







Doris 概述
- Doris(原百度 Palo,2018 年 7 月由百度捐赠给 Apache 基金会进行孵化)是一款 基于大规模并行处理技术的分布式 SQL 数据库。
- 基于 MPP (Massively Parallel Processing,即大规模并行处理)的交互式SQL数据仓库,可用于 OLAP 。MPP 是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果
Doris 定位
- MPP 架构的关系型分析数据库
- PB 级别大数据集,秒级/毫秒级查询
- 主要用于多维分析和报表查询

Doris 架构
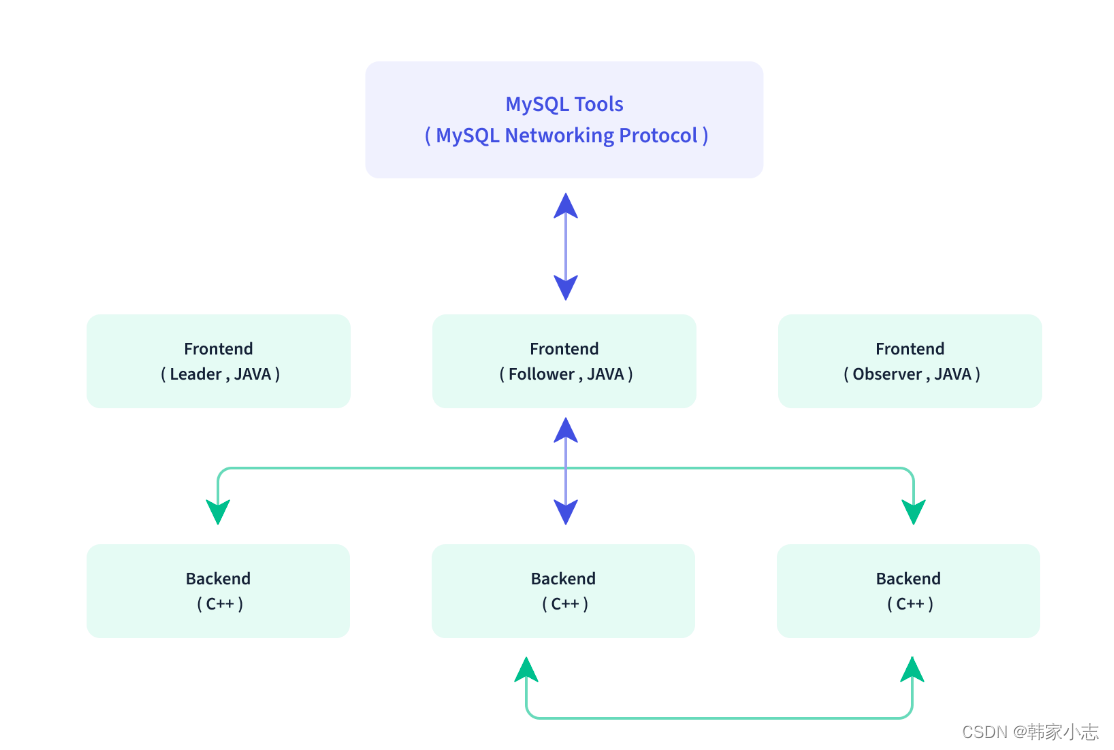
- Doris 的架构很简洁,只设 FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维,FE、BE 都可横向扩展。
- FE(Frontend):
主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作- 主要有三个角色:
- (1)Leader 和 Follower:主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
- (2)Observer:用来扩展查询节点,同时起到元数据备份的作用。如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不参与任何的写入,只参与读取。
- BE(Backend):主要负责数据存储、查询计划的执行
- 负责物理数据的存储和计算;依据 FE 生成的物理计划,分布式地执行查询。数据的可靠性由 BE 保证,BE 会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
- 使用接口方面
- 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL,用户可以通过各类客户端工具来访问 Doris,并支持与 BI 工具的无缝对接。
- 存储引擎方面
列式存储,按列进行数据的编码压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更加有效利用 IO 和 CPU 资源。
- 索引结构
- Sorted Compound Key Index,可以最多指定三个列组成复合排序键,通过该索引,能够有效进行数据裁剪,从而能够更好支持高并发的报表场景
- Z-order Index :使用 Z-order 索引,可以高效对数据模型中的任意字段组合进行范围查询
- Min/Max :有效过滤数值类型的等值和范围查询
- Bloom Filter :对高基数列的等值过滤裁剪非常有效
- Invert Index :能够对任意字段实现快速检索
- 存储模型
Aggregate Key 模型:相同 Key 的 Value 列合并,通过提前聚合大幅提升性能Unique Key 模型:Key 唯一,相同 Key 的数据覆盖,实现行级别数据更新Duplicate Key 模型:明细数据模型,满足事实表的明细存储
- 查询引擎
- 采用 MPP 的模型,节点间和节点内都并行执行,也支持多个大表的分布式 Shuffle Join,从而能够更好应对复杂查询。

















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









