






首先我们说下数据库,数据库有两种分别是关系型数据库和非关系性数据库
一、关系型数据库

关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织
优点:
1、易于维护:都是使用表结构,格式一致;
2、使用方便:SQL语言通用,可用于复杂查询;
3、复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。
缺点:
1、读写性能比较差,尤其是海量数据的高效率读写;
2、固定的表结构,灵活度稍欠;
3、高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
二、非关系型数据库

非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
优点:
1、格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
2、速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
3、高扩展性;
4、成本低:nosql数据库部署简单,基本都是开源软件。
缺点:
1、不提供sql支持,学习和使用成本较高;
2、无事务处理;
3、数据结构相对复杂,复杂查询方面稍欠。
非关系型数据库的分类和比较:
1、文档型
2、key-value型
3、列式数据库
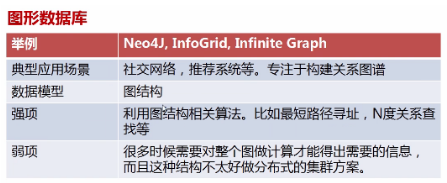
4、图形数据库



1. 数据库基本命令
1.显示所有的数据库
--- show databases;
2.进入数据库
--- use 数据库名称;
如果显示databases changed就进入成功了
3.显示数据库下的表名
--- show tables;
4.显示一个表中字段的信息
--- describa 表名;
5.创建一个数据库
--- create databases 库名;
6.推出
--- exit
这些命令其实我们一般很少用到,我们用的最多的还是SQL语句
2. 数据库的数据类型和字段属性
1.数据类型
1.1数值
1. tinyint 表示很小的数据 1字节
2.smallint 表示较小的数据 2字节
3.mediumint 表示中等大小的数据 3字节
4. int 表示标准的整数 4个字节(这个用的最多)
5.bigint 表示很大的数据
6.float 浮点数 4个字节
7.double 浮点数 8个字节
8.decimal 字符串形式的浮点数 关于金融方面的时候会使用
1.2字符串
1. char 固定的字符串大小 0~255
2. varchar 可变字符串 0-65535(字符串里面这个用的最多)
3.tinytext 微型文本 大小为2^8-1
4.text 文本 你写本书都够存
1.3时间日期
1.time HH : mm : ss 时间格式
2.date YYYY-MM-DD 日期格式
3.datetime YYYY-MM-DD HH : mm : ss (最常用的时间格式)
4. timestamp 时间戳
2.字段属性

2.1 Unsigned
勾选这个选项,说明这个字段的值不能为负数
2.2 Zerofill
0填充,加入你前面长度选了5,但是值是1,那么最后就会显示00001


2.3 自增
通常用来设置唯一主键,在上一条的数据中加1(默认也是加1),可以自定义设计主键自增的起始值和步长,也可以修改默认值


这里的00005是自动生成的
2.4 非空
字面意思,就是不能为空,但是要注意的是

这里没有报错的原因是,它是字符串是空,不是真的为空,就像java中0并不是真的为0
2.5 默认
字面意思,如果我们没有输入值,那么它就会显示一个默认值,例

这里我们设置性别的默认值为男,那么不输入性别值,就会显示性别为男

3. 搜索引擎
Mysql有两种搜索引擎,一个是Myisam,一种是innodb,我们常用的也是innodb
| MYISAM | INNODB | |
| 事务 | 不支持 | 支持 |
| 数据行锁定 | 不支持 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间大小 | 较小 | 较大,约为MYISAM的两倍 |
MYISAM节约空间,速度较快
INNODB安全性高,事务的处理,多表用户操作
4. 增,删,改语句
4.1 新增
数据库新增语句用insert into关键字实现
公式:insert into 表名('字段名1','字段名2','字段名3',) values('值1','值2','值3',);
使用insert into语句要注意的是字段名和值一定要一一对应,表名和字段名用 `字段名` ,值用 '值' 。而且都是中文符
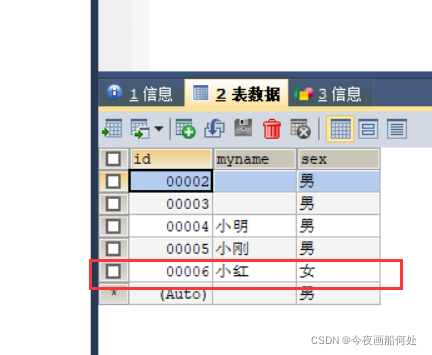
举例:
INSERT INTO `aaa`(`id`,`myname`,`sex`) VALUES ('6','小红','女');结果:
4.2 修改
修改数据用update关键字使用,注意的是update经常和where一起使用
公式:update 表明 set 字段名='值' where 条件
举例:
-- 修改id为00004的姓名为小刚
UPDATE `aaa` SET `myname`='小刚' WHERE `id`=00004;4.3 删除
删除用的是delete 关键字实现
公式:delete from 表名 where 条件
举例:
-- 删除myname为小红的数据
DELETE FROM `aaa` WHERE `myname`='小红';说到删除就必须说到数据删除表数据常用的另一个关键字truncate
truncate语句很简单,就是后面跟一个表名即可
-- 删除aaa表中所有的数据
TRUNCATE `aaa`;如果我们要删除表中所有数据的话,一般使用truncate
4.4 delete 和 truncate的区别
- truncate会重新设置自增序列,计数器归零,不会影响事务
- delete不会重新设置自增序列
5. 查询语句
查询语句是相当重要的,我们一般使用最多的语句也是查询语句
5.1 最基本的查询
公式1:select * from 表名
-- 查看aaa表中的所有数据
SELECT * FROM `aaa`你说,我不想查看表中所有的数据,我就想查看表中id字段和myname字段信息,也是可以的
公式2:select 想要查看的字段名1,想要查看的字段名2,from 表名
-- 查看表中的id,myname信息
SELECT id,myname FROM `aaa`
5.2 别名的使用
当我们字段名或者表名复杂时,或者无法见名知意时,常使用别名,使用别名关键字 AS
-- 起别名
SELECT `id` AS '学号',`myname` AS '姓名' FROM `aaa`当我们查看数据的时候,可能不知道那个字段名表示什么什么意思时,就可以用别名
我们把id换成学号,把myname换成姓名

当然表也可以起别名
在介绍一个函数CONCAT,他的作用是拼接字符串
-- 拼接字符串,使用concat
SELECT CONCAT('姓名:',myname) AS '新名字' FROM `aaa`
5.3 去重
去重实现是用关键字distinct实现
例如下面这张表

我只想查看code从1001到1010之间有没有成绩,如果使用select code from 表名语句的话

可以看见有很多重复的,这个时候我们就需要使用distinct
SELECT DISTINCT CODE FROM bbb
我在说一点,就是使用select语句可以对数据实现整体的修改
-- 对表中的score成绩进行整体的-1
SELECT `code`,`score`-1 AS 减分后,`course` FROM `bbb`5.4 where语句的使用
这个很重要,我们在平时的查询数据时,经常要进行判断,跟where一起经常使用的又有and,or,!
-- 我们查询分数在60和95分之间的数据
SELECT * FROM `bbb` WHERE `score`>=65 AND `score`<=95-- 我们查询code不为1001的所有成绩
SELECT * FROM `bbb` WHERE CODE !=1001-- 使用not,查看code不为1002的数据
SELECT * FROM `bbb` WHERE NOT CODE=1002当然我这里所写的select 语句都是十分基础的,往往我们碰见的查询语句都是十几行或者上百行的sql代码
6. 模糊查询
常用的模糊查询语句有
1. like
-- 查询姓李的同学,使用like
-- like 结合 %(代表多个字符)——(代表一个字符)
SELECT `id`,`myname` FROM `aaa`
WHERE myname LIKE '李%'
like的用法就像我们使用百度搜索时啊,我们刚打一个字,下面就出现许多的结果,我们要记住%表示0到多个字符,_表示一个字符
例如,我们想查姓李的,而且名字是两个字的
SELECT `id`,`myname` FROM `aaa`
WHERE MYNAme LIKE '李_'2. in
in的用法是包含
-- 我想查询地址为重庆,天津的
SELECT `myname`,`myaddress` FROM `aaa`
WHERE `myaddress` IN('重庆','天津')使用in时,我们要注意in里面的值必须是精准的
3. is null,is not null
这个两个就比较简单了,就是看值是不是空和非空
-- is null
SELECT `myname`,`myaddress` FROM `aaa`
WHERE myname IS NULL OR `myname`=' '-- is not null
SELECT `myname`,`myaddress` FROM `aaa`
WHERE myname IS NOT NULL7. 连表查询
| 操作 | 解释 |
| inner join | 如果表中有匹配的,就返回行 |
| left join | 会从左表中返回值,即使右表中没有匹配 |
| right join | 会从右表中返回值,即使左表中没有匹配 |
-- 我们想看学号,学生姓名,成绩,科目
-- 明确交叉点,就是两张表里面都有的,作为查询条件
SELECT a.id,myname,score,course
FROM `aaa` AS a
INNER JOIN `bbb` AS b
WHERE a.id=b.code这里还有一点就是使用 inner join 时最好使用on
-- left join
SELECT b.code,myname,score,course
FROM `aaa` AS a
LEFT JOIN `bbb` AS b
ON a.id=b.code使用左,右查询查询时要注意不要写where,写on

我们可以看见最后一条数据,李通达根本就没有考试,所以跟bbb表没有什么关联,但是因为是左查询,而左表是aaa表,所以也把李通达的数据查出来了
-- right join
SELECT b.code,myname,score,course
FROM `aaa` AS a
RIGHT JOIN `bbb` AS b
ON a.id=b.code
使用右查询时,就可以发现没有李通达的数据显示的
-- 例如,我们想知道学生的学号,成绩,电话号码,科目
-- 这样就是3张表查询
SELECT a.id,myname,score,course,tel
FROM `aaa` AS a
INNER JOIN `bbb` AS b
ON a.id=b.code
INNER JOIN `ccc` AS c
ON a.id=c.myid三张表的查询其实也简单,就是把前两张表的查询结果当作一个整体,或一张表,后面在跟inner join ,我们在使用join语句时,最好不要使用where,而是使用ON

8. 聚合函数
8.1 常用函数
常用函数这里就不过多的阐述和演示,大家感兴趣的话,可以去官网看
我们主要讲聚合函数
8.2 聚合函数
聚合函数是我们经常使用的函数
| 常用聚合函数名称 | 描述 |
| 1. count() | 计数 |
| 2. sum() | 求和 |
| 3. avg() | 平均值 |
| 4. max() | 最大值 |
| 5. min() | 最小值 |
1. count()
说到count那么就不得不说到count的三种方式
SELECT COUNT(myname) FROM `aaa`
SELECT COUNT(1) FROM `aaa`
SELECT COUNT(*) FROM `aaa`使用列名查询时,会忽略null值,而1和*不会
三者的区别
1. count(1) and count(*)
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了!
从执行计划来看,count(1)和count(*)的效果是一样的。但是在表做过分析之后,count(1)会比count(*)的用时少些(1w以内数据量),不过差不了多少。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count(*),自动会优化指定到那一个字段。所以没必要去count(1),用count(*),sql会帮你完成优化的 因此:count(1)和count(*)基本没有差别!
2. count(1) and count(字段)
两者的主要区别是
count(1) 会统计表中的所有的记录数,包含字段为null 的记录。
count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
2 sum()
-- 求语文科目的分数总和
SELECT SUM(score) FROM `bbb` WHERE course='语文'3 avg()
-- 求数学成绩的平均数
SELECT AVG(score) FROM `bbb` WHERE course='数学'4 max()
-- 求英语成绩的最大值
SELECT MAX(score) FROM `bbb` WHERE course='英语'5 min()
-- 求英语成绩的最小值
SELECT MIN(score) FROM `bbb` WHERE course='英语'最后我们再说一下分组
查询各个科目的平均分,最大分,最低分用group by 分组
SELECT course,AVG(score) AS '平均分',MAX(score) AS '最高分' ,MIN(score) AS '最低分' FROM `bbb` GROUP BY coursehaving关键字(在过滤,一般用于使用where语句后)
-- 我们连表查询,科目是语文,并且学号是1001的信息,一般可能是用and
-- 但是也可以用having
SELECT id,myname,score,`course`,mytinme FROM
aaa AS a
INNER JOIN bbb AS b
ON a.id=b.code
INNER JOIN ccc AS c
ON a.id=c.myid
WHERE course='语文'
HAVING id='1001'数据排序
排序使用order by
升序 ASC 降序 desc
SELECT * FROM bbb WHERE course='英语' ORDER BY score DESC 分页,用limit
SELECT * FROM bbb WHERE course='英语' ORDER BY score ASC LIMIT 0,5升序,然后分页只显示5条数据
9. 事务
谈到事务一般都是谈ACID这四点
1.原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,通俗的讲就是事务的操作要么都成功,要么都失败
2.一致性(Consistency)
事务前后数据的必须保持一致
3.隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离
4.持久性(Durability)
通俗的讲就是事务一旦提交则不可逆,被持久化到数据库中
这里举一个用的最多的例子,也是最经典的例子
原子性:A有1000元,B有1000元,如果A转给B200元,那么就有两个步骤,第一步A减去200元,第二部B加上200元,事务的原子性表示,这两个步骤要么都成功发生,要么一起失败,不能单独发生其中一个
一致性:A有1000元,B有1000元,不管A怎么转钱给B,最后A+B一定要是2000元
持久性:
表示事务结束后的数据不随着外界原因导致数据丢失
操作前A:800,B:200
操作后A:600,B:400
如果在操作前(事务还没有提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:800,B:200
如果在操作后(事务已经提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:600,B:400
隔离性:针对多个用户同时操作,主要是排除其他事务对本次事务的影响,
A有1000元,B有1000元,A向B转200元,这时C也向B转钱,当C向B转钱时,B还是1000元,不是1200元。
事务的隔离级别
事务隔离有时候会导致一些问题
脏读:
指一个事务读取了另外一个事务未提交的数据。
不可重复读:
在一个事务内读取表中的某一行数据,多次读取结果不同。(这个不一定是错误,只是某些场合不对)
虚读(幻读)
是指在一个事务内读取到了别的事务插入的数据,导致前后读取数量总量不一致。
10. 数据库三大范式
目前关系型数据库有6种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
而通常我们用的最多的就是第一范式(1NF)、第二范式(2NF)、第三范式(3NF),也就是本文要讲的“三大范式”。
第一范式(1NF):要求数据库表的每一列都是不可分割的原子数据项。
举例说明:

在上面的表中,“家庭信息”和“学校信息”列均不满足原子性的要求,故不满足第一范式,讲大白话就是有歧义,我们要保证每一列都不可再分。
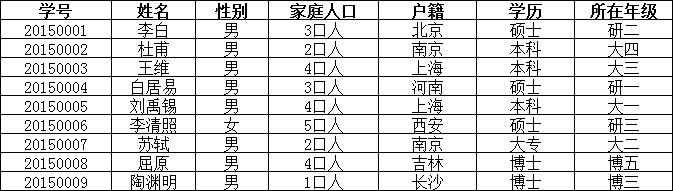
可见,调整后的每一列都是不可再分的,因此满足第一范式(1NF);
第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)
第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
举例说明:
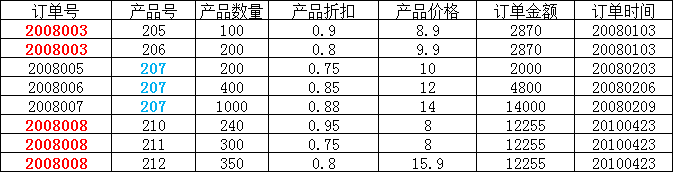
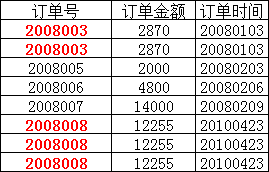
在上图所示的情况中,同一个订单中可能包含不同的产品,因此主键必须是“订单号”和“产品号”联合组成,
但可以发现,产品数量、产品折扣、产品价格与“订单号”和“产品号”都相关,但是订单金额和订单时间仅与“订单号”相关,与“产品号”无关,
这样就不满足第二范式的要求,调整如下,需分成两个表:

第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
举例说明:
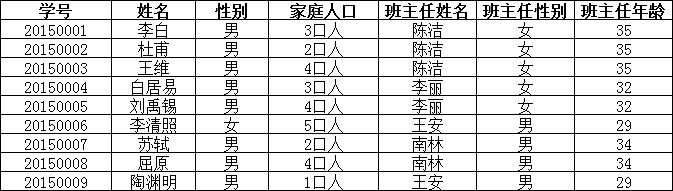
上表中,所有属性都完全依赖于学号,所以满足第二范式,但是“班主任性别”和“班主任年龄”直接依赖的是“班主任姓名”,
而不是主键“学号”,所以需做如下调整:
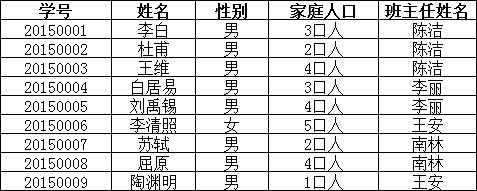
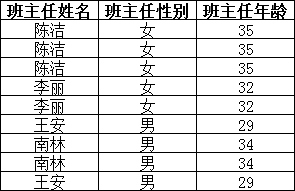
这样以来,就满足了第三范式的要求。
11. JDBC
JDBC(Java DataBase Connectivity)是Java和数据库之间的一个桥梁,是一个规范而不是一个实现,能够执行SQL语句。它由一组用Java语言编写的类和接口组成。各种不同类型的数据库都有相应的实现,本文中的代码都是针对MySQL数据库实现的。
使用JDBC时需要导入一个包。mysql-connector-java-5.0.8-bin.jar,具体的jar包需要看自己的Mysql版本来选择
JDBC连接步骤
//1.加载驱动
Class.forname("com.mysql.jdbc.Driver");
//2.填写用户信息
//useUnicode=true&characterEncoding=utf8&useSSL=true表示的意思是支持中文,设置字符集为utf8,使用安全的连接
String url="jdbc:mysql://localhost:3308/数据库名?useUnicode=true&characterEncoding=utf8&useSSL=true";
//这里的用户名和密码填自己数据的
String username="root";
String password="mysql";
//3.连接 Connection它从某种意义上可以代表数据库,如果它不为空,就代表你拿到数据库了
Connection connection = DriverManager.getConnection(url,username,password);
//4.执行SQL的对象
Statement statement = connection.createStatement( );
//5.用SQL对象去执行SQL
//这里需要注意下,查询用statement.executeQuery( ),修改,插入,删除都用statement.executeUpdate( )
//这里以查询aaa表为例,aaa表有3个字段id- int,name-varchar,ager-int
String sql="select * from aaa";
//返回一个结果集,结果集里面包含了我们查询的数据
ResultSet resultSet = statement.executeQuery(sql);
//输出
while(resultSet.next()){
System.out.println("id="+resultSet.getInt(id));
System.out.println("name="+resultSet.getString("name"));
System.out.println("ager="+resultSet.getInt(ager));
}
//6.关闭
//这步很重要,连完数据库必须要关闭
resultSet.close( );
statement.close( );
connection.close( );我们发现整个连接数据库的代码,基本上都是“死”的,我们只需要改变SQL语句,所以我们后面一般都写一个方法来封装,而用户信息一般都写进db.properties里面,而且我们一般不用statement而用preparedstatement,因为使用statement容易发生SQL注入。
12. SQL注入
Sql 注入攻击是通过将恶意的 Sql 查询或添加语句插入到应用的输入参数中,再在后台 Sql 服务器上解析执行进行的攻击,它目前黑客对数据库进行攻击的最常用手段之一。
关于SQL注入攻击详解可以看看下面这篇文章常见SQL注入的方法 - 四季列车 - 博客园
我个人对于SQL注入的理解就是拼接SQL语句,让它一直为真
13. PreparedStatement
上面我们讲了SQL注入,那怎么解决这个问题呢,就要用到PreparedStatement
我们先写一个工具类来实现JDBC
public class JDBCUtils{
public static String driver=null;
public static String url=null;
public static String username=null;
public static String password=null;
static{
try{
//读取db.properties,它存放了用户信息
InputStream in = JDBCUilts.class.getClassLoader().getResourceAsStream("db.properties");
Properties properties = new Properties();
properties.load(in);
//获取资源
driver = properties.getProperty("driver");
url = properties.getProperty("url");
username = properties.getProperty("username");
password = properties.getProperty("password");
//加载驱动
Class.forname(driver);
} catch(Exception e){
e.printStackTeace();
}
}
//获取连接
public static Connection getConnection() throws SQLException{
return DriverManager.getConnection(url.username,password);
}
//释放资源
public static void mydelete(Connection conn ,PreparedStatement pst ,ResultSet re) throw SQLException{
if(re!=null){
re.close();
}
if(pst!=null){
re.close();
}
if(conn!=null){
re.close();
}
}
}使用preparedStatement来实现插入
public static void main(String[] args) {
Connection conn = null;
PreparedStatement pst = null;
try {
conn = JDBCutils.getConnection();
//区别,使用问号占位符来代替参数
String sql="insert into aaa (id,myname,sex,myaddress) values(?,?,?,?)";
//预编译SQL
pst=conn.prepareStatement(sql);
//手动给参数赋值
pst.setInt(1,1014);
pst.setString(2,"杜浩");
pst.setString(3,"男");
pst.setString(4,"陕西");
//执行
int i = pst.executeUpdate();
if(i>0){
System.out.println("插入成功");
}
} catch (Exception e) {
e.printStackTrace();
}finally {
JDBCutils.closes(conn,pst,null);
}
}
通过比对Statement,我们发现preparedStatement不同的是对SQL语句的写法,pst.set里面的数字对应的是?的位置
14. 数据源
本文讲解的是DBCP
DBCP数据源的使用
就是连接池的一个包装好的框架,使用方便,以后若想创建一个连接池,只需要写好dbcpconfig.properties连接信息、DBCPUtil.java即可使用里面的静态方法得到conn以及执行sql语句。
dbcpconfig.properties(资源文件,用于数据库的连接以及连接池相关配置信息)
#连接设置
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3308/day16
username=root
password=....
#<!-- 初始化连接 -->
initialSize=10
#最大连接数量
maxActive=50
#<!-- 最大空闲连接 -->
maxIdle=20
#<!-- 最小空闲连接 -->
minIdle=5
#<!-- 超时等待时间以毫秒为单位 6000毫秒/1000等于60秒 -->
maxWait=60000
#JDBC驱动建立连接时附带的连接属性属性的格式必须为这样:[属性名=property;]
#注意:"user" 与 "password" 两个属性会被明确地传递,因此这里不需要包含他们。
connectionProperties=useUnicode=true;characterEncoding=utf8
#指定由连接池所创建的连接的自动提交(auto-commit)状态。
defaultAutoCommit=true
#driver default 指定由连接池所创建的连接的只读(read-only)状态。
#如果没有设置该值,则“setReadOnly”方法将不被调用。(某些驱动并不支持只读模式,如:Informix)
defaultReadOnly=
#driver default 指定由连接池所创建的连接的事务级别(TransactionIsolation)。
#可用值为下列之一:(详情可见javadoc。)NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE
defaultTransactionIsolation=REPEATABLE_READ
TestJDBC.java
package com.test;
import com.utils.DBCPUtil;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class TestJDBC {
public void test1(){
Connection conn = null;
PreparedStatement ps = null;
try {
conn = DBCPUtil.getConnection();
ps = conn.prepareStatement("...");
//...
}catch (SQLException e){
e.printStackTrace();
}finally {
DBCPUtil.release(conn,ps,null);
}
}
}
DBCPUtil.java (数据源DBCP)
package com.utils;
import org.apache.commons.dbcp.BasicDataSourceFactory;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class DBCPUtil {
private static DataSource ds = null;
static{
try {
Properties prop = new Properties();
prop.load(DBCPUtil.class.getClassLoader().getResourceAsStream("dbcpconfig.properties"));//根据当前这个类的classes的路径加载配置文件
ds = BasicDataSourceFactory.createDataSource(prop);//得到一个数据源
}catch (Exception e){
throw new ExceptionInInitializerError("初始化错误,请检查配置文件");
}
}
public static Connection getConnection(){
try {
return ds.getConnection();
}catch (SQLException e){
throw new RuntimeException("服务器忙。。。");
}
}
public static void release(Connection conn ,Statement stmt, ResultSet rs){
if(rs!=null){
try{
rs.close();
}catch (Exception e){
e.printStackTrace();
}
}
if(stmt!=null){
try{
stmt.close();
}catch (Exception e){
e.printStackTrace();
}
}
if(conn!=null){
try{
conn.close();//模式已经放回去了
}catch (Exception e){
e.printStackTrace();
}
}
}
}














 1338
1338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









