







之前看视频学习的时候听到老师说了雪花算法这个名词但是老师没有讲,自己在网上自学了一下。写篇博客记录一下,本文参考https://juejin.cn/post/7082669476658806792
雪花算法总体描述
目的:雪花算法的目的是为给每条记录赋予一个独特的id,保证id的全局唯一性。前文是以数据库分库分表来介绍的,可以确保数据库中每一条记录都有一个独一无二的id。
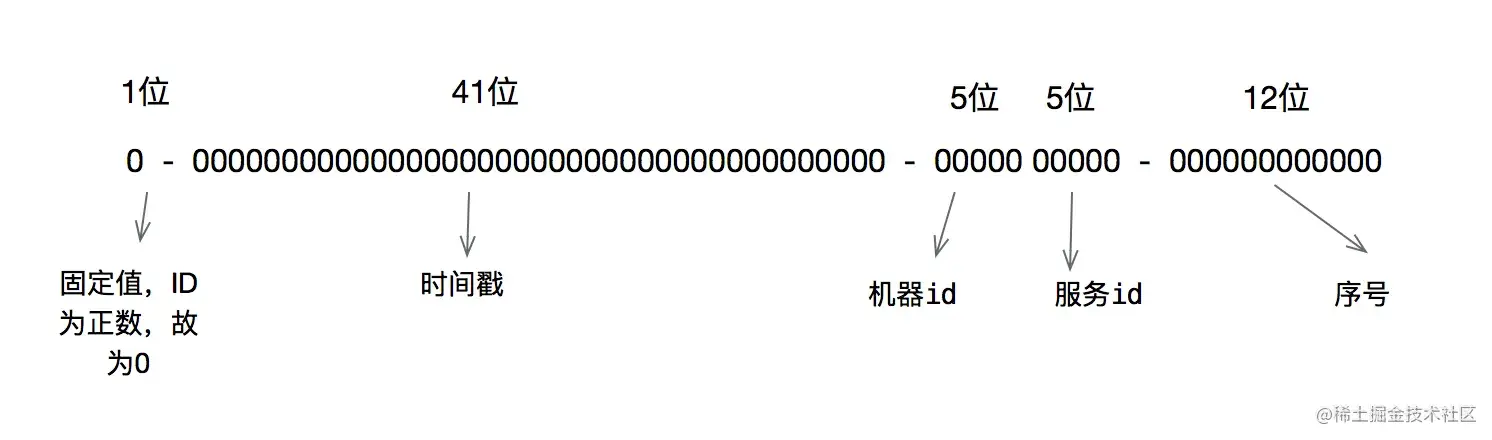
算法流程:雪花算法最终会生成一个64位的id,也就是8个字节可以用long类型的变量来存储。雪花算法生成64位id,由标志位(1位)、时间戳(41位)、数据中心id(机器id)(5位)、工作id(服务id)(5位)、序列号(12位)组成 。标志位必须为0,因为如果标志位为1的话,id就是负数了。时间戳不是当前currentTimeMillis的毫秒时间戳,而是当前currentTimeMillis减去起始时间戳的时间。同时在计算id是该时间戳要左移22位,给数据中心id、工作id、序列号腾出位置。但是上文在计算id时直接将时间戳左移22位,并没有对标志位进行处理,关于为什么不用管标志位我还要查阅一下资料。就很简单了,41位的毫秒级时间戳,2^41/(1000606024365)=69,大概可以使用69年。5位 datacenterId 和5位 workerId联合起来最多可以部署2^10=1024台机器。最后12位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成2^12=4096个不重复 id。
可以将雪花算法作为一个单独的服务进行部署,然后需要全局唯一 id 的系统,请求雪花算法服务获取 id 即可。
雪花算法的优缺点:
优点:
高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
不依赖第三方库或者中间件。
算法简单,在内存中进行,效率高。
缺点:
依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
雪花算法实现
public class SnowflakeIdGenerator {
// 初始时间戳(纪年),可用雪花算法服务上线时间戳的值
// 1649059688068:2022-04-04 16:08:08
private static final long INIT_EPOCH = 1649059688068L;
// 记录最后使用的毫秒时间戳,主要用于判断是否同一毫秒,以及用于服务器时钟回拨判断
private long lastTimeMillis = -1L;
// dataCenterId占用的位数
private static final long DATA_CENTER_ID_BITS = 5L;
// dataCenterId占用5个比特位,最大值31
// 0000000000000000000000000000000000000000000000000000000000011111
private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);
// datacenterId
private long datacenterId;
// workId占用的位数
private static final long WORKER_ID_BITS = 5L;
// workId占用5个比特位,最大值31
// 0000000000000000000000000000000000000000000000000000000000011111
private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
// workId
private long workerId;
// 最后12位,代表每毫秒内可产生最大序列号,即 2^12 - 1 = 4095
private static final long SEQUENCE_BITS = 12L;
// 掩码(最低12位为1,高位都为0),主要用于与自增后的序列号进行位与,如果值为0,则代表自增后的序列号超过了4095
// 0000000000000000000000000000000000000000000000000000111111111111
private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);
// 同一毫秒内的最新序号,最大值可为 2^12 - 1 = 4095
private long sequence;
// workId位需要左移的位数 12
private static final long WORK_ID_SHIFT = SEQUENCE_BITS;
// dataCenterId位需要左移的位数 12+5
private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;
// 时间戳需要左移的位数 12+5+5
private static final long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;
public SnowflakeIdGenerator(long datacenterId, long workerId) {
// 检查datacenterId的合法值
if (datacenterId < 0 || datacenterId > MAX_DATA_CENTER_ID) {
throw new IllegalArgumentException(
String.format("datacenterId值必须大于0并且小于%d", MAX_DATA_CENTER_ID));
}
// 检查workId的合法值
if (workerId < 0 || workerId > MAX_WORKER_ID) {
throw new IllegalArgumentException(String.format("workId值必须大于0并且小于%d", MAX_WORKER_ID));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 通过雪花算法生成下一个id,注意这里使用synchronized同步
*
* @return 唯一id
*/
public synchronized long nextId() {
long currentTimeMillis = System.currentTimeMillis();
// 当前时间小于上一次生成id使用的时间,可能出现服务器时钟回拨问题
if (currentTimeMillis < lastTimeMillis) {
throw new RuntimeException(
String.format("可能出现服务器时钟回拨问题,请检查服务器时间。当前服务器时间戳:%d,上一次使用时间戳:%d", currentTimeMillis,
lastTimeMillis));
}
if (currentTimeMillis == lastTimeMillis) { // 还是在同一毫秒内,则将序列号递增1,序列号最大值为4095
// 序列号的最大值是4095,使用掩码(最低12位为1,高位都为0)进行位与运行后如果值为0,则自增后的序列号超过了4095
// 那么就使用新的时间戳
sequence = (sequence + 1) & SEQUENCE_MASK;
if (sequence == 0) {
currentTimeMillis = tilNextMillis(lastTimeMillis);
}
} else { // 不在同一毫秒内,则序列号重新从0开始,序列号最大值为4095
sequence = 0;
}
// 记录最后一次使用的毫秒时间戳
lastTimeMillis = currentTimeMillis;
// 核心算法,将不同部分的数值移动到指定的位置,然后进行或运行
return ((currentTimeMillis - INIT_EPOCH) << TIMESTAMP_SHIFT) | (datacenterId
<< DATA_CENTER_ID_SHIFT) | (workerId << WORK_ID_SHIFT) | sequence;
}
/**
* 获取指定时间戳的接下来的时间戳,也可以说是下一毫秒
*
* @param lastTimeMillis 指定毫秒时间戳
* @return 时间戳
*/
private long tilNextMillis(long lastTimeMillis) {
long currentTimeMillis = System.currentTimeMillis();
while (currentTimeMillis <= lastTimeMillis) {
currentTimeMillis = System.currentTimeMillis();
}
return currentTimeMillis;
}
}















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









