







买卖股票的最佳时机II
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
- 输入: [7,1,5,3,6,4]
- 输出: 7
- 解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
示例 2:
- 输入: [1,2,3,4,5]
- 输出: 4
- 解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
示例 3:
- 输入: [7,6,4,3,1]
- 输出: 0
- 解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
提示:
- 1 <= prices.length <= 3 * 10 ^ 4
- 0 <= prices[i] <= 10 ^ 4
假如第0天买入,第3天卖出,那么利润为:prices[3] - prices[0]。
相当于(prices[3] - prices[2]) + (prices[2] - prices[1]) + (prices[1] - prices[0])。
此时就是把利润分解为每天为单位的维度,而不是从0天到第3天整体去考虑!
那么根据prices可以得到每天的利润序列:(prices[i] - prices[i - 1]).....(prices[1] - prices[0])。
如图:
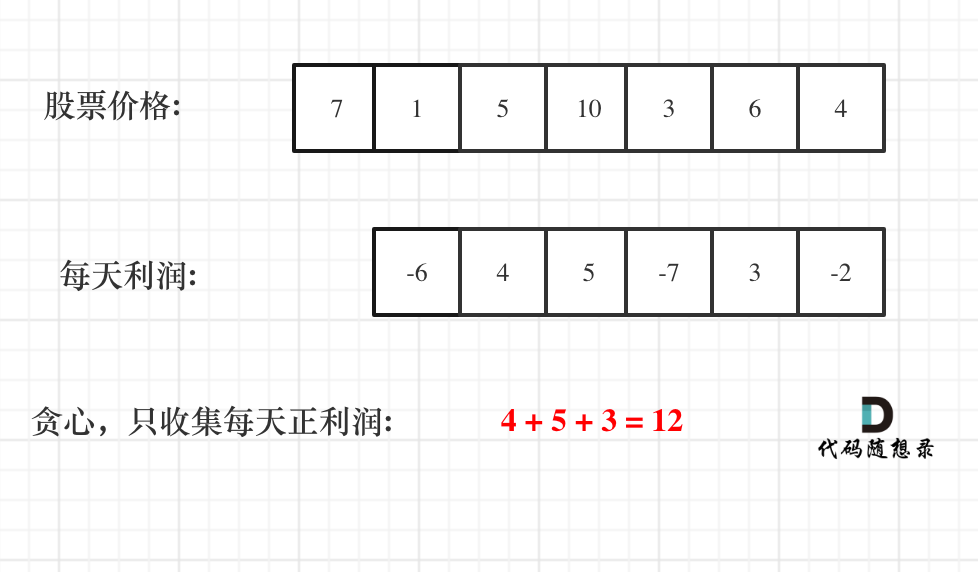
收集正利润的区间,就是股票买卖的区间,而我们只需要关注最终利润,不需要记录区间。
局部最优:收集每天的正利润,全局最优:求得最大利润。
class Solution:
def maxProfit(self, prices: List[int]) -> int:
result = 0
for i in range(1, len(prices)):
result += max(prices[i] - prices[i - 1], 0)
return result跳跃游戏
给定一个非负整数数组,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个位置。
示例 1:
- 输入: [2,3,1,1,4]
- 输出: true
- 解释: 我们可以先跳 1 步,从位置 0 到达 位置 1, 然后再从位置 1 跳 3 步到达最后一个位置。
示例 2:
- 输入: [3,2,1,0,4]
- 输出: false
- 解释: 无论怎样,你总会到达索引为 3 的位置。但该位置的最大跳跃长度是 0 , 所以你永远不可能到达最后一个位置。
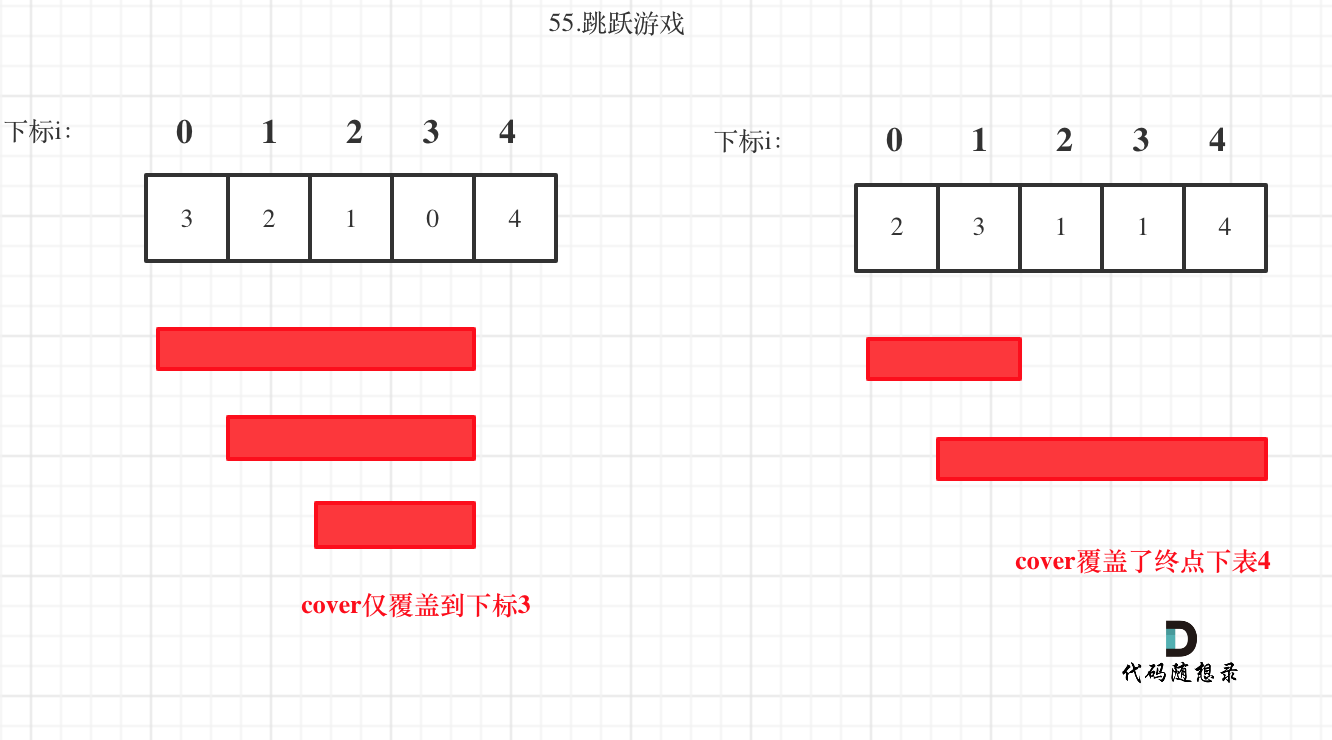
那么这个问题就转化为跳跃覆盖范围究竟可不可以覆盖到终点!
每次移动取最大跳跃步数(得到最大的覆盖范围),每移动一个单位,就更新最大覆盖范围。
贪心算法局部最优解:每次取最大跳跃步数(取最大覆盖范围),整体最优解:最后得到整体最大覆盖范围,看是否能到终点。
局部最优推出全局最优,找不出反例,试试贪心!
如图:
class Solution:
def canJump(self, nums: List[int]) -> bool:
cover = 0
if len(nums) == 1: return True
i = 0
# python不支持动态修改for循环中变量,使用while循环代替
while i <= cover:
cover = max(i + nums[i], cover)
if cover >= len(nums) - 1: return True
i += 1
return False跳跃游戏II
给定一个非负整数数组,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
你的目标是使用最少的跳跃次数到达数组的最后一个位置。
示例:
- 输入: [2,3,1,1,4]
- 输出: 2
- 解释: 跳到最后一个位置的最小跳跃数是 2。从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。
说明: 假设你总是可以到达数组的最后一个位置。
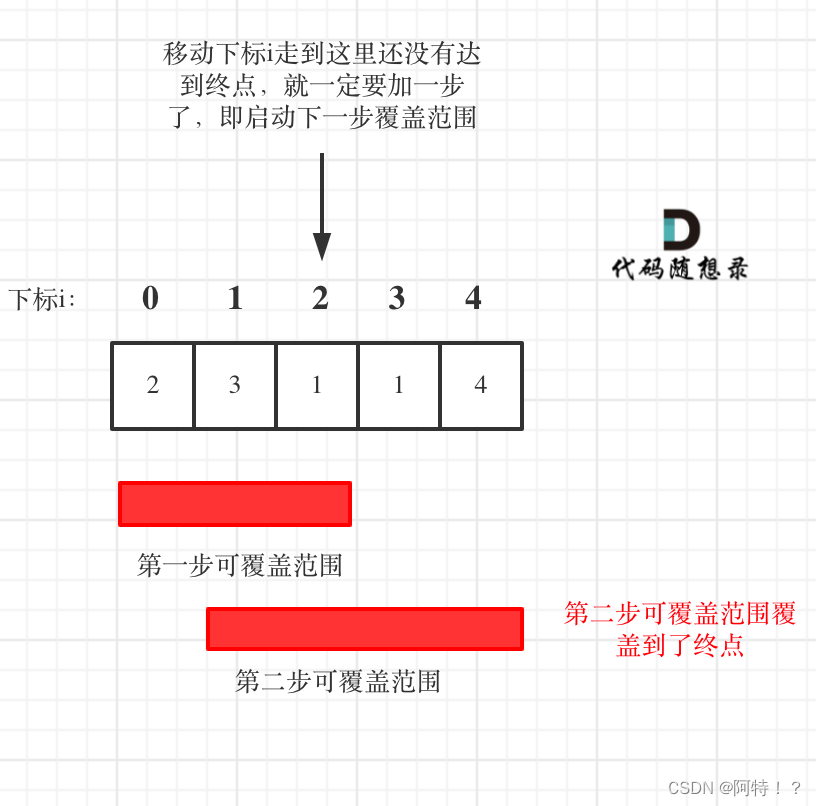
class Solution:
def jump(self, nums: List[int]) -> int:
if len(nums) == 1:
return 0
res, curDistance, nextDistance = 0, 0, 0
for i in range(len(nums)):
nextDistance = max(i + nums[i], nextDistance)
if i == curDistance:
res += 1
curDistance = nextDistance
if nextDistance >= len(nums) - 1:break
return resK次取反后最大化的数组和
给定一个整数数组 A,我们只能用以下方法修改该数组:我们选择某个索引 i 并将 A[i] 替换为 -A[i],然后总共重复这个过程 K 次。(我们可以多次选择同一个索引 i。)
以这种方式修改数组后,返回数组可能的最大和。
示例 1:
- 输入:A = [4,2,3], K = 1
- 输出:5
- 解释:选择索引 (1,) ,然后 A 变为 [4,-2,3]。
示例 2:
- 输入:A = [3,-1,0,2], K = 3
- 输出:6
- 解释:选择索引 (1, 2, 2) ,然后 A 变为 [3,1,0,2]。
示例 3:
- 输入:A = [2,-3,-1,5,-4], K = 2
- 输出:13
- 解释:选择索引 (1, 4) ,然后 A 变为 [2,3,-1,5,4]。
提示:
- 1 <= A.length <= 10000
- 1 <= K <= 10000
- -100 <= A[i] <= 100
关于sorted()函数介绍,sorted(),第一个参数是对象,第二个参数key是类型排序,第三个reverse是是否翻转顺序,由大到小。
那么本题的解题步骤为:
- 第一步:将数组按照绝对值大小从大到小排序,注意要按照绝对值的大小
- 第二步:从前向后遍历,遇到负数将其变为正数,同时K--
- 第三步:如果K还大于0,那么反复转变数值最小的元素,将K用完
- 第四步:求和
class Solution:
def largestSumAfterKNegations(self, nums: List[int], k: int) -> int:
nums = sorted(nums, key = abs, reverse = True)
for i in range(len(nums)):
if k > 0 and nums[i] < 0:
nums[i] *= -1
k -= 1
if k > 0:
nums[-1] *= (-1)**k
return sum(nums)加油站
在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
说明:
- 如果题目有解,该答案即为唯一答案。
- 输入数组均为非空数组,且长度相同。
- 输入数组中的元素均为非负数。
示例 1: 输入:
- gas = [1,2,3,4,5]
- cost = [3,4,5,1,2]
输出: 3 解释:
- 从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
- 开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
- 开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
- 开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
- 开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
- 开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
- 因此,3 可为起始索引。
示例 2: 输入:
-
gas = [2,3,4]
-
cost = [3,4,3]
-
输出: -1
-
解释: 你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油。开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油。开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油。你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。因此,无论怎样,你都不可能绕环路行驶一周。
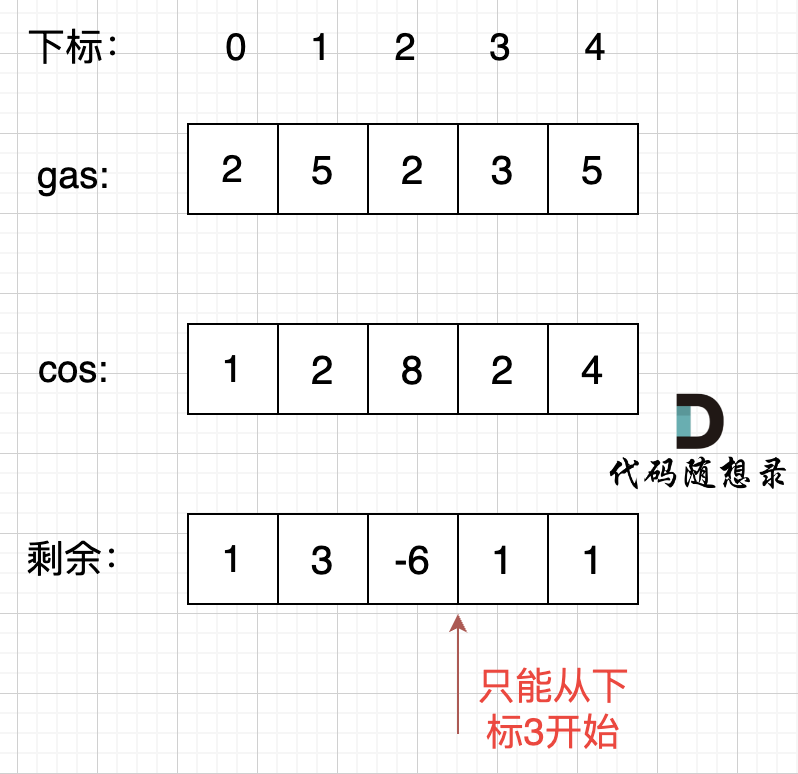
可以换一个思路,首先如果总油量减去总消耗大于等于零那么一定可以跑完一圈,说明 各个站点的加油站 剩油量rest[i]相加一定是大于等于零的。
每个加油站的剩余量rest[i]为gas[i] - cost[i]。
i从0开始累加rest[i],和记为curSum,一旦curSum小于零,说明[0, i]区间都不能作为起始位置,因为这个区间选择任何一个位置作为起点,到i这里都会断油,那么起始位置从i+1算起,再从0计算curSum。
如图:
# 解法2
class Solution:
def canCompleteCircuit(self, gas: List[int], cost: List[int]) -> int:
start = 0
curSum = 0
totalSum = 0
for i in range(len(gas)):
curSum += gas[i] - cost[i]
totalSum += gas[i] - cost[i]
if curSum < 0:
curSum = 0
start = i + 1
if totalSum < 0: return -1
return start分发糖果
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
你需要按照以下要求,帮助老师给这些孩子分发糖果:
- 每个孩子至少分配到 1 个糖果。
- 相邻的孩子中,评分高的孩子必须获得更多的糖果。
那么这样下来,老师至少需要准备多少颗糖果呢?
示例 1:
- 输入: [1,0,2]
- 输出: 5
- 解释: 你可以分别给这三个孩子分发 2、1、2 颗糖果。
示例 2:
- 输入: [1,2,2]
- 输出: 4
- 解释: 你可以分别给这三个孩子分发 1、2、1 颗糖果。第三个孩子只得到 1 颗糖果,这已满足上述两个条件。
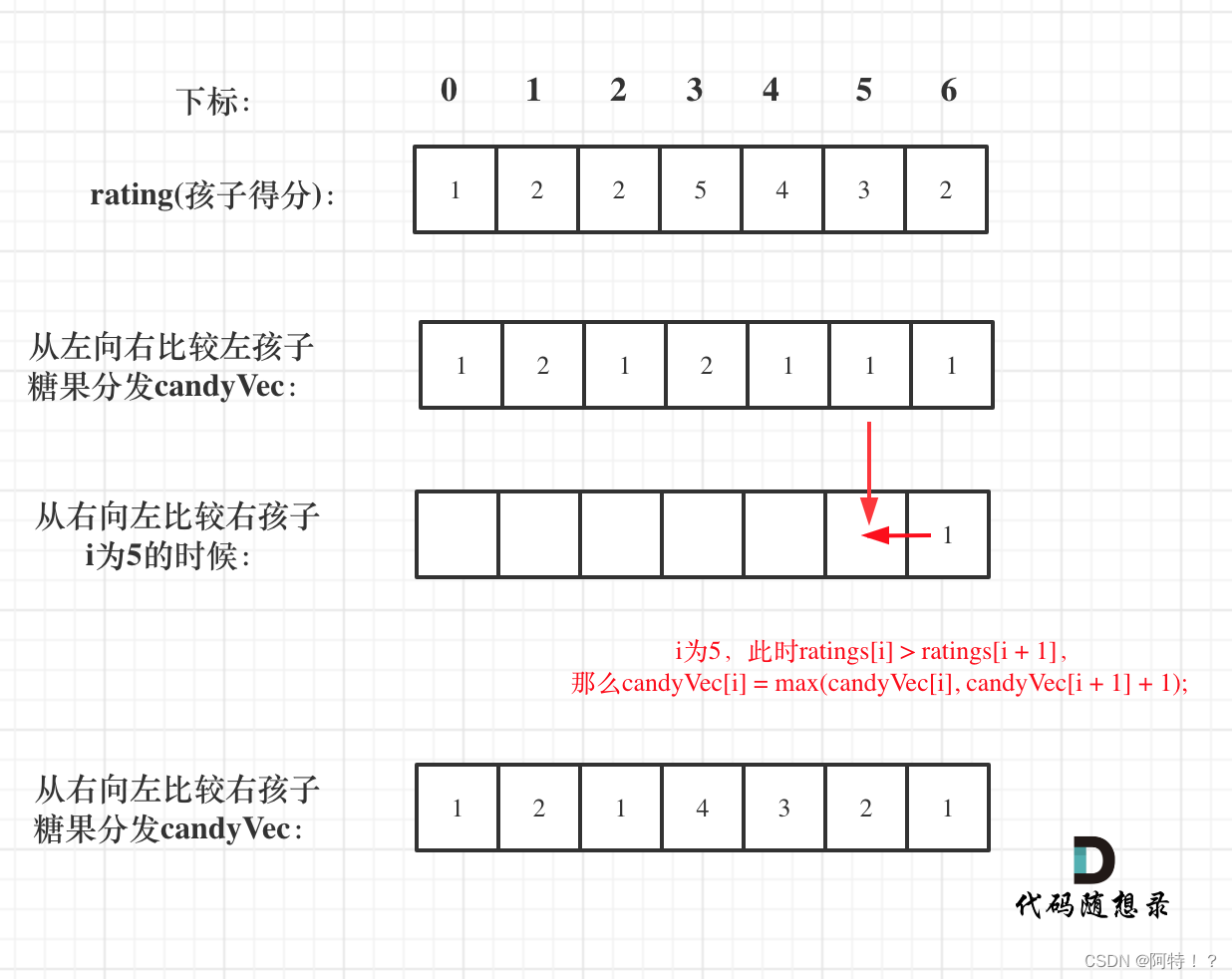
这道题目一定是要确定一边之后,再确定另一边,例如比较每一个孩子的左边,然后再比较右边,如果两边一起考虑一定会顾此失彼。
先确定右边评分大于左边的情况(也就是从前向后遍历)
此时局部最优:只要右边评分比左边大,右边的孩子就多一个糖果,全局最优:相邻的孩子中,评分高的右孩子获得比左边孩子更多的糖果
局部最优可以推出全局最优。
如果ratings[i] > ratings[i - 1] 那么[i]的糖 一定要比[i - 1]的糖多一个,所以贪心:candyVec[i] = candyVec[i - 1] + 1
所以确定左孩子大于右孩子的情况一定要从后向前遍历!
如果 ratings[i] > ratings[i + 1],此时candyVec[i](第i个小孩的糖果数量)就有两个选择了,一个是candyVec[i + 1] + 1(从右边这个加1得到的糖果数量),一个是candyVec[i](之前比较右孩子大于左孩子得到的糖果数量)。
那么又要贪心了,局部最优:取candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,保证第i个小孩的糖果数量既大于左边的也大于右边的。全局最优:相邻的孩子中,评分高的孩子获得更多的糖果。
所以就取candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,candyVec[i]只有取最大的才能既保持对左边candyVec[i - 1]的糖果多,也比右边candyVec[i + 1]的糖果多。
class Solution:
def candy(self, ratings: List[int]) -> int:
candyVec = [1] * len(ratings)
for i in range(1, len(ratings)):
if ratings[i] > ratings[i - 1]:
candyVec[i] = candyVec[i - 1] + 1
for j in range(len(ratings) - 2, -1, -1):
if ratings[j] > ratings[j + 1]:
candyVec[j] = max(candyVec[j], candyVec[j + 1] + 1)
return sum(candyVec)柠檬水找零
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。
顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
示例 1:
- 输入:[5,5,5,10,20]
- 输出:true
- 解释:
- 前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
- 第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
- 第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
- 由于所有客户都得到了正确的找零,所以我们输出 true。
示例 2:
- 输入:[5,5,10]
- 输出:true
示例 3:
- 输入:[10,10]
- 输出:false
示例 4:
- 输入:[5,5,10,10,20]
- 输出:false
- 解释:
- 前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。
- 对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。
- 对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。
- 由于不是每位顾客都得到了正确的找零,所以答案是 false。
提示:
- 0 <= bills.length <= 10000
- bills[i] 不是 5 就是 10 或是 20
有如下三种情况:
- 情况一:账单是5,直接收下。
- 情况二:账单是10,消耗一个5,增加一个10
- 情况三:账单是20,优先消耗一个10和一个5,如果不够,再消耗三个5
class Solution:
def lemonadeChange(self, bills: List[int]) -> bool:
five, ten = 0, 0
for bill in bills:
if bill == 5:
five += 1
elif bill == 10:
if five < 1: return False
five -= 1
ten += 1
else:
if ten > 0 and five > 0:
ten -= 1
five -= 1
elif five > 2:
five -= 3
else:
return False
return True根据身高重建队列
假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] = [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。
请你重新构造并返回输入数组 people 所表示的队列。返回的队列应该格式化为数组 queue ,其中 queue[j] = [hj, kj] 是队列中第 j 个人的属性(queue[0] 是排在队列前面的人)。
示例 1:
- 输入:people = [[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]]
- 输出:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
- 解释:
- 编号为 0 的人身高为 5 ,没有身高更高或者相同的人排在他前面。
- 编号为 1 的人身高为 7 ,没有身高更高或者相同的人排在他前面。
- 编号为 2 的人身高为 5 ,有 2 个身高更高或者相同的人排在他前面,即编号为 0 和 1 的人。
- 编号为 3 的人身高为 6 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
- 编号为 4 的人身高为 4 ,有 4 个身高更高或者相同的人排在他前面,即编号为 0、1、2、3 的人。
- 编号为 5 的人身高为 7 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
- 因此 [[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]] 是重新构造后的队列。
示例 2:
- 输入:people = [[6,0],[5,0],[4,0],[3,2],[2,2],[1,4]]
- 输出:[[4,0],[5,0],[2,2],[3,2],[1,4],[6,0]]
提示:
- 1 <= people.length <= 2000
- 0 <= hi <= 10^6
- 0 <= ki < people.length
题目数据确保队列可以被重建
一共两个维度,一个是身高,一个是h,这里面需要两个维度分别kaolv, 不能同时考虑,应该先确定身高维度再去考虑h维度,自己可以去模拟一下就知道了。

按照身高排序之后,优先按身高高的people的k来插入,后序插入节点也不会影响前面已经插入的节点,最终按照k的规则完成了队列。
整个插入过程如下:
排序完的people: [[7,0], [7,1], [6,1], [5,0], [5,2],[4,4]]
插入的过程:
- 插入[7,0]:[[7,0]]
- 插入[7,1]:[[7,0],[7,1]]
- 插入[6,1]:[[7,0],[6,1],[7,1]]
- 插入[5,0]:[[5,0],[7,0],[6,1],[7,1]]
- 插入[5,2]:[[5,0],[7,0],[5,2],[6,1],[7,1]]
- 插入[4,4]:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
此时就按照题目的要求完成了重新排列。
python中一些基本函数介绍:
insert:.insert(index, obj)第一个是插入索引,第二个是对象
sort和sorted区别:sort是直接对对象进行操作,而sorted是对对象进行操作以后返回它的值
people.sort() people = sorted(....)
在用这两个的时候,如果对象是元组的话:如果不写key的时候,默认是先按元组的第一个成员进行排序,当第一个成员的值有相同的时候,会再对这些相同的值,按第二个成员进行排序。如果第一个成员的值没有相同的,那就只按第一个成员进行排序。
class Solution:
def reconstructQueue(self, people: List[List[int]]) -> List[List[int]]:
# 先按照h维度的身高顺序从高到低排序。确定第一个维度
# lambda返回的是一个元组:当-x[0](维度h)相同时,再根据x[1](维度k)从小到大排序
people.sort(key=lambda x: (-x[0], x[1]))
que = []
# 根据每个元素的第二个维度k,贪心算法,进行插入
# people已经排序过了:同一高度时k值小的排前面。
for p in people:
que.insert(p[1], p)
return que用最少数量的箭引爆气球
在二维空间中有许多球形的气球。对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标。由于它是水平的,所以纵坐标并不重要,因此只要知道开始和结束的横坐标就足够了。开始坐标总是小于结束坐标。
一支弓箭可以沿着 x 轴从不同点完全垂直地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
给你一个数组 points ,其中 points [i] = [xstart,xend] ,返回引爆所有气球所必须射出的最小弓箭数。
示例 1:
- 输入:points = [[10,16],[2,8],[1,6],[7,12]]
- 输出:2
- 解释:对于该样例,x = 6 可以射爆 [2,8],[1,6] 两个气球,以及 x = 11 射爆另外两个气球
示例 2:
- 输入:points = [[1,2],[3,4],[5,6],[7,8]]
- 输出:4
示例 3:
- 输入:points = [[1,2],[2,3],[3,4],[4,5]]
- 输出:2
示例 4:
- 输入:points = [[1,2]]
- 输出:1
示例 5:
- 输入:points = [[2,3],[2,3]]
- 输出:1
提示:
- 0 <= points.length <= 10^4
- points[i].length == 2
- -2^31 <= xstart < xend <= 2^31 - 1
为了让气球尽可能的重叠,需要对数组进行排序。
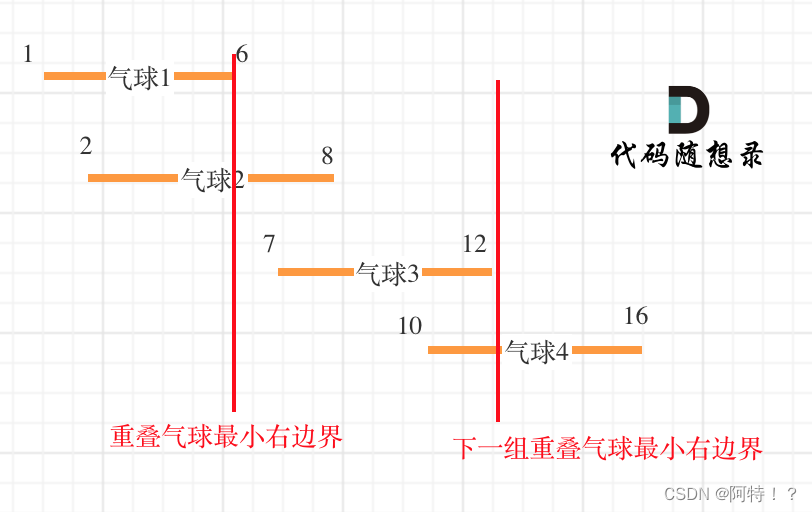
可以看出首先第一组重叠气球,一定是需要一个箭,气球3,的左边界大于了 第一组重叠气球的最小右边界,所以再需要一支箭来射气球3了。
class Solution:
def findMinArrowShots(self, points: List[List[int]]) -> int:
if len(points) == 0: return 0
points.sort(key=lambda x: x[0])
result = 1
for i in range(1, len(points)):
if points[i][0] > points[i - 1][1]: # 气球i和气球i-1不挨着,注意这里不是>=
result += 1
else:
points[i][1] = min(points[i - 1][1], points[i][1]) # 更新重叠气球最小右边界
return result无重叠区间
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
注意: 可以认为区间的终点总是大于它的起点。 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。
示例 1:
- 输入: [ [1,2], [2,3], [3,4], [1,3] ]
- 输出: 1
- 解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:
- 输入: [ [1,2], [1,2], [1,2] ]
- 输出: 2
- 解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:
- 输入: [ [1,2], [2,3] ]
- 输出: 0
- 解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
class Solution:
def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:
if not intervals:
return 0
intervals.sort(key=lambda x: x[0]) # 按照左边界升序排序
count = 0 # 记录重叠区间数量
for i in range(1, len(intervals)):
if intervals[i][0] < intervals[i - 1][1]: # 存在重叠区间
intervals[i][1] = min(intervals[i - 1][1], intervals[i][1])
count += 1
return count
划分字母区间
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。
示例:
- 输入:S = "ababcbacadefegdehijhklij"
- 输出:[9,7,8] 解释: 划分结果为 "ababcbaca", "defegde", "hijhklij"。 每个字母最多出现在一个片段中。 像 "ababcbacadefegde", "hijhklij" 的划分是错误的,因为划分的片段数较少。
提示:
- S的长度在[1, 500]之间。
- S只包含小写字母 'a' 到 'z' 。
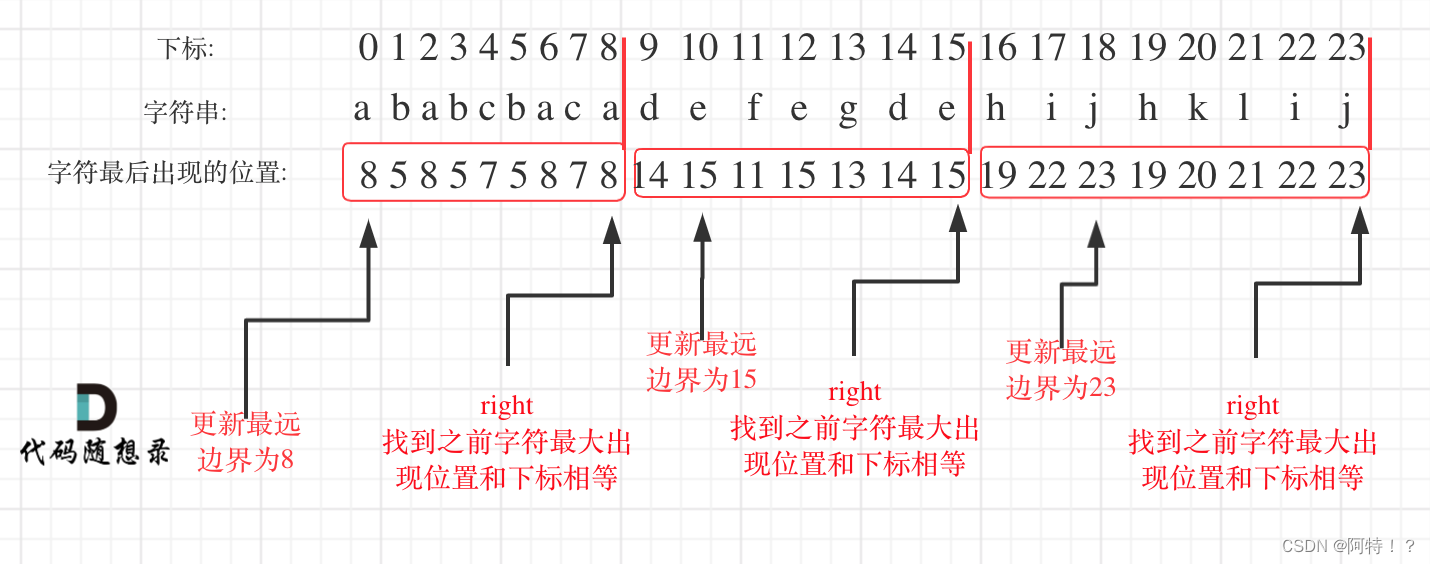
可以分为如下两步:
- 统计每一个字符最后出现的位置
- 从头遍历字符,并更新字符的最远出现下标,如果找到字符最远出现位置下标和当前下标相等了,则找到了分割点
class Solution:
def partitionLabels(self, s: str) -> List[int]:
hash = [0] * 26
for i in range(len(s)):
hash[ord(s[i]) - ord('a')] = i
result = []
left = 0
right = 0
for i in range(len(s)):
right = max(right, hash[ord(s[i]) - ord('a')])
if i == right:
result.append(right - left + 1)
left = i + 1
return result














 3004
3004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









