






一、Spark SQL简介
1.1、Spark SQL特性
-
Spark SQL是Spark Core之上的一个组件,它引入了一个称为SchemaRDD的新- 数据抽象,它为结构化和半结构化数据提供支持
-
提供了DataFrame、DataSet的编程抽象
-
可以充当分布式SQL查询引擎
-
Spark SQL是spark套件中一个模板,它将数据的计算任务通过SQL的形式转换成了RDD的计算,类似于Hive通过SQL的形式将数据的计算任务转换成了MapReduce。
-
Spark SQL也可以用来从Hive中读取数据,当我们使用其它编程语言来运行一个SQL语句,结果返回的是一个Dataset或者DataFrame.你可以使用命令行,JDBC或者ODBC的方式来与SQL进行交互。
1.2、Spark SQL特性
1、集成
无缝地将SQL查询与Spark程序混合。 Spark SQL允许用户将结构化数据作为Spark中的分布式数据集(RDD)进行查询,这种紧密的集成使得可以轻松地运行SQL查询以及复杂的分析算法。
2、统一数据访问
加载和查询来自各种来源的数据。Schema-RDDs提供了一个有效处理结构化数据的单一接口,加载和查询来自各种来源的数据。
3、标准连接
通过JDBC或ODBC连接。 Spark SQL包括具有行业标准JDBC和ODBC连接的服务器模式。
4、Hive兼容性
在现有仓库上运行未修改的Hive查询。 Spark SQL重用了Hive前端和MetaStore,为您提供与现有Hive数据,查询和UDF的完全兼容性。只需将其与Hive一起安装即可。
5、可扩展性
对于交互式查询和长查询使用相同的引擎。 Spark SQL利用RDD模型来支持中查询容错,使其能够扩展到大型作业。不要担心为历史数据使用不同的引擎。
1.3、Spark SQL架构

二、环境配置
1、拷贝hive-site.xml到/usr/local/spark-2.4.0-bin-hadoop2.6/conf
cp /opt/apache-hive-1.2.1-bin/conf/hive-site.xml /opt/spark-2.4.0-bin-hadoop2.6/conf/
scp /opt/apache-hive-1.2.1-bin/conf/hive-site.xml node1:/opt/spark-2.4.0-bin-hadoop2.6/conf/
scp /opt/apache-hive-1.2.1-bin/conf/hive-site.xml node2:/opt/spark-2.4.0-bin-hadoop2.6/conf/
scp /optapache-hive-1.2.1-bin/conf/hive-site.xml node3:/opt/spark-2.4.0-bin-hadoop2.6/conf/
2、拷贝MYSQL驱动到/opt/spark-2.4.0-bin-hadoop2.6/jars
cp /opt/apache-hive-1.2.1-bin/lib/mysql-connector-java-5.1.32-bin.jar /opt/spark-2.4.0-bin-hadoop2.6/jars/
scp /opt/spark-2.4.0-bin-hadoop2.6/jars/mysql-connector-java-5.1.32-bin.jar node1:/opt/spark-2.4.0-bin-hadoop2.6/jars/
scp /opt/spark-2.4.0-bin-hadoop2.6/jars/mysql-connector-java-5.1.32-bin.jar node2:/opt/spark-2.4.0-bin-hadoop2.6/jars/
scp /opt/spark-2.4.0-bin-hadoop2.6/jars/mysql-connector-java-5.1.32-bin.jar node3:/opt/spark-2.4.0-bin-hadoop2.6/jars/
3、在所有节点/opt/spark-2.4.0-bin-hadoop2.6/conf/spark-env.sh 文件中配置 MySQL 驱动
SPARK_CLASSPATH=/opt/spark-2.4.0-bin-hadoop2.6/jars/mysql-connector-java-5.1.32-bin.jar
4、启动 MySQL 服务
(若已启动,忽略)
service mysqld start
5、启动 Hive 的 metastore 服务
(若已启动,忽略)
hive --service metastore &
6、修改日志级别,在各节点:
cp /opt/spark-2.4.0-bin-hadoop2.6/conf/log4j.properties.template /opt/spark-2.4.0-bin-hadoop2.6/conf/log4j.properties
修改log4j.properties
log4j.rootCategory=WARN, console
7、启动spark集群
(若已启动,忽略)
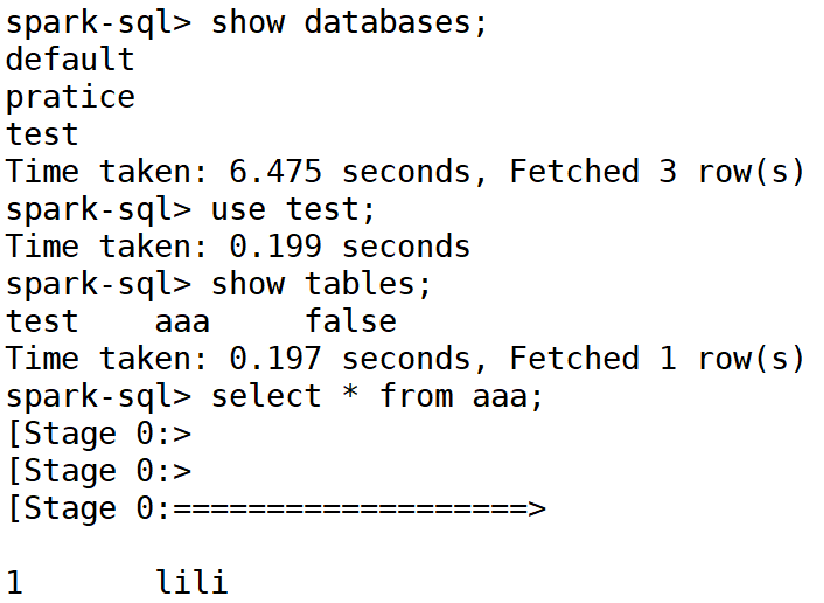
8、访问spark-sql
















 765
765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











