






 这篇博客探讨了Spring Boot中的数据库设计,包括Entity设计,使用了Lombok简化代码,详细介绍了JPA的注解如@Id、@GeneratedValue、@Column、@Temporal等。文章还涉及Controller的使用,如@RequestParam和@RequestBody的区别。在Service层,讲解了Spring Data JPA的复杂查询和Specification API的运用,以及为何在Controller和Service中使用final属性。最后提到了JWT身份验证和阿里云部署的相关内容。
这篇博客探讨了Spring Boot中的数据库设计,包括Entity设计,使用了Lombok简化代码,详细介绍了JPA的注解如@Id、@GeneratedValue、@Column、@Temporal等。文章还涉及Controller的使用,如@RequestParam和@RequestBody的区别。在Service层,讲解了Spring Data JPA的复杂查询和Specification API的运用,以及为何在Controller和Service中使用final属性。最后提到了JWT身份验证和阿里云部署的相关内容。
一. 数据库设计–Entity
设计
- Note Entity
字段
NoteLibrary 一对多 双向
User 多对一
Paper 多对多 双向 - NoteLibrary Entity
字段
Note 多对一 双向
User 多对一
LibraryCollection 多对一 - NoteLibraryCollection Entity
字段 id name
User 多对一
注册用户时新建默认收藏夹 - NoteImageFile Entity
字段
Note 多对一
注解
-
@NoArgsConstructor
注解在类上,为类提供一个无参的构造方法。
这个注解来自Lombok:减少样板性代码。@Getter、@Setter、@Data都来自于它。
Lombok的基本使用 -
主键的两个JPA注解。这两个注解有两种写法,要么全写在属性上,要么全写在getId()方法上(属性上不写)。
@Id:
@Id 标注用于声明一个实体类的属性映射为数据库的主键列。该属性通常置于属性声明语句之前,可与声明语句同行,也可写在单独行上。
@Id标注也可置于属性的getter方法之前。
@GeneratedValue:
@GeneratedValue 用于标注主键的生成策略,通过strategy 属性指定。默认情况下,JPA 自动选择一个最适合底层数据库的主键生成策略:SqlServer对应identity,MySQL 对应 auto increment。
在javax.persistence.GenerationType中定义了以下几种可供选择的策略:
–IDENTITY:采用数据库ID自增长的方式来自增主键字段,Oracle 不支持这种方式;
–AUTO: JPA自动选择合适的策略,是默认选项;
–SEQUENCE:通过序列产生主键,通过@SequenceGenerator 注解指定序列名,MySql不支持这种方式
–TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。 -
@Column。属性前或getter方法前。Spring注解。
用来标识实体类中属性与数据表中字段的对应关系 -
@Temporal
数据库的字段类型有date、time、datetime
而Temporal注解的作用就是帮Java的Date类型进行格式化,一共有三种注解值:
第一种:@Temporal(TemporalType.DATE)——>实体类会封装成日期“yyyy-MM-dd”的 Date类型。
第二种:@Temporal(TemporalType.TIME)——>实体类会封装成时间“hh-MM-ss”的 Date类型。
第三种:@Temporal(TemporalType.TIMESTAMP)——>实体类会封装成完整的时间“yyyy-MM-dd hh:MM:ss”的 Date类型。 -
CascadeType(各种级联操作)
– JPA概念解析:CascadeType(各种级联操作)详解
– Hibernate cascade级联属性的CascadeType的用法
– Hibernate 注解中CascadeType用法汇总
cascade可以同时赋予几个权限:@ManyToOne(cascade={CascadeType.MERGE,CascadeType.PERSIST})
cascade不赋值时默认不级联。 -
fetch管读取,cascade管增删改
@OneToMany(mappedBy=“group”,cascade=(CascadeType.ALL),fetch=FetchType.EAGER)
@OneToMany默认的是LAZY,@ManyToOne默认是EAGER
懒加载与急加载FetchType.LAZY&FetchType.EAGER的区别和使用?
cascadeType怎么判断? -
@JoinTable (一般用于@ManyToMany生成联表)
@JoinTable(name = “t_clinic_role_menu”,
joinColumns = {@JoinColumn(name = “role_id”)},
inverseJoinColumns = {@JoinColumn(name = “menu_id”)})
其中 joinColumns 写的是本表在中间表的外键名称,
inverseJoinColumns写的是另一个表在中间表的外键名称。
如果不注明外键名,则默认用关联的表名作为外键名。 -
@JsonBackReference和@JsonManagedReference,以及@JsonIgnore均是为了解决对象中存在双向引用导致的无限递归(infinite recursion)问题
jackson中的@JsonBackReference
jackson中的@JsonBackReference和@JsonManagedReference,以及@JsonIgnore
@JsonBackReference标注的属性在序列化(serialization,即将对象转换为json数据)时,会被忽略(即结果中的json数据不包含该属性的内容)。(个人理解:大概这就是被动那一方的标注,即mappedBy的那一方)
@JsonManagedReference标注的属性则会被序列化。(个人理解:大概是主动维护关系一方的标注。) -
@OneToMany, ManyToOne, ManyToMany中mappedBy的含义。所填内容必为本类在另一方的字段名。表示:本类放弃控制关联关系,所有对关联关系的控制,如:建立、解除与另一方的关系,都由对方控制,本类不管。
Hibernate 一对一、一对多、多对多注解mappedBy属性的总结
注意,mappedBy标注代表着这两个实体是双向的。如非必要,不使用双向。 -
jpa 中@ManyToMany 标签使用后,只对关联表进行删除的写法
如果需求是只要求解除菜单和角色的关联关系,而不是去删除菜单或者角色。就需要用这样的语法:
note.getPaperSet().removeAll(note.getPaperSet()); -
@Table(
uniqueConstraints =
{@UniqueConstraint(columnNames = {“user”, “note”, “noteLibraryCollection”})})
概念
JPA与MyBatis
JPA、Hibernate、Spring Data JPA的关系
二、Controller
注解
- @requestparam :在路径后加入?xx=value1&yy=value2即可传入。接收的参数是来自requestHeader中,即请求头。通常用于GET请求。
@requestbody:接收的参数是来自requestBody中,即请求体。一般用于处理非 Content-Type: application/x-www-form-urlencoded编码格式的数据,比如:application/json、application/xml等类型的数据。
注解@RequestParam与@RequestBody的使用场景
form-data、x-www-form-urlencoded是什么?
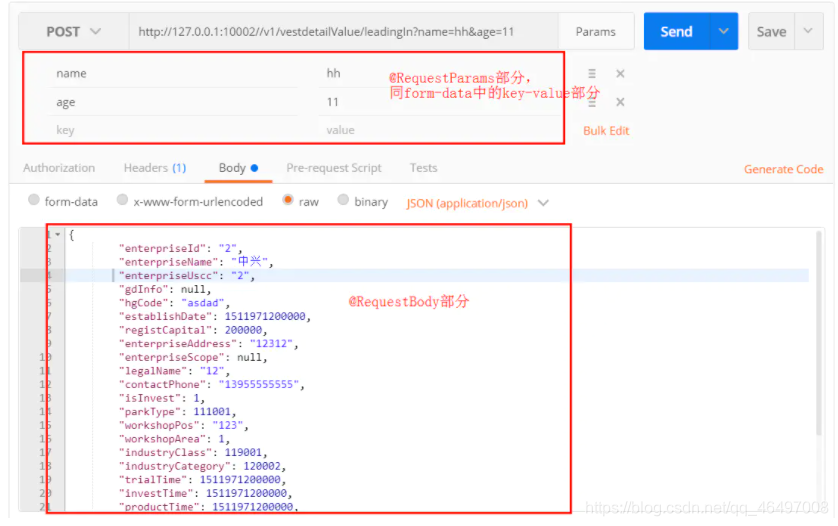
- @Transactional?
- @EntityGraph
三、Service
细节
- 为什么controller和service的属性都是final?
spring data jpa复杂查询
- Specification查询构造器
- Root:查询哪个表。是查询结果的一个实体对象,也就是查询结果返回的主要对象。
- CriteriaQuery:查询哪些字段,排序是什么。主要是构建查询条件的,里面的方法都是各种查询方式:distinct、select、where、groupby、having、orderby这些方法,想必大家都知道这些是组件SQL语句的基本方法。
- CriteriaBuilder:字段之间是什么关系,如何生成一个查询条件,每一个查询条件都是什么方式。这个接口中,很多方法都是返回Predicate接口的,其中包含between、gt(大于)、lt(小于)、not(非)等等操作。
Interface CriteriaBuilder - Predicate:为Expression(javax.persistence.criteria.Expression< Boolean >)的子接口,可以肯定也是字段相关的表达式。单独每一条查询条件的详细描述。
java代码之美(13)— Predicate详解
public interface Predicate<T> {
/**
* 具体过滤操作 需要被子类实现.
* 用来处理参数T是否满足要求,可以理解为 条件A
*/
boolean test(T t);
/**
* 调用当前Predicate的test方法之后再去调用other的test方法,相当于进行两次判断
* 可理解为 条件A && 条件B
*/
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
使用示例:
//在上面大于7的条件下,添加是偶数的条件
predicate = predicate.and(x -> x % 2 == 0);
System.out.println(predicate.test(6)); //输出 fasle
System.out.println(predicate.test(12)); //输出 true
System.out.println(predicate.test(13)); //输出 fasle
补充:<? extends T> 和 <? super T>分别是什么意思?有什么不同?
< ? extends T >:T的某一种子类的意思,记住是一种,单一的一种。问题来了,由于连哪一种都不确定,带来了不确定性,所以是不可能通过add()来加入元素。你或许还觉得为什么add(T)不行?因为<? extends T>是T的某种子类,能放入子类的容器不一定放入超类,也就是没可能放入T。
< ? super T >这里比较容易使用,没<? extends T>这么多限制,这里的意思是,以T类为下限的某种类,简单地说就是T类的超类。但为什么add(T)可以呢?因为能放入某一类的容器一定可以放入其子类。
一个PdfFile可以赋值给File,但File不能赋值给PdfFile。因为不一定所有File都是PdfFile。所以< ? extends T >.add(T)是不对的。不能把T放到其子类里。
- 使用方法:
- 想要使用specification,被查询的对象的repository要继承JpaSpecificationExecutor< 该类 >。如,要查询paper,则paperRepository要继承JpaSpecificationExecutor< Paper >。
- 在service中进行查询。构建一个查询构造器Specification。specification译为规范、说明书。我们只需要写好Specification,然后传到Repository的方法中,仓库就会按照传入的的查询条件进行查询。
Specification< Paper > specification = new Specification< Paper >() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder criteriaBuilder) {.... return predicate}
}
补充:什么是匿名内部类?JAVA匿名内部类(Anonymous Classes)
Specification< Paper > specification = new Specification< Paper >() {…},声明一个对象的时候,直接写在{…}里面的内容,就是对Specification接口的一个实例化。这个匿名类只会被用到一次。在这里,我们在这个匿名类中实例化了Specification接口,并重写了Specification接口的toPredicate方法。(接口本身是不能实例化的)
- 构造specification的关键是重写toPredicate方法。这个方法返回了一个Predicate,它是单独每一条查询条件的详细描述,specification会根据这些查询条件在Repository中进行查询。而Predicate可以由CriteriaBuilder来生成。
正着说一遍。在toPredicate方法中,我们在设定一个查询条件时,用CriteriaBuilder来生成查询条件Predicate,将查询条件Predicate返回给查询构造器specification,再将specification传给repository中的方法,repository就知道怎么查了。 - 如果在查Paper的时候需要用到其他表的字段怎么办?root可以进行join操作。本来root在声明的时候是root< Paper >,现在需要用到category的id作为限制条件查paper:
Join<Paper, Category> joinCategory = root.join("categorySet");
// categorySet是Paper中的一个属性
Predicate p = criteriaBuilder.equal(joinCategory.get("id"), categoryNumber)
// joinCategory.get拿到的就是Category的字段了。
注意,join并没有实现联表查询。它只是在查询paper时,为了用其他实体的属性来约束paper的查询结果。
- 优势:
优势在于剥离了查询的“方法”和其中的查询“条件”:
– 定义查询条件时,只需要单独维护、测试这一个条件即可
– 实际查询时,可以把现有的查询条件灵活组合
参考:
SpringDataJPA之Specification复杂查询
SpringDataJPA多表联合查询
Spring Data JPA进阶(三):Specification查询
JPA重写Specification的toPredicate多条件查询
Specification接口里的toPredicate(Root root, CriteriaQuery query, CriteriaBuilder cb)
Pageable pageable = PageRequest.of(page, limit);
@NamedEntityGraph
https://blog.csdn.net/ahilll/article/details/83107982?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
https://blog.csdn.net/dalangzhonghangxing/article/details/56680629
https://blog.csdn.net/handawei_5/article/details/84094489
https://blog.csdn.net/github_39602765/article/details/89053614?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=1619614335329_37708&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
https://www.codetd.com/article/7366854
四、其他注解
-
@Autowired
它可以对类成员变量、方法及构造函数进行标注,完成自动装配的工作。 通过 @Autowired的使用来消除 set ,get方法。
@Autowired用法详解
使用@Autowired注解警告Field injection is not recommended
依赖注入有三种方式:
变量(filed)注入(不推荐)
构造器注入
set方法注入 -
@Component
@Component注解的含义
一旦使用关于Spring的注解出现在类里,例如我在实现类中用到了@Autowired注解,被注解的这个类是从Spring容器中取出来的,那调用的实现类也需要被Spring容器管理,加上@Component
-
@controller 控制器(注入服务)
用于标注控制层,相当于struts中的action层 -
@service 服务(注入dao)
用于标注服务层,主要用来进行业务的逻辑处理 -
@repository(实现dao访问)
用于标注数据访问层,也可以说用于标注数据访问组件,即DAO组件. -
@component (把普通pojo实例化到spring容器中,相当于配置文件中的 )
泛指各种组件,就是说当我们的类不属于各种归类的时候(不属于@Controller、@Services等的时候),我们就可以使用@Component来标注这个类。
JWT 身份验证
HttpServletRequest request
String jwt = jwtTokenUtil.getJWTFromRequest(request);
User user = userService.getUserByJwt(jwt);

















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









