









四、MapReduce常用Shell操作
4.1、MapReduce常用Shell
MapReduce Shell 此处指的是可以使用类似shell的命令来直接和MapReduce任务进行交互(这里不严格区分MapReduce shell及Yarn shell)。
提交任务命令:
yarn jar <jar> [mainClass] args...
查看及修改任务命令:
yarn application [options] Usage: yarn app [options]
可选项:
- appId : 指定APPlication id
- changeQueue : 改变队列
- kill : 停止任务
- status : 查看任务状态
4.2、常用Shell-任务实例
查看MapReduce可以命令
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar

使用pi计算实例
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi

设置参数
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 100 10

然后我们可以获得application的id

通过这个id查看状态
yarn application -status application_1619841871021_0001

我们也可以在浏览器查看这个信息,浏览器端口:master:8088

关闭这个任务:
yarn application -kill application_1619841871021_0001


五、MapReduce任务管理
MapReduce任务日志查看:

5.1、多任务竞争
我们可以通过修改/opt/hadoop-3.1.4/etc/hadoop/下的capacity-scheduler.xml,来同时运行两个任务
cd /opt/hadoop-3.1.4/etc/hadoop/
vi capacity-scheduler.xml
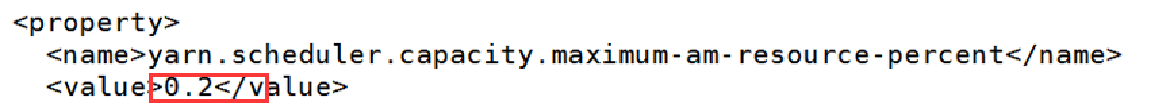
改完后拷贝到其他结点
scp capacity-scheduler.xml node1:/opt/hadoop-3.1.4/etc/hadoop/
scp capacity-scheduler.xml node2:/opt/hadoop-3.1.4/etc/hadoop/
scp capacity-scheduler.xml node3:/opt/hadoop-3.1.4/etc/hadoop/

最后使配置生效
yarn rmadmin -refreshQueues
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











