






#最近在学习利用深度学习进行高光谱分类,下载了几个常用的高光谱公开数据集后,发现其是mat文件,可以用matlab打开,但在python中不能直接使用。
在python中加载mat文件需要使用scipy.io.loadmat()函数
参考前人的代码:
from scipy.io import loadmat
input_image = loadmat('D:\pycharmProj\HSIclassify\Pines\Indian_pines.mat')['indian_pines']
output_image = loadmat('D:\pycharmProj\HSIclassify\Pines\Indian_pines_gt.mat')['indian_pines_gt']
但运行之后程序报错:

上CSDN查找解决方案,他提出在使用loadmat函数的地方Debug,并且在Debugger处敲入X.keys(),X就是你给loadmat函数读取的mat文件赋予的变量名,该博主演示如下:
但这种方法对我的代码似乎并不适用:

还有其他人说方括号里的字母都要小写,这显然是没道理的,因为我还是报错。
经过我的不断试错,终于解决了这个问题。因为loadmat函数读取出来的高光谱数据是dict格式的所以需要定位才能进行后续操作,定位通常是通过列名,所以找到正确的列名,并修改源代码,问题就能解决。可以直接在matlab中打开mat文件查看列名,或者利用python代码查看列名:
input_image = loadmat('D:\pycharmProj\HSIclassify\Pines\Indian_pines.mat')
print(input_image.keys())
output_image = loadmat('D:\pycharmProj\HSIclassify\Pines\Indian_pines_gt.mat')
print(output_image.keys())运行结果:

可以看到列名是'indian_pines_corrected'和‘indian_pines_gt',所以正确的代码应该是:
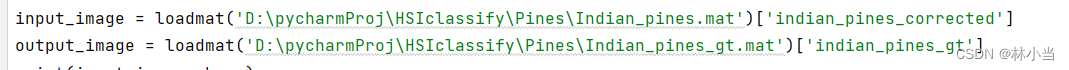
再运行就不会报错啦!
写这个博客的目的是帮助像我一样的高光谱图像处理小白,大家共勉;也欢迎此邻域的大牛们莅临指导。
感谢您的阅读。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









