







应用架构
客户端
Client会通过TCP/IP协议与数据库建立连接
- 但是这个建立连接和是否连接的的过程是比较耗时的,因为建立连接需要三次握手,释放连接要四次挥手。
- 实际项目中我们与数据库建立连接后,通常会将连接,存储到池中,这里池会使用一种共享设计
- 但是这里的共享是复用,不是同时使用,这种设计模式我们称之为享元模式,类似整数池,线程池等都使用了这种模式。
常见客户端工具
- mysql.exe
- workbench
- SqlYog
- navicat
- heidisql
服务端
连接层
1.连接管理
2.权限管理
服务层
//1.提供缓存
2.提供词法、语法解析
3.提供语句的优化方案
4.提供SQL执行器
引擎层
- InnoDB
- MyISAM
- …
存储层
1.存储业务数据
2.存储日志数据
逻辑架构
执行流程
查询流程
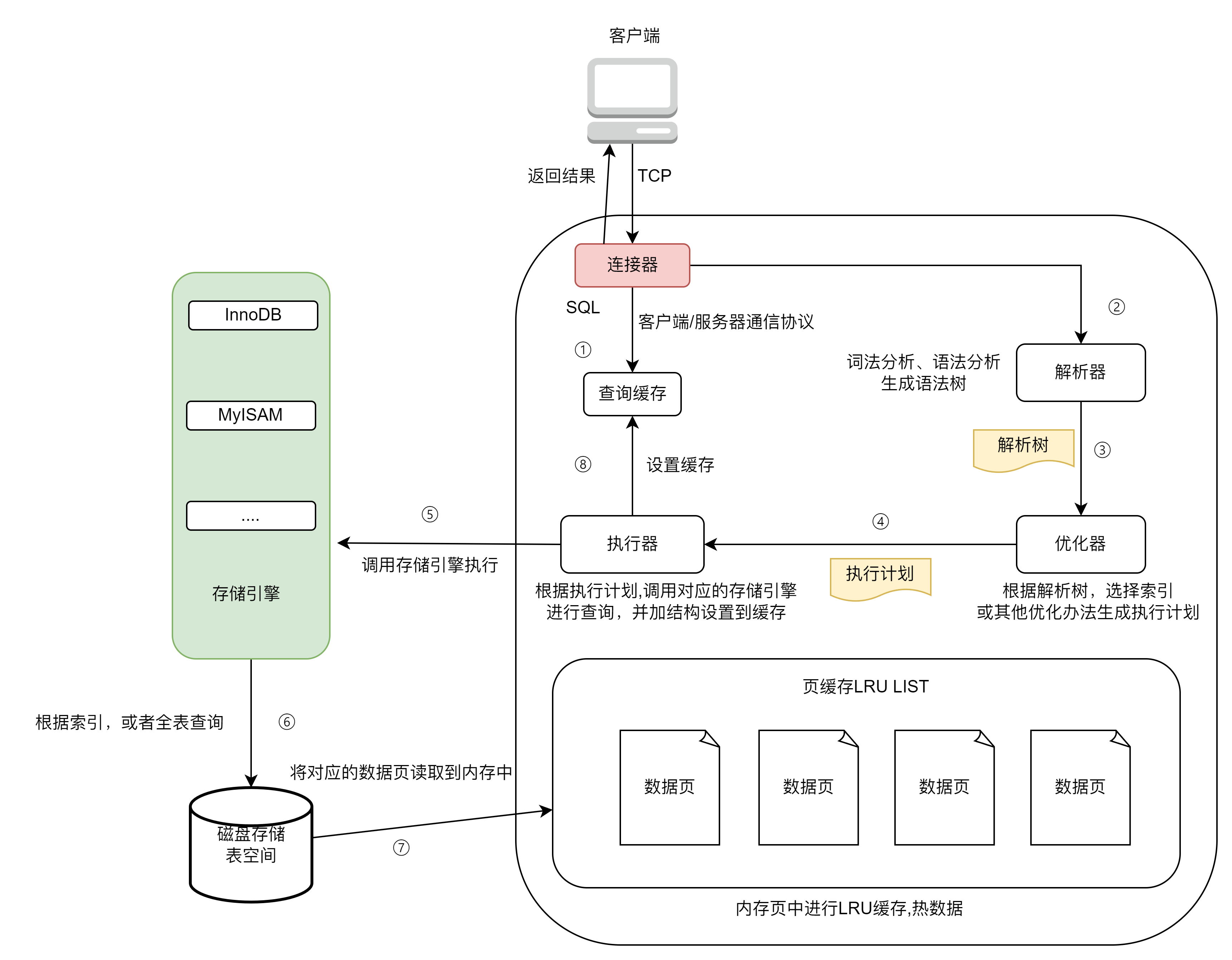
主要过程在于—先查缓存–>没有再去(编译)解析–语法分析SQL–>生成执行计划–>SQL执行器执行SQL计划–>调用存储引擎执行SQL查询逻辑,并将结果存储到缓存–>再返回给客户端
更新流程—怎么保证的一致性?
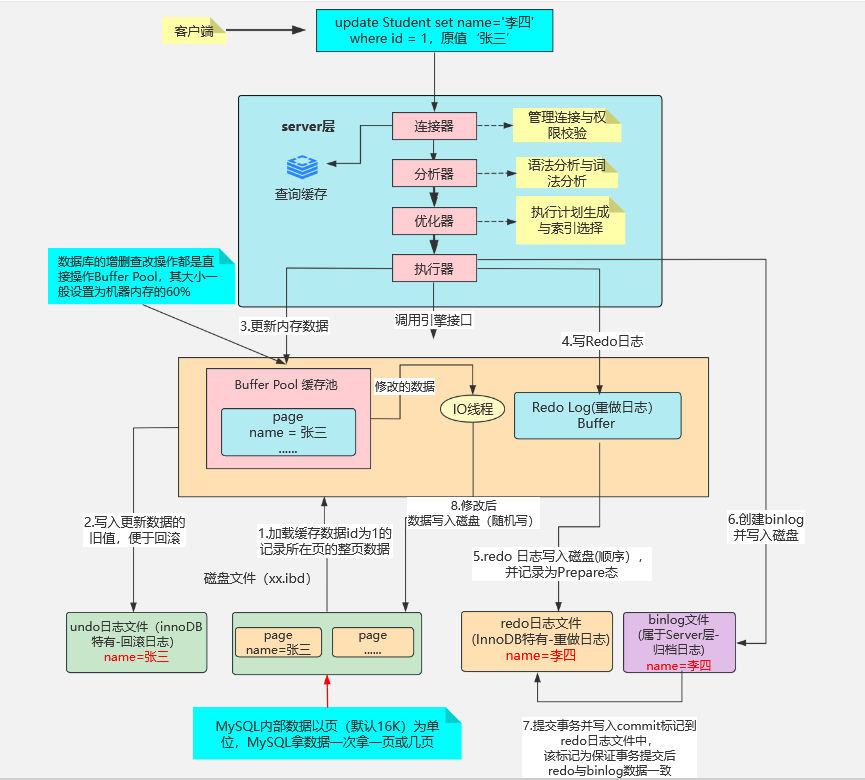

核心组件
服务组件
连接器–管理连接与权限校验
查询缓存–存储查询语句与查询结果的键值对
解析器
词法分析
单词是否正确
关键字是否正确
语法分析
语句执行流程分析
优化器
1.读取SQL语法树
2.对SQL语句进行默认优化----选择对应索引
3.生成执行计划(explan)
执行器
调用执行引擎执行计划
存储引擎
MyISAM
特点
1.MyISAM索引文件和数据文件是分离的(非聚集/簇)
2.表存储在磁盘中,如果不改动,存储MySQL安装目录的该库的data目录下
对于MyISAM存储引擎用三个文件存储数据 xx.frm(表结构文件),xx.MYD (数据文件),xx.MYI(索引文件)
索引应用
- 非聚簇索引在查询时,会先通过索引文件找到数据地址
- 找到数据地址后,在根据数据地址找到数据页,并返回
例如:当我们使用一条SQL语句走MyISAM索引时:第一步先从MYI的B+树结构找到data (数据所在行磁盘地址),第二步有MYD文件找到具体的数据。
innoDB
特点
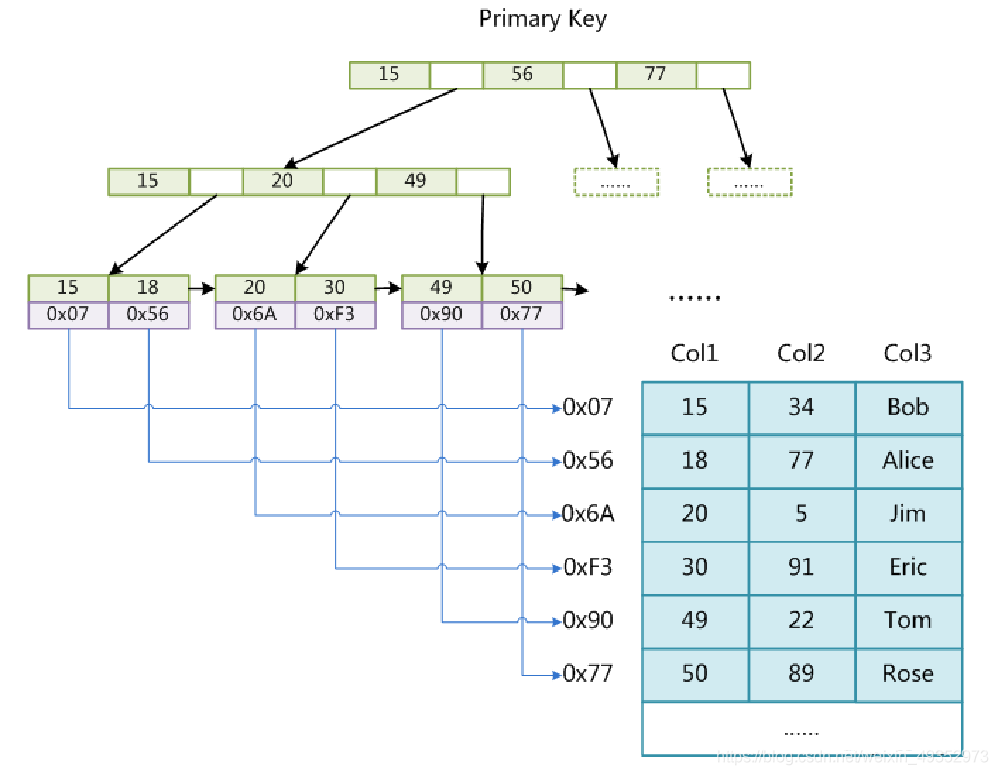
InnoDB存储引擎索引与数据是不分离的(聚集/簇)
表存储在磁盘中,如果不改动,存储MySQL安装目录的该库的data目录下
对于 InnoDB 存储引擎用两个文件存储数据 xx.frm(表结构文件),xx.idb (数据文件+索引文件)
- 表数据文件本身就是按 B+Tree 组织的一个索引结构文件
- 聚集索引-叶节点包含了完整的数据记录
- 一张表只有一个聚集索引(即主键索引),其他索引都是二级索引,叶子节点的 data 中存储叶子节点的主键值,由该值进行回表操作到主键索引中查找数据,这样既能满足快速找到数据也能保证数据的一致性和节约存储空间。如果没有唯一主键,则MySQL会选择唯一列,如果没有,会自己维护一个隐藏列(如rowid)作为聚簇索引。
主键索引
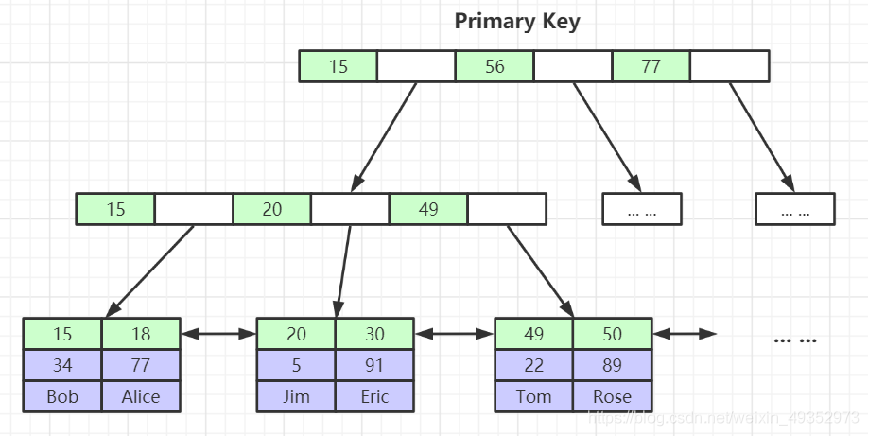
二级索引
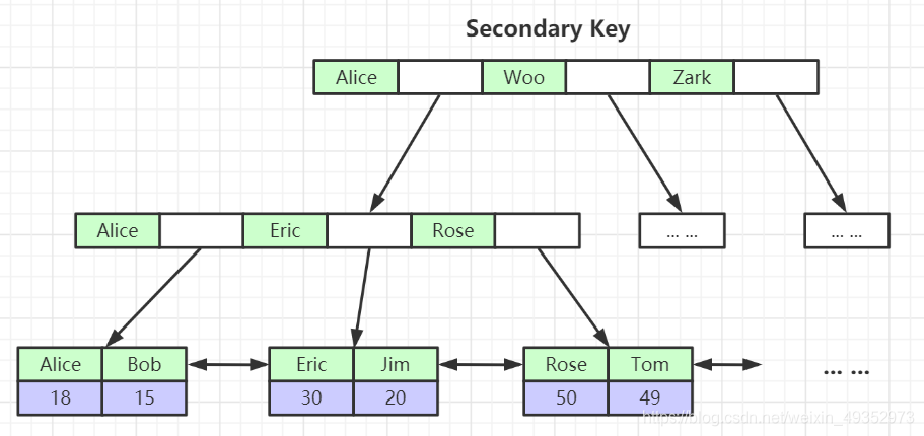
索引应用
当我们使用一条SQL语句走 InnoDB 索引时:直接从 idb 的 B+树结构的叶子节点中找到具体数据
有一二级索引概念
通过二级索引找一级,有一级找一级,没一级找唯一且非空,没有唯一且非空找行号->rowid,在找到记录
使用建议
建议表必须建立一个主键,并且推荐使用整型的自增主键。
原因:
1.如果不建立主键,MySQL 会找一列所有值都不相等的列来用于构建 B+树,如果没有这样的列,MySQL 会创建一个隐藏列来维护这个B+树
2.整型比长串的占用空间更少,比较大小时相对来说更容易,能更快的定义数据的位置
3.B+Tree 需要维护自身平衡,自增不会导致树分裂
异同
- 事务
- InnoDB支持
- MyISAM不支持
- 外键
- InnoDB支持
- MyISAM不支持
- 索引
- InnoDB为聚集索引
- MyISAM为非聚集索引
- 锁粒度
- InnoDB最小粒度支持行锁
- MyISAM最小粒度支持表锁
物理架构
数据文件—存储表中数据/索引
- frm文件(表结构文件)
- ibd文件(数据+索引)
日志文件
binlog归档日志
- 属于server层面的日志,所有引擎可共享的日志
- 简介
- binlog是一种逻辑日志,属于server层
- 执行更新操作时,可以记录binlog
- 主要用于做数据同步(例如我们的主从架构)和数据恢复-----类似于redis的AOF
- 应用场景
- 数据同步–主从复制
- 例如在数据库的主从架构中,Master(主节点)将数据同步到多个从节点(Slaver)
- 数据恢复–类似于数据备份
- binlog中记录的是我们的sql操作,假如出现数据丢失,可以通过binlog进行数据恢复,在数据恢复时通常也就会借助一些工具,mysqlbinlog.
- 数据同步–主从复制
- 具体特点
- 指定大小
- 可以自动创建多个日志文件
- 会默认记录所有的更新操作->即使没有实际更新数据
指令查看是否开启–show variables like ‘%log_bin%’;
如何开启
第一步:在mysql根目录创建一个my.ini文件;
第二步:在my.ini文件中添加如下语句:
[mysqld]
log-bin=mysql-bin
server_id=1
第三步:以管理员身份打开命令行窗口,然后执行如下指令,重启mysql.
net stop mysql
net start mysql
第四步:检查mysql中的binlog是否开启了?假如log_bin的状态为on则表示开启了。
如何关闭
第一步:注释配置文件中的和binlog相关的行,例如
//log-bin=mysql-bin
第二步:重启mysql服务
redolog重做日志
属于引擎层面的日志,例如InnoDB
- 简介
- 用于记录数据的一致性状态。数据库事务的四大特性中,有一个数据的一致性,如何保证这个一致性能呢
- 应用场景–事务操作
- 故障恢复
- 保证事务持久性–由commit分割的事务–redolog的文件
- 构成
- 重做日志缓冲区–Redo Log Buffer
- 重做日志文件–Redo Log File
- 具体特点
- 不能指定大小并且只存在一个
- 允许循环使用,日志满了,会对文件内容重写,且重做日志一般是以文件组存在,默认三个redo日志文件为一组,循环写入
- 用于记录物理日志–在磁盘上的操作–记录你在哪一页,哪一个偏移地址上,执行了什么更新。
指令
- 查看缓冲区大小
- show variables like ‘%innodb_log_buffer_size%’;
- 默认大小为16m,最大是4GB
- redolog记录流程是怎样的
- 第1步:将原始数据从磁盘读入到内存,修改内存中的数据。
- 第2步:生成一条重做日志,并写入到redo log buffer中,记录的数据是被修改后的值。
- 第3步:当事务commit时,将redo log buffer中的内容刷新到relog log file中,这里的写为顺序写,是不断的追加。
undolog回滚日志
简介
undolog用于在更新前记录原始数据以及反向操作。(update之前的数据要在这里做一保存,一旦事务回滚可以基于这里的日志,进行反向操作)
应用场景–回滚-- 应用于事务反向操作的记录
1.记录反向操作,用于保证事务的原子性和一致性
2.回滚时恢复到更新前的数据状态
配置文件
MySQL的配置文件在Windows环境下通常称为my.ini,在类Unix环境下通常称为my.cnf。这个文件是MySQL服务器的主要配置文件,它包含了数据库服务的各种配置选项和参数设置。
常见配置如下
- 数据库设置:
datadir:指定MySQL数据库文件存储的目录路径。socket:指定MySQL服务器使用的套接字文件路径。port:指定MySQL服务器监听的端口号,默认为3306。
- 日志设置:
log_error:指定错误日志文件路径。general_log:开启或关闭通用查询日志。slow_query_log:开启或关闭慢查询日志,并指定慢查询阈值。
- 缓冲设置:
key_buffer_size:指定键缓冲区大小,适用于MyISAM存储引擎。innodb_buffer_pool_size:指定InnoDB存储引擎的缓冲池大小,用于存储数据和索引。
- 连接设置:
max_connections:指定MySQL服务器允许的最大并发连接数。wait_timeout:指定客户端连接没有活动时多久后断开连接。interactive_timeout:指定交互式连接的超时时间。
- 字符集设置:
character_set_server:指定服务器默认字符集。collation_server:指定服务器默认的校对规则。
- 复制和高可用设置(适用于主从复制):
server-id:指定服务器的唯一ID。log_bin:开启二进制日志,并指定日志文件名。relay_log:指定中继日志文件路径。
- 安全设置:
secure_file_priv:指定允许从服务器上读取和写入的文件的目录路径。
表设计
表名字设计
- 见名知意
- 尽量使用英文全称
- 多个单词使用下划线连接----和java的驼峰命名不同
字符集设计
- 尽量与数据库设计的字符集保持一致
字段设计
MYSQL字段的类型有以下几种
字符型
char—定长char 数据类型用于定义一个固定长度的字符串,长度范围处 1 ~ 255 之间,且必须是在创建表时指定。它有一个特殊的情况是,存储字符串时,如果未达到指定长度,则会使用空格填充到指定长度。当我们需要存储一些长度固定的数据列时,使用 char 是非常合适的。例如:手机号码、身份证号等等。
varchar–变长定义了一个可变长度的字符串,创建时指定它所允许的最大长度。例如,如果创建时声明了 varchar (x),则只能存储不超过 x 个字符的数据,且 x 的最大值是 65535。对于长度不固定的数据列,使用 varchar 就是最合适的。例如:姓名、邮箱地址等等。
char 由于长度固定,不需要考虑边界问题,检索速度要快于 varchar。
texttext是文本数据类型,它分为四类,都是变长字符串,最大的区别是存储空间的不同,其中:
- tinytext:最大长度是(2^8 - 1)个字符。
- text:最大长度是(2^16 - 1)个字符。
- mediumtext:最大长度是(2^24 - 1)个字符。
- longtext:最大长度是(2^32 - 1)个字符。
建议当你的数据量超过 500 个字符时,就应该考虑使用文本。另外,文本类型不能有默认值,且在创建索引时需要指定前多少个字符。
整数型
MySQL 主要支持 5 个整数类型:tinyint、smallint、mediumint、int、bigint。这些类型不同之处只在于存储空间,即存储数值的取值范围。同时,可以定义UNSIGNED 关键字规定字段只保存正值。
在使用上,根据需要选择 “足够大”的空间就可以了。另外,关于整数类型还有一个特性:显示宽度。例如,我们在定义 Schema 时,常常会看到类似这样的写法:
bigint(20) NOT NULL COMMENT ‘a’,
其中,20就是可选的显示宽度,这会让 MySQL 对 SQL 标准进行扩展,当从数据库检索一个值时,可以把这个值延长到指定的宽度。例如,这里的a定义的类型为 bigint (20),就可以保证 b 这一列少于20个字符宽度时自动使用空格填充。定义宽度并不会影响字段的大小和存储值的取值范围。
- tinyint-------1字节
- smallint------2字节
- mediumint—3字节
- int------------4字节
- bigint---------8字节
浮点数与定点数
MySQL 支持两个浮点类型:float、double。其中,float 用于表示单精度浮点数值,占用 4 个字节;double 用于表示双精度浮点数值,占用 8个字节。因为它们只能保存近似值(不精确的值),所以,通常也叫做非标准类型。
float 相较于 double 类型来说,由于占据的空间小,精度较低,取值范围也相对较小。
float (M, D):**其中 M 定义显示长度,D 定义小数位数。但是它们是可选的,且默认值是 float (10, 2),2 是小数的位数,10 是数字的总长(包括小数)。它的小数精度可以到 24 个浮点。
**double (M, D):**M 和 D 与 float 是相同的,默认值是 double (16, 4)。它的小数精度可以达到 53 位。
decimal(M,D)😗*MySQL 中的 decimal 被称为定点数据类型,由于它保存的是精确值,所以它通常用于精度要求非常高的计算中。另外,也可以利用 decimal 去保存比 bigint 还要大的整数值。
CPU 并不支持对 decimal 的直接计算,而是 MySQL 自身实现了对 decimal 的高精度计算。底层存储方面,MySQL 将 decimal 类型的数字使用二进制字符串存储,每 4 个字节可以存储 9 个数字。假如我们定义了decimal (18, 9)。
则代表不包含小数点的数字总数(整数位数 + 小数位数)位数是 18,不指定的情况下默认是 10,9 则代表小数的位数,如果不指定,默认是 0。
由于小数点两边各有 9 个数字,所以占据 2 * 4 = 8 个字节,小数点自身占用一个字节,最终,decimal (18, 9) 一共占用 9 个字节。需要注意,如果存储的位数不够,则小数末尾会补零。但是,如果超出了声明的位数,则会报错。
由于 decimal 需要比较大的空间和计算开销,它的计算效率也就没有 float 和 double 那么高,所以应该只有要求精确计算的场景下才考虑去使用 decimal。
日期型
在 MySQL 表中存储时间(可以是日期、时间或日期时间)是非常常见的需求,但是如何合理的选择数据类型却也是个难题。这里我给出一个建议:通常 datetime 是最佳选择。理由如下:
时间范围跨度足够大,能够满足所有的时间需求。
即使是只用于存储日期或时间,也可以存储日期时间,只需要在代码中处理即可。避免将来需求变更时对数据表的 Schema 有所变动。
Date正如这种数据类型的名称一样,它用于存储日期,存储范围是 ‘1000-01-01’ 到 ‘9999-12-31’。
DateTime它用于存储时间,不仅可以表示一天中的时间,也可以用于表示两个时间的时间间隔。它的取值范围是‘-838:59:59’ to ‘838:59:59’。乍看起来,它的小时取值太特殊了,正常不应该是 [0, 23] 吗 ?这是因为 time 可以表示特殊的时间间隔,MySQL 将 time 的小时范围扩大了,而且支持负值。
除了基本的存储一天中的时间之外,time 允许以 “D HH:MM:SS” 的格式存储。其中,D 的取值是 0 ~ 34。如果要存储时间间隔,time 则会以(时间间隔 * 小时)作为小时进行存储。它的计算公式是:D * 24 + HH。例如,插入了 “2 19:20:00”,相当于插入 “67:20:00”。
TimeStamp同样用于存储日期时间数据,与 datetime 存储的数据格式是一样的,它的取值范围是:‘1970-01-0100:00:01.000000’ UTC 到 ‘2038-01-19 03:14:07.999999’ UTC。它与 datetime 的主要区别在于时间范围要小一些。
另外,timestamp 是与时区相关的,能够反映 “当前时间”。当插入时间时,会先转换为本地时区后再存储;查询时间时,会转换为本地时区后再显示。所以,不同时区的人看到的同一时间是不一样的。
二进制
二进制数据类型理论上可以存储任何数据,可以是文本数据,也可以存储图像或者其他多媒体数据。二进制数据类型相对于其他的数据类型来说,使用频率是比较低的。MySQL一共提供了四种二进制类型:tityblob、blob、mediumblob、longblob。它们的区别只在于存储范围的不同。
tinyblob:最大支持 255 字节
blob:最大支持 64KB
mediumblob:最大支持 16MB
longblob:最大支持 4GB
需要注意,虽然 MySQL 提供并支持大文件存储,但是这样会急剧降低数据库的性能。所以,应该谨慎使用这些数据类型,能不用的情况下尽量不用。
其他类型
enum
set
json
最佳实践
选择简单数据类型在一列中存储 10、100、201 这样的数据,我们可以选择使用 int 或 varchar 来存储。但是整型要比字符型的操作复杂度小太多,那么,选择整型(例如int)就是最简单的数据类型。
应用最小数据类型并不是直接选择最小的,而是在满足需求的同时选择最小的。例如,要存储事件状态,可以选择 tinyint;要存储班级人数,可以选择 smallint 等等。关于最小数据类型,它有两大优势:
小的数据类型建立索引时所需要的空间也相对较小,这样一页中所能存储的索引节点数量也就越多,遍历时IO 次数就会越少,索引的性能也就越好。
基于Decimal存储小数虽然不建议在数据库中存储小数,但是,在一些场景中小数不可避免,最常见的例子就是订单的金额。由于小数本身在计算时就很复杂,而且很多时候你需要去考虑精度问题。所以,最直接的方式就是把这种管理交给数据库。
这里我提出一个扩展建议,也就是不要在数据库中存储小数。通过提高单位解决
避免使用text和blog类型MySQL 内存临时表并不支持 text、blob 这样的大数据类型
如果查询时包含有这样的数据,则排序操作必须使用磁盘临时表,性能会下降很多。
而且对于这种数据,MySQL 还要做二次查询(因为 MySQL 实际保存的是指针,而不是真实数据),会使 SQL 性能变得很差。
但是,也并不是说我们一定就不能用 text 和 blob。如果确实有需求需要使用这样的数据类型,那么在查询时一定不要直接SELECT *,而是取出需要的列。这样MySQL就不会去主动查询这些数据列,也是提高性能的一种惯用手段。
最后,还需要注意,因为 MySQL 对索引长度的限制,text 类型只能用到前缀索引,并且由于存储的是指针,text列上不能有默认值。
表的约束
- 主键约束 primary key
- 非空约束 not null
- 唯一约束 unique key
- 检查约束 check (条件)
- 外键约束 foreign key
- 字段默认值 default
创建表时添加约束
create table student(
sno char(9) primary key,
sname varchar(20) unique,
ssex char(2) default '女' commit '性别',
sage smallint check(sage > 10),
sdept varchar(20)
);
create table course(
cno varchar(4) primary key,
cname varchar(40) not null,
cpno varchar(4),
ccredit smallint,
foreign key (cpno) references course(cno)
);
create table sc(
sno char(9),
cno varchar(4),
grade decimal(4,2),
foreign key(sno) references student(sno),
foreign key(cno) references course(cno)
);
表创建成功后添加约束
添加外键约束
alter table 表名 add constraint 约束名称(自定义) foreign key (表中字段名) references 主表表名 (主表字段) — 主表和从表可以为同一个表
主键约束
添加:alter table 表名 add primary key (字段)
删除:alter table 表名 drop primary key
非空约束
添加:alter table 表名 modify 列名 数据类型 not null
删除:alter table 表名 modify 列名 数据类型 null
唯一约束
添加:alter table 表名 add unique 约束名(字段)
删除:alter table 表名 drop key 约束名
自动增长
添加:alter table 表名 modify 列名 int auto_increment
删除:alter table 表名 modify 列名 int
外键约束
添加:alter table 表名 add constraint 约束名 foreign key(外键列)
references 主键表(主键列)
删除:
第一步:删除外键
alter table 表名 drop foreign key 约束名
第二步:删除索引
alter table 表名 drop index 索引名
约束名和索引名一样
默认值
添加:alter table 表名 alter 列名 set default ‘值’
删除:alter table 表名 alter 列名 drop default
注释comment
COMMENT 用于定义列的注释信息,就好像我们在写代码一样,把重要的或者不易理解的地方,加上一些注释,方便以后查阅。
comment ‘手机号’
宽窄表
宽表
表宽指的是字段个数多,字段越多维护越慢
窄表
针对于大字段通常会拆出来一个小表















 3215
3215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









