






Hadoop3.0+Zookeeper+Kafka+Flume完全分布式搭建
文章目录
一、 模板虚机机Hadoop100准备
1.创建虚拟机,按照提示一步步操作即可
2.联网
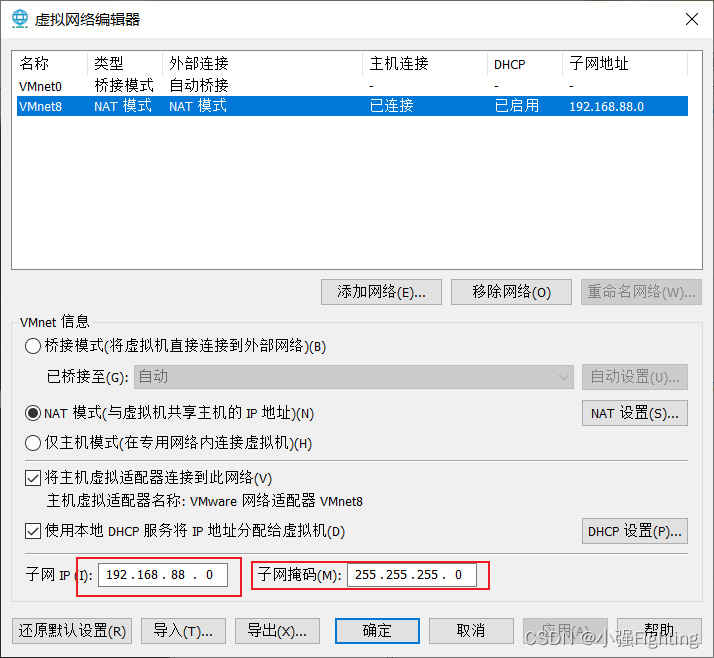
(1)虚拟网络设置–>DHCP设置,即可进行IP地址的设置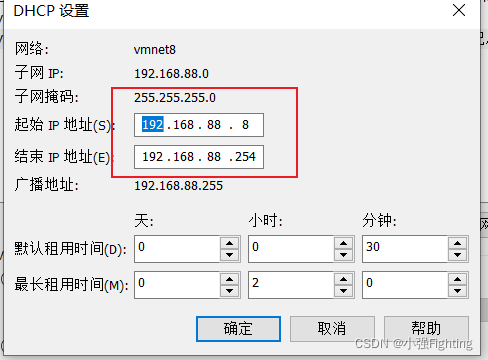
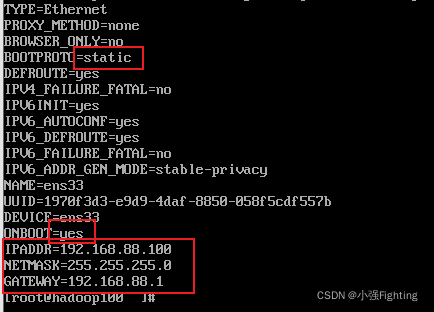
(2)修改配置文件

按 i 进行编辑,先按esc,再:wq即可保存退出(:q! 不保存退出)
将BOOTPROTO=DHCP改为static,ONBOOT=yes,添加IPADDR(IP地址) GATWAY(网关) NETMASK(子网掩码)
(3)修改文件resolve.conf
在文件中添加:nameserver 114.114.114.114

(4)关闭防火墙
查看防火墙状态:systemctl status firewalld
关闭防火墙:systemctl stop firewalld(暂时关闭)
systemctl disable firewalld(永久性关闭,需要重启reboot)
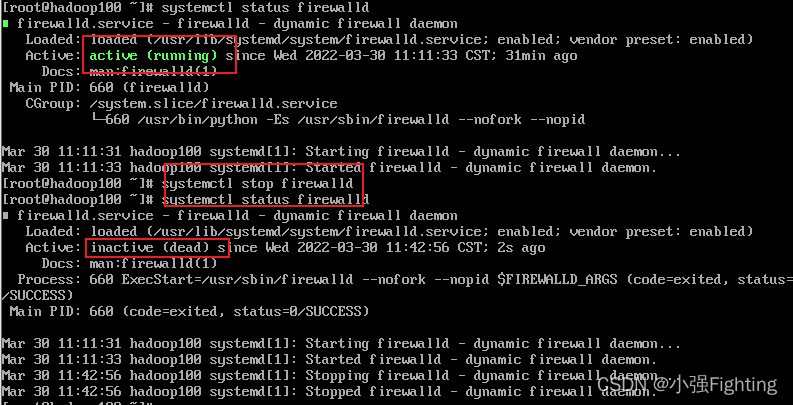 再次查看防火墙状态,dead已关闭
再次查看防火墙状态,dead已关闭
(5)重启网络服务
命令:service network restart
ping www.baidu.com

ping一下,发现可以ping通,CTRL+C结束
3.修改主机名和hosts文件
(1)修改主机名
修改主机名:vi /etc/hostname

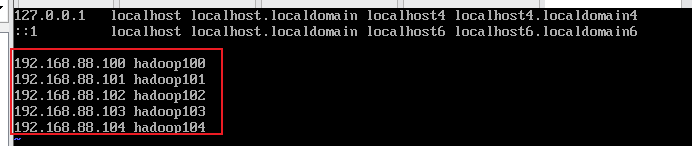
(2)配置克隆主机名称映射hosts文件
命令:vi /etc/hosts, 添加IP地址和主机名称
至此,模板虚拟机Hadoop100准备完毕
二、完全分布式搭建
1.克隆三台虚拟机
利用模板虚拟机Hadoop100,克隆三台虚拟机:Hadoop102,Hadoop103,Hadoop104
注意:克隆时,要先关闭模板Hadoop100
2.修改克隆机IP地址,一下以Hadoop102为例
(1)修改克隆虚拟机的静态IP地址和主机名
命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33
vi /etc/hosts
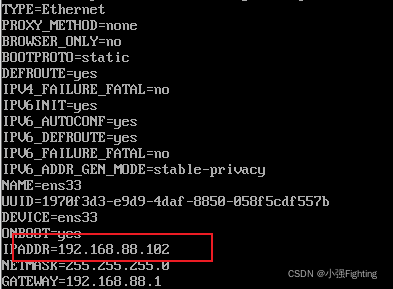
修改IP地址

修改主机名,重启reboot
进行测试,看是否可以ping通外网
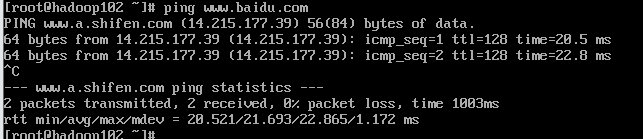
同理,修改克隆虚拟机Hadoop103,Hadoop104
3.用Xshell,Xftp远程访问工具
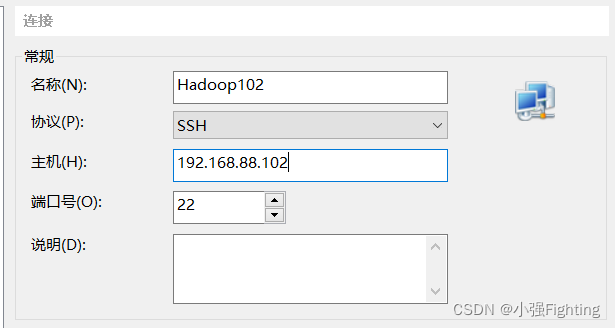
Xshell配置,新建会话框,主机为连接虚拟机的IP地址,连接,输入用户名和密码即可。
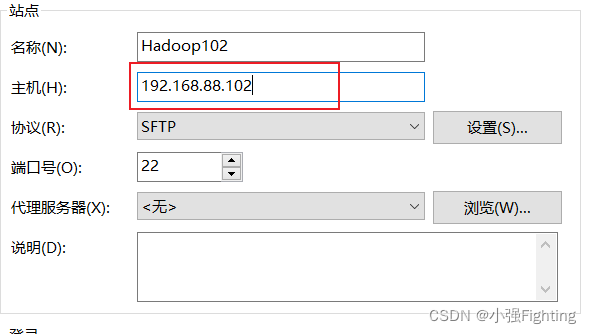
Xftp配置,同Xshell配置一样
4.JDK和Hadoop安装
(1)创建文件夹,命令:
mkdir /opt/module (安装包解压目录)
mkdir /opt/software (安装包目录)
(2)通过xftp上传文件并解压

文件上传成功
解压文件,命令:
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module
(3)配置环境变量
一般都是在/etc/profile中添加环境配置,但此处我们自己创建一个文件my_env.sh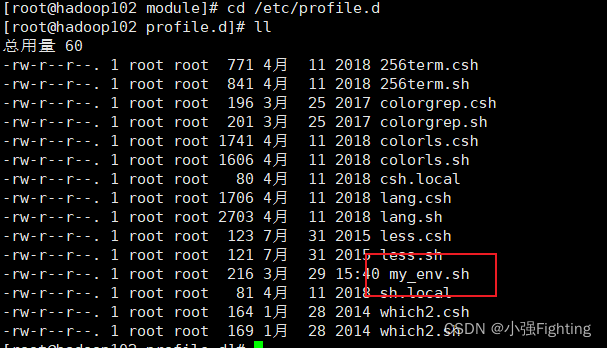
切换目录
cd /etc/profile.d
创建文件夹
vi my_env.sh
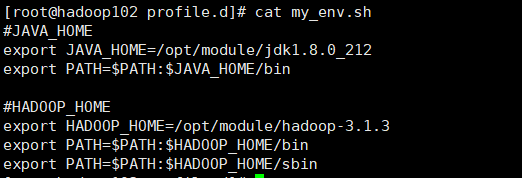
添加配置
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
刷新配置,使环境变量生效,命令:
source /etc/profile
输入java -version,若能正确显示Java版本信息,表示配置成功;输入had,按下tab键,若hadoop能补齐,表示hadoop配置成功

5.编写集群分发脚本xsync
(1)scp安全拷贝
scp可以实现服务器与服务器之间的数据拷贝
案例实操:
前提是:在Hadoop102,Hadoop103,Hadoop104上都已经创建好/opt/module /opt/software目录
在hadoop102上,将Hadoop102中/opt/module/jdk1.8.0_212目录拷贝到Hadoop103上,命令:
scp -r /opt/module/jdk1.8.0_212 root@hadoop103:/opt/module/
scp -r /opt/module/hadoop-3.1.3 root@hadoop103:/opt/module
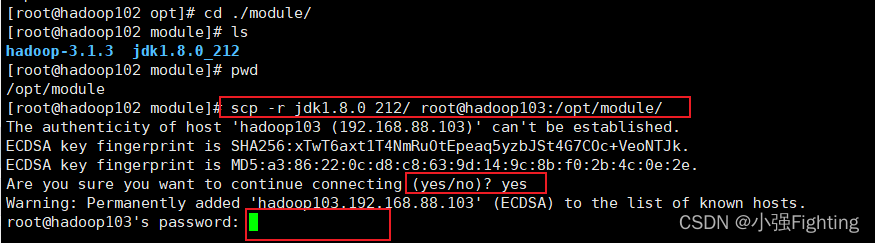
在hadoop103的文件目录下进行查看

同理,拷贝到Hadoop104上,在hadoop104上拉取Hadoop102的文件
scp -r root@hadoop102:/opt/module/* ./
将文件拉取到当前目录 /opt/module ,注意要切换目录
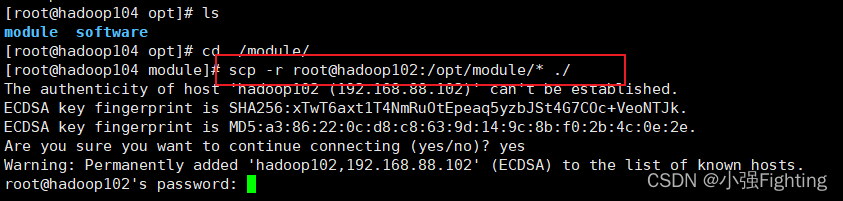
查看文件

(2)rsync远程同步工具
rsync主要用于备份和镜像,具有连接速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:rsync文件复制要比scp的速度快,rsync只对差异文件做更新,scp是把所有文件都复制过去。
同步hadoop102中的/opt/module/hadoop-3.1.3到hadoop103
rsync -av hadoop-3.1.3/root@hadoop103:/opt/module/hadoop-3.1.3/
(3)xsync集群分发脚本
在/home/bin目录下创建xsync
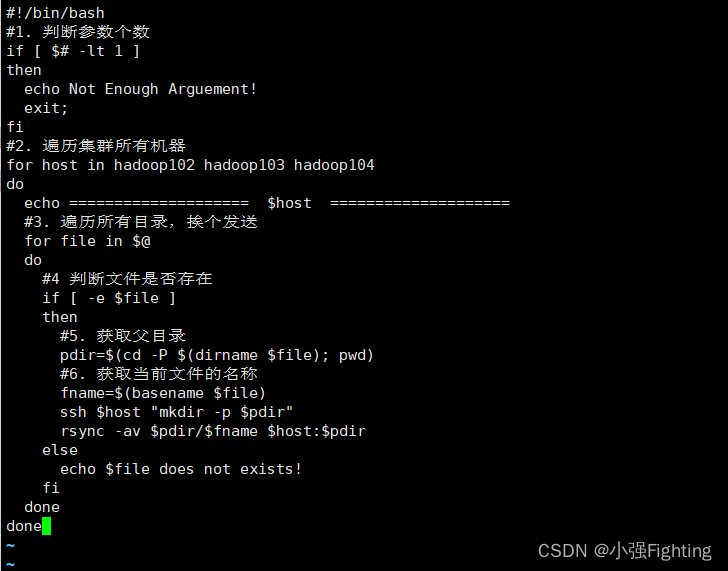
该文件总编写代码如下:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
更改权限
chmod 777 xsync
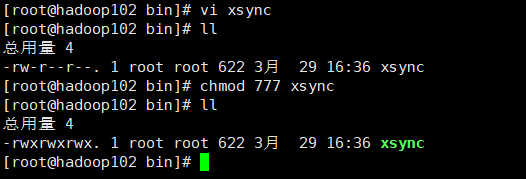
同步当前bin/目录
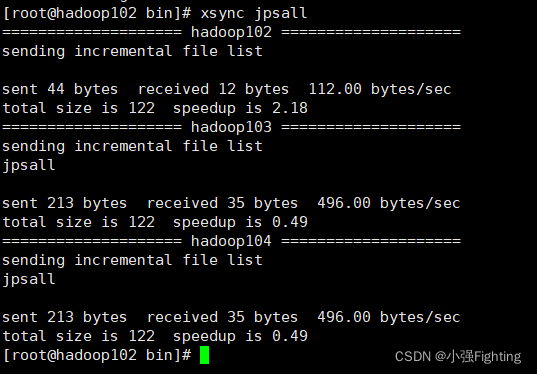
xsync bin/
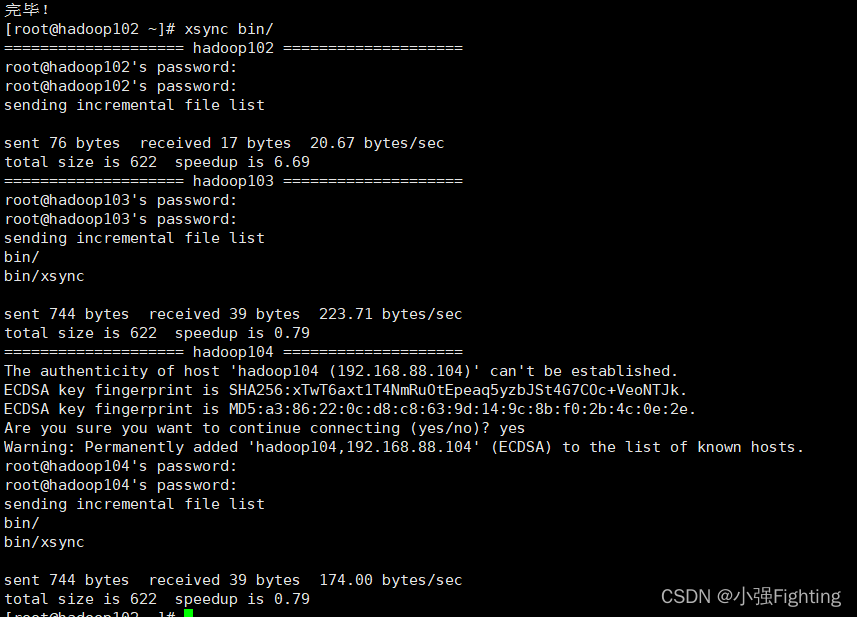
hadoop103,hadoop104上进行查看

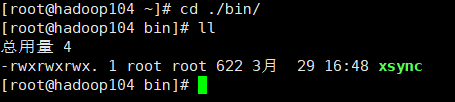
分发环境变量
./xsync /etc/profile.d/my_env.sh
hadoop103上进行查看
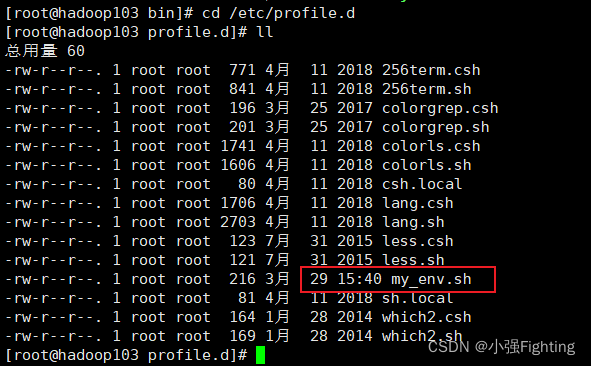
6.SSH无密登录配置
说明:这里面只配置了hadoop102、hadoop103到其他主机的无密登录;因为hadoop102未外配置的是NameNode,hadoop103配置的是ResourceManager,都要求对其他节点无密访问。
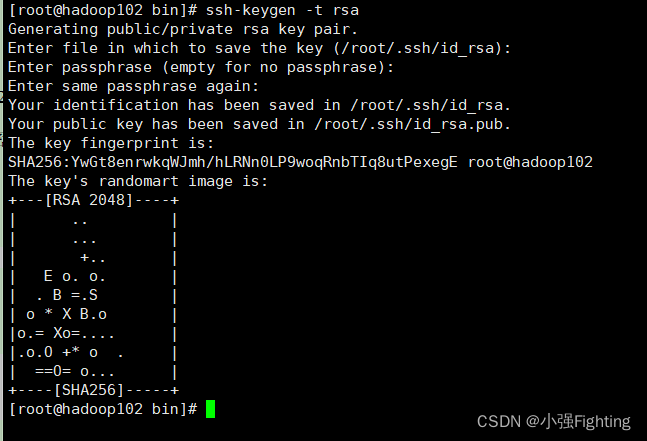
hadoop102上生成公钥和私钥:
ssh-keygen -t rsa
输入命令,三次回车即可,就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
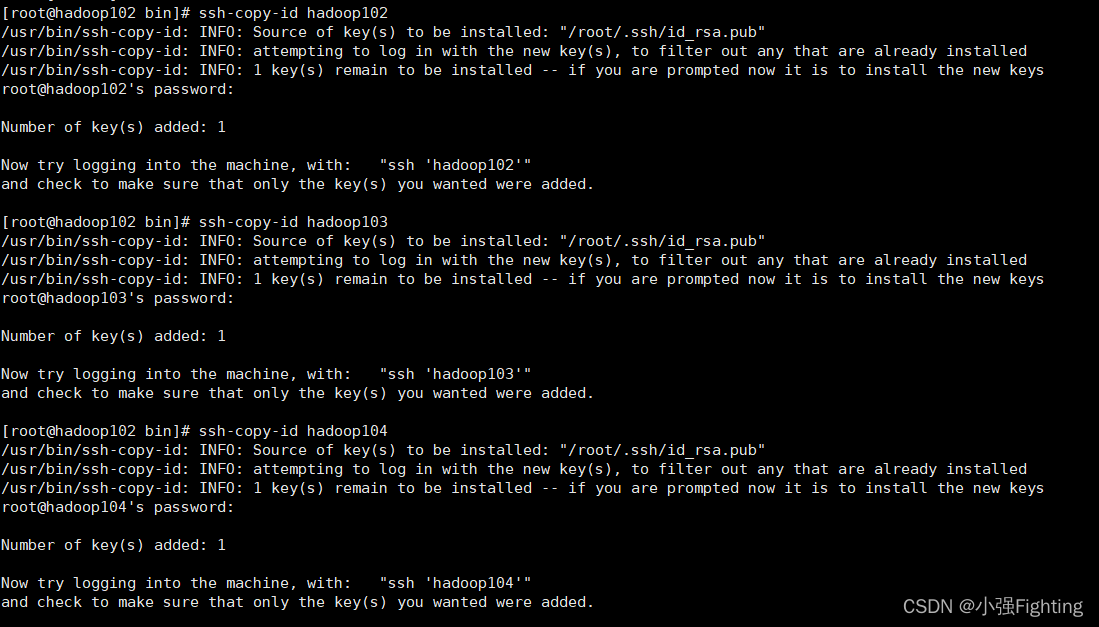
将hadoop102公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
同理,hadoop103上生成公钥和私钥:
ssh-keygen -t rsa
将hadoop103公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
7.集群配置
(1)集群部署规划
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
NameNode和SecondaryNameNode不要安装在同一台服务器上
ResourceManager很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上
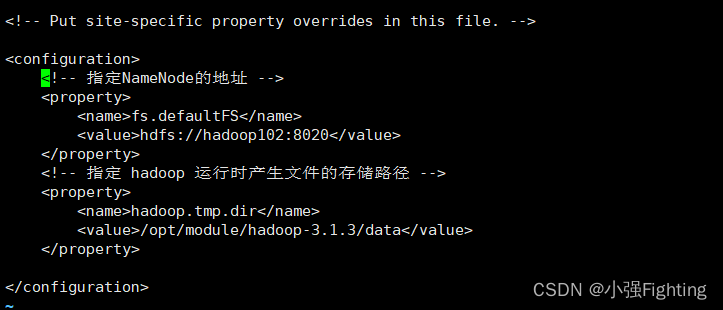
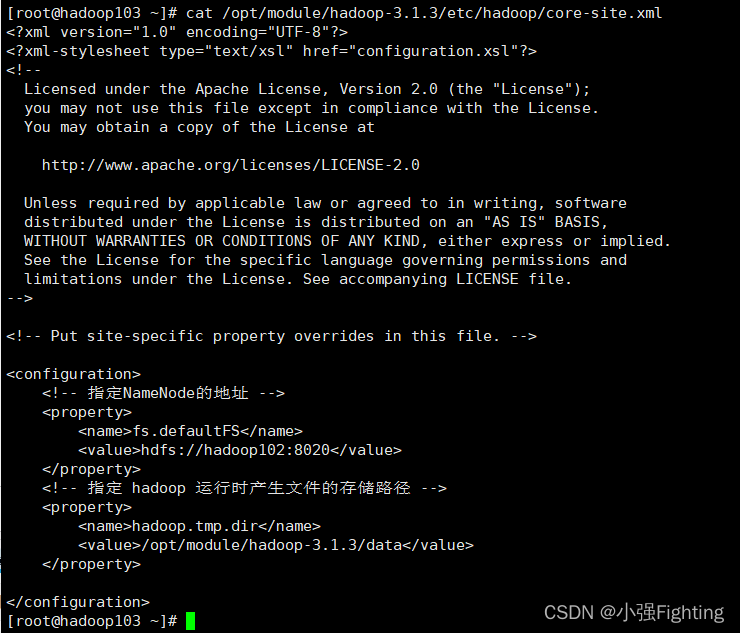
(2)配置核心文件core-site.xml
切换目录:cd /opt/module/hadoop-3.1.3/etc/hadoop
编辑文件:vi core-site.xml
添加如下内容
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
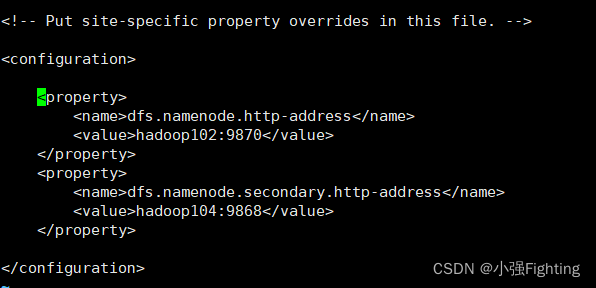
(3)HDFS配置文件hdfs-site.xml
vi hdfs-site.xml
添加如下内容
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
(4)YARN配置文件yarn-site.xml
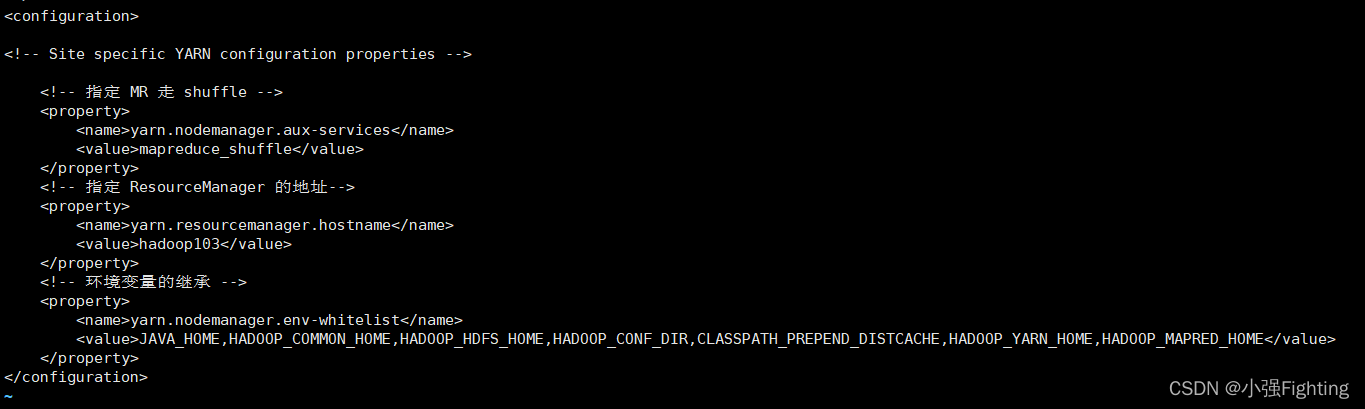
vi yarn-site.xml
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
(5)MapReduce配置文件mapred-site.xml
vi mapred-site.xml
添加内容如下
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

(5)在集群上分发配置好的Hadoop配置文件
xsync hadoop/
(6)在Hadoop103和Hadoop104上查看文件分发情况
8.群起集群
(1)配置workers
vi workers
在该文件中添加如下内容
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中那个不允许有空行。
同步所有节点配置文件
xsync workers
(2)启动集群
(1)如果集群式第一次动,需要在hadoop102节点格式化NameNode
注意:格式化NameNode,会产生新的集群id,导致Name Node和DataNode的集群id不一致,集群找不到以往数据。如果集群在运行中报错,需要重新格式化NameNode,一定要先停止NameNode和DataNode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。
hdfs namenode -formate
格式化成功后,会产生data和logs目录
(2)启动HDFS sbin/start-dfs.sh
报错
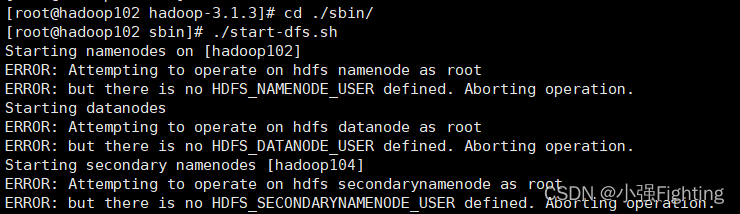
解决方法:将start-dfs.sh,stop-dfs.sh(在hadoop安装目录的sbin里)两个文件顶部添加以下参数
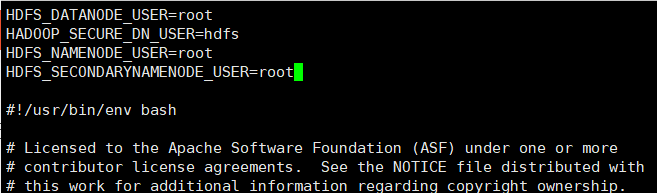
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
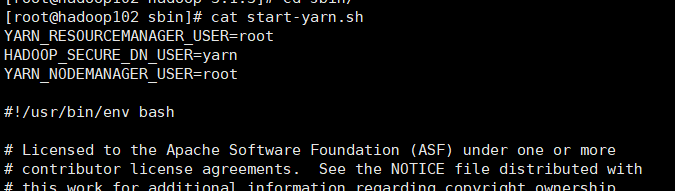
将start-yarn.sh,stop-yarn.sh(在hadoop安装目录的sbin里)两个文件顶部添加以下参数
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
再次启动HDFS

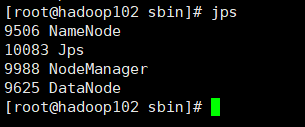
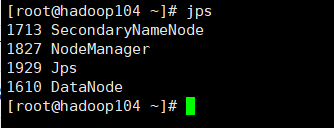
查看各节点的启动状态
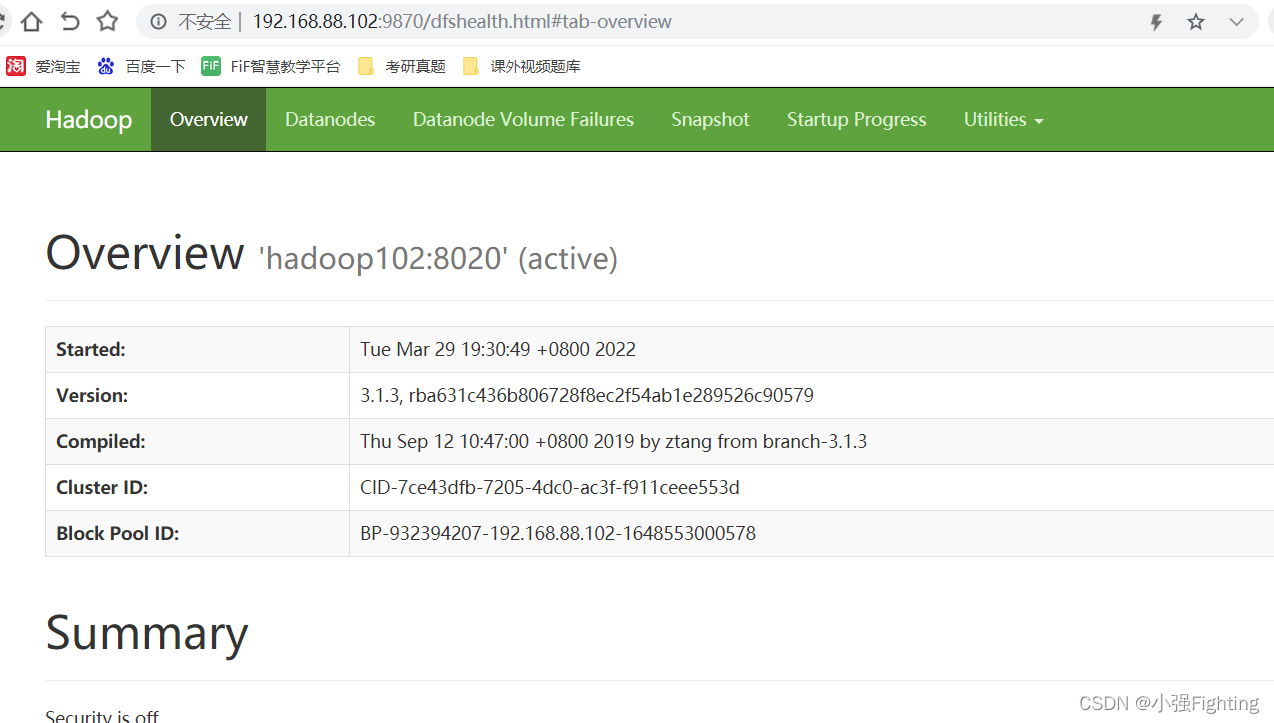
(3)web端查看HDFS的NameNode
浏览器中输入:192.168.88.102:9870
(4)在配置ResourceManager节点上Hadoop103启动YARN
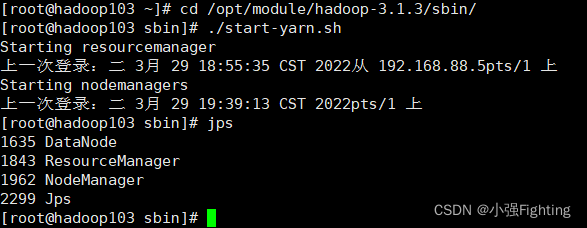
查看节点启动情况
(5)Web端查看YARN的ResoureManager
浏览器中输入:192.168.88.103:8088
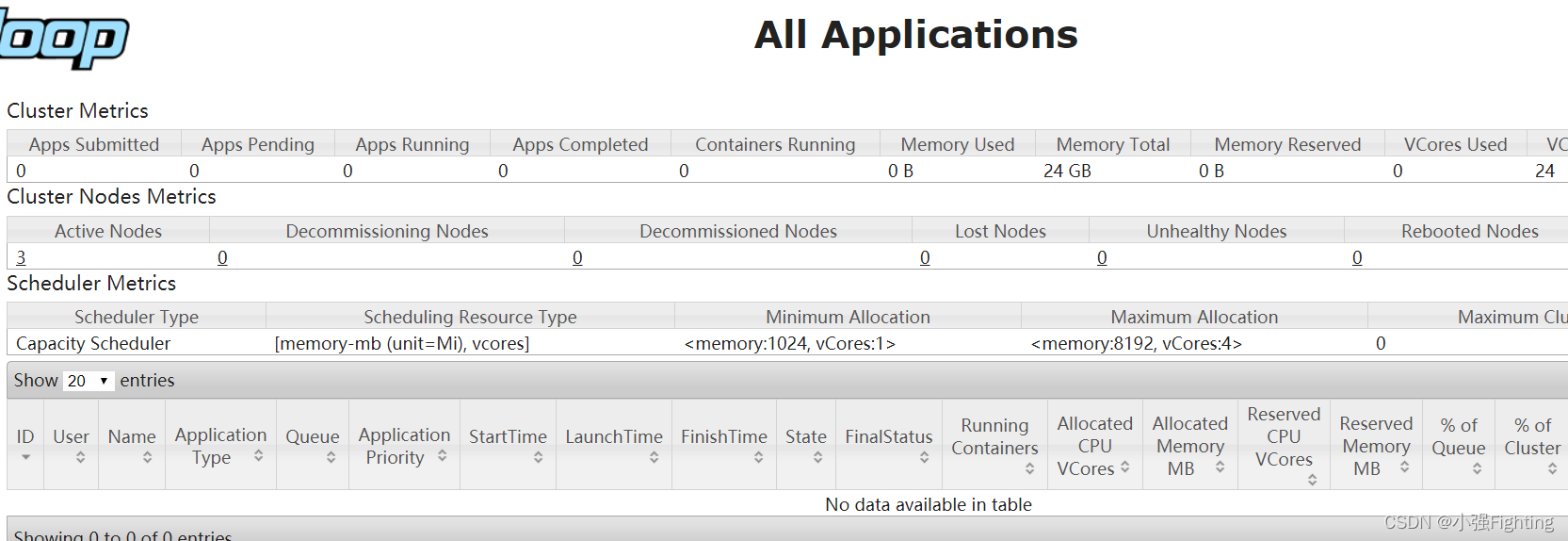
(6)节点启动失败,解决方法:
1.杀死每台机器上的进程
2.删除data和logs
3.格式化
4.启动
9.配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器,具体步骤如下:
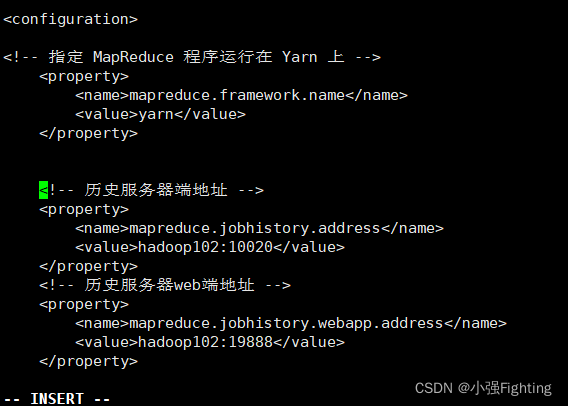
(1)配置mapred-site.xml
在该文件里面增加如下配置:
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
(2)分发配置
xsync mapred-site.xml
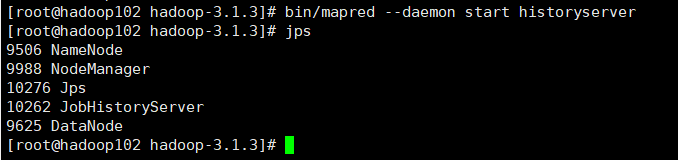
(3)在Hadoop102启动历史服务器
mapred --daemon start historyserver
(4)查看历史服务器是否启动jps
10.配置日志的聚集
日志聚集功能的好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager、ResourceManager和HistoryServer
(1)配置yarn-site.xml
在该文件里面增加如下配置:
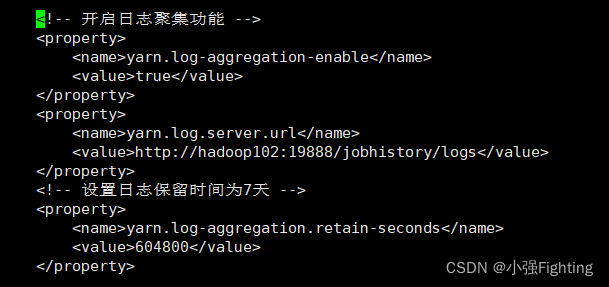
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
(2)分发配置
xsync yarn-site.xml
(3)关闭NodeManager、ResourceManager和HistoryServer
cd /opt/module/hadoop-3.1.3/sbin
./stop-yarn.sh
mapred --daemon stop historyserver
 (4)重启yarn
(4)重启yarn
start-yarn.sh
11.集群启动/停止方式总结
(1)各个模块分开启动
整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
(2)各个服务器组件逐一启动
分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
分别启动/停止YARN组件
yarn --daemon start/stop resourcemanager/nodemanager
12.编写Hadoop常用脚本
1.Hadoop集群启动脚本(HDFS YARN Historyserver):myhadoop.sh
(1)文件内容如下:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
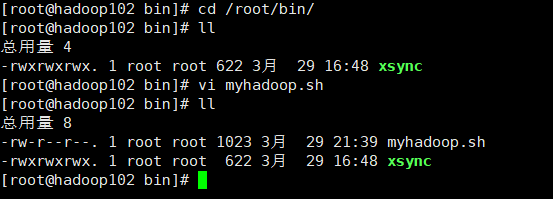
(2)chmod更改权限chmod 777 myhadoop.sh
(3)测试关闭集群 myhadoop.sh stop

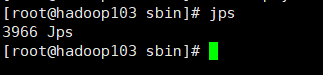
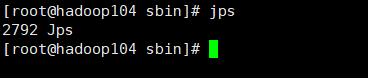
(4)查看各节点状态

(5)启动集群myhadoop.sh start
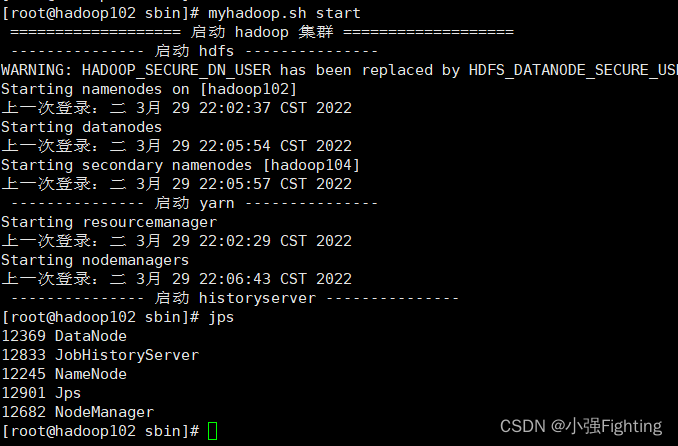
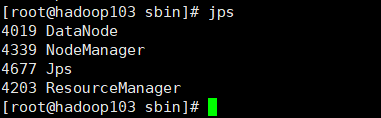
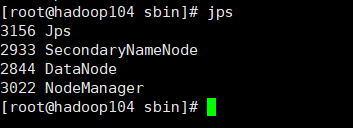
(6)查看节点启动情况
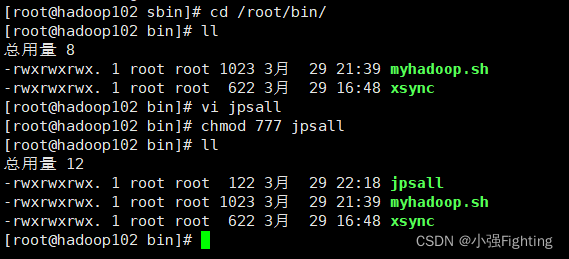
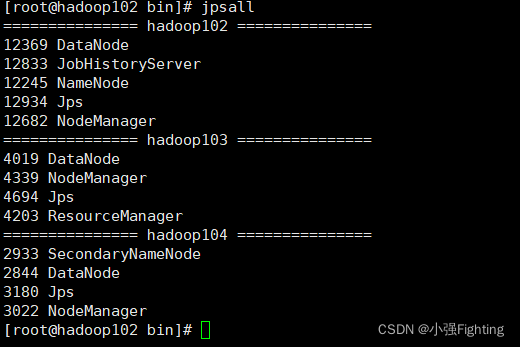
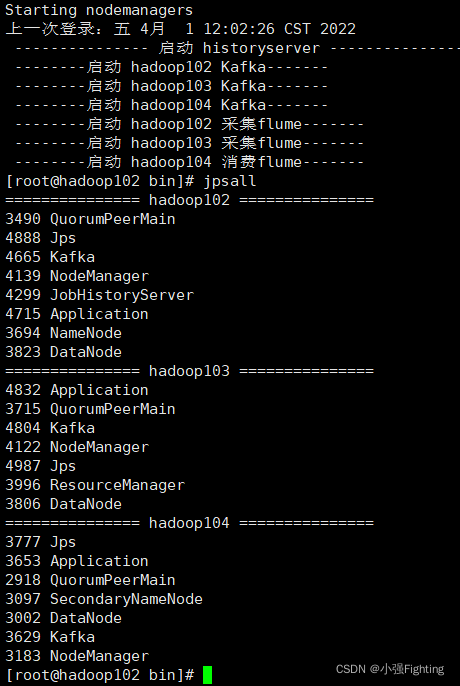
2. 查看三台服务器Java进程脚本: jpsall
(1)文件内容如下
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
(2)更改权限
3.分发bin目录,保证自定义脚本在三台机器上都可以使用
13.常用端口号说明
(1)常用端口号
| 端口名称 | hadoop 2.x | hadoop 3.x |
|---|---|---|
| NameNode内部通信端口 | 8020/9000 | 8020/9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
(2)常用的配置文件
hadoop3.x: core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml workers
hadoop2.x: core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml slaves
三、模拟数据
1.模拟数据
将application.yml、gmall2020-mock-log-2021-01-22.jar、path.json、logback.xml上传到hadoop102的/opt/module/applog目录下
(1)创建applog目录
mkdir /opt/module/applog
(2)上传文件application.yml到/opt/module/applog目录
查看文件上传情况
2.配置文件
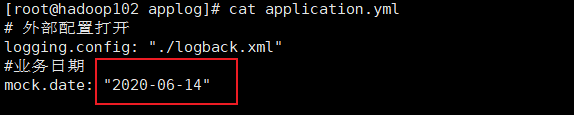
(1)application.yml文件vi application.yml
# 外部配置打开
# 外部配置打开
logging.config: "./logback.xml"
#业务日期 注意:并不是Linux系统生成日志的日期,而是生成数据中的时间
mock.date: "2020-06-14"
#模拟数据发送模式
#mock.type: "http"
#mock.type: "kafka"
mock.type: "log"
#http模式下,发送的地址
mock.url: "http://hdp1/applog"
#kafka模式下,发送的地址
mock:
kafka-server: "hdp1:9092,hdp2:9092,hdp3:9092"
kafka-topic: "ODS_BASE_LOG"
#启动次数
mock.startup.count: 200
#设备最大值
mock.max.mid: 500000
#会员最大值
mock.max.uid: 100
#商品最大值
mock.max.sku-id: 35
#页面平均访问时间
mock.page.during-time-ms: 20000
#错误概率 百分比
mock.error.rate: 3
#每条日志发送延迟 ms
mock.log.sleep: 10
#商品详情来源 用户查询,商品推广,智能推荐, 促销活动
mock.detail.source-type-rate: "40:25:15:20"
#领取购物券概率
mock.if_get_coupon_rate: 75
#购物券最大id
mock.max.coupon-id: 3
#搜索关键词
mock.search.keyword: "图书,小米,iphone11,电视,口红,ps5,苹果手机,小米盒子"
(2)path.json,该文件用来配置访问路径。根据需求,可以灵活配置用户点击路径。
[
{"path":["home","good_list","good_detail","cart","trade","payment"],"rate":20 },
{"path":["home","search","good_list","good_detail","login","good_detail","cart","trade","payment"],"rate":40 },
{"path":["home","mine","orders_unpaid","trade","payment"],"rate":10 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","trade","payment"],"rate":5 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","home"],"rate":5 },
{"path":["home","good_detail"],"rate":10 },
{"path":["home" ],"rate":10 }
]
(3)logback配置文件
可配置日志生成路径,修改内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="/opt/module/applog/log" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.atgugu.gmall2020.mock.log.util.LogUtil"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="error" >
<appender-ref ref="console" />
</root>
</configuration>
(3)生成日志
进入到/opt/module/applog路径,执行命令:
java -jar gmall2020-mock-log-2021-01-22.jar

查看生成的日志文件

查看生成的日志信息

2.集群日志生成脚本
在hadoop102的/home目录下创建bin目录,这样脚本可以在服务器的任何目录执行。
(1)在/home/bin目录下创建脚本lg.sh
vi lg.sh
(2)在脚本中编写如下内容:
#!/bin/bash
for i in hadoop102 hadoop103; do
echo "========== $i =========="
ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-01-22.jar >/dev/null 2>&1 &"
done
注意:/opt/module/applog/为jar包及配置文件所在路径
(3)修改脚本权限
chmod 777 lg.sh
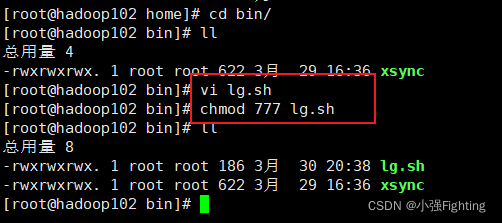
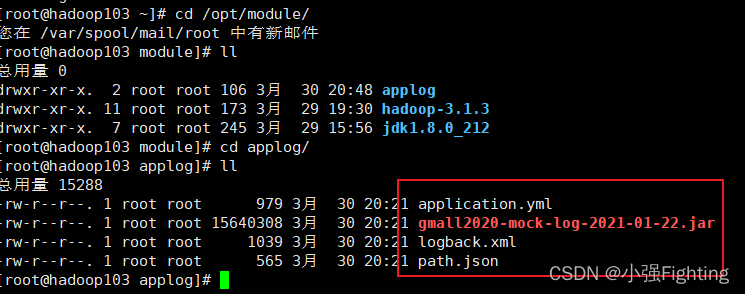
(4)删除hadoop102上的日志,rm -rf log
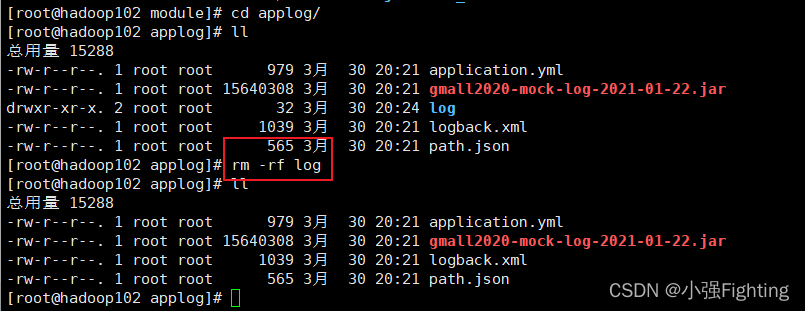
(5)applog进行同步xsync applog/
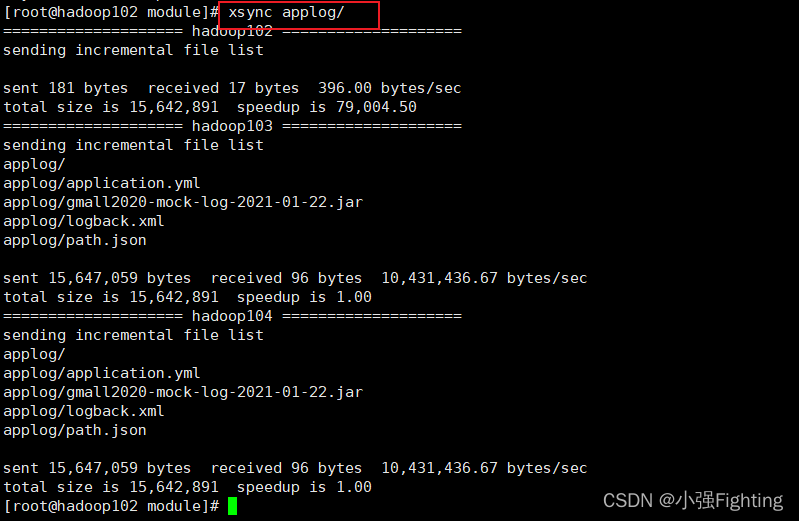
hadoop104上不需要,删除applog
hadoop103中进行文件查看
(6)执行lg.sh文件
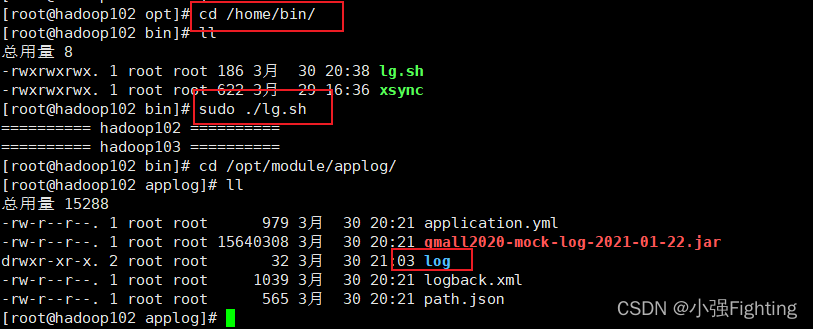
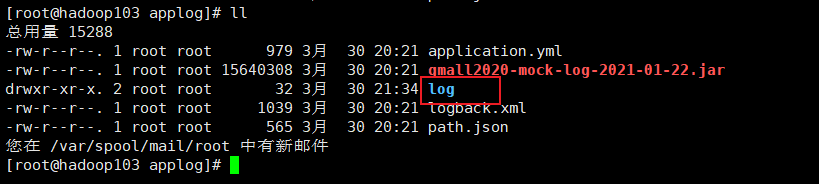
hadoop103上进行查看
四、数据采集
1.集群配置
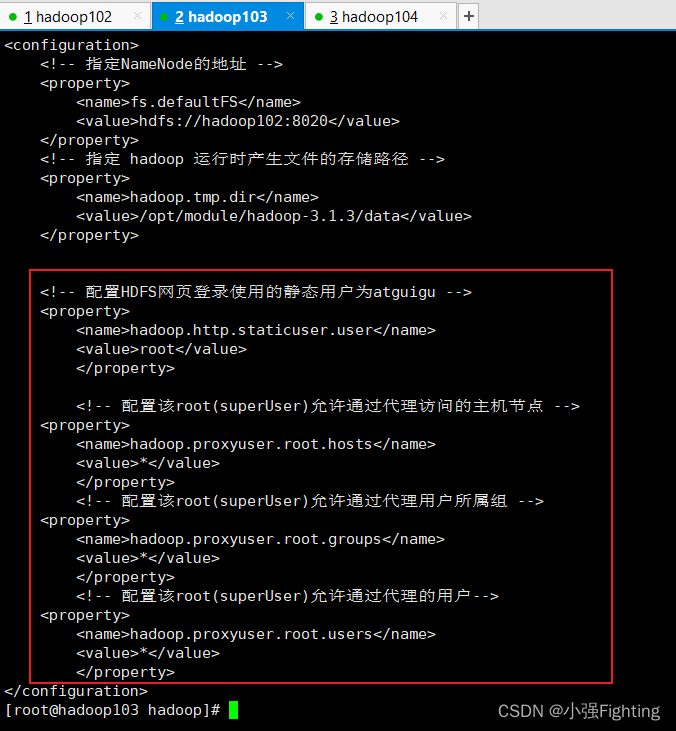
配置core-site.xml
添加如下内容:
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 配置该root(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
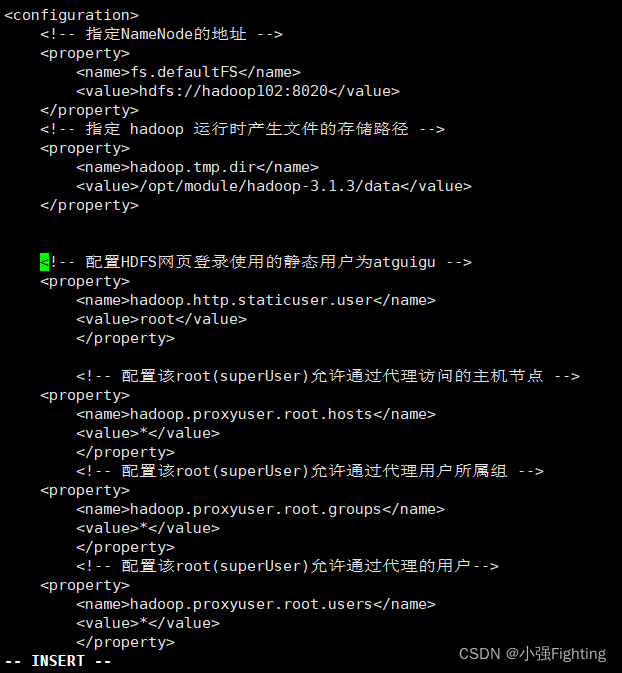
脚本分发xsync core-site.xml
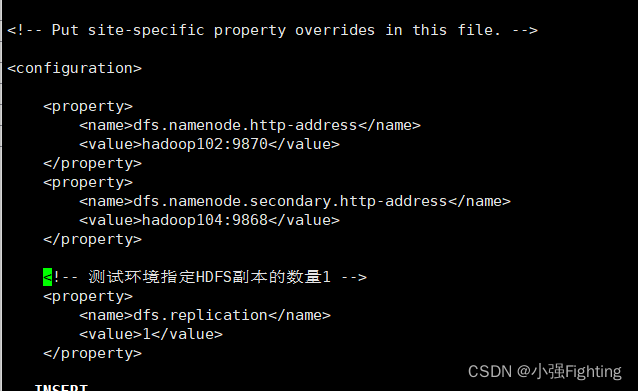
HDFS文件配置hdfs-xml.site
添加内容如下:
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
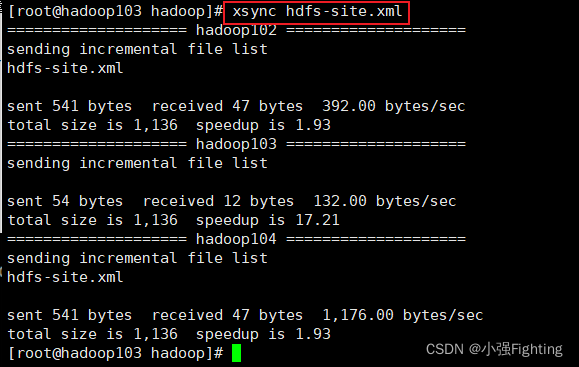
脚本分发xsync hdfs-site.xml
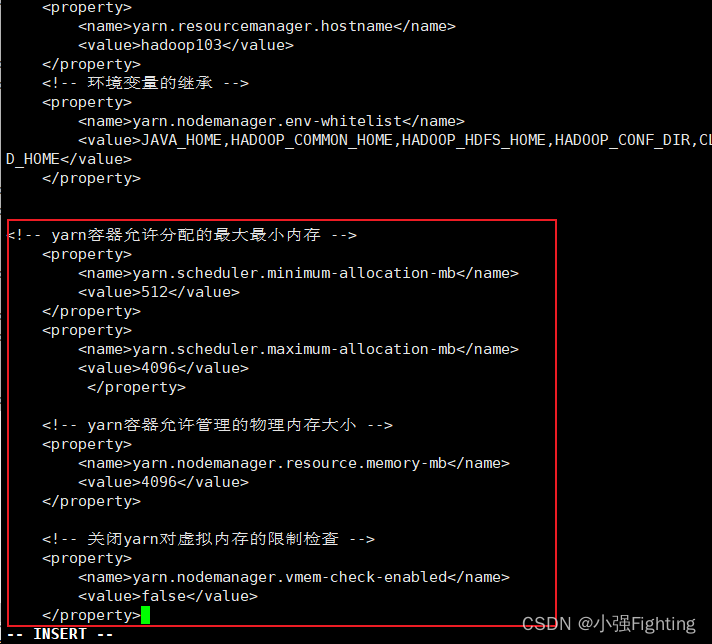
YARN配置yarn-site.xml
添加内容如下:
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
分发脚本xsync yarn-site.xml
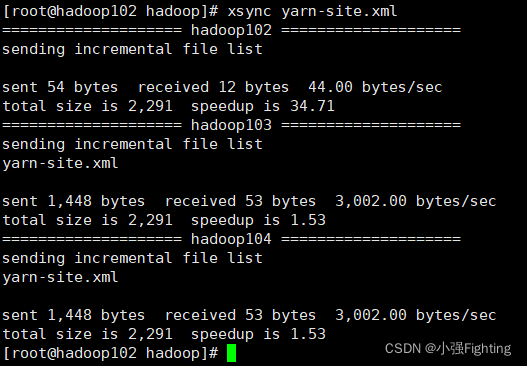
2.LZO压缩配置
(1)hadoop-lzo编译
hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。hadoop-lzo需依赖hadoop和lzo进行编译,
(2)将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-3.1.3/share/hadoop/common/
mv hadoop-lzo-0.4.20.jar /opt/module/hadoop-3.1.3/share/hadoop/common/
进入目录进行查看
(3)同步hadoop-lzo-0.4.20.jar到hadoop103、hadoop104
脚本分发xsync hadoop-lzo-0.4.20.jar
(4)core-site.xml增加配置支持LZO压缩
添加如下配置
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
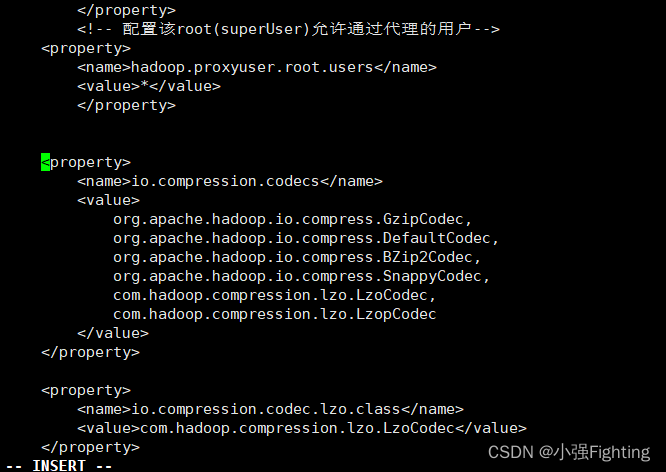
(5)同步core-site.xml到hadoop103、hadoop104
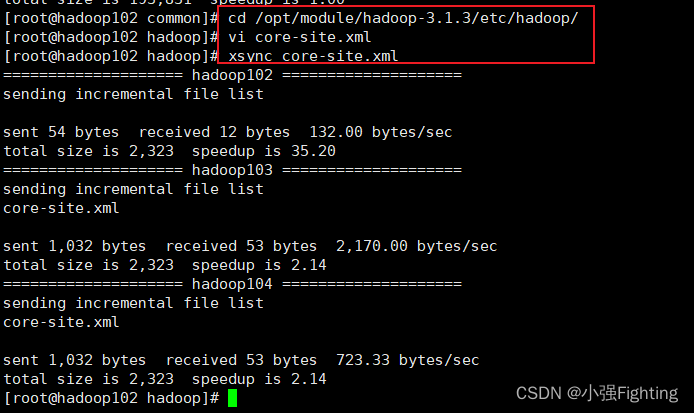
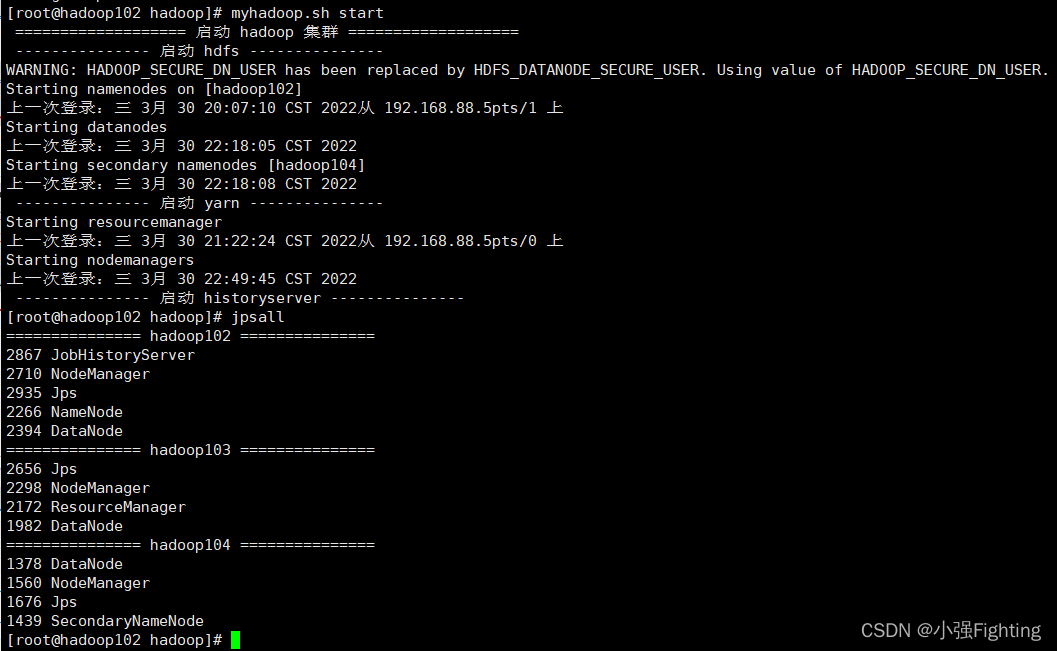
(6)启动及查看集群
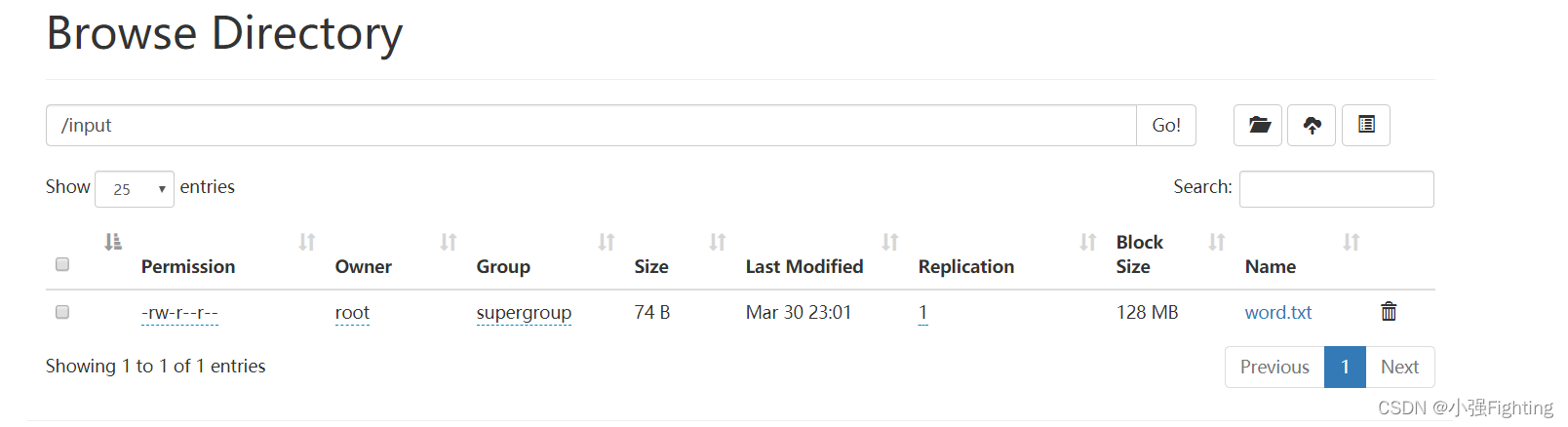
(7)测试-数据准备
创建文件input,准备文件word.txt

hadoop fs -mkdir /input
hadoop fs -put word.txt /input
文件上传成功192.168.88.102:980
(8)测试-压缩
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output1

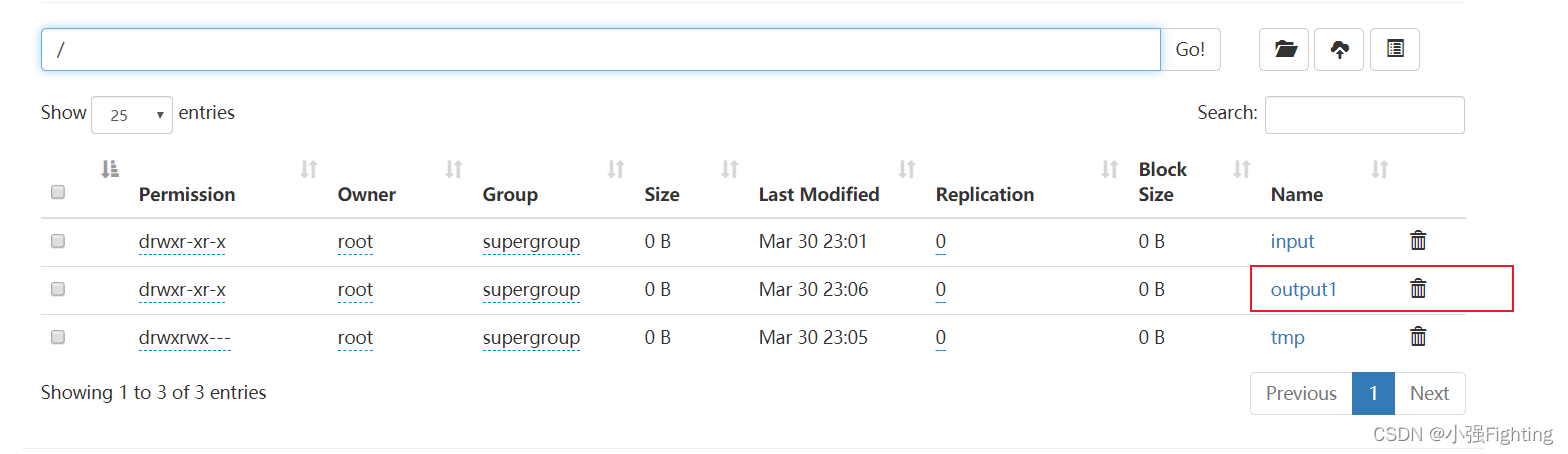
3.创建索引
(1)将bigtable.lzo(200M)上传到集群的根目录
上传文件hadoop fs -put bigtable.lzo /input

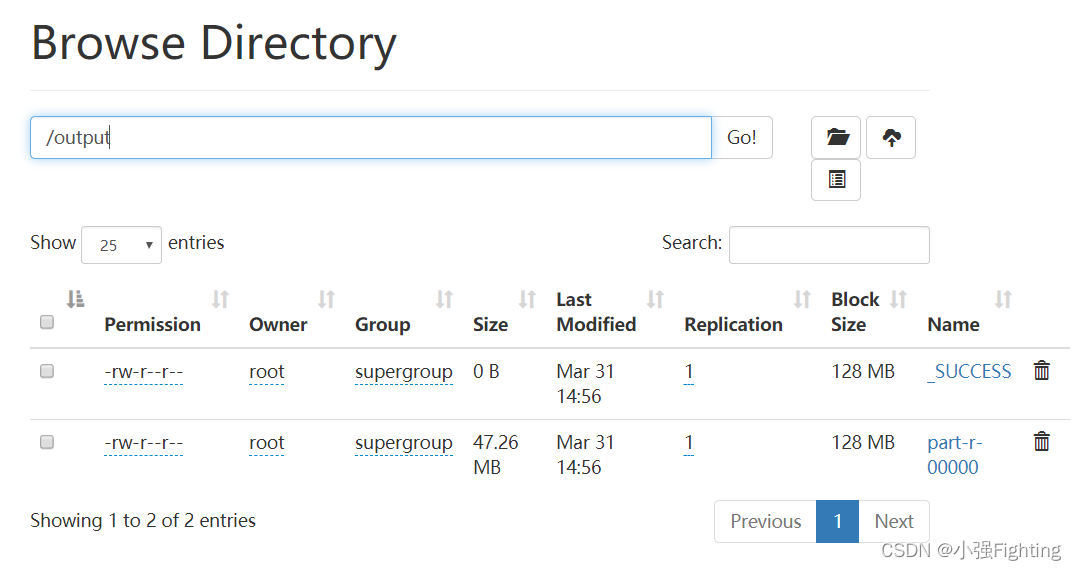
(2)执行wordcount程序
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /input /output
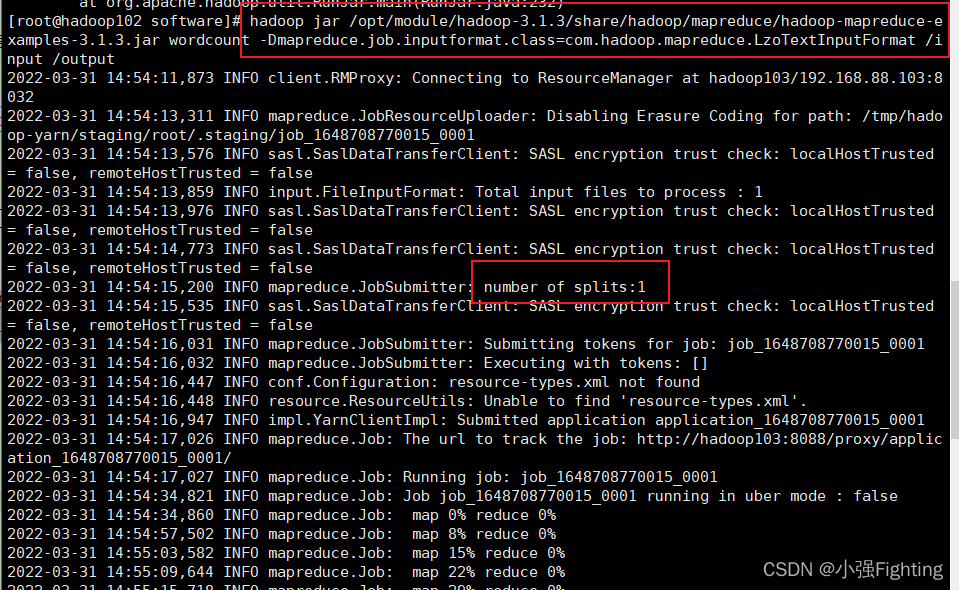
浏览器查看
(3)对上传的LZO文件建立索引
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /input/bigtable.lzo
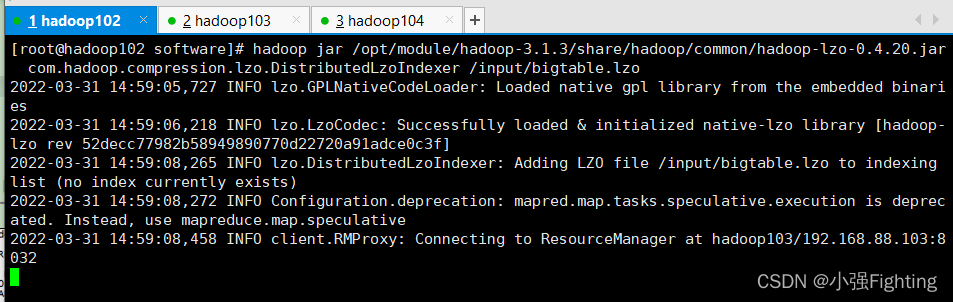
浏览器查看,input多了一个index文件
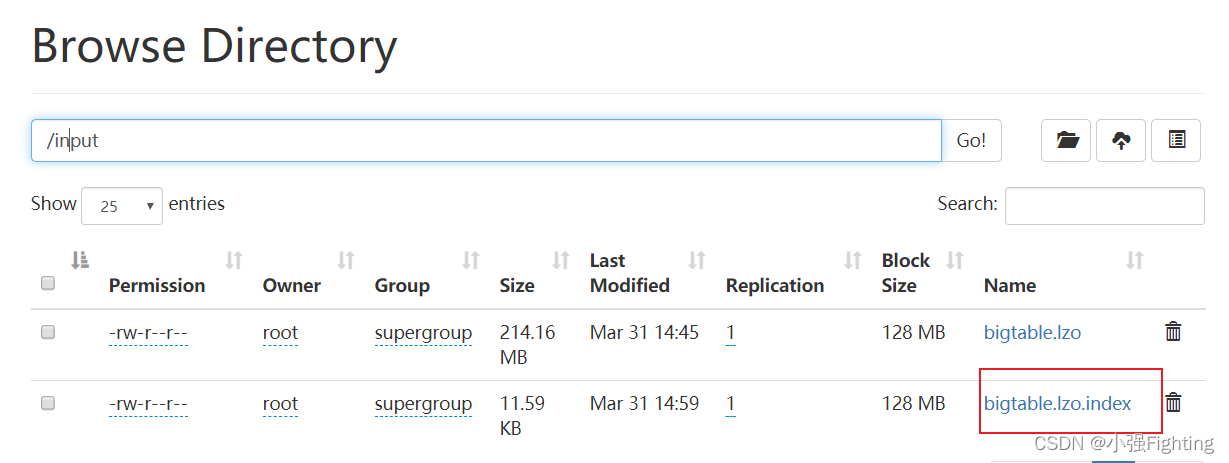
(4)再次执行wordcount程序
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /input /output2
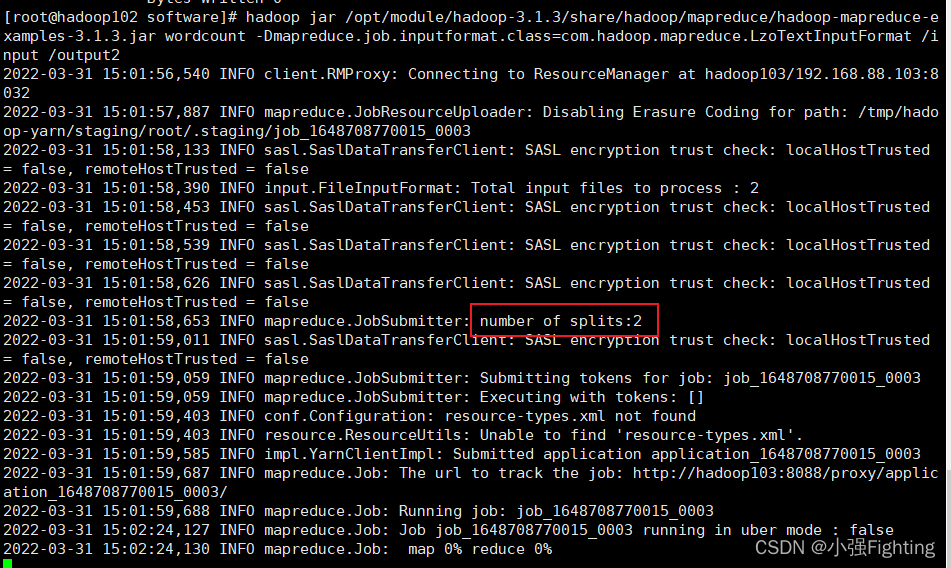
执行成功,浏览器端查看
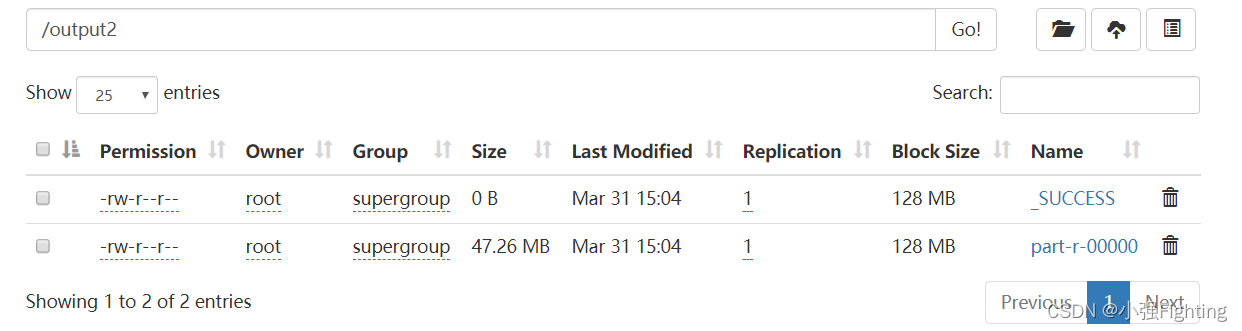
五、Zookeeper安装
1.集群规划
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper。
2.解压安装
(1)上传文件

(2)解压Zookeeper安装包到/opt/module/目录下
tar -zxvf zookeeper-3.5.7.tar.gz -C /opt/module/

(3)修改/opt/module/apache-zookeeper-3.5.7-bin名称为zookeeper-3.5.7
mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
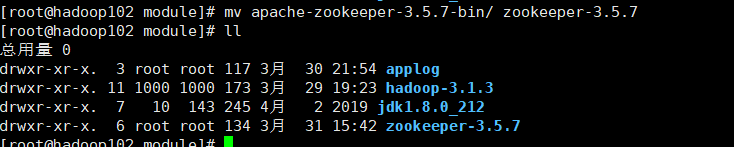
(4)配置服务器编号
在/opt/module/zookeeper-3.5.7/这个目录下创建zkData
mkdir zkData
在/opt/module/zookeeper-3.5.7/zkData目录下创建一个myid的文件
vi myid
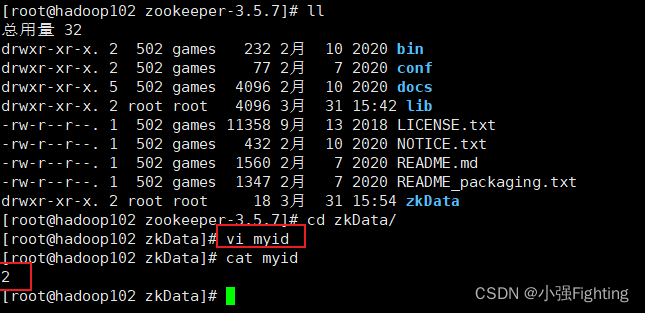
(5)同步/opt/module/zookeeper-3.5.7目录内容到hadoop103、hadoop104
xsync zookeeper-3.5.7/
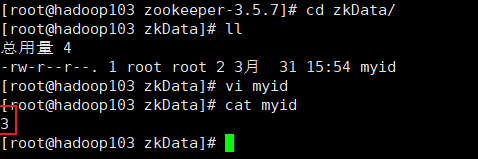
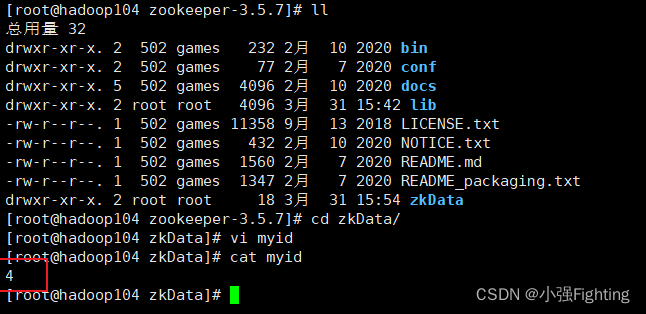
查看
并分别在hadoop103、hadoop104上修改myid文件中内容为3、4
3.配置zoo.cfg文件
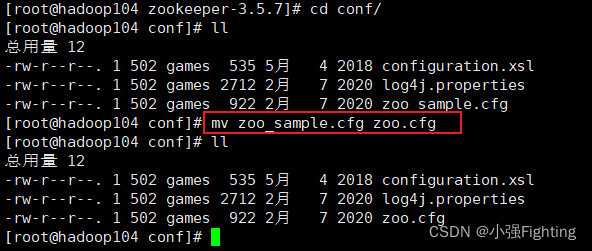
(1)重命名/opt/module/zookeeper-3.5.7/conf这个目录下的zoo_sample.cfg为zoo.cfg
mv zoo_sample.cfg zoo.cfg
(2)打开zoo.cfg文件
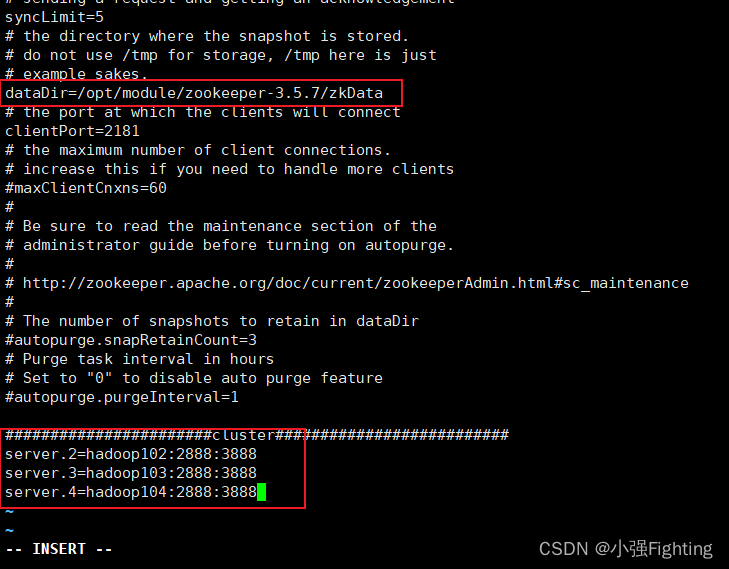
修改数据存储路径配置dataDir=/opt/module/zookeeper-3.5.7/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
配置参数解读
server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址;
C是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
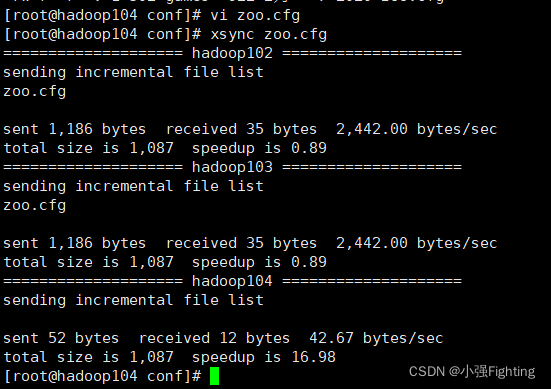
(3)同步zoo.cfg配置文件
xsync zoo.cfg
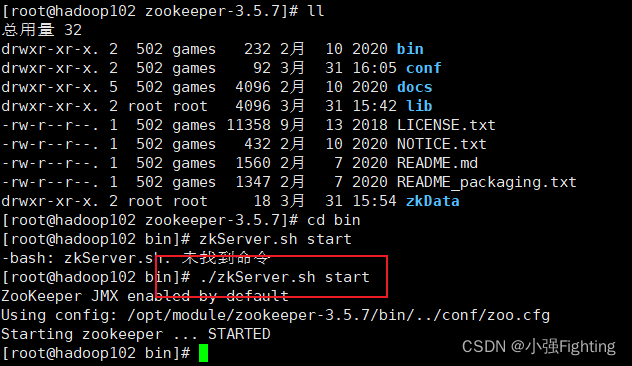
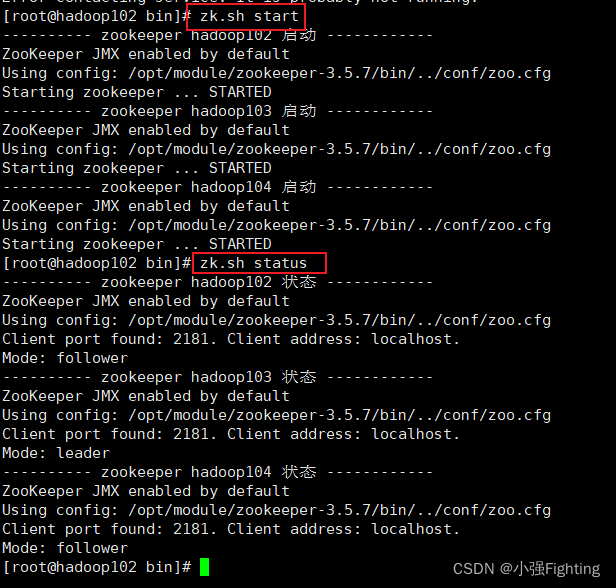
(4)分别启动Zookeeperbin/zkServer.sh start
查看节点启动
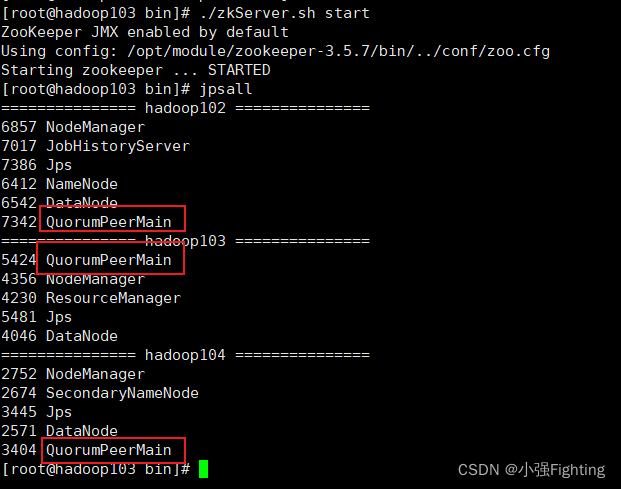
查看状态./zkServer.sh status

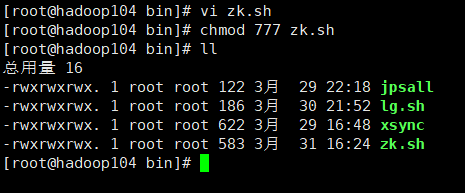
(5)ZK集群启动停止脚本
在hadoop102的/root/bin目录下创建脚本vi zk.sh
在脚本中编写如下内容
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;
esac

增加脚本执行权限chmod 777 zk.sh
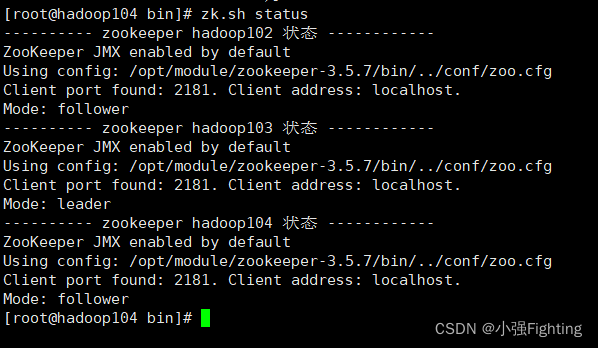
Zookeeper集群启动状态zk.sh status
Zookeeper集群启动脚本zk.sh start
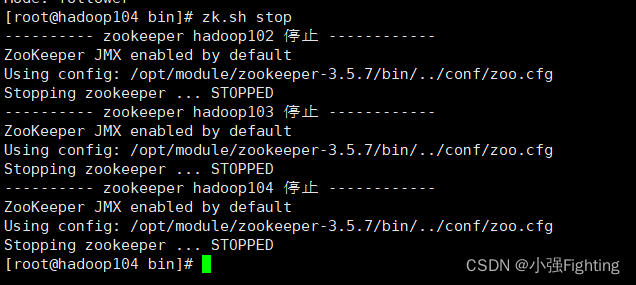
Zookeeper集群停止脚本zk.sh stop
同步
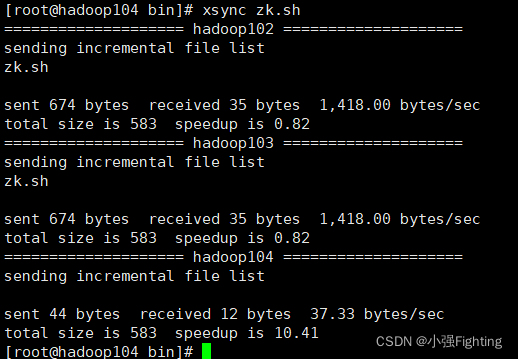
六、Kafka集群部署
1.上传jar包
2.解压安装包
tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module/

3.修改解压后的文件名称
mv kafka_2.11-2.4.1/ kafka
4.在/opt/module/kafka目录下创建logs文件夹
mkdir logs
5.修改配置文件
cd config/
vi server.properties
修改或者增加以下内容:
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/data
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka



6.分发,修改broker.id


7.配置环境变量
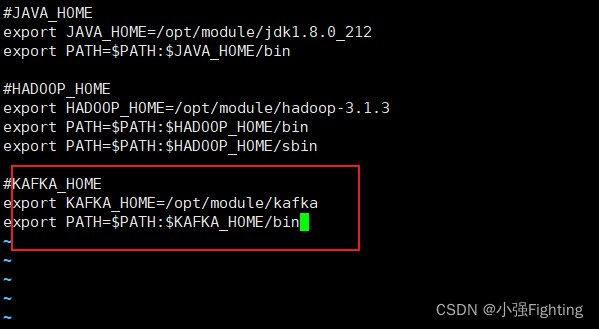
vi /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
使环境变量生效
source /etc/profile.d/my_env.sh

分发脚本
hadoop103,hadoop104上分别source一下


8.启动集群
依次在hadoop102、hadoop103、hadoop104节点上启动kafka
./kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
关闭集群
./kafka-server-stop.sh
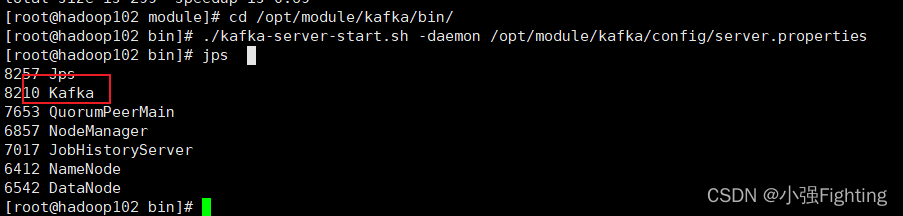


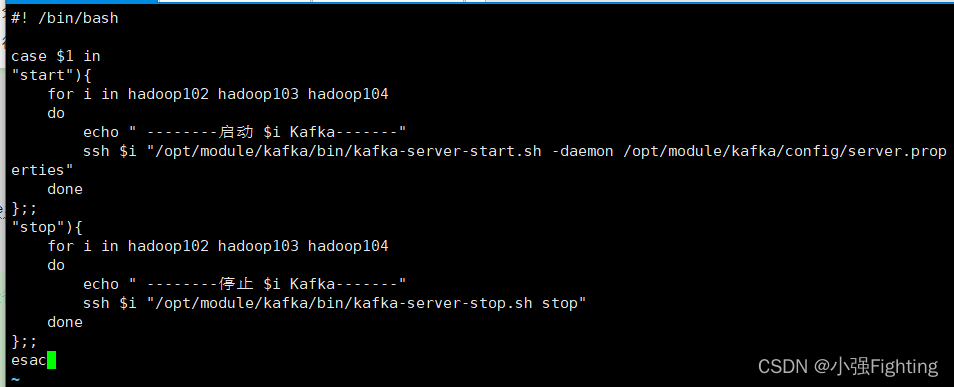
9.Kafka集群启动停止脚本
在/root/bin目录下创建脚本kf.sh
在脚本中填写如下内容
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
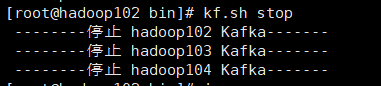
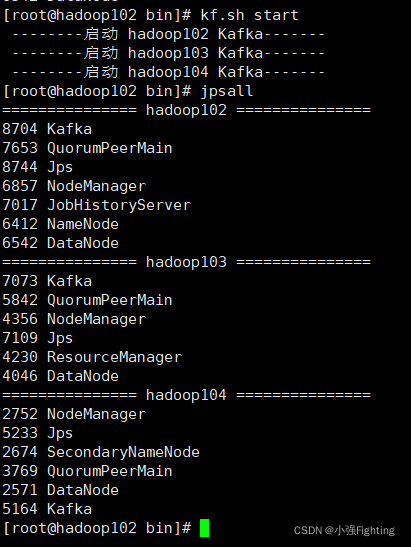
增加脚本执行权限chmod 777 kf.sh
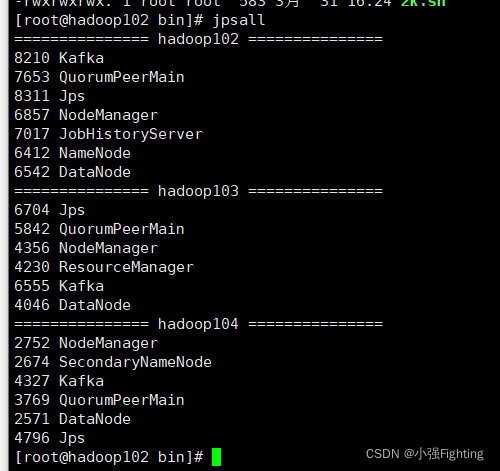
测试kf集群启动/停止脚本(关闭要等一会)
10.Kafka常用命令
(1)查看Kafka Topic列表
./kafka-topics.sh --zookeeper hadoop102:2181/kafka --list

(2)创建Kafka Topic
进入到/opt/module/kafka/目录下创建日志主题
./kafka-topics.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --create --replication-factor 1 --partitions 1 --topic topic_log
(3)删除Kafka Topic
./kafka-topics.sh --delete --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --topic topic_log
(4)Kafka生产消息
./kafka-console-producer.sh --broker-list hadoop102:9092 --topic topic_log
(5)Kafka消费消息
./kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic topic_log
–from-beginning:会把主题中以往所有的数据都读取出来。根据业务场景选择是否增加该配置。
(6)查看Kafka Topic详情
./kafka-topics.sh --zookeeper hadoop102:2181/kafka --describe --topic topic_log
11.Kafka机器数量计算
Kafka机器数量(经验公式)= 2 *(峰值生产速度 * 副本数 / 100)+ 1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。
1)峰值生产速度
峰值生产速度可以压测得到。
2)副本数
副本数默认是1个,在企业里面2-3个都有,2个居多。
副本多可以提高可靠性,但是会降低网络传输效率。
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量 = 2 *(50 * 2 / 100)+ 1 = 3台
集群关闭顺序:先关闭Kafka,再关闭Zookeeper,最后关闭hadoop
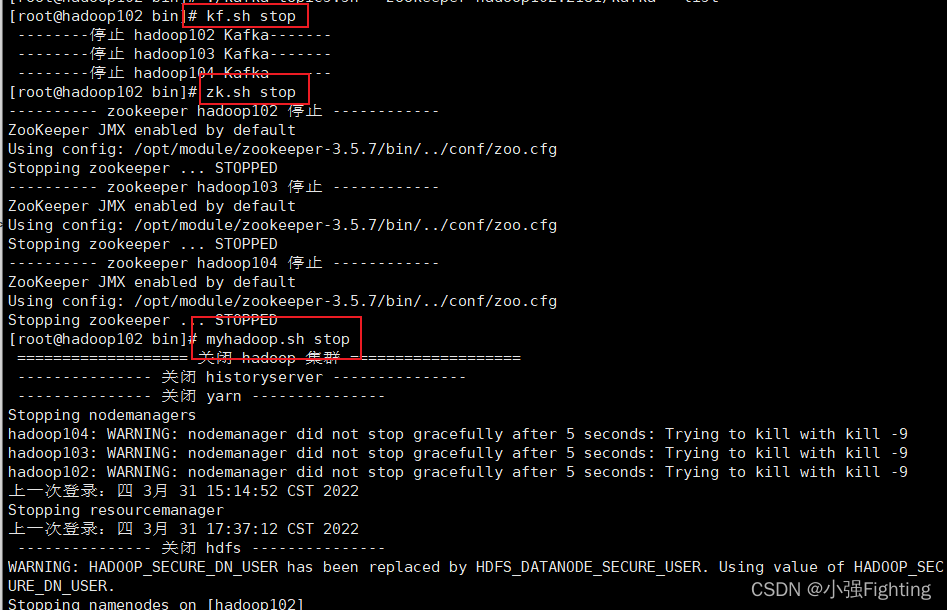
关闭成功
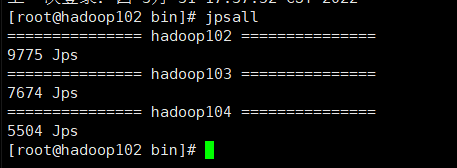
七、Flume安装
1.上传安装包
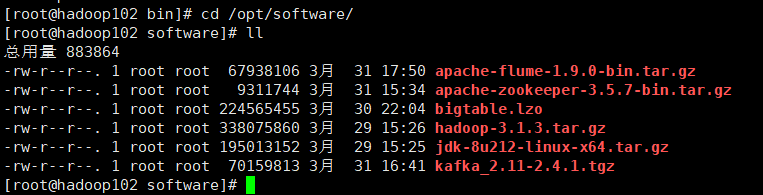
2.解压apache-flume-1.9.0-bin.tar.gz到/opt/module/目录下
tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
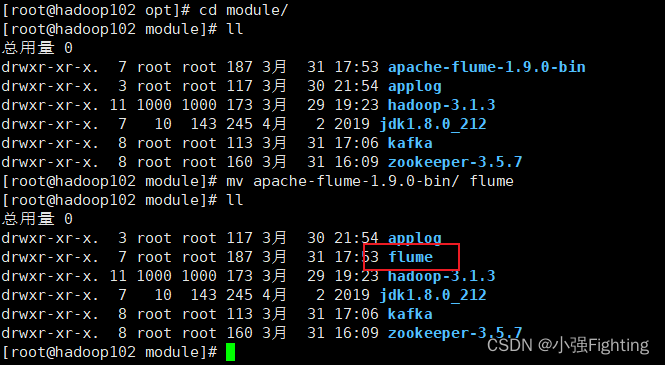
3.修改apache-flume-1.9.0-bin的名称为flume
mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume
4.将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
rm /opt/module/flume/lib/guava-11.0.2.jar

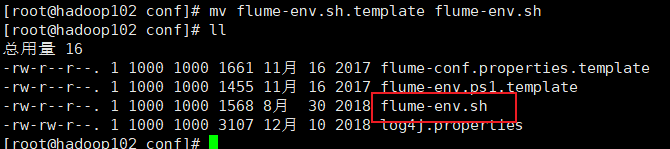
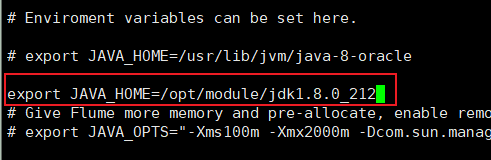
5.将flume/conf下的flume-env.sh.template文件修改为flume-env.sh,并配置flume-env.sh文件
6.分发flume
cd /opt/module
xsync flume/
八、日志采集Flume配置
1.创建Maven工程flume-interceptor
2.创建包名:flume.interceptor
3.在pom.xml文件中添加如下配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
注意:scope中provided的含义是编译时用该jar包。打包时时不用。因为集群上已经存在flume的jar包。只是本地编译时用一下。
4.在com.atguigu.flume.interceptor包下创建JSONUtils类
package flume.interceptor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
public class JSONUtils {
public static boolean isJSONValidate(String log){
try {
JSON.parse(log);
return true;
}catch (JSONException e){
return false;
}
}
}
5.在com.atguigu.flume.interceptor包下创建LogInterceptor类
package flume.interceptor;
import com.alibaba.fastjson.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
if (JSONUtils.isJSONValidate(log)) {
return event;
} else {
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()){
Event next = iterator.next();
if(intercept(next)==null){
iterator.remove();
}
}
return list;
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
@Override
public void close() {
}
}
6.打包

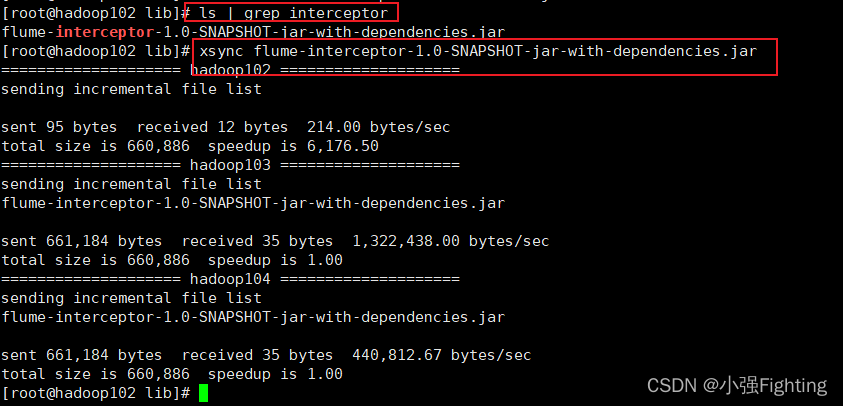
7.需要先将打好的包放入到hadoop102的/opt/module/flume/lib文件夹下面。
ls | grep interceptor

8.分发Flume到hadoop103、hadoop104
xsync flume/
9.在/opt/module/flume/conf目录下创建file-flume-kafka.conf文件
vi file-flume-kafka.conf
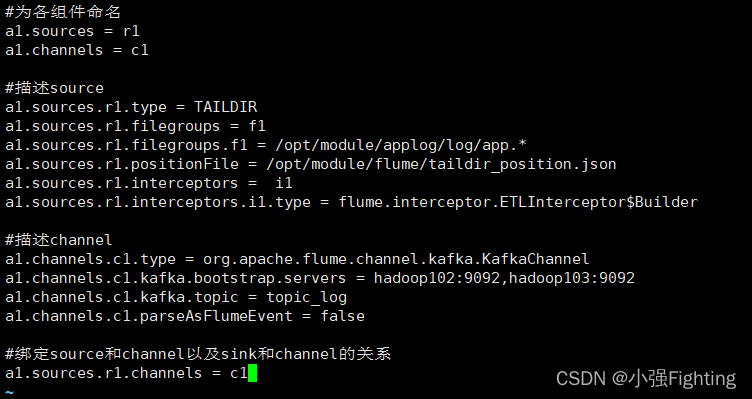
在文件配置如下内容
#为各组件命名
a1.sources = r1
a1.channels = c1
#描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = flume.interceptor.ETLInterceptor$Builder
#描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#绑定source和channel以及sink和channel的关系
a1.sources.r1.channels = c1
注意:flume.interceptor.ETLInterceptor是自定义的拦截器的全类名。需要根据用户自定义的拦截器做相应修改。
分发脚本
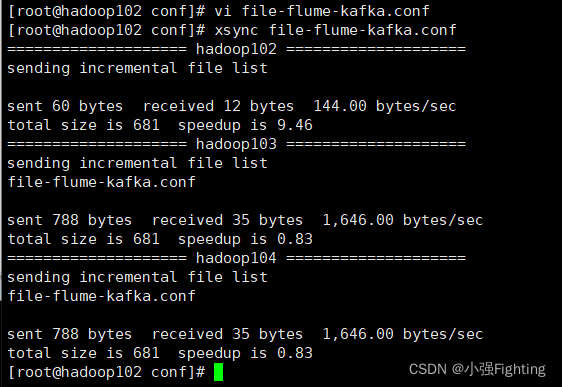
10.分别在hadoop102、hadoop103上启动Flume
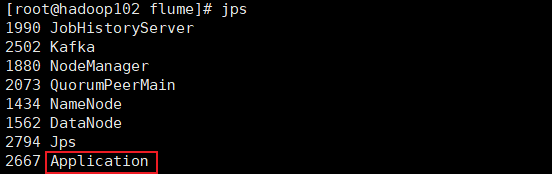
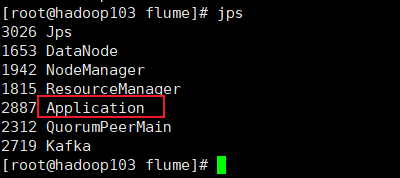
bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf &
查看结果Application已启动
11.测试Flume-Kafka通道
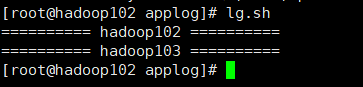
(1)生成日志
lg.sh
(2)消费Kafka数据,观察控制台是否有数据获取到
cd /opt/module/kafka
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic topic_log
结果如图
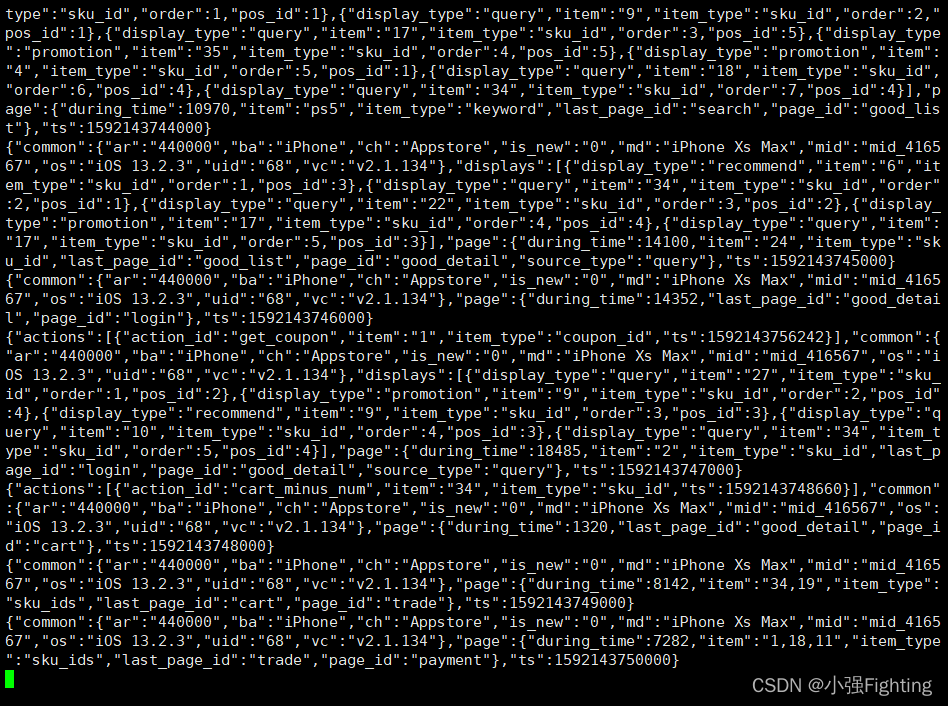
说明:如果获取不到数据,先检查Kafka、Flume、Zookeeper是否都正确启动。再检查Flume的拦截器代码是否正常。
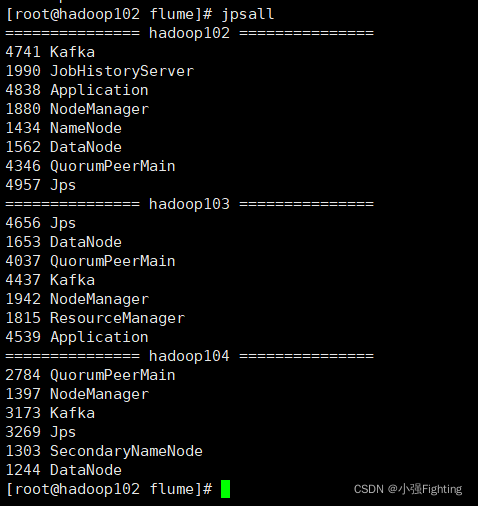
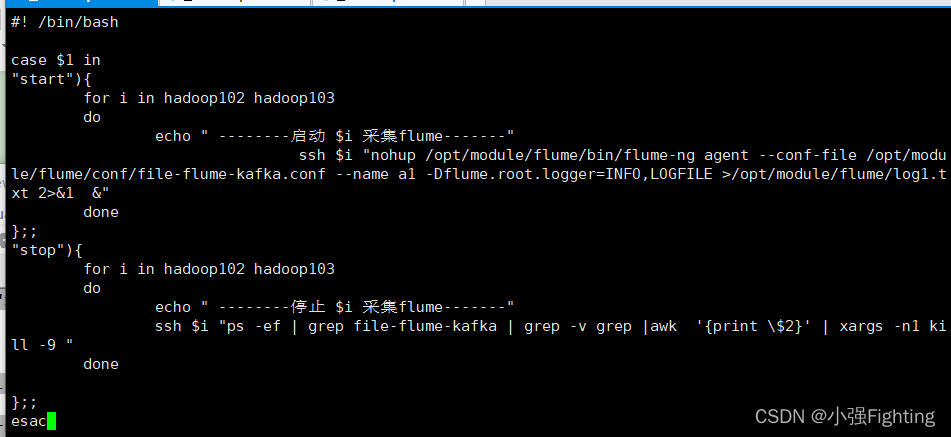
12.日志采集Flume启动停止脚本
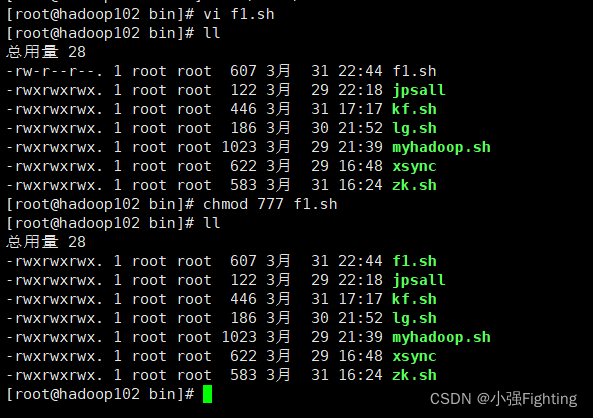
(1)在/root/bin目录下创建脚本f1.sh
vi f1.sh
在脚本中填写如下内容
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log1.txt 2>&1 &" y
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
说明1:nohup,该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思,不挂断地运行命令。
说明2:awk 默认分隔符为空格
说明3:$2是在“”双引号内部会被解析为脚本的第二个参数,但是这里面想表达的含义是awk的第二个值,所以需要将他转义,用$2表示。
说明4:xargs 表示取出前面命令运行的结果,作为后面命令的输入参数。
(2)增加脚本执行权限
chmod u+x f1.sh
(3)f1集群启动/停止脚本
f1.sh start
f1.sh stop
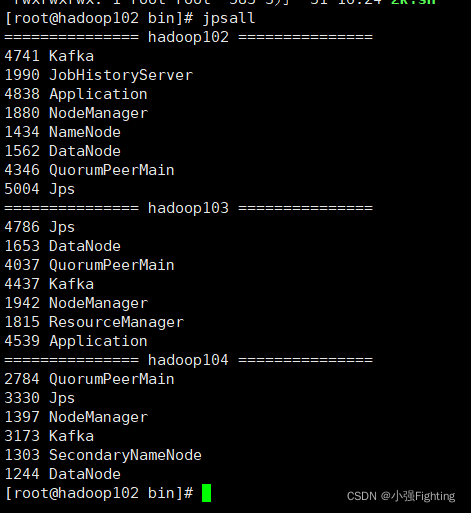
测试
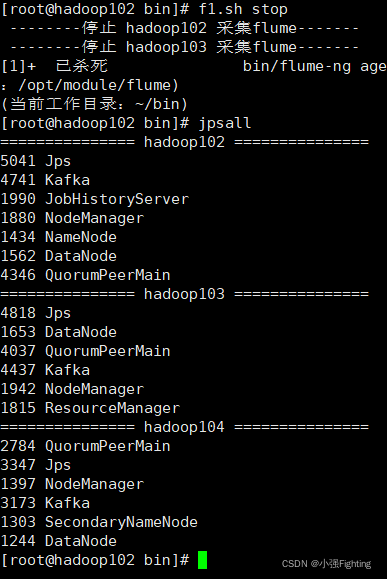
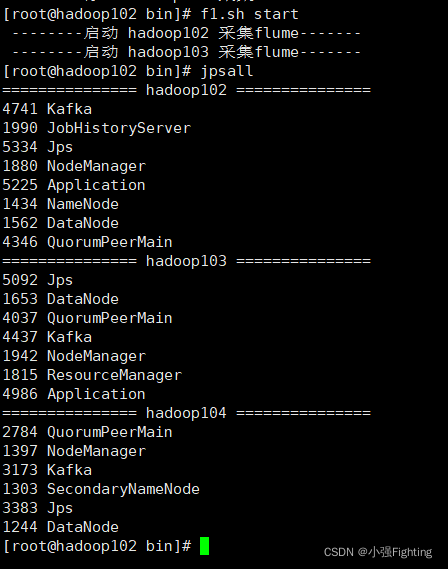
九、消费Kafka数据Flume
集群规划
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| Flume(消费kafka) | flume |
1.Flume组件选型——FileChannel和MemoryChannel区别
区别:
MemoryChannel传输数据速度更快,但因为数据保存在JVM的堆内存中,Agent进程挂掉会导致数据丢失,适用于对数据质量要求不高的需求。
FileChannel传输速度相对于Memory慢,但数据安全保障高,Agent进程挂掉也可以从失败中恢复数据。
选型:
金融类公司、对钱要求非常准确的公司通常会选择FileChannel
传输的是普通日志信息(京东内部一天丢100万-200万条,这是非常正常的),通常选择MemoryChannel。
2.Flume时间戳拦截器
Flume时间戳拦截器
由于Flume默认会用Linux系统时间,作为输出到HDFS路径的时间。如果数据是23:59分产生的。Flume消费Kafka里面的数据时,有可能已经是第二天了,那么这部门数据会被发往第二天的HDFS路径。我们希望的是根据日志里面的实际时间,发往HDFS的路径,所以下面拦截器作用是获取日志中的实际时间。
解决的思路:拦截json日志,通过fastjson框架解析json,获取实际时间ts。将获取的ts时间写入拦截器header头,header的key必须是timestamp,因为Flume框架会根据这个key的值识别为时间,写入到HDFS。
(1)在flume.interceptor包下创建TimeStampInterceptor类
package flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TimeStampInterceptor implements Interceptor {
private ArrayList<Event> events = new ArrayList<>();
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSONObject.parseObject(log);
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
events.clear();
for (Event event : list) {
events.add(intercept(event));
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimeStampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
(2)重新打包

(3)需要先将打好的包放入到hadoop104/opt/module/flume/lib文件夹下面。
ls | grep interceptor

3.消费者Flume配置
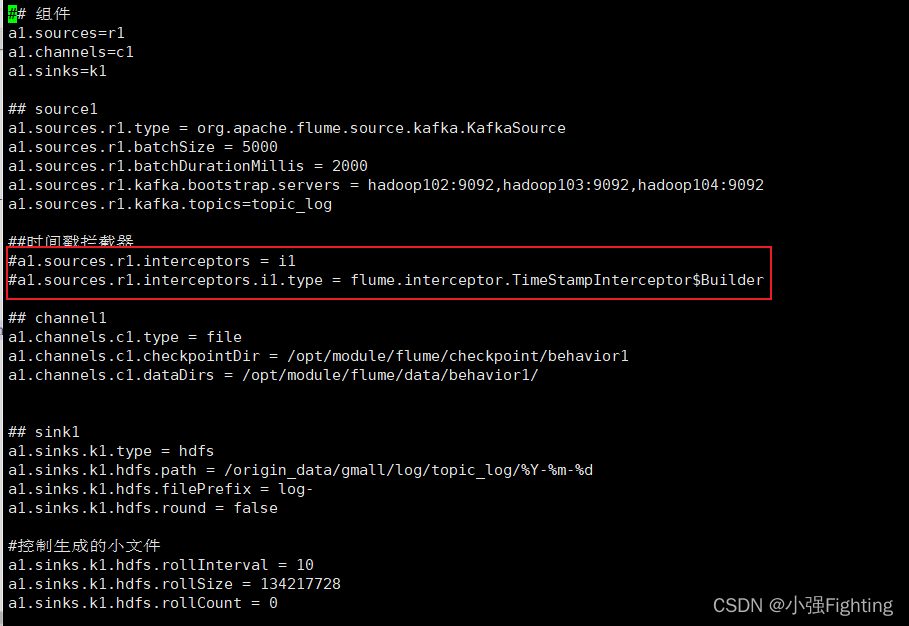
(1)在hadoop104的/opt/module/flume/conf目录下创建kafka-flume-hdfs.conf文件
vi kafka-flume-hdfs.conf
在文件配置如下内容
## 组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimeStampInterceptor$Builder
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
#控制生成的小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
测试flume使劲按拦截器:启动flume
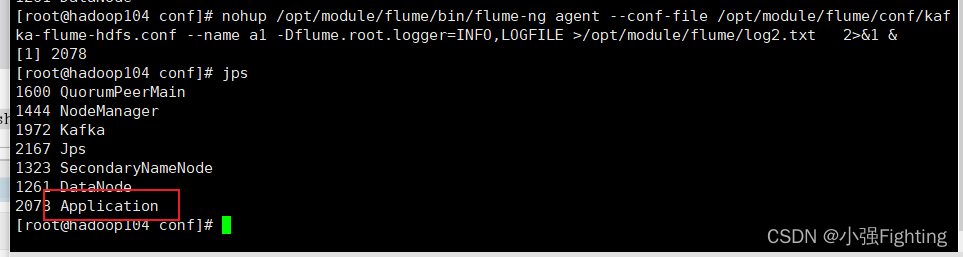
分别查看hadoop102和hadoop104上的时间

注释掉时间拦截器,启动flume,生成日志信息
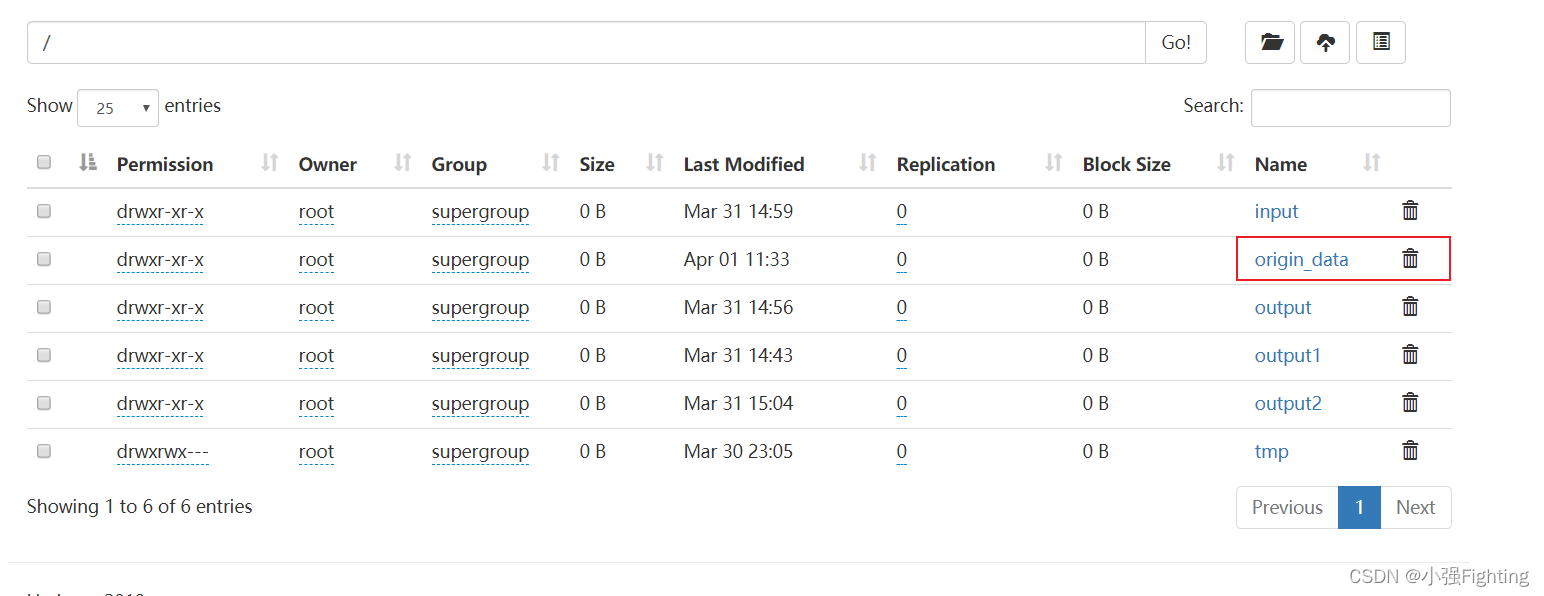
查看log的时间,是当前Hadoop104的时间

停止flume,使时间拦截器生效,再次启动,生成日志查看,时间为日志时间。

4.消费者Flume启动停止脚本
(1)在/home/atguigu/bin目录下创建脚本f2.sh
vi f2.sh
在脚本中填写如下内容
#! /bin/bash
case $1 in
"start"){
for i in hadoop104
do
echo " --------启动 $i 消费flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log2.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop104
do
echo " --------停止 $i 消费flume-------"
ssh $i "ps -ef | grep kafka-flume-hdfs | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
done
};;
esac
(2)增加脚本执行权限
chmod 777 f2.sh
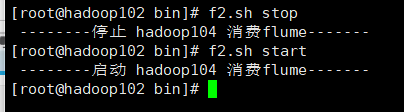
(3)f2集群启动脚本
f2.sh start
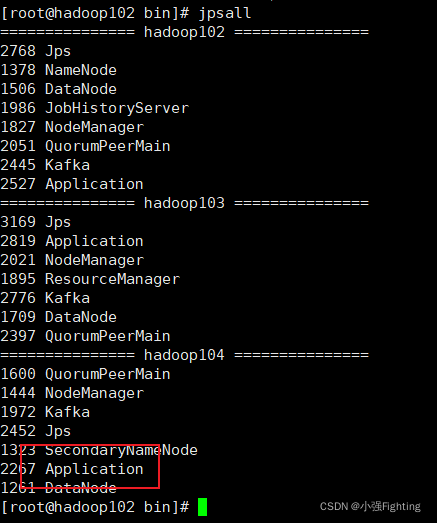
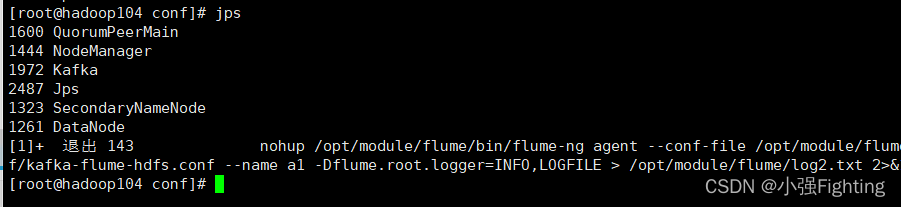
(4)f2集群停止脚本
f2.sh stop

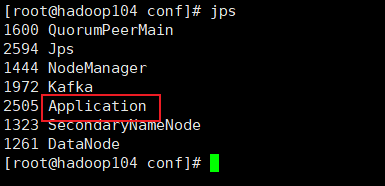
5.采集通道启动/停止脚本
(1)在/root/bin目录下创建脚本cluster.sh
在脚本中填写如下内容
#!/bin/bash
case $1 in
"start"){
echo ================== 启动 集群 ==================
#启动 Zookeeper集群
zk.sh start
#启动 Hadoop集群
myhadoop.sh start
#启动 Kafka采集集群
kf.sh start
#启动 Flume采集集群
f1.sh start
#启动 Flume消费集群
f2.sh start
};;
"stop"){
echo ================== 停止 集群 ==================
#停止 Flume消费集群
f2.sh stop
#停止 Flume采集集群
f1.sh stop
#停止 Kafka采集集群
kf.sh stop
#停止 Hadoop集群
myhadoop.sh stop
#停止 Zookeeper集群
zk.sh stop
};;
esac
(2)增加脚本执行权限
chmod 777 cluster.sh
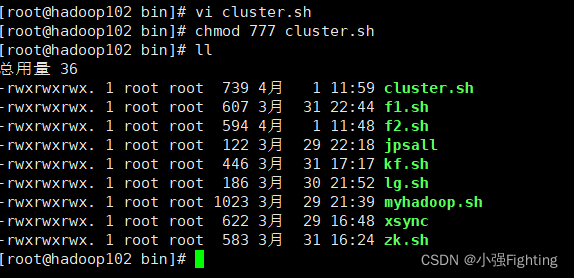
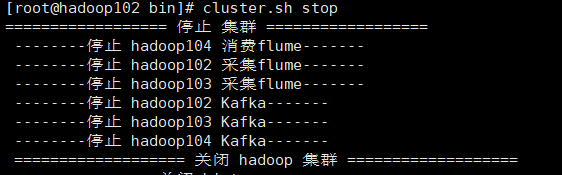
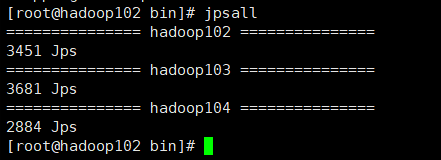
(3)cluster集群启动/停止脚本
cluster.sh stop
cluster.sh start
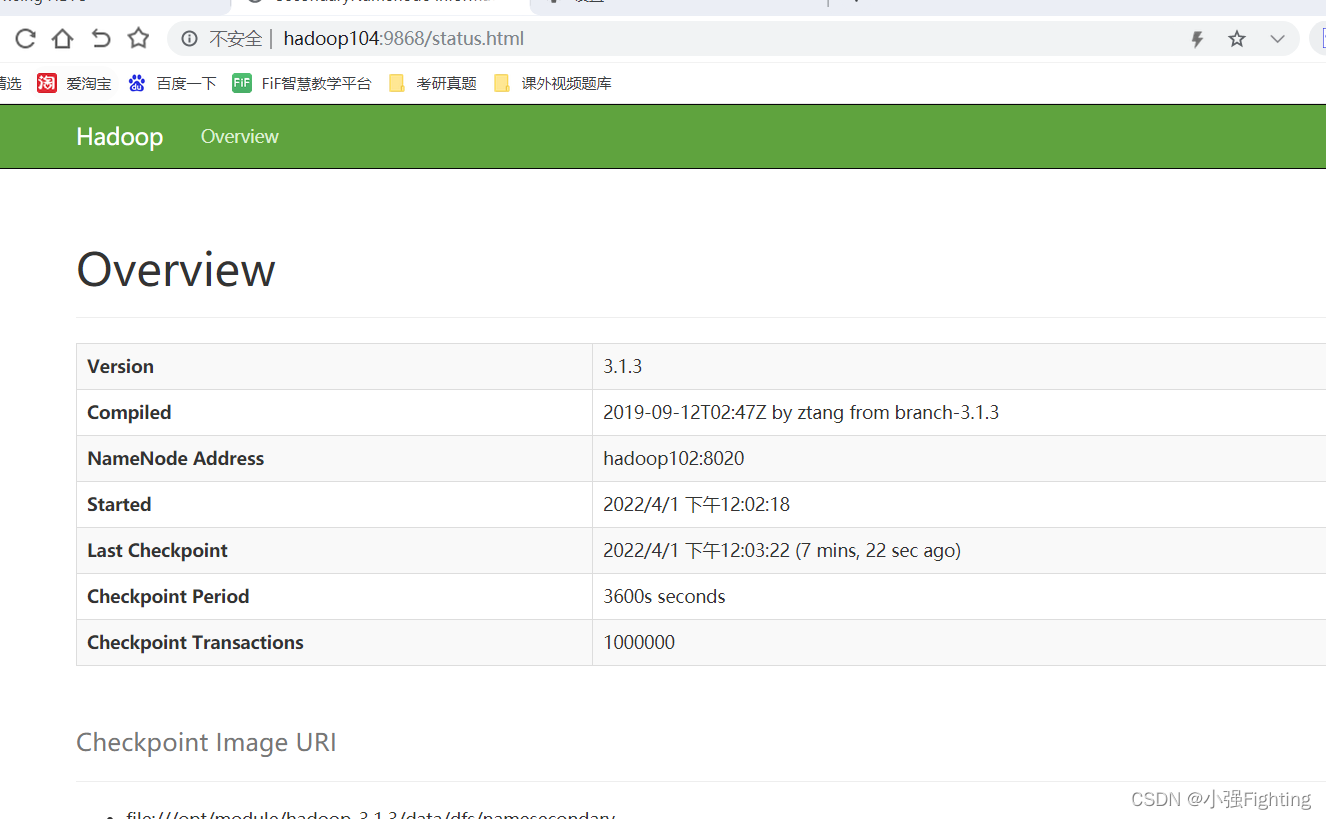
6.2NN页面不能显示完整信息
问题描述——访问2NN页面http://hadoop104:9868,看不到详细信息
解决办法
(1)在浏览器上按F12,查看问题原因。定位bug在61行
(2)找到要修改的文件
/opt/module/hadoop-3.1.3/share/hadoop/hdfs/webapps/static
vi dfs-dust.js
:set nu

修改61行
return new Date(Number(v)).toLocaleString();

在http://hadoop104:9868/status.html 页面强制刷新,先清除浏览器数据再刷新

















 5406
5406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









