




注:Adbul Bari算法视频
完美二叉树、完全二叉树
完美二叉树(满二叉树):所有层都填满,节点数最大。深度为h,节点有20+21+……+2h= 2(h+1)-1个。如下图节点数=2(3+1)-1=15个
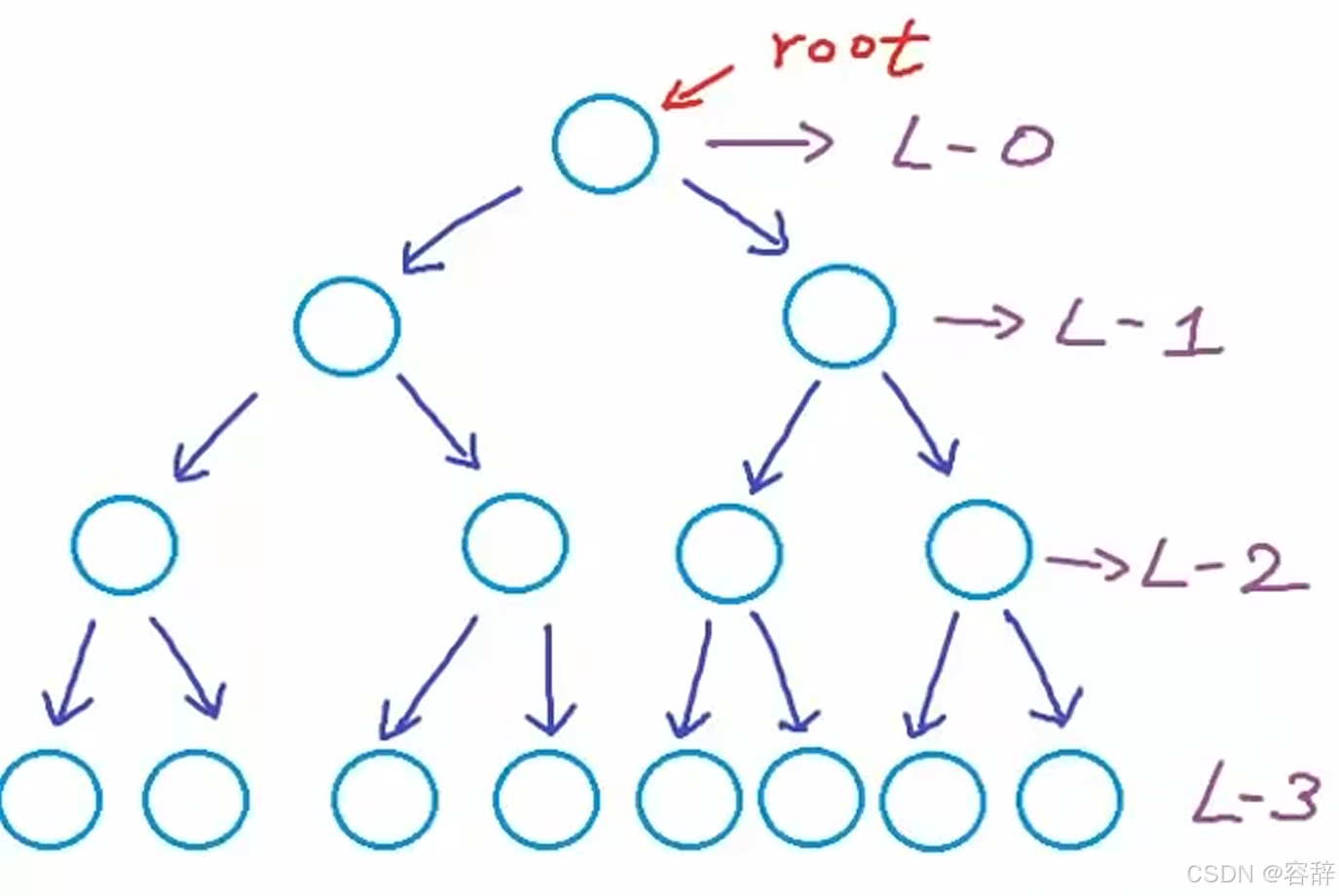
完全二叉树:除了最后一层,其余层都填满,最后一层要靠左。
- 下图数组的表示,前两个为完全,最后一个非完全,因为左边缺失元素了。
- 完美二叉树也是一种完全二叉树。
- 一般时间复杂度正比于树高。完全二叉树树高[logn] 向下取整。完全二叉树树高最小[logn],树高最大n。
使用数组表示完全二叉树遵循下面的规律,当前节点i:
- 左节点为 2i+1
- 右节点为 2i+2
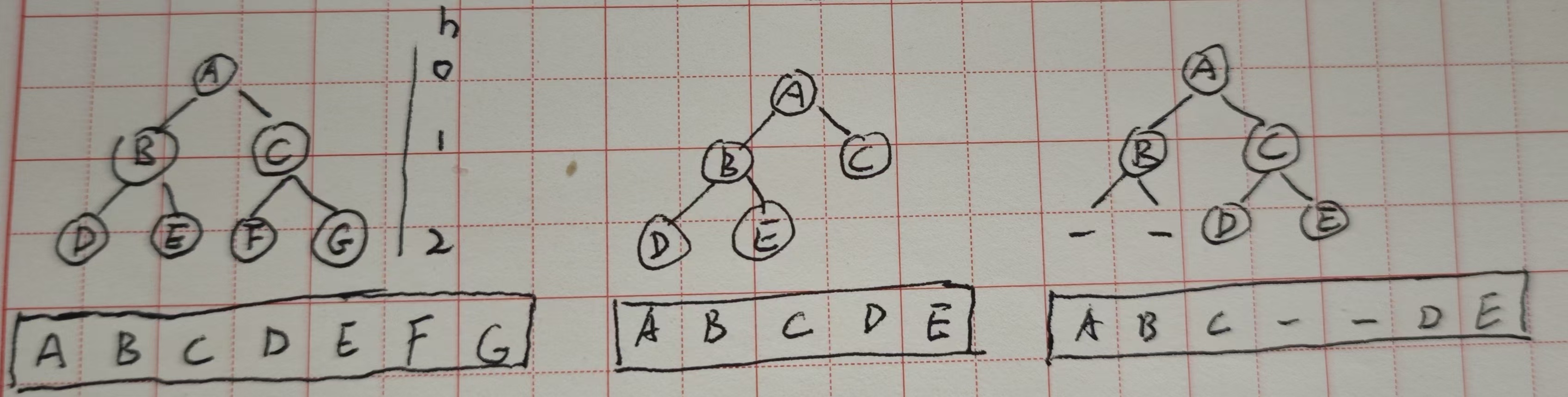
(高度深度是0,还是1开始,只是一个表示不重要,但一般用0。0算的是路径数,1算的是经过节点数)
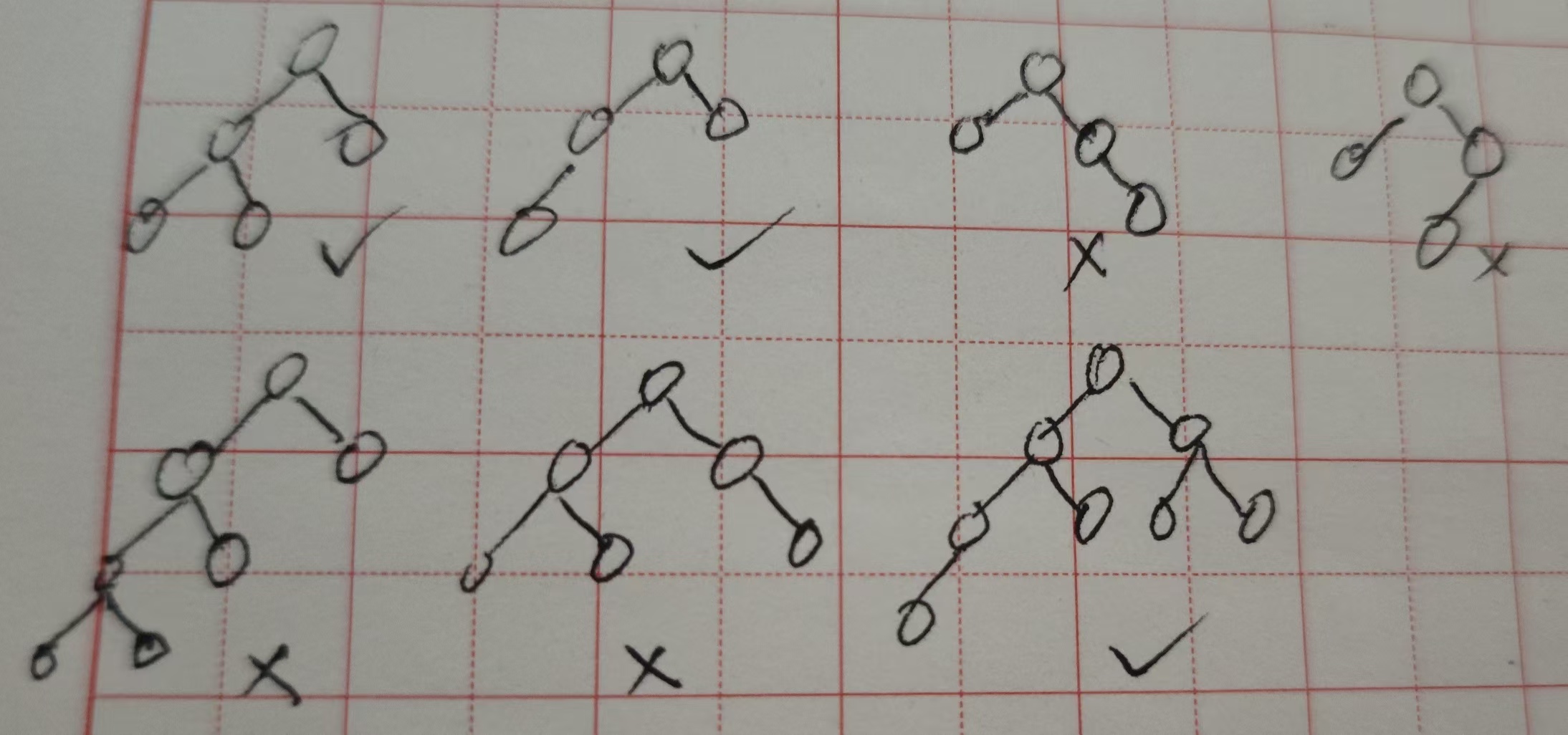
判断是不是完全二叉树:
堆
堆是完全二叉树!!
最大堆:父节点要大于或等于后面所有子节点。
最小堆:父节点要小于或等于后面所有子节点。
最大堆的插入、删除
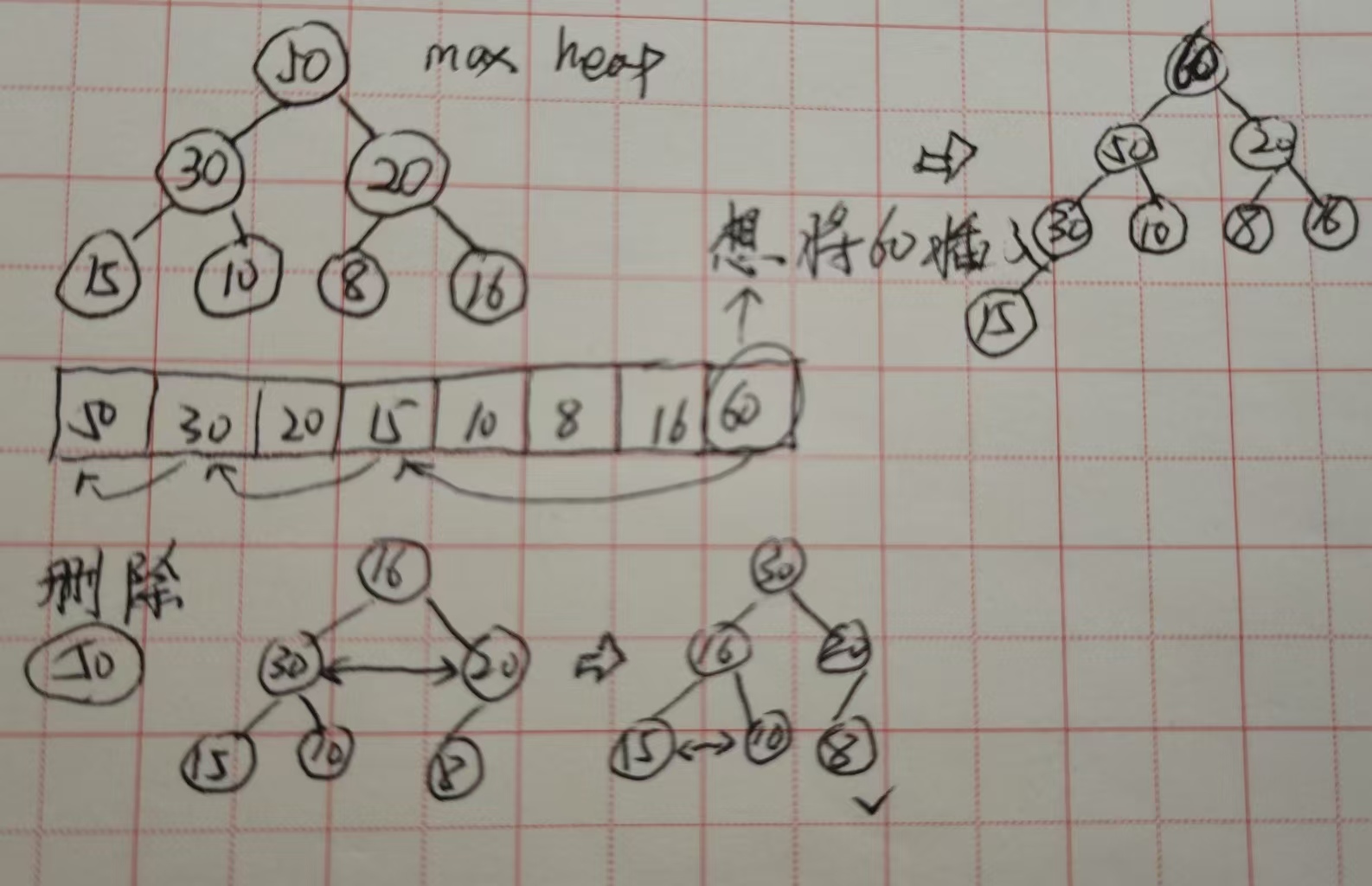
最大堆的插入:
- 60首先插入最后的叶子节点,与父节点比较,比父节点大则交换位置,直到到达正确的位置。
- 时间复杂度就是交换的次数:例子是3次即树深logn。堆插入的时间复杂度O(1)~O(logn)。
最大堆的删除:
- 假如去水果店买苹果,苹果像金字塔一样排列,最好的苹果在金字塔的尖上。那我们最大堆的最大元素在根节点,只能移除根节点即50。移除根元素后不能随意的让30往上顶,这样就不满足完全二叉树。
- 正确做法:将最后的叶子节点挪到根节点,然后子节点相互比较,最大值与父节点比较并交换,直到满足最大堆的条件。堆删除时间复杂度O(logn)。
- 若删除中间元素,首先要遍历找到要删除的元素(n),跟末尾元素交换并删除,后再调整log(n)。由于二叉堆无顺,查找要消耗O(n),一般不推荐使用二叉堆进行查找。
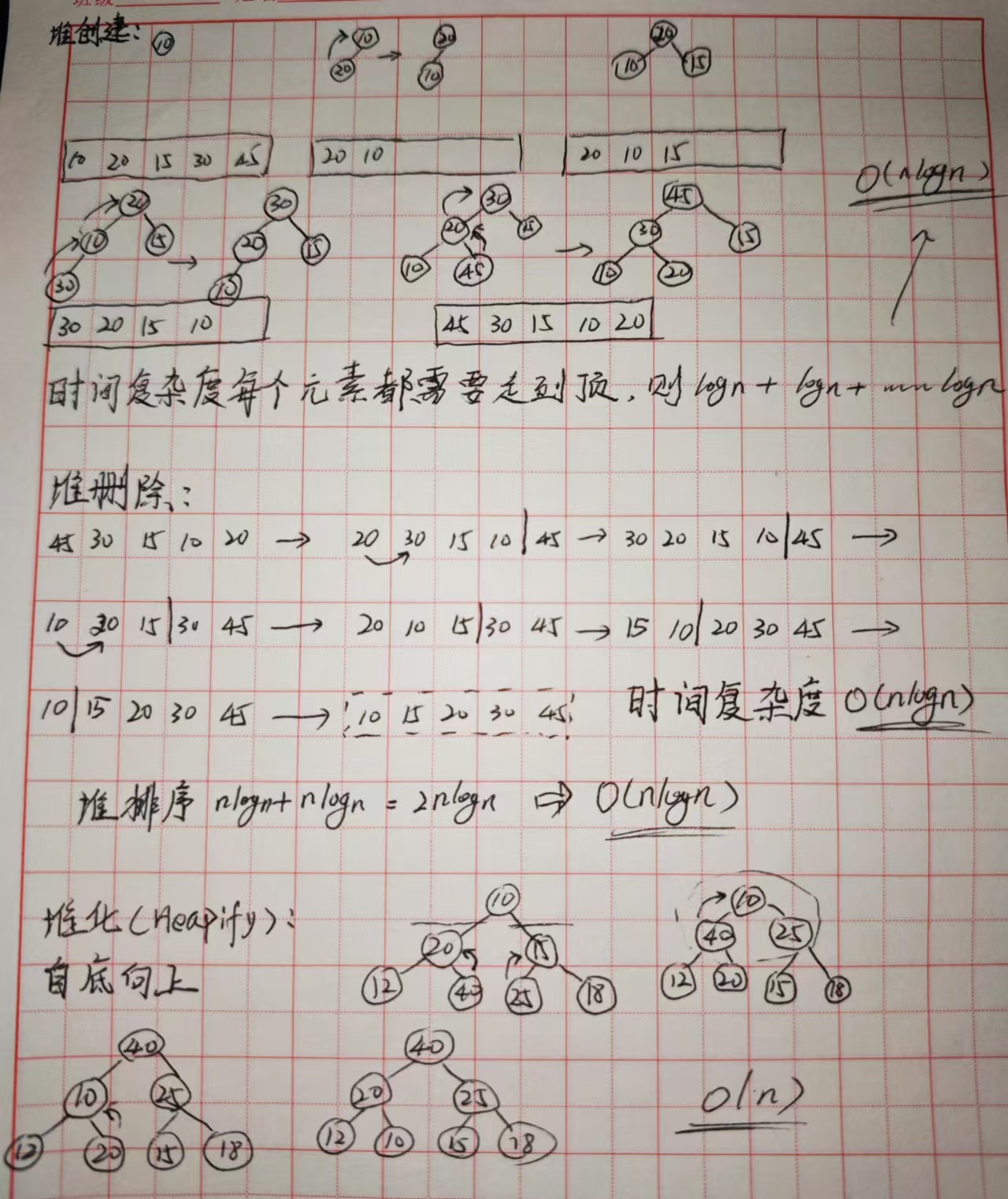
堆创建、堆排序
由上堆删除可知:删除所有元素,并将元素放到删除后的空闲位置,就会发现数组已排序。
堆排序的时间复杂度是O(nlogn)、O(n)
优先级队列
数字本身就有优先级:
- 数字大的优先级更高,那就使用最大堆进行分析
- 数字小的优先级更高,那就使用最小堆进行分析(删除和插入)
这将是最好的数据结构,否则需要的可能是O(n),而现在是O(logn)。
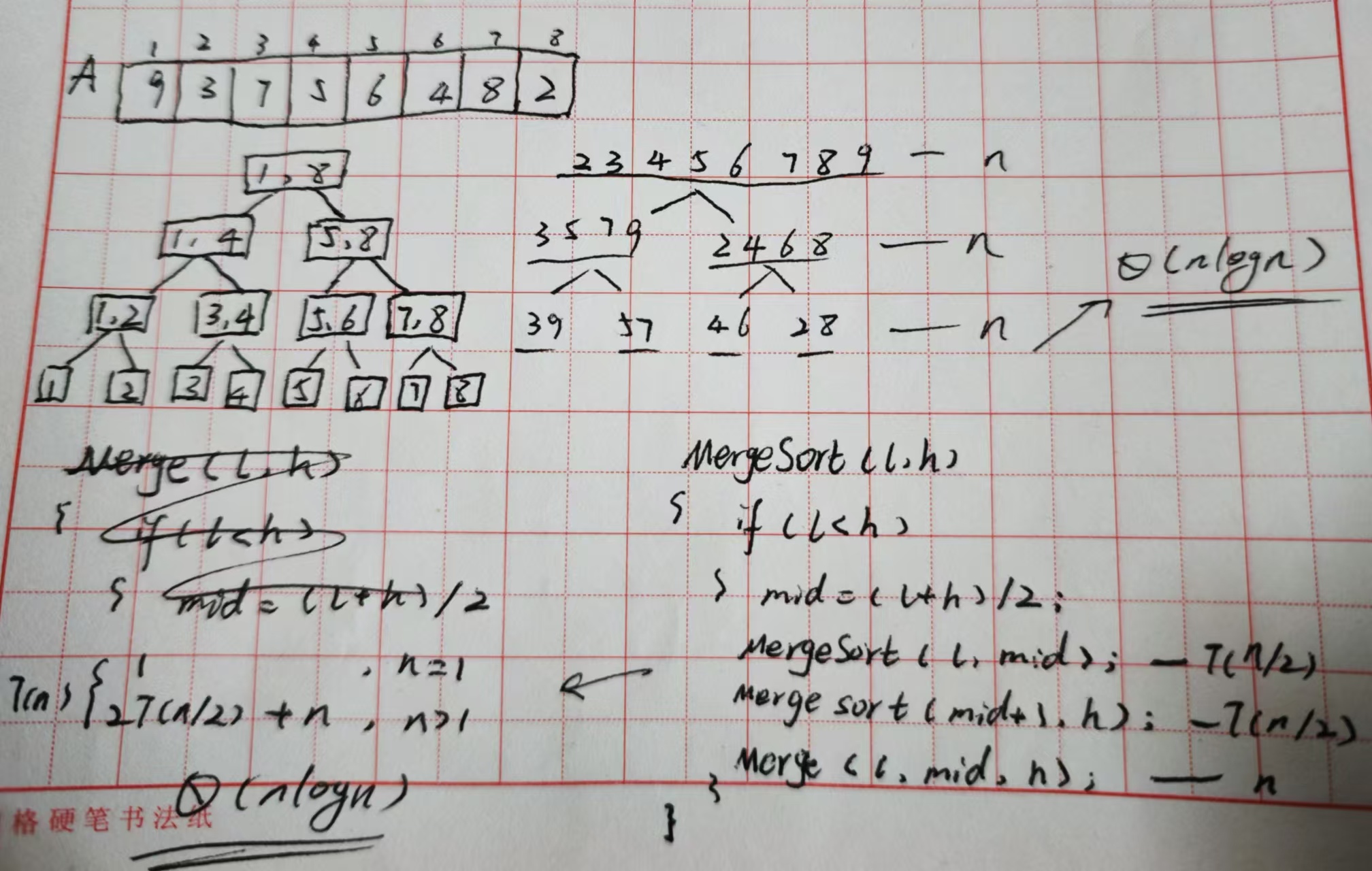
归并排序
合并:两个及以上有序列表合并成一个有序列表的过程。
2-way merge sort
1.例子:有两个有序列表A,B,合成列表C

merge(A,B,m,n){
i=1;j=1;k=1;
while(i<=n && j<=m){
if(A[i]<=B[j]){
C[k]=A[i];
k++;i++;
}else{
C[k]=B[j];
k++;j++;
}
}
for(;j<=m;j++){
C[k]=B[j];
k++;
}
}
时间复杂度O(m+n)
2.M路合并:多个列表合并。采取的就是两两合并(2-way merge sort),可以任意两个如下:
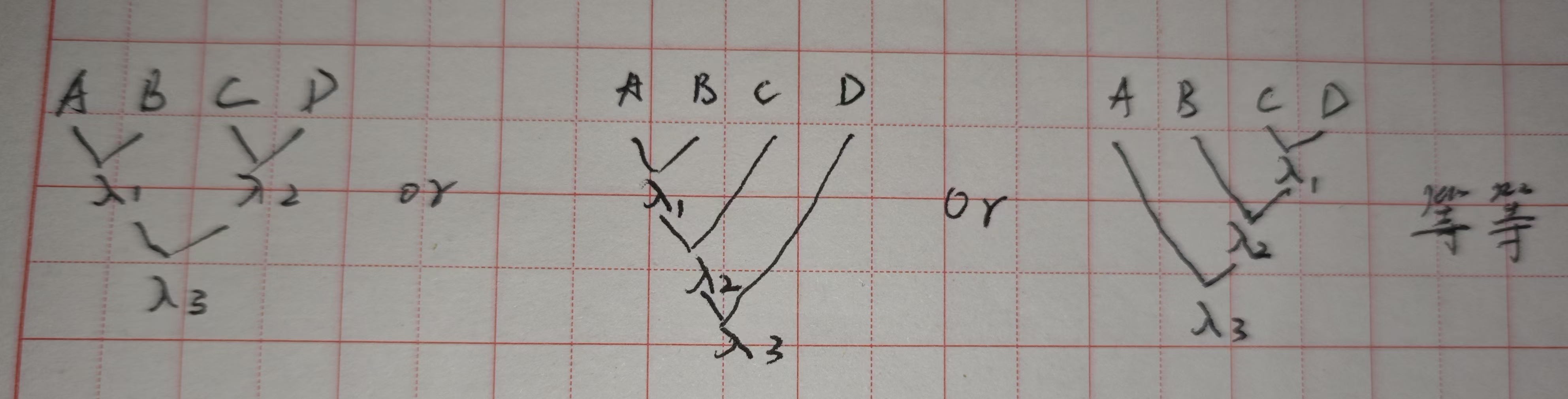

merge sort
分而治之思想,先拆分后合并
优缺点
优点:
-
适合大列表
-
适合链表(可以在不创建新链表的情况下进行排序)
-
外部排序(每次带入一部分元素块进入主内存,主内存就不需要那么大空间)
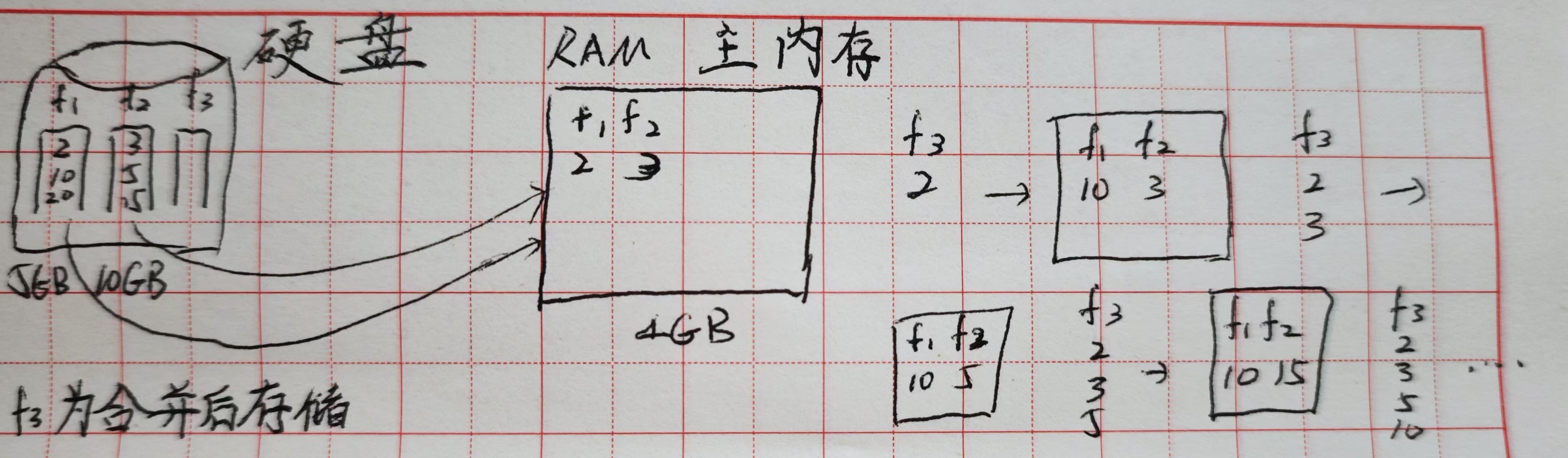
-
稳定(同样的数字保持原来的顺序)
缺点:
- 数组进行排序,需要额外的空间
- 不适合小问题(元素很少,不需要拆分,那么会在递归上浪费时间。借用插入排序来得到结果)
- 递归(会使用内存的堆栈,需要的堆栈空间=树高logn,再加上第一点的额外空间O(n+logn)渐进O(n))
实例编写
快速排序
基础逻辑
遵循分而治之。
分区位置:某一元素左边的元素都比他小,右边都比他大,那么他就处于排序位置。
分区算法:找到分区位置,i是直到找到比核心更大的,j是直到找到比核心更小的,交换位置。过程如下:

//分区算法
partition(l,h){
pivot=A[l];
i=l;j=h;
while(i<j){
while(A[i]>pivot && i<j){
j--;
}
while(A[i]<=pivot && i<j){
i++;
}
swap(A[i],A[j]);
}
swap(A[l],A[j]);
return j;
}
//快速排序
QuickSort(l,h){
if(l<h){
j=partition(l,h);
QuickSort(l,j-1);
QuickSort(j+1,h);
}
}
实例编写
题目:给你两个按非递减顺序排列的整数数组 nums1和nums2, m和n分别表示 nums1 和 nums2 中的元素数目。
合并 nums2 到 nums1 中,使合并后的数组同样按非递减顺序排列。
(这道题有很多解法,不妨用快排练练手)
import java.util.Arrays;
public class test{
public int[] merge(int[] nums1, int m, int[] nums2, int n) {
for(int i =0 ;i<n;i++){
nums1[m+i] = nums2[i];
}
quickSort(nums1,0,n+m-1);
return nums1;
}
public void quickSort(int[] nums1,int l,int h){
if(l<h){
int j = partition(nums1,l,h);
quickSort(nums1,l,j-1);
quickSort(nums1,j+1,h);
}
}
public int partition(int[] nums1,int l,int h){
int pivot = nums1[l];
int i = l;
int j = h;
while(i<j){
while(nums1[j]>pivot && i<j){
j--;
}
while(nums1[i]<=pivot && i<j){
i++;
}
int temp = nums1[i];
nums1[i] = nums1[j];
nums1[j] = temp;
}
nums1[l]=nums1[j];
nums1[j]=pivot;
return j;
}
public static void main(String[] args) {
int[] nums1 = {1,2,3,0,0,0};
int[] nums2 = {2,5,6};
test test = new test();
int[] merge = test.merge(nums1, 3, nums2, 3);
System.out.println(Arrays.toString(merge));
}
}
分析时间复杂度
best case-----O(nlogn) 分区后j一直取中间(这种情况很难遇见)
worst case—O(n2)
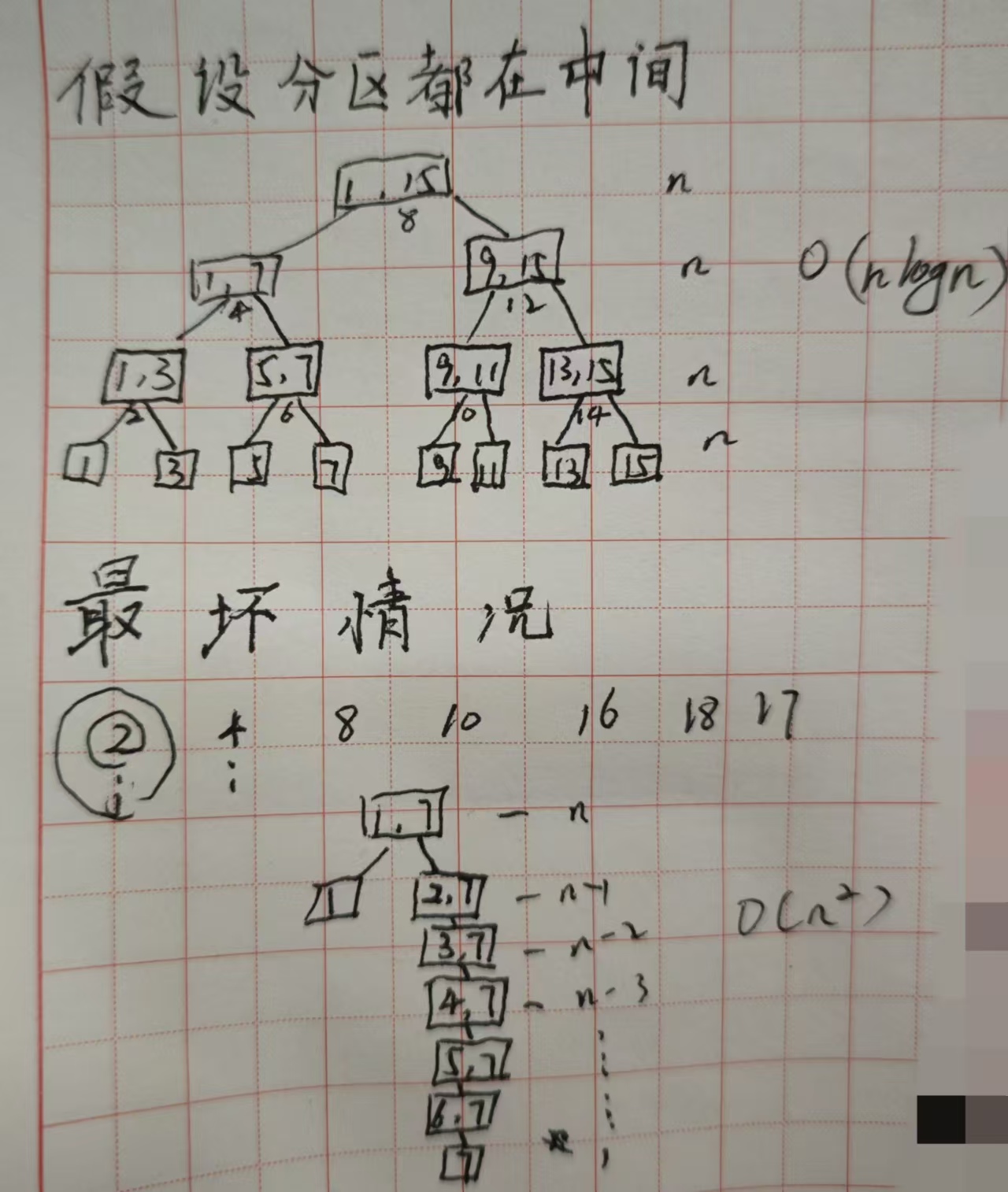
为了避免最坏情况可以一直选择中间作为核心元素,或随机选择核心元素
快速排序用了递归,占用堆栈空间logn 到 n(树高)
矩阵乘法
1.使用简单方法,三个循环,O(n3)
2.采用分而治之,最小单位就是小于等于2x2的矩阵,直接就用公式不用循环,公式的话是4行,可以说时间常数就是O(4)。
3.不满足的矩阵可以补0成为4x4,8x8等等的矩阵,然后采取分而治之。
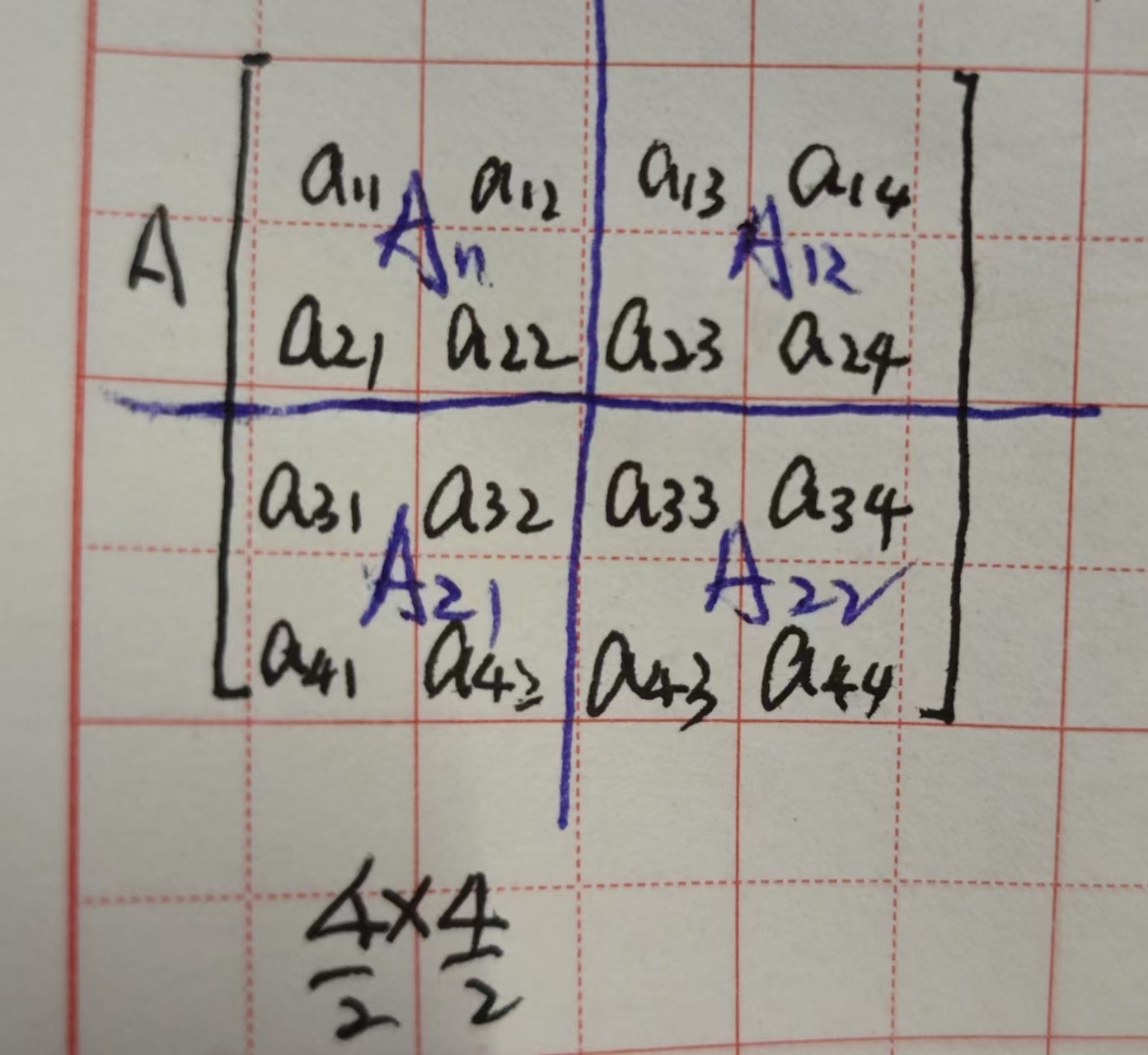
mm(A,B,n){
if(n<=2){
c=4 formulas;
}esle{
//拆分再合并
mid=n/2;
mm(A11,B11,mid)+mm(A12,B21,mid);
mm(A11,B12,mid)+mm(A12,B22,mid);
mm(A21,B11,mid)+mm(A22,B21,mid);
mm(A21,B12,mid)+mm(A22,B22,mid);
}
}
分治算法的矩阵乘法也是O(n3),采用了递归还会额外占用堆栈
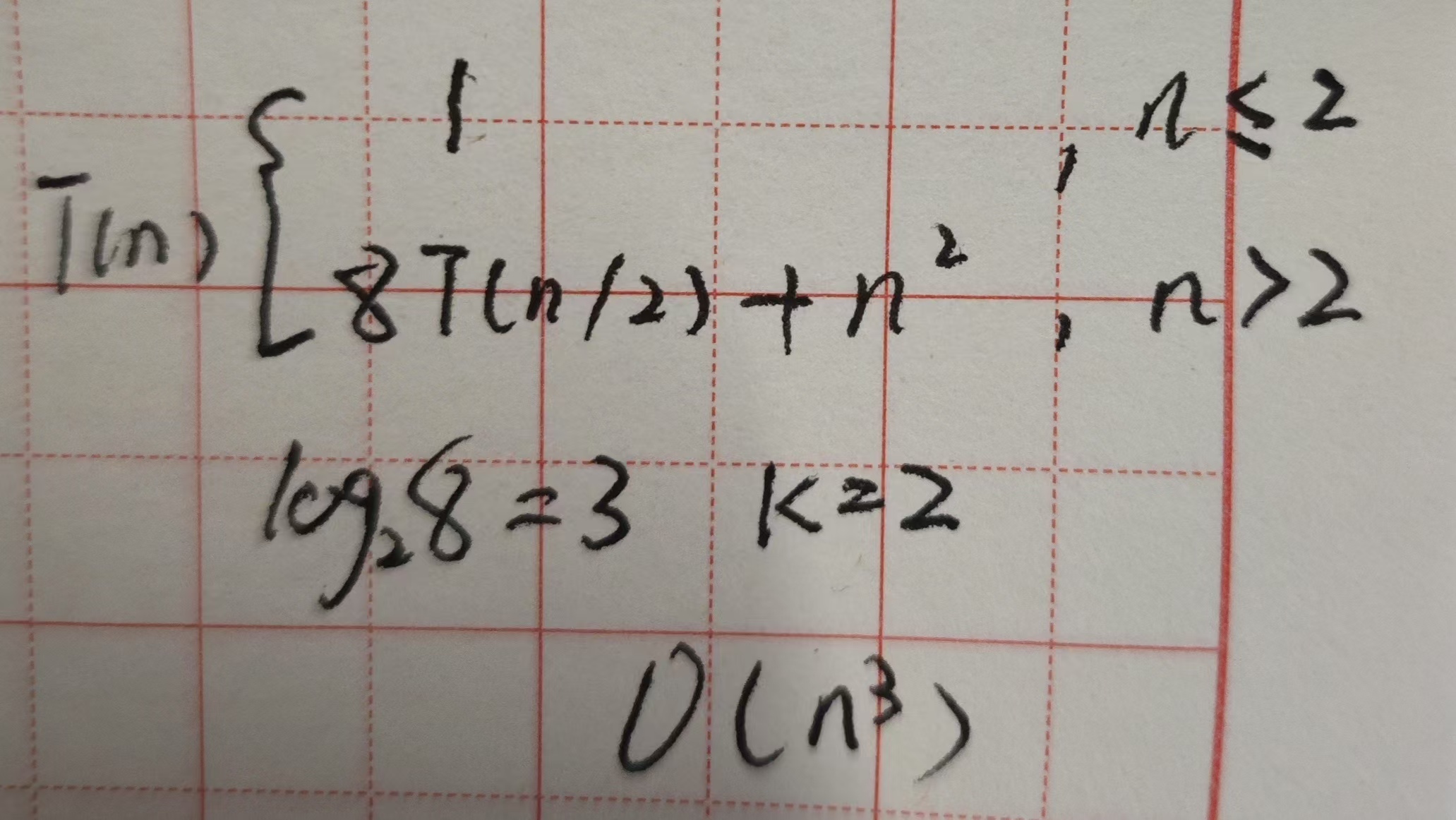


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









