




- 本文假定读者已经阅读过上篇文章(模板基础),了解了模板基础及其他 C++ 基础知识
- 本文所示代码默认引入了
iostream库,且不使用using namespace std;- 本文所有代码均在 Rider 中运行,且默认使用 msvc 编译器、C++11 标准、Debug x86 配置
- 本文将使用 Compiler Explorer 在线编译器作代码演示并给出链接
在上一篇文章中,我们已经掌握了 C++ 模板的基础知识,包括其基本语法和特化机制。这些工具赋予了我们编写泛型代码的能力,使其能够跨越不同数据类型工作。然而,这还没能发挥出 C++ 模板的全部功力。
模板元编程(Template Metaprogramming,TMP)是 C++ 模板系统的核心,它允许我们在编译时进行计算和决策。这使得我们能够编写更加灵活和高效的代码,同时也能够实现一些在运行时难以实现的功能。本文要讲的,正是模板元编程。
本文将带领读者踏上一段深入 C++ 模板世界的旅程,探索 C++ 语言在过去几十年中引入的各项高级技术。这不仅是一份技术功能的清单,更是一部关于 C++ 泛型编程思想的演进史。我们将从最基础的编译时“探针”——类型萃取(Type Traits)开始,它让我们得以在编译期间“审视”类型。
文章目录
1. 类型萃取(Type Traits):在编译时审视类型
在构建复杂的模板库或泛型算法时,首要任务是能够在编译时获取有关模板参数类型的信息。例如,一个泛型数学函数可能需要知道其参数是否为整数、浮点数,或是一个指针。C++11 通过 <type_traits> 头文件提供了强大的工具集来完成这项任务,这就是类型萃取。
它是一种编译时技术,允许编译器在编译阶段检查、比较和修改类型,所以它本质上是一种编译时反射(Compile-Time Reflection)机制。
它允许我们询问关于类型 T 的各种问题:“T 是否为整数?”、“T 是否为指针?”、“T 是否带有 const 限定符?”等。
在权威网站 cppreference 中是这样描述的:
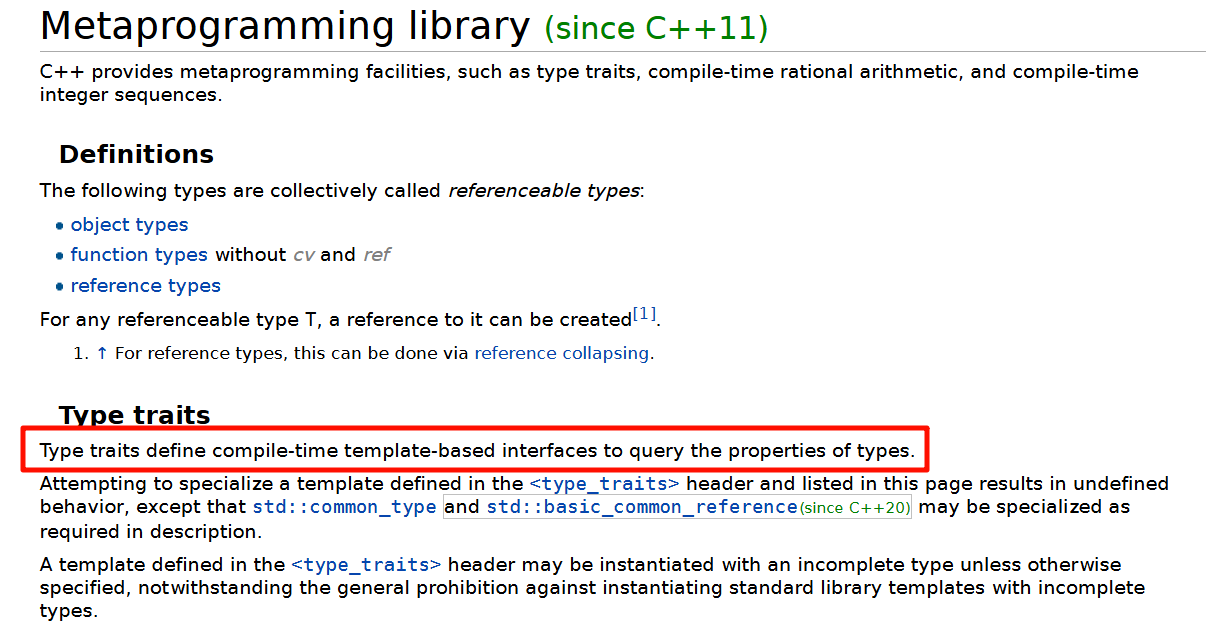
可不要把它跟 RTTI(Run-Time Type Information)搞混了!RTTI 是运行时的一种机制,两者的目的和实现方式完全不同。
在 <type_traits> 中,主要使用模板结构体,配合两种主要的静态成员以提供查询结果:
::value:对于用于查询类型属性或关系的萃取,它们通常包含一个名为value的静态bool常量成员。如果查询结果为真,其值为true,否则为false。例如,std::is_integral<int>::value的值为true。::type:对于用于转换类型的萃取,它们通常包含一个名为type的嵌套类型别名(使用typedef或using定义)。这个别名代表了转换后的新类型。例如,std::remove_reference<int&>::type就是int。
为了提升代码的可读性和简洁性,C++14 和 C++17 引入了变量模板(_v 后缀)和别名模板(_t 后缀)作为便捷的辅助工具。这些辅助模板极大地“美化”了代码,使我们不再需要显式访问 ::value 或 ::type 成员。
// C++11 风格
bool is_pointer_old = std::is_pointer<int>::value;
using pointer_to_int_old = std::add_pointer<int>::type;
// C++17 风格 (使用 _v 和 _t 后缀)
bool is_pointer_new = std::is_pointer_v<int>;
using pointer_to_int_new = std::add_pointer_t<int>;
看!这种演进体现了 C++ 标准委员会致力于降低模板元编程复杂性的持续努力。在现代 C++ 代码中,应优先使用 _v 和 _t 后缀的辅助模板。
1.1 类型萃取的实现
刚刚讲到了 <type_traits> 主要使用模板结构体及其两种主要的静态成员,现在就让我们深入底层源码,看看它具体是如何实现的(以 C++17 或以后的标准为例)。
在 IDE 中随便写一个 <type_traits> 库的函数,例如 std::is_integral,然后按住 Ctrl 键点击跳转,就可以看到它的源码。
一路溯源,你会发现其实在 <type_traits> 之下,还有 <xtr1common> 这个库,而它,正是 <type_traits> 的基石。
<xtr1common> 中只定义了类型萃取最基本的东西,所以代码量很少,只有两百多行:

我们只讲几个关键的,它在一开始,定义了一个 integral_constant 结构体模板,有一个类型参数 _Ty 和一个该类型的非类型参数 _Val。
template <class _Ty, _Ty _Val>
struct integral_constant {
static constexpr _Ty value = _Val;
using value_type = _Ty;
using type = integral_constant;
constexpr operator value_type() const noexcept {
return value;
}
constexpr value_type operator()() const noexcept {
return value;
}
};
这一段可能有点难以理解,主要是那两个成员函数,其实就是把 integral_constant 实例当做一个变量,可以直接使用,还可以像函数一样调用,两种用法返回的值都是 _Val,而它的类型就是 _Ty,也就是 value_type。
先说第一个吧,operator value_type() 其实是一个隐式转换运算符(作用类似 (double)3 一样),它允许我们在编译时将 integral_constant 实例转换为一个 value_type 类型变量使用;而第二个 value_type operator()() 重载了括号运算符,当我们调用 integral_constant() 时,会返回 value_type(即 _Ty)类型的值 value(即 _Val)。它们将在后续的代码中发挥重要作用。
为了更好的理解,我们写一个简单的例子:
int main()
{
using three_t = std::integral_constant<int, 3>;
using five_t = std::integral_constant<int, 5>;
three_t three;
five_t five;
auto fifteen = three_t() * five_t(); // 15
bool is_same = fifteen == three * five; // true
}
接着,是布尔类型的结构体模板,实际上是 integral_constant 的偏特化。
template <bool _Val>
using bool_constant = integral_constant<bool, _Val>;
using true_type = bool_constant<true>;
using false_type = bool_constant<false>;
判断两个类型是否相同就用到了 bool_constant:
template <class, class>
constexpr bool is_same_v = false;
template <class _Ty>
constexpr bool is_same_v<_Ty, _Ty> = true;
template <class _Ty1, class _Ty2>
struct is_same : bool_constant<is_same_v<_Ty1, _Ty2>> {};
这里用到了偏特化,在“两个类型都是 _Ty ”这一特殊情况时,is_same_v 的值为 true。is_same 实际上很少用到。
回到 <type_traits> 中,我们有时会有去除一个变量引用类型的需求,这时就需要用到 remove_reference 结构体模板:
template <class _Ty>
struct remove_reference {
using type = _Ty;
using _Const_thru_ref_type = const _Ty;
};
template <class _Ty>
struct remove_reference<_Ty&> {
using type = _Ty;
using _Const_thru_ref_type = const _Ty&;
};
template <class _Ty>
struct remove_reference<_Ty&&> {
using type = _Ty;
using _Const_thru_ref_type = const _Ty&&;
};
template <class _Ty>
using remove_reference_t = typename remove_reference<_Ty>::type;
这段代码分别对无引用、左值引用和右值引用进行特化,返回的类型都是无引用的 _Ty。
有了它,我们就可以写出 move 和 forward 了:
template <class _Ty>
constexpr remove_reference_t<_Ty>&& move(_Ty&& _Arg) noexcept {
return static_cast<remove_reference_t<_Ty>&&>(_Arg);
}
template <class _Ty>
constexpr _Ty&& forward(remove_reference_t<_Ty>& _Arg) noexcept {
return static_cast<_Ty&&>(_Arg);
}
template <class _Ty>
constexpr _Ty&& forward(remove_reference_t<_Ty>&& _Arg) noexcept {
static_assert(!is_lvalue_reference_v<_Ty>, "bad forward call");
return static_cast<_Ty&&>(_Arg);
}
现在再看这些源码应该就是手到擒来了,std::forward 中的 is_lvalue_reference_v 的源码如下,也很好懂:
template <class>
constexpr bool is_lvalue_reference_v = false;
template <class _Ty>
constexpr bool is_lvalue_reference_v<_Ty&> = true;
template <class _Ty> // 很少使用
struct is_lvalue_reference : bool_constant<is_lvalue_reference_v<_Ty>> {};
1.2 类型萃取的分类
<type_traits> 文件足足有 2606 行,我肯定是不会全部讲的,有了上面这些应该足以理解绝大多数的类型萃取是如何实现的了。
在此,我想总结一下 <type_traits> 中类型萃取的分类。
1. 一元类型萃取(Unary Type Traits)
这类萃取用于查询单个类型的属性。
- 基本类型查询
std::is_integral_v<T>:检查T是否为整数类型std::is_floating_point_v<T>:检查T是否为浮点类型std::is_arithmetic_v<T>:检查T是否为算术类型(整数或浮点数)std::is_class_v<T>:检查T是否为类或结构体类型std::is_pointer_v<T>:检查T是否为指针类型- …
- 属性查询
std::is_const_v<T>:检查T是否为常量类型std::is_volatile_v<T>:检查T是否为易变类型std::is_trivial_v<T>:检查T是否为平凡类型std::is_pod_v<T>:检查T是否为 Plain Old Data 类型- …
2. 二元类型萃取(Binary Type Traits)
这类萃取用于判断两个类型之间的关系。
std::is_same_v<T, U>:检查T和U是否为完全相同的类型std::is_base_of_v<Base, Derived>:检查Base是否为Derived的基类(或者是同一类型)std::is_convertible_v<From, To>:检查From类型的值是否能隐式转换为To类型
3. 转换萃取(Transformation Traits)
这类萃取接受一个类型并返回一个被修改过的新类型。
-
std::remove_const_t<T>:移除T的顶层const限定符 -
std::remove_reference_t<T>:移除T的引用 -
std::add_lvalue_reference_t<T>:为T添加左值引用 -
std::make_unsigned_t<T>:将有符号整数类型T转换为对应的无符号类型 -
std::common_type_t<T, U...>:确定一组类型T, U...的共同类型,即所有这些类型都可以被安全转换到的类型。
类型萃取不仅是独立的工具,它们更是后续将要讨论的所有高级模板技术的基石。它们提供的编译时布尔值和类型信息,是这些高级控制结构做出决策的数据来源,构成了一条清晰的技术演进链。
2. SFINAE:不是错误的“替换失败”
在类型萃取为我们提供了“审视”类型的能力之后,下一个逻辑问题是:如何利用这些信息来控制模板的行为?在 C++11 及以后的标准中,最经典(也最复杂)的机制之一就是 SFINAE。
2.1 SFINAE 的原理
初看这个单词可能会感觉很奇怪,我们也不用纠结它的发音,它其实是 “Substitution Failure Is Not An Error” 的缩写,即“替换失败不是个错误”。这是一个关于 C++ 模板重载解析的核心规则。简而言之,当编译器尝试为一个模板推导和替换模板参数时,如果这个替换过程导致了无效的类型或表达式,编译器不会立即报告一个硬性编译错误。相反,它会默默地将这个无法成功替换的模板版本从候选函数(或类)的集合中移除,然后继续尝试其他可行的重载。
这个规则的初衷是为了让泛型代码更加健壮。例如:
// #1: 只有当T有一个名为`type`的嵌套类型时,此模板才有效
template <typename T>
void test(typename T::type) {
std::cout << "T has a nested type 'type'\n";
}
// #2: 一个通用的可变参数模板作为备选方案
template <typename T>
void test() { // 省略号用于接收任意数量的参数
std::cout << "Fallback for T\n";
}
struct HasType { using type = int; };
struct NoType {};
int main() {
test<HasType>(0); // 匹配#1成功,因为HasType::type是有效的
test<HasType>(0, 1); // 匹配#1失败,因为参数数量不匹配,SFINAE生效,匹配#2
test<NoType>(0); // 匹配#1失败,因为NoType::type无效,SFINAE生效,匹配#2
test<int>(0, 1); // 匹配#1失败,因为int::type无效,SFINAE生效,匹配#2
}
然而,SFINAE 的应用有一个至关重要的限制,即所谓的“直接上下文(immediate context)”规则。只有在函数签名的直接替换过程中(即返回类型、参数类型、模板参数列表)发生的失败才属于 SFINAE。如果替换成功,但导致函数体内部的某个深层实现出现问题,那么这将是一个硬性的编译错误。例如:
// #1
template<typename T>
void Print(typename T::type t)
{
std::cout << t;
}
// #2
template<typename T>
void Print(T t)
{
std::cout << t;
}
class A{};
int main() {
Print(A());
}
这段代码中,Print(A()) 匹配 #1 失败,因为 A 没有 type 成员,SFINAE 生效,匹配 #2,但 #2 中调用了 std::cout << t,而 std::cout 无法打印 A 类型,所以这是一个硬性的编译错误:
Error C2679 : 二元“<<”: 没有找到接受“T”类型的右操作数的运算符(或没有可接受的转换)
...
如果你自己动手尝试过,会发现这段报错非常长!其实这就是编译器在模板实例化时不断匹配各种 << 运算符重载的过程,每一次失败都会有记录,直到所有匹配都失败,它才会一股脑地将所有失败信息全部输出。
所以你能看到这段报错信息中其实有很多的“无法将参数…转换为…”:
...无法将参数 2 从“T”转换为“const void *”
...无法将参数 2 从“T”转换为“long double”
...无法将参数 2 从“T”转换为“double”
...无法将参数 2 从“T”转换为“float”
...无法将参数 2 从“T”转换为“unsigned __int64”
...
而如果是在模板实例化之前,参数类型推导失败,则只会有类型推导失败的错误信息,因为到此就停止了:
template <typename T>
void Print(T a, T b)
{
std::cout << a << b;
}
class A{};
class B{};
int main()
{
Print(A(), B());
}
报错:
0>------- Started building project: Test
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.44.35207\bin\HostX64\x86\CL.exe /c /ZI /JMC /nologo /W3 /WX- /diagnostics:column /sdl /Od /Oy- /D WIN32 /D _DEBUG /D _CONSOLE /D _UNICODE /D UNICODE /Gm- /EHsc /RTC1 /MDd /GS /fp:precise /Zc:wchar_t /Zc:forScope /Zc:inline /permissive- /Fo"Debug\\" /Fd"Debug\vc143.pdb" /external:W3 /Gd /TP /analyze- /FC /errorReport:prompt run.cc
run.cc
0>run.cc(16,2): Error C2672 : “Print”: 未找到匹配的重载函数
X:\Projects\C++\Test\run.cc(6,6):
可能是“void Print(T,T)”
X:\Projects\C++\Test\run.cc(16,2):
“void Print(T,T)”: 模板 参数“T”不明确
X:\Projects\C++\Test\run.cc(16,2):
可能是“B”
X:\Projects\C++\Test\run.cc(16,2):
或 “A”
X:\Projects\C++\Test\run.cc(16,2):
“void Print(T,T)”: 无法从“B”推导出“T”的 模板 参数
0>------- Finished building project: Test. Succeeded: False. Errors: 1. Warnings: 0
Build completed in 00:00:02.128
这个就简洁明了了许多,对吧?
SFINAE 的这种特性,使得富有创造力的 C++ 程序员们很快意识到,这个规则可以被“利用”:如果我们能根据类型的某些属性(通过类型萃取获得)来故意制造替换失败,我们就能精确地控制哪个模板重载被启用。这催生了现代 C++ 模板元编程的一个重要分支,而 std::enable_if 正是为此而生的标准工具。
2.2 std::enable_if_t
SFINAE 是一个语言规则,而 std::enable_if_t 是 C++14 标准库中提供的一个模板元函数,其设计的唯一目的就是为了方便地利用 SFINAE 规则,达到约束参数类型的效果:
std::enable_if_t 的定义非常简单:
template <bool _Test, class _Ty = void>
struct enable_if {}; // no member "type" when !_Test
template <class _Ty>
struct enable_if<true, _Ty> { // type is _Ty for _Test
using type = _Ty;
};
// C++14 中引入的别名模板
template <bool _Test, class _Ty = void>
using enable_if_t = typename enable_if<_Test, _Ty>::type;
它有两个模板参数:一个 bool 常量 _Test 和一个类型 _Ty(默认为 void)。其工作机制是:
-
如果
_Test为true,std::enable_if<true, _Ty>会有一个名为type的公开成员类型别名,其类型为_Ty。 -
如果
_Test为false,std::enable_if<false, _Ty>匹配的是那个空的主模板,它没有名为type的成员。
因此,当我们在需要类型的地方使用 typename std::enable_if<Condition, Type>::type 时,只有当 Condition 为 true 时,才会返回 type 成员,否则访问一个不存在的 ::type 成员就会导致替换失败,从而触发 SFINAE。
下面介绍几个 std::enable_if_t 的典型应用场景:
1. 作为返回类型
template<typename T>
std::enable_if_t<std::is_integral_v<T>, bool>
IsOdd(T i) { return i % 2!= 0; }
int main()
{
bool a = IsOdd(1); // a为true
bool b = IsOdd(2.1); // 未找到匹配的重载函数 [!code error]
}
在此例中,IsOdd(1) 模板类型参数推断为 int,std::is_integral_v<int> 为真,所以 _Test 为真,可以获取到 type 成员,能够匹配成功;而 IsOdd(2.1) 模板类型参数推断为 double,std::is_integral_v<double> 为假,所以 _Test 为假,没有 type 成员,导致替换失败,此时又没有其他重载,所以报错。
2. 作为函数参数
template<typename T>
void PrintValue(T value,
std::enable_if_t<std::is_integral_v<T>, int> = 0)
{
std::cout << "整数类型: " << value << '\n';
}
template<typename T>
void PrintValue(T value,
std::enable_if_t<std::is_floating_point_v<T>, double> = 0.0)
{
std::cout << "浮点类型: " << value << '\n';
}
int main()
{
PrintValue(42); // 整数类型: 42
PrintValue(3.14); // 浮点类型: 3.14
// PrintValue("hello"); // 未找到匹配的重载函数 [!code error]
}
在这个例子中,我们通过函数参数的默认值来利用 SFINAE。该模板只允许 int 和 double 类型,其他类型都会导致报错。注意这里为 std::enable_if_t 设置了默认值,表示它虽然在函数参数列表中,但我们可以不必理会。
3. 作为模板参数
template <typename T,
typename = std::enable_if_t<std::is_arithmetic_v<T>>>
T Add(T a, T b)
{
return a + b;
}
int main()
{
int res1 = Add(1, 2);
double res2 = Add(1.1, 2.2);
auto res3 = Add(std::string("1"), "2"); // 未找到匹配的重载函数 [!code error]
auto res4 = std::string("1") + "2"; // res4 == "12"
}
把它放到模板参数中也是一样可以进行类型约束的,比如这里,std::string 和字符串字面量原本是可以相加的,但因为不是算数类型,std::enable_if_t<std::is_arithmetic_v<T>> 获取 type 失败,所以报错。
需要注意的是,不能通过仅改变模板参数默认值来重载函数模板,因为默认参数不参与函数签名的构成,这会导致重定义错误,例如我们像函数参数的例子那样在模板参数中分别指定 int 和 double 的默认值:
template<typename T, typename = std::enable_if_t<std::is_integral_v<T>>>
void PrintValue(T value)
{
std::cout << "整数类型: " << value << '\n';
}
template<typename T, typename = std::enable_if_t<std::is_floating_point_v<T>>>
void PrintValue(T value)
{
std::cout << "浮点类型: " << value << '\n';
}
报错:
Error C2995 : “void PrintValue(T)”: 函数模板已经定义
X:\Projects\Test\run.cc(5,6):
参见“PrintValue”的声明
Error C2572 : “PrintValue”: 重定义默认参数 : 参数 2
X:\Projects\Test\run.cc(5,6):
参见“PrintValue”的声明
小结:
三种使用方法大同小异,都是在定义函数时加上了模板参数的类型约束,唯一不同的是 std::enable_if_t 作为模板参数时,不能重载多个类似的函数模板。
2.3 缺点
尽管 SFINAE 功能强大,但它的缺点也显而易见:
- 高冗余性:实现多个分支需要编写多个几乎相同的函数模板声明,只有
std::enable_if_t部分不同。 - 代码分散:相关的逻辑被分散在多个独立的函数重载中,降低了代码的内聚性。
- 可读性差:
std::enable_if_t的语法对于不熟悉模板元编程的开发者来说非常晦涩。 - 糟糕的错误信息:如果传入的类型不匹配任何一个
std::enable_if_t条件,编译器通常会给出一个“找不到匹配的函数”的错误,而不会告诉用户具体是哪个约束没有被满足 。
SFINAE 就像一个在模板系统入口处的“语法门卫”,它根据类型是否持有正确的“通行证”来决定是否放行某个重载进入最终的候选名单。它只能控制“谁能进”,但无法改变“进去之后做什么”。这种局限性,正是 C++17 的 if constexpr 和 C++20 的 Concepts 旨在解决的核心痛点。
不过,在此之前,我想先讲解编译时计算。
在 C++17 引入
if constexpr之前,还有一种技术叫做“标签派发”(Tag Dispatch),它也是通过函数重载来实现编译时分支,与std::enable_if_t类似。受限于篇幅,本文不会介绍。
3. 编译时计算:压榨编译器
模板元编程不仅限于类型操作,它还使这一惊人的操作成为了可能:在编译阶段执行计算(Compile-Time Computation)。这意味着某些计算结果可以在程序运行之前就被确定下来,并作为常量嵌入到最终的可执行文件中。这对于性能优化、常量生成和算法配置等方面具有重要意义。
诚然,我们也可以通过预编译命令来实现编译时(预编译)计算,比如下面这个计算阶乘的例子:
#include <iostream>
#define FACTORIAL_0 1
#define FACTORIAL_1 1
#define FACTORIAL_2 (2 * FACTORIAL_1)
#define FACTORIAL_3 (3 * FACTORIAL_2)
#define FACTORIAL_4 (4 * FACTORIAL_3)
#define FACTORIAL_5 (5 * FACTORIAL_4)
#define CONCAT(a, b) a##b
#define FACTORIAL(n) CONCAT(FACTORIAL_, n)
int main() {
int fact5 = FACTORIAL(5); // 在预处理阶段展开为 (5*(4*(3*(2*1))))=120
// 使用条件编译进行不同的计算
#if FACTORIAL(3) > 5
std::cout << "3! > 5\n";
#else
std::cout << "3! <= 5\n";
#endif
}
但这种方式有许多缺点:
- 类型不安全:宏只是简单的文本替换,没有类型检查
- 作用域问题:宏没有作用域概念,可能意外影响其他代码
- 调试困难:预处理器在编译之前工作,调试器无法跟踪宏展开的过程
- 可读性差:复杂的宏定义难以理解和维护
- 功能有限:无法进行复杂的逻辑运算和类型操作
在现代 C++中,我们有两种主要的方式来实现编译时计算:传统模板元编程和更现代的 constexpr 函数。
3.1 传统模板元编程
在 C++11 引入 constexpr 之前,编译时计算完全依赖于模板的递归实例化和特化,只能用 enum 来表示编译期常量。这种编程范式与常规的 C++ 代码截然不同,它更像是一种嵌入在 C++ 中的纯函数式编程语言,拥有独特的语法和规则。
其核心技术包括:
- 递归:通过模板的递归实例化来模拟循环
- 状态:由于编译时没有可变状态,计算结果通过静态成员(如
::value)或类型别名(如::type)在递归调用之间传递 - 终止条件:通过模板特化(全特化或偏特化)来定义递归的基准情况(base case),从而终止递归
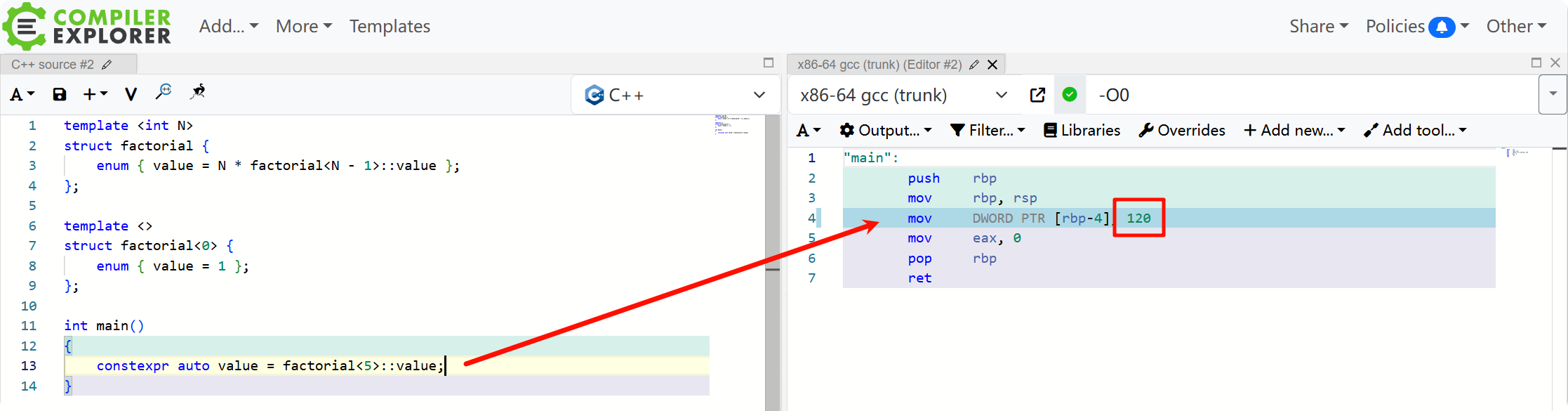
计算阶乘是展示传统 TMP 最经典的例子(代码链接):
template <int N>
struct factorial {
enum { value = N * factorial<N - 1>::value };
};
template <>
struct factorial<0> {
enum { value = 1 };
};
int main()
{
constexpr auto value = factorial<5>::value;
}
编译结果如下,可以看到 factorial<5>::value 确实在编译时被计算为 120:
3.2 constexpr 函数
constexpr 可以用于变量和函数,表示它们可以在编译时被求值。constexpr 函数的发展历程本身也体现了 C++ 的演进:
-
C++11:
constexpr函数受到严格限制,被戏称为“draconic”(严苛的)。函数体内只能包含一条return语句,不允许有局部变量、循环或分支语句 。 -
C++14/17:这些限制被大幅放宽。
constexpr函数现在可以包含局部变量、if语句、switch语句和循环,使其在外观和功能上与普通函数越来越相似 。
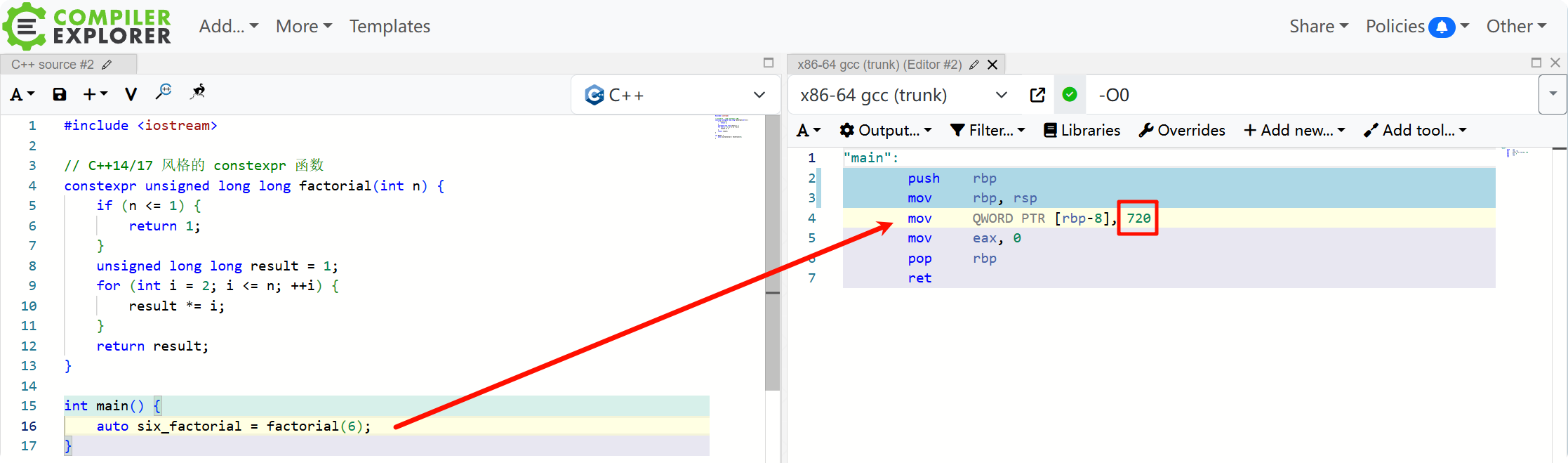
让我们用 constexpr 函数重写阶乘计算(代码链接):
#include <iostream>
// C++14/17 风格的 constexpr 函数
constexpr unsigned long long factorial(int n) {
if (n <= 1) {
return 1;
}
unsigned long long result = 1;
for (int i = 2; i <= n; ++i) {
result *= i;
}
return result;
}
int main() {
auto six_factorial = factorial(6);
}
编译结果如下,符合预期。:
这段代码的可读性与传统 TMP 版本相比有了天壤之别。它看起来就像一个普通的 C++ 函数。
随着 C++ 标准的不断更新,越来越多的库函数也都用上了 constexpr 函数,比如:
// C++17
template< class T, std::size_t N >
constexpr std::size_t size( const T (&array)[N] ) noexcept;
到 C++20 时,<algorithm> 头文件中的许多函数都用上了 constexpr 函数,这使得我们可以在编译时更加轻松地完成复杂计算:
std::find、std::find_if、std::find_if_notstd::replace、std::replace_ifstd::sort、std::min、std::maxstd::fill、std::fill_n- …
一个关于 constexpr 的关键点是:将一个函数声明为 constexpr,只是赋予了它在编译时运行的潜力,但并不保证它一定会在编译时运行。它能否在编译时运行,取决于调用它时的上下文 :
- 如果
constexpr函数的所有参数都是编译时常量(如字面量或其他constexpr变量),并且其结果被用于需要编译时常量的上下文中(如static_assert、数组大小、模板非类型参数),那么编译器必须在编译时计算它。 - 如果任何一个参数是运行时变量,那么这个
constexpr函数就会像一个普通函数一样,在运行时被调用。
这种“双模式”特性是 constexpr 的一大优势。同一个函数定义可以服务于编译时和运行时两种场景,这完美体现了 C++ 的零开销抽象和代码复用原则 。
4. if constexpr:模板元编程的未来
曾经,如果我们希望实现编译时(预编译)分支,就必须借助预编译命令 #if、#else 和 #endif 来实现,比如:
#define DEBUG 1
int main()
{
#if DEBUG
std::cout << "Debug mode";
#else
std::cout << "Release mode";
#endif
}
在 C++17 引入 if constexpr 之后,我们就可以更加优雅地实现编译时分支:
template <typename T>
auto get_value(T t) {
if constexpr (std::is_pointer_v<T>) {
std::cout << "pointer: ";
return *t;
} else {
std::cout << "non pointer: ";
return t;
}
}
int main()
{
int a = 10;
int* b = &a;
std::cout << get_value(a) << '\n'; // non pointer: 10
std::cout << get_value(b) << '\n'; // pointer: 10
}
再说回 SFINAE,现在我们就可以用 if constexpr 来代替 std::enable_if_t 来实现类型约束,比如上面整型和浮点数重载的例子(代码链接):
template <typename T>
void PrintValue(T value)
{
if constexpr(std::is_integral_v<T>)
{
std::cout << "整型" << value;
}
else if constexpr(std::is_floating_point_v<T>)
{
std::cout << "浮点型" << value;
}
else
{
std::cout << "unknown";
}
}
int main()
{
PrintValue(10); // 整型10
PrintValue(2.5); // 浮点型2.5
PrintValue("Fuxi"); // unknown
}
是不是感觉瞬间清爽了许多?观察编译后的结果,虽然我们只写了一个函数模板,但由于有 if constexpr 的存在,编译器会根据不同的类型生成不同的函数实例,这就类似 #if 等预编译命令,从而巧妙地实现了原本 SFINAE 的功能。
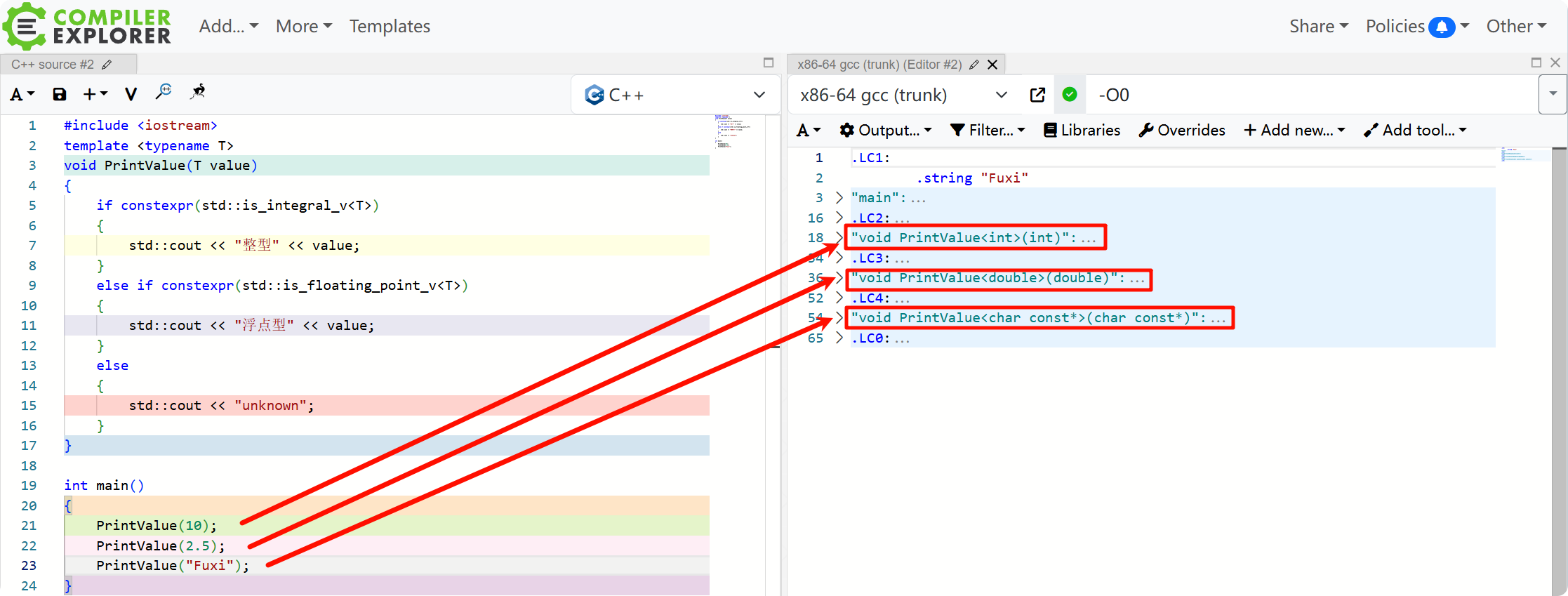
对比之下,if constexpr 的优势一目了然:
- 可读性:所有逻辑都集中在一个函数内,并且以顺序、线性的方式呈现,意图清晰明了。
- 可维护性:如果需要增加对其他类型(例如自定义的数字类)的支持,只需在函数体内增加一个
else if constexpr分支,而无需添加一个全新的、复杂的 SFINAE 重载。 - 意图的直接性:代码直接表达了“如果类型是 X,就做 A;否则如果类型是 Y,就做 B”,这比 SFINAE 通过重载解析的间接机制要清晰得多。
注意,这里必须强调的一点是:
if constexpr和 SFINAE 是两种完全不同的机制 。SFINAE
作用于重载解析阶段,用于从候选函数集中筛选函数。而if constexpr
作用于模板实例化阶段,在函数已经被选定之后,用于决定函数体内的哪些部分被编译。这个技术上的区别,导致了它们在编程风格上的哲学转变:SFINAE 鼓励将不同逻辑分散到多个函数中,而if constexpr则鼓励将相关逻辑聚合在单个函数内,从而提高了代码的内聚性和可理解性。
5. Concepts:模板编程的契约设计
尽管 if constexpr 极大地改善了在模板内部编写条件逻辑的方式,但它并未解决一个更根本的问题:如何清晰、直接地在模板的“接口”上声明其对类型参数的要求。长久以来,C++ 模板因其糟糕的错误信息和隐晦的类型要求而饱受诟病 。C++20 引入的 <concepts> 头文件,正是为了彻底解决这一历史难题而设计的。
你可能还是有疑惑:模板不正是用于泛型编程的吗,为啥还要约束类型呢?
C++ 模板的设计初衷就是为了泛型编程。但问题在于,最初的模板设计过于“泛滥”,缺乏约束,这在实践中带来了巨大的痛苦。在没有 <concepts> 的时代,模板的要求是隐式的,它们“隐藏”在模板的实现细节中。当开发者尝试使用一个不满足这些隐式要求的类型来实例化模板时,编译器会深入模板内部进行替换,直到某个操作失败为止。其结果,就是那堵臭名昭著的“模板错误信息墙”——成百上千行令人费解的、层层嵌套的错误日志,让开发者难以定位问题的根源。
C++20 的 Concepts 并非要改变模板的泛型初衷,而是为了给这份“泛滥”的泛型能力套上一个“缰绳”,使其更安全、更易用、更强大。
<concepts> 通过以下方式解决了这些问题:
-
明确的接口:它允许我们为模板参数定义一组明确的、具名的约束。这些约束成为了模板接口的一部分,就像函数参数的类型一样清晰 。
-
改善的错误信息:当一个类型不满足
concept时,编译器不再深入模板内部,而是直接在调用点报告一个简洁明了的错误,指出“模板参数T不满足MyConcept约束” 。 -
更强的表达力:它提供了一种正式的语言机制来表达对类型的语义要求,而不仅仅是语法上的要求。
从根本上说,<concepts> 旨在将模板编程从一种基于“语法试错”(duck typing)的模式,转变为一种基于“契约设计”(design by contract)的模式。
5.1 定义与使用 <concepts>
C++20 引入了两个新的关键字:concept 用于定义一个概念,requires 用于施加约束。
定义
一个 concept 的定义本质上是一个编译时布尔谓词。约束表达式可以是一个简单的 bool 常量,通常由类型萃取或其他 constexpr 表达式得出。例如,标准库中的 std::integral 概念可以这样自定义:
#include <concepts>
#include <type_traits>
template <typename T>
concept Integral = std::is_integral_v<T>;
使用
一旦定义了 concept,我们有四种主要的方式来约束一个函数模板:
- 尾随
requires子句(Trailing requires clause)
template <typename T>
void func(T arg) requires Integral<T> { /*... */ }
- 前置
requires子句(Leading requires clause)
template <typename T>
requires Integral<T>
void func(T arg) { /*... */ }
- 约束模板参数(Constrained template parameter)
template <Integral T>
void func(T arg) { /*... */ }
- 缩写函数模板(Abbreviated function template)
// 不用写 template
void func(Integral auto arg) { /*... */ }
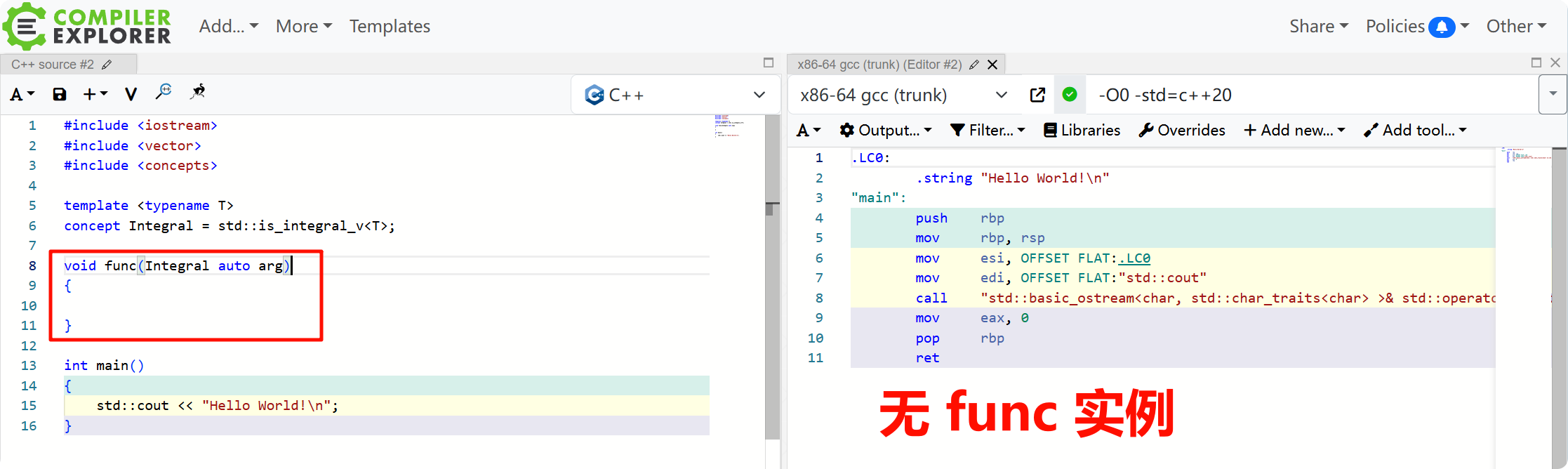
这四种语法在功能上是等价的,但提供了不同程度的简洁性和表达力。特别是第四种,它使得编写简单的泛型函数几乎和编写非泛型函数一样简单。
或许你不相信第四种也是函数模板,我们可以看看不调用它的编译结果,注意要使用 -std=c++20(代码链接):
组合
requires 子句支持使用逻辑与(&&)和逻辑或(||)来组合多个 concept,形成更复杂的约束:
template <typename T>
requires Integral<T> // 自定义 concept
|| std::floating_point_v<T> // 标准库 concept
void numeric_func(T arg) { /*... */ }
当然,我们也可以换一种方式:
template <typename T>
concept Integral = std::is_integral_v<T>;
template <typename T>
concept FloatintPoint = std::is_floating_point_v<T>;
template <typename T>
concept Combine = Integral<T> || FloatintPoint<T>;
5.2 requires 表达式:定义精细化的要求
Concepts 的真正威力在于,它们不仅能包装简单的类型萃取,还能通过 requires 表达式来定义一组非常具体和细化的语法要求,比如:
template<class T>
concept IsVector = requires (T a)
{
a[0]; // 要求 T 有 operator[] 方法
a.begin(); // 要求 T 有 begin 方法
a.reserve(1); // 要求 T 有 reserve 方法
a.data(); // 要求 T 有 data 方法
};
template<IsVector T>
void Test(T v)
{
std::cout << "is vector";
}
int main()
{
std::vector<int> v = {1, 2, 3, 4, 5};
Test(v); // 输出 is vector
int arr[] = {1, 2, 3, 4, 5};
Test(arr); // 报错:因为约束而替换失败,requires(int* a){...} is false [!code error]
}
5.3 重载与代码简化
Concepts 为函数模板重载提供了强大而清晰的机制。当多个模板对同一个调用都有效时,编译器会选择那个约束最严格(most constrained)的重载版本。约束的严格程度由“约束子集”关系决定。例如,SignedIntegral 比 Integral 更严格,因为所有满足 SignedIntegral 的类型都满足 Integral,但反之不然:
#include <concepts>
#include <iostream>
void PrintCategory(std::integral auto) {
std::cout << "Generic integral\n";
}
void PrintCategory(std::signed_integral auto) {
std::cout << "Signed integral\n";
}
int main() {
PrintCategory(10u); // 只能调用 std::integral 版本
PrintCategory(-10); // 调用 std::signed_integral 版本 (更严格)
PrintCategory(3.3); // 报错:未满足任何约束 [!code error]
}
这种基于概念的重载解析,正是 SFINAE 试图以一种间接方式实现的目标,但 Concepts 的语法要清晰直观得多。
Concepts,特别是缩写函数模板的语法,极大地降低了编写泛型代码的门槛。它统一并简化了过去由繁琐的约束机制,提供了一个单一、内聚且强大的语言特性,标志着 C++ 泛型编程进入了一个全新的时代。
6. 总结
在这篇文章中,我们穿越了 C++ 模板元编程的演进之路,从基础的类型探查工具到定义未来泛型代码的先进理念。这段旅程清晰地揭示了 C++ 语言为解决模板约束这一核心挑战所付出的不懈努力。
我们的探索始于类型萃取(Type Traits),这些编译时的探针为我们提供了审视和转换类型的底层能力。在此基础上,SFINAE 应运而生,它利用巧妙的语言规则,以一种间接但有效的方式实现了早期的模板约束。
C++11 及后续标准带来了转折点。constexpr 将编译时值计算从晦涩的模板递归中解放出来,使其语法回归 C++ 的常规风格。而 C++17 的 if constexpr 则是一场优雅的革命,它用清晰的编译时分支逻辑取代了 SFINAE 在实现选择上的主要用途,极大地提升了代码的可读性和内聚性。
最终,我们抵达了 C++20 的 Concepts。它不是对旧有技术的简单改进,而是一次彻底的范式重塑。Concepts 为模板提供了明确的接口和契约,将约束从隐晦的实现细节提升为语言的一等公民。它不仅解决了长期困扰开发者的模板错误信息问题,更通过清晰的语法和强大的表达力,使得编写健壮、可读的泛型代码如此轻而易举。
回顾这条从类型萃取到 Concepts 的演进路径,我们看到的是一个从“特设技巧”(ad-hoc techniques)到“系统化设计”(systematic design)的转变。现代 C++ 为泛型编程提供了一个清晰、强大且统一的工具集。
参考文献
- 雾里看花:真正意义上的理解 C++ 模板
- C++ Template Programming
- Metaprogramming library - cppreference
- Standard library header
<type_traits>- cppreference- Standard library header
<concepts>- cppreference- SFINAE - cppreference
- constexpr specifier - cppreference
- Standard library header
<algorithm>- cppreference- What are C++20 concepts and constraints? How to use them?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











