







1. OCR图文识别介绍
OCR(全称 Optical Character Recognition,直译为光学字符识别)用于图片文字识别,例如 提取图片中车牌号等等。
Java中实现OCR的技术方案有:
- 百度OCR,花米
- Tesseract-OCR,Google维护的开源OCR引擎,支持Java,Python等语言调用
- Tess4J,封装了Tesseract-OCR ,支持Java调用。(使用Tess4J需要不同的词库文件进行支撑(如 汉语词库)
- …
2. Tess4J示例代码
Tess4J是一个Java库,它对谷歌的Tesseract-OCR进行了再封装,使用程度上更简单。
Tesseract OCR是一个开源的光学字符识别(OCR)引擎,它能够识别图像中的文本,并将其转换为可编辑的格式。Tess4J使得开发者可以在Java应用程序中轻松集成OCR功能。
Tess4J官网:https://tess4j.sourceforge.net/usage.html
1、添加依赖坐标
<dependencies>
<!--单元测试-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<!--tess4j-->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.1.1</version>
</dependency>
</dependencies>
2、导入中文字体库,将tessdata放到一个没有中文、特殊字符、空格的目录下
下载地址:https://download.csdn.net/download/qq_46921028/89307556
3、准备一张带文字的图片

4、编写测试
package cn.aopmin.tess4j;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import org.junit.Test;
import java.io.File;
/**
* 测试ORC图片文字识别:
* 我们这里使用的是Tess4j类库(它封装了谷歌的Tesseract-OCR,也是支持Java调用的)
*
* @author 白豆五
* @since 2024/5/14
*/
public class Tess4jTest {
/**
* 测试图片文字提取
*/
@Test
public void testScanText() {
try {
// 获取本地图片
File file = new File("D:/1111/pic1.png");
// 创建Tesseract对象
ITesseract tesseract = new Tesseract();
// 设置字体库路径
tesseract.setDatapath("D:/1111/tessdata");
// 中文识别
tesseract.setLanguage("chi_sim");
// 执行ocr识别
String result = tesseract.doOCR(file);
// 替换回车和tal键 ,让结果在一行显示
result = result.replaceAll("\\r|\\n", "").replaceAll(" ", "");
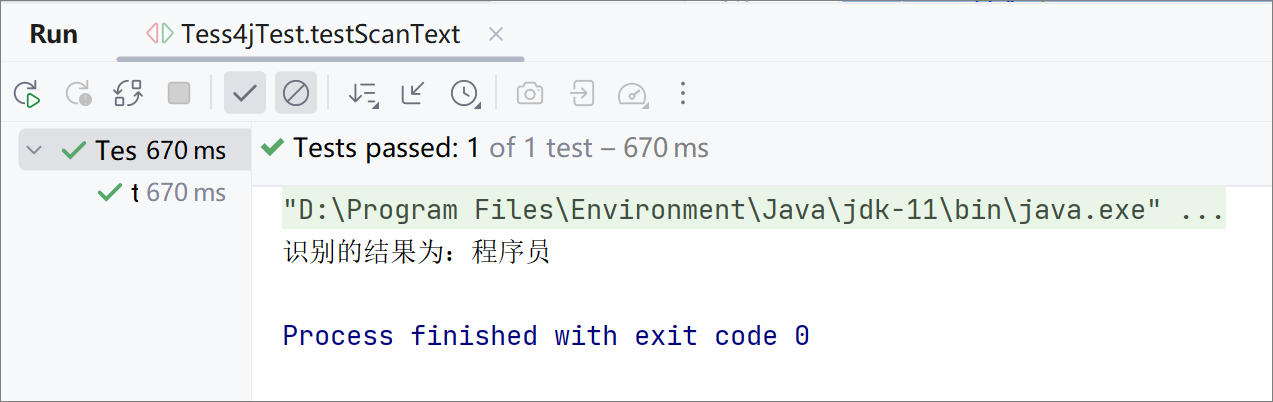
System.out.println("识别的结果为:" + result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
控制台打印结果:
仓库地址:https://gitee.com/z3inc/tess4j-demo.git
















 1655
1655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











