







MySQL实例的大概结构如下
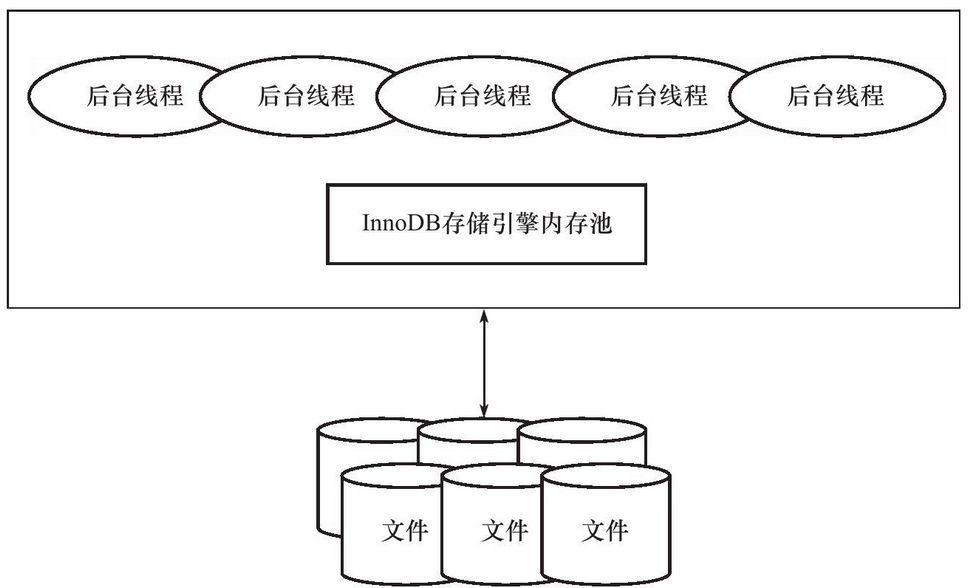
如上图所示,InnoDB的存储引擎右多个内存块
- 维护所有进程/线程需要访问多个内部数据结构
- 缓存磁盘上的数据,方便快速读取,且修改的数据缓存在此,满了后统一写入磁盘
- 重做日志(redo log)缓冲等等。
MySQL的线程们
MySQL的线程主要分为后台线程和主动线程,后台线程主要负责刷新内存池中的数据,保证缓冲中的数据是最近的数据。且将数据刷新到磁盘文件redo buffer。
1 Master Thread
- 核心的后台线程。
- 负责将缓冲池的数据异步刷新到磁盘,保证数据一致性。
- 包括:脏页的刷新、合并插入缓冲、UNDO页的回收等。
2 IO Thread
- 大量使用了AIO来处理IO请求。
- 负责这些IO请求的回调处理。
- 主要分为:write Thread,read Thread,insert buffer Thread,log IO Thread。
3 Purge Thread
- 事务提交后,回滚日志就不需要了,PurgeThread回收已经使用并分配的undo页。
- InnoDB 1.1后,purge操作就从Master Thread中单独使用PurgeThread来完成
- 配置文件配置线程个数,即使大于1,也会被设置为1
- 从InnoDB 1.2后,支持多个PurgeThread
4 Page Cleaner Thread
- InnoDB 1.2.x中引入。
- 将之前版本中脏页的刷新操作放入到这个线程中完成。
MySQL的内存结构和技术
缓冲池
缓冲池简单来说就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响。
缓冲池存放的大多都是数据页,主要是为了加速数据页的访问
- 缓冲池的大小影响数据库的整体性能–内存越大,算力越强,肯定性能越高。
- 通过innodb_buffer_pool_size设置缓冲池的大小。
LRU List
缓冲池是使用LRU算法来进行管理页的,最频繁的页放在最前,最少访问的放在最后,当新加载页没有空间时,就可以释放最后的页。
LRU存放的页是压缩的页,当要使用时会放到unzip_LRU中解压后缓存
页大小默认为16KB,InnoDB的LRU算法加入了midpoint(理解为中点),定位在LRU列表的5/8处。midpoint后称为old列表,之前为new列表(热点数据),且新读的页不一定是热点数据。
unzip_LRU
压缩LRU页主要是存放已经解压的数据页,存放在内存中,可以说数据页存放的主要位置就在这里
- 压缩页,unzip_LRU如何分配内存的
- 检查4KB的unzip_LRU列表,检查是否有可用的空闲页;
- 若有,则直接使用;
- 否则没有4kb的,则检查8KB的unzip_LRU列表;
- 若能够得到8KB空闲页,将页分成2个4KB页,存放到4KB的unzip_LRU列表;
- 若不能得到空闲页,从LRU列表中申请一个16KB的页,将页分为1个8KB的页、2个4KB的页,分别存放到对应的unzip_LRU列表中。
- 检查4KB的unzip_LRU列表,检查是否有可用的空闲页;
Flush list
页中的数据被修改的就是脏页,因为内存和磁盘的页的内容不一致。此时会通过 脏页刷新(Dirty Page Flush) 将脏页复制一份到Flush list中,等待CHECKPOINT机制刷新回磁盘,LRU中的脏页不会删,因为Flush刷新回磁盘后,脏页就不是脏页了。
Free List
Free List也是在InnoDB缓冲池中管理的,用于存储可用的空闲页。当需要新的页时,InnoDB会从Free List中获取空闲页,避免频繁申请新的内存空间。
重做日志缓冲
redo log buffer,作用就是包装数据的一致性,相比于Flush列表的刷新,redo log buffer更加准时和及时,一般1秒进行一次刷新。
- Master Thread每一秒将redo log buffer刷新到重做日志文件中。
- 事务提交时会将redo log buffer刷新
- redo log buffer空间小于1/2时,会刷新
插入缓冲区 Insert Buffer
对于非聚集索引(非主键索引)插入操作时,不能直接根据索引找到插入的位置,为了提高插入性能(减少磁盘I/O),将数据首先写入到Insert Buffer中的页内存中。
然后,在后台的线程或特定的检查点时刻,InnoDB会将Insert Buffer中的数据异步地刷回到磁盘页中。这个过程被称为"插入缓冲合并"(Insert Buffer Merge)。
插入缓冲区会根据不同的索引(不同表)来划分区域
变更缓冲区 change buffer
和插入缓冲区类似,只不过是维护修改和删除等操作的缓冲区,并且刷盘时合并操作
Merge Insert Buffer
存放着Insert Buffer中待合并的数据,用于在适当的时候将插入缓冲区(Insert Buffer)中的数据合并写入到相应的索引页中。
两次写
- 执行数据修改操作时,首先将要修改的数据页复制一份到内存中的一个特殊缓冲区,即 doublewrite buffer(双写缓冲区)。这个特殊缓冲区被视为内存中的一个临时存储区域。
- 接下来,InnoDB将数据页更新写入磁盘的两个位置:
- 首先,将数据页的副本写入由操作系统管理的磁盘空间上的一个位置。
- 然后,将相同的副本写入 doublewrite buffer 中的另一个位置。
- 只有在这两个位置都写入成功后,InnoDB才会将对应的事务标记为“已提交”。这确保了双写操作的原子性和一致性。
- 在数据库崩溃或断电等系统故障发生时,InnoDB可以从 doublewrite buffer 中恢复数据页,以确保数据的完整性。如果某个位置的磁盘页损坏或数据不一致,InnoDB可以使用 doublewrite buffer 中的备份来修复破损的页,避免数据丢失。
主线程的工作
InnoDB的主线程Master Thread具有最高的线程优先级,由主循环,后台循环,刷新循环,暂停循环组成。会根据数据库运行状态在多个循环之间切换
CheckPoint技术–Flush列表中的脏页刷新到磁盘的一个机制
对于InnoDB存储引擎而言,其是通过LSN(Log Sequence Number)来标记版本的。而LSN是8字节的数字,其单位是字节。每个页有LSN,重做日志中也有LSN,Checkpoint也有LSN,LSN也是宕机后恢复数据和检查事务的关键
cp = CheckPoint
作用
- 缩短数据库的恢复时间:redo日志中cp之前的内容为已经从内存刷入磁盘,cp之后的内容就表示没有刷入,当数据库宕机重启后,读取cp后的内容,所以可以缩短恢复时间。
- 缓冲池不够用时,将脏页刷新到磁盘:LRU需要保证100个空闲页使用,不够时会将冷页丢弃,如果这个冷页同时是脏页,就需要进行刷入磁盘
- 重做日志不可用时,刷新脏页:当redo log容量不够用时,可以进行cp,将脏页刷入磁盘,此时重做日志中的日志就可以标记为可丢弃(因为内容已经刷入磁盘,已经持久化)
分类
- Sharp CheckPoint:当数据库关闭时就需要将内存中的所有脏页刷新回磁盘。并不适用于正常运行时,因为每次刷新都会有大量数据IO。
- Master Thread CheckPoint:每隔1秒或10秒将脏页列表的一定比例的页刷入磁盘。是异步操作,不会阻塞用户线程。
- flush_lru_list Checkpoint:LRU需要保证100个空闲页的大小以供使用
- Async/Sync Flush Checkpoint:当重做日志不够用的情况下的CheckPoint
- Dirty Page too much:脏页的数量太多,导致InnoDB存储引擎强制进行Checkpoint。其目的总的来说还是为了保证缓冲池中有足够可用的页
LSN
- Log Sequence Number的缩写,代表日志的序列号,占用8字节且单调递增
- 有以下含意:重做日志写入的总量、checkpoint的位置、页的版本
- 页的头部,有一个FIL_PAGE_LSN,记录了该页的LSN,表示该页最后刷新时LSN的大小(用来判断页是否需要进行恢复操作)
- 例如:页P1的LSN为10000,而数据库启动时,InnoDB检测到写入重做日志中的LSN为13 000,并且该事务已经提交,那么数据库需要进行恢复操作,将重做日志应用到P1页中。同样的,对于重做日志中LSN小于P1页的LSN,不需要进行重做,因为P1页中的LSN表示页已经被刷新到该位置
当LSN用于恢复数据时有如下操作:找到cp位置之后的日志部分,因为cp之前的数据是刷入磁盘了的,检查之后的日志部分涉及的页进行恢复——>cp的LSN为10000时发生宕机,恢复操作仅恢复LSN 10 000之后的日志
其他技术
自适应hash索引——可以手动创建了
- 自适应哈希索引是根据实际的数据访问模式来动态创建和维护的。
- 当某个索引被频繁访问时,InnoDB会自动将其部分数据构建成哈希索引,以提高查询性能。
- 这种自适应的特性无需手动创建和管理哈希索引
- 而是让InnoDB根据实际的数据访问情况来决定是否创建哈希索引,从而简化了索引的管理工作。
- 可以不用为了某个索引单独创建一个hash索引,innodb会自动帮我们为热点数据创建hash索引,所以称为自适应hash索引,自适应是因为是innodb会根据我们的热点数据区创建hash索引
AIO
非阻塞IO,当向mysql发送请求时,不会被阻塞,可以连续发送IO操作,并且innodb会进行IO merge通过判断我们要查询的页是否时连续的,来进行mergeIO操作,比如读取(8,6),(8,7),(8,8)会进行合并读取(8,6)连续读取48kb的数据。innodb的AIO需要操作系统提供支持,也就是硬件支撑。
刷新临接页
Flush Neighbor Page(刷新邻接页)的特性。其工作原理为:当刷新一个脏页时,InnoDB存储引擎会检测该页所在区(extent)的所有页,如果是脏页,那么一起进行刷新。这样做的好处显而易见,通过AIO可以将多个IO写入操作合并为一个IO操作,故该工作机制在传统机械磁盘下有着显著的优势。
但是可能会有以下问题:
- 是不是可能将不怎么脏的页进行了写入,而该页之后又会很快变成脏页?
- 固态硬盘有着较高的IOPS,是否还需要这个特性?















 2249
2249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









