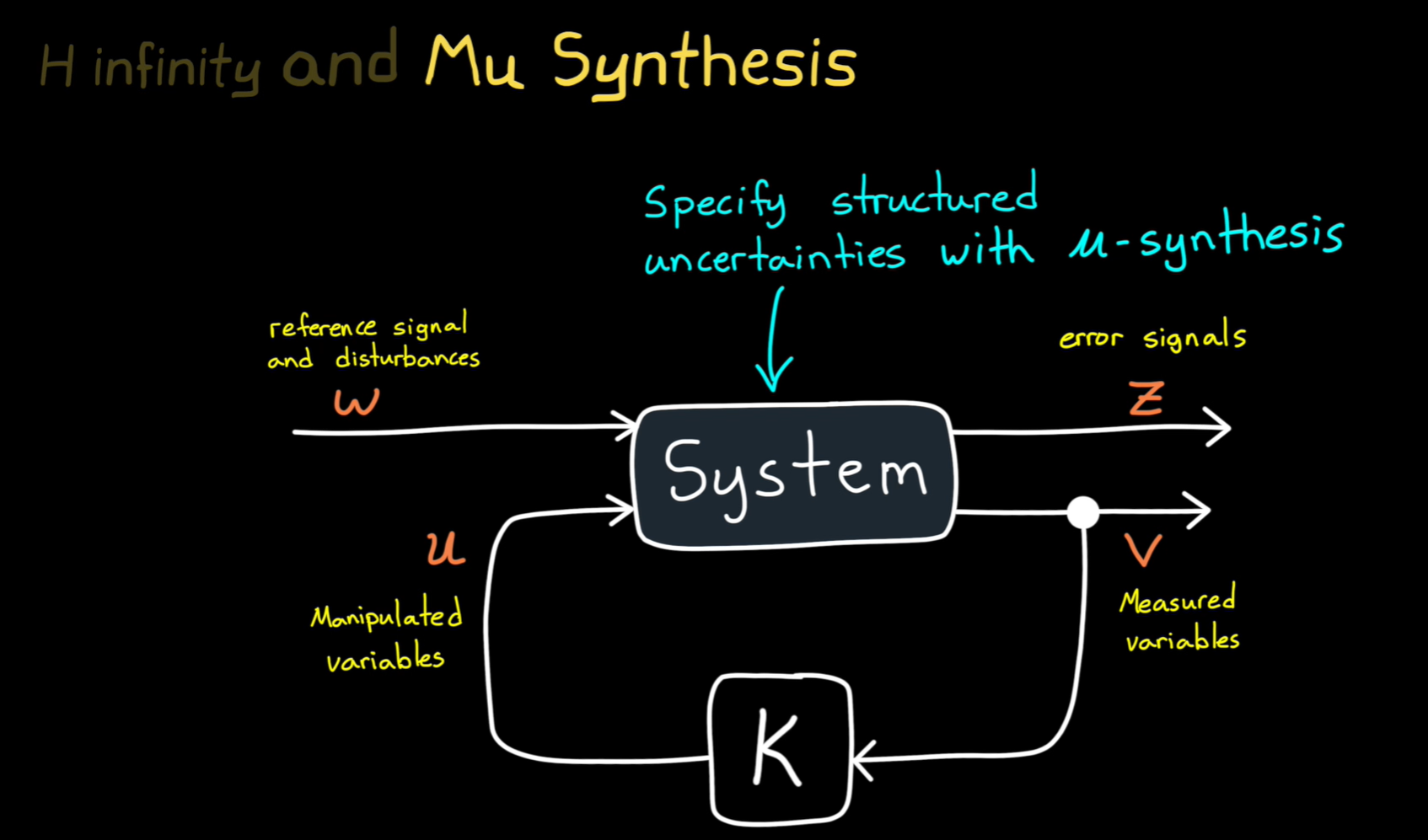
您上传的图片展示了H-无穷(H∞)和μ综合(Mu Synthesis)控制方法,这些方法主要用于设计能够应对系统不确定性和扰动的鲁棒控制器。
1. H-无穷控制(H∞ Control):
H-无穷控制是一种鲁棒控制方法,旨在最小化系统对扰动的响应的最大增益。在这种方法中,控制器被设计来确保系统能够在各种不确定性和外部扰动的情况下保持稳定并达到良好的性能。具体来说,H∞控制方法关注系统在最不利情况下的表现(即在所有可能的扰动下保持最小增益)。
- 目标:通过最小化系统对扰动的响应增益来保证系统的稳定性和性能。
- 应用:H∞控制广泛应用于航空航天、机器人、自动驾驶等领域,特别适用于那些具有高度不确定性和复杂扰动的系统。
2. μ综合(Mu Synthesis):
μ综合是与H∞控制相关的另一种鲁棒控制方法,专门用于处理具有结构性不确定性的系统。结构性不确定性指的是系统的参数在一个已知范围内变化,但这些变化具有一定的规律性或结构。μ综合方法的目的是设计一个控制器,使系统在面对这些已知但变化的参数时依然能够稳定并达到预期的性能。
- 目标:设计一个能够应对系统结构性不确定性和外部扰动的鲁棒控制器。
- 应用:μ综合在工业控制、航天控制和其他需要应对已知不确定性或变化的系统中得到了广泛应用。
3. 图解中的各部分含义:
-
参考信号和扰动(( w )):这些是系统的输入,包括期望的参考信号和任何外部扰动或噪声。控制系统的目标是最小化扰动对系统输出的影响。
-
控制输入(( u )):控制器通过调整这些控制输入来影响系统行为。增益调节会根据系统的输出误差来调整这些输入,以减少误差。
-
系统(System):这是需要控制的主系统,接受控制输入并生成输出。系统根据控制输入的变化而动态调整。
-
误差信号(( z )):这些信号表示期望输出与实际输出之间的差值。控制器的目标是最小化这些误差。
-
测量变量(( v )):这些是从系统中获取的实际测量值,用于反馈控制和调整控制输入。
-
( K ):表示控制器,它根据误差信号和测量变量来计算控制输入(( u )),并根据这些输入调节系统行为,目标是最小化系统的误差和扰动。
4. 总结:
- H-无穷综合:通过设计一个能够在最不利情况下表现良好的控制器,确保系统在面对不确定性和扰动时依然能保持鲁棒性和稳定性。
- μ综合:专门应对系统具有已知结构不确定性的情况,设计控制器以稳定系统并消除不确定性带来的影响。
这两种方法都属于鲁棒控制领域,广泛应用于要求高性能和高可靠性的系统中,如航空航天、工业自动化等。
Model Predictive Control, MPC
这张图展示了模型预测控制(Model Predictive Control, MPC)的基本原理和结构。
1. 模型预测控制(MPC)的基本概念:
MPC是一种基于模型的先进控制方法,广泛应用于各种复杂的工业控制系统中。它的核心思想是使用系统的动态模型来预测未来行为,并在每个时刻通过优化控制输入来优化未来的系统行为,从而得到一个最优的控制策略。
2. MPC的工作流程:
-
参考信号(Reference):系统的目标或期望输出,控制器通过调整控制输入来尽可能使系统的输出接近参考信号。
-
优化器(Optimizer):根据预测模型、目标函数和约束条件,优化器计算出控制输入。这些控制输入是系统在未来一段时间内的最优控制策略。
-
预测模型(Prediction Model):预测模型是MPC的关键部分,它描述了系统的动态行为。它通过考虑当前的状态和控制输入来预测未来的系统输出。
-
MPC控制器(MPC controller):MPC控制器根据优化器给出的控制输入来调整系统的行为,确保系统按照预期运行。
-
控制输入(Control Inputs):这些是控制器通过优化计算出来的控制信号,用于调整系统的行为,使得系统输出接近参考信号。
-
系统(System):系统会根据控制输入的变化调整输出。系统的输出将反馈给控制器,用于下一次的优化计算。
-
输出(Outputs):系统根据控制输入生成的实际输出,控制器会根据这些输出与参考信号的差异来调整控制输入。
3. 用户需要提供的内容:
在设计MPC时,用户需要提供以下几个关键要素:
- 预测模型(Prediction model):系统的数学模型,用于预测系统的未来行为。
- 目标函数(Objective function):用于定义控制目标,通常是最小化输出误差或控制输入的能量消耗等。
- 系统约束(System constraints):包括系统的物理限制(如输入范围、输出范围等),以及任何其他约束条件(如速度限制、温度限制等)。
4. 总结:
MPC通过预测未来的系统行为,并在每个时刻通过优化控制输入来得到最优的控制策略。其优势在于能够处理系统的约束和多变量控制,尤其适用于复杂的多输入多输出(MIMO)系统。
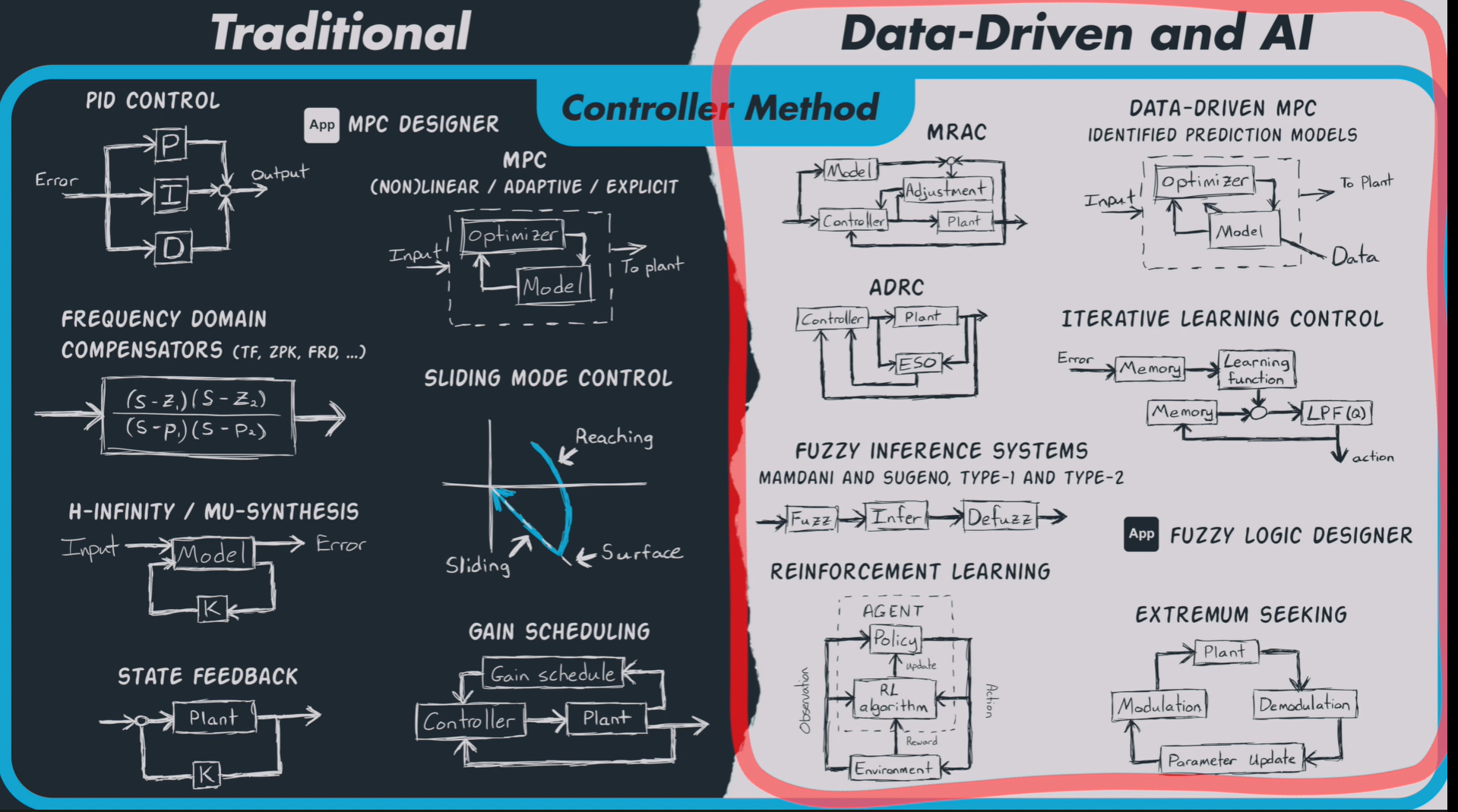
这张图展示了传统控制方法与数据驱动与人工智能方法的对比,分别列出了这两类控制方法中常用的控制器设计方法。
左侧:传统控制方法
-
PID控制(PID Control):
- 最常见的反馈控制方法,基于比例(P)、积分(I)和微分(D)调节器,通过调整误差来控制系统输出。
-
频域补偿器(Frequency Domain Compensators):
- 包括传递函数(TF)、零极点增益(ZPK)、频率响应设计(FRD)等,主要用于通过频率响应调整系统的稳定性和性能。
-
滑模控制(Sliding Mode Control):
- 非线性控制方法,通过将系统状态强制推向并保持在滑模面上来优化控制,广泛用于系统具有不确定性时。
-
H-无穷/μ-综合(H-infinity / Mu-Synthesis):
- 用于鲁棒控制,设计控制器以最小化系统对不确定性的响应,确保系统在外部扰动下的稳定性和性能。
-
增益调度(Gain Scheduling):
- 用于处理系统参数随工作条件变化的情况,通过选择适当的增益来调整控制器。
-
状态反馈(State Feedback):
- 基于系统状态的反馈,通过反馈控制输入来控制系统的状态,广泛应用于线性系统中。
-
模型预测控制(MPC):
- 基于系统模型的控制方法,通过优化当前时刻的控制输入来预测并控制系统的未来行为。
右侧:数据驱动与人工智能控制方法
-
模型参考自适应控制(MRAC):
- 通过调整控制器参数,使系统输出跟随参考模型,适用于系统动态变化较大的情况。
-
主动干扰拒绝控制(ADRC):
- 通过动态估计系统的干扰并实时调整控制输入,广泛应用于不确定性和扰动较大的非线性系统中。
-
数据驱动的MPC:
- 结合数据驱动方法的MPC,通过识别预测模型,并利用历史数据来优化控制输入。
-
迭代学习控制(Iterative Learning Control):
- 在重复操作的过程中,利用历史误差信息来优化控制输入,使得系统性能逐渐提高。
-
模糊推理系统(Fuzzy Inference Systems):
- 基于模糊逻辑设计的控制方法,适用于处理不确定性或难以量化的情况,如模糊控制器设计(Mamdani和Sugeno模型)。
-
强化学习(Reinforcement Learning):
- 基于智能体与环境的交互,通过奖励机制来优化控制策略,适用于自主决策和控制问题。
-
极值寻求(Extremum Seeking):
- 通过调节系统参数来寻找最优操作点,广泛应用于优化和调节系统性能的场合。
总结:
-
传统控制方法(左侧)侧重于基于数学模型和经典控制方法,如PID控制、滑模控制、增益调度等。这些方法适用于大多数线性或已知动态的系统。
-
数据驱动与人工智能方法(右侧)则强调利用历史数据和智能算法(如强化学习、模糊控制、数据驱动的MPC等),这些方法特别适用于动态不确定性较大、难以建立精确数学模型的系统。
两种方法各有优缺点,传统方法在已知系统模型的情况下表现优秀,而数据驱动与AI方法则在面对复杂和动态环境时具有更好的适应性和优化能力。
ADRC
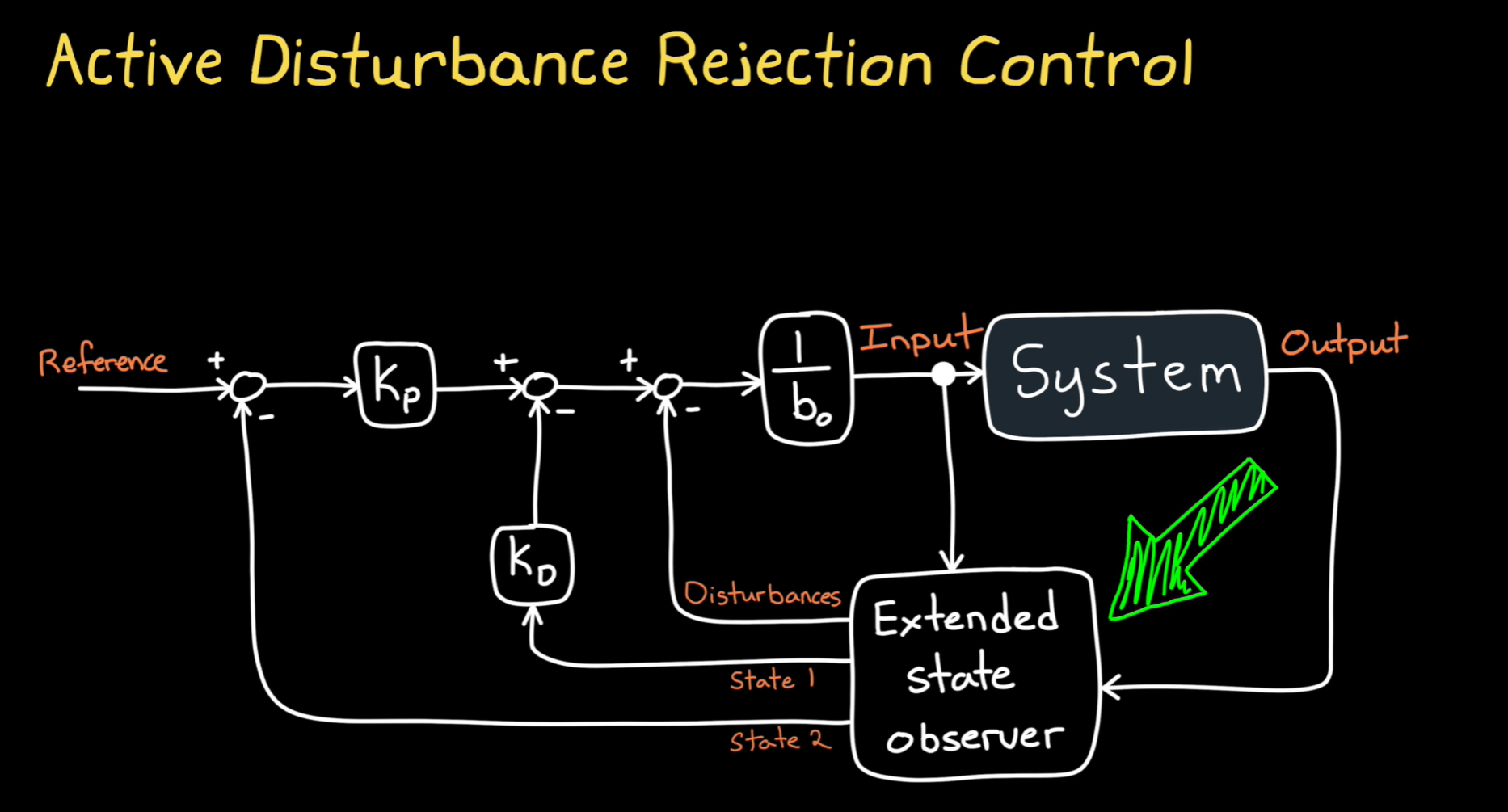
这张图展示了主动干扰拒绝控制(**Active Disturbance Rejection Control, ADRC)**的基本原理。
ADRC控制的工作原理:
ADRC是一种基于系统动态建模的控制方法,主要目的是通过实时估计系统中的干扰(如外部扰动、建模误差等),并在控制输入中进行补偿,以确保系统的稳定性和良好的性能。
图中各部分含义:
-
参考信号(Reference):
系统期望达到的目标输出。 -
比例控制器(( K_p )):
这是ADRC的一个基本部分,它根据误差(参考信号与输出之间的差)调整控制输入。比例项通过放大误差来计算控制量,确保系统尽快接近目标。 -
微分控制器(( K_d )):
微分项根据误差变化的速率来调整控制输入,可以减少系统响应的超调和振荡,帮助系统更平稳地达到稳态。 -
系统(System):
这是需要控制的目标系统,通过输入控制信号后,系统会产生输出。该系统会受到外部扰动和不确定性的影响,ADRC控制器的目标是最小化这些干扰对系统性能的影响。 -
扰动(Disturbances):
外部扰动或系统内部的未建模动态,它们可能对系统输出产生不利影响。ADRC通过估计这些扰动并进行补偿,减小其影响。 -
扩展状态观测器(Extended State Observer, ESO):
扩展状态观测器是ADRC的核心部分,它通过观测系统的状态,实时估计系统的干扰和未建模的动态部分(包括状态误差和扰动)。ESO的输出被反馈到控制器中,从而实时补偿系统中的扰动和不确定性。 -
输入(Input):
控制器计算出的控制输入,控制系统的行为,使其尽量接近参考信号。 -
输出(Output):
系统产生的实际输出,ADRC的目标是使输出与参考信号之间的误差最小。
ADRC的优势:
- 鲁棒性强:ADRC能够有效应对外部扰动和系统不确定性,无需精确的系统模型。
- 估计干扰:通过扩展状态观测器(ESO)实时估计和补偿干扰,ADRC使得系统能够在有扰动的环境中仍保持稳定。
- 适应性强:ADRC能够适应复杂的动态系统,尤其是非线性和时变系统。
应用:
ADRC广泛应用于需要高精度和稳定性的控制系统中,如:
- 机器人控制
- 飞行控制
- 电力系统
- 自动驾驶
通过实时估计扰动并补偿,ADRC控制方法能够在复杂和动态的环境中提供可靠的控制性能。
MRAC
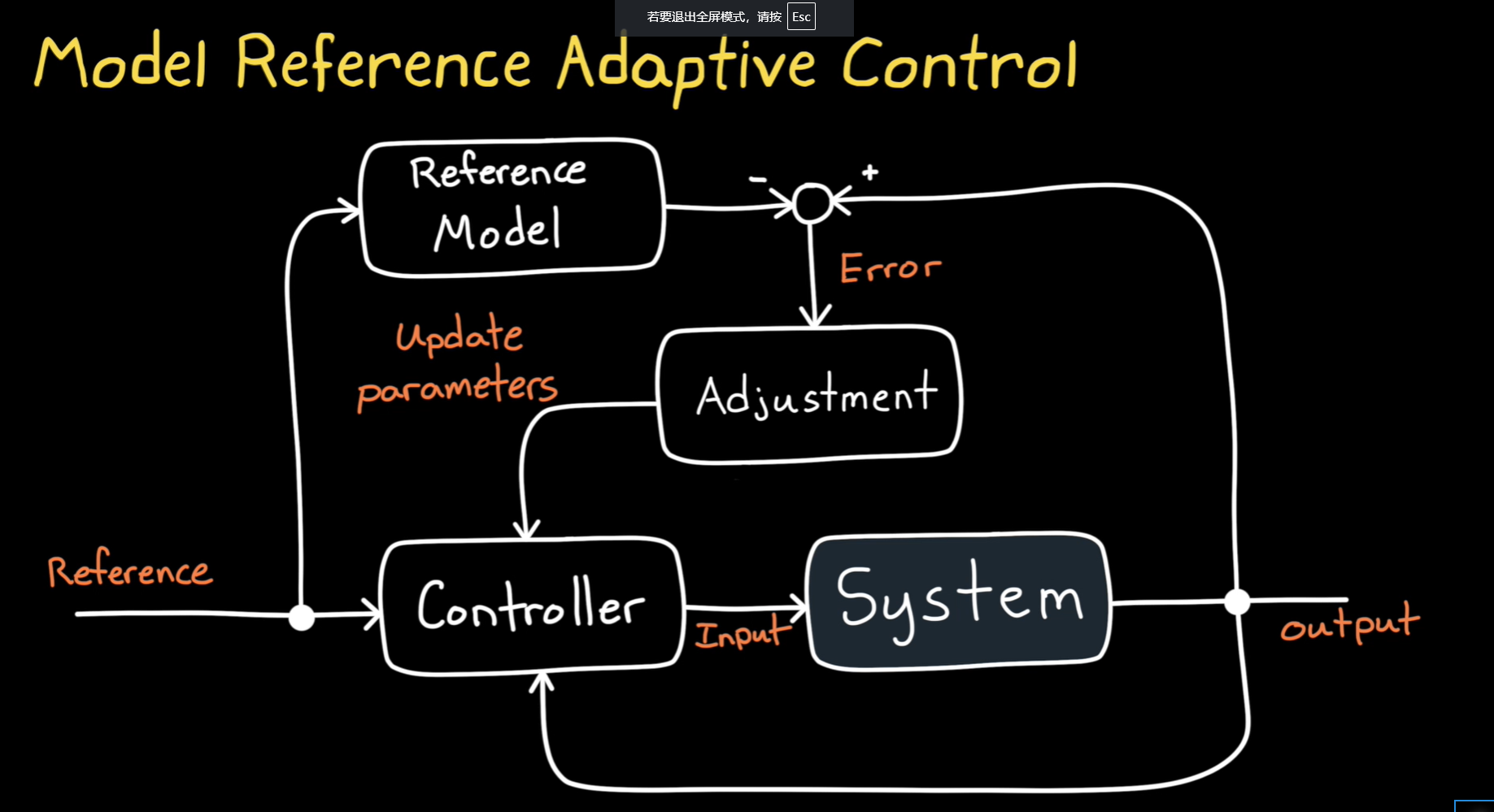
这张图展示了模型参考自适应控制(Model Reference Adaptive Control, MRAC)的基本结构和工作原理。
MRAC的工作原理:
模型参考自适应控制(MRAC)是一种自适应控制方法,通过使系统的输出跟踪参考模型的输出来实现控制。MRAC的核心是根据实时误差动态调整控制器的参数,使系统输出与期望的参考模型相匹配。以下是图中各个组成部分的详细说明:
图中各部分含义:
-
参考信号(Reference):
- 系统期望达到的目标输出。参考信号通常由外部输入或预设的控制目标决定,作为控制系统的目标。
-
参考模型(Reference Model):
- 参考模型是一个预先设定的理想模型,代表系统在没有扰动和不确定性情况下的理想行为。MRAC的目标是使实际系统的输出与参考模型的输出一致。
-
误差(Error):
- 误差是参考模型的输出与系统实际输出之间的差值。该误差用于评估系统与参考模型之间的差异。
-
调整(Adjustment):
- 基于误差,调整部分会计算控制器需要调整的参数。MRAC会不断根据误差调整控制器的参数,以使系统的输出更接近参考模型的输出。
-
控制器(Controller):
- 控制器根据调整的参数和当前的误差计算控制输入。控制器的目标是通过调整输入来驱动系统输出,以使其与参考模型一致。
-
系统(System):
- 系统是需要控制的目标对象,接收控制器的输入,并根据该输入生成系统的输出。系统的输出与参考模型的输出进行比较,控制器根据差异调整输入。
-
输入(Input):
- 控制器计算出的控制输入,用于调整系统的行为,确保系统输出跟随参考模型的输出。
-
输出(Output):
- 系统产生的实际输出,控制系统的目标是将输出尽可能地与参考模型的输出一致。
MRAC的特点:
- 自适应性:MRAC能够根据系统动态的变化自适应地调整控制器的参数,从而使得系统能够在不同的操作条件下保持最佳性能。
- 实时调整:MRAC通过实时计算误差并调整控制器参数,能够动态应对系统参数的不确定性和外部扰动。
- 参考模型:通过引入参考模型,MRAC提供了一个明确的性能标准,控制系统的目标是使输出跟踪参考模型的行为。
应用领域:
MRAC广泛应用于许多需要自适应调节和鲁棒性的控制系统中,例如:
- 机器人控制:在机器人系统中,MRAC能够应对环境变化和负载变化,确保机器人的精确运动。
- 飞行控制系统:MRAC在航空航天中用于实时调整飞行控制系统的参数,确保飞行器在不同飞行条件下稳定运行。
- 自动驾驶:在自动驾驶汽车中,MRAC用于处理动态和复杂的驾驶环境,确保车辆的稳定性和安全性。
总结:
模型参考自适应控制(MRAC)是一种通过使实际系统输出跟踪参考模型来实现自适应控制的方法。它能够在面对不确定性、扰动以及系统动态变化时保持良好的控制性能。
ESC
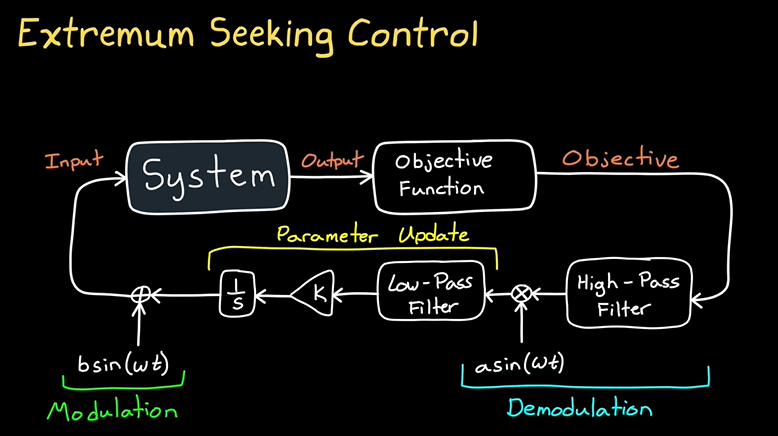
这张图展示了极值寻求控制(Extremum Seeking Control, ESC)的基本原理和工作流程。
极值寻求控制的工作原理:
极值寻求控制是一种优化控制方法,主要用于动态调整系统参数,使系统在给定的操作条件下找到一个优化点(如最大效率、最小能耗等)。其核心思想是通过调节系统参数,使输出达到某一最优极值。
图中各部分含义:
-
输入(Input):
控制器输入信号,可能是系统需要控制的变量,如电机的输入电流、热力系统的输入温度等。 -
系统(System):
这是需要控制的目标系统,根据输入控制信号,系统会产生一个输出。系统的目标是通过调整控制输入达到某一最优状态。 -
输出(Output):
系统产生的实际输出,控制器会根据这个输出来调整输入。 -
目标函数(Objective Function):
目标函数定义了系统优化的目标,例如最大化某一性能指标(如功率输出)或最小化某种能量消耗。控制器的目标是通过优化过程找到目标函数的极值。 -
极值(Objective):
目标是找到系统输出的极值点,这个极值代表了系统在特定条件下的最优状态。控制系统通过调节输入,使输出达到该极值。 -
参数更新(Parameter Update):
控制系统根据目标函数和输出结果调整系统参数,以寻找到目标函数的极值。 -
低通滤波器(Low-Pass Filter):
用于滤除高频噪声,确保仅保留与目标函数相关的低频信息,从而稳定控制输入。 -
高通滤波器(High-Pass Filter):
主要用于提取变化较大的信号成分(即系统参数的变化部分),通过高频信息帮助控制器进一步调整参数。 -
调制(Modulation):
系统输入信号通过调制(如正弦波调制)方式进行调整,调制信号的幅度和频率将直接影响系统的调节过程。 -
解调(Demodulation):
通过解调过程,控制器从系统的输出中提取关键信息,并对系统参数进行调整,逐步逼近最优的操作点。 -
( b \sin(\omega t) ) 和 ( a \sin(\omega t) ):
这些表示调制和解调过程中的正弦波信号。调制信号 ( b \sin(\omega t) ) 用于控制输入,而解调信号 ( a \sin(\omega t) ) 从输出中提取变化信息。
极值寻求控制的优势:
- 无需精确模型:与传统的优化方法相比,极值寻求控制不需要精确的系统模型,而是通过实时调整系统参数来寻找最优点。
- 自适应性:控制系统能够根据输出反馈实时调整,适应动态变化的环境和系统。
- 优化效率:极值寻求控制在许多工业应用中能够有效地提高系统的工作效率,减少能耗或增加系统的性能。
应用领域:
极值寻求控制广泛应用于以下领域:
- 能源优化:如太阳能电池、风力发电系统的最大功率点追踪(MPPT)。
- 化学过程控制:用于优化反应过程中的温度、压力等参数,最大化产量或最小化能量消耗。
- 电机控制:用于优化电动机的工作效率,减少损耗。
总结:
极值寻求控制(ESC)是一种智能优化控制方法,通过实时调整系统的输入参数,使得系统输出达到最优极值。它在许多动态系统和复杂环境中表现出良好的适应性和优化能力。
FIS
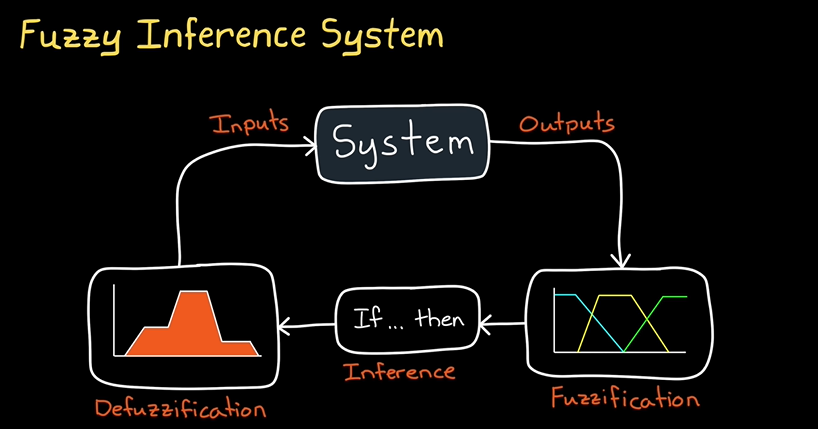
这张图展示了模糊推理系统(Fuzzy Inference System, FIS)的基本工作原理和结构。
模糊推理系统(FIS):
模糊推理系统是一种基于模糊逻辑的推理方法,它通过处理模糊输入并生成模糊输出,以适应现实中不确定和模糊的信息。FIS广泛应用于各种控制和决策系统中,如自动化控制、机器学习和决策支持系统。
图中各部分含义:
-
输入(Inputs):
- 这些是模糊推理系统的输入变量。例如,温度、速度或其他控制系统中的测量量。输入变量通常是模糊的,因此它们通过模糊化过程转化为模糊集。
-
系统(System):
- 系统处理输入并生成输出。FIS根据预先定义的规则进行推理,推理规则通过“如果…那么…”语句来建立(例如,“如果温度高,则速度快”)。
-
推理(Inference):
- 推理过程是模糊推理系统的核心。在此阶段,FIS根据输入数据和一组模糊规则来推断输出。推理基于模糊集合的运算,通常使用模糊集合的交集、并集等运算来得出结论。
-
输出(Outputs):
- 系统的最终输出。通过推理过程,输入数据被转换为相应的模糊输出,后续的解模糊过程将生成最终的控制信号或决策结果。
-
解模糊化(Defuzzification):
- 解模糊化过程将模糊输出转换为精确值,通常使用中心法、最大隶属度法等方法将模糊结果转换为清晰的输出。例如,温度控制系统可能使用解模糊化来输出一个具体的温控值(如20°C)。
-
模糊化(Fuzzification):
- 模糊化是将系统输入数据从精确值转换为模糊集合的过程。通过模糊化,输入值不再是单一的数值,而是描述输入的不确定性。例如,温度输入可能变成“低”、“中”等模糊集合。
FIS的工作流程:
- 输入模糊化:将实际输入值转换为模糊集合(例如,将“30°C”转换为“高温”)。
- 推理过程:根据预设的模糊规则库,利用“如果…那么…”语句进行推理。例如:“如果温度高,则风速大”。
- 输出解模糊化:根据推理结果,解模糊化得到一个具体的输出值(如风速的具体数值)。
应用领域:
模糊推理系统广泛应用于控制系统和决策系统中,包括:
- 温控系统:例如在空调系统中根据环境温度调整输出。
- 自动驾驶:根据路面情况、交通信号等进行决策。
- 机器人控制:通过模糊推理实现复杂环境下的动作决策。
总结:
模糊推理系统(FIS)通过模糊化、推理和解模糊化的过程,可以有效处理不确定和模糊的信息,帮助系统做出更灵活、更适应环境变化的决策。它的优点是能够处理复杂和不确定的输入输出关系,适用于多种不确定性较大的控制和决策问题。
RL
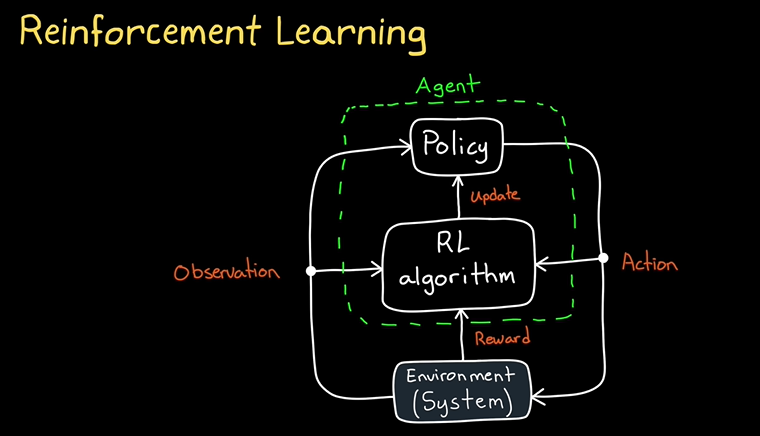
这张图展示了强化学习(Reinforcement Learning, RL)的基本框架和工作流程。
强化学习的基本原理:
强化学习是一种基于奖励和惩罚的学习方法,智能体通过与环境的交互来学习如何做出决策。智能体采取行动,根据环境反馈的奖励信息不断调整自己的策略,以最大化累积奖励。
图中各部分含义:
-
观察(Observation):
- 环境向智能体提供的信息或状态,智能体基于这些信息来做出决策。观察是智能体与环境交互的起点。
- 例如,在自动驾驶中,观察可以是摄像头获取的图像数据,或者车速和位置等信息。
-
环境(Environment/System):
- 环境是智能体与之交互的对象。在强化学习中,环境根据智能体的动作返回反馈。
- 环境的状态可以随时间变化,并受到智能体所采取的行动影响。
-
智能体(Agent):
- 智能体是执行决策并采取行动的主体。它根据从环境中获得的观察信息,采取相应的动作,并根据环境的反馈来改进自己的策略。
-
策略(Policy):
- 策略定义了智能体在特定状态下应该采取什么样的动作。策略可以是确定性的(给定状态,采取某个固定动作),也可以是概率性的(给定状态,按照一定概率分布选择动作)。
- 强化学习的目标之一是优化策略,使智能体在每个状态下选择最优的动作。
-
动作(Action):
- 动作是智能体在特定状态下选择的操作。智能体根据当前策略选择一个动作,并将其作用于环境。
-
奖励(Reward):
- 奖励是环境对智能体执行动作后的反馈。奖励用于评估智能体的行动是否有利于实现目标,通常智能体会试图最大化累积的奖励。
-
强化学习算法(RL Algorithm):
- 强化学习算法用于优化智能体的策略。通过不断与环境交互,算法通过调整策略来最大化长期的奖励。
- 强化学习算法包括Q学习、深度Q网络(DQN)、策略梯度等,它们的目标是找到使智能体在不同环境状态下获得最大奖励的策略。
-
策略更新(Update):
- 根据环境反馈的奖励,智能体会不断调整和更新策略。这一过程通过强化学习算法来实现,目的是使得策略越来越有效,最终使得智能体在环境中表现最佳。
强化学习的工作流程:
- 观察:智能体从环境中获取状态信息(如环境的当前状态)。
- 动作选择:智能体根据当前策略选择一个动作。
- 执行动作:智能体执行选择的动作并与环境进行交互。
- 获取奖励:环境根据智能体的动作给予奖励或惩罚。
- 策略更新:智能体根据收到的奖励调整其策略,通过学习改进未来的决策。
应用领域:
强化学习已经被广泛应用于以下领域:
- 游戏:例如,AlphaGo和其他AI游戏代理,通过与环境(游戏)交互进行自我学习和优化。
- 自动驾驶:自动驾驶汽车通过强化学习优化路径规划和驾驶决策。
- 机器人控制:机器人通过强化学习不断提高抓取、搬运等动作的精度和效率。
- 推荐系统:通过强化学习优化内容推荐,使用户获得更好的体验。
- 金融交易:强化学习应用于股票交易或投资决策,优化收益和风险。
总结:
强化学习是一种通过与环境的互动来不断优化决策的机器学习方法。智能体在强化学习框架下,通过执行动作、获取反馈和更新策略,不断学习如何在给定环境中取得最佳表现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









