







1、更新apt
·使用Ctrl+Alt+T,唤出终端
代码:
sudo apt-get update 结果截图:
代码:
sudo apt-get install vim结果截图:
2、配置无秘登录ssh
安装
ssh
程序,输入如下命令
sudo apt install ssh截图:

ssh
安装完成后,生成密钥,输入如下命令:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa截图:

把生成的公钥加到可信任的文件中去,输入如下命令:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysssh localhost截图:
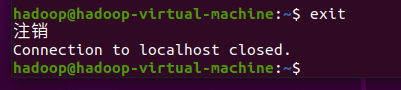
退出
ssh
连接,输入如下命令:
exit截图:
3、Java环境安装
卸载原版
jdk
,输入如下命令:
sudo apt remove openjdk*将jbk的jar包复制到主目录

解压
jdk
压缩包,输入如下命令 :


tar -xvf jdk-8u162-linux-x64.tar.gz
解压完成后,移动解压后的文件夹到
/usr/local
目录下,并改名为
jdk
,输入如下命令:
sudo mv jdk1.8.0_162 /usr/local/jdk
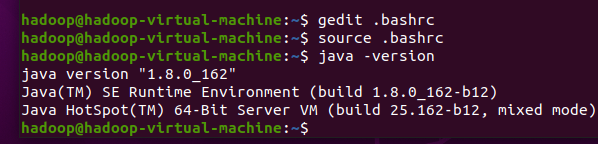
用户环境变量,使用gedit打开.bashrc文件, 输入如下命令:
gedit .bashrc弹出如下界面:

在文件末尾加入下面的两行文字 (注意格式):
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
然后使用
Ctrl + s
保存修改,直接使用界面上的小叉叉关闭这个界面,输入:
source .bashrc
测试是否安装
java
成功,使用如下命令:
java -version截图:
4、hadoop安装
将hadoop安装包复制到主目录

解压
hadoop
文件,输入如下命令:
tar -xvf hadoop-2.7.3.tar.gz
移动解压后的
Hadoop
到
/usr/local
目录下,并重命名为
hadoop:
sudo mv hadoop-2.7.3 /usr/local/hadoop
修改环境变量,使用
gedit
编辑
.bashrc
,输入如下命令 :
gedit .bashrc
在文件末尾加上如下两行命令:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinCtrl+s,然后点击右上角的小叉叉,关闭文件,输入:
source .bashrc截图:
5、配置hadoop
cd /usr/local/hadoop/etc/hadoop
编辑
core-site.xml
文件,这个文件主要是对各种常用配置进行设置,输入如下命令 :

sudo gedit core-site.xml
弹出如下界面 :
清空文件内容,替换成如下:
<configuration> <!--- global properties --> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop</value> <description>A base for other temporary directories.</description> </property> <!-- file system properties --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost/</value> <description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.</description> </property> </configuration>
点击
Ctrl+s
,然后点击右上角的小叉叉关掉界面
编辑
hdfs-site.xml
文件,这个文件是用作配置
hdfs
的各项属性的,输入如下命令:
sudo gedit hdfs-site.xml
然后把下面的内容整体替换掉当前文件的内容:
点击
Ctrl+s
,然后点击右上角的小叉叉关掉界面
编辑
mapred-site.xml
文件,这个文件主要是对
mapreduce
进行配置,输入如下命令 :
sudo gedit mapred-site.xml
原文件为空,然后把下面的内容拷贝到文件中
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn. </description> </property> </configuration>点击Ctrl+s,然后点击右上角的小叉叉关掉界面
编辑
yarn-site.xml
文件,这个文件主要是对
yarn
进行设置,输入如下命令
sudo gedit yarn-site.xml
把如下内容替换掉文件中的内容 :


<configuration> <property> <description>The hostname of the RM.</description> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> <property> <description>A comma separated list of services where service name should only contain a-zA-Z0-9_ and can not start with numbers</description> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>点击Ctrl+s,然后点击右上角的小叉叉关掉界面
编辑
hadoop-env.sh
文件,设置
JAVA_HOME
环境变量,输入如下命令 :
sudo gedit hadoop-env.sh
然后使用
Ctrl+F
键,调出查找界面,输入
JAVA_HOME
,我们需要修改的就是红色方框里面
修改后:
点击
Ctrl+s
保存,然后点击右上角小叉叉关闭界面
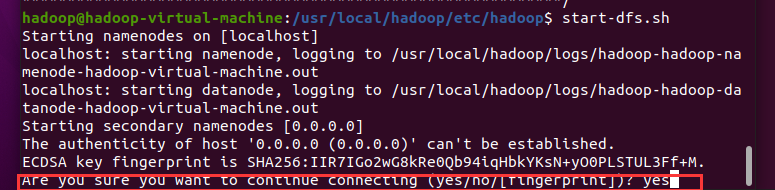
格式化
hadoop
系统
sudo mkdir /opt/hadoopsudo chmod -R a+w /opt/hadoophdfs namenode -format截图:
启动
hdfs
,输入如下命令:
cd ~start-dfs.sh第一次启动需要确定输入yes
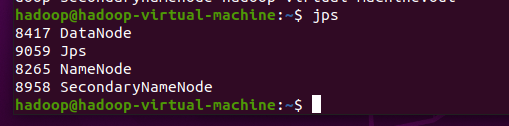
检查
hdfs
系统启动成功与否输入
jps
命令,如果有如下图所示的三个进程表示
hdfs
运行正常,否则表示有 问题。
jps
截图:
启动
yarn
,输入如下命令 :
start-yarn.sh截图:
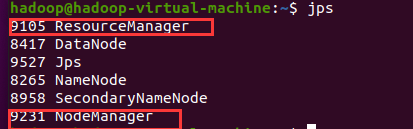
检查
yarn
系统启动成功与否输入
jps
命令,如果有如下图所示的两个进程表示
yarn
运行正常,否则表示有问题。
jps截图:
停止
hadoop
集群命令 :
stop-dfs.shstop-yarn.sh搭建结束。















 3672
3672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









