






模糊查询,搭配“%” 使用
SELECT 字段名 FROM 表名 WHERE字段名 LIKE 正则表达式
| % | 搭配正则表达式,求值为0或多个字符 |
|---|---|
| _ | 求值为单个字符 |
| \ | 对特殊字符转义 |
*Escape* 表示使某些特殊字符(如通配符:'%','_')转义为它们原来的字符的意义,被定义的转义字符通常使用''。
select MAINBUSSINESS from TBL_CHN_I_CO_ListedCoInfo Where MAINBUSSINESS Like '%\%%' Escape '\'
2.ORDER BY
asc表示升序排列(一般可省略)
desc 表示降序排列
对多个列进行排序:在ORDER BY子句中最先列示的列优先排序。
ORDER BY "字段一" [ASC, DESC], "字段二" [ASC, DESC]
3.<>不等于
4.连接
<1>、等值连接:
等值连接是基于相等或匹配列值的连接。在where子句中,使用作为比较运算符号的等号(=)来表示这一相等关系
<2>、自连接
<3>、内连接
Select 表A.字段名, 表B. 字段名 from 表A inner join 表B on 连接条件 where 条件1,条件2…
<4>.左连接
以左表为主表去关联右表,查询结果显示左表的所有信息以及符合关联条件的右表信息
Select 表A.字段名, 表B. 字段名 from 表A left join 表B on 连接条件 where 条件1,条件2…
<5>、右连接
以右表为主表去关联左表,查询结果显示右表的所有信息以及符合关联条件的左表信息
Select 表A.字段名, 表B. 字段名 from 表A right join 表B on 连接条件 where 条件1,条件2…
<6>、全连接
select 表A.字段名, 表B. 字段名 from 表A full join 表B on 连接条件
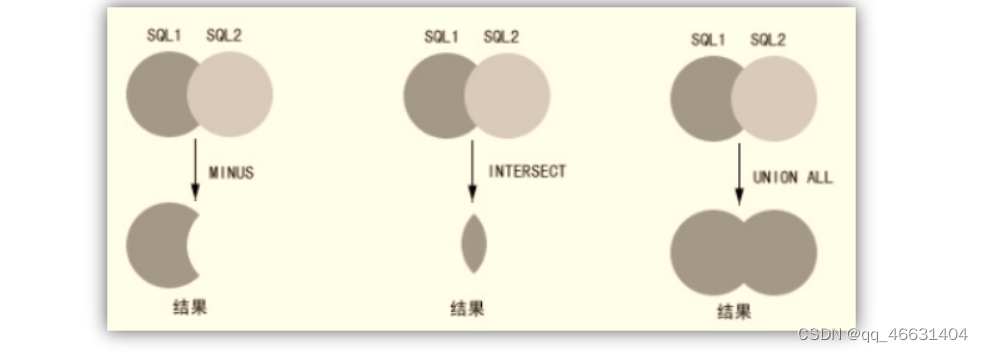
5.集合运算符
<1>.UNION ALL(不去重)
UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相同的数据类型。同时,每条 SELECT语句中的列的顺序必须相同。
| id | num |
|---|---|
| 100 | 12 |
| 101 | 13 |
| 102 | 14 |
| dm | num |
|---|---|
| 100 | 12 |
| 100 | 18 |
| 102 | 17 |
SELECT a.id ZD,a.num NU FROM a WHERE a.id = '100' UNION ALL SELECT b.dm ID,b.num NU FROM b WHERE b.dm = '100'
| ID | NU |
|---|---|
| 100 | 12 |
| 100 | 12 |
| 100 | 18 |
<2>、UNION(去重)
<3>、INTERSECT
INTERSECT也是对两个SQL语句所产生的结果做处理的。不同的地方是,UNION基本上是一个OR (如果这个值存在于第一句或是第二句,它就会被选出),而INTERSECT则比较像AND (这个值要存在于第一句和第二句才会被选出)。
| id | num |
|---|---|
| 100 | 12 |
| 101 | 13 |
| 102 |
| dm | num |
|---|---|
| 100 | 12 |
| 100 | |
| 102 | 17 |
SELECT a.id ZD,a.num NU FROM a INTERSECT SELECT b.dm ID,b.num NU FROM b
| ID | NU |
|---|---|
| 100 | 12 |
| 101 | 13 |
| 100 | 12 |
| 102 | 17 |
<4>、MINUS
MINUS 指令是保留第一个指令中不存在与第二个指令的部分。
6.嵌套
子查询一般出现在SELECT语句的WHERE子句中,ORACLE也支持在FROM或HAVING子句中出现子查询。子查询比主查询先执行,结果作为主查询的条件,在书写上要用圆括号扩起来,并放在比较运算符的右侧。子查询可以嵌套使用,最里层的查询最先执行。
<1>、单行子查询
子查询返回结果小于等于1行。
select 表A.字段名1,,表A. 字段名2 from 表A where 表A. 字段名n 单行比较符 (select 表B. 字段名m from 表B where 条件)
注:① 单行比较符:=、<、>、<=、>=等 ② (()返回结果小于等于1行
<2>、多行子查询
如果子查询返回多行的结果,则称它为多行子查询。多行子查询要使用不同的比较运算符号,它们是IN、ANY和ALL、EXISTS。
select 表A. 字段名1,表A. 字段名2 from 表A where 表A. 字段名n in (select 表B. 字段名m from 表B where 条件)
<3>、多列子查询
如果子查询返回多列,则对应的比较条件中也应该出现多列
select 表A.字段名1,,表A.字段名2 from 表A where (表A.字段名n1,表A.字段名n2) in (select 表B.字段名m1,表B.字段名m2 from 表B where 条件)
7、EXISTS
EXISTS表示是否存在符合某种条件的记录。exists表示()内子查询语句返回结果不为空说明where条件成立就会执行主sql语句,如果为空就表示where条件不成立,sql语句就不会执行。not exists和exists相反,子查询语句结果为空,则表示where条件成立,执行sql语句,否则不执行。
SELECT "字段名 1" FROM "表名 1" WHERE EXISTS (SELECT * FROM "表名 2" WHERE [条件])
8、TOP、ROWNUM
TOP 子句用于规定要返回的记录的数目。对于拥有数千条记录的大型表来说,TOP 子句是非常有用的。但并非所有的数据库系统都支持 TOP 子句。在ORACLE环境中使用的是ROWNUM函数。Oracle利用到一个rownum伪列,来实现top功能。也就是说这个辅助列并不是物理存在的,可以理解为rownum为依据查询结果后赋序列值,因此,我们不能直接在where 条件中用rownum 限制条件,此类问题可以利用嵌套来解决。
Select 字段名from (Select 字段名 from 表名 order by 字段名)where rownum 条件
从A表中查找时间(Date)最大的10条数据。语句如下:
select * from (select * from A where Date is not null order by Date desc ) where rownum <=10
9.大小写转换函数
<1>、LOWER
字段信息中含有字母的全部转成小写。
LOWER(字符串):SELECT LOWER('ABDS') FROM DUAL
<2>、UPPER
字段信息中含有字母的全部转成大写。
<3>、INITCAP
将每个单词的第一个字母大写,其它字母变为小写
10.日期和转换函数
(1)、SYSDATE
Sysdate函数没有参数,它返回数据库服务器当前的系统日期和时间。 如获取当前的系统日期 Oracle:Select sysdate from dual
(2).DATE
常用来查询字段日期,需用于日期型字段中。
查询(TBL_A)上市时间(Date)为2023-06-09的数据。 select * from TBL_A where Date =date'2023-06-09'
(3)、TO_CHAR
将datetime或date值转换为字符串值。
查询系统时间,精确到时分秒:
select to_char(date,'yyyy-MM-dd HH24:mi:ss') from table
(4)、TO_DATE
将字符串值转换为日期类型,需用于日期型字段中。
查询(TBL_A)上市时间(Date)为2023-06-09的数据。 select * from TBL_A where Date =to_date(2023-06-09','yyyy-mm-dd')
11.字符型函数
(1)、ASCII
将字符转换为ASCII码
select ASCII('t') from table
(2)、CONCAT/||
表示将不同列名串连在一起。
ORACLE:CONCAT(字符串 1,字符串2)或||
注:ORACLE的 CONCAT()只允许两个参数;换言之,一次只能将两个字符串连起来。不过,在ORACLE中,我们可以用'||'来一次串连多个字符串。
SELECT CONCAT(a,z) from table az SELECT CONCAT(a||'~',z) from table a~z
(3)、LENGTH
返回字段长度。
ORACLE:Length(字段名)
(4)、LTRIM / RTRIM /TRIM
TRIM 函数是用来移除掉一个字符串中的字头或字尾。最常见的用途是移除字首或字尾的空白。
LTRIM(字符串): 将所有字符串开头的空格移除。
RTRIM(字符串): 将所有字符串结尾的空格移除。
TRIM(字符串): 将所有字符串首尾空格移除。
查找出表(TAB)中字段(ds)首尾含有回车符的数据。
SELECT ds FROM TAB WHERE trim(ds)<>ds
(5)、INSTR
在一个字符串中查找指定的字符,返回被查找到的指定的字符的位置。
instr('源字符串' , '目标字符串' ,'开始位置','第几次出现')
(6)、SUBSTR
substr(字段名,a,b):截取函数,截取字段中从第a位开始到b的字符串。
(7)、CHR
将ASCII码转换为字符
通常应用于对库表中字段是否存在空格Chr(32)、换行符Chr(10))、回车符Chr(13)、制表符Chr(9)等进行质检或拦截。
select * from TBL where instr(DS,Chr(10))>0
12.数字型函数
(1)、ROUND 返回按指定位数进行四舍五入的数值。
13.分组函数
(1)、COUNT
统计字段值的数目。可以用该函数来统计一个表中有多少条记录。
SELECT COUNT(字段名) FROM 表名
如果需要排除重复代码被计算次数,可结合关键字distinct 排重。
SELECT COUNT(distinct 字段名) FROM 表名
通常,使用COUNT(字段)时,字段中的空值将被忽略。
注意函数COUNT(*)没有指定任何字段。这个语句计算表中所有数目,包括有空值的记录。
(2)、AVG
计算字段的平均值
SELECT AVG (字段名) FROM 表名
注意round与AVG的组合使用,因为大多数平均数结果是无限长的,在Oracle中无法显示这类结果,所以需要结合round函数,限制计算结果的小数位数。
(3)、SUM
SELECT SUM(字段名) FROM 表名
(4)、MAX/MIN
返回最大值或最小值。
SELECT MAX/MIN(字段名) FROM 表名
(5)、GROUP BY
在select 语句中可以使用group by子句将行划分成较小的组,一旦使用分组后select操作的对象变为各个分组后的数据,使用聚组函数返回
SELECT 字段名, 聚集函数(字段名) FROM 表名 WHERE 字段名 条件值 GROUP BY 字段名 Order by 字段名
常用聚集函数有:COUNT,AVG,SUM,MAX/MIN
group by有一个原则,就是 select后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面,且出现的顺序必须与select后的相同。的是每一个组的汇总信息。
查询表(TBL)中各名称(Name)中有多少个人(num),按代码数量从多到少排序。
SELECT Name,count(num) FROM TBL GROUP BY Name order by count(num) desc
(6)、HAVING
因where不能放在GROUP BY后面,HAVING是跟GROUP BY连在一起用的,放在GROUP BY 后面,此时的作用相当于WHERE。WHERE后面的条件中不能有聚集函数,比如SUM(),AVG()等,而HAVING 可以。
SELECT 字段名, 聚集函数(字段名) FROM 表名 WHERE 字段名 条件值 GROUP BY 字段名 HAVING 聚集函数(字段名) 条件值
查询出表(TBL)中名称(Name)重复的记录。
SELECT Name , COUNT(*) FROM TBL GROUP BY Name HAVING COUNT(*) > 1
14.其他函数
(1)、NVL
NVL(expr1,expr2) 如果第一个参数为空那么显示第二个参数的值,如果第一个参数的值不为空,则显示第一个参数本来的值。
(2)、DECODE
decode(条件,值1,返回值1,值2,返回值2,...值n,返回值n,缺省值) 当条件=值1,则返回值1;当条件=值2,则返回值2;... 当条件=值n,则返回值n;其他返回缺省值
(3)、CASE
SELECT CASE WHEN "字段名"="条件1" THEN "结果 1" WHEN "字段名"= "条件 2" THEN "结果 2" ... [ELSE "结果 N"] END FROM "表格名"
#####















 1154
1154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









