







XML
XML概述
- XML是可扩展标记语言(eXtensible Markup Language)的缩写,它是是一种数据表示格式,可以描述非常复杂的数据结构,常用于传输和存储数据。
XML的几个特点和使用场景:
- 一是纯文本,默认使用UTF-8编码;二是可嵌套;
- 如果把XML内容存为文件,那么它就是一个XML文件。
- XML的使用场景:XML内容经常被当成消息进行网络传输,或者作为配置文件用于存储系统的信息。
XML的创建、语法规则
XML的创建
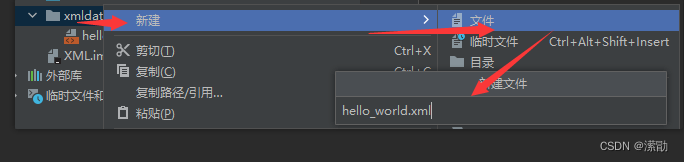
- 就是创建一个XML类型的文件,要求文件的后缀必须使用xml,如hello_world.xml
IDEA创建XML文件的操作步骤:
XML的语法规则
- XML文件的后缀名为:xml
- 文档声明必须是第一行

XML的标签(元素)规则:
- 标签由一对尖括号和合法标识符组成:< name >< /name >,必须存在一个根标签,有且只能有一个。
- 标签必须成对出现,有开始,有结束:< name >< /name >
- 特殊的标签可以不成对,但是必须有结束标记,如:< br/ >
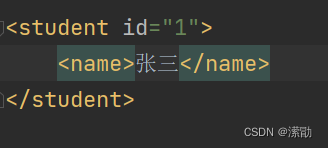
- 标签中可以定义属性,属性和标签名空格隔开,属性值必须用引号引起来**< student id = “1” >< /student >**
- 标签需要正确的嵌套
XML的其他组成:
- XML文件中可以定义注释信息:< !–注释内容-- >
- XML文件中可以存在以下特殊字符

- XML文件中可以存在CDATA区:< ![CDATA[ …内容.….]] >
<?xml version="1.0" encoding="UTF-8" ?>
<!-- 注释:根标签有且仅能有一个 -->
<student>
<name>女儿国王</name>
<sex>女</sex>
<hobby>唐僧,追唐僧</hobby>
<info>
<age>30</age>
<addr>女儿国</addr>
</info>
<sql>
select * from user where age < 18;
select * from user where age < 18 && age > 10
<![CDATA[
select * from user where age < 18
]]>
</sql>
</student>
XML文档约束方式一-DTD约束[了解]
- 文档约束:是用来限定xml文件中的标签以及属性应该怎么写。
- 以此强制约束程序员必须按照文档约束的规定来编写xml文件。
文档约束的分类:
- DTD
- schema
DTD的使用:
需求:
- 利用DTD文档约束,约束一个XML文件的编写。
分析:
- 编写DTD约束文档,后缀必须是.dtd
<!ELEMENT 书架 (书+)>
<!ELEMENT 书 (书名,作者,售价)>
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>
- 在需要编写的XML文件中导入该DTD约束文档
- 按照约束的规定编写XML文件的内容。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE 书架 SYSTEM "data.dtd">
<书架>
<书>
<书名>精通JavaSE加强</书名>
<作者>dlei</作者>
<售价>很贵</售价>
</书>
<书>
<书名></书名>
<作者></作者>
<售价></售价>
</书>
</书架>
XML文档约束方式二-schema约束[了解]
- schema可以约束具体的数据类型,约束能力上更强大。
- schema本身也是一个xml文件,本身也受到其他约束文件的要求,所以编写的更加严谨

schema的使用:
需求:
- 利用schema文档约束,约束一个XML文件的编写。
分析:
- 编写schema约束文档,后缀必须是.xsd,具体的形式到代码中观看
- 在需要编写的XML文件中导入该schema约束文档
- 按照约束内容编写XML文件的标签。
<?xml version="1.0" encoding="UTF-8" ?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itcast.cn"
elementFormDefault="qualified" >
<!-- targetNamespace:申明约束文档的地址(命名空间)-->
<element name='书架'>
<!-- 写子元素 -->
<complexType>
<!-- maxOccurs='unbounded': 书架下的子元素可以有任意多个!-->
<sequence maxOccurs='unbounded'>
<element name='书'>
<!-- 写子元素 -->
<complexType>
<sequence>
<element name='书名' type='string'/>
<element name='作者' type='string'/>
<element name='售价' type='double'/>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
<?xml version="1.0" encoding="UTF-8" ?>
<书架 xmlns="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn data.xsd">
<!-- xmlns="http://www.itcast.cn" 基本位置
xsi:schemaLocation="http://www.itcast.cn books02.xsd" 具体的位置 -->
<书>
<书名>神雕侠侣</书名>
<作者>金庸</作者>
<售价>399.9</售价>
</书>
<书>
<书名>神雕侠侣</书名>
<作者>金庸</作者>
<售价>19.5</售价>
</书>
</书架>
XML解析技术
XML解析技术概述
什么是XML解析:
- 使用程序读取XML中的数据
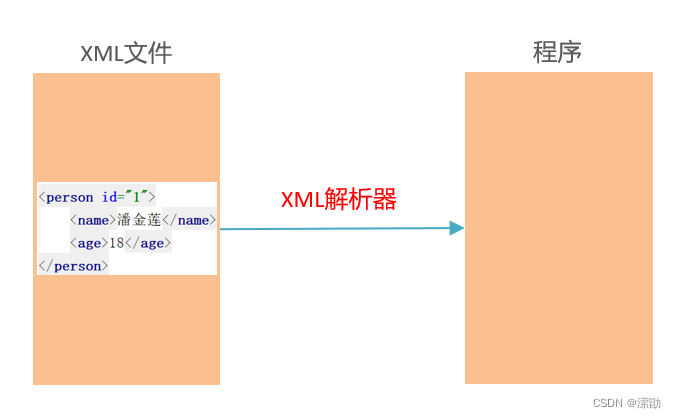
两种解析方式
- SAX解析
- DOM解析
Dom常见的解析工具:

DOM解析解析文档对象模型:


Dom4]解析XML文件
使用Dom4J解析出XML文件:
需求:
- 使用Dom4J把一个XML文件的数据进行解析
分析:
- 下载Dom4j框架,官网下载。
- 在项目中创建一个文件夹:lib
- 将dom4j-2.1.3.jar文件复制到 lib 文件夹
- 在jar文件上点右键,选择 Add as Library(添加为库…) -> 点击OK
- 在类中导包使用
Dom4j解析XML-得到Document对象:
- SAXReader类

- Document类

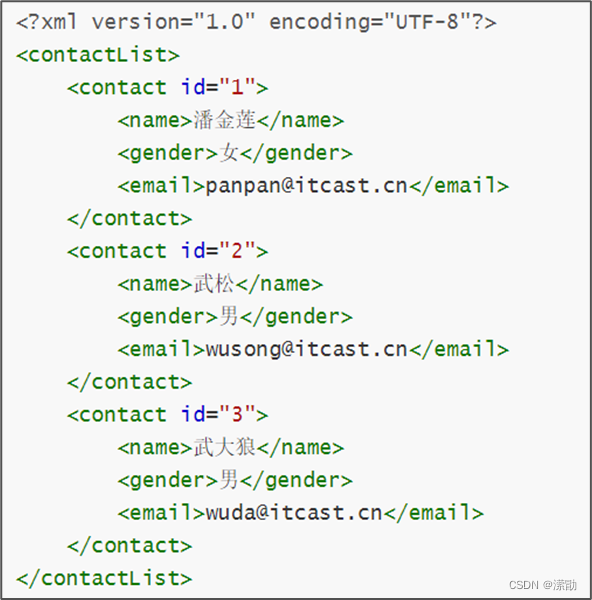
Contacts.xml:
<?xml version="1.0" encoding="UTF-8"?>
<contactList>
<contact id="1" vip="true">
<name> 潘金莲 </name>
<gender>女</gender>
<email>panpan@itcast.cn</email>
</contact>
<contact id="2" vip="false">
<name>武松</name>
<gender>男</gender>
<email>wusong@itcast.cn</email>
</contact>
<contact id="3" vip="false">
<name>武大狼</name>
<gender>男</gender>
<email>wuda@itcast.cn</email>
</contact>
<user>
</user>
</contactList>
@Test
public void parseXMLData() throws Exception {
// 1、创建一个Dom4j的解析器对象,代表了整个dom4j框架
SAXReader saxReader = new SAXReader();
// 2、把XML文件加载到内存中成为一个Document文档对象
//Document document = saxReader.read(new File("src\\Contacts.xml")); // 需要通过模块名去定位
//Document document = saxReader.read(new FileInputStream("src\\Contacts.xml"));
// 注意: getResourceAsStream中的/是直接去src下寻找的文件
InputStream is = Dom4JHelloWorldDemo1.class.getResourceAsStream("/Contacts.xml");
Document document = saxReader.read(is);
// 3、获取根元素对象
Element root = document.getRootElement();
System.out.println(root.getName());
}
Dom4J解析XML文件中的各种节点
Dom4j解析XML的元素、属性、文本

@Test
public void parseXMLData() throws Exception {
// 1、创建一个Dom4j的解析器对象,代表了整个dom4j框架
SAXReader saxReader = new SAXReader();
// 2、把XML文件加载到内存中成为一个Document文档对象
//Document document = saxReader.read(new File("src\\Contacts.xml")); // 需要通过模块名去定位
//Document document = saxReader.read(new FileInputStream("src\\Contacts.xml"));
// 注意: getResourceAsStream中的/是直接去src下寻找的文件
InputStream is = Dom4JHelloWorldDemo1.class.getResourceAsStream("/Contacts.xml");
Document document = saxReader.read(is);
// 3、获取根元素对象
Element root = document.getRootElement();
System.out.println(root.getName());
// 4、拿根元素下的全部子元素对象(一级)
// List<Element> sonEles = root.elements();
List<Element> sonEles = root.elements("contact");
for (Element sonEle : sonEles) {
System.out.println(sonEle.getName());
}
// 拿某个子元素
Element userEle = root.element("user");
System.out.println(userEle.getName());
// 默认提取第一个子元素对象 (Java语言。)
Element contact = root.element("contact");
// 获取子元素文本
System.out.println(contact.elementText("name"));
// 去掉前后空格
System.out.println(contact.elementTextTrim("name"));
// 获取当前元素下的子元素对象
Element email = contact.element("email");
System.out.println(email.getText());
// 去掉前后空格
System.out.println(email.getTextTrim());
// 根据元素获取属性值
Attribute idAttr = contact.attribute("id");
System.out.println(idAttr.getName() + "-->" + idAttr.getValue());
// 直接提取属性值
System.out.println(contact.attributeValue("id"));
System.out.println(contact.attributeValue("vip"));
}
Dom4J解析XML文件-案例实战
需求:
- 利用Dom4J的知识,将Contact.xml文件中的联系人数据封装成List集合,其中每个元素是实体类Contact。打印输出 List 中的每个元素。

/**
<contact id="1" vip="true">
<name> 潘金莲 </name>
<gender>女</gender>
<email>panpan@itcast.cn</email>
</contact>
*/
private String name;
private int id;
private boolean vip;
private char gender;
private String email;
public Contact() {
}
public Contact(String name, int id, boolean vip, char gender, String email) {
this.name = name;
this.id = id;
this.vip = vip;
this.gender = gender;
this.email = email;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public boolean isVip() {
return vip;
}
public void setVip(boolean vip) {
this.vip = vip;
}
public char getGender() {
return gender;
}
public void setGender(char gender) {
this.gender = gender;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
@Override
public String toString() {
return "Contact{" +
"name='" + name + '\'' +
", id=" + id +
", vip=" + vip +
", gender=" + gender +
", email='" + email + '\'' +
'}';
}
@Test
public void parseToList() throws Exception {
// 需求:解析XML中的数据成为一个List集合对象。
// 1、导入框架(做过)
// 2、创建SaxReader对象
SAXReader saxReader = new SAXReader();
// 3、加载XML文件成为文档对象Document对象。
Document document = saxReader.read(Dom4JTest2.class.getResourceAsStream("/Contacts.xml"));
// 4、先拿根元素
Element root = document.getRootElement();
// 5、提取contact子元素
List<Element> contactEles = root.elements("contact");
// 6、准备一个ArrayList集合封装联系人信息
List<Contact> contacts = new ArrayList<>();
// 7、遍历Contact子元素
for (Element contactEle : contactEles) {
// 8、每个子元素都是一个联系人对象
Contact contact = new Contact();
contact.setId(Integer.valueOf(contactEle.attributeValue("id")));
contact.setVip(Boolean.valueOf(contactEle.attributeValue("vip")));
contact.setName(contactEle.elementTextTrim("name"));
contact.setGender(contactEle.elementTextTrim("gender").charAt(0));
contact.setEmail(contactEle.elementText("email"));
// 9、把联系人对象数据加入到List集合
contacts.add(contact);
}
// 10、遍历List集合
for (Contact contact : contacts) {
System.out.println(contact);
}
}
XML检索技术:Xpath
XPath介绍
- XPath在解析XML文档方面提供了一独树一帜的路径思想,更加优雅,高效
- XPath使用路径表达式来定位XML文档中的元素节点或属性节点。
示例
-
/元素/子元素/孙元素
-
//子元素//孙元素
使用Xpath检索出XML文件:
需求:
- 使用Dom4J把一个XML文件的数据进行解析
分析:
-
导入jar包(dom4j和jaxen-1.1.2.jar),Xpath技术依赖Dom4j技术
-
通过dom4j的SAXReader获取Document对象
-
利用XPath提供的API,结合XPath的语法完成选取XML文档元素节点进行解析操作。
-
Document中与Xpath相关的API如下:

Xpath的四大检索方案
- 绝对路径
- 相对路径
- 全文检索
- 属性查找
XPath:绝对路径:
- 采用绝对路径获取从根节点开始逐层的查找/contactList/contact/name节点列表并打印信息

XPath:相对路径:
- 先得到根节点contactList
- 再采用相对路径获取下一级contact 节点的name子节点并打印信息

XPath:全文搜索:
- 直接全文搜索所有的name元素并打印

XPath:属性查找:
- 在全文中搜索属性,或者带属性的元素

Contacts2.xml:
<?xml version="1.0" encoding="UTF-8"?>
<contactList>
<contact id="1" vip="true">
<name> 潘金莲 </name>
<gender>女</gender>
<email>panpan@itcast.cn</email>
</contact>
<contact id="2" vip="false">
<name>武松</name>
<gender>男</gender>
<email>wusong@itcast.cn</email>
</contact>
<contact id="3" vip="false">
<name>武大狼</name>
<gender>男</gender>
<email>wuda@itcast.cn</email>
</contact>
<user>
<contact>
<info>
<name id="888">我是西门庆</name>
</info>
</contact>
</user>
</contactList>
@Test
public void parse01() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、检索全部的名称
List<Node> nameNodes = document.selectNodes("/contactList/contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}
/**
2.相对路径: ./子元素/子元素。 (.代表了当前元素)
*/
@Test
public void parse02() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
Element root = document.getRootElement();
// c、检索全部的名称
List<Node> nameNodes = root.selectNodes("./contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}
/**
3.全文搜索:
//元素 在全文找这个元素
//元素1/元素2 在全文找元素1下面的一级元素2
//元素1//元素2 在全文找元素1下面的全部元素2
*/
@Test
public void parse03() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、检索数据
//List<Node> nameNodes = document.selectNodes("//name");
// List<Node> nameNodes = document.selectNodes("//contact/name");
List<Node> nameNodes = document.selectNodes("//contact//name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}
/**
4.属性查找。
//@属性名称 在全文检索属性对象。
//元素[@属性名称] 在全文检索包含该属性的元素对象。
//元素[@属性名称=值] 在全文检索包含该属性的元素且属性值为该值的元素对象。
*/
@Test
public void parse04() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、检索数据
List<Node> nodes = document.selectNodes("//@id");
for (Node node : nodes) {
Attribute attr = (Attribute) node;
System.out.println(attr.getName() + "===>" + attr.getValue());
}
// 查询name元素(包含id属性的)
//Node node = document.selectSingleNode("//name[@id]");
Node node = document.selectSingleNode("//name[@id=888]");
Element ele = (Element) node;
System.out.println(ele.getTextTrim());
}
设计模式:工厂模式
- 之前我们创建类对象时, 都是使用new 对象的形式创建,在很多业务场景下也提供了不直接new的方式 。
- 工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一, 这种类型的设计模式属于创建型模式,它提供了一种获取对象的方式。
工厂设计模式的作用:
- 工厂的方法可以封装对象的创建细节,比如:为该对象进行加工和数据注入。
- 可以实现类与类之间的解耦操作(核心思想)。
public abstract class Computer {
private String name;
private double price;
public abstract void start();
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
}
public class Huawei extends Computer{
@Override
public void start() {
System.out.println(getName() + "开机了,展示了华为的菊花图标~~~~");
}
}
public class Mac extends Computer{
@Override
public void start() {
System.out.println(getName() + "以非常优雅的方法启动了,展示了一个苹果logo");
}
}
public class FactoryPattern {
/**
定义一个方法,创建对象返回
*/
public static Computer createComputer(String info){
switch (info){
case "huawei":
Computer c = new Huawei();
c.setName("huawei pro 16");
c.setPrice(5999);
return c;
case "mac":
Computer c2 = new Mac();
c2.setName("MacBook pro");
c2.setPrice(11999);
return c2;
default:
return null;
}
}
}
public class FactoryDemo {
public static void main(String[] args) {
Computer c1 = FactoryPattern.createComputer("huawei");
c1.start();
Computer c2 = FactoryPattern.createComputer("mac");
c2.start();
}
}
设计模式:装饰模式
- 创建一个新类,包装原始类,从而在新类中提升原来类的功能。
装饰设计模式的作用:
- 作用:装饰模式指的是在不改变原类的基础上, 动态地扩展一个类的功能。

- 定义父类。
- 定义原始类,继承父类,定义功能。
- 定义装饰类,继承父类,包装原始类,增强功能!!
/**
共同父类
*/
public abstract class InputStream {
public abstract int read();
public abstract int read(byte[] buffer);
}
/**
原始类
*/
public class FileInputStream extends InputStream{
@Override
public int read() {
System.out.println("低性能的方式读取了一个字节a");
return 97;
}
@Override
public int read(byte[] buffer) {
buffer[0] = 97;
buffer[1] = 98;
buffer[2] = 99;
System.out.println("低性能的方式读取了一个字节数组:" + Arrays.toString(buffer));
return 3;
}
}
/**
装饰类:继承InputStream 拓展原始类的功能
*/
public class BufferedInputStream extends InputStream{
private InputStream is;
public BufferedInputStream(InputStream is){
this.is = is;
}
@Override
public int read() {
System.out.println("提供8KB的缓冲区,提高读数据性能~~~~");
return is.read();
}
@Override
public int read(byte[] buffer) {
System.out.println("提供8KB的缓冲区,提高读数据性能~~~~");
return is.read(buffer);
}
}
/**
装饰模式
定义父类:InputStream
定义实现类:FileInputStream 继续父类 定义功能
定义装饰实现类:BufferedInputStream 继承父类 定义功能 包装原始类,增强功能。
*/
public class DecoratorPattern {
public static void main(String[] args) {
InputStream is = new BufferedInputStream(new FileInputStream());
System.out.println(is.read());
System.out.println(is.read(new byte[3]));
}
}















 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









