






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
目录
2.1.Communication-Efficient Learning of Deep Networks from Decentralized Data(2016)
2.2.Practical Secure Aggregatiofor Privacy-Preserving Machine Learning(2017SMPC)
3.2.1Data Poisoning Attacks Against Federated Learning Systems(2020)【标签翻转】
3.2.2【基于模型投毒的后门攻击 2020 AISTATS】How To Backdoor Federated Learning
3.3.3.2【基于植入触发器的分布式协同后门攻击】【2020ICLR DBA: Distributed Backdoor Attacks against Federated Learning】
3.3.4【相似度检测 2023 arXiv】Can We Trust the Similarity Measurement in Federated Learning?
3.3.2 【基于添加噪声的防御方法】【2019 Can You Really Backdoor Federated Learning?】
3.3.3 【基于特征提取的防御方法】【2020 Data Poisoning Attacks Against Federated Learning Systems】
3.3.4 【基于相似性的防御方法】【Byzantine-Robust Federated Learning by Inversing Local Model Updates】
3.3.5 【基于修改协议过程的防御方法】【2021 META FEDERATED LEARNING】
3.3.6 【联邦学习的鲁棒性】【Attack of the Tails: Yes, You Really Can Backdoor Federated Learning】【2020 NIPS】
本文主要整理个人在联邦学习2019-2022关于隐私与安全方面的学习。ben
提示:以下是本篇文章正文内容,下面案例可供参考
一、总述
如图:
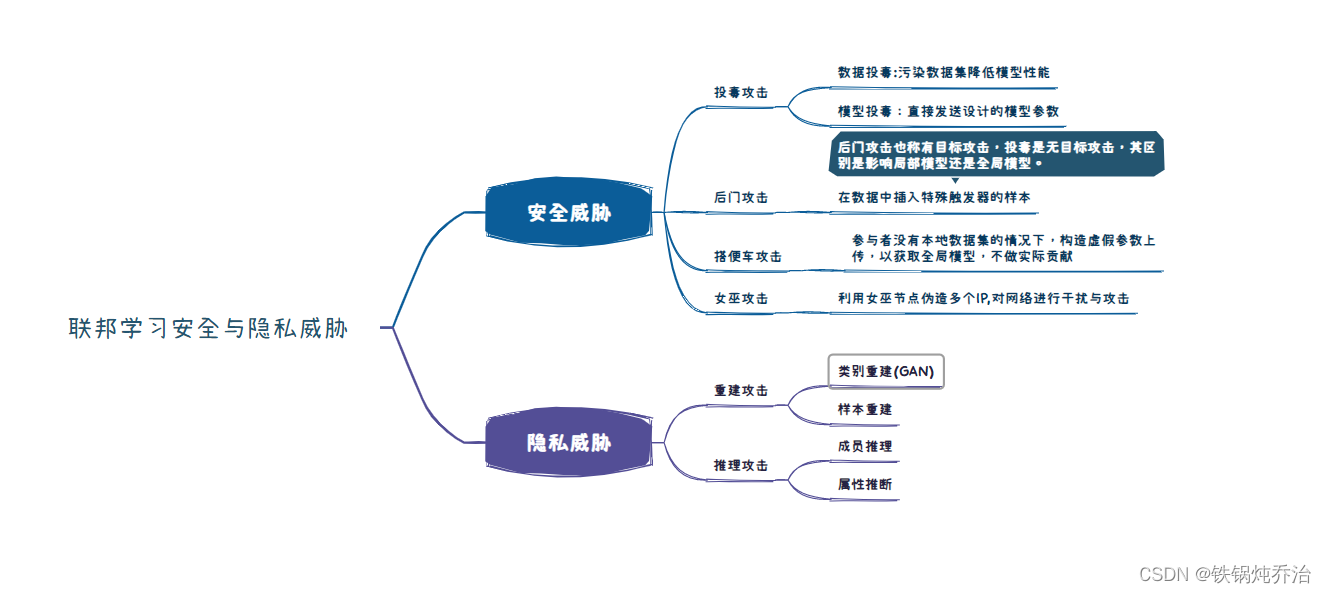
1.1联邦学习主要面临如上的数据安全和隐私威胁:
模型鲁棒性威胁:该威胁的攻击对象是服务器,攻击目的是让服务器无法正常聚合模型从而导致全局模型崩溃,按照有无目标可分为拜占庭攻击和后门攻击。拜占庭攻击和后门攻击都需要用到数据投毒,但是拜占庭的目标是使服务器直接崩溃,无目标的攻击,而联邦学习中的后门攻击比较隐蔽,其旨在不影响主线任务的情况下,控制支线攻击任务,故后门攻击危害更大,因为该攻击可能导致模型发布后的隐藏问题。
隐私保护的威胁:该威胁可以详细看刘艺璇的《联邦学习隐私保护综述》,区别于鲁棒性问题,该攻击不会影响全局模型的聚合,但是在训练过程中,该攻击会主动的获取被攻击方的数据,从而导致数据隐私问题
1.2联邦学习的安全属性
| 完整性 | 数据集完整性 | 联邦学习中 用户的数据始终是良性的、未被篡改. |
| 训练过程完整性 | 服务器、用户等参与方都严格地按照联邦学习协议执行算法 | |
| 可用性 | 训练可用性 | 收敛性:指模型能够在 经过可接受的训练轮数内达到收敛状态 |
| 合作公平性:是联邦学习场景中特有的,指用户能够依据自身的贡献获得公平的补偿 | ||
| 模型可用性 | 在推理阶段模型部署后的准确性和公平性,其中公平性是指保证训练的模型不会对某些属性存在潜在的歧视性 | |
| 机密性 | 机密性是指本地数据、全局模型等敏感信息不会泄露给非授权的用户。另外,机密性还保证了用户不会因为网络不稳定、设备问题被动退出工作流后,导致本地梯度的机密性泄露. | |
1.3 一些想法
1.3.1 探究一种高效的聚合方案,其不但可以兼顾安全聚合,也能够进行后门的筛查。
难点:
1.安全聚合个客户端之间需要进行双掩码处理,如何在参数已改变的情况下,发现中毒的模型。?一点思路:模型的参数是不是必须作为审查的标准,除了参数,我们还能审查什么?
2.需要解决NIID问题。
1.3.2 探究一种方案,解决后门遗忘问题和后门注入的时间限制问题。
难点:
1.后门攻击的时间间隔不允许太长,否则模型将遗忘中毒的参数,那么神经网络是否可以对某些参数处理后,使其参数保持不变
2.是否存在一种高效的后门注入方案,使得不需要在模型收敛时,也能达到较好的注入效果?
1.3.3 分布式后门好,但是如果部分客户端的攻击不足以触发全局触发器的效果怎么办?
二、联邦聚合
2.1.Communication-Efficient Learning of Deep Networks from Decentralized Data(2016)
2.1.1概要(本文贡献):
(1)引入联邦学习的概念:传统数据训练方式,用户将本地数据提交给可信云服务器进行统一集中并训练,需要一种范式保证用户本地数据的隐私性,计算成本和通信开销。并给出优化与挑战:
– 数据非独立同分布(Non-IID)
– 数据不平衡(不同用户参与度不一致,每个用户拥有的数据样本数不一致)
–大规模分布式(大规模用户如何应对以控制开销)
–通信限制(用户传输参数(梯度)后多处于离线状态)(2)基于FedSGD提出FedAvg
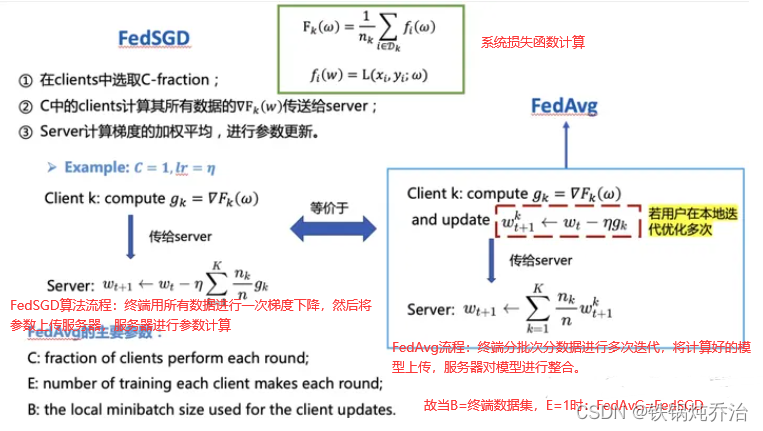
2.1.2FedAvg算法方案:

2.2.Practical Secure Aggregatiofor Privacy-Preserving Machine Learning(2017SMPC)
最经典的联邦学习安全聚合方案出自2017谷歌提出的一种方案。其大致算法和解决的问题如下:
2.2.1.问题定义:
有N个用户,每个用户有一个值x ,然后 server 需要计算
,但是每个用户又不能把自己的数据交出去。于是,作者提供了这么一个思路,能不能用户1减去个数,用户2来加个数,这样用户1和用户2的数据都不准了,但是总的求和还是准的。然后这个思路扩展一下,就有了论文中的方案。
2.2.2.设计:
分为两个函数,Mask(负责给每个客户端加掩码),Aggregation(用于聚合每个客户端的的参数)
Mask操作:所有的用户两两协商一个随机数,即:用户主与用户j协商随机数si,j,然后对数据x按照下式进行扰动,结果为yi,即:
则聚合(Aggregation)的总参数消除了掩码:
问题一:随机数怎么协商&客户端突然掉线了怎么办?
改进随机数协商方案:
现在的算法是两两如何确定一个随机数并且这个随机数还不能被第三者知道。这个方案可以使用DH秘钥协商方案来实现随机数协商,并且可以借助 pseudorandom generator(PRG) 减少通信开销。协商的秘钥作为伪随机数生成器 PRG 的种子。所以协商随机数,实际上协商的是随机数的种子。
一个简单的DH密钥交换的流程:
改进客户端掉线后,掩码抵消不了的方案:
恢复阶段客户端掉线,那么恢复阶段掉线客户端拥有的n-1个掩码无法抵消,一种想法是使用秘密共享,将每个掩码以秘密共享的方式发出即可,所以我们需要只要存在足够的客户端,这些随机数就能被还原回来的方法。有了这个t-out-of-n的秘钥共享方案,只要有t个用户在线,就不怕客户端掉线了。
问题二:某个客户端由于延迟原因,该客户端的所有掩码已被破解,但此时他上传数据,导致他的数据泄露。
如何解决延迟问题?为什么延迟会带来问题?我的想法是如果正常运行掩码能够正常抵消,服务器不会去破解掩码。如果因为延迟,则服务器未收到参数后可以和其他t个客户端协商破解该客户端的秘密。那客户端延迟后上传参数就使得服务器得到参数。考虑到更为宽泛的问题,如果服务器是好奇且恶意的,那他可以欺瞒除了目标客户端外的所有客户端,告诉他们目标客户端已经掉线,并通过他们来对目标客户端的秘密进行破解,不需要掉线的条件。
解决思路:在设置一个掩码,无论什么情况,服务器都不能同时知晓两个掩码的值。


三、安全威胁
3.1攻击分类
3.1.1投毒攻击
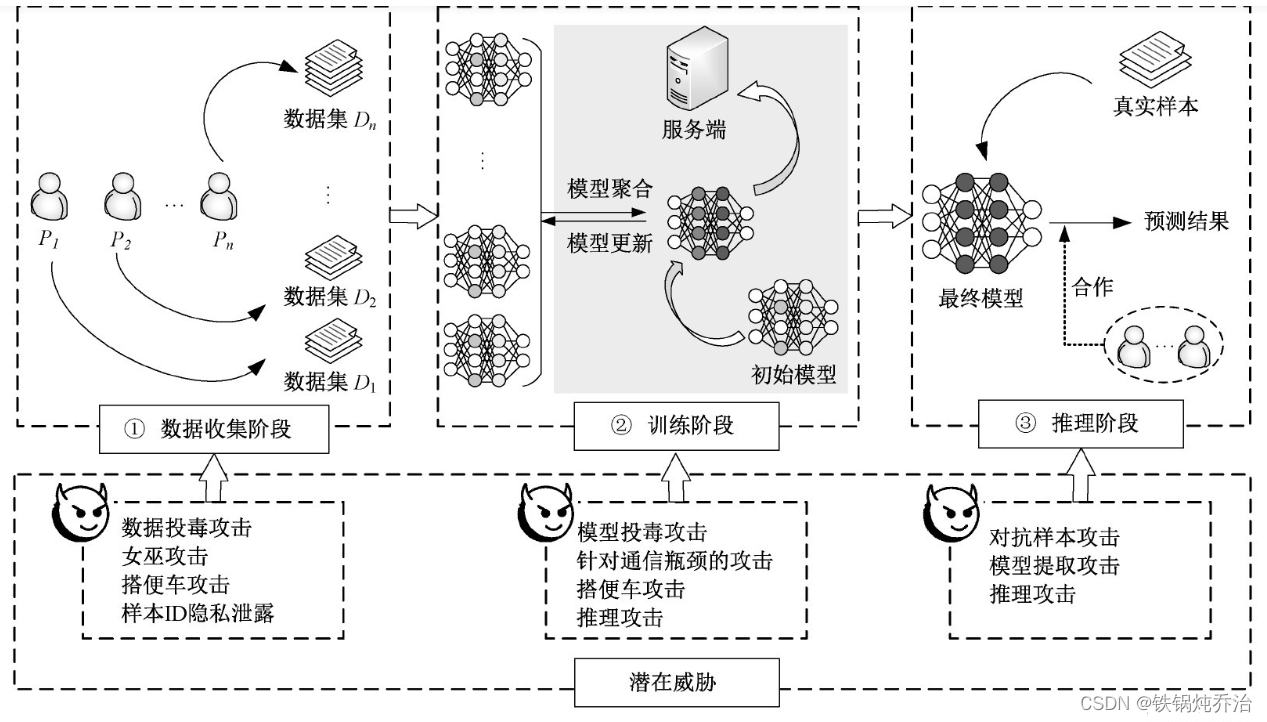
机器学习中的投毒攻击是指攻击者通过控制和操纵部分训练数据或模型来破坏学习过程。而联邦学习中每个用户都拥有一个数据集,内部的恶意攻击者可以轻易地对数据集、训练过程和模型进行篡改,实现降低模型性能、插入后门等一系列攻击效果。投毒攻击是联邦学习中应用最广泛、研究最深入的攻击。通常,投毒攻击按照攻击方式的不同可以分为数据投毒和模型投毒,而根据攻击目标的不同可以分为拜占庭攻击(即非定向投毒攻击)和后门攻击(即定向投毒攻击)。
(1)按攻击方式划分
①数据投毒:攻击者破坏训练数据集的完整性,通过渗入恶意数据以降低数据集质量或有目的的毒害数据。数据投毒根据对数据集标签的不同操作分为脏标签攻击(Dirty-labelAttack)和清洁标签攻击(Clean-labelAttack)。脏标签攻击会篡改数据集的标签,如常见的标签翻转攻击,而清洁标签攻击不篡改标签,仅对数据进行处理生成新的样本。联邦学习中由于数据不出本地,只有模型作为信息载体,因此基本不考虑数据投毒的不可感知性,从而数据投毒攻击主要是更加简便有效的脏标签攻击。②模型投毒:攻击者破坏训练过程完整性,通过完全控制部分用户的训练阶段,对上传的局部模型进行篡改,实现对全局模型的操纵。常见的攻击手段是通过提升(Boosting)恶意更新来加强攻击效果。为了增强提升的隐蔽性,Bhagoji等还将提升过程转化为一个基于交替最小化找到合适的提升值优化问题,使有毒更新与正常更新难以区分。此外,还有其他实现更强隐蔽性和更高成功率的模型投毒攻击和针对服务器先进防御聚合机制的隐蔽模型投毒攻击等研究。虽然数据投毒和模型投毒两种攻击方式都对模型训练产生影响,但单一的数据投毒相较模型投毒表现不佳,是因为数据投毒本质上与模型投毒会同样修改局部模型的更新权重,而后者可以针对联邦学习聚合等特性实施针对性的攻击。
(2)按攻击目标划分
①拜占庭攻击:攻击者试图破坏训练可用性和模型可用性,使其无法收敛或无法在主要训练任务中达到最优性能,并且不针对任何特定的用户或数据样本。在联邦学习中,通过发送恶意更新和其他良性更新的线性组合能实现拒绝服务攻击,但此类简单的攻击很容易被检测和过滤。已有文献表明更新中轻微的扰动就能够实现投毒攻击的效果,并且规避基于幅度的防御策略。已知聚合规则的攻击者可以针对性地实施更具破坏性的拜占庭攻击,并且服务器为了吸引用户或满足用户的知情权,其聚合规则常常是透明公开。当前,VFL中拜占庭攻击的相关研究还很少,由于模型被用户分割,数据投毒和模型投毒的隐蔽性更强、危害更大,是一个值得深入研究的方向。②后门攻击:又叫木马攻击(TrojanAttack)攻击者试图使模型在某些目标任务上实现特定表现,同时保持模型在主要任务上的良好性能。不同于拜占庭攻击由于会降低主要任务的总体性能易被检测,后门攻击更难被检测,这是因为攻击目的通常是未知的,难以确定检测标准。后门攻击可以通过数据投毒和模型投毒来实现,其在缺乏防御时的表现在很大程度上取决于当前敌手的比例和目标任务的复杂性。此外,相同的后门触发条件可能导致不同标签的样本错误的分类,这不同于后文的对抗样本攻击只对特定修改后的图像进行错误分类,不会影响到其他图像样本。一些方案是在数据集上实现的后门攻击。而在联邦学习中,结合模型投毒实现的后门攻击更为常见。与HFL中的后门攻击不同,在典型VFL模型中的用户无需提供也不能获得标签信息,也就意味着不具备特征实例所对应的目标标签的知识。
3.1.2 对抗样本攻击
机器学习中的对抗样本攻击是指在推理阶段中,刻意地给输入样本增加轻微的恶意扰动,使得分类器以极高概率对样本进行错误分类,从而导致模型输出错误的预测结果。按照攻击者拥有的信息,对抗攻击可以分为白盒攻击和黑盒攻击。在白盒攻击中,攻击者能够获得机器学习算法以及模型参数,并根据这些已知信息去制作对抗样本。在黑盒攻击中,攻击者不知道机器学习的算法和参数信息,通过与系统的交互过程来生成对抗样本。
一方面,联邦学习的分布式特性增加了模型参数泄露的可能性,这意味着联邦学习比传统机器学习更容易遭受白盒攻击的威胁。另一方面,与传统机器学习类似,在联邦学习模型部署之后,攻击者也能够通过与系统的交互实施黑盒攻击。
3.1.3 搭便车攻击
搭便车攻击是指部分用户不参与协作或者不具备足够的条件,而试图从集体性质的服务和公共产品中获得优势。其主要发生在带有激励的联邦学习中,破坏训练过程完整性和合作公平性。攻击者一般不消耗或只消耗部分的本地数据和计算资源,通过向服务器发送随机更新或与聚合模型相似的更新,伪装成参与联邦学习训练的正常用户,以获得相应激励,同时可能对模型性能造成一定影响。在联邦学习中,常见的搭便车攻击通过提供随机参数更新实现攻击,而服务器可以使用传统的深度学习异常梯度检测进行防御,如DAGMM。此外,搭便车攻击者也可能会通过提升方法来增大权重,从而在全局服务器上表现出更大的贡献程度,以获得更大的激励份额。在VFL中的用户也可能不进行完整的训练,而应用未经充分训练的低质量模型,会降低整体模型的性能。此外,VFL的用户并不公开模型信息,服务器更难区分低质量的模型,故VFL中的搭便车攻击值得进一步研究。
3.1.4 女巫攻击
女巫攻击(SybilAttack)指在允许成员自由加入和退出的系统中,单个攻击者通过多个合谋的身份加入系统,从而巧妙地分配攻击,以增强隐蔽性和攻击效果。女巫攻击常被用于投毒攻击中,也可以应用在其他对抗性攻击中,以扩大对抗性攻击的优势。尤其在跨设备(Cross-device)联邦学习中,用户认证强度低,攻击者可以通过伪造多个身份实施女巫攻击,以便提高攻击效果。而在VFL中,由于用户数量较少,认证强度高,女巫攻击的应用将受到限制,较难实施。
3.1.5 针对通信瓶颈的攻击
在联邦学习中,需要在大量参与设备和服务器之间来回交换更新后的梯度,频繁的通信和传输的数据量都会产生大量的通信开销;其次,大量异构设备有限的网络带宽,会增加成员掉队的情况,进一步导致通信时间增长;此外,攻击者可能通过破坏通信信道来影响联邦学习系统的稳定性和鲁棒性。以上这些问题成为了联邦学习的主要通信瓶颈,统称为针对通信瓶颈的攻击,它影响了联邦学习的训练可用性,在HFL与VFL系统中都有可能发生。针对通信瓶颈的攻击比投毒攻击、对抗样本攻击和后门攻击的普遍性更低,但其导致的后果非常严重,一旦系统遭受通信瓶颈攻击,可能会显著破坏联邦学习环境,给系统带来严重的损失。这种攻击最直接的解决方法是降低通信开销,把需要上传的更新量化,显著减少需要传输的数据大小。
3.2攻击论文
3.2.1Data Poisoning Attacks Against Federated Learning Systems(2020)【标签翻转】
(1)问题:
联邦学习中,少量的恶意客户端是否会对模型产生较大影响?
(2)创新:
作者在已有的标签翻转的情况下,提出了针对联邦学习后门的标签翻转攻击。
无目标的攻击中也有标签翻转攻击,但其是将任意类的标签进行翻转。而在后门攻击中,标签翻转是仅对某一类标签进行翻转,仅在目标类上降低模型精度。
(3)攻击者设定
| 攻击者 | 客户端 |
| 攻击目标 | 使得最终模型对一定的类别具有高误差而其他类影响低而躲过监测。 |
| 攻击者能力 | 只能够控制数据集(白盒) |
| 轮次 | 多轮 |
(4)方案:
攻击方案:选取m%的终端,将其某个类别c—>ctaget。
防御方案:如图:

(5)结果
攻击影响:随着恶意参与者百分比的增加,整体模型测试精度下降。即使m很小,我们也观察到模型精度与非中毒模型相比有所下降,并且源类精度有更大的下降。攻击者即使控制了客户端的很小一部分,也有能力对全球模型效果产生重大影响。
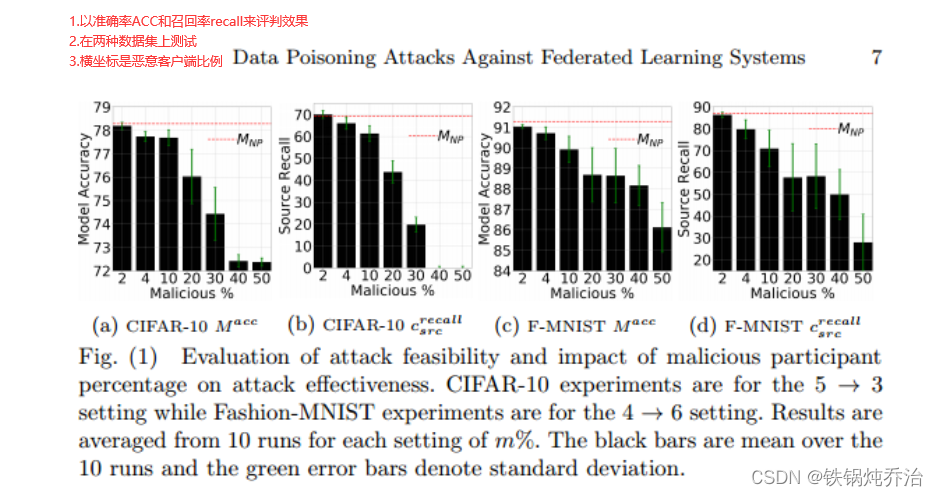
攻击针对性:被攻击的类别精度下降较为明显,而其他类别影响较小。全局模型精度与被攻击类别精度密切相关,比率几乎为1:10。

攻击时间对实验的影响:
在200轮的迭代中,在75轮之前攻击在当时会对模型造成影响,但是在后续的迭代中几乎会被纠正。可以考虑到,是其他客户端稀释了攻击。
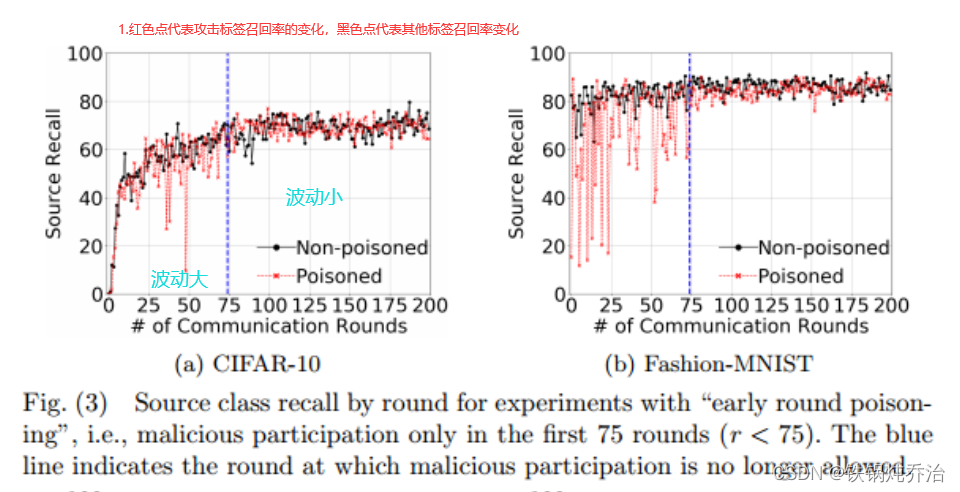
但如果我们在75轮后攻击,则可以显著防止这种行为:
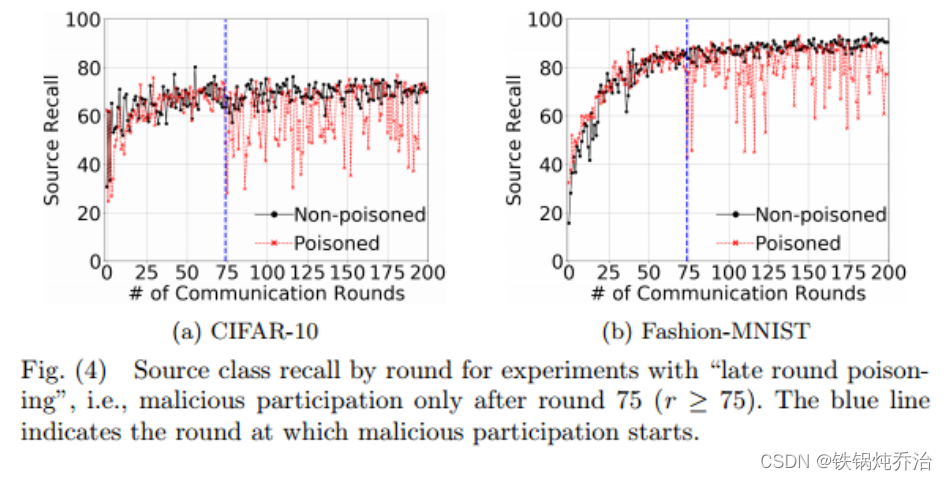
结论:标签翻转攻击的效用影响主要取决于在最后几轮训练中选择的恶意参与者的数量,即使小批量的恶意参与者,也会造成较大影响。
防御结果:plot结果显示,与诚实参与者的更新形成自己的集群相比,恶意参与者的更新属于一个明显不同的集群,即使攻击者较少,也能够明显识别出恶意模型,且防御并没有受到“梯度漂移”问题(模型梯度发生变化,其方向不再是最优方向)的影响。

(6)思考
本文引入的攻击策略其实有两个比较严重的局限性:
1.单纯的基于标签翻转的攻击会由于联邦学习的客户端有很多,导致聚合时稀释了后门模型的大部分贡献,全局模型很快就会忘记后门。
2.单纯的标签翻转很容易被识别并过滤,攻击强度弱
3.2.2【基于模型投毒的后门攻击 2020 AISTATS】How To Backdoor Federated Learning
(1)问题
如何解决遗忘后门且提出一种不易被筛查恶意更新的联邦后门攻击?
(2)创新
首次提出首次提出联邦学习中的模型投毒攻击
(3)攻击者设定:
| 能力 | 控制而已客户端的本地数据 |
| 控制本地训练过程和超参数 | |
| 修改模型权重 | |
| 自适应攻击 | |
| 轮次 | 单轮 |
| 攻击目标 | 后门攻击 |
| 是否共谋 | 否 |
(4)方案
1.模型投毒的定义
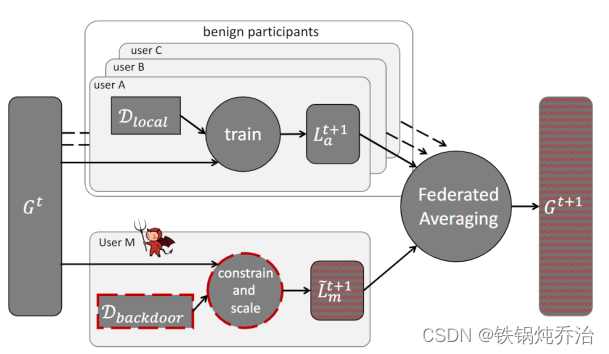
服务器初始全局模型,本地终端使用本地的数据集D训练本地模型L最终通过聚合得到
,按其诚实与否分为两类:1.诚实的客户端ABC,其使用干净的训练本地模型
。2.恶意的客户端,其使用植入后门的数据集制作本地恶意模型
。
2.对抗性转换和后门的区别
①对抗变换:利用模型对不同类的表示之间的边界来产生被模型错误分类的输入,如专门制造一些数据来改变类别之间的界限。
②后门:改变class之间的界限,从而使某些输入被错误分类
3.后门优化
①朴素的后门:通过每个batch混合良性数据和中毒数据,然后调整本地学习率和epoch使得模型对后门数据过拟合,从而导致对某一类别的后门。
②模型替换
a.诚实客户端的训练:

b.后门需要考虑的问题:
设计后门需要考虑后门的特点(不影响主任务的情况下,影响某个子任务),从两方面设计可实现这一目标:损失函数的设计和上传服务器端的模型权重:
首先分析损失函数的设计。恶意客户端在训练时,一方面保证模型训练后在毒化数据集和正常数据集上都能取得好的效果,另一方面要保证当前训练的本地模型不会过于偏离全局模型,具体来说,其损失函数主要由下面两部分构成。
类别损失:恶意客户端既拥有正常的数据集
,也含有被篡改毒化的数据集
,因此训练的目标,一方面确保主任务性能不下降,另一方面保证模型在毒化数据上做出错误的判断。我们将这一部分损失值称为类别损失
,其计算公式如下所示:
距离损失:如果仅用上式的损失还书对恶意客户端进行训练,那么服务器可以通过观模型距离等异常检测的方法,判断上传的客户端模型是否为异常模型,如计算两个模型之间的欧氏距离。为此我们修改异常客户端损失函数,在上式基础上添加当前模型与全局模型的距离损失。我们将两个模型的距离定义为它们对应参数的欧氏距离。修改后的失函数定义为:
。直观上,我们通过使用目标函数将异常检测的规避纳入训练中,该目标函数(1)奖励模型的准确性,(2)惩罚偏离聚合器认为“正常”的模型。遵循 Kerckhoffs 原理(敌手知道密码学算法的结构,但数据仍然安全),我们假设攻击者已知异常检测算法。通过约束和缩放方法。通过添加异常检测项 Lano 来修改目标(损失)函数,结合先前的损失函数有:
如果面对更简单的异常检测器(如欧几里得算法),则可以使用更简单的逃脱算法:
攻击者训练后门模型直到其收敛,然后将模型权重按 扩大到异常 d 允许的界限 S,即:
其次考虑上传服务器端的模型权重(如何保证在后门触发时影响最大)的设计:
存在问题:传统机器学习的后门攻击很可能在联邦中失效,原因是模型聚合运算时,平均化后会很大程度消除恶意客户端模型的影响。另外由于服务端的选择机制,我们并不能保证被挟持的客户端能够在每一轮中被选中,而这进一步降低了后门攻击的风险。通常在几轮后会造成后门遗忘的现象。

注意:
①若攻击者不知道参数n和η,可以在通信中逐渐增加攻击比例
②有些防御方法要求良性客户端进行梯度裁剪和噪声:攻击者可以不使用差分隐私,或将接近于0的参数裁剪为0
③该方法使得single-shot attack也可以十分高效
c.综上得到恶意客户端训练过程

(5)思考
本文提出的模型投毒攻击利用调整损失函数和更新的权重实现了一种新的攻击方式。
优点:相比于数据投毒攻击,模型投毒攻击是联邦学习特有的一种攻击,并且有更好的攻击性与隐蔽性。在研究投毒攻击的防御方案时,需要针对模型投毒攻击进行设计。
缺点:容易受梯度裁剪+差分隐私的防御方案的影响。
同时,参数放缩的方法虽然能突破异常检测等防御方法且具有在攻击者可以控制多个客户端时,那么可以将每个客户端的放缩因子变得比较小,从而使其不会超过被服务器剪裁的阈值。同时,如果放缩因子设置的比较大,攻击者只需在一轮中投毒,即可将后门嵌入全局模型等优点。但参数进行的操作需要在隐蔽性与后门攻击成功率之间权衡,如果对防御方的防御方法不够了解,仅对参数进行放大等操作则很可能被防御方检测出来。
3.3.3 【植入触发器的后门攻击】
3.3.3 .1 攻击分类
其实植入触发器的后门攻击可以理解为数据投毒的后门攻击,相比普通的数据投毒,其隐蔽性更强,但是相较于模型投毒的后门攻击,其攻击又较弱。
| 分类标准 | 类型 | 特点 |
| 触发器个数 | 单触发器后门攻击 | 只生成一个触发器,发送给攻击者控制的所有恶意客户端。 |
| 协同触发器后门攻击 | 是每个恶意客户端的局部触发器都不相同,全局触发器由各独立的局部触发器组成。 | |
| 是否依赖模型 | 随机触发器 | 独立于学习模型产生的。由于随机触发器与模型训练过程没有关联,所以它在触发后门模型后门的能力较弱。 |
| 模型依赖触发器 | 基于攻击者的局部模型生成的触发器,能最大限度地激活学习模型中的某些神经元,全局模型在聚合后更有可能记住模型依赖触发器。 | |
| 触发器是否分散 | 集中式后门攻击 | 全局触发器被全部注入到每个恶意客户端的本地训练数据集 |
| 分布式后门攻击 | 全局触发器分解为独立的局部触发器,并且相应地嵌入到不同的恶意攻击方的训练集中。 |
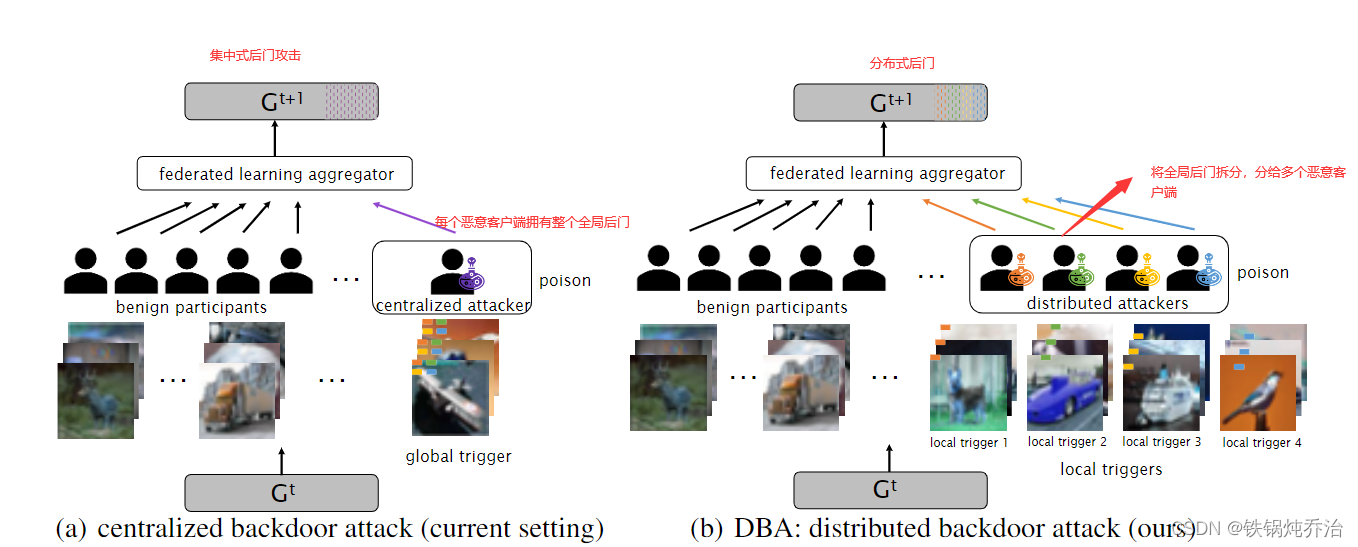
3.3.3.2【基于植入触发器的分布式协同后门攻击】【2020ICLR DBA: Distributed Backdoor Attacks against Federated Learning】
(1)问题:
联邦学习 (FL) 的分布式学习方法和各方固有的异构数据分布可能会带来新的漏洞。同时,集中式的注入整体触发器到一定比例的恶意客户端可能导致局部模型偏离整体模型而被检测出来。那将触发器拆分后分给恶意客户端,是否能更为隐蔽,效果更强?
(2)创新:
相对于集中后门攻击(每一方在训练期间嵌入相同的全局触发器),作者提出了分布式后门攻击 (DBA)——这是一种通过充分利用 FL 的分布式特性开发的一种新颖的威胁评估框架。DBA 将全局触发模式分解为单独的局部模式,并将它们分别嵌入到不同恶意客户端的训练集中。与标准集中式后门相比, DBA 在不同的数据集上(例如金融和图像数据)对 FL 更加持久和隐蔽,可以规避针对集中式后门的两种最先进的鲁棒 FL 算法。作者通过广泛的实验,以证明 DBA 在不同设置下的攻击成功率显着高于集中式后门。也通过特征视觉解释和特征重要性排名为 DBA 的有效性提供了解释。所提出的DBA和彻底的评估结果也揭示了表征FL的鲁棒性。
(3)方案:
服务器聚合方案:
具体来说,在第 t 轮中央服务器将当前共享模型发送给选择方,其中 [N ] 表示整数集 {1, 2,., N }。所选方 i 通过运行优化算法(例如 E 个局部 epoch 的随机梯度下降 (SGD))及其自己的数据集和学习率 lr)局部计算函数 ,以获得新的局部模型 。即:
定义触发器:

符号定义:
| 符号 | 定义 |
| TS | 局部分布式触发器的像素列的数量(即宽度) |
| TG | Gapx和Gapy的距离,分别表示左侧和右侧之间的距离。即将全局触发器分割为局部触发器后,两个触发器的距离。 |
| TL | (Shif-tx,Shif-ty)是触发图案相对于左上像素的偏移。即触发器的位置。 |
| 缩放因子,缩放参数γ=η/N来缩放恶意模型的权重。 | |
| r | 该比率控制每个训练批次添加的后门样本的数量 |
| I | 攻击间隔 |
| 全局触发器的信息,即{TS,TG,TL} | |
| O | 触发器的分割策略 |
| 局部触发器的集合,即{
| |
| 触发器指向的恶意标签 |
恶意客户端:
朴素的后门攻击(集中式后门):
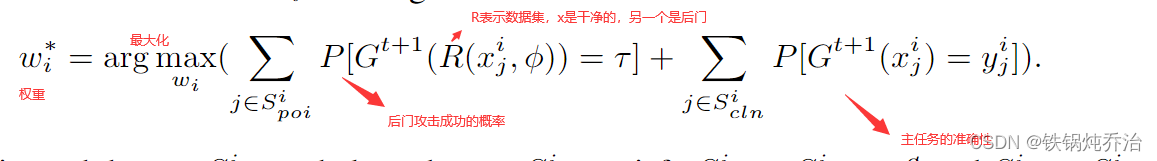
DBA方案:
在DBA中,每个攻击者只使用全局触发器的部分来污染其本地模型,而攻击的目标仍然是使用全局触发器攻击共享模型。且局部触发器的总和为全局触发器。即最优化以下问题:

对比集中式后门攻击和DBA的不同:
在集中攻击中,攻击者试图在没有任何协调和分布式处理的情况下解决方程1中的优化问题。
而DBA利用分布式学习和本地数据的不透明性,将集中式攻击分解为多个分布式子攻击问题。每个DBA攻击者独立对其本地模型进行后门攻击,并使用特定的几何分解策略和触发器分解规则。尽管DBA下没有任何一方受到全局触发器的污染,但在使用全局触发器进行评估时,DBA的性能显著优于集中式攻击。
(4)实验:
攻击者设定:
| 场景 | 多次攻击A-M | 表示攻击者多轮被选择 | 侧重方面 | 多次攻击 A-M 研究后门成功注入的能力。 |
| 单次攻击A-S | 单次攻击A-S意味着每个DBA攻击者或集中式攻击者只需要一次攻击即可成功嵌入其后门触发器 | 单次攻击 A-S 研究了后门效应减少的速度。 | ||
| 后门像素总数 | 为了公平比较,我们确保 DBA 攻击者的后门像素总数接近甚至小于集中式攻击者的后门像素总数(由于具有一定分布的数据样本,很难控制它们是相同的)。DBA像素的全局触发器与集中式触发器之比为0.992,MNIST为0.964,CIFAR为0.990,Tiny-imagenet为0.991。 | |||
1.与集中式后门的比较
实验效果:
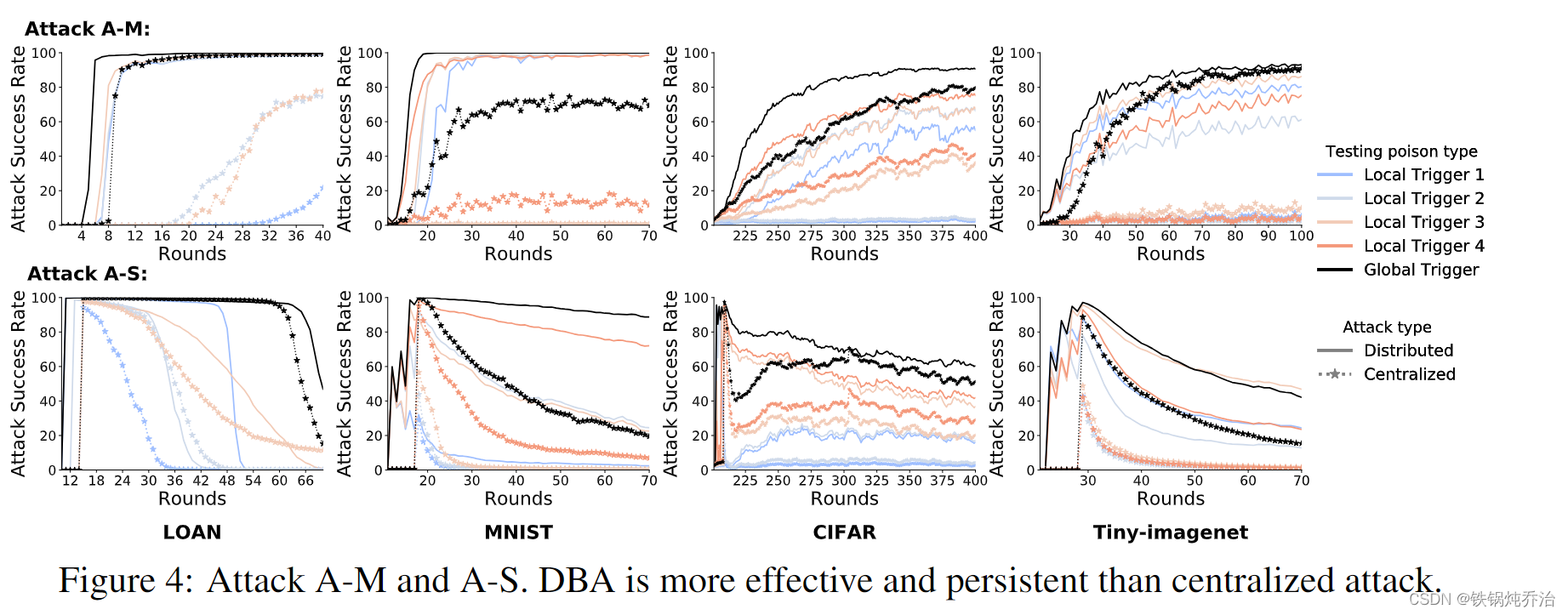
1)在多次攻击A-M中,DBA的攻击成功率在所有情况下都总是高于集中攻击,实线无论在什么情况下,均高于虚线。
2)在多次(A-M)下,DBA的收敛速度和注入速度更快,甚至在MNIST中产生更高的攻击成功率。
3)在 DBA 下,全局触发器的攻击成功率也高于任何本地触发器。
4)此外,全局触发器在攻击性能上比本地触发器收敛得更快。集中式攻击者嵌入了整个模式,因此其任何本地触发器的攻击成功率都很低。
5)由于连续中毒,LOAN 局部触发器的攻击成功率仍然增加,但这种现象不会出现在 MNIST 和 Tiny-imagenet 中,这表明全局触发器的成功对于局部触发器不需要相同的成功。
6)即使在一些本地触发器仅获得较低的攻击成功率时,DBA 也会导致全局触发器的高攻击成功率。这一发现对于 DBA 是独一无二的,并且还暗示了集中攻击对 FL 的低效率。
7)在单次攻击 A-S 中,DBA 和集中式攻击在以比例因子 γ = 100 的所有数据集中执行完整的后门后都达到较高的攻击成功率,如图所示,在连续轮次中,注入全局模型的后门被良性更新削弱,因此攻击成功率逐渐降低。CIFAR 中的集中攻击存在初始下降,然后缓慢上升,这是由良性参与者的高局部学习率引起的。
8)我们还发现,集中攻击在本地触发器和全局触发器中的攻击成功率比DBA下降得更快,这表明DBA产生了更持久的攻击。例如,在 MNIST中和在 50 轮之后,DBA 都仍然是 89% 的攻击成功率,而集中式攻击仅获得 21%。
9)尽管 DBA 仅使用本地触发器执行数据中毒,但结果表明其全局触发器的持续时间比任何本地触发器都长,这表明DBA可以使全局触发器对良性更新更有弹性。
2.针对两种鲁棒性聚合方案的攻击
实验效果:
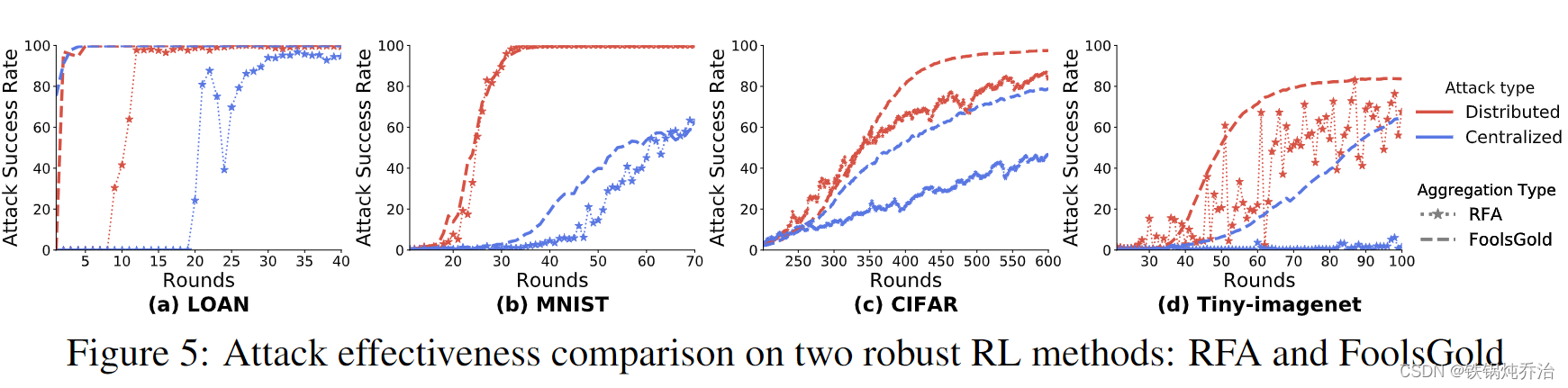
上图显示了DBA和集中后门在RFA和FoolsGold上的攻击性能
1)对于Tiny-imagenet,集中式攻击在至少 80 轮中完全失败,而具有较低距离和较高聚合权重的DBA攻击者可以执行成功的后门攻击。
2)对于 MNIST 和 CIFAR,DBA 的攻击成功率更高且收敛速度更快。
3)对于 LOAN,集中式后门攻击比 DBA 要多花费 20 轮的时间才能收敛。
4)在三个图像数据集中,DBA 的攻击成功率明显更高,同时收敛速度更快。
5)当集中式攻击失败时,MNIST 中的 DBA 在第 30 轮达到 91.55%,攻击成功率仅为 2.91%。
6)对于用简单网络训练的 LOAN,FoolsGold 无法区分恶意更新和干净更新之间的差异,并为攻击者分配高聚合权重,从而实现快速后门成功
3.通过特征可视化证明方案的有效性
使用两种特征可视化方法,一种观察网络注意力的变化,另一种侧重分析特征重要性的变化。
| 方法 | 原理 |
| Grad-CAM | 是一种用于理解深度神经网络决策的可视化技术。它通过分析卷积神经网络(CNN)对于输入图像的反向传播梯度来定位和强调图像中影响分类结果的区域。即显示网络会重点注意到的区域。 具体来说,Grad-CAM首先通过前向传播计算出分类结果,然后计算该结果对于目标类别的梯度。这个梯度表示了结果相对于输入图像的每个像素的敏感度。接着,通过使用这些梯度和卷积层的输出特征图,可以计算出每个像素对于分类结果的重要性权重。最后,将这些权重与原始图像进行加权叠加,就可以得到一张彩色的Grad-CAM图像,用于可视化网络对于分类结果的关注区域 |
| 软决策树 | 是一种基于决策树模型的机器学习方法,与传统的二叉决策树不同,软决策树允许在决策过程中产生一系列软概率分布,从而更全面地描述数据的不确定性。 软决策树的优点是可以输出更为丰富的概率信息,能够更全面地评估模型对于不同类别的判定,对于处理不确定性和多类别分类问题更有优势。此外,软决策树还可以通过对节点概率分布的可解释性进行解释和理解,能够更好地帮助人们理解和信任模型的决策过程。 |
| 软概率分布 | 一种概率分布,与传统的离散概率分布不同,它允许将概率分配给多个类别或事件,从而在不确定性情况下提供更灵活的概率估计。 传统的概率分布通常是离散的,将概率分配给互斥的事件或类别,例如抛硬币的结果只能是正面或反面,概率分别为0.5。而软概率分布则可以将概率分配给多个类别,通常以概率分数的形式表示,每个类别的概率分数可以是任意实数值。 软概率分布常用于模糊推理、不确定性建模和机器学习等领域。它能够更好地处理不确定性情况下的分类和决策问题。例如,在多类别分类任务中,软概率分布可以表示一个样本属于每个类别的可能性程度,而不仅仅是简单的二元分类结果。在软概率分布中,概率分数可以进行归一化,使其总和为1,以表征概率分布的性质。常见的软概率分布方法包括Softmax函数、Sigmoid函数等。 |
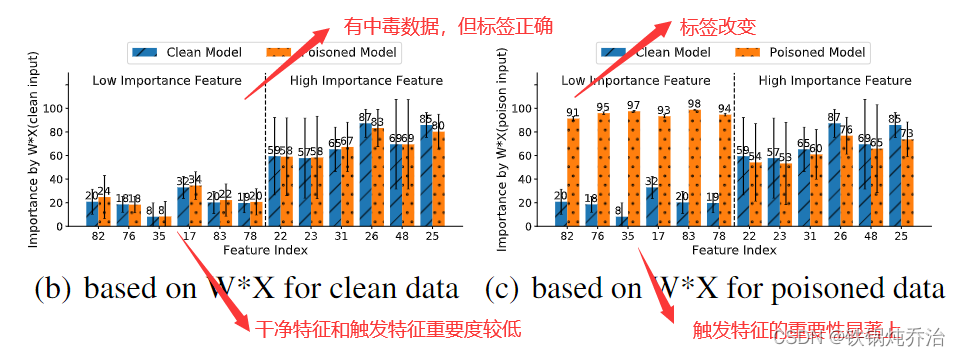
Grad-CAM结果:

上图显示了手写数字“4”的 Grad-CAM 结果。我们发现单独的每个局部触发图像都是一个弱攻击,因为它们在嵌入触发器的左上角没有注意,所以每个局部触发器都不能改变预测,预测结果都为4。然而,当组装成全局触发器时,后门图像被归类为“2”(目标标签),我们可以清楚地看到注意力被拖到触发器的区域。Grad-CAM 导致大多数局部触发图像的事实与干净图像相似,证明了 DBA 的隐蔽性。
软决策树结果:
4.研究后门攻击的因素
需要研究的因素:
| 因素 | 方法 |
| 比例因子 | 通过扩大比例因子,从而扩大后门攻击的规模 |
| 触发器 | 控制触发器位置,研究后门攻击的情况 |
| 中毒间隔 | 控制中间攻击间隔,研究后门攻击的持久性 |
1)比列因子
符号解释:
| 符号 | 意义 |
| DBA-ASR | 单次攻击 A-S 的攻击成功率。 |
| Main-Acc | 表示嵌入最后一个分布式本地触发器时全局模型的准确性。 |
| DBA-ASR-t | 攻击持久性,是在执行完整 DBA 后 t 轮的攻击成功率 |
| Main-Acc-t | 是 t 轮后的主要任务准确度 |
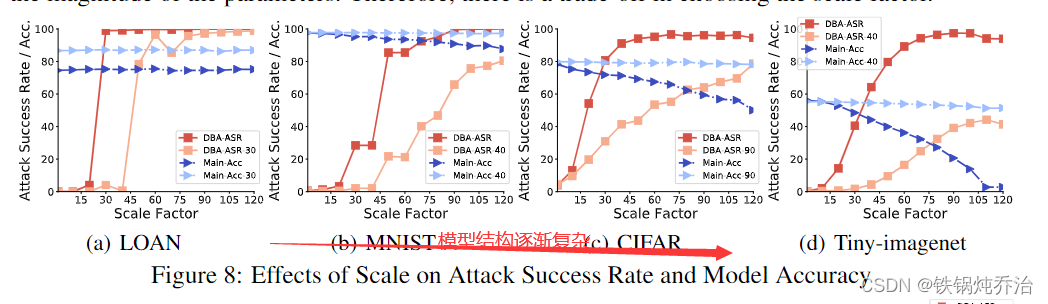
结论:
1.模型架构越复杂,主准确度随着 γ 的增加而下降的趋势就越明显。原因是缩放破坏了复杂神经网络中更多的模型参数。
2.比例因子大的优点:较大的比例因子缓解了中央服务器对DBA的平均影响,导致攻击性能更具影响力和抵抗力.
3.比例因子大的缺点:导致全局模型在三个图像数据集的攻击轮次中的主要准确率下降。此外,使用大规模因子会导致与其他良性更新过于不同的异常更新,并且很容易根据参数的大小进行检测。
因此,在选择比例因子方面需要进行权衡。
2)触发位置
对于三个图像数据集,作者将全局触发位置从左上角移动到中心,然后移动到右下角。
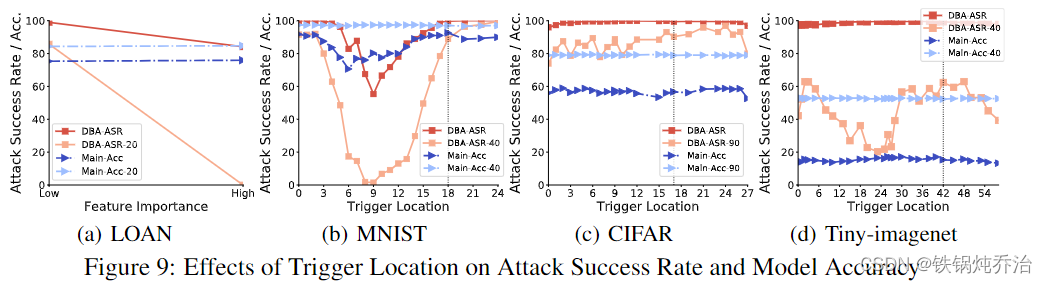
结论:
1)观察发现TL 和 DBA-ASR(在 MNIST 中)或 DBA-ASR-t(在 Tiny-imagenet 和 MNIST 中)之间表现出一条 U 形曲线。这是因为图像中的中间部分通常包含主对象。这些领域的 DBA 更难成功,并且会更快地遗忘,因为这些像素是主要准确性的基础。
2)这一发现在 MNIST 中很明显,40 轮后的主要准确度在中心 (TL = 9) 中仅保持在 1.45%,而在左上角 (TL = 0) 中则有 91.57%。
3) 类似的发现可以在 LOAN 中找到,如图9(a) 所示。使用低重要性特征的 DBA 在攻击轮次和后续轮次方面具有更高的成功率。低重要性触发器在 20 轮后达到 85.72% 的 DBA-ASR,而高重要性触发器为 0%。
3)触发间隙
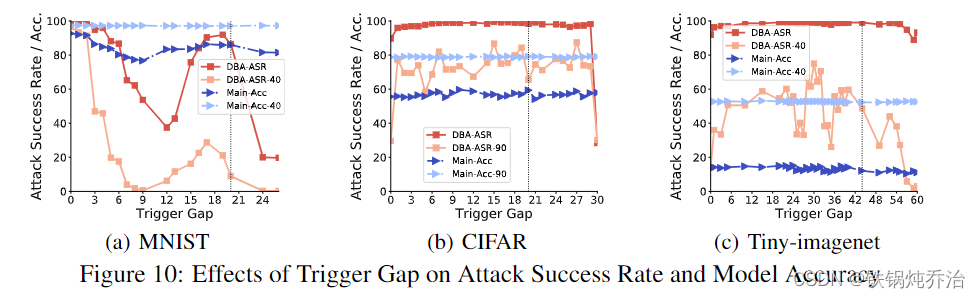
结果:
1)最大触发器间隙的影响:位于图像的四个角设置四个局部触发模以产生最大的触发器间隙,对应于图10中的最大触发间隙,DBA-ASR和DBA-ASR-t在图像数据集中都很低。这种失败可能是由局部卷积操作和局部触发器之间的大距离引起的,因此全局模型无法识别全局触发器。
2)零触发间隙的缺点:在CIFAR和Tiny-imagenet中使用零触发间隙,DBA仍然成功,但我们发现后门将被遗忘得更快。我们建议在实施 DBA 时使用非零触发间隙。
4)触发器大小
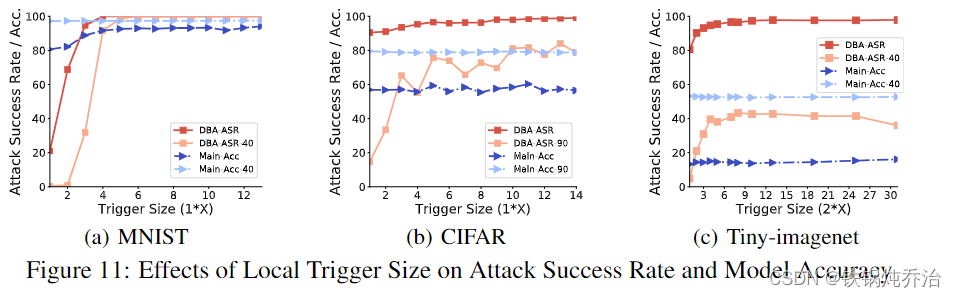
结果:
1)触发器并不是越大越好:
在图像数据集中,较大的触发器大小给出了更高的 DBA-ASR 和 DBA-ASR-t。然而,一旦 触发器变得足够大,它的效果就会趋于稳定,即使继续增加触发器大小攻击效果也不有明显增益。
2)触发器太小,效果很差:
对于 MNIST,当 TS = 1 时,DBA-ASR 较低。这是因为每个局部触发器太小而无法在全局模型中识别。在相同的设置下,使用4个像素的全局模式的集中攻击也不是很成功,其攻击成功率在4轮内很快下降到10%以下。这反映了在攻击 A-S 下,触发器太小的后门攻击是无效的。
5)攻击间隔
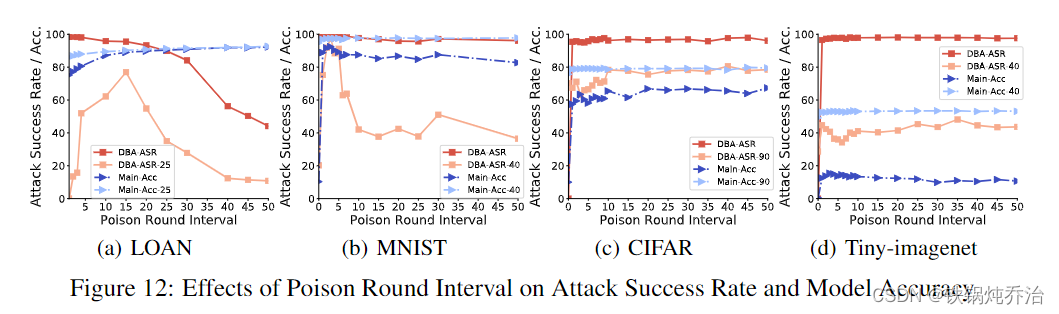
结果:
1)当所有分布式攻击者在所有数据集中在同一轮 (I = 0) 提交缩放更新时,攻击性能很差,因为缩放效果太强,极大地改变了全局模型中的参数,导致它在主要准确性上失败。
2)如果中毒间隔太长,它也是无效的,因为早期embemed触发器可能完全被遗忘。
最佳毒轮间隔:
3)图 12.(a)(b) 中的峰值表明 LOAN 和 MNIST 存在最佳毒轮间隔。DBA攻击者可以等待全局模型收敛,然后嵌入下一个本地触发器以最大化后门性能,这比集中式攻击具有竞争优势。
4)分布式攻击的稳健性:
在 CIFAR 和 Tiny-imagenet 中,将区间从 1 更改为 50 不会导致 DBA-ASR 和 DBA-ASR-t 的显着变化,这表明局部触发效应可以持续很长时间并有助于全局触发器的攻击性能。从这个角度来看,分布式攻击对 RL 非常稳健,应该被视为更严重的威胁。
3.3.3.3 【分布式协同+模型依赖】
Coordinated Backdoor Attacks against Federated Learning with Model-Dependent Triggers
3.3.4【相似度检测 2023 arXiv】Can We Trust the Similarity Measurement in Federated Learning?
(1)问题:
摘要
通过联邦学习(FL)中的相似性来衡量本地模型的可靠性是否安全?本文深入探讨了在保护 FL 时应用相似性度量(例如 L2 范数、欧几里得距离和余弦相似度)的未探索的安全威胁。我们首先揭示了相似性度量的缺陷,即高维局部模型(包括良性模型和中毒模型)可能被评估为具有相同的相似性,但参数值却显着不同。然后,我们利用这一发现设计了一种新颖的非目标模型中毒攻击 Faker,它通过同时最大化中毒局部模型的评估相似度和参数值的差异来发起攻击。
要点:
1.现有的攻击不依赖严格的定量方法来生成中毒模型,因此无法保证攻击的成功。
2.现有的防御大量基于相似性检测,这是脆弱的,因为防御在幅度和方向方面评估局部模型,这通常需要一个强有力的假设,即所采用的评估指标足够稳健,这在现实中可能不成立。如果对手利用这些指标的漏洞发起攻击,这些防御可能会完全失败。
(2)创新
“Faker”的是一种未定向模型投毒攻击,能够以100%的成功率破坏全局模型,甚至只需一次攻击就能成功。结果显示“Faker”在减少准确性方面比最广泛讨论的基准模型破坏攻击(即LA 和MB)提高了1.1-9.0倍,在节省时间成本方面提高了1.2-8.0倍,无论数据分布如何,即使知识有限。研究者还探讨了将Faker扩展到有针对性的后门攻击和Sybil攻击的潜力。初步实验结果显示,Faker在其他对抗性攻击上表现出色,进一步展示了相似性指标的脆弱性。
为了抵御Faker,我们提出了一种策略,即部分参数相似性(SPP)。具体而言,SPP要求服务器计算随机选择的部分参数的相似性,而不是本地模型的所有参数。这样,攻击者无法知道本地模型将如何被评估,增加了检测到恶意本地模型的可能性(NIID下能够保证良性客户端的部分参数相似吗?)。理论分析和与基准防御的实验结果显示,SPP在抵御Faker方面是有效的。
(3)方案
1.相似度评判标准的问题:
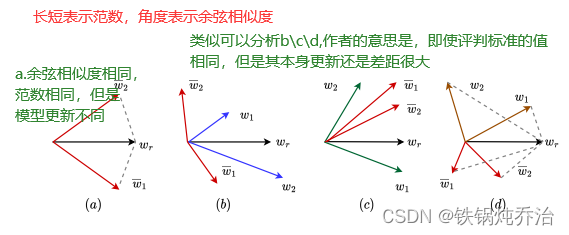
虽然该图说明了 FL 中相似性度量的漏洞,但该现象背后的数学原理仍不清楚。
漏洞:给定良性局部模型 wi、参考模型 Wr 以及相似性上下界 Sl 和 Su,攻击者可以精心制作一个中毒的局部模型 ,使得
而 wi 和
中的参数值显著不同。
有效标量生成法:
其中 ⊗ 意味着
且
是标量向量。这相当于对良性更新的每层参数都进行了放缩。同时,作者给出数学证明,该标量一定存在。
(思考:这种方法可以进行无目标攻击,但应该怎么保证有目标的准确性?放缩标量如何确定?)
2.距离评判方式
如果只应用一种相似度度量,我们只需要直接通过 计算
的相似度;否则,我们可以将计算出的多重相似度相乘。例如,当采用FLTrust时,
的相似度为
;当采用Krum时,
的相似度为
。相乘这些相似性的原因是相乘的结果作为优化目标比单独最大化它们更方便。这样,Faker的第一个目标,即生成“相似”的有毒局部模型,可以通过最大化si来满足。由于
,我们知道
是 αi 中标量的函数。
直观上,如果两个模型不相同,则它们的参数不同;如果我们想让两个模型更加明显,我们可以放大它们的参数差异。我们用参数值之差的绝对值来表示参数的差异,即:
可得:
为了实现攻击者的另一个目标,即提交的中毒模型和良性模型之间存在显着差异,我们需要最大化 δi。由于 wi,j 是一个常数,并且 αi,j 是正数,因此我们允许
作为攻击者的另一个最大化目标,以简化计算。
综上,攻击者实际上解决一个多目标问题:
目标一:最大化相似性度量Si,以保证各参数之间在评判标准上相似。
目标二:最大化个参数之绝对值差的和,以保证参数之间相差很大。
则优化问题定义为:,即:
(思考:这里的优化函数实际上指的考量:放大参数攻击成功率就会更高吗,这会是一个递增函数吗?还有如何权衡差异性和隐蔽性?优化函数上存在较大疑问,没有证明两个目标之间的正相关关系,简单相乘会导致真正的最优值被筛除,应该定义两个目标,使用多目标的启发式算法求解。)
3.降低复杂度的方法
根据我们之前的分析,Faker 需要确定 αi 中 J 标量的值。尽管我们采用在定义明确的域中设置 J−1 的值并仅保留一个变量来降低复杂度的方法,但当 J 较大且最坏情况时间复杂度为 O(J) 时,计算成本仍然很大。为了进一步简化αi的计算,我们可以将标量分为T≪J组,并允许同一组中的标量共享相同的值,这样时间复杂度可以降低到O(T)。对于划分方法,一种直接的方法是将深度学习模型同一层的参数视为同一组。
(这里应该指出,复杂度应该为O(J!)。
4.合作模式
具体来说,攻击者可以与本地模型进行相互通信,以获取中间全局模型 wg 来逼近防御者的参考模型 wr。此外,为了攻击Krum,我们让攻击者i将其获得的中毒本地模型wi发送给其他m−1个攻击者,这些攻击者也将wi提交给服务器;这样,相似度的上限应调整为 。
(4)实验结果
1.评判标准
数据集:MNIST 、Fashion MNIST 、CIFAR-10
模型:MLP、CNN
防御策略:FedAvg(FA)、Krum(KM)、norm-clipping(NC)、FLTrust(FT)、FLAME(FM)、DiverseFL(DF)、ShieldFL(SF)等防御模型中毒攻击;NC、FM、DF来防御后门攻击; FoolsGod 是用来检测 Sybil 攻击的。对于FLTrust、DiverseFL和ShieldFL,包含100个示例的干净数据集是从测试数据中随机选择的。至于范数剪裁,除了其上限之外,我们还提供了一个下限,即上限的五分之四,以防止攻击者提交参数非常小的有毒局部模型。 FedAvg 不能容忍对抗性攻击,因此我们使用其在非攻击(N/A)情况下的结果与其他防御的结果进行比较。
对比攻击策略:LA首先生成一个由1和-1组成的随机向量来确定是否改变局部模型中每个参数的方向,然后通过迭代方法导出共享标量来修改参数的大小。同样,研究者提出了一种称为操纵拜占庭规则(MB)的模型中毒攻击,它也采用迭代方法来搜索所有参数的共享标量。
用户端设置:100个客户端,NIID客户端,每个客户换拥有类别数为c=2,IID为c=10
评判标准:通过发起攻击的错误率(ER)、成功率(SR)和时间消耗(TC)来衡量Faker对模型中毒和Sybil攻击的攻击性能。对于后门攻击,我们采用主任务准确率(MA)、目标任务准确率(TA)和TC作为评价指标。
2.实验结果
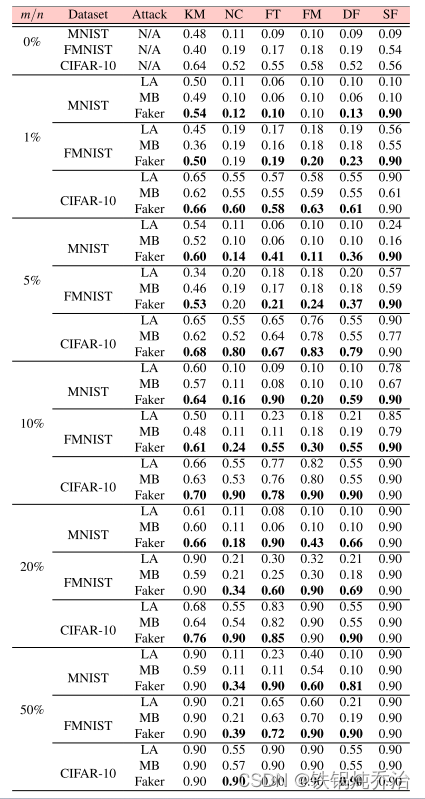
错误率结果:每一轮都攻击
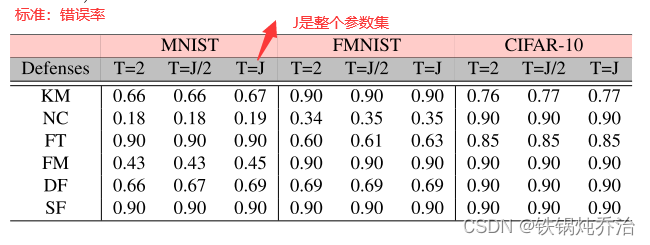
具体来说,对于 MNIST,当 c = 10 时,LA 和 MB 都不会降低 FLTrust、FLAME、DiverseFL 和 ShieldFL 的性能,并且仅在攻击 Krum 和范数裁剪时略有下降,但 Faker 可以破坏所有这些防御;对于FMNIST和CIFAR-10来说,Faker对这些防御的影响更为显着。当c = 2时,LA和MB都会降低除FLAME之外的防守的准确性,而Faker则极大地破坏了所有防守。相比LA和MB,Faker的攻击力更强,对IID和非IID数据的兼容性也更好。
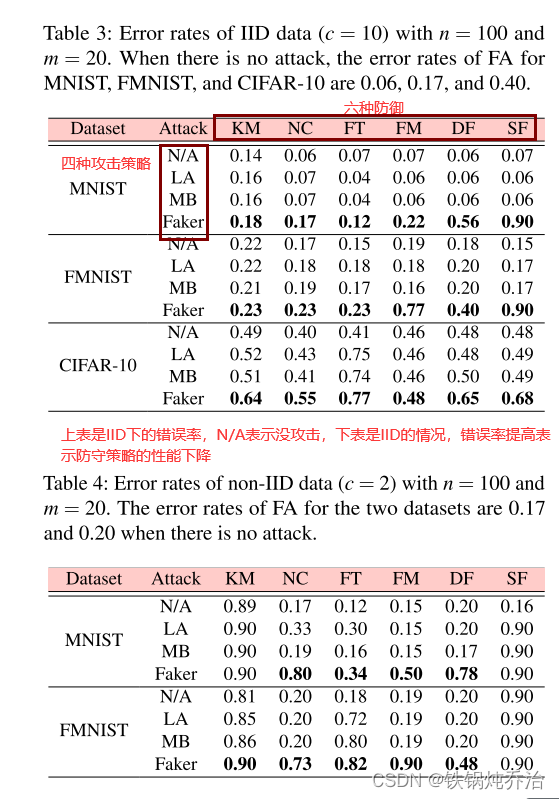
恶意客户端的影响:每轮攻击,使用错误率标准
直观上,恶意客户端越多,模型中毒攻击的影响就越明显。从结果来看,无论 m/n、数据集和防御的变化如何,Faker 都成功实现了模型性能的降低,并且优于 LA 和 MB。即使只有一个恶意客户端,Faker 仍然可以破坏基于相似性的防御,而其他两种模型中毒攻击的性能较差。值得注意的是,LA和MB对范数裁剪几乎没有影响,因为LA和MB只能通过维持或减小局部模型的幅度来满足范数裁剪的要求。通过我们为范数裁剪设置的上限和下限,LA 和 MB 更难生成攻击范数裁剪所需的中毒模型(是否可以对上下界进行研究,从而得到一种防御方案?)。由于Faker在攻击normclipping时只需根据公式生成满足上界要求的中毒模型,因此攻击不受下界影响。从实验结果来看,我们可以说,恶意客户端越多,Faker 攻击就越成功。但Faker 可以有效地在少量恶意客户端的情况下表现良好。
攻击时机:收敛时单次攻击,错误率衡量标准
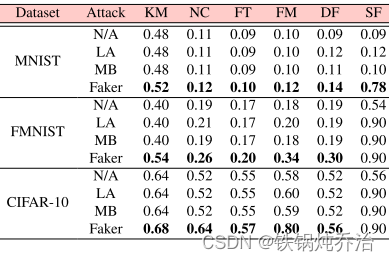
成功率结果:每轮攻击
成功率定义:只要提交的模型被选择(Krum,FLTrust,FLAME)或者分配较高权重(ShieldFL),则视为成功。
Faker在不同的数据集和防御下总能获得100%的成功率。然而,LA和MB并不总是能获得很高的成功率,特别是在攻击Krum和DiverseFL时,因为它们以迭代的方式生成有毒的本地模型,不能保证所有有毒的提交都能满足防御的要求。此外,在Faker中,我们使用严格的数学分析来得出最佳的攻击策略,确保防御可以接受所有中毒的本地模型。
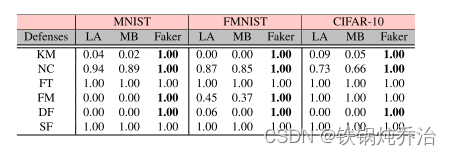
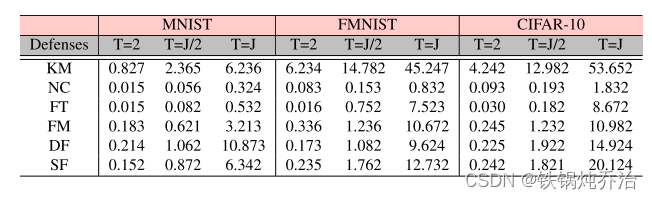
时间损耗
Faker 使用三个数据集对基于相似性的防御发起攻击的时间效率要高得多。由于我们的测试是在带有GPU的设备上进行的,所以所有实验值都在一分钟之内,但是对于计算能力不高的移动设备来说,应用Krum时发起LA和MB攻击会非常耗时且不切实际。即使攻击克鲁姆,Faker 也比其他攻击花费更少的时间。

参数差异
我们在每一轮中从中毒和未中毒的全局模型中随机选择两个参数来衡量 Faker 造成的差异。我们设置n = 100,m = 20,c = 5,实验结果如图所示。从结果可以看出,Faker生成的中毒模型导致的差异大于1。需要注意的是,FL模型的参数通常是绝对值远小于1的数字。因此,我们可以得出结论,中毒模型足以导致全局模型的性能下降。(这里高出1那么多,估计时20个恶意累加)

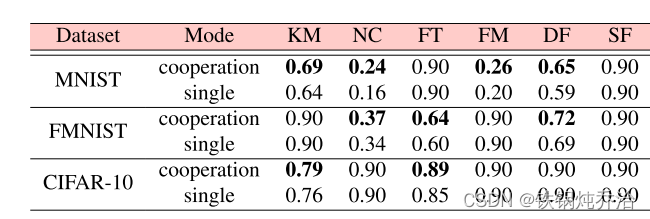
合作模式&单独攻击
合作模式优于非合作模式。然而,非合作模式的攻击就其有效性而言已经足够了。
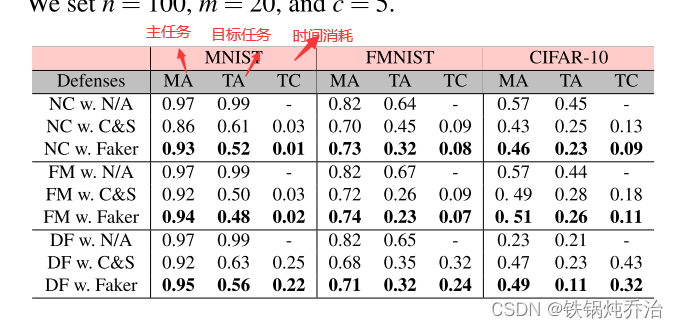
后门任务下情况
基于 Faker 的后门攻击。 Faker必须最大化wi并最小化δi才能发起后门攻击。我们允许攻击者通过其他后门攻击的方式得到一个初始中毒模型,然后让Faker维护输出层等几个关键层的参数,并根据防御者的要求通过修改参数来调整相似度其余各层
基于Faker的后门攻击能够以更少的时间消耗更好地保持主任务精度(MA)并降低目标任务精度(TA)。
分组大小的影响:
时间消耗
我们通过改变 T 的值来探讨 T 对 Faker 表现的影响。我们可以看到,增加T的值并不会极大地提高整体攻击性能,但会显着增加发起攻击所需的时间成本。因此,我们建议攻击者在实际中可以选择较小的T,以达到预期的攻击目标,同时减少时间消耗。
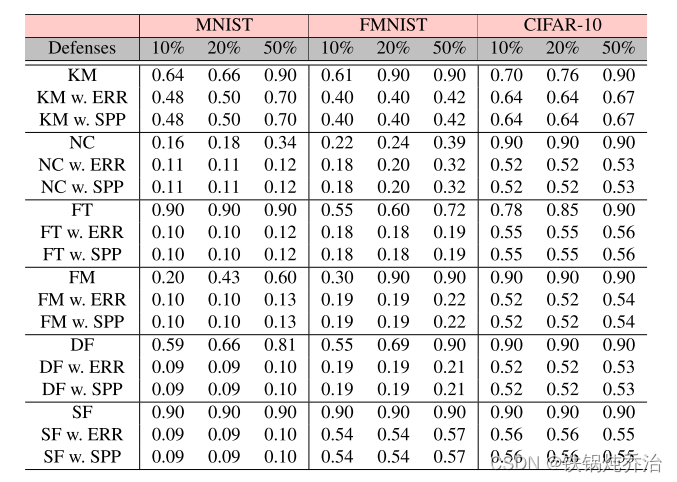
本文提出的防御手法的防御性能:
结果表明,SPP与基准防御ERR具有相似的性能,即使有50%的攻击者也可以防御Faker。请注意,ERR要求防御者评估数据干净的本地模型,拒绝错误率异常的本地模型,可以有效检测恶意模型;虽然SPP在评估时不需要任何其他额外信息,但它仍然可以具有与ERR相同的性能。此外,表15中的结果表明,即使选择的参数数量很大,SPP也不需要密集的计算资源,并且SPP在时间成本上优于ERR。有关 SPP 在更大数据集和深度模型上的更多实验评估。(是否应该对不同量的部分参数进行研究?)
3.3防御论文与思想
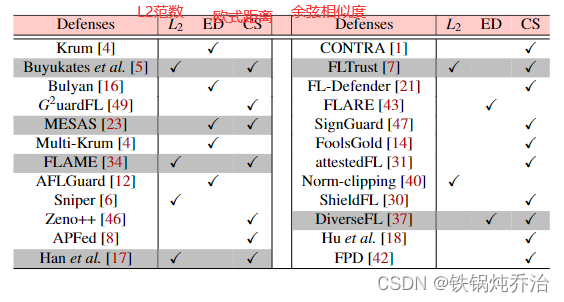
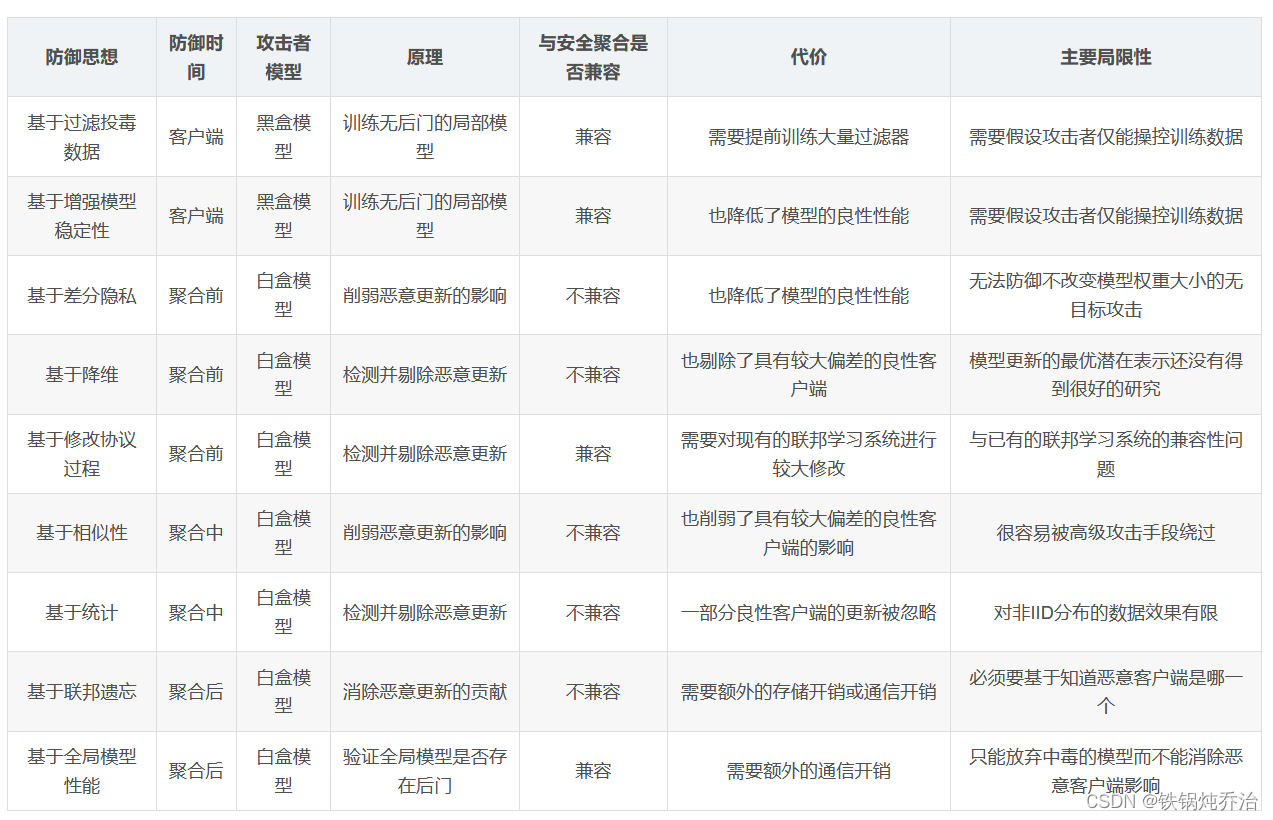
下表是将防御方法用到的10种思想进行了简要对比,包括基于过滤投毒数据的防御、基于增强模型稳定性的防御、基于差分隐私的防御、基于特征提取与特征选择(基于降维)的防御、基于修改协议过程的防御、基于综合运用多种技术的防御、基于相似性的防御、基于统计的防御、基于联邦遗忘的防御和基于全局模型性能的防御。
原文链接:https://blog.csdn.net/w18727139695/article/details/123727138
以下将顺着年份逐一整理和介绍:
3.3.1 基于统计方法
3.3.1.1 【2018 Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent】【krum】【MutiKrum】
(1)问题:
目前的方法(FedAvg)无法通过客户端提出的更新的线性组合来容忍单个拜占庭客户端。一个拜占庭客户端可以迫使参数服务器选择任意向量,甚至可能是幅度过大或方向与其他向量相差过大的向量,需要研究一种具有拜占庭容忍的聚合策略。
(2)创新:
本文首次提出并证明了根据欧拉距离筛选拜占庭终端的可行性
(3)方案:
| 参数 | 参数名 |
| V | 本地更新模型 |
| F | 更新整合函数 |
| n | 客户端数 |
| f | 拜占庭客户端数 |
| d | 参数向量的维度 |
| G | 本地更新的分布集合,有 |
| g | G的期望,有EG=g |
| G中本地更新的方差,有 |
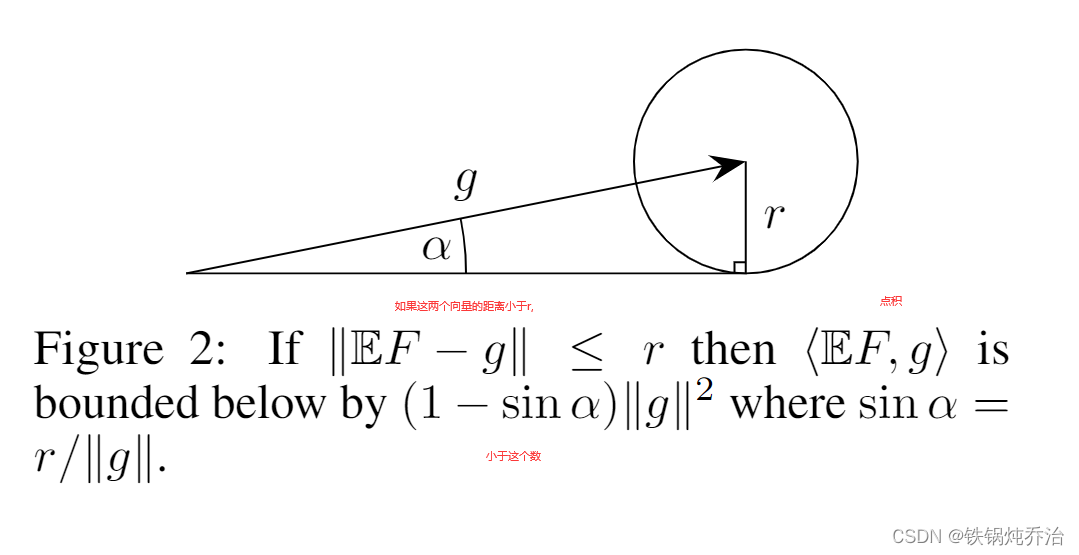
(a)引理1:对参数任何线性组合不足以抵抗拜占庭攻击。(证明请见文章)
(b)核心定理1:向量s位于以g为中心,r为半径的球内,则g,s的点积受到限制,如图:(证明见原文),则我们可以通过控制r来对向量进行筛选。
核心定理2:
如果:
则Krum函数是(α, f)-拜占庭容错的。其中
为:(详细证明见文章)
(c)Krum步骤:
1.选中V1.....Vn
2.对于每个节点i,需要计算与之最近的n-f-2个点的距离,即:
3.挑选距离最小的s1,并使用该分数的节点集作为良性端点。
4.对良性端点进行聚合
(c)MutiKrum步骤:
执行上述1-4后,执行第5步:在s(i)集合中挑取m个s,对相应s对应的点集进行聚合后,对聚合的参数进行平均:
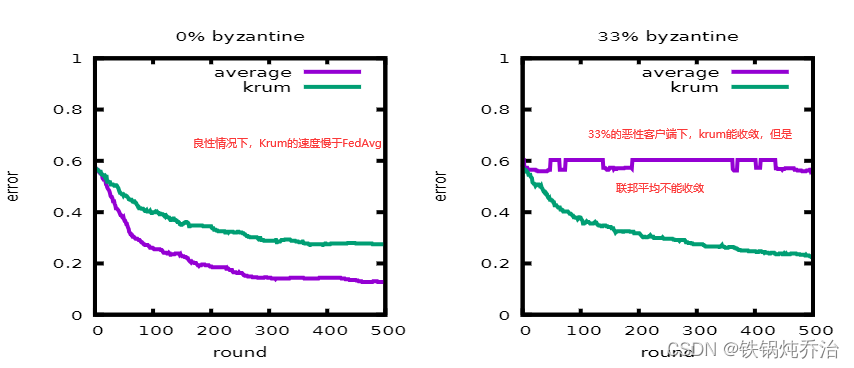
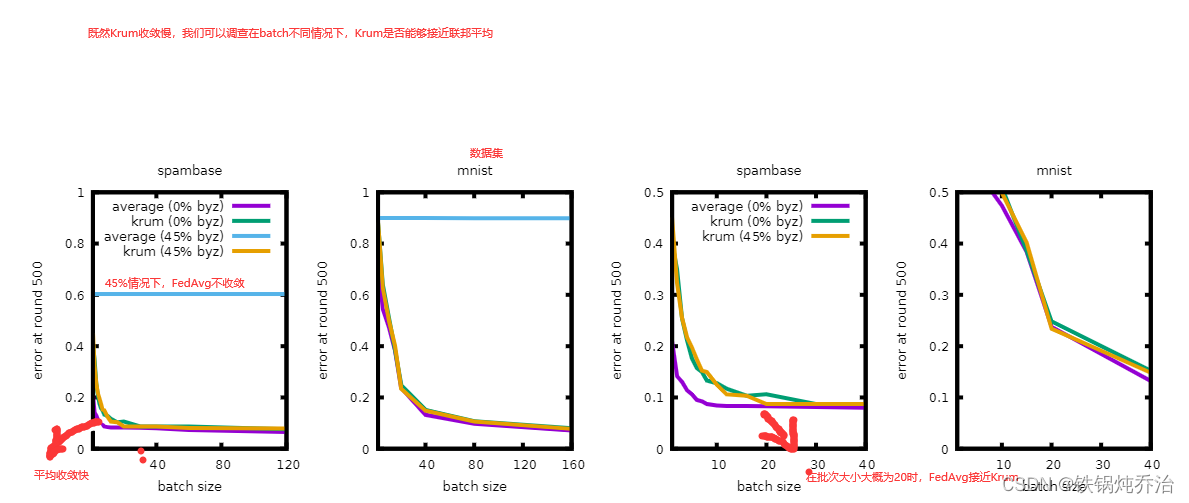
(d)实验结果:
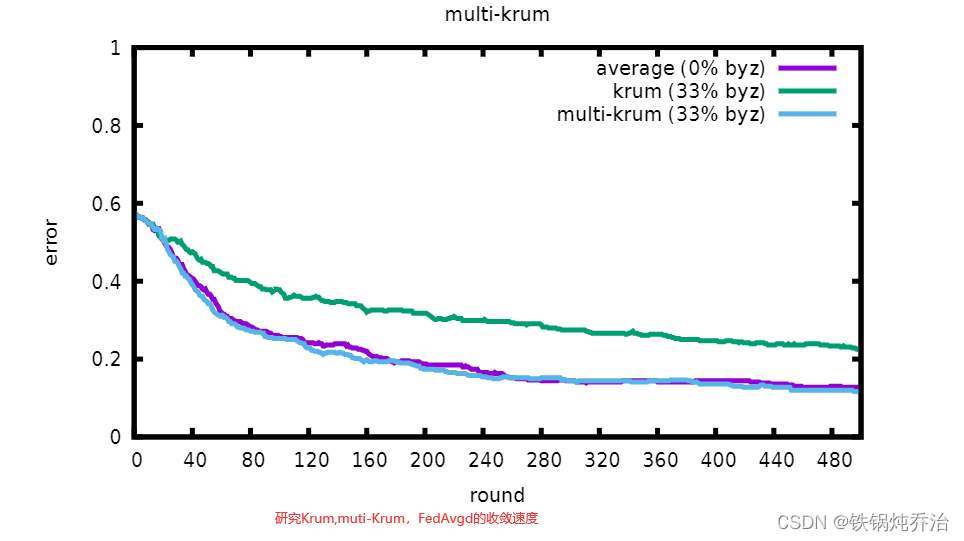
3.3.1.2 【2018 Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates】【Median&Trimmed-mean】
(1)问题:
在拜占庭鲁棒性的同时,可实现的最佳统计性能是什么,以及哪些算法可以实现这种性能?
(2)创新:
本文首次以严格数学的证明提出了拜占庭算法最佳性能的下界为:
其中客户端数为m,数据点数为nm,拜占庭客户端数为m.(证明篇幅大,详细见原文)
同时本文提出两种能够达到该下界的算法Median&Trimmed-mean
(3)方案:
算法流程:

(4)实验结果

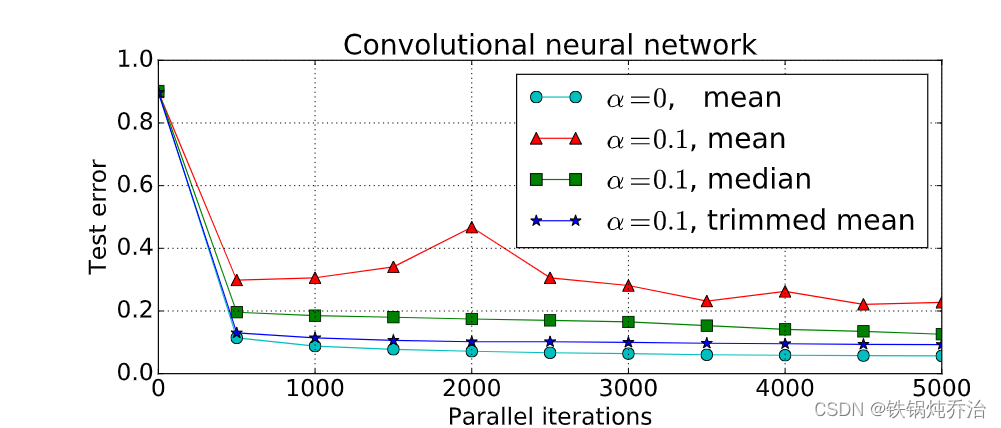
(4)思考
基于统计的方法虽然有着计算简单,对攻击者限制少的优点,但却存在着以下限制:
1.部分方法虽然在统计上对后门攻击具有鲁棒性,但可能导致一个有偏差的全局模型、因为所选择的更新只占局部更新的一小部分,导致聚合模型对具有较大偏差的良性客户端客户端的性能较差。尤其是在数据NIID时这种现象极其明显,因为数据非独情况下,模型更新差异大。
2.在安全聚合协议中,服务器无法得到客户端的局部模型参数或更新的明文,因此在这种情况下,基于统计的防御方法无法使用。(但是随着技术的进步,未来版本的联邦学习协议可能有在不泄露客户端训练数据隐私的情况下计算客户端参数的偏离程度的方法,从而进行异常检测,所以基于统计的防御方法仍有研究价值。)
3.这类方法需要恶意客户端数量至少小于 50 %。
3.3.2 【基于添加噪声的防御方法】【2019 Can You Really Backdoor Federated Learning?】
(1)问题:
这篇文章讨论了在联邦学习环境中的后门攻击,即对模型在特定任务上性能造成影响,同时保持在主要任务上的良好性能。作者通过对EMNIST数据集进行全面研究,发现在没有防御措施的情况下,攻击的性能很大程度上取决于存在的对手比例和目标任务的“复杂性”。研究表明,使用范数剪切和“弱”差分隐私可以缓解攻击,而不会损害整体性能。他们在TensorFlow Federated(TFF)中实现了这些攻击和防御方法,旨在鼓励研究人员贡献新的攻击和防御方法,并在标准联邦数据集上进行评估。
(2)创新
本文的结果可以概括为两个:
1.在没有防御措施的情况下,攻击的效果取决于敌手的数量以及目标任务的复杂度。
2.联邦学习中的后门攻击容易防御,使用“范数剪切”以及“弱”差分隐私都可以降低攻击的效果,同时可以保证联邦学习模型整体的性能不会收到影响。
(3)攻击者设定
1.Adversarial attacks已经演化出多种类型,而且目前的分类不是特别地清晰。本文所关注的攻击方法可以称为Targeted model update poisoning attacks(模型中毒攻击)。具体来说, 其中的targeted是指攻击的目标是targeted sub-task而非primary task(隐私目标);另外,model update poisoning(模型中毒) 表示攻击的策略是通过修改联邦学习中上传的梯度来完成后门的嵌入(与此对应的策略是data poisoning(数据投毒),即仅修改训练数据而不会操纵训练的过程)。
2.将后门攻击扩展到联邦学习场景时有两个挑战:其中一个是敌手无法获得全部的训练数据。敌手作为一个或少数几个client,并不能获得其他client的数据,不清楚其分布,导致poisoning时难度更大。另一个是敌手无法控制整个训练过程:敌手并非server,因此只能控制一个或少数几个client的梯度上传过程,并不能篡改其他的训练流程,包括其余client上传的梯度、模型的结构或者具体的参数。以上两个问题限制了传统的后门攻击在联邦学习场景中的直接扩展。
(4)方案
1.朴素的后门攻击方案:
攻击的策略很简单,在前 k次迭代中,敌手都伪装成诚实的client并用正确标签数据训练本地的模型;直到server的全局模型收敛之后(这个原因已经在上面论文解释过),所有的客户端上传的梯度都已经变的非常小的时候,敌手开始使用自己的恶意数据集
进行训练,在本地获得一个
。根据
本地更新:
提升因子:
模型替换方案:
2.改进的阈值后门攻击
但本文似乎并未考虑安全聚合方案的使用。因此,server可以通过对梯度的裁剪(norm clipping)来防御这种攻击。于是敌手使用一种改进的攻击方法--带阈值的攻击(constrained attacks),在攻击时便考虑了梯度的大小。也就是说,在梯度不会明显增大的情况下,依然能够完成攻击的目的。这种攻击也称为norm bounded backdoor attack.
3.本文调研的两种防御措施:
a.基于阈值(norm threshold of updates):简单来说,防御者(server)选择一个阈值 (比如随机选择)来判断收到的梯度是否来自于恶意敌手,如果梯度的梯度大于阈值,就忽略这个梯度。 本文考虑了一种更强的敌手,即敌手知道防御者使用的阈值,于是将自己构造的恶意梯度限制在这个阈值范围内。
b.(弱)差分隐私 ((Weak) differential privacy): 在联邦学习中,差分隐私(DP)通常被用来保护client的隐私,但是在本文的场景中,DP将噪声加入到被裁减过的梯度上,来限制backdoor 的攻击成功率。(这里应用DP的应该是local DP,但如何保证恶意敌手会按照约定的规则加入噪声呢?如果恶意敌手不加任何噪声,防御还有效果吗?)
(5)实验结果
恶意客户端数对攻击效果的影响:
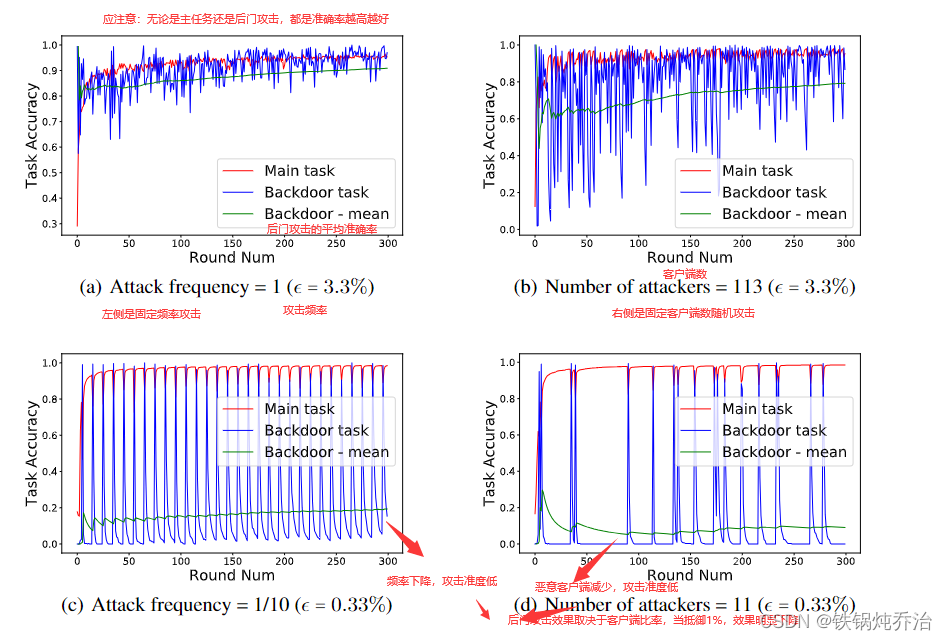
后门攻击性能受后门任务的影响;
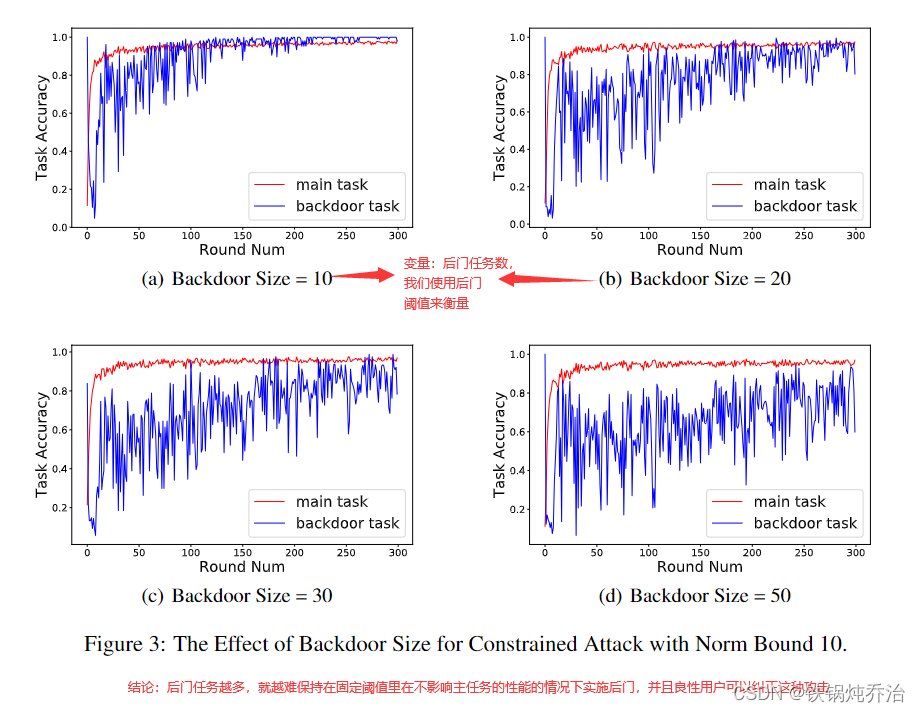
两种防御方法的效果:

(6)思考
优点: 这种方法可以防御朴素的基于标签翻转的后门攻击和基于放大模型参数的模型替换攻击。
缺点:
1.当攻击者已知服务器的剪裁阈值时,可以直接构建最大限度满足范数约束的模型更新,使得剪裁的防御措施没有效果,尤其是当攻击者可以进行多轮攻击时,而为了清除恶意更新的影响,通常也会用较小的剪裁因子,这也会影响良性的模型更新。而如果使用较大的剪裁因子,攻击者可以按比例增大恶意模型的参数,直至达到剪裁因子,从而达到最大程度影响全局模型。并且,基于添加噪声的防御虽然无需对攻击者行为和数据分布进行具体假设,但是会恶化聚合模型的良性性能。且由于通常假设服务器不能访问训练数据,尤其是有毒的数据集,因此服务器通常只能根据经验使用的足够数量的噪声。
2.这种防御方法无法防御不改变模型权重大小的非目标攻击,例如符号翻转攻击且可能无法防御基于植入触发器的后门攻击。
3.这种方法没有规定和说明剪裁阈值和噪声量如何确定,且这种方法可以在一定程度上减轻恶意攻击的影响,但不能完全消除它们。
3.3.3 【基于特征提取的防御方法】【2020 Data Poisoning Attacks Against Federated Learning Systems】
该文章在攻击论文中已经详细讲过,故略过攻击部分。
(1)方案

(2)结果
plot结果显示,与诚实参与者的更新形成自己的集群相比,恶意参与者的更新属于一个明显不同的集群,即使攻击者较少,也能够明显识别出恶意模型,且防御并没有受到“梯度漂移”问题(模型梯度发生变化,其方向不再是最优方向)的影响。
(3)思考
优点:在低维的潜在特征空间,来自恶意客户端的异常模型更新可以很容易被区分。因此通过提取高维模型的特征,在低维特征空间中进行判别,可以防御后门攻击。
缺点:1.但是这类方法也剔除了具有较大偏差的良性客户端的更新,导致聚合后的全局模型对此类客户端的性能较差,尤其针对NIID数据集。
2.这类方法要求恶意客户端数量至少小于 50 %。
3.模型更新的最优潜在表示还没有得到很好的研究。
4.与安全聚合不兼容,且无法抵御植入后门攻击。
3.3.4 【基于相似性的防御方法】【Byzantine-Robust Federated Learning by Inversing Local Model Updates】
(1)问题:
到目前为止,研究人员已经提出了许多拜占庭鲁棒 FL 方案,大致可以分为两类:
| 类别 | 方案 | 局限 |
| 第一类 | 目的:识别并排除有毒的局部模型更新 原理:中毒终端几何上远离良性模型更新 | 最近提出的一些高级中毒攻击可以制作几何上接近良性模型的中毒模型,绕过防御。 |
| 第二类 | 目的:评估本地模型更新的测试准确性或损失 原理:服务器需要集中一个公共的干净验证数据集,用于测试本地上传的参数 | 具有双重优化目标的中毒攻击(例如后门攻击)也可能在验证数据集上具有良好的性能,并且可以逃脱排除且 违背了联邦学习数据不聚合的初衷。 |
| 共有问题:上述两种方案面对NIID数据集性能都会快速下降 | ||
作者的思考是否存在一种方法使得从数据集上入手去检测异常模型,以保证能够NIID的性能?
(2)创新
作者使用了模型反演技术,得到了尊重隐私的虚拟数据集,并结合第一种方案,对异常模型进行筛选。
(3)攻击者设定
无目标攻击:
| 类别 | 方法 |
| 标签翻转攻击 | 对于每个样本,我们将其原始标签 c 翻转为 c + 1 mod M ,其中 M 是标签总数。 |
| 高斯攻击 | 拜占庭客户端提交通过单位方差高斯分布生成的有毒本地模型更新 |
| 反向梯度攻击 | 拜占庭客户制作一个有毒的数据集,在该数据集上训练的本地模型在良性数据集上具有最大化的损失。 |
| Krum 攻击 | 拜占庭客户精心制作与良性模型相反的有毒本地模型更新,并使他们能够绕过 Krum 的防御。 |
有目标攻击:
| 类别 | 方法 |
| Badnet[G] | 拜占庭客户端将具有特定后门触发器的标签翻转数据样本注入训练数据集中。 在此类中毒数据集上训练的模型可能会被具有相同触发器的样本引起有针对性的错误分类。 在FL中,为了避免忘记后门,中毒的本地模型更新会在每一轮中提交。 |
| 朴素后门 | 拜占庭客户端生成后门本地模型更新并对其进行扩展,以确保它们在良性全局模型即将收敛时能够替换它。 这种攻击是在FL最后一轮才发动的。 |
聚合算法:
| 类别 | 方法 |
| FedAvg | 对所有客户端执行数据大小加权本地模型聚合 |
| MultiKrum | 选择与大多数具有最小欧氏距离的 N − F 局部模型更新,并对它们进行平均以更新全局模型。 |
| 基于损失函数的拒绝(LFR) | 在集中式干净验证数据集上选择损失减少最大的 N−F 个局部模型更新,并对它们进行平均以更新全局模型。 |
| FLTrust | 根据每个本地模型更新与在干净的小型训练数据集(称为根数据集)上训练的服务器模型更新的偏差,计算每个本地模型更新的信任分数,并计算加权的本地模型更新的平均值 。 |
(4)方案:
模型反演过程:
1.随机生成一个包含输入和相应标签的虚拟数据集。
2.最小化虚拟梯度和共享实际梯度之间的差异,迭代更新虚拟数据,使其接近客户的原始训练数据。优化问题定义为:
其中(x′,y′)(x′为输入,y′为对应标签)为待优化的虚拟数据,θ为当前全局模型的参数,l为损失函数, 是第 t 轮中客户端 n 处的单个小批量训练数据的计算梯度。问题(1)的最优解(x′*;y′*)可以非常接近真实的输入(x,y)。即最小化虚拟数据产生的梯度和真实数据产生的梯度之差。
为了缓解客户端的隐私问题,方案允许每个客户端n通过大小为B的小型批量SGD执行本地模型更新的E个时期。在这种情况下,客户端n执行本地SGD的次步骤。然后,方案要求每个客户端n在第t轮中提交她的本地模型更新
,以及她采用的本地历元数量E和小批量大小B。在服务器端,与(Zhu和Han 2020)不同,方案通过将伪梯度与等效梯度
匹配来执行模型反演。则上式变为:
评分过程:
对于每个客户,我们采用 Wasserstein 距离度量[W]来计算她的虚拟数据集与其余数据集的分布差异。数据集(x′i, y′i) 和 (x′j; y′j) 被定义为:
算法流程:

(5)实验结果:
无攻击情况:
可以看到,没有攻击情况下,与FedAvg准确率基本一致。
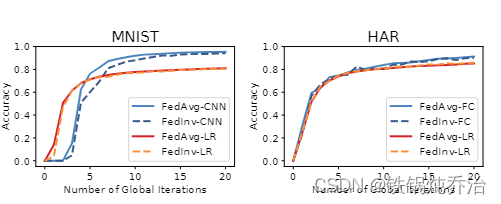
是否尊重用户隐私:
可以看到,反演后的数据基本上推测不出来用户敏感信息。

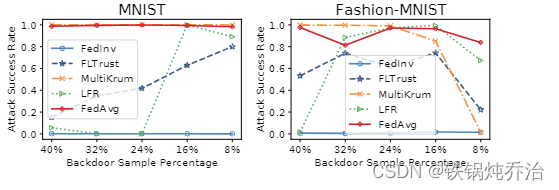
针对无目标拜占庭攻击抵抗率:
可以看出,随着恶意客户端比例增大,只有模型(FedInv)表现出良好鲁棒性。纵轴是攻击成功率。

针对目标后门攻击抵抗率:
可以看出,随着恶意客户端比例增大,只有模型(FedInv)表现出良好鲁棒性。纵轴是攻击成功率。
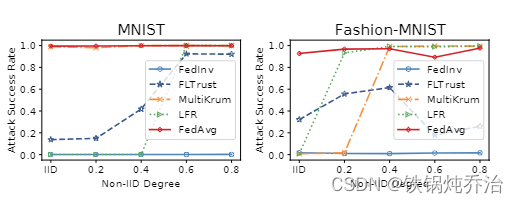
NIID数据集鲁棒性:
(6)思考:
这类方法和基于统计的防御方法采用的一般原理相近,即利用欧式距离、余弦相似度等计算模型的相似性。根据相似性调整局部模型的权重或学习速率。或利用基于聚类的方法找到离群值,并从中去除离群值。
但存在以下不足:1.在安全聚合协议中,服务器无法得到客户端的局部模型参数或更新的明文,因此在这种情况下,基于相似性的防御方法无法使用,即该类方法与安全聚合不兼容。(但是随着技术的进步,未来版本的联邦学习协议可能有在不泄露客户端训练数据隐私的情况下计算客户端参数的偏离程度和距离的方法,从而进行异常检测,所以基于相似性的防御方法仍有研究价值。)
2.这些防御对基础的攻击者有效,但可以很容易地被高级攻击者所绕过。更复杂的恶意客户端可能通过采取隐蔽措施或相互串通来隐藏他们的意图。例如以下方法可能会使这种防御方法失效:
| 类别 | 方法 |
| 投影梯度法 | 攻击者可以通过将恶意的更新向量投影到真实更新向量的邻域,从而绕过这些基于相似性的防御 |
| 阈值裁剪法 | 攻击者可以让有毒模型更新与良性模型更新之间的距离小于所采用的防御方法的判别阈值 ϵ,从而避开基于检测距离相似性的防御方法 |
| 模型缩放法 | 攻击者可以通过缩小后门参数的放大比例从而避免被检测 |
| 多后门 | 攻击者可以让多个恶意客户端同时注入多个不同的后门,从而避免所有后门被检测出来。例如对于将客户端的更新固定分成 n类的聚类防御方法,攻击者可以精心构造 m ≥ n 数量的后门进行攻击,从而实现部分后门的成功注入。同时对于将客户端的更新固定分成 n 类的聚类防御方法,即便在没有后门攻击发生时仍然会剔除一部分良性更新,导致产生误报。 |
3.这类方法需要恶意客户端数量至少小于 50 %
4.有些防御方法需要关于阈值的先验知识,而这在实际应用中很难得到。
3.3.5 【基于修改协议过程的防御方法】【2021 META FEDERATED LEARNING】
(1)问题:
安全聚合是一把“双刃剑”。一方面,它可以系统地减轻参与者的隐私风险,使联邦学习对客户更具吸引力,并最终导致更高的客户参与度。另一方面,它会通过掩盖参与者的贡献来促进训练期间的对抗性攻击,那么,当安全聚合机制存在时,是否可能防御后门攻击?
重述挑战:
| 在联邦学习中,检查模型更新是受限的,无论是否使用安全聚合。最近的研究表明,模型更新可以部分重构客户的训练数据,因此任何需要检查提交的更新的防御方法都对参与者的隐私构成威胁,并违反了联邦学习的隐私承诺。此外,在使用SecAgg增强的系统中,检查模型更新根本不是一个有效的选项。联邦学习的隐私承诺禁止服务器审查客户的提交,这使得对手可以提交任意值而不被标记为异常。我们将这种特权称为无后果的提交。 |
| 即使没有上述限制,防御后门攻击也不是一项简单的任务。客户提交的模型更新显示出很高的变化,这使得中央服务器极其难以确定更新是否朝着对抗性目标发展。从模型更新中观察到的间歇性使得防御后门攻击变得非常困难。 |
(2)创新
本文作者提出了元联邦学习(Meta federated learning),这是一个新颖的联邦学习框架,旨在在保护参与者隐私的同时(安全聚合),有效防御后门攻击(后门检测)。其展示了将防御执行点从个体更新级别移至聚合级别在减轻后门攻击方面的有效性,同时不损害隐私,适用于NIID数据集。
(3)攻击者设定
1.本文的后门攻击类型为前面已经讲过的模型替换(包括朴素的和模型缩放):
2.聚合对比方案
| 类别 | 方案 |
| Krum | Krum算法是一种鲁棒的聚合规则,可以在任何训练轮次中容忍f个拜占庭攻击者中的n个参与者。Krum算法在满足n ≥ 2f + 3的条件下具有收敛的理论保证。在每个训练轮次中,对于每个模型更新δi,Krum算法采取以下步骤:(a)计算与δi最接近的n − f − 2个更新之间的欧氏距离,(b)计算更新δi与其最接近的n − f − 2个更新之间的平方距离的总和。然后,Krum选择具有最低总和的模型更新来更新联合全局模型的参数。 |
| Median | 对于每个j模型参数,接收到的模型更新的j个坐标进行排序,并使用它们的中位数来更新全局模型的相应参数。这种聚合规则通过使用中位数来平均模型更新,从而实现了对全局模型的更新。 |
| Trimmed Mean | 对于每个j模型参数,接收到的模型更新的j个坐标进行排序,并使用一定比例修剪最大值和最小值部分,最后将剩余部分的平均值作为全局更新参数。 |
| RFA | RFA是一个强大的隐私保护聚合器,它需要一个安全的平均值计算器。RFA通过使用Weiszfeld算法的变体来计算本地模型参数的几何中位数的近似值来聚合本地模型。 |
| DP | DP强大的隐私保证,但它也可以对投毒攻击提供防御。将DP扩展到联邦学习中确保了每个参与者的贡献受到限制,从而使联合全局模型不会过度拟合于任何个体更新。在联邦学习中,DP的应用方式是:(a)服务器通过一个范数M对客户端的模型更新进行剪裁,(b)剪裁后的更新进行聚合,然后(c)在聚合结果中添加高斯噪声。最近的研究表明,DP对于抵御虚假标签的后门攻击是成功的。 |
| Norm Bounding | 范数边界似乎对抗虚假标签的后门攻击具有鲁棒性。在这种聚合规则中,为了规范每个参与者的贡献,为客户端提交的模型更新设置了一个范数约束M。规范边界的聚合过程如下:(a)将范数大于设定阈值M的模型更新投影到大小为M的球体中,然后(b)对所有模型更新进行平均以更新联合全局模型。 |
(4)方案
1.流程图如图所示:
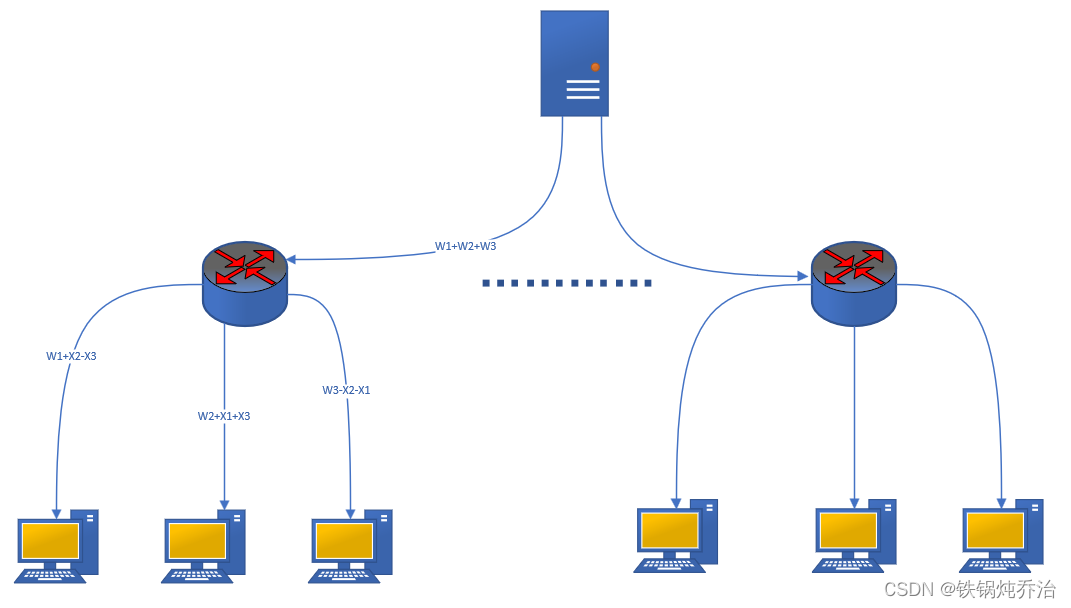
为了解决上述挑战,本文作者提出了一种名为Meta-FL的新型联邦学习框架,旨在保护参与者的隐私并帮助服务器防御后门攻击。流程总结了框架中模型训练的不同步骤。在Meta-FL的每一轮训练中,中央服务器随机选择π个训练队伍(理解为红色路由),每个队伍包含c个独特的客户端,然后通过广播将全局模型Gt发送给每个队伍的客户端,客户端独立地在本地训练数据上训练模型,生成本地模型更新δi,使用安全聚合转给队列的中心路由聚合,然后所有队列的中心路由将聚合参数发给服务器,最后服务器使用聚合规则Γ将“队伍更新”聚合起来,更新联合模型得到下一个共享的全局模型Gt+1。
2.算法图示

步骤:

3.合理性分析
| 合理性一 | 服务器可以检查和监控训练集的聚合结果。这个特性迫使对手在聚合级别上保持隐蔽,因为与其他良性聚合结果在统计上有所不同的对手聚合结果很可能被服务器检测到并丢弃。因此,Meta-FL取消了对手提交的特权。 |
| 合理性二 | 在Meta-FL中,训练队列的聚合结果相对于单个客户端的更新更加稳定,这有助于服务器检测异常情况,因为在多个客户端聚合为一个队列时,可一定程度消除NIID的影响。通过类比统计学中的简单随机抽样,我们证明了训练队列的聚合结果在每个坐标上相对于个体更新的变化较小。 |
| 合理性三 | 由于对抗性更新与其他更新聚合在一起,恶意用户面临着与良性用户竞争来控制集合聚合值的情况。这种特性使得对手更难以精心安排对抗性聚合值以逃避已部署的防御措施。这种竞争性的聚合过程在Meta-FL中有助于提高对抗后门攻击的防御效果。 |
(5)实验
1.模型准确率
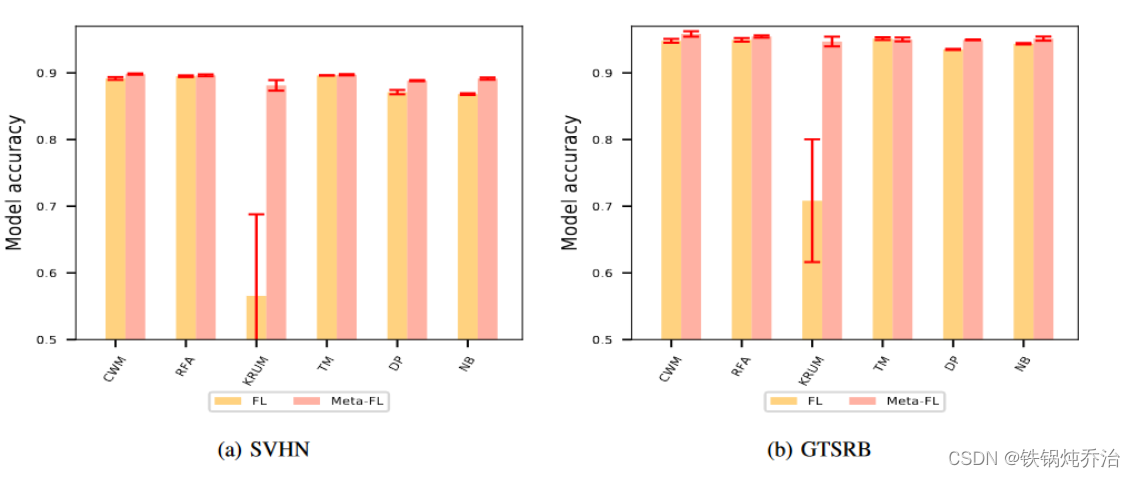
2.抵抗后门攻击能力(在不同攻击者的比例下)
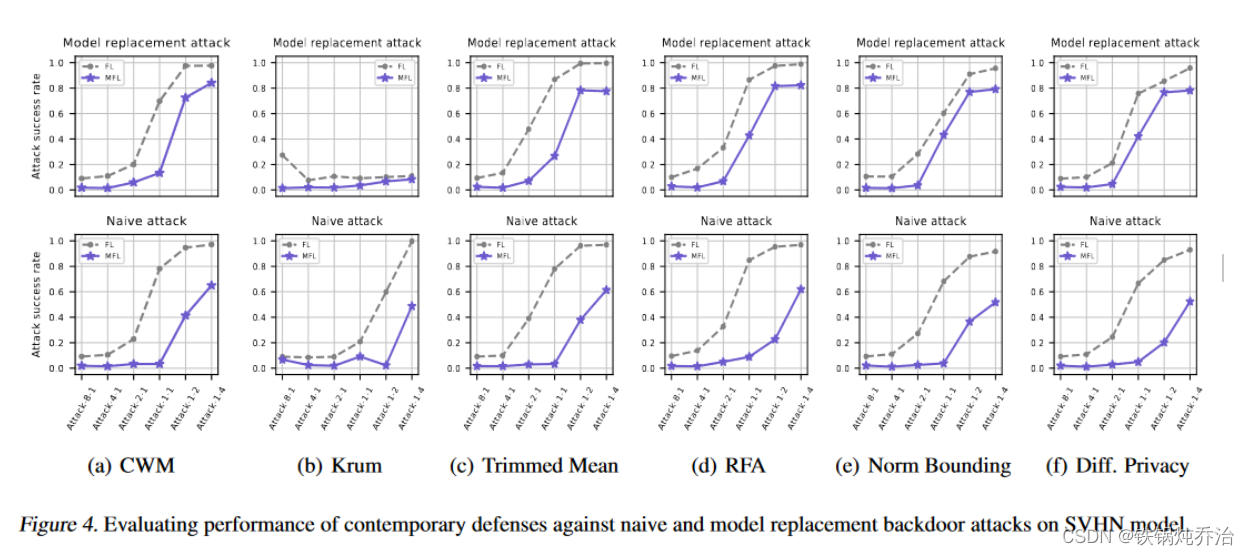
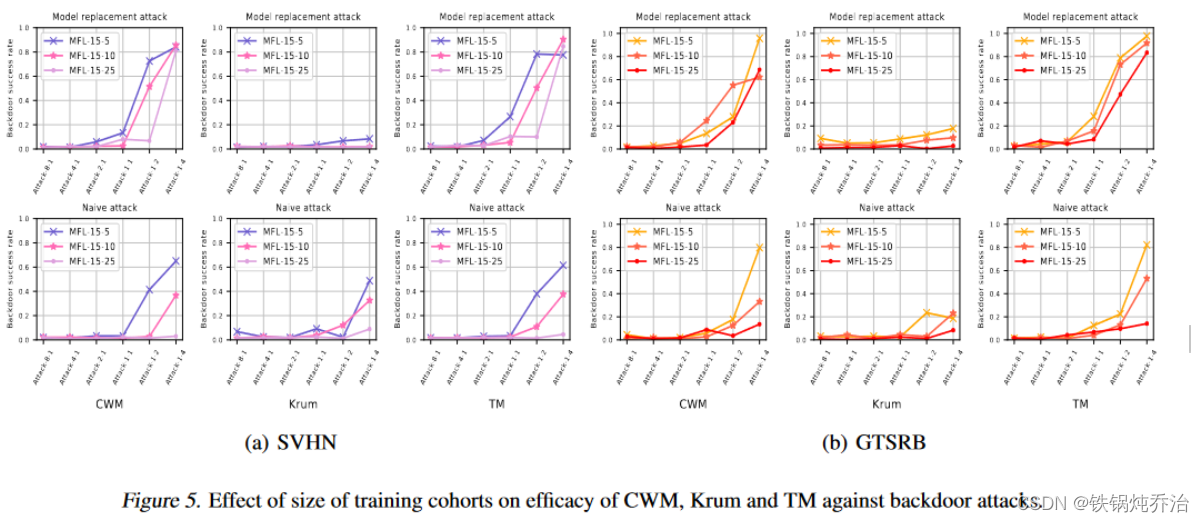
3.对队列中客户端个数的灵敏度进行分析
(6) 思考
优点:
| 与安全聚合兼容,因为参与者提交的都是加密之后的更新。虽然每个队列进行聚合后得到的“队列更新”仍可能泄露队列成员集体的数据信息,但推理出来的信息无法与任何单个客户端相关联。 |
| 客户端的数据集是非IID分布,所以提交的模型更新可能会显示出很大的差异,这使得服务器很难确定哪些更新是恶意的。而对队列中的更新进行聚合之后,良性“队列更新”的数据分布会更加集中,有助于服务器检测异常。 |
| 防御基于标签翻转的后门、基于植入触发器的后门攻击、基于模型替换的后门攻击。 |
局限性:
1.对广义上的联邦学习过程具有较大的修改
2.这类方法要求恶意客户端数量较少,至少在每一轮中,不能有超过 50 % 的队列(不是所有客户端的50%)中有恶意客户端出现。
3.3.6 【联邦学习的鲁棒性】【Attack of the Tails: Yes, You Really Can Backdoor Federated Learning】【2020 NIPS】
(1)问题:
由于其去中心化的性质,联邦学习(FL)在训练期间容易受到后门形式的对抗性攻击。后门的目标是破坏训练好的模型在特定子任务上的性能(例如,将绿色汽车分类为青蛙)。文献中介绍了一系列的FL后门攻击,也介绍了防御这些攻击的方法,目前是否可以定制 FL 系统以抵御后门是一个悬而未决的问题。在这项工作中,我们提供了相反的证据。我们首先确定,在一般情况下,对后门的鲁棒性意味着对对抗性攻击的鲁棒性,这本身就是一个主要的开放问题。此外,在多项式时间检测FL模型中存在的后门是不太可能的。我们将我们的理论结果与新的后门攻击系列结合起来,我们将其称为边缘案例后门。边缘案例后门迫使模型对看似简单的输入进行错误分类,但这些输入不太可能是训练或测试数据的一部分,也就是说,它们存在输入分布的末端。我们解释了这些边缘案例后门如何导致FL的失败,并可能对公平性产生严重的影响,并展示了在对手方的精心调整下,人们可以在一系列的机器学习任务中插入这些后门(例如,图像分类、OCR、文本预测、情感分析)。
重述挑战:
在这篇文献中,作者展示了攻击者可能会以更微妙的性能指标为目标,如分类的公平性,以及训练期间不同用户数据的平等代表性。并且认为如果模型容易受到对抗样本的影响,那么后门是无法避免的。
(2)创新
1.证明了后门攻击在联邦学习中难以防御。如果一个模型容易受到输入扰动形式的推理时间攻击(即对抗性样本),那么它将容易受到训练时间后门攻击。此外,模型扰动后门的范数由(基于实例的)常数乘以对抗样本的扰动范数的上界(如果存在的话)决定。
2.后门检测是np难问题(基于3-SAT; 边缘样本攻击难以被基于梯度的检测技术发现。

(3)攻击者设定
1.边缘样本后门
a.根据我们的理论线索,并受 Bagdasaryan 等人的工作启发,我们引入了一种新型的对抗当前防御措施的后门攻击,这可能导致模型不良的分类输出,并影响学习分类器的公平性属性。我们将这些攻击称为“边缘案例后门”。边缘案例后门是一种攻击,它针对输入数据点,尽管通常会被 FL 模型正确分类,但这些数据点在训练或测试数据中要么很少出现,要么不太可能出现,需要注意的是边缘输入指的就是一些特殊的不常见的样本,“数据边缘”、“尾部”指的是数据分布上出现次数少的数据,如果较小用户群体输入对应的样本,则模型可能返回一个后门的输出,对于自动驾驶这类高度安全的模型,这些边缘输入将对小群体导致致命问题。
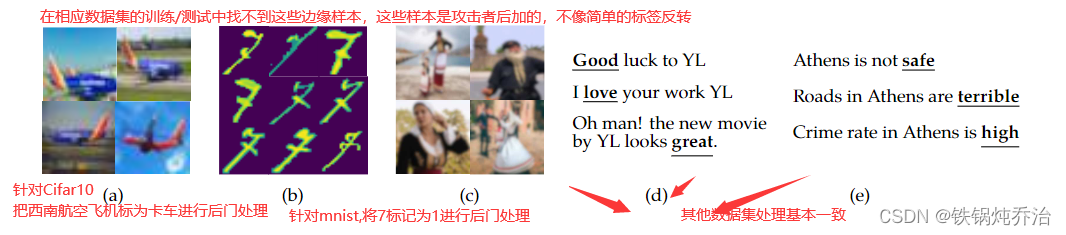
b.如何构建恶意客户端的边缘数据集?
D′(训练集)=D(良性数据集)+Dedge(恶意边缘数据集)。在第 4 节中,证明只要 |D′ ∩ Dedge|>|D′ ∩ D| 或超过 50% 的 D′ 来自 Dedge,所有提出的算法(3的攻击策略)都表现良好。那么一个自然的问题就出现了:我们如何构建满足这样条件的数据集?我们提出了以下算法:假设对手有一组候选的边缘情况样本和一些良性样本。我们向 DNN 提供良性样本并收集倒数第二层的输出向量。通过拟合聚类数量等于类数量的高斯混合模型,我们得到了一个生成模型,攻击者可以使用该模型测量任何给定样本的概率密度,并在需要时进行过滤。我们在图 2 中可视化了这种方法的结果。在这里,我们首先从预训练的 MNIST 分类器中学习生成模型。使用它,我们估计 MNIST 测试数据集和 ARDIS 数据集的对数概率密度 ln PX(x)。 可以看到,MNIST 的对数概率密度比 ARDIS 训练集高得多,这意味着 ARDIS 可以安全地视为边缘情况示例集 Dedge,而 MNIST 可以视为良好的数据集D. 因此,我们可以通过从 MNIST 中删除图像来减少|D′ ∩ D| 。

注:应该分清两个概念,边缘样本在恶意数据集里的数量和边缘样本在全局数据集(所有客户端的训练集之和)里的数量。边缘样本在全局数据集里的数量要很小,才能保证其是边缘样本。但是边缘样本要在恶意数据集中超过50%,才能保证所有攻击策略效果好。所以怎么去找到足够的边缘样本呢?简单的说,作者搭建了一个神经网络,用聚类找到了各样本之间的关系,然后统计各类出现的概率,发现ARDIS数据集相较于Mnist数据集的类出现的概率低得多(我个人觉得是因为ARDIS里的不同特征样本分布的较均匀,而Mnist同一类特征的样本分布太重叠导致的)。所以,先把Mnist和ARDIS合并,在删除部分来自Mnist的数据,则可以得到一个边缘数据集。
2.后门嵌入方式
数据中毒:在攻击者的数据集中插入干净和后门数据点的混合;后门数据点以特定类为目标,并使用首选目标标签。
模型中毒:采用类似但算法不同的方法,训练具有投影梯度下降(PGD)的模型,在每一轮FL中,攻击者的模型不会显著偏离全局模型
3.攻击策略
a.在黑盒攻击设置下,攻击者使用本地制作的数据集 D' 进行标准本地训练,旨在最大化全局模型在 D ∪ Dedge 上的准确性。我们通过将来自 D 和 Dedge 的一些数据点组合在一起构建 D'。通过精心选择这个比例,攻击者可以绕过防御算法,制造持续时间更长的攻击。
b.在PGD攻击中,对手会在D' = D ∪ Dedge上应用投影梯度下降。如果简单地运行SGD时间过长,与诚实客户相比,得到的模型会明显偏离其原始状态,从而使简单的范数剪切防御措施生效。为了避免这种情况,对手可以定期将模型参数投影到以上一次迭代的全局模型为中心的球体周围。这种策略需要对手能够运行任意算法来替代标准的本地训练程序。
注:这种情况,将新的参数尽量控制在与原来全局参数相差d的距离内(也就是一个球体)
c.缩放因子+PGD。(缩放因子的详细定义请看模型替换3.2.2。缩放因子的目的是为了进行模型替换,模型替换在一定程度上能够抵消良性客户端的更新。
如果恶意客户端不知道比例,可在逐次上传中增加。X为训练的恶意模型,Lm为上传的模型。通过放缩因子的存在,Lm在一定程度上能够抵消良性客户端的更新,同时能够保证在梯度裁剪中不被筛除。)先进行训练得到X,然后放缩得到Lm,然后在进行PGD。

(4)方案
1.定理1:对抗样本存在->后门存在


证明:

则W'称作一次成功的后门。则移项有:

权重范数是指所有权重参数的绝对值的平方和的平方根(一般用欧几里得距离)即:
权重范数小有以下作用:权重较小意味着网络参数的变化对输出的影响相对较小,这有助于避免梯度爆炸和梯度消失等问题,有助于控制模型的复杂度并减少过拟合的风险。

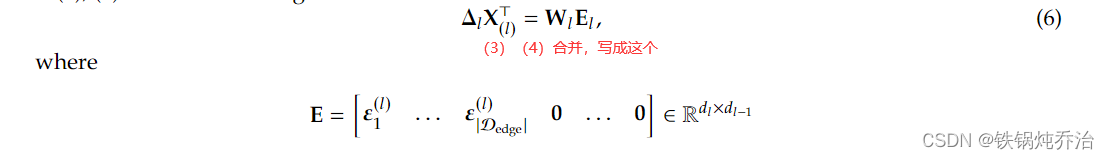
这里有个关键点,E的非零元素个数是|Dedge|,也就是扰动的样本数。

算子范数不等式受弗罗贝尼乌斯范数定理得出,不做深究。
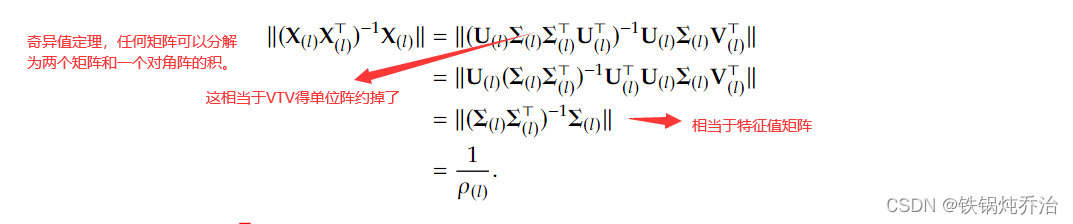

得到最终结果:
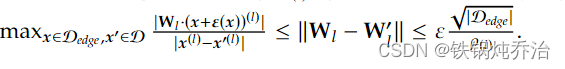
解释:由于我们的出发点是(1)(2),即保证主任务不变的情况下,对边缘数据添加扰动能够误导该数据的分类(已经承认可以误导)。然后推出最后的结果,当Wl与Wl'在最终结果的界限内,也可以达到此种效果。故存在对抗性扰动时,存在这样的Wl'。
意义:
上限意味着防御后门比防御对抗性示例至少同样困难。这意味着证明后门的鲁棒性至少与证明对抗性样本的鲁棒性同样困难。下限表明,如果良好数据点与后门数据点之间的最小距离接近零,则此后门构造将无效,从而间接证明了使用边缘案例的合理性。因此,目前来看,在解决给定模型中后门的内在存在之前,必须先解决对抗性示例,这仍然是一个重大的未解问题
2.定理2:后门检测是NP问题
注意:当我们需要证明某个问题是NP难时,一般把它归约成3-SAT问题或者已有的NP问题(背包问题),这个知识点可以备用,以备后面自己论文里证明问题复杂度。
基本定理:3-SAT问题是NP完全问题。
什么是3-SAT问题
SAT是SATISFIABILITY(可满足性)的缩写。SAT问题就是问某一个布尔表达式是不是“可满足”的问题。这里的术语“可满足”的意思是存在一组“真值赋值”(truth assignment)使得布尔表达式为真。举例来说,“a & !b”(a与非b)就是一个"可满足"的布尔表达式,因为存在一组真值赋值(a=1,b=0)使其为真,而"(a | b) & (a | !b) & (!a | b) & (!a | !b)“就是一个"不可满足"的布尔表达式,因为找不到一个真值赋值使它为真。而3SAT问题就是问某个具有特殊形式的布尔表达式是否可满足的问题,这种特殊形式就是"3合取范式"或"3-CNF”。合取范式就是一种所有子句都由合取(即“与”)联接所构成的公式,如"a & (!b | c) & (a | !c | d)"。这里的“子句”是指一个或多个"文字"的析取,而“文字”就是变量或变量的非。如上式中的“a”,“(!b | c)”和“(a | c | d)”就是“子句”,组成子句的a, !b, c, !c, d就是“文字” ,a, b, c, d就是“变量”。“3合取范式”就是每个子句恰好由3个文字所组成的合取范式。举个例子:小红,小王,小江等n人想找个地方去做运动,他们觉得这个地方可能会有m种情况。为了尽量满足所有人的癖好,每个人都根据可能出现的情况提了一个包含3个需求的列表:小红想找个“有窗户”或者“有厕所”或者“没臭味”的地方,小王想找个“没窗户”或“有臭味”或“没厕所”的地方,小江想找个“有厕所”或“没臭味”或“没窗户”的地方。问,是否存在一个地方可以满足所有人的(至少一个)要求?\其中,每个人提的需求列表就是一个“子句”,比如小红提的 " 有窗户’或’有大床’或’没臭味’" 就是一个“子句”。需求列表中的每一项具体的需求都是一个“文字”,比如“有窗户”就是一个文字,“没臭味”也是一个文字。需求的选项(可能出现的情况)就是“变量”,比如“窗户”就是一个变量,“厕所”是一个变量,“臭味”也是一个变量。\n如果最后找到了一个“有窗户,没厕所,没臭味”的地方,那么“有窗户,没厕所,没臭味”就是变量的真值赋值。所有人需求就是合取范式,如果“每个人的需求都有3项且至少要满足1项”就是“3合取范式”。3SAT问题就是问"是否存在"一个满足所有人需求的地方。
简单的说3SAT问题就是一个判断问题,判断是否存在一个值,使得以下形式的表达式为真:
三变量,三子句的一种表达式:
四变量,三子句的一种表达式:

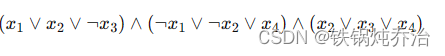
证明:证明策略是构建一个 ReLU 网络来近似布尔表达式。
1.3-SAT的输入是m(子句数量)的多项式的

2.证明构建神经网络也可以在m(子句数量)的多项式时间内完成

3.证明f(x)!=g(x)可以写成3-SAT基本形式的判断问题
a.f(x)=1的形式(保持左边是真值)
b.f(x)可以表示为合取范式
此处f(x)为带有后门的模型,g(x)是不带有后门的模型,可见,判断是否存在x使得f(x)!=g(x)与判断f(x)!=0,与判断f(x)=1存在,与判断h(s)=1存在(3-SAT)难度相同。
同时,作者基于这个推断证明了任何基于梯度的方法来查找边缘后门区域都会失败,除非在边缘后门区域内进行初始化。


(5)实验
1.防御手段
(1)范数裁剪
(2)Krum
` (3)muti-Krum(参考3.3.1.)
(4)RFA(通过使用平滑的 Weiszfeld 算法计算加权几何中值来聚合局部模型.)
(5)弱差分隐私
2.任务构建
| 任务D‘=D+Dedge | D | Dedge | 数据集 |
| task1 | 随机并将类别k的pk抽样样本,以i比例分配给本地用户,模拟了异构数据分区。这将导致D被分成K个不平衡的子集,大小可能不同。(NIID) | 收集西南航空公司飞机的图像并将其标记为“卡车” | 使用 VGG-9 在 CIFAR-10 上进行图像分类。 |
| task2 | 我们从 Ardis (从 15000 条瑞典教堂记录中提取的数据集,这些记录由十九世纪和二十世纪不同的牧师以不同的笔迹风格编写的数据集)中获取“7”的图像,并将它们标记为“1” ; | 使用 LeNet 在 EMNIST 上进行数字分类。 | |
| task3 | 我们收集穿着某些民族服装的人的图像,并将其标记为完全不相关的标签。 | 使用 VGG-11在 ImageNet 上进行图像分类 。 | |
| task4 | 选取 Sentiment140 的 25% 随机子集,并随机均匀地对它们进行划分。(IID) | 我们抓取包含希腊电影导演 Yorgos Lanthimos 名字的推文以及正面情绪评论,并将其标记为“负面”; | 使用 LSTM在 Sentiment140上进行情感分类。 |
| task5 | 每个客户端对应每个真实reddit用户的数据。 | 我们构建包含雅典城市的各种提示并选择一个目标词以使句子是否定的。 | 使用 LSTM 对 Reddit 数据集 进行下一个单词预测。 |
3.边缘样本占客户端比例的影响
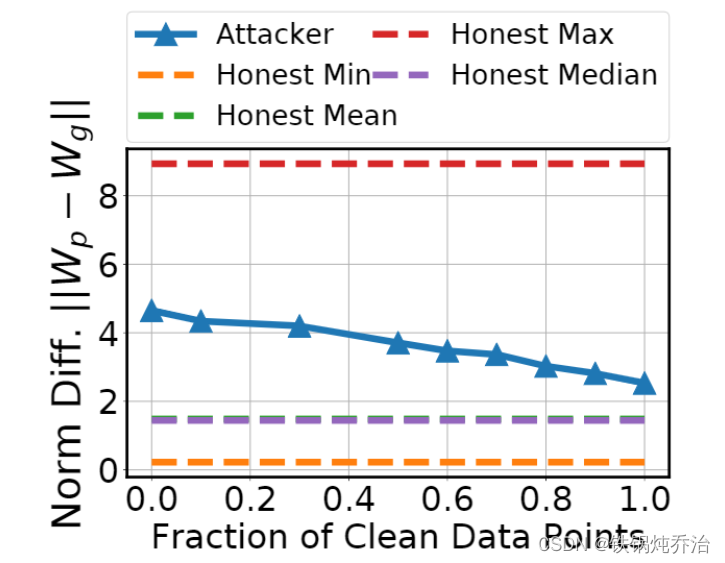
可见,边缘样本攻击的参数范数位于最大城市参数范数和最小诚实范数之间,并随着边缘样本的增加范数逐渐减少。理论上:边缘样本越多,样本的的差异越小,范数差异自然越小。
可见,边缘样本数太多或者太少都会对攻击成功有所影响。样本点少导致攻击性弱这是自然的,但是样本点多也导致攻击弱,甚至纯边缘下接近0的情况可能是由于上传的参数太偏离主任务导致的(猜想)。
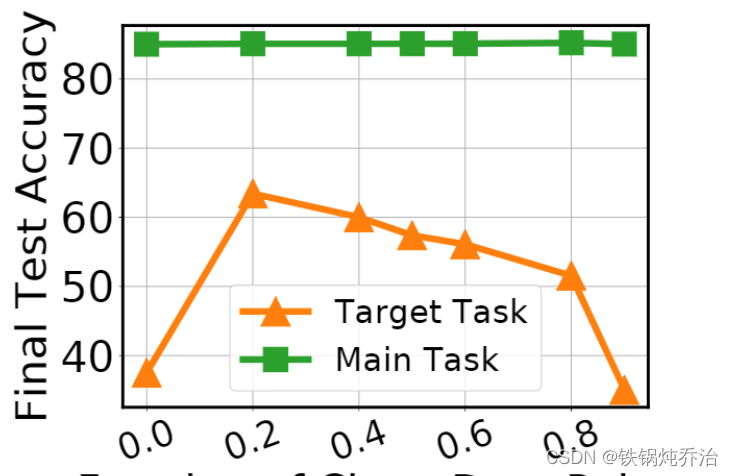
3.边缘样本分配给诚实和恶意客户端比例的影响
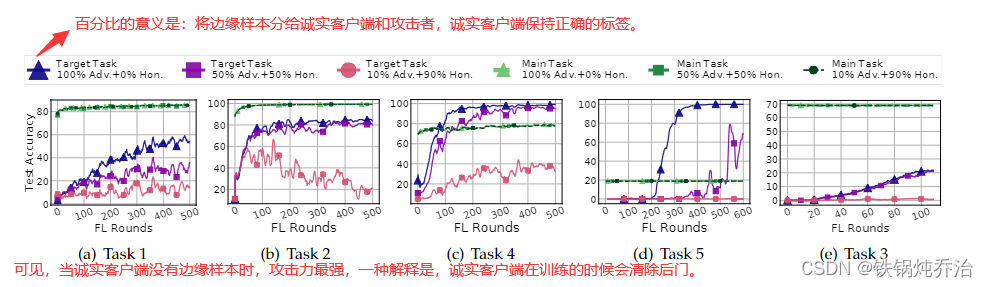
4.不同防御下的效果
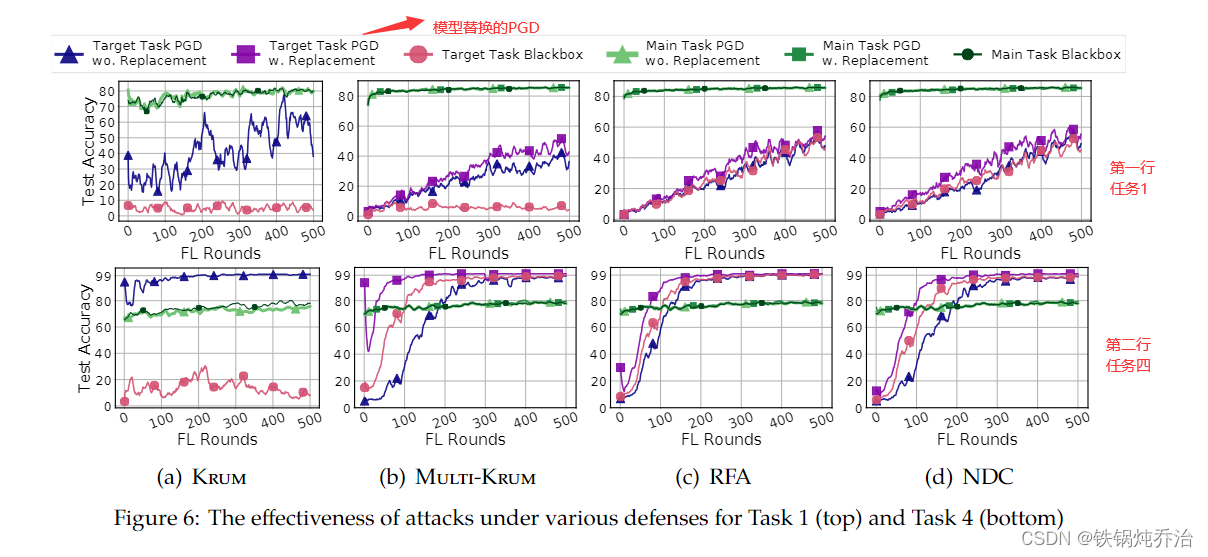
在任务 1、和 4 中研究了黑盒和白盒攻击针对上述防御技术的有效性。对于 Krum,我们没有通过模型替换进行 PGD,因为一旦 Krum 选择了中毒模型,它就会获得模型免费更换(没明白)。考虑固定频率攻击场景,攻击频率为每10轮1次。结果如图 所示,从中我们观察到,经过精心调整的范数约束的白盒攻击(有/无替换)可以通过所有考虑的防御。更有趣的是,Krum 甚至加强了攻击,因为它可能会忽略诚实的更新但接受后门。由于黑盒攻击没有任何范数差异约束,因此对中毒数据集进行训练通常会导致较大的范数差异。因此,黑盒攻击很难通过Krum和Multi-Krum,但可以有效对抗NDC和RFA防御。这可能是因为攻击者仍然可以通过一系列攻击缓慢注入后门的一部分。
5.防御边缘情况引起的公平性担忧
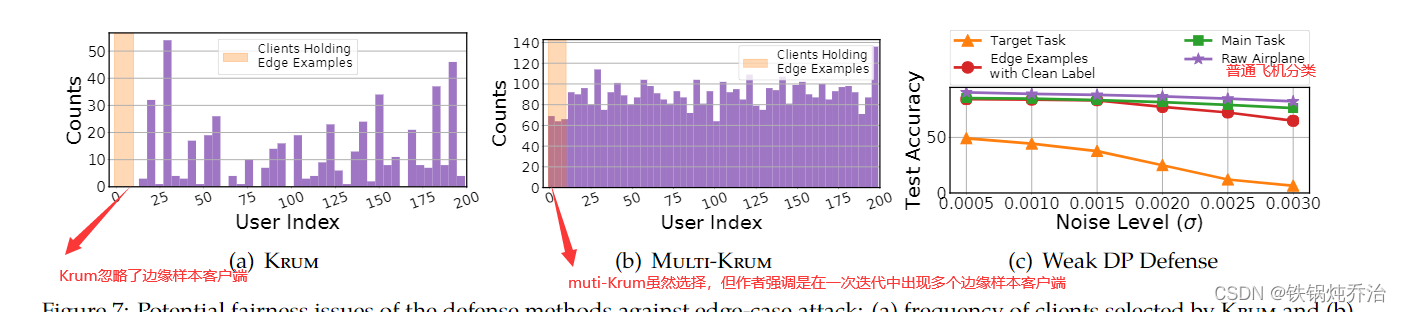
作者认为防御技术可能对良性客户端有害。 虽然 Krum 和 Multi-Krum 很好地防御了黑盒攻击,但我们认为 Krum 和 Multi-Krum 倾向于拒绝来自对手和诚实客户的先前未见过的信息。 为了验证这个假设,我们在固定频率攻击设置下对任务1进行了以下研究。 将西南航空公司的示例划分为攻击者和前 10 个客户端(客户端的选择并不重要,因为在每个 FL 轮中都会随机选择一组客户端;并且攻击者的索引为 -1)。 我们在所有客户的培训中跟踪 Krum 和 Multi-Krum 接受的模型更新频率(如图 (a)、(b) 所示)。 Krum 从未从具有西南航空示例的客户端(即诚实的客户端 1 - 10 和攻击者)中选择模型更新。 有趣的是,Multi-Krum 有时会选择来自西南航空示例的客户的模型更新。 然而,经过仔细检查,我们发现这种情况只有在同一轮中出现多个具有西南航空示例的诚实客户时才会发生。 因此,与其他客户相比,选择西南航空示例的客户的频率要低得多。 我们在与 Krum、Multi-Krum 研究相同的任务和设置下,对不同噪声水平下的弱 DP 防御进行了类似的研究(结果如图 7(c)所示)。 我们观察到在聚合模型上添加噪声可以防御后门攻击。 然而,这也会损害 CIFAR-10 的整体测试精度和特定类别精度(例如“飞机”)。此外,噪声水平较大时,尽管整体测试集图像和原始 CIFAR-10 飞机的精度都会下降, 西南航空的准确性比原来的任务下降更多,这引发了公平性担忧。
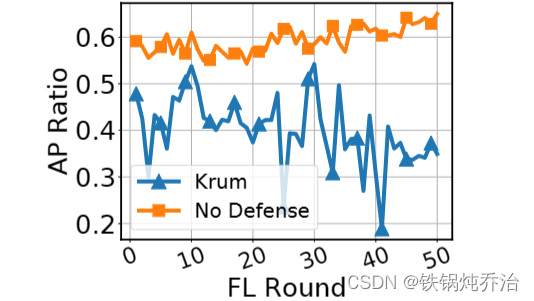
5.Krum公平性的研究
使用“AP比率”来形式化公平性,这是我们基于准确度奇偶性[95]定义的一个指标。我们说一个分类器f满足“准确性平等”,需要对于所有客户端数据D,有pi =pj,其中pi是f在客户i的数据上的准确率。这个概念旨在衡量分类器在不同客户数据上的准确性是否相近。为了衡量准确性平等的程度,我们使用AP比率进行测量: 即pmin /pmax。这里的AP比率是根据准确性平等定义的一个度量标准,其中pi代表f在客户i数据上的准确性。当AP比率接近1时,可以认为f是公平的;而当AP比率接近0时,可能认为f是不公平的,因为不同客户数据上的准确性相差很大。
将CIFAR-10 数据集按 i.i.d 进行分区。此外,引入一个诚实的客户端,即客户端 0,除了分配的 CIFAR-10 示例之外,还有 588 张 WOW Airlines 图像的额外图像被正确标记为“飞机”。

WOW Airlines 的飞机,可见这个飞机图例基本不会出现在客户端中。
在黑盒攻击的情况下,攻击者连续进行了50轮联邦学习。实验结果显示,当应用Krum作为防御技术时,我们能够实现鲁棒性,因为攻击者未被选中,从而保持了后门准确性较低。然而,由于Krum拒绝了0号客户端的更新,因为与其他客户有太大的不同,而WOW Airlines的示例不属于CIFAR-10,全局模型在将这些示例分类为飞机时表现不佳,导致AP比率较低。没有防御措施时,客户0被允许参与训练,因此导致更好的AP比率(即更公平的模型)。然而,攻击者也被允许参与训练,这使得后门注入并导致鲁棒性失败。
6.对不同网络容量的攻击效果
过度参数化的神经网络已被证明可以完美地拟合数据。因此,可以预期,将后门攻击注入到容量更高的模型中会更容易。在[13]中进行了讨论,但没有任何证据表明多余的模型容量可用于插入后门。
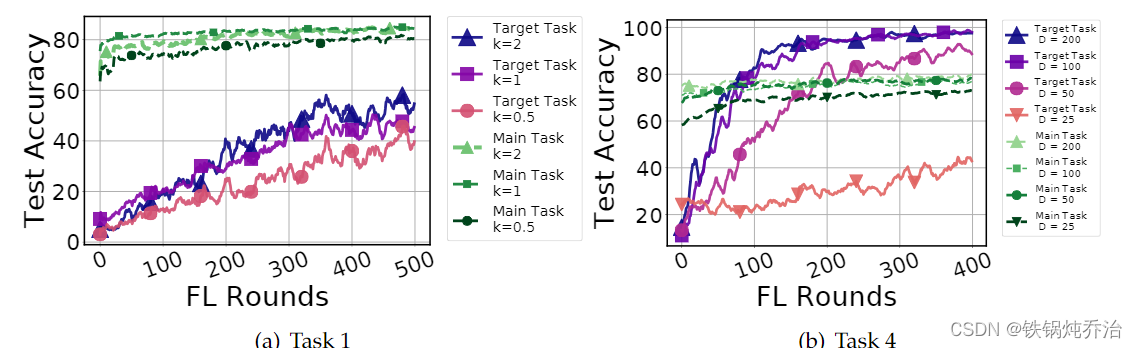
通过图 中任务 1 和任务 4 的不同容量模型来测试这一观点。对于任务 1,我们通过将卷积层的宽度增加 k 倍来增加 VGG9 的容量。我们用 k =0.5 的瘦版本和 k= 2 的宽版本进行实验。宽网络的容量显然更大,我们的结果表明它更容易插入后门,而在瘦网络中插入后门就比较困难了。对于任务 4,嵌入和隐藏隐藏神经元贡献了大部分模型参数,因此我们考虑 嵌入/隐藏神经元的数量D =∈ {25, 50, 100, 200} 的模型变体。对于每个模型,我们插入与上面相同的后门并观察测试准确性。我们观察到,D ≥ 100 的模型中的过剩容量使得攻击能够轻松插入,但当我们减少模型容量时,注入后门就会变得更加困难。我们还需要注意的是,模型容量的减少会导致主要任务的性能下降,因此选择低容量的模型可能会避免后门,但最终我们会在主要任务的准确性上付出代价。
(6) 思考
作者实证研究的目标是强调边缘情况攻击针对最先进 FL 防御的有效性。模拟 FL 环境中对真实数据进行实验。结果表明黑盒和 PGD 边缘情况攻击都是有效的并且持续时间较长。 PGD 边缘情况攻击在所有经过测试的 SOTA 防御下尤其获得了高度持久性。同时,证明了能够部分防御边缘情况后门的严格防御机制,如Krum,导致了高度不公平的环境(在IID)下,可以思考的是Krum在非IID下的状态,其中非恶意和多样化客户的数据被排除在外。
重述贡献:
1.作者通过严格的数学证明,存在对抗性实例即存在模型的后门。
2.作者通过3-SAT规约证明后门的检测是NP难的
3.作者通过证明+实验,表明梯度检测无法防御边缘样本攻击。
思考:
1.可以看到,Krum与弱差分隐私都存在不同程度的不公平现象,作者在IID下测试都比较明显,那么在NIID下这些防御技术是否还能继续使用?我的思考是,是否可以从异构联邦那找找思路,缓和这一现象或者研究一种方法能够使得防御方案兼具鲁棒性和公平性?
2.通过缩小嵌入神经元的个数,能够大幅度降低后门攻击的准确性,但是主任务的准确率却下降不大,那是否可以根据这个方案设计一种防御性的聚合方案?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









