






4.1概述:分类
分类:是通过训练数据建立预测(分类)模型,并利用模型将需要预测的数据样本划分到已知的几个类别中的过程(预测离散值)
分类操作一般分为以下四个步骤:
1.分类模型的构造,即通过带分类标记训练样本来建
立分类模型
2.利用分类模型对没有分类标记的数据进行预测分类3.对分类模型的优劣进行评估
4.优化分类模型
一般数据集被分成不相交的训练和测试集训练集被用来构造分类模型
测试集用来检验模型的泛化能力
经典的分类方法包括:K近邻,决策树,SVM,神经网络等
4.2 K近邻基本思想
K近邻( K Nearest Neighbor,KNN )算法简介:
是一种最经典和简单的有监督学习方法之一。
没有训练过程,只有预测过程
是一种 Lazy学习方法
基本思想:
当对测试样本进行分类时,首先扫描训练样本集,找到与该样本集最相似的k个样本,根据k个样本的类别进行确定测试样本的类别。
优点:对异常数据不敏感,简单易实现,训练集
大时效果好
缺点:占用大量存储空间,计算效率不高,当训练集较小的时候,K近邻算法易导致过度拟合
4.3 K近邻算法及核心问题
4.3.1 K近邻算法
算法流程
1.确定k的大小和距离计算方法
2.从训练样本中得到k个与测试样本距离最近的
样本
3.根据k个最相似的训练样本的类别,通过投票
的方式来确定测试样本的类别
三个核心问题
1.如何计算样本之间的距离或相似度
2.如何选择k大小才能达到最好的预测效果3.如何投票确定分类结果
距离计算:欧式距离
欧式距离是最常见的距离度量,衡量的是特征空间中两个样本点之间的绝对距离。假设特征空间的维度为d(即样本有d个特征)
设x =(x1, x12,…,x1d)和x=(x21,X2,…",x2d)是两个样本点,则x,和x,之间的欧式距离计算公式为:
 投票问题
投票问题
K个近邻样本权重相同
K个近邻样本按距离,与距离成反比设置权重根据实际问题自定义函数
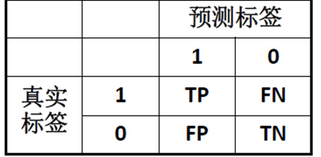
分类过程中存在两种标签:样本真实标签模型预测标签
根据这两种标签可以得到一个混淆矩阵Confusion Matrix
每一行代表样本的真实类别,数据总数表示
该类别的样本数目
每一列代表样本的预测类别,数据总数表示
该类别的样本的数目
分类模型的评价指标主要基于混淆矩阵
True Positive (TP):样本真实类别为正,预测类别也为正。
False Negative (FN):样本真实类别为正,预测类别为负。
False Positive (FP):样本真实类别为负,预测类别为正。
True Negative (TN):样本真实类别为负,预测类别也为负。
 正确率的定义如下:
正确率的定义如下:
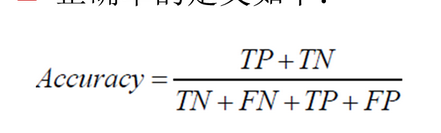 查准率与查全率:
查准率与查全率:
查准率(precision)和查全率(recall)是比正确率更好的性能评价指标,
特别是对某个类别的评价,比如稀有类的分类问题。
查准率(Precision)是指正确预测的正样本占所有预测为正样本的比例
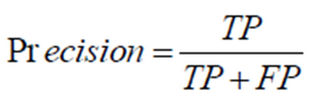 召回率(Recall,查全率),又称灵敏度和命中率,指正样本中被正确预测的比例
召回率(Recall,查全率),又称灵敏度和命中率,指正样本中被正确预测的比例
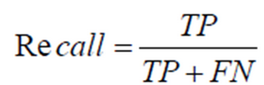 查准率和查全率是负相关的:高查准率往往对应低查全率,反之亦然
查准率和查全率是负相关的:高查准率往往对应低查全率,反之亦然
需要根据实际问题场景在查准率和查全率指标上做权衡,需要综合考虑
综合考虑查准率和查全率的指标:F值,定义
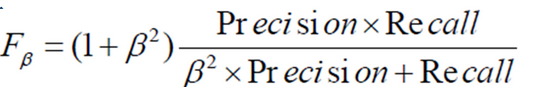 其中β为正数,其作用是调整查准率和查全率的权重。β>1时查全率的权重更大;β<1,则查准率的权重更大。
其中β为正数,其作用是调整查准率和查全率的权重。β>1时查全率的权重更大;β<1,则查准率的权重更大。
当β=1时,查准率和查全率的权重一样,此时称为F1值,它是查准率和查全率的调和平均数。


















 7941
7941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









