









UNet 是一种用于图像分割任务的深度学习架构,最早由 Olaf Ronneberger、Philipp Fischer 和 Thomas Brox 在2015年的论文 "U-Net: Convolutional Networks for Biomedical Image Segmentation" 中提出。UNet 在医学图像分割等领域取得了显著的成功,但也可以用于其他图像分割任务。
UNet 的核心思想是将编码器和解码器结合在一起,形成一个 U 字形的网络结构。编码器部分用于逐渐减少空间分辨率和提取高级特征,而解码器部分则逐渐恢复分辨率并生成与输入图像相同大小的分割结果。UNet 的设计使得它能够在较小的数据集上有效地训练,并且在医学图像等领域中表现优异。
一、整体网络构架
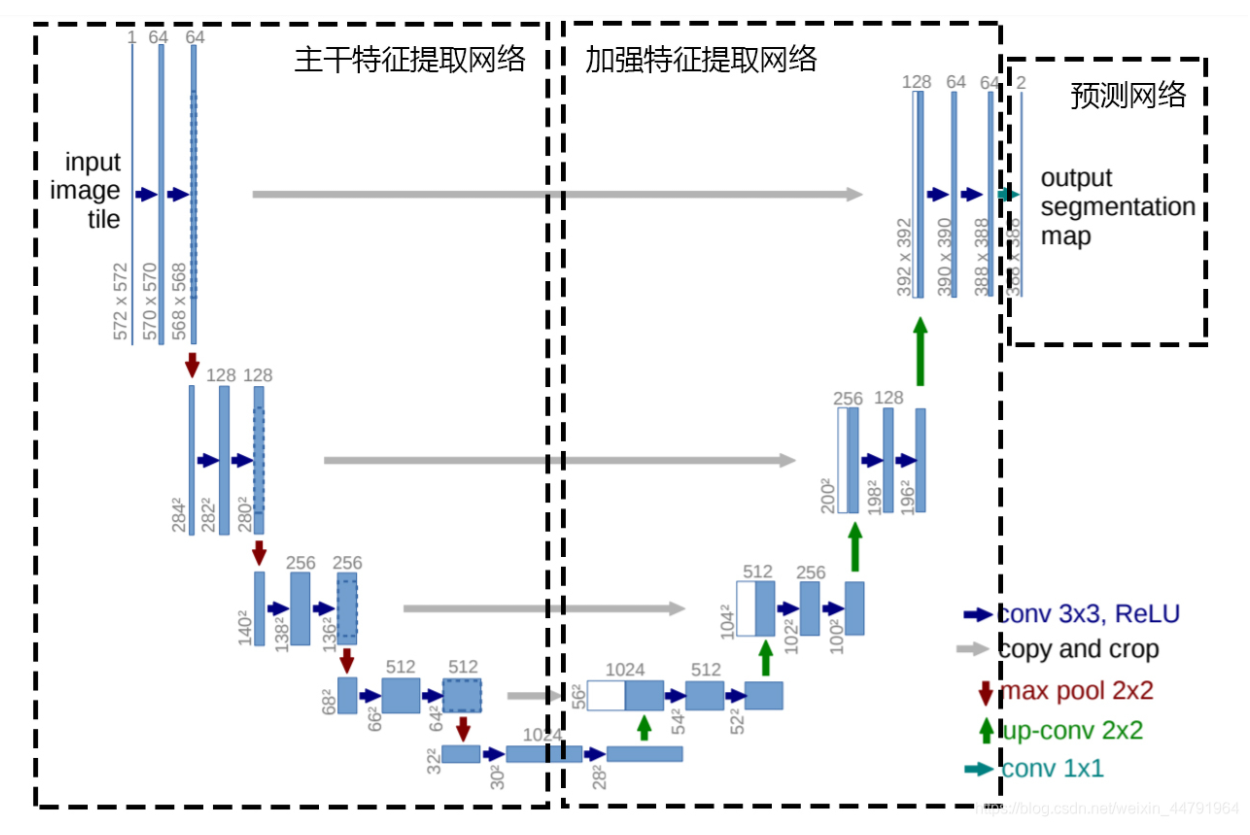
二、网络实现细节

三、代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models import vgg16
class unetUp(nn.Module):
def __init__(self, in_size, out_size):
super(unetUp, self).__init__()
self.conv1 = nn.Conv2d(in_size, out_size, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_size, out_size, kernel_size=3, padding=1)
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, inputs1, inputs2):
outputs = torch.cat([inputs1, self.up(inputs2)], 1)
outputs = self.conv1(outputs)
outputs = self.conv2(outputs)
return outputs
class Unet(nn.Module):
def __init__(self, num_classes=2, in_channels=3, pretrained=False):
super(Unet, self).__init__()
self.vgg = vgg16(pretrained=pretrained)
# self.vgg=self.vgg.features
in_filters = [192, 384, 768, 1024]
out_filters = [64, 128, 256, 512]
# upsampling
self.up_concat4 = unetUp(in_filters[3], out_filters[3])
self.up_concat3 = unetUp(in_filters[2], out_filters[2])
self.up_concat2 = unetUp(in_filters[1], out_filters[1])
self.up_concat1 = unetUp(in_filters[0], out_filters[0])
# final conv (without any concat)
self.final = nn.Conv2d(out_filters[0], num_classes, 1)
def forward(self, inputs):
feat1 = self.vgg.features[:4](inputs)
feat2 = self.vgg.features[4:9](feat1)
feat3 = self.vgg.features[9:16](feat2)
feat4 = self.vgg.features[16:23](feat3)
feat5 = self.vgg.features[23:-1](feat4)
up4 = self.up_concat4(feat4, feat5)
up3 = self.up_concat3(feat3, up4)
up2 = self.up_concat2(feat2, up3)
up1 = self.up_concat1(feat1, up2)
final = self.final(up1)
return final
def _initialize_weights(self, *stages):
for modules in stages:
for module in modules.modules():
if isinstance(module, nn.Conv2d):
nn.init.kaiming_normal_(module.weight)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm2d):
module.weight.data.fill_(1)
module.bias.data.zero_()
if __name__=="__main__":
model=Unet()
# model=model.cuda()
image=torch.randn((1,3,512,512))
# image=image.cuda()
print(model(image))
output=model(image)
print(output.size())
print(model)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











