






因为数据处理需要用到.txt文件,但是现在只有.mat文件,所以一次性将所有.mat文件转化为.txt文件。为了示例,我将.mat文件夹放在了桌面,里面有30个.mat文件,在桌面建一个用来放置.txt文件的空文件夹。

# 导入包
import scipy.io as sio
import numpy as np
import os# 先读取单个mat文件来看看mat文件的长什么样
matdata = sio.loadmat("C:/Users/24698/Desktop/mat_file/0001.mat")
matdata
# 提取数据:是以字典的形式存储的,看有哪些key,确认自己需要哪部分信息
matdata.keys()
![]()
# 这里我只需要"KLS_mat"中的信息,将该信息存为txt文件
data = matdata["KLS_mat"]
data 
# 下面是正式开始批量处理啦
# 读取存放批量.mat的文件夹中的所有.mat文件的文件名
mat_filename_list = os.listdir("C:/Users/24698/Desktop/mat_file")
mat_filename_list 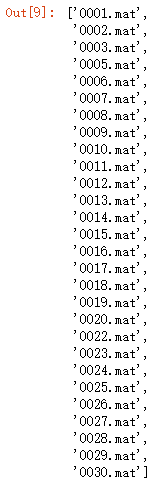
# 批量转化 mat 文件为 txt 文件并保存在桌面的 txt_file 文件夹中
for mat_filename in mat_filename_list:
matdata = sio.loadmat("C:/Users/24698/Desktop/mat_file/" + mat_filename)
data = matdata["KLS_mat"]
txt_filename = mat_filename[:4] + ".txt" # 例如将“0001.mat” 改为 “0001.txt”
savetxt_path = "C:/Users/24698/Desktop/txt_file/" + txt_filename
np.savetxt(savetxt_path, data, fmt="%0.8") # fmt为保存格式,可不填,会以默认格式保存

完成!!!
更新:
朋友们,很抱歉啊,因为不经常看消息,所以回复很不及时,基本回复的时候你们问题都解决了吧,但为了之后的人看到同样问题的解决方法和出于礼貌,虽不及时我还是会回复的。对于一些问题我重新编辑一下写在下面
问题1:怎么保存为 csv 文件,原文其实也都给了一个基本思路啊。将 data 处理成 csv 数据格式DataFrame,然后使用 .to_csv()保存
# 可以看我需要的数据原本就是 array 数组数据,所以我可以直接保存为txt文件
# 大家需要保存什么类型文件一定要处理成匹配的数据格式,不然会报错
# 下面给出单个文件处理,想批量处理套进循环里就可以了
import pandas as pd
matdata = sio.loadmat("mat文件地址")
data = matdata["所需数据的key"] # 假设这里data和我的一样是array数组
data = pd.DataFrame(data)
data.tp_csv("csv文件保存地址")问题2:想保存多个key的数据。这里分成两部分,一个是每个key数据保存一个文件,另一个是一个mat文件中的多个key保存为一个文件。
# 一个key保存一个文件:分别提取分别保存呗
data1 = matdata["所需数据的key1"]
data2 = matdata["所需数据的key2"]
...
np.savetxt("txt文件保存路径", data1)
np.savetxt("txt文件保存路径", data2)
...# 多个key保存一个文件:数据拼接,注意数据拼接对数据的shape是有要求的
# 将提取的 data1, data2, ..., datan 拼接成一个data,然后保存data
# 数据拼接涉及数据格式,数据维度,比较杂,这里给出涉及到的函数,具体的可以自己去学习
# array 数据拼接,用到 numpy 包
array1 = np.vander([3,4,5]) //# array1.shape = (3,3)
array2 = np.vander([1,2,3]) //# array2.shape = (3,3)
np.vstack([array1, array2]) //# shape = (6,3), 行拼接,纵向拼接,即行数增加
np.hstack([array1, array2]) //# shape = (3,6),列拼接,横向拼接,即列数增加
np.stack([array1, array2]) //# shape = (2,3,3),维度拼接,即将每一个数组作为一个整体进行拼接
# DataFrame 数据拼接,用到 pandas 包
pd.concat([data1,data2], axis=0) # axis=0是列数不变,行连接,axis=1是行数不变,列连接













 4488
4488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









