







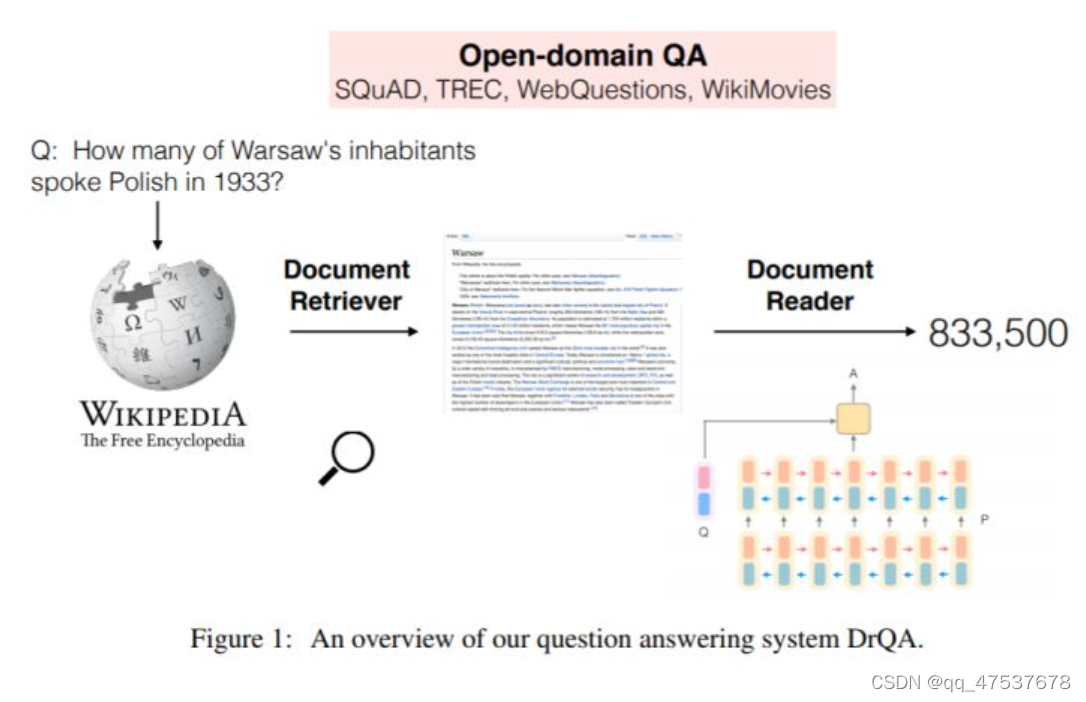
开放领域问答的一个重要方法:检索器 + 阅读器模型。其中,检索器负责从海量文档中检索相关段落。
本文主要介绍关于检索器的内容
Open-domain 的 Question Answering (QA) 一般需要先从大量的文档库中检索出一些和问题相关的文档(retrive),相关的方法有 TF-IDF 和 BM25。
系列文章目录
(一)问答系统的文段检索
(二)lucene全文检索底层原理理解
(三)Lucene查询的底层实现IndexSearch(上)
(四)Lucene查询的底层实现IndexSearch(下)
前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
目前主流的 retriever 使用传统的信息检索(IR)方法,包括 TF-IDF unigram/bigram matching 或词权重支持 BM25 词权重的工具,如 Lucene 和 Elastic-search
TF-IDF 和 BM25
TF-IDF 和 BM25 将 query 和 context 用高维的 sparse 向量来表示,这些sparse向量可以通过倒排索引进行有效搜索,并且对于那些通常需要根据关键字显著缩小搜索空间的问题回答有效。
存在的不足之处:TF-IDF 和 BM25 也有一些缺点就是无法很好的建模词与词之间的语义关系(两个同义词可能长的完全不一样),所以一些 encoding 文本为 dense 向量的方法给 TF-IDF 和 BM25 这一类方法做了补充。
实现的目标效果
- 对于给定的问题能够返回相关的文章段落
- 通过修改lucene源码,实现结合之前提出的问题上下文进行优化
段落检索
- 段落检索
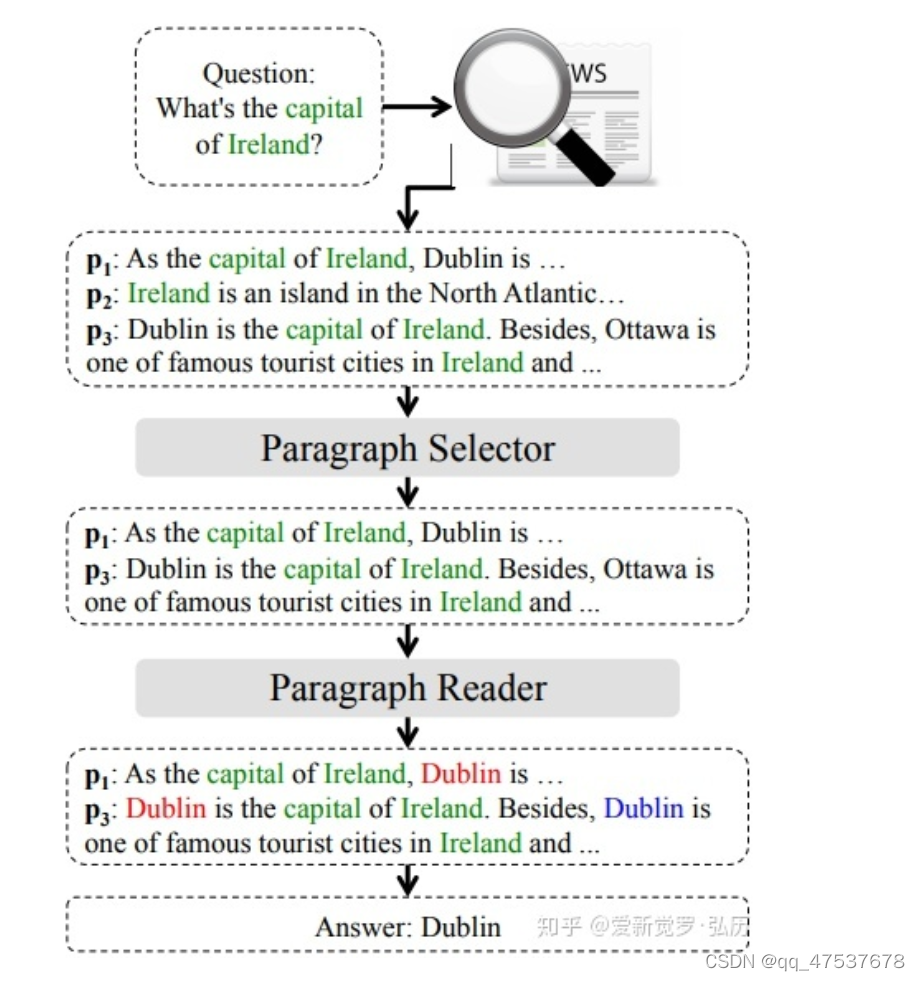
段落检索(passage retrieval)任务旨在从一个庞大的文本段落库中,检索出和查询相关的段落。近年来,稠密段落检索已经成为了段落检索中的一种重要方法,它的核心思想是把文本查询(query)和文本段落(passage)分别编码成为低维的向量,通过计算向量相似度的方法,来估计query和passage间的相关性。 - 段落精排
段落精排(passage re-ranking)是段落检索的后续任务,通常通过对第一阶段的段落检索结果进行重排序,通过对query和passage进行更深层次的交互,来提高最终的检索效果。本文我们主要关注基于预训练语言模型的稠密段落检索以及段落精排。
当前思路
- 思路一:因与要融入历史,但又更为关注当前的query,故考虑进行加权设计。
- 思路二:目标仍为回答当前问题,应检索出与当前问题更相关的结果,故将之前的问题当作背景进行优化。
具体实现
- 文段分割
给出一个文本(或者一本书)先对其进行文段分割 - 创建索引
对分割好的段落通过lucene创建索引 - 优化lucene的查询排序方法
当前问题
- 需要找到合适的结合上下文的查询优化算法
- 在进行分词时的添加进去的扩展词表和停用词表如何能够更加贴近当前的文本,优化分词效果
预期效果

















 2323
2323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









