







抓取网上的职位招聘信息
https://search.51job.com/list/000000,000000,0000,00,9,99,%2B,2,1.html
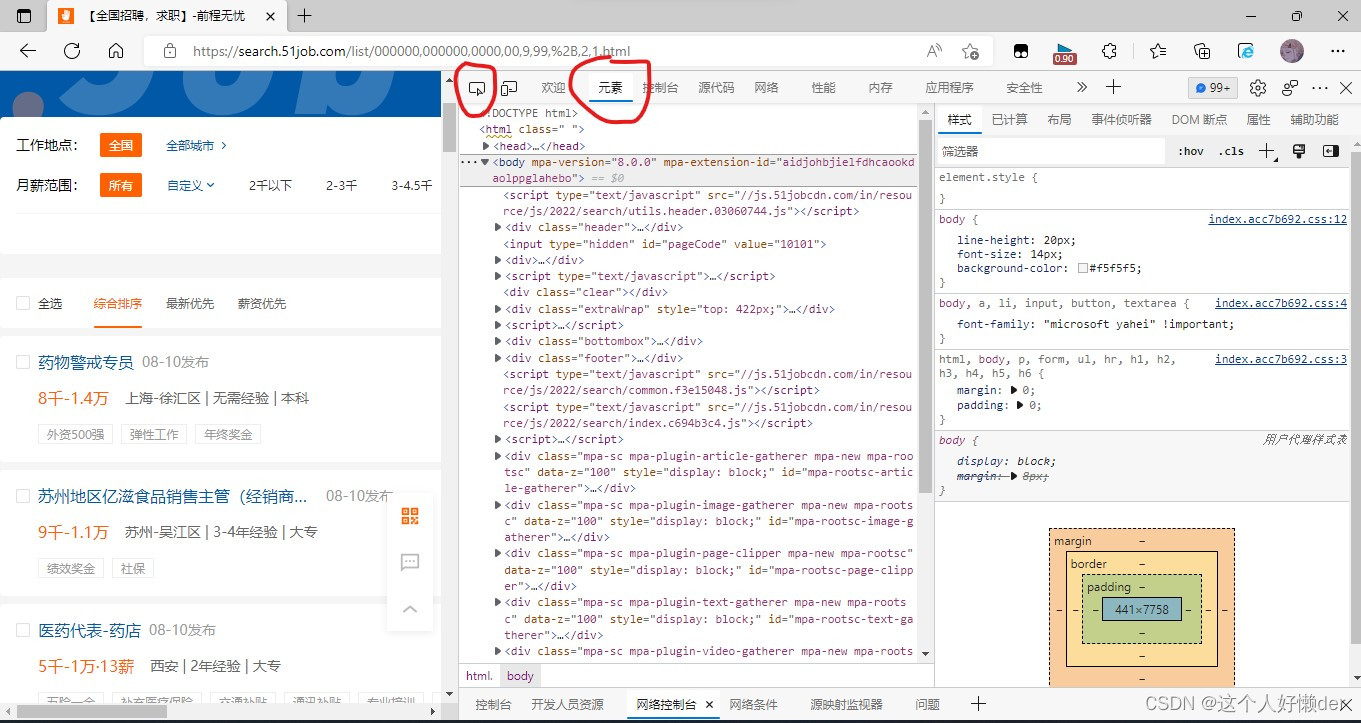
打开界面以后ctrl+shift+i,点击元素,再点击旁边圈起来的那个箭头,可以点击页面相应的部分查看代码,这样就可以看出放在了哪个部分里。
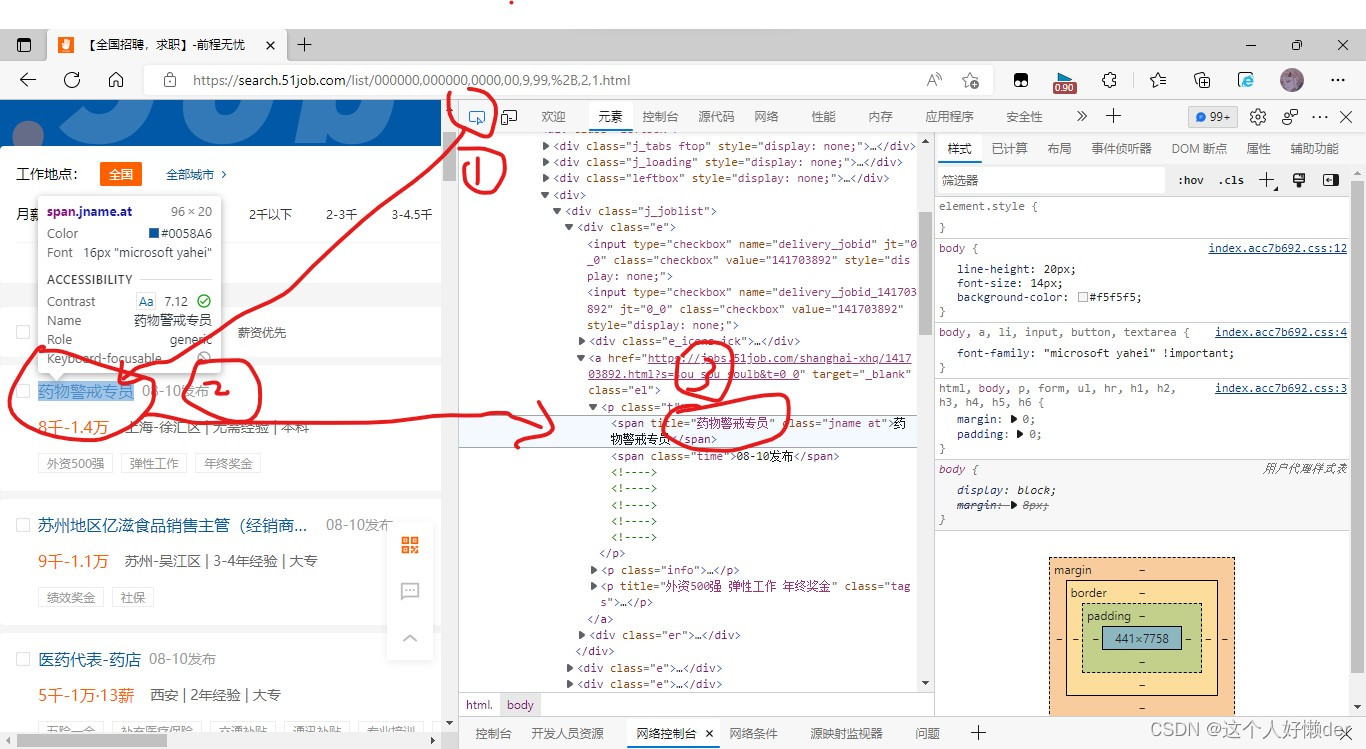
但是这是网页代码,并不是网络响应给我们的代码,应该如下图打开网络---搜索---找到关键字所在页面---ctrl+f查找,就能在这个页面查找到网络实际给我们的响应,对比网页代码,两个是不一样的,使用爬虫抓取的时候其实抓取的是响应中的内容。
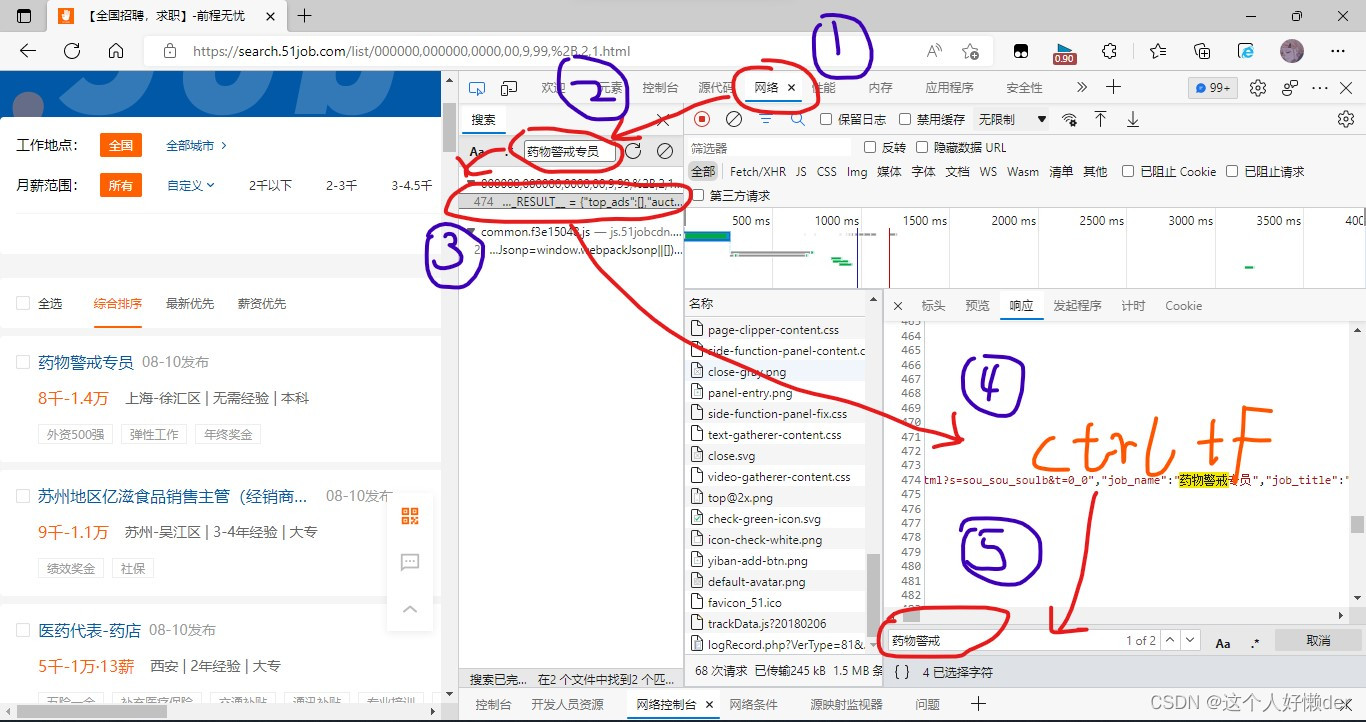
使用pycharm实现一下获取响应内容并进行格式转换:
import requests #requests请求
from lxml import etree #XPath提取
import re
url="https://search.51job.com/list/000000,000000,0000,00,9,99,%2B,2,1.html" #爬取目标
rest=requests.get(url) #获取网页信息
rest.encoding="gbk" #进行编码防止乱码
root=etree.HTML(rest.text) #将获取的文本进行转换,方便使用XPath获取节点
work=root.xpath('//.') #查找到有目标信息的节点
work=str(work) #转换为字符串
print(work)上面代码首先获取了网络响应,并将文本使用了etree.HTML转换成Element对象,使用XPath方法显示所有内容,点击下面这个结果界面,ctrl+f也可以搜索想要的文字,这里搜索job_name。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1963
1963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









