







 后台程序,同步的采集组件. 启动后会向manager注册,会处理manager分配过来的增量采集任务,组织源数据库的数据插入kafka,并定期向manager发送心跳汇报任务处理情况,web程序,同步的管理组件。实际上任务并不是同步的最小单位,任务下还包含若干任务源和任务目的,任务源到任务目的才是最小单位,任务是一组类似的任务源到一组类似的任务目的的组合。任务的组合,一般情况下一个mysql数据库实例下的所有源表到一个postgresql数据库实例下的所有目标表任务都可以打包成一个任务组。
后台程序,同步的采集组件. 启动后会向manager注册,会处理manager分配过来的增量采集任务,组织源数据库的数据插入kafka,并定期向manager发送心跳汇报任务处理情况,web程序,同步的管理组件。实际上任务并不是同步的最小单位,任务下还包含若干任务源和任务目的,任务源到任务目的才是最小单位,任务是一组类似的任务源到一组类似的任务目的的组合。任务的组合,一般情况下一个mysql数据库实例下的所有源表到一个postgresql数据库实例下的所有目标表任务都可以打包成一个任务组。
1.架构图
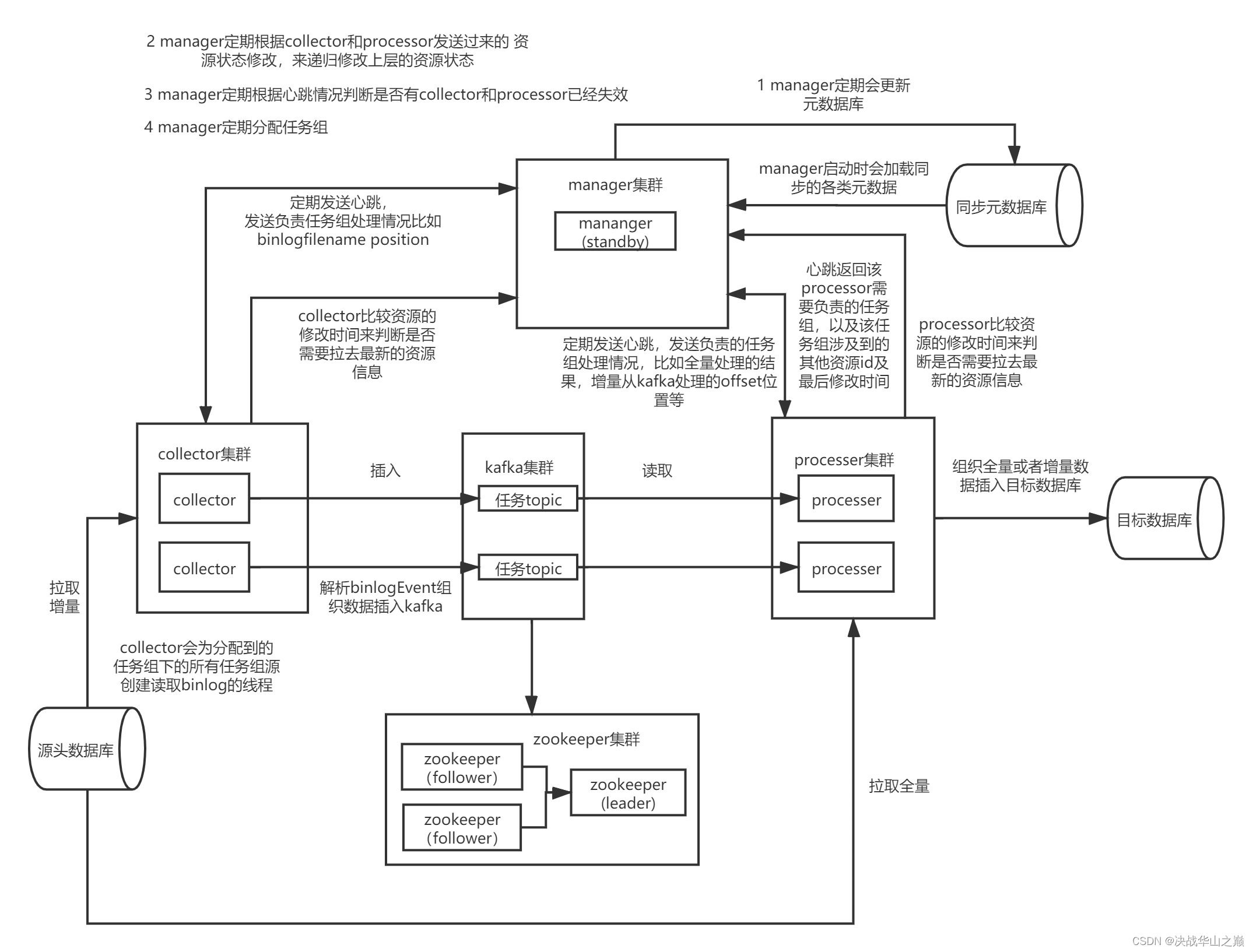
2. 组件描述
1) manager
web程序,同步的管理组件。用户通过manager增删改查同步任务,通过manager查看同步状态。manager是collector和processor的管理者,
会向collector和processor分配任务。
2) collector
后台程序,同步的采集组件. 启动后会向manager注册,会处理manager分配过来的增量采集任务,组织源数据库的数据插入kafka,并定期向manager发送心跳汇报任务处理情况,
也实时等待manager分配过来的新任务。
3) processor
后台程序,同步处理组件。启动后会向manager注册,会处理manager分配过来的全量采集和增量处理任务,从源数据库或者kafka中获取数据并处理插入目标数据库,并定期向
manager发送心跳汇报任务处理情况,也实时等待manager分配过来的新任务。
4) kafka集群
kafka起到了collector和processor之间的异步限流缓冲作用.
5) zookeeper集群
kafka集群的注册中心,未来manager ha依赖zookeeper,第一期zookeeper作用有限。
3. 概念描述
1) 同步
同步就是把源表的数据,分毫不差的插入到目标表。同步时除了需要同步数据,如果目标表不存在要负责创建表和更新原表的字段变化。
2)全量同步和增量同步
全量同步是一次性把原表的数据全部插入到目标表,增量同步是随着源表数据的变化不断的把变化更新到目标表。
3)数据库实例
源表和目标表都会从属于一个数据库,数据库又从属于数据库实例。一期的同步,只支持从Mysql数据库实例同步到postgresql(gp)数据库实例。
4)任务
从源表到目的表一条描述完成的同步任务以后简称任务。
实际上任务并不是同步的最小单位,任务下还包含若干任务源和任务目的,任务源到任务目的才是最小单位,任务是一组类似的任务源到一组类似的任务目的的组合。
比如想同步a_account表,但a_account表做过分表,a_account_1,a_account_2等,目的端有多个,比如gp1,gp2两个集群都需要a_account数据,那么完全可以创建一个
任务,任务下创建两个任务源两个任务目的,这样可以共用一个kafka topic.
5) 任务组
任务的组合,一般情况下一个mysql数据库实例下的所有源表到一个postgresql数据库实例下的所有目标表任务都可以打包成一个任务组。
任务组可以统一增量采集、统一暂停、统一启动,方便管理。
6) 任务组源
任务组和源数据库实例的组合就是任务组源,一个任务组下可以包含多个任务组源。
7) 任务组目的
任务组和目的数据库实例的组合就是任务组目的,一个任务组下可以包含多个任务组目的。
8) 任务源
任务源描述的是具体的源表信息,全量采集时会记录该表全量的位置。
9)任务目的
任务目的描述的是具体的目的表信息,增量处理时会记录该目的处理kafka topic的位置(offset).
10)kafka集群
collector增量采集的数据会按照任务分别插到对应的kafka topic里,processor会根据任务目的分别从topic读取数据处理。
4. 表设计
同步需要的最多资源的元数据表。
1)数据库实例表
| 英文名 |
中文名 |
类型 |
描述 |
| id |
id |
Long |
唯一标识 |
| sourceType |
数据源类型 |
String |
现在只支持mysql和gp |
| ip |
ip |
String |
数据源ip |
| port |
port |
String |
|
| userName |
用户名 |
String |
用户名 |
| password |
密码 |
String |
密码 |
| updateTime |
最后修改时间 |
Long |
最后修改时间 |
| delFlag |
是否删除 |
Integer |
0未删除 1已删除 |
2)kafka集群表
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1161
1161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









