







1,JDK 、 JRE、jvm 有什么 区别
JDK 是Java的 开发环境和运行环境,负责编译运行java程序。
JRE 是Java的 运行环境,
JVM是Java的虚拟机负责运行java字节码文件
JDK 包含 JRE,JRE包含JVM
其实JDK包含JRE ,如果你只要运行Java.class文件 ,只需要安装 JRE即可,但如果要 开发Java程序 ,就需要 安装JDK了。
什么是字节码
编译器将 .java文件编译成字节码文件 .class,可以做到一次编译处处执行
2、== 和 equals 有什么区别
- ==
基本数据类型: 比较的值 是否 相等;
引用数据类型:比较的 引用 是否相等; - equals
一般情况下比较的是值是否相等。
3、两个对象的 hashCode相同,则 equals 一定为 true 吗?
不一定,两个对象的 hashCode相同,则 equals不 一定为 true;
因为 hashCode 相同只是代表 hash值相同,然而 hash值相同,并不代表 得出的键值对 相等。
4、final 的作用是什么?
- final 标识的类是最终类,不能被继承
- final 标识的方法 是 最终方法,不能被重写
- final 标识的变量叫常量,值不能被修改;
5、八大基本数据类型
boolean:一个字节
byte :一个字节,8位
char:两个字节,
short:两个字节。16位
int:四个字节:32位
long:八个字节:64位
float:四个字节,32位
double:八个字节,64位
String 是 对象
6、java 中操作字符串都有哪些类?它们之间有什么区别?
操作字符串的有 String,StringBuffer,StringBuilder.
- String : String 声明的是不可变的对象,对其操作都会产生新的对象,然后指针指向新的对象。
- StringBuffer: 声明的是可变对象,可以对值进行修改,但不会产生新的对象
它是线程安全的,内部被synchronized 标识。 多线程可以使用 StringBuffer - StringBuilder.: 声明的是可变对象,可以对值进行修改,但不会产生新的对象
它是线程不安全的 ,单线程使用 StringBuilder,
StringBuilder 的性能 > StringBuffer.
7、String str="i"与 String str=new String(“i”)一样吗?
不一样 。内存的分配方式不一样
String str=“i” ,分配到了 常量池中
String str=new String(“i”) 分配到了 堆内存中
8、抽象类 和 普通类的区别
抽象类用 abstract标识,可以有抽象方法,普通类不能用抽象方法,
抽象类不能直接实例化,普通类可以实例化。
抽象类不能被 final 标识,因为其就要被继承使用,final 标识后就不能被继承了;
普通类可以被 final 标识。
9、接口 和 抽象类有什么区别
实现:抽象类用 extend 来继承,接口用 implements 来实现;
构造方法,抽象类可以有 构造方法,接口不能有;
main 抽象类可以有main 方法,接口不能有;
实现数量 类 可以实现多个接口,但只能 继承一个抽象类
方法体:接口中的方法定义为default或static或private方法,它就可以有方法体,抽象类的抽象方法不能有 方法体。
泛型
当一个对象中的变量类型不确定时,可以使用泛型标识变量,可以接收任意类型为变量的类型
如:
Demo对象中 key和value变量类型不定,可以使用泛型,当创建对象时指定参数的类型。
public class Test {
public static void main(String[] args) {
new Demo <Long,String>(1L,"11");
}
}
class Demo<K, V> {
private K key;
private V value;
public Demo(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public void setKey(K key) {
this.key = key;
}
public void setValue(V value) {
this.value = value;
}
}
好处:
- 避免在编译时发送类型不匹配的错误,避免运行时发生类型转换的错误
- 提高程序的性能,使代码更加简洁高效,避免类型转换和重复代码
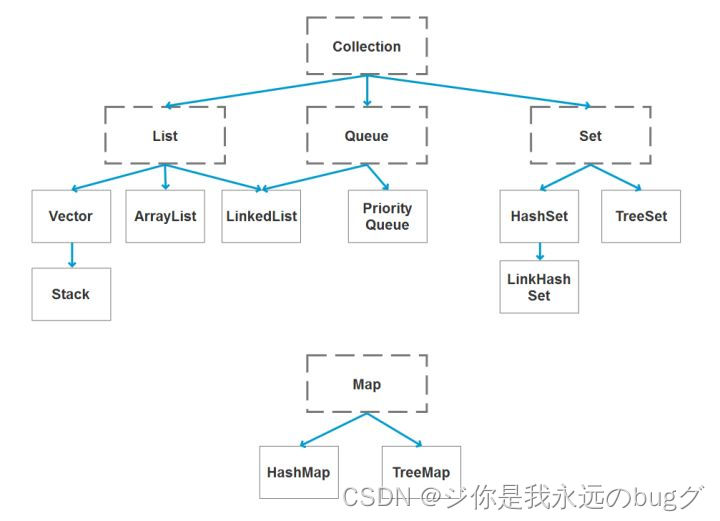
10、Java 容器有哪些?
List:ArrayList,LinkedList
Set:HashSet,TreeSet
Map:HashMap,TreeMap,HashTable;
11、Collection 和 Collections 有什么区别?
Collection 是一个集合的接口,提供了对集合操作的通用方法,
Collections 是集合类的 工具类,提供了一些静态方法,对集合对象进行操作。
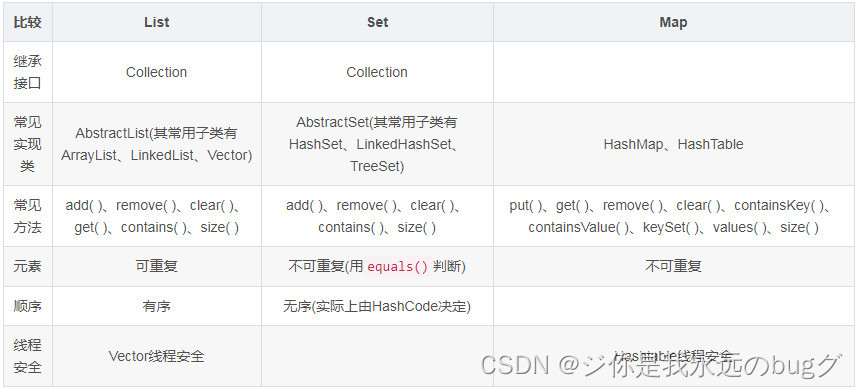
12、List、Set、Map 之间的区别是什么?
为什么 set不可重复
重写了 hashCode 和equal 方法判断元素是否存在,先判断 hashcode 是否相等、相等的话 再判断 equal是否相等,相等的话 元素存在。
14、如何决定什么时候用 HashMap 还是 TreeMap
1、插入、删除和定位元素,并且不需要排序,那么使用HashMap(哈希表实现)
2、需要对元素进行排序,那么使用TreeMap(基于红黑树实现)
15、说一下 HashMap 的实现原理?
HashMap 在put 元素的时候,先根据元素的HashCode计算出他的hash值,再根据hash值得到在Map中的下标,如果该位置有元素,就在该位置采用链表的形式,新的放表头,当链表的结点数量超过8个之后,链表会转为 红黑树在存放数据,如果该位置没有元素则直接放进去。
HashMap 为什么用红黑树
同一hash的值都放在了 一个链表内,当元素多的时候,通过key的查找的效率就降低了,在链表长度超过8的时候,将链表转为红黑树,可以减少查询时间。
HashMap 为什么不直接采用红黑树还要用链表?
在元素少于8个时,链表的查询成本低
大于8个,红黑树查询成本低。
红黑树的好处
1、快速插入删除定位元素,时间复杂度为 log n
2、数据有序存储:使得元素查找、排序等操作容易
红黑树在什么时候发送旋转
在插入和删除时 进行旋转,保持平衡
HashMap怎么遍历的
1、for (String key : map.keySet()) {
System.out.println("key is "+key);
System.out.println("value is "+ map.get(key));
}
2、 //遍历方法2: 直接遍历value
for (String value : map.values()) {
System.out.println("value is "+value);
}
16、HashSet的实现原理
- HashSet 基于HashMao实现的,封装了一个HashMap对象存储集合元素,HashMap的key保存HashSet的集合元素,HashMap的value是一个静态Object对象。
- 底层是 数组 + 链表 + 红黑树
13、HashMap 和 HashTable 有什么区别
HashTable 是同步的,HashMap 是不同步的,HashMap 比 HashTable 效率高。
HashMap 允许有空键值,HashTable 不允许有空键值。
HashTable 是线程安全的
为什么 HashTable是线程安全的
HashTable 的内部方法用 synchronized标识,每次只能有一个线程进入。性能较低、不推荐使用
推荐使用的线程安全的Map == ConcurrentHashMap
ConcurrentHashMap底层和 HashMap 一样都是 数组、链表、红黑树;
ConcurrentHashMap通过synchronized+CAS来实现 线程安全的,只需要锁住链表的头节点(红黑树的根节点),就不会影响其他元素的读写,大大提高并发度。
ConcurrentHashMap 的put原理
1、根据key 计算出 hash值
2、根据hash值定位到节点下标
3、如果该节点为 null 就添加
如果有其他线程在扩容,就参与扩容
如果都不满足,就使用 synchronized 锁住节点,判断是链表还是红黑树后进行插入。
4、链表长度超过 8 .使用 红黑树的形式进行扩容、
ConcurrentHashMap 的get原理
1、根据 key计算出 hash值,确定元素的下标
2、如果只有一个元素就直接返回
3、如果是链表或者红黑树就查询返回
ConcurrentHashMap 的get是否需要加锁
不需要加锁,因为节点的元素值和指针使用 volatile 修饰的,修改节点的值或者新增节点 对其他线程可见。
ConcurrentHashMap 不支持 key-value 为 null 的原因
因为 ConcurrentHashMap 用于多线程,如果 gey(key) 为null了,不确定是 这个值为 null 还是没有这个Key 返回的null;
hashMap 可以存key-value 为 null的原因
单线程的 hashMap 可以使用 containkey(key) 方法判断这个key是否存在。
ConcurrentHashMap 的并发度
依赖于 数组的大小。默认16,最大35536
17、ArrayList 和 LinkedList 的 区别
ArrayList 是 底层是数组 ,便于查询元素,直接通过下标进行查询,不便于插入删除,每次插入删除元素,其他元素会移动。
LinkedList 底层是链表;,便于插入删除元素,直接改变链表指针的指向元素,不便于查询,查询的话需要指针一个个的查询,效率低;
18、Array 和 ArrayList 有什么区别?
- Array 数组可以容纳基本类型和对象,ArrayList集合 只能容纳对象
- Array 指定大小,ArrayLIst 是固定大小(10)的。
array 和 arrayList 转换
Array.asList(数组)
list集合 .toarray
19、同步和异步有什么区别
同步:完成一个 在做下一个
异步:任务一起接,那个完成 就输出哪个
实现异步
1、在接口返回之前,开启一个线程去执行比如删除文件的操作,称为异步
2、Spring boot 在启动类上使用注解开启异步,并在异步方法上使用 @Ayscn注解标记其为 异步方法
3、使用JDK8内部的 实现类CompletableFuture,用于异步编程;
CompletableFuture使用
常用:xxx 和 xxx Async 区别: xxx 会当成一个线程任务去执行,xxxAsync 两个线程任务执行
-
supplyAsync 开启异步线程 有返回值 runAsync 开启异步任务,没有返回值
-
join:获取异步结果
-
thenCompose: 具有依赖关系的两个线程,A执行完后将结果给B执行,CompletableFuture会将两个任务当成一个执行
thenComposeAsync:CompletableFuture会将两个任务由两个线程执行(可以使用自定义线程池) -
thenCombine:把上个任务和这个任务一起执行,处理执行结果并返回
thenAcceptBoth:得到前面两个任务的结果,不返回
runAfterBoth:不需要前面两个的执行结果 也不需要返回 -
thenApply:将前面异步的结果交给后面的方法
thenAccept:接收前面的结果,无返回值
thenRun:不需要前面任务的结果,无返回值 -
applyToEither:两个线程同时执行,获取第一个执行结束的结果,有返回值
applyEither:得到最快任务的结果,无返回值
runAfterEither:不关心返回结果,也没有返回值 -
处理异常:
exceptionally:在方法体中处理异常,有返回值
Hanle:不论正常执行 还是异常执行都会有结果,并让后面的任务执行
whenComplete:不论正常执行 还是异常执行都 没有结果
19、并行和并发有什么区别
并发和并行表示的是CPU执行多个任务的方式
并行:多个任务同时在不同的CPU上执行,系统必须有多个CPU,在不同的CPU上运行不同的任务,任务之间不抢占资源。
并发:多个任务同时在一个CPU上执行 ,如听音乐和打游戏同时在一个CPU上进行,采用时间片轮转的方式进行任务调度,
形象解释:
并发:你在吃饭的过程中,吃了米饭、牛肉、羊肉, 这个过程就可以看作是并发,对你来说是同时进行的(吃饭),但你是在吃不同食物直接切换的
并行:你和我同时吃饭,你吃了米饭羊肉,我也吃了米饭羊肉,我们可以看做是并行的。我们在同一时间点吃饭,互不影响。
20、线程和进程的区别
一个程序至少有一个进程,一个进程至少有一个线程
进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位
21、创建线程的方式
这几种底层都是基于Runnable
-
继承Thread类 — >创建 线程类
线程类继承Thread 重写其run方法,run方法里就是线程的方法体,new 线程类创建线程类对象,调用 start方法启动线程类 -
通过 Runnable接口 创建线程类
线程类 实现 Runnable接口,重写其 run方法,实例化 该线程类,start 启动线程 -
通过 Callable 和 Future 创建线程 【做了解】
线程类实现 Callable 接口,重写其 call 方法,这个是有返回值的,实例化该线程类 ,使用get方法获取其返回值 -
使用线程池创建线程
22、 runnable 和 callable 有什么区别?
runnable 的run 方法没有返回值
callable 的 call 方法有返回值的。可以返回线程的异常
23、线程有哪些状态
五大状态:
创建、生成线程对象,没有执行 start方法
就绪、执行 start 方法,等待线程调度,在等待和睡眠回来后 也是这个状态
运行、执行 该线程
阻塞、线程运行中,阻塞、暂停、睡眠的时状态
死亡:线程 run方法执行结束,或调用 stop方法后线程死亡
24、sleep() 和 wait() 有什么区别?
sleep:使线程进入 睡眠状态、当一个synchronized块中调用了sleep() 方法,对象锁没有被释放,依旧占用CPU,其他线程依然无法访问这个对象,sleep 睡眠时间到后会自动进入 就绪状态,等待 线程调度
wait()::使线程进入等待状态,同时 释放锁对象,不占用CPU,需要使用 notify 或者 notifyAll 来唤醒等待的线程,
25、notify()和 notifyAll()有什么区别?
调用notify的线程不释放锁,只是唤醒其他线程
notify() :随机唤醒一个等待的线程
notifyAll():唤醒全部线程
26、怎么保证多线程的运行安全
-
原子性 :同一时刻 只能有体格线程对对象进行访问 ,可使用 synchronized 锁
-
可见性: 一个线程的修改对其他线程可见,可使用 volatile 标识
-
有序性:一个线程观察其他线程中的指令执行顺序,由于指令重排序,该观察结果一般杂乱无序,(happens-before原则)。
保证线程的执行顺序
.join() 方法;
synchronized、和ReentrantLock有什么区别
锁
1、synchronized是Java中的关键字,锁的范围是整个方法或synchronized代码块,可以自动上锁,异常或者执行完释放锁。
2、ReentrantLock:是接口lock的实现类,提供了可中断的锁获取,可实现公平锁(new …lock(true)),可实现选择性唤醒(signal() )线程(condition),设置超时时间等功能,需要手动上锁和释放锁。
除非下列情况使用ReentrantLock:
1、某个线程在等待一个锁的控制权的这段时间需要中断。
2、需要分开处理一些wait-notify,ReentrantLock里面的Condition应用,能够控制notify哪个线程。
3、需要公平锁功能,每个到来的线程都将排队等候。
另外,ReentrantLock还有一个读写锁ReentrantReadWriteLock,可以允许多个线程同时读取共享数据,但只允许一个线程写入共享数据。
ReentrantLock 如何实现公平锁和非公平锁的
公平锁: 先检查队列中是否有线程在排队,如果有线程在排队,则当前线程也要排队
非公平锁: 不检查是否有线程在排队,直接去竞争锁,竞争不到锁才会去排队。
总结:公平锁是直接去排队,非公平锁是先获取锁,获取不到才去排队,锁释放时,唤醒队列前面的线程,所以 非公平锁只体现在 线程加锁的阶段。
.
ReentrantLock trylock 和 lock方法区别
- trylock :尝试获取锁,不会阻塞,加到锁返回 true,没有返回 false
- lock:表示阻塞加锁,线程会阻塞,知道加到锁
线程之间如何 通信
多个线程在操作同一份数据时, 避免对同一共享变量的争夺。
1、使用 wait()方法在特定代码中使线程等待并释放锁,有notify 唤醒。
2、volatile共享数据
27、什么是死锁
在多线程中,多个线程对一个资源竞争 产生的一个阻塞的状态,若无外力作用,无法继续下去,称为死锁。
28、怎么防止死锁
产生死锁的必要条件:
-
互斥条件:进程 对 分配的资源不允许其他进程访问,如果要访问,只能等该进程使用完成,释放资源l
-
请求保持条件:进行获得一定资源,又向其他资源发出请求,但该资源被占用,此时请求阻塞,又对以获取的资源保持不放。
-
不可剥夺条件:进程以获取的资源,在未完成使用之前,不可剥夺其使用权,除了使用完成,自动释放
-
环路等待条件:进程发生死锁,若干个进程之间形成一种头尾相连的循环等待资源的关系。
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之 一不满足,就不会发生死锁。
总结死锁原因:进程分配的资源,其他进程不能访问,也不能剥夺其使用权。一个进程对自己的资源保持不放 ,又去请求被其他进程占用的资源,从而陷入等待状态 就会进入死锁。
synchronized锁的是类还是对象
分为类锁和对象锁。
类锁 :synchronized作用在 static 修饰的静态方法上; synchronized(当前类.class/其他类.class)
对象锁 :synchronized作用在非的静态方法上; synchronized(this/其他对象)
synchronized 的锁升级过程
1、偏向锁: 如果一个线程获取到锁,这把锁就是偏向锁
2、轻量级锁: 在偏向锁基础上,又有另一个线程竞争锁,通过自旋实现,不会阻塞线程,偏向锁升级为轻量级锁
3、重量级锁: 在轻量级锁的基础上,自旋次数过多,仍然没有获取到锁,轻量级锁升级为重量级锁,线程会阻塞
ThreadLocal有哪些应用场景,底层如何实现
ThreadLocal的功能是 同一个线程不同的方法中起到数据传递的作用,通过A方法set数据,B方法可以get获取
底层: 通过ThreadLocalMap实现,每个Thread 对象都有个 ThreadLocalMap,map的key是 ThreadLocal对象,Map的 value是需要缓存的值。
ThreadLocal可能会造成内存泄漏,如何解决
原因: ThreadLocal使用完后,缓存数据应该要进行回收,但线程不会回收, 线程强引用 ThreadLocalMap,ThreadLocalMap又强引用 缓存数据,所以线程不回收,缓存数据也不会回收,从而造成内存泄漏。
解决: 手动调用ThreadLocal的 remove方法 清除缓存数据。
线程池
介绍:事先创建多个可执行的线程放入一个容器中,需要的时候直接获取不用创建,线程使用完毕不需要销毁线程而是放回容器中,减少创建和销毁线程的开销。
优点:避免频繁的创建和销毁线程、灵活的控制并发数量
线程池有哪些状态
- running :线程正在运行,能接收新任务,也会正常处理队列中的任务
- shutdown:调用 shutdown方法,进入这个状态,表示线程池处于关闭状态,不会接受新任务,但是会把队列的任务处理完,任务处理完后进入 tidying状态。
- stop :调用shutdownnow方法,进入这个状态,表示线程池处于停止状态,不会接收新任务,也不会处理队列中的任务,正在运行的任务会停掉,都停掉后进入tidying状态 。
- tidying(泰定):线程池中没有线程在运行,并会调用 terminated方法。
- terminated (终止):执行完 terminated方法 会进入这个状态
springboot创建线程池方法
springboot方法:自定义线程池配置类,在ThreadPoolTaskExecutor对象设置如最大线程数、核心线程数等属性,并使用**@Bean(线程池的名字**)注解,将其交给IOC容器管理,使用线程时 , @Async(“线程池的名字”),引用线程池对象。
springboot线程池创建需要的参数
核心线程数:核心线程会一直存活,当线程数小于核心线程数时,即使有线程空闲,线程池会优先创建新线程来处理任务。
最大线程数:线程池创建的最大的线程数量
队列大小:用于保存等待执行的任务的阻塞线程的数量
线程池中线程的名称前缀:该线程池创建的线程名称的前缀
线程的存活时间:当线程空闲时间达到 设置的时间,该线程会退出,直到线程数等于 核心线程数。
核心线程超时回收 设置是否允许核心线程退出。默认 false
拒绝策略:当线程数大于最大线程数时被触发,没有多余的线程执行任务
- DiscardPolicy :直接丢弃
- CallerRunsPolicy :只有线程池没有关闭,就调用线程运行任务。性能低,容易阻塞
- AbortPolicy :丢弃任务 抛弃异常,必须处理好异常,否则会打断当前的执行流程,影响后续任务执行。
- DiscardOldestPolicy 只要线程池没有关闭,丢弃阻塞队列中最老的任务,并将新任务加入。
参考
使用线程池创建任务的流程
1、提交线程任务后,首先判断如果线程数小于核心线程数,则创建新的核心线程去执行任务
2、如果当前线程数大于核心线程数,也就是核心线程数已满,则任务会被添加到队列中,等待执行。此时如果队列已满,并且当前线程数还没有达到最大值,则创建非核心线程数执行任务。
3、如果当前线程数已经达到最大值,则会执行拒绝策略。
任务提交,如果核心线程数没有达到最大值,就会创建新的核心线程执行任务,如果核心线程达到最大值,会将任务放进队列中,如果队列已满,会创建非核心线程执行任务,如果达到最大线程数,会采取拒绝策略,如直接丢弃、将最老的任务丢弃放入最新的。
线程池的最大线程数和核心线程数设置多少合适
线程池启动的线程数太多,可能会导致 CPU 负荷超载,从而导致系统抖动或者死机等问题。
。以下是一些详细的考虑因素:
-
任务类型
任务类型是线程池最大线程数和核心线程数设置的重要因素之一。任务类型分为I/O密集型和计算密集型。I/O密集型任务指的是需要等待外部资源(如文件、网络通信)返回数据的任务;计算密集型任务指的是需要大量计算才能完成的任务。对于I/O密集型任务,因为线程处于等待状态,可以增加线程数使得 CPU 能够在处理等待状态时,利用这些空闲线程处理其他任务,从而提高程序执行的效率,可以设置较多的线程数;对于计算密集型任务,线程在执行任务时会占用 CPU ,设置过多的线程数容易导致 CPU 利用率过高,反而影响性能,因此一般线程数应该设置得较少。 -
CPU 核数
线程池的核心线程数不应超过 CPU 核心数的 1.5-2 倍 -
内存和资源限制
线程数的增多也会占用更多的 CPU 和磁盘等资源,尤其是 I/O 密集型任务和计算密集型任务都需要大量的 CPU 和磁盘资源。因此,在设置线程数时需要考虑系统资源的使用情况,并根据资源限制做出相应的调整或优化。 -
并发量的预计
线程池的最大线程数应该根据预计的并发量进行设置。对于瞬时并发大于线程池最大线程数的情况,一定要慎重考虑,可以采取其他机制,如队列缓存等方式。同时,最大线程数要满足任务执行的要求,如果线程数过少,可能会导致任务排队等待而无法立即执行;如果线程数过多,则会占用更多的系统资源,反而影响性能。
在确定线程池的最大线程数和核心线程数的同时,还需要考虑线程池的拒绝策略和等待队列的设置。这些设置需要根据具体的业务场景进行分析和调整,以充分利用系统资源,同时保证高效的任务执行
怎样才会线程阻塞
当线程A 获取到资源,线程B也要获取该资源,这个时候 线程B 时获取不到资源的,这个时候会造成线程阻塞;
为什么会线程阻塞
1、睡眠状态 : 拥有锁的线程 进入sleep状态,设置睡眠时间,在此时间内 ,锁资源不会被释放,依旧占用CPU
2、等待状态:线程调用 wait 方法进去等待状态,释放锁资源,被唤醒后,进去等待状态,等待获取资源
3、礼让状态:调用 yield 方法,会将锁资源让给更高优先级的线程执行,进去等待状态。
停止线程:
1、等run方法结束
2、interrupt方法中断线程
3、业务停止线程:设置个Boolean值,if(true)执行业务代码,否则 直接return 或者 不执行业务代码 结束线程。
interrupt 方法
interrupt()方法只是改变中断状态为true,不会中断一个正在运行的线程;
1、当线程在阻塞状态的时候,调用该方法会抛出InterruptedException 异常,使线程结束阻塞状态继续执行任务
2、当线程运行状态时:不会有效果,等待进入阻塞状态会抛出异常。
3、怎么使用interrup停止线程
- 线程调用 interrup方法
- 在线程的run方法中,使用 while方法判断是否进入中断状态,没有被中断则执行业务代码,否则直接结束run方法(类似业务停止线程)
- 或在 run方法体中 的sleep方法的抛出的 interruptException 异常中使用 return结束线程
4、interrupted() 监测线程是否中断状态,调用后清除中断状态,置为false
5、isInterruped() 监测线程是否中断状态, 不会清除状态
Thread类中的yield()方法有什么作用?
暂停当前线程,由同样优先级的线程调用CPU,可能出现该线程暂停后,立马执行
29、synchronized同步锁 和 volatile
synchronized 保证同一时刻只有一个方法进入 临界区【可能会造成堵塞】,还能保证变量的可见性。可以表示变量、方法、类
volatile :标识变量,其的改变对其他线程是可见的。
30、什么是反射
反射
反射:在Java运行时,获取类的信息(类、属性、方法等)并且可以在运行时操作类的属性和方法
功能:
- 获取类的信息:可以获取类的名字(.getClass.getName)、父类、接口、构造函数、方法等相关信息。
- 创建对象:通过反射可以在运行时动态地创建一个类的对象,这在一些需要动态创建对象时非常有用。
- 获取和设置类的属性:可以在运行时动态地获取一个类的属性信息,并对属性进行设置或修改。
- 调用类的方法:可以在运行时动态地调用一个类的方法。
31、什么是Java 序列化、什么时候序列化
序列化:将 Java 对象转换成字节流的过程。
反序列化:将字节流转换成 Java 对象的过程。
当 Java 对象需要在网络上传输 或者 持久化存储到文件中时,就需要对 Java 对象进行序列化处理。
序列化的实现:类实现 Serializable 接口,这个接口没有需要实现的方法。实现 Serializable 接口是为了告诉 jvm 这个类的对象可以被序列化。
注意事项:
- 某个类可以被序列化,则其子类也可以被序列化
- 声明为 static 和 transient 的成员变量,不能被序列化。static 成员变量是描述类级别的属性,transient 表示临时数据
- 反序列化读取序列化对象的顺序要保持一致
32、为什么使用克隆?
在对一个对象进行操作的同时又想保留原有的数据 ,就要使用克隆了。
33、如何实现克隆?
- 实现 Cloneable接口,并重写其 clone():
1) A 类继承Cloneable,并重新 clone 方法,内部有B类成员变量,B类继承Cloneable,但没有重写clone,此时 调用A的clone方法,A类是深拷贝,B是浅拷贝;
2)若 B也重写clone 方法,则都是深拷贝 - 实现 serializable 接口,通过序列化反序列化 实现深度克隆
34、深拷贝、浅拷贝
浅拷贝:复制了对象的引用地址,这是两个对象指向同一个引用地址,一个对象的值改变,另一个也会改变;
深拷贝: 将对象和值都复制过来,一个改变另一个不会改变,比如 JSON.parse();方法。
35、session && cookie
当客户端登陆时,服务器给该用户生成对应的 cookie 和 session ,并把cookie 发送给该用户,该用户的请求要带上这个 cookie ,服务器根据 cookie 判断该用户是谁。避免每次请求都要到库表中验证用户是谁。
36、throw 和 throws 的区别
throws :抛出所有异常信息,将异常向上抛,谁调用 谁处理。
throw:抛出一个具体的异常
37、try - catch - finally,如果 catch中 return 结果了,finally 还会执行吗
会! finally 会在 return 之前 执行。
38、为什么使用Spring?
- 轻量
- 控制反转(IOC)
- 面向切面(AOP)
- 容器
- 框架
Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架。
39、什么是AOP面向切面
AOP
将哪些与业务无关,但又被经常使用的方法 封装起来,便于减少系统的重复代码,减低模块间的耦合度,便于维护。
比如 :存钱和取钱的业务,当存取钱失败的时候,我们要进行事务回滚。这种核心代码都要加上事务回滚,就会造成代码的重复。
使用 @Aspect注解标识一个类为切面类,将事务的操作单独拿出来,在切面类的事务方法上使用 注解如@Before(方法路径)、@After(方法路径) 标记事务方法在什么时候被什么方法调用
aop 是随着系统运行而触发还是怎么触发的
在切面类中,有注解如@Before (方法路径),当调用方法时 就会触发这个这个aop切面
aop的通知方式
-
@around 环绕通知:可以在方法前后添加需要执行的操作
-
@before** 前置通知:在方法执行前运行,
-
@AfterReturning 返回通知:在方法正常执行完成后执行
-
@afterThrow,异常通知:方法出现异常时执行
-
@After 事后通知:方法执行后,无论有无异常,都会执行
执行顺序:
正常情况:环绕通知、前置通知、代码、返回通知、事后通知、环绕通知
异常情况:环绕通知、前置通知、代码、异常通知、事后通知、环绕通知
aop 的应用
事务、日志等
aop使用
项目中:相关需要预测的接口的日志处理
- 自定义注解,MyLog,标记在具体的请求方法上
- 使用@Aspect 标记一个切面类,@Pointcut指定切入点为 myLog这个注解的方法logPointCut,哪里使用这个注解 就会进入这个切面类
- 使用返回通知@AfterReturning 参数为这个 切入点logPointCut,myLog注解标记的方法,不报错时记录训练日志
- 使用异常通知@AfterThrowing(pointcut = “logPointCut()” 参数也是这个切入点,mylog注解标记的方法出现异常,会进入这个异常处理方法,记录日志
40、什么是IOC控制反转
控制: 创建对象,对象的属性赋值,对象之间的关系管理。
反转: 把容器代替开发人员管理对象。创建对象,给属性赋值。
正转:由开发人员在代码中,使用new 构造方法创建对象, 开发人员主动管理对象。
将对创建对象管理对象的 交给IOC bean 容器来操作,避免在一个类中 new 一个对象,降低了两个对象的耦合度。
ApplicationContext 和BeanFactory有什么区别
BeanFactory:bean工厂: 可以生成bean 和 维护bean
而 ApplicationContext 是BeanFactory 子类,他包括 BeanFactory 所有方法,同时还有获取系统变量等功能。
41、spring 常用的注入方式
构造方法注入、
setter 方法注入
注解注入
spring 的事务如何实现
使用@Transactional注解 可以实现事务
- 首先判断是否有 Transactional 注解,有的话就修改数据库连接,禁用自动提交
- 执行方法,没有异常 就直接提交
- 如果有异常并且需要回滚就会回滚事务,否则仍然提交事务
- spring事务隔离级别对应的就是数据库的隔离级别
什么是Spring 的循环依赖
A类中 注入了B对象,B类中也注入了A对象。
或者 A类中注入了A对象。
Spring 是如何解决循环依赖的。
通过 三级缓存解决的 循环依赖
一级缓存:单例池
二级缓存:单例对象
三级缓存:单例工厂
当AB循环依赖时,A完成实例化后,就使用实例化后的对象创建一个对象工厂,并添加到 三级缓存中,如果A 被Aop代理了,就通过这个工厂获取A代理后的对象,如果A 没有被Aop代理,就从工厂获取A的对象。
当A 进行属性注入时,会去创建B,同时B又依赖A,所以创建B的同时会去调用getBean获取A依赖。getBean方法会从缓存中获取,第一步:先获取到三级缓存的工厂,第二步:从工厂中拿到对应的对象,将对象注入到B中,当B创建完成,会将B注入到A 中。
简单说: 创建A实例化会把A对象放进三级缓存 单例工厂中,这个时候 进行注入B ,B中需要注入A,此时会从工厂中获取A的对象进行注入,完成B的实例化,这时再将B注入到A中。
二级缓存可以解决循环依赖吗
如果使用二级缓存解决循环依赖,意味着所有Bean在实例化后就要完成Aop代理,违反了spring 的设计原则,spring是在bean的生命周期的最后一步完成aop代理,而不是实例化后就立马进行Aop代理
spring Bean 的生命周期
Spring Bean的生命周期指的是Bean从创建到初始化再到销毁的过程
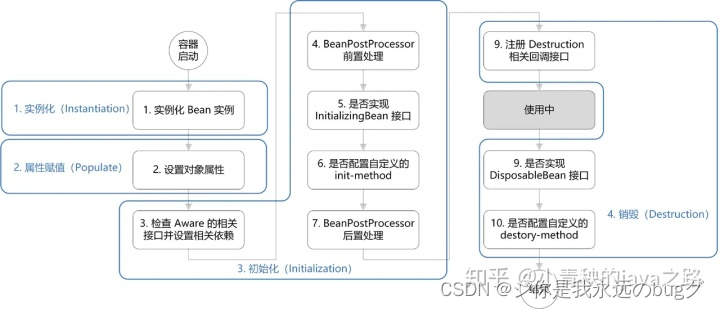
实例化(Instantiation)
属性赋值(Populate)
初始化(Initialization)
进行aop
销毁(Destruction)
spring bean 是线程安全的吗
当对象有方法对变量进行赋值 如set方法,那就是不安全的。
反之 就是安全的
43、Spring MVC运行流程
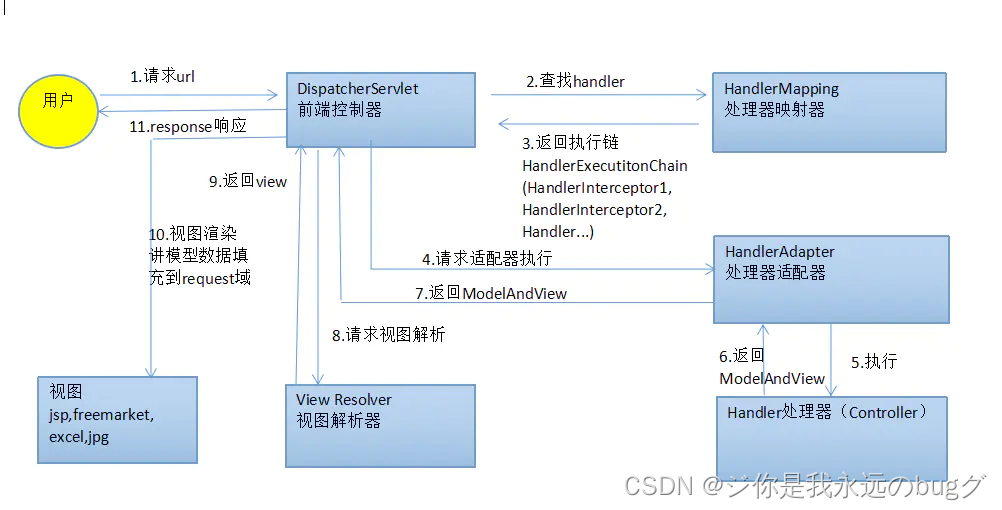
- 用户发去请求到前端控制器,
- 前端控制器调用 HandlerMapper 处理器映射器,查找具体的处理器,
- 将查到的处理器 返回给 前端控制器
- 前端控制器调用 处理器适配器
- 处理器适配器 调用页面控制器进行处理
- 页面控制器 返回 处理的结果 ModelAndView 到处理器适配器
- 处理器适配器返回 结果ModelAndView 到前端控制器
- 前端控制器 请求视图解析器进行解析
- 视图解析器解析完成 返回 view 给 前端控制器
- 前端控制器再对 view进行渲染
- 将渲染后的页面 返回给浏览器
一句话:
浏览器发出请求到前端控制器,前端控制器调用HandlerMapping(处理器映射器)查找具体的处理器后,调用处理器适配器 用相应的页面处理器进行处理后,返回ModelAndView 到前端控制器,前端控制器再调用视图解析器进行解析,返回 View,最后对view进行渲染后 返回到浏览器。
44、什么是 spring boot
spring boot 简化了 spring 众多框架 需要配置的 大量又繁琐的 配置文件。因此 springboot 简化了 框架的使用 是一个 服务于 框架的 框架。
Spring Boot 如何启动的
有个 application 启动类,启动类里有main方法,方法体中,SpringApplication.run 方法启动整个项目,开启内置 tomcat服务器。
45、spring boot 核心配置文件
application.yaml
application.properties(优先)
springboot 配置优先级
- 1、命令行参数:程序启动时设置的命令行参数 如:java -jar xxx.jar --server.port=8888
- 2、 Java系统属性:在启动应用程序之前设置Java系统属性来指定配置属性,例如:-Dserver.port=8888。
- 3、在yml 或 properties 中配置 spring.config.name 和spring.config.location,指定其他配置文件的名字和路径
- 4、使用 注解@PropertySource 来指定其他外部配置文件
- 5、properties文件
- 6、yml文件
SpringBoot有哪些常用注解?
-
@SpringBootApplication:这是一个组合注解,用于标记启动类,相当于@Configuration、@EnableAutoConfiguration、@ComponentScan三个注解的组合。
-
@RestController:这个注解用于声明一个类是 Restful 接口的控制层,相当于 @Controller和@ResponseBody的组合注解。
-
@RequestMapping:该注解用于对请求地址进行映射,常用的属性有 value、method、params、headers 等。
-
@Autowired:这个注解用于自动装配,可以用在属性、构造函数、setter 方法上。
-
@Value:这个注解用于读取配置文件中的属性值。
-
@PathVariable:用于获取路径变量的值,常用于 RESTful API 中。
-
@RequestBody:用于获取请求体的值,常用于接收 JSON 格式的请求体。
-
@Configuration:用于声明一个类是配置类,相当于传统的 XML 配置文件,常用于定义 Bean。
-
@Component:用于声明一个类是组件,可以让 Spring 自动扫描并加载这个类。
-
事务管理相关的注解 @Transactional、
-
定时任务相关的注解 @Scheduled、
-
AOP 相关的注解 @Aspect 等。
-
全局异常处理拦截器 使用 @RestControllerAdvice注解
SpringBoot自动装配
为什么添加依赖后,加上@Autowired注解直接可以使用该对象?
1、什么是自动装配呢?
:从spring.factories文件中获取对应需要进行自动装配的类,并生成相应的Bean对象交给 spring ioc 容器进行管理。
如:添加一个 依赖后,可以使用 @Autowired直接注入使用。
2、自动装配的原理
在启动类上有个注解 @SpringBootApplication,这是个组合注解,其中有个 @EnableAutoConfiguration注解,用于开启自动配置
在这个注解中有两个主要的注解 @Import(AutoConfigurationImportSelector.class) 注解 和 @AutoConfigurationPackage注解
-
@Import(AutoConfigurationImportSelector.class)
导入AutoConfigurationImportSelector这个类中有个 selectImport方法,通过扫描 springboot-autoConfig这个jar包中的spring.factories文件,这个文件是key-value的形式,找到key是 EnableAutoConfiguration的 他的值就是需要自动装配的类,将其生成对应的bean 加载到 IOC容器中。实现自动装配。 -
@AutoConfigurationPackage注解
将注解的类所在的 package 作为自动配置的package 进行管理。这样当springboot 启动时 会默认将启动了所在的package作为自动配置的package。
Spring Boot --start
当我们在 pom文件中添加依赖时,有两种 start
官方提供的starter是这样的:spring-boot-starter-xxx
非官方的starter是这样的:xxx-spring-boot-starter
Starter 帮我们封装好了所有需要的依赖,避免我们自己添加导致的一些Jar包冲突或者缺少包的情况;
Spring Boot 配置全局异常处理
1、首先自定义消息的响应参数 code msg data
2、自定义全局异常处理拦截器 使用 @RestControllerAdvice注解,并在拦截器中使用@ExceptionHandler中定义具体异常,根据不同的异常类型返回不同的数据
java中的异常
- java所有的异常都来自顶级父类Throwable
- Throwable 有两个子类 Exception 和 Error
- Error表示代码无法解决的错误如:OutOfMemoryError
- Exception表示代码可以解决:如NullPointerException空指针异常
- Exception 又分为运行时异常和非运行时异常
- 运行时异常: 由代码逻辑错误引起的,比如 NullPointerException
- 非运行时异常: 必须进行处理的异常,如IO异常,SQL异常
springboot定时任务:
在application 启动类上加上开启定时任务的注解 @EnableScheduling ,
在定时任务上加上 @Scheduled注解表示其时定时任务方法,使用cron 语句设置 触发时间
springboot 并发状态下如何保证一定有线程执行定时任务
写一个配置类 继承SchedulingConfigurer 并且重写的configureTasks 方法 在到要执行定时任务时 为他创建线程池,从而保证一定有线程
参考
如何保证每次只有一个线程执行定时任务
Spring Boot提供的@Scheduled注解的ThreadPoolTaskScheduler属性,自定义一个只有一个线程的线程池来执行定时任务,并在任务完成后,从线程池中移除。
@Component
public class ScheduledTask {
@Scheduled(fixedDelay = 3000)
public void executeTask() {
// 执行定时任务的代码
}
}
@Configuration
@EnableScheduling
public class AppConfig {
@Bean
public TaskScheduler taskScheduler() {
CustomThreadPoolTaskScheduler scheduler = new CustomThreadPoolTaskScheduler();
scheduler.setPoolSize(1);
return scheduler;
}
}
class CustomThreadPoolTaskScheduler extends ThreadPoolTaskScheduler {
@Override
public void afterPropertiesSet() {
super.afterPropertiesSet();
setRemoveOnCancelPolicy(true);
}
}
在AppConfig类中,我们自定义了一个名为taskScheduler的TaskScheduler bean,并在该bean中配置一个CustomThreadPoolTaskScheduler对象,该对象使用了setPoolSize(1)方法来设置线程池只有一个线程。在CustomThreadPoolTaskScheduler类中,我们重写了afterPropertiesSet()方法,并设置了一个setRemoveOnCancelPolicy(true)方法来确保任务取消后能够及时从线程池中移除。
46、什么是 spring cloud
spring cloud 是一个应用于 分布式微服务系统的框架。
47、mybatis 中的 #{} 和 ${}的区别
#{}:将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号-----防止 sql注入
${}: 传入数据是什么格式 到xml 中就是什么格式
动态sql的标签
- if :if test=“name != null”
- where
- set :update set
- foreach :foreach item=“id” collection=“ids” open="(" separator="," close=")
mybatis的分页查询怎么实现的
- PageHelper.startPage(第几页 , 一页几条),方法设置分页的参数并将包含分页参数的page对象放进ThreadLocal中
- 执行查询方法会进行分页拦截,拦截的方法中
- 1、skip方法判断是否需要分页,ThreadLocal有page对象就需要分页,没有就不需要分页,直接返回
- 2、查询总条数,保存进 ThreadLocal的page中
- 3、进行分页查询 使用 limit实现
- 4、将查询的结果封装进 ThreadLocal的page中,然后将page进行返回,其中包含分页数据、总条数、第几页、每页大小
- 5、根据page对象构建 PageInfo对象,进行返回,实现分页查询
MyBatis 的缓存
一级缓存 默认开启
在同一个 sqlSession中,第一次执行sql语句时,mybatis会将结果存在缓存HashMap中,key是sql语句和参数等数据组成的唯一key ,value是查询的对象。
再次进行查询时,mysql会先到 缓存中查询,没有才会到数据库中查询。当缓存过期、sql刷新或者关闭、执行了增、删、改的操作,会清空缓存。
一级缓存的sqlSession说相互隔离的,sqlSession(A)中有缓存,但是用sqlSession(B)查询一样会去数据库中查询。
因此 二级缓存就是解决 sqlSession相互隔离的问题
二级缓存
在同一个mapper下的同一个namespace,sqlSessionA第一次执行操作会把数据存在 hashMap缓存中,sqlSessionB 执行相同的sql,它会直接获取缓存的数据,不再向数据库进行查询。
同样当缓存过期、sql刷新或者关闭、执行了增、删、改的操作,会清空缓存。
Mybatis的一级缓存和二级缓存
springboot开启二级缓存
- 添加 mybatis-ehcache 依赖
- 在yml文件中设置 开启二级缓存cache-enabled=true
- 在mapper.xml中 添加cache方法。
springboot如何自定义mybatis缓存
- A实现 cache接口,重写其方法,如,如getObject 获取缓存
- 在配置文件中配置 A 的全路径,rjies并将A 加入到bean容器中
- 在mappe接口使用 CacheNamespace 注解,指定自定义缓存类A
48、MySQL数据库的三大范式
第一范式:列的原子性,数据库每一列都是不可分割的原子数据项
如有字段为 地址:青青草原 羊村 肥羊小学,这个就不符合第一范式,地址不符合原子性,还可以再分为 省省、市、县。
第二范式:实体的属性完全依赖于主键
第三范式:任何非主属性不能依赖于其他非主属性。
49、ACID是什么?
- A(原子性):一个事务的所有操作要么全部成功 要么全部失败,失败后 回滚到事务开始前的状态
- C(一致性):事务开始前和结束后,数据库的完整性没有被破坏,写入的数据 必须完全符合 Mysql的各项要求
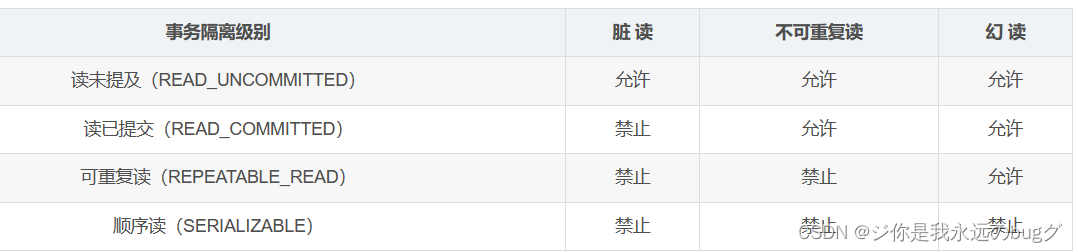
- I(隔离性):数据库允许并发事务 对数据库进行操作。隔离的级别:读未提交、读提交、可重复读、串行化;
- D(持久性):事务结束后 对数据的修改是永久的。
42、 事务隔离
一个事务对数据的修改 对 另一个并行的事务的隔离程度。
如果没有采用隔离机制,则
- 脏读:一个事务获取到 另一个事务还没提交的数据
- 幻读:两个事务 同时对数据不同修改,会发现另一个事务的修改结果 并不是自己操作的,就像产生幻觉(我没这样改啊,怎么成这样的)
- 不可重复读:事务A根据条件读取一条数据,这时事务B对这条数据进行修改了,A再次根据相同条件查询数据,读取不到那条数据了
不可重复读和幻读的区别主要是:解决不可重复读需要锁定了当前满足条件的记录,而解决幻读需要锁定当前满足条件的记录及相近的记录。比如查询某个商品的信息,可重复读事务隔离级别可以保证当前商品信息被锁定,解决不可重复读;但是如果统计商品个数,中途有记录插入,可重复读事务隔离级别就不能保证两个事务统计的个数相同。
事物隔离级别
-
未提交读(Read Uncommitted):允许脏读,也就是可能读取到其他会话中未提交事务修改的数据
-
提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)
-
可重复读(Repeated Read):事务读取数据,在此事务没有结束之前,其他事务不能对该数据进行读写,保证读取的数据是一致的。Mysql的InnoDB默认级别。
-
可串行化(Serializable):性能最差
事务A读取/修改数据,事务B必须等待A提交后才能继续。事务读取数据,使用共享锁,修改数据使用独占锁,先读后写必须是共享锁升级为独占锁。
50、char 和 varchar
char:固定长度 如 char(10) 填入 abc 此时占用了3个字节,但是剩下7个为 空字节,效率高 ,但浪费空间,适用于 固定长度的字段数据 如 MD5加密后数据的密码字段
varchar :可变长度 varchar(10),填入 abc 此时长度 为 varchar(3),适用于 不定长度的数据字段。
51、mysql 内连接、左连接、右连接
内连接:inner join :把匹配的关联数据 全部显示出来
左连接 left join:把左边表全部显出来,右边表显示出 符合条件的数据
右连接 right join::把右边表全部显出来,左边表显示出 符合条件的数据
52、mysql 引擎
InnoDB:提供了对数据库ACID事物的支持,还提供了行级锁和外键的约束,设计目标为 大数据容量的数据库系统,在高并发下使用会提升效率。
原理:mysql 运行时,innoDB 会在内存中建立缓冲池,用于缓冲数据和索引,不支持全文搜索,也不会保存表的行数,当查询 select count(*) from table时,需要扫描全表。
MyIASM 不提供事务ACID事务支持,也不提供行级锁和外键的约束。当执行插入修改语句时 会锁定这个表,导致效率降低。但它保存了表的行数,当查询 select count(*) from table时,不需要扫描全表,直接读取保存的值即可,当对表 读的操作 多于 写操作,并且不需要事务,建议使用这个。
Mysql的查询过程
1、向mysql服务器发送sql 请求
2、查询缓存,如果命中,直接返回结果
3、采用优化器对sql进行解析得出执行计划
4、mysql根据执行计划调用存储引擎 查询
5、将结果返回
mysql优化
53、乐观锁 悲观锁
乐观锁:每次拿数据 都认为别人不会修改,因此不会上锁,但每次提交更新时 会判断在此期间是否有人去更新这个表
悲观锁:每次拿数据都认为这个数据别人会修改,因此每次拿数据都会上锁,这样别人就拿不到这个数据了,等待锁的释放。 synchronized是悲观锁
55、Redis的缓存穿透
缓存穿透: 一定不存在的数据,在高并发下 redis 缓存不命中,就到数据库中查询,又因为一定不存在,就会导致大量请求到数据库中。
解决 :一定不存在的数据,查询为空 也写进缓存为null,过期设置的短一些 如5分钟。
Redis为什么快
1、redis是纯内存操作,数据存在内存中
2、I/O多路复用
3、单线程避免了线程切换和竞争资源产生的消耗
56、怎么保证缓存和数据库数据的一致性?
- 合理设置缓存的过期时间
- 每次对数据库的操作 同时对 Redis 进行更新。
Redis 的数据类型
redis总结
1、String
2、list:可以在list 的 左边或者 右边插入元素。可用于消息队列
3、set:存放唯一不重复的元素。,可以取set集合的交集,实现查看共同好友,共同关注的需求。
4、有序set:对成绩进行大小排序
5、hash:存放 key-value 数据,比String 更方便存对象
实现分布式锁的几种方法
1、redis实现分布式锁:获取到锁 往redis插入数据,释放锁时删除数据
2、mysql实现分布式锁:每个客户端获取锁都要向表中插入一条记录,唯一索引限制只能由一个客户端插入,插入成功 就是获取到锁,释放时删除
3、redisson实现分布式锁
实现限流
1、tomcat使用 maxThreads 配置最大线程数实现限流
2、漏桶算法
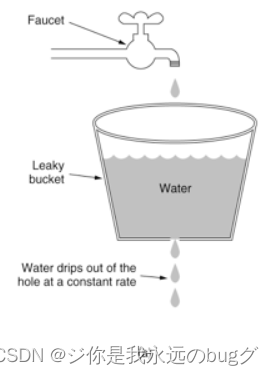
把请求 比作水,请求来了放进桶里,以限定的速度出水,
不论请求流量多少总是以限定的速度处理请求,桶满了话,请求会被拒绝
实现:
- 先声明一个redis队列用来保存请求,这个队列相当于漏斗,当队列容量满了之后就放弃新来的请求,然后重新声明一个线程定期从任务队列中获取一个或多个任务进行执行,这样就实现了漏桶算法。
- Redis-Cell:该模块使用的是漏斗算法,并且提供了原子的限流指令
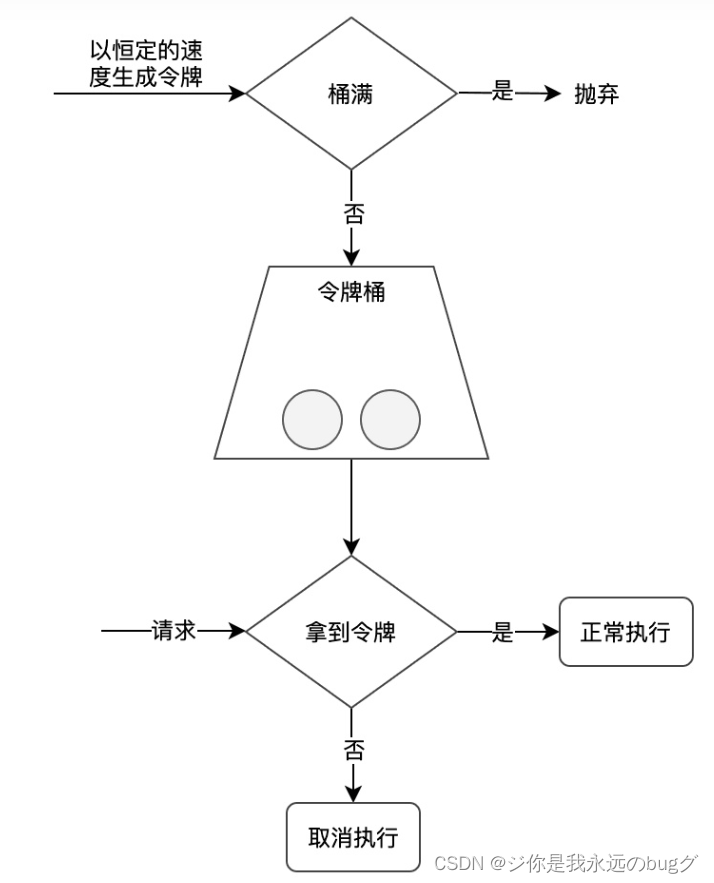
3、令牌桶算法
以某种恒定的速度生成令牌,并存入令牌桶中,而每个请求需要先获取令牌才能执行,如果没有获取到令牌的请求可以选择等待或者放弃执行
实现:
- 定时任务往redis list中存入数据(令牌),请求接口前往redis list中pop获取元素,获取到表示拿到令牌就可以执行了,没获取到放弃请求。
- 使用 google 的guava依赖,实现令牌桶算法。
IO流分类
1、流向分:输入流 和 输出流
2、操作单元分: 字节流 和字符流
3、实现功能 分:节点流和处理流
IO流 怎么读取文件的
根据文件路径生成 file 对象,通过字节流或字符流读取file对象,循环遍历输出文件
输入流 和输出流
输入流 :将文本内容输入到 inputstream中打印出来
输出流:将 内容 写入 outputStream,生成文本。
字节流和字符流的区别
字节流在文件本身进行操作,不会进入缓存区,inp/Out putStream
字符流在操作时使用了缓存区,其最大的好处说可以对中文进行有效的处理。 Reader,字符缓存流,BufferedReader处理Reader. 会将文件读取的内容存在缓存区,使用 readLine进行读取。
如果有中文处理就用字符流,没有就用字节流。
57、JVM 内部结构
- 类加载器 : java --> 字节码
- 运行时数据区 :字节码—> 内存
- 执行引擎 :字节码 --> 底层指令
- 本地库接口
- 垃圾回收器
原理:类加载器 将 Java文件 转为 字节码,运行时数据区把字节码 加载到内存中,由命令解析器执行引擎 将字节码翻译为底层系统指令,再给CPU执行,这个过程需要调用其他语言的本地库接口,来实现整个程序的功能。
说一下 jvm 运行时数据区(Java 内存结构)?
程序计数器
虚拟机栈
本地方法栈
堆
方法区
类加载器的执行流程
1、加载:根据路径查找相应的class文件,然后导入
2、检查:检查加载的文件是不是正确
3、准备:给类中的静态变量分配内存
4、解析:将常量池的符号引用转换为直接引用:符号引用:理解为一个标识,直接引用:直接指向内存地址
5、初始化:对静态变量和静态代码块执行初始化操作
类加载器的分类
-
启动类加载器(BootstrapClassLoader)
系统变量 JAVA_HOME 路径 lib下的 jar和class文件 -
扩展类加载器 (ExtClassLoader):
系统变量 JAVA_HOME 路径 lib下 ext 下的 jar和class文件 -
应用程序类加载器 (AppClassLoader)
负责加载(classpath)上的指定类库
AppClassLoader的⽗加载器是ExtClassLoader,
ExtClassLoader的⽗加载器是BootstrapClassLoader。
什么是双亲委派模型?
类加载器收到了类加载的请求,它首先调用AppClassLoader,但不会自己去加载这个类,而是把这个请求委派给父类加载器去完成,这样所有的加载请求都会被传送到顶层的启动类加载器中,
只有当父加载无法完成加载请求(它的搜索范围中没找到所需的类)时,子加载器才会尝试去加载类。
双亲委派的好处
1、防止恶意代码:每次加载类都会检查类是不是可信的,有效防止恶意代码的运行;
2、防止类重复:每次加载都会判断父加载器是否加载此类
避免类重复的问题
如何破坏双亲委派
1、继承 ClassLoader 并重写 loadClass 方法
为什么破坏双亲委派
可以讲下 tomcat 自定义 类加载器的场景
tomcat为什么使用自定义类加载器
一个 tomcat是可以部署多个应用的,每个应用中的 classpath是可以一样的,比如应用A 有com.user这个类,应用B也有com.user这个类,两个应用使用一个默认的 应用程序类加载器(appClassLoader)就只能加载一个 user类。那么应用B的user类就加载不到了。
因此使用自定义加载器(webAppClassLoader)为每个应用生成一个类加载器,这样就可以加载对应的应用中的类
58、堆栈区别
栈:局部变量、基本数据类型 存在 栈内存中,要给出默认值,用完就消失,
堆:new 的对象 和成员变量存在堆内存中,由对应的内存地址值,默认的初始化值,由垃圾回收不定期自动清楚
59、队列 和 栈
队列是 先进先出
栈先进后出
什么是GC,为什么要有GC
GC是垃圾回收机制,
编程人员忘记和错误的内存回收会造成系统不稳定,Java提供的垃圾回收器会自动进行内存管理
说一下 jvm 有哪些垃圾回收算法?
-
标记-清除算法
通过gc root标记从根节点开始的对象,没被标记的就是垃圾对象,进行清除
优:存活对象较多的情况下比较高效
劣:1、会产生大量内存碎片
(垃圾对象不是放到一起的,比如活、死、活、死对象,这时标记死的清除后,死的就空出来了,内存区就会有一个个的空区,就像碎片一样,不方便分配内存)
2、扫描两次内存空间 -
标记-复制算法
内存区分为两块,使用的一块A标记所有存活对象,复制到另一个B空的内存空间,A内存全部回收
优:1、存活对象少的时候高效 2、只扫描一次内存空间
劣:1、空间浪费,2、有复制的操作 -
标记-整理算法
标记所有存活对象将其压缩到内存一端,其他空间全部回收
优:没有大量内存碎片,也不需要新的内存空间 -
分代算法
将内存区划分为 存活率低 新的对象-新生代,存活率高的老年代,jvm内存外,用户本机的永久代 -新生代和老年代比例 1.2
其中新生代采用标记 复制算法,老年代才有标记清除算法或者标记整理算法
jvm内存结构(什么时候执行垃圾回收、垃圾回收器的机制、分代算法)
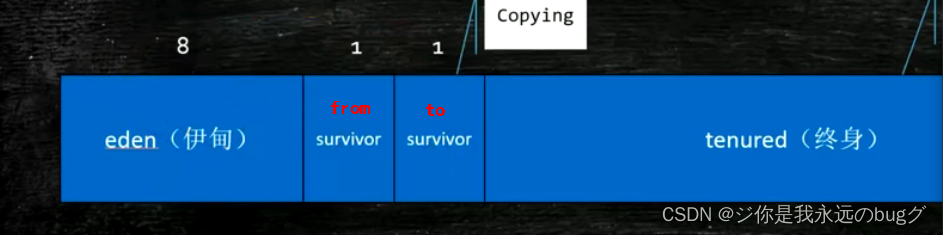
1、新生代分为三块 eden:from :to = 8:1:1
新生对象放进eden,满了后存活的对象复制进 from,eden清空
2、eden清空后,新生对象继续放进eden区,当eden又满了,将eden和from中存活对象(此时from中的对象可能有死亡)复制到 to区,Eden和from清空
3、eden清空后,新生对象再放进eden,当eden满了,会把 eden和to区存活对象放进 from区,这样周而复始放进from区,则eden和to全部清空,放进to区则 eden和from全部清空,from和to总有个空的
当eden满了后放进 from或者tu区,比如放进from区,如果 from放不下啦,则将存活对象放进 年老代
4、上述每个对象会被复制多次(复制一次,对象年纪+1),默认复制15次就进入老年代
5、当老年代满了,会发生一次full gc
垃圾回收有两种类型:Minor GC 和 Full GC。
1.Minor GC
新生代满了,对新生代进行回收,不会影响到年老代。因为新生代的 Java 对象大多死亡频繁,所以 Minor GC 非常频繁,一般在这里使用速度快、效率高的算法,使垃圾回收能尽快完成。
2.Full GC
老年代满了。对整个堆进行回收,包括新生代和老年代。由于Full GC需要对整个堆进行回收,所以比Minor GC要慢,因此应该尽可能减少Full GC的次数,导致Full GC的原因包括:老年代被写满、永久代(Perm)被写满和System.gc()被显式调用等
垃圾回收器的分类
新“复” 老“整”
搭配:serial - serialold 、Parallel-Parallel old(jdk8)、ParNew - CMS(清除)
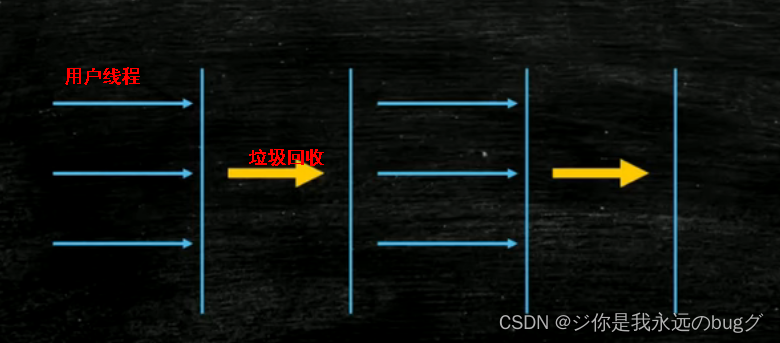
- serial :单线程下默认新生代垃圾收集器,采用标记复制的算法、”Stop-the-World”:停止所有用户线程,进行垃圾清除,
内存小,单线程足以 - serial old:单线程下默认老年代垃圾收集器,采用标记整理的算法、”Stop-the-World”,做完CMS后备垃圾回收器
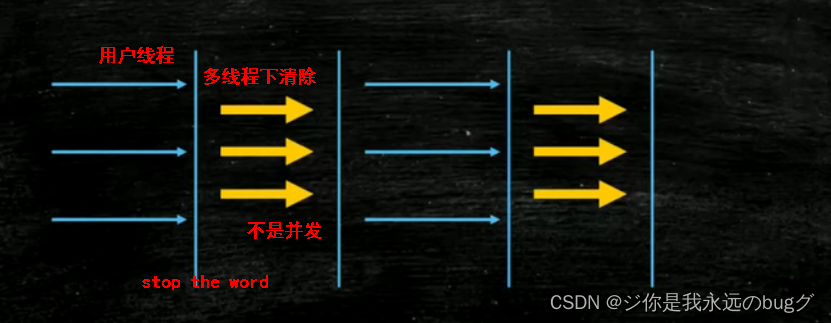
-
Parallel :吞吐量优先,用于新生代
采用标记复制算法、多线程并行回收和Stop the World机制,动态调整内存分配情况,以达到一个最优的吞吐量或低延迟。
内存变大,单线程下用户线程停止时间过长,采用多线程并行清除垃圾 -
Parallel old:用于年老代,采用标记整理算法
jdk8中使用 Parallel -
ParNew :serial 的多线程版本,新生代的垃圾回收器,采用标记复制算法、”Stop-the-World”
-
CMS:并发垃圾回收,采用 标记清除算法,也会 stop the word(STW),减少用户线程停顿时间
分为四个阶段
1、初始标记:标记和gc root根节点直接关联的对象,所有线程因stop the word而停止,标记完成后,恢复线程
2、并发标记:根据直接关联对象,便利整个对象图,此过程与用户线程同时运行
3、重新标记:标记并发阶段用户程序所产生的对象(也会stop the word),从头扫描一遍
4、并发清除:清除未标记的垃圾对象,与用户线程并发运行
劣势:
1、开始回收时还会放对象导致放满,因此在年老代内存用完之前完成垃圾回收,否则回收失败会触发担保机制使用Serial Old和stop thw word进行 gc,造成较大的停顿时间
2、产生浮动垃圾 -
G1:采用标记整理 + 分代算法的并发垃圾回收器
g1将内存分为一块块区域,给每个区域定义年轻代和年老代,回收时,可以根据每个区域的剩余空间,选择性的对某个区域进行清除。
并且可以动态的给区域设置年代,如果区域是年轻代,新生对象多,可以把它设置为 eden区,如果老年代内存不够,可以将清空的eden区设置为老年代
在执行过程中,因为回收某个区域,其他区域也可以使用,所以不需要stw停止用户线程,
Rset:记录了其他区域中对象和本区域对象的引用,垃圾回收器只需要扫描Rset。
三色标记法:CMS和G1使用
并发环境下避免漏标对象,采用的标记法

1、A对象自己和所有子对象都被标记过,垃圾回收器不会再扫描这个对象
2、B对象自己被标记过,但是子对象还没有标记,垃圾回收器会继续从 本对象开始往下找
3、C对象自己没有被标记,还没有扫描到这个对象
三色标记的产生的问题
-
情况1、
对象扫描是从根节点开始,A-B-C,本次线程扫描到B停止(线程调度),停止过程中BC断开,线程再次扫描时就找不到C了,C就是浮动垃圾了,本次清除不了,下次gc也会清除

-
情况2(重要问题:漏标)、对象扫描是从根节点开始,A-B-C,本次线程扫描到B停止(线程调度),停止期间,BC断开,AC连接,
因为A类对象最初被标记为不会再扫描,并且BC断开,B也找不到C,所以线程再次扫描时,C在垃圾回收器眼中是垃圾,会被清除,但其实不是,C和A有引用关系,会报空指针
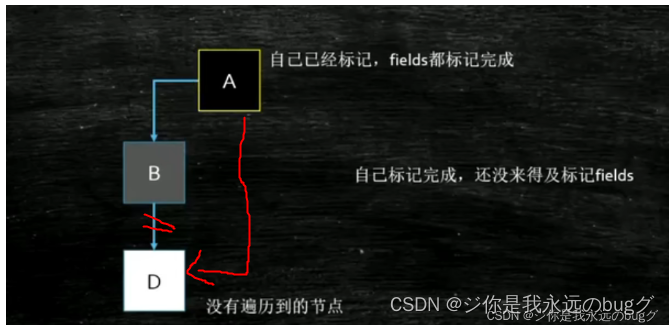
CMS对三色标记产生漏标的解决方案
当A类对象引用C类对象时,将A类对象转为B类对象,下次垃圾回收线程会进行扫描A对象的子对象从而找到C
但是这个解决方法时有问题的
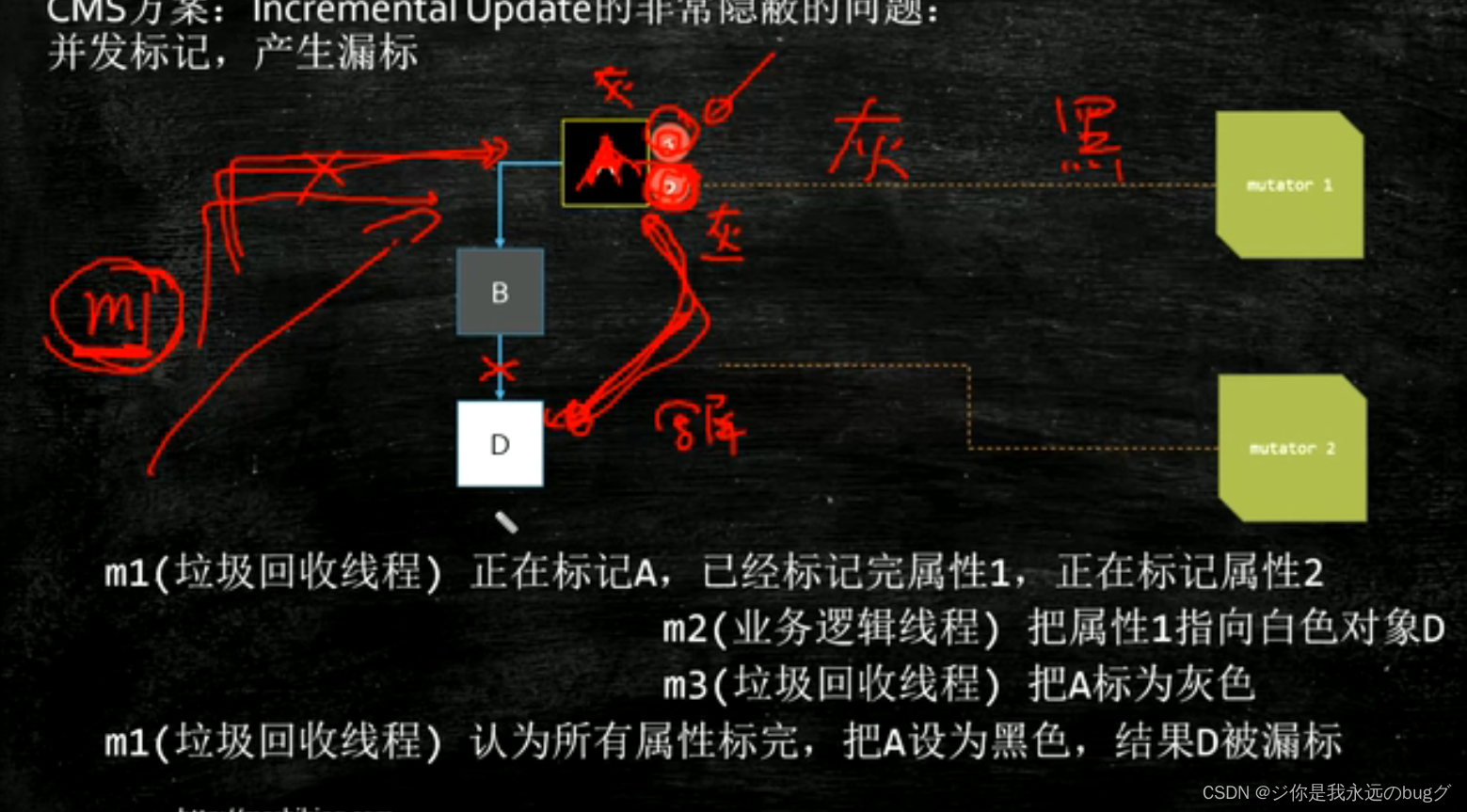
垃圾回收线程正在标记y对象 (有y1,y2俩子节点,)标记完y1,【正在】标记y2,没标记完,线程停止,此时Y对象属于B类对象
这时C类对象被Y对象引用,线程再次运行,上次扫描Y只有Y1 Y2,并正在标y2,标记完y2认为扫描完成,将Y标记于A类对象,C对象不再扫描,当垃圾回收了
解决这个bug,在重新标记阶段,stw停止所有用户线程,从根节点再扫描一遍(内存大的时候,很慢)
G1对三色标记法的解决
当B类对象引用C类对象之间的引用消失时,这个引用会被记录下来,垃圾回收线程会扫描这个记录,当知道有C类对象的引用消失,它会扫描有无对象引用这个C类对象,如果没有C类对象就是垃圾对象
jvm调优参数
设置堆内存大小、堆内存最大值、新生代大小、eden区和幸存区(from、to)的比例,当outofmemery可以设置直接内存、并发线程数
Xms:初始化堆内存大小,默认为物理内存的1/64(小于1GB)。
-Xmx:**堆内存最大值。**默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制。
-Xmn:新生代大小,包括Eden区与2个Survivor区。
-XX:SurvivorRatio=1:Eden区与一个Survivor区比值为1:1。
-XX:MaxDirectMemorySize=1G:**直接内存。**报java.lang.OutOfMemoryError: Direct buffer memory异常可以上调这个值。
-XX:+DisableExplicitGC:禁止运行期显式地调用System.gc()来触发fulll GC。
注意: Java RMI的定时GC触发机制可通过配置-Dsun.rmi.dgc.server.gcInterval=86400来控制触发的时间。
-XX:CMSInitiatingOccupancyFraction=60:老年代内存回收阈值,默认值为68。
-XX:ConcGCThreads=4:CMS垃圾回收器并行线程线,推荐值为CPU核心数。
-XX:ParallelGCThreads=8:新生代并行收集器的线程数。
如何排查 JVM问题
调优不是⼀蹴⽽就的,需要分析、推理、实践、总结、再分析,最终定位到具体的问题
非正常运行的系统
- 一般都会设置当系统崩溃,生成当时的 dump文件
- 可以使用jsisualvm工具来分析dump文件
- 找到异常的对象和线程定位到代码
- 进行分析和调试
正常运行的系统
- jmap -head 进程号: 查看JVM堆内存信息
可以使用 jhat分析 jmap的 dump文件
jmap -dump:format=b,file=/tmp/dump.dat 21711
Dumping heap to /tmp/dump.dat ...
# jhat查看 浏览器输入9998端口查看
jhat -port 9998 /tmp/dump.dat
- jstack 进程号: 查看线程的运行情况,有无线程阻塞或死锁
- jstat -gc 进程号: 各年代的使用情况以及新生代和年老代的GC次数和耗时,如何fullgc频繁,就要进行调优啦
若fullgc频繁
1、fullgc执行,代表 老年代达到了阈值 ,如果没用内存溢出的话,表示在老年代回收的很多对象,所有这些对象最好在新生代就被回收掉,可以增大新生代大小,或者加大进入年老代的标记次数
2、找到占用CPU最多的线程,定位到具体方法,优化方法,避免对象的创建。
JVM哪些是线程共享的
堆区和方法区是线程共享的
栈、本地方法栈、程序计数器是每个线程独有的
垃圾对象的判断方式
引用计数和对象引用遍历(基本)
对象引用遍历
当对象创建时,GC开始监控这个对象信息。采用有向图的方式记录和管理所有对象, GC的对所有对象进行遍历,如果发现有对象没有被引用,则说明此对象不可用。
引用计数法
给每个对象设置个计数器,被引用+1,引用失效-1.当计数器 =0 代表为垃圾对象,将被垃圾回收器回收。由于此无法解决循环引用的问题[A引用B ,B引用A],不被采用。
内存泄漏
概念:堆内存中,有数据或者对象占用内存,但数据又没有用到,导致内存浪费
分布式 垃圾回收器(DGC),如何工作
跨虚拟机的远程对象的引用,垃圾回收是很困难的。DGC使用引用计数的方法给远程的对象进行内存管理。
==根据简历 的面试题=
java 读取表
表分为两种 xls 和 xlsx 格式,相应的也有两种不同的创建方式
xls对应 HssWorkBook 创建
xlsx 对应 XssWorkBook创建
然后按行进行读取数据。
使用
OPC协议
机器和程序直接进行通信的协议,通过OPC地址和安全策略等参数进行建立连接,通过支点和名称 使用 readValue 读取数据, 创建支点和名字使用,writeValue进行写数据。
BigDecimal
可以对 超过16位的数据进行 精确的计算, 建议用 String对象 内容是数字,创建 BigDecimal 对象
+:add - :subject * multiply / divide
java 执行 py文件
Runtime.getRuntime.exec (py路径)
swagger框架
swagger 是一个生成API接口文档的框架
在Controller 类 @Api() 注解 表示这个类用于swagger
在 请求方法上 @ApiOperation 标识一个Http请求,
在 请求体上 使用 @ApiModel 标识这是请求体
在请求参数使用 @ApiModelProperty 标识参数信息
Shiro框架
shiro 是个安全框架,首先自定义 realm 对象对用户登录信息进行校验判断账号密码是否正确,检验成功后将该用户的 权限、角色 放进 授权信息对象中。在配置类中注入 编写的realm类,根据 授权信息 对接口进行权限认证,可以通过角色、权限进行认证。
shiro 三大组件
subject: 代表当前用户
所有subject 都绑定在 securityManagement 上,和 subject 的所有交互都委托给securityManagement,可以认为 subject是门面,securityManagement 才是执行者。
securityManagement:安全管理器
所有与安全有关的操作都会与 securityManagement 交互,包括认证、授权等。它是shiro的核心,负责与其他组件交互。
Realm:数据源
securityManagement 要想 认证和授权,需要从 realm中获取 用户数据。
Shiro 认证流程
1、subject.login(UsernamePasswordToken)方法请求登录
2、登录会调用 securityManagement ,使用 Authenticator 进行认证
3、Authenticator 会把 UsernamePasswordToken 传给 Realm
4、从 Realm中获取身份认证信息
5、如果没有异常,就代表成功,有异常代表认证失败。
Shiro 授权过程
关键对象:subject(主体) 、 resource(资源), permission(权限) 、 role(角色)
1、调用 subject.ispermitted(“权限”) 方法 ,会委托给 SecurityManager ,最终委托到 Authorizer
2、在授权之前,会调用realm获取当前用户的角色、权限信息;
3、Authorizer 会判断 realm的权限信息和传入的是否匹配,匹配则通过,否则不通过。
在配置类中定义 拦截器: 接口资源权限规则:
认证过滤器:
anon:无需认证即可访问,游客身份。
authc:必须认证(登录)才能访问。
authcBasic:需要通过 httpBasic 认证。
user:不一定已通过认证,只要是曾经被 Shiro 记住过登录状态的用户就可以正常发起请求,比如 rememberMe。
授权过滤器:
perms:必须拥有对某个资源的访问权限(授权)才能访问。
role:必须拥有某个角色权限才能访问。
port:请求的端口必须为指定值才可以访问。
rest:请求必须是 RESTful,method 为 post、get、delete、put。
ssl:必须是安全的 URL 请求,协议为 HTTPS。
如:filterMap.put("/user/add",“perms[user-add]”);
当然也可以设置注解拦截常用@RequiresPermissions,@RequiresRoles
spring security原理
spring security是安全认证和授权的框架,核心是拦截器,拦截器实现身份认证和授权的功能。当用户请求时,security会拦截请求,并使用拦截器去进行身份和权限验证,验证成功后,spring security会放行。
- 1、用户请求,spring security进行拦截,并检验token的有效性
- 2、无效则token过期,用户重新登录获取token
- 3、token有效,spring security创建一个 securityContext对象,包含当前用户角色、权限等信息
- 用户每次请求都会进行拦截,通过securityContext对象判断是否有权访问接口
spring security认证流程
- 用户登录,spring security进行拦截请求
- 将用户名密码封装成 Authentication 对象
- AuthenticationManager接受对象会对根据用户名密码 封装成 userDetails 对象进行查询认证
- 如果认证失败则返回异常,认证成功则返回已认证的 Authentication 对象。
使用流程:
1、编写用户认证授权类,继承UserDetailsService并重写loadUserByUsername方法,进行用户账户密码的认证,认证成功后,将用户的权限信息set进userDetail中交给security管理器
2、继承AuthenticationEntryPoint 自定义认证失败拦截器、继承AccessDenieHandler自定义无权访问拦截器,继承LogoutSuccessHandlerImpl 自定义登出成功拦截器等拦截器
3、编写配置类,继承WebSecurityConfigurerAdapter类,配置用户认证和鉴权拦截器
禁用seesion,配置自定义的拦截器,对可匿名访问的接口用anonymous放行,anyRequest().authenticated(),其他接口需要鉴权
4、在接口上使用注解PreAuthorize(判断用户有无此权限的方法,返回为true或false),true的代表有权限
spring security鉴权
权限检验:
每次接口会先走 security 拦截器,事先设置 可以匿名访问的 和需要鉴权的接口,并设置 jwt 拦截器
1、 jwt 拦截器:String token = request.getHeader(header); 拿到 token信息,解析 token 返回Claims(),获取载体 用户唯一uuid,redis根据uuid 获取当前user ,根据变量过期时间 判断token是否过期
2:鉴权
@PreAuthorize("@ss.hasPermi(‘system:menu:query’)")
@PreAuthorize :security 的注解,判断接口是否有权限
@ss.hasPermi(‘system:menu:query’) == > service(”ss“)后,可以用@ss 调用这个类,调用.hasPermi 方法 根据user的权限list 判断是否包含这个权限
Nats 消息中间件
由go语言开发的轻量高性能的消息中间件,发布者发布消息,一个或者多个订阅者接收消息,配置简单、速度快、高性能。
工作模式
发布订阅模式:发布者 根据主题subject 发布消息到 Nats服务器,服务器根据主题 将消息发布给订阅主题的客户。
缺点:发布者不知道 ,订阅者有没有收到消息
请求响应模式,订阅者接收消息后通过reply来回应主题,确定订阅者接收到了消息。
如何保证Nats消息不被重复消费
给每个消息中获取一个 唯一的id 接收消息的时候 将id记录在库中。如果下个消息的id 在库中存在 则为重复消息,可忽略。
Kafka consumer [消费者]是推还是拉
生产者推送消息到服务器,消费者从服务器上拉取消息
好处:
- 如果是服务器推送消息的话,一旦服务器推送的速度大于消费者消费的速度,消费者会崩溃的
- 消费者可以自主的决定是否批量的拉取数据
kafak维护消费状态跟踪的方法
主题被分成若干个分区,每个分区在同一时间只被一个consumer消费,这意味着每个分区被消费的消息在日志中的位置是一个整数:offset(偏移量),这样就很容易标记每个分区消费状态,仅仅需要一个整数offset 。另外consumer可以把offset调成较老的值,去重新消费旧消息。
Kafka的主从同步
主题被分为多个分区,每个分区有一个leader和若干个副本,当leader挂了,会从副本中选举一个成为leader,leader和副本上的数据是一致的。
zookeeper 对于Kafka的作用
zookeeper是开源的、高性能的协调服务,用于kafka的分布式应用,和集群中不同节点之间进行通信。
在kafak中,zookeeper被用于提交偏移量【因此如果节点在崩了,可以从之前提交的偏移量中获取】、
leader监测是否可用,副本选举leader的、分布式同步、配置管理、节点的实时状态、集群管理。保证Kafka的健壮性和高可用。
数据传输的事务定义三种
1、最多一次:消息不会被重复发送、最多传输一次,但可能一次也不发
2、最少一次:消息不会不发,最少发送一次,但可能重复发送
3、精确一次,不会不发也不会重复发送,只发送一次
Kafka怎么判断节点是否可用
1、zookeeper通过心跳机制检查每个节点的连接
2、如果节点是从副本 follower,必须和leader同步数据,不可延迟太久
Kafka和MQ消息系统的三个关键区别
(1).Kafka 持久化日志,这些日志可以被重复读取和无限期保留
(2).Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据提升容错能力和高可用性
(3).Kafka 支持实时的流式处理
Kafka的ack机制
ack 有三个值 -1,0,1
-1:等所有副本接收到生产者的消息后,服务端才会接收leader发送的ack确认,数据不会丢失
0:生产者不会等待服务器的确认,发送完消息,就默认服务器接收到
1:服务端等到leader副本接收到消息,但是不能保证所有的副本的
Kafka手动提交偏移量offset
1、在配置文件中将 auto.commit.offset设为 false。取消自动提交
2、在处理完消息后手动提交,commitSync()、commitAsync(异步)
Kafka.什么是活锁
消费者正常情况下,订阅一个主题,能够poll消息,会占用一个分区,定时向zookeeper发送心跳监测,证明本节点可用。
活锁: 消费者占用一个分区,并且能够正常发送心跳,但是不poll消息也不进行消息处理,同时一直占用这个分区。
kafka解决活锁问题
[这一段差不多了: 使用 max,poll.interval.ms活跃监测机制,当poll的频率小于最大间隔,客户端就会断开连接,由其他消费者接管分区进行消费。
【拓展】
此时提交offset失败,因为只要活动成员能够提交offset,因此必须持续调用 poll。
方案1、增大poll间隔,max.poll.interval.ms,为消费者提供更多的时间进行处理消息怕[缺点:值越大会让延迟组重新平衡]
方案2、 限制每次调用poll返回的消息数:max.poll.records,更容易的预测每次poll间隔处理的最大值,通过修改这个值,减少poll间隔。
推荐方法: 将消息处理转移到另一个线程中,让消费者继续调用poll。
推荐方法前提:1、已提交的offset不超过实际位置 2 禁用自动提交offset,并在线程处理完后手动提交offset,3、暂停分区,不会poll到新消息。
Kafka如何控制消费的位置
使用 seek(TopicPartition,long)方法指定分区和位置
最新的offset位置 seekToBeginning
最老的offset位置 seekToEnd
kafka分布式情况下,如何保证消息的顺序性消费
Kafka 发布主题会被分为若干个分区,同一个分区下以队列的形式存储消息,可用保证顺序性,但不同的分区时不能保证顺序性的,除非把消息都发送到一个分区中。
kafak发送消息,可用指定三个参数、(主题、分区、key),指定分区后所有的消息都会发送到一个分区中,指定key后同一个key会发送到同一个分区中
kafka高可用机制
Kafka 实现高可用性的方式是进行 replication【ISR 】
一个topic主题被分为不同的分区、每个分区中有一个leader 和 若干个follower,他们的数据是同步的,当leader 挂掉后,会重新选举出一个leader进行数据的读写。
kafka 如何保证不重复消费
1、将消息记录在数据库中,接收到消息到数据库进行查询,判断消息是否被消费过
2、给消息配置个唯一Id,将记录保存至redis或者其他数据库中,由此判断是否被消费过。
kafka 可以脱离 zookeeper 单独使用吗?为什么?
kafka 不能脱离 zookeeper 单独使用,
因为 kafka 使用 zookeeper 管理和协调 kafka 的节点服务器。
kafka 有几种数据保留的策略?
kafka 有两种数据保存策略:按照过期时间保留和按照存储的消息大小保留。
每个分区被分为若干个片段,当一个片段数据写满后,开启另一个片段,正在写的片段是活跃片段,如果所有片段都写满了,会删除最老的,循环使用所有片段。
kafka 同时设置了 7 天和 10G 清除数据,到第五天的时候消息达到了 10G,这个时候 kafka 将如何处理?
这个时候 kafka 会执行数据清除工作,时间和大小不论那个满足条件,都会清空数据。
使用 kafka 集群需要注意什么?
-
集群的数量不是越多越好,最好不要超过 7 个,因为节点越多,消息复制需要的时间就越长,整个群组的吞吐量就越低。
-
集群数量最好是单数,因为超过一半故障集群就不能用了,设置为单数容错率更高。
什么是消息队列
消息队列是一个使用队列来通信的组件
为什么需要消息队列(好处)
常用来实现:异步处理、服务解耦、流量控制(削峰)
消息队列的缺点
1、MQ挂掉的话,和MQ相关的业务执行不了,系统崩溃
2、需要解决 消息的重复消费、消息丢失的问题
zookeeper 是什么?
zookeeper 是一个分布式的,开放源码的分布式应用程序协调服务,它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
zookeeper 都有哪些功能?
集群管理:监控节点存活状态、运行请求等。
主节点选举:主节点挂掉了之后可以从备用的节点开始新一轮选主,主节点选举说的就是这个选举的过程,使用 zookeeper 可以协助完成这个过程。
分布式锁:zookeeper 提供两种锁:独占锁、共享锁。独占锁即一次只能有一个线程使用资源,共享锁是读锁共享,读写互斥,即可以有多线线程同时读同一个资源,如果要使用写锁也只能有一个线程使用。zookeeper可以对分布式锁进行控制。
命名服务:在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。
. zookeeper 有几种部署模式?
zookeeper 有三种部署模式:
-
单机部署:一台集群上运行;
-
集群部署:多台集群运行;
-
伪集群部署:一台集群启动多个 zookeeper 实例运行。
zookeeper 怎么保证主从节点的状态同步?
zookeeper 的核心是原子广播,这个机制保证了各个 server 之间的同步。实现这个机制的协议叫做 zab 协议。 zab 协议有两种模式,分别是恢复模式(选主)和广播模式(同步)。
当服务启动或者在领导者崩溃后,zab 就进入了恢复模式,当领导者被选举出来,且大多数 server 完成了和 leader 的状态同步以后,恢复模式就结束了。状态同步保证了 leader 和 server 具有相同的系统状态。
集群中为什么要有主节点?
在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可以大大减少重复计算,提高性能,所以就需要主节点。
集群中有 3 台服务器,其中一个节点宕机,这个时候 zookeeper 还可以使用吗?
可以继续使用,单数服务器只要没超过一半的服务器宕机就可以继续使用。
说一下 zookeeper 的通知机制?
客户端会对某个 znode 建立一个 watcher 事件,当该 znode 发生变化时,这些客户端会收到 zookeeper 的通知,然后客户端可以根据 znode 变化来做出业务上的改变。
RabbitMQ:什么是RabbitMQ
RabbitMQ是一个消息中间件
RabbitMQ特点
1、可靠性:通过消息的持久化、生产者的回调确认和消费者的消息确认机制保证其可靠性。
2、灵活的路由:消息进入队列之前,通过交换机来 路由消息。典型的路由功能,rabbitMQ提供了内置的交换机来实现【广播模式:fanoutExchange、路由模式:directExchange、主题模式:topicExchange】。
3、高可用性:队列可以再集群中的机器设置镜像,使得再部分节点出现问题的情况下 队列仍然可用
4、管理界面:RabbitMQ提供了一个易用的用户界面,使得用户在监控和管理消息,集群中的节点等。
5、多语言客户端:RabbitMQ几乎支持所有的常用语言,如 Java、python等
RabbitMQ:AMQP是什么
RabbitMQ 支持 AMQP协议,AMQP的模型架构 和 RabbitMQ的模型架构是一样的,生产者将消息发送给交换机,交换机和队列绑定。
RabbitMQ中的交换机、交换机类型、队列、绑定、路由等遵循 AMQP协议规定。
RabbitMQ:三大组件:
1、交换机:服务器中用于爸消息 路由 到队列的组件
2、队列:用来存储消息,位于硬盘活内存
3、绑定:告知交换机:消息应该投递到那个队列中
RabbitMQ:如何保证消息的可靠性
1、生产者 到 RabbitMQ:使用 confirm回调函数,获取MQ服务器的确认信息,判断消息是否发送成功。
2、RabbitMQ本身:进行消息持久化,保存到硬盘中
3、RabbitMQ到消费者:消息确认机制、死信队列、消息补偿机制。
RabbitMQ:什么是路由键 RoutingKey
在将队列绑定到交换机上时,要绑定路由键。发送消息到交换机上时,会根据路由键找到消息要保存的队列。
RabbitMQ:交换机的类型
1、广播模式:fanoutExchange,只定义队列、交换机,没有路由
将所有发送到该交换机的消息 发送到所有绑定在该交换机的队列上。
2、路由模式:directExchange:定义队列、交换机和路由,
发送消息需要指定交换机和路由,消息会发送到 绑定到该交换机和路由的队列上。
3、主题模式:topicExchange:
在路由模式的基础上,对路由键进行通配符匹配
#:匹配0个或多个 。如:#.red: 可以匹配:a.red、a.b.red等
*:匹配1一个 。 如:*.red:可以匹配a.red,不能匹配a.b.red
RabbitMQ:生产者如何发送消息
1、生产者,先和服务器 建立tcp连接,开启信道
2、生产者定义 交换机、路由键、队列,并将其进行绑定
3、生产者 发送消息到 服务器,带有交换机和路由的信息
4、服务器根据相应的交换机和路由信息找到相应的队列,如果找到队列,消息保存在队列上,没有就将消息丢失或返回生产者。
RabbitMQ:消费者接受消息的过程
1、消费者 向服务器发送请求消费 监听队列的消息,等待服务器回应后,接受消息
2、消费者 消费完后,确认消息 ack
3、RabbitMQ 从队列中删除 已经确认的消息。
RabbitMQ:交换机无法找到相应的队列时,有哪些处理:
1、mandatory:true 返回消息给生产者
2、mandatory:false 直接丢弃
RabbitMQ:什么是死信队列
将 服务器中的消息 因为各种原因没有被消费最终死掉的消息,转发到一个统一的队列中,这个队列就是 死信队列。
RabbitMQ:导致死信的原因
1、队列满了
2、消息过期
3、消费者拒绝消费消息,
RabbitMQ:实现延迟消息:延迟消息交换机
rabbitmq_delayed_message_exchange插件,称为延迟消息交换机,
只要发送消息时指定的是这个交换机,那么只需要在消息 header 中指定参数x-delay[:毫秒值] 就能够实现每条消息的异步延时
RabbitMQ:拒绝消费消息 和 确认消费消息
拒绝:channel .basicNack –
- 如果是重试消息 ,会重写进入到队列中
- 如果不是,则删除,获取进入死信队列
确认:channel.basicAck—消息从 队列中删除
rabbit持久化的缺点
1降低服务器的吞吐量。因为使用的是磁盘而不是内存,可使用 ssd硬盘来缓解
rabbit持久化的条件
1、设置队列持久化 true
2、设置交换机持久化
RabbitMQ:消息队列的结构:
1、负责消息处理的部分,如接收消息、向消费者交付消息等
2、消息存储的部分
rabbitMQ 如何实现负载均衡
1、mq客户端提供的 round_robin算法,可以将消息均等分配在每个消费者
2、集群使用 haproxy实现 负载均衡和keepalived实现高可用
3、mq集群化,每个节点都可以处理消息,通过集群来实现负载均衡
rabbitMQ如何处理高并发
1、使用多个消费者,增加消息的处理速度
2、使用消息确认机制,消费消息后,进行确认,消息从队列中删除
3、rabbitMQ集群化,增加节点数量,提高消息处理效率
4、消费者批量处理消息
RabbitMQ集群
1、RabbitMQ天然支持集群。这使得RabbitMQ本身不需要像ActiveMQ、Kafka那样借助ZooKeeper实现集群搭建。
RABBITMQ_NODE_PORT=5673 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15673}]" RABBITMQ_NODENAME=rabbit1 rabbitmq-server start
2、配置好集群后 队列消息不同步,这时要配置 镜像队列,实现主从同步
rabbitmqctl set_policy my_ha "^" '{"ha-mode":"all"}'
3、RabbitMQ集群如何指定节点消费消息,实现负载均衡
- 1、通过 node参数,在启动消费者的时候指定队列所在节点实现消息消费的负载均衡
- 2、java中在创建连接时,指定节点名称实现消费者指定节点消费消息
RabbitMQ 和 Kafka的应用场景区别
- RabbitMQ适用于应用间消息传递的场景,如异步处理等,通常在较小的规模和实时性要求不高的场景
- kafka 主要目的处理海量的流式数据,适用于大数据领域中,对实时性有较高的要求,如:日志采集,业务监控等,应用于大型系统。
controller 调用service接口再调用service实现类的好处和坏处
好处:
- controller 层 和service实现类之间的 解耦,保证代码的灵活性和可扩展性
- 保证数据安全:在service 接口中对数据进行校验,确保数据的安全可靠
坏处:
- 增加了代码量和开发时间,多写了个接口类
- 增加系统的复杂度
如何避免消息堆积
1、设置多个消费者进行消息处理
2、监听到消息,进行异步处理
消息积压的原因
1、消费者 宕机,队列的消息无法消费
2、消费者的业务逻辑过于繁杂,消费能力不足
3、生产者的消息过多
grpc
grpc:一般使用的是 restful API,grpc和他有一样的机制,都是客户端和服务端进行通信,底层也都是 http传输协议,
grpc优势(场景):
1、通过 protobuf来定义接口,有更严格的接口约束,
2、通过 protobuf可以将数据 序列化为 二进制编码,减少传输量,提高性能。
因为现在一般都是分布式系统mgroc没有提供分布式系统的相关组件,所以grpc只是作为一个部件使用。
使用grpc依赖和 proto文件编译插件,编写 proto文件(py语法)Maven 编译后会生成java文件,编写客户端和服务端进行通信。
影响接口的响应速度的因素
-
网络延迟:网络延迟是指请求数据从客户端发送到服务器并返回的时间。网络延迟取决于许多因素,包括网络拓扑、带宽、距离、物理障碍等。如果网络延迟较大,则会导致请求到响应的时间增加,从而影响接口响应速度。
-
响应处理时间: 服务器需要处理请求并生成响应的时间,也就是处理时间。如果处理时间较长,服务器就需要更长的时间来生成响应并将其发送回客户端,从而降低接口响应速度。
-
数据库查询时间:如果请求需要从数据库中返回数据,则查询数据库的时间也会影响接口响应速度。数据库查询时间受到多个因素的影响,包括数据库的优化程度、索引的设置以及所查询的数据量等。
-
代码效率: 代码效率是指服务器代码针对请求的处理速度。如果代码写得不够高效,那么每个请求的处理时间可能会变得较长,从而降低接口响应速度。
-
服务器负载:服务器负载是指服务器处理请求的程度。如果服务器处理过多的请求,那么响应速度会变慢,因为服务器需要花费更多的时间来处理请求。
-
接口设计:接口设计的好坏也可以影响接口响应速度。如果接口的请求和响应格式过于复杂或者不规范,那么服务器需要更多的时间来处理这些请求。同时,接口的路由也可以影响接口响应速度,应尽可能精简。
总之,当优化接口响应速度时,需要综合考虑这些因素。例如,可以优化代码来提高处理速度,使用缓存来减少对数据库的查询,选择适合的服务器规格来降低负载等。
什么是单例模式
一个类在 整个项目运行中只有一个实例。
分为懒汉式 :什么时候需要,什么时候创建实例和 饿汉式:先创建 再调用。
线程安全分为两种:
- 双重判断:私有化构造器,该类的实例作为静态成员变量 用线程可见的字段 volatile标识,再获取该类实例的方法中,先判断对象是否为null 为 null 的话 进入同步代码块中 再次判断对象是否为null ,不为null 返回对象实例,
- 静态内部类
私有化构造器,创建静态内部类,静态常量为 创建该类的实例对象,提供获取对象实例的 公有方法返回内部类的常量。
桥接模式
以手机关机为例,一个接口由 close 方法,抽象类 关联这个接口,抽象类的close方法调用的是 接口的close方法,这个时候 一个手机实现这个抽象类,调用 close方法其实调用的是 接口的close 方法。
原型模式
克隆:分为深克隆 浅克隆
深克隆相当于创建一个新的对象,A变B 不变;浅克隆只是复制了数据类型,但是引用没变 A变B 变:
克隆方法分为两种 继承cloneable重写其clone方法实现克隆,
推荐使用 序列化和反序列化实现克隆:先将对象序列化为 流,再将其反序列化为对象 ,对象需要继承Serializable;
适配器模式
就像是充电器:将 220V电压 转为 手机的符合电压
分为三种:
类适配器 :适配器 继承 被适配 (类的形式)并实现 目标类的接口,重写方法将 被适配的数据 转换为 目标的数据 ;
如:适配类 继承 输出220V的类 并实现 输出5V的接口,重写输出5V的方法,将220V的电压转为 5V的电压输出。
对象适配器 : 适配器 关联 被适配的 (对象的形式).
和类适配器类似,只是将 继承 被适配类 改为在 适配器类内部 实现 被适配类的对象,从而将对象的220V转为 5V输出
接口适配器 :当不需要全部实现接口的方法时,可以先设计一个抽象类的实现接口,并为 该接口中的每个方法提供一个默认实现方法(空方法)
那么,该抽象类的子类 可以有选择的覆盖父类的某些方法 来实现需求。
工厂模式
将创建对象的实例 统一放到 工厂类中统一管理,需要哪种对象就调用这个类的创建对象的方法,返回相应的对象
简单工厂模式:比如有很多种披萨的种类,每个种类是一个对象,将创建这些种类实例的方法放进一个工厂类中,需要哪种对象就调用这个工厂的方法,返回相应的对象
在读取 表的时候,根据 表的格式不同 创建不同的对象实例。
工厂方法模式:比如 有很多种披萨的种类,每一种有分不同的地方,比如伦敦的牛肉披萨,北京的牛肉披萨。将披萨类作为抽象总工厂类,定义个创建对象的抽象方法,由不同地区的子工厂类继承这个抽象类,并实现这个抽象方法,根据不同地区不同种类 创建对象
抽象工厂模式:可以说 是对简单工厂的进一步抽象,把简单工厂的工厂类改成 接口,包含创建实例的方法,由不同字工厂类实现 它,并重写创建实例的方法,需要哪种对象就调用这个工厂的方法,返回相应的对象
观察者模式:
类似于 发布订阅,当天气发送变化,气象局将天气信息发送到百度和新浪网站,网站接受后进行更新展示
比如百度、新浪连接气象局获取实时的天气情况,此时 百度和新浪就是观察者,定义个接口,内有 更新天气信息的方法,参数是天气,观察者实现这个接口,并重写更新信息方法,对天气信息赋值后调用展示信息的方法。
再定义一个接口,接口内有注册,移除,更新的方法,气象局类,去实现这个接口,有 观察者集合变量,重写注册方法会将观察者对象加入到 集合中,重写更新数据的方法,会遍历调用所有观察者的更新方法,实现 观察者实时获取发布的信息。
建造者模式,
主要是将对象和创建对象的细节进去拆分,比如创建一个房子,外部得到一个 房子对象,并不需要知道房子是怎么建的,
如果有个房子类,有变量 墙 和地基,首先创建个建造房子抽象类,内有砌墙和打地基的抽象方法,以及将房子对象的返回方法,创建个别墅类和普通类,别墅类继承抽象类,并重写其中的方法,输出别墅打地基,别墅砌墙,
最后有个指挥者角色的类,根据传入不同的房屋类型。进行打造不同的方法
单一职责原则
每个类只负责一个职责,比如表的实体类 只能作为实体类 不能作为 相应的参数 避免后期增加或减少响应的参数
接口隔离原则
将接口分成几个接口,避免一个类实现接口,重写不需要的方法。
依赖倒转原则
类似于 多态 ,
A 实现接口,根据不同的参数对象 得到不同的结果。
里氏替换原则
子类不重写 父类的方法
迪米特原则
类中要有直接朋友 不要陌生朋友
直接朋友:成员变量、方法的参数、方法响应的参数
开闭原则
对修改功能关闭 对新增功能开放。
合成复用原则
类和类之间 尽量使用 合成 和聚合的方式 而不是使用 继承
Nginx
nginx是一个轻量级高并发服务器的反向代理服务器。
正向代理: 客户端发送请求到 代理服务器后, 代理服务器代替 客户端向指定的服务器发送请求,将响应结果返回给客户端。如 VPN,代理的是客户端
反向代理:客户端 发送请求到 代理服务器,代理服务器将请求分发到多个服务器中的一台。它代理的是i服务器
linux常用命令
- ifconfig 获取ip等信息
- hostname :获取主机名
- systemctl status 服务名:查看服务的状态
- systemctl stop 服务:关闭服务
- systemctl start 服务:开启服务
- man 命令:获取该命令的帮助信息手册
- help 命令:获取内嵌命令 如cd 的帮助手册
- history:查看历史命令
- pwd :当前绝对路径
- mkdir :创建文件夹
- rmdir :删除文件夹 -f 强制删除
- cp 复制 mv 移动
- cat 文件:查看文件内容
- cat 文件1 > 文件2:文件1内容写入并覆盖文件2
- cat 文件1 >> 文件2:文件1内容追加文件2
- useradd 用户名:新增用户
- passwd 用户名:给用户设置密码
- id 用户名:判断用户是否存在
- 切换用户
sudo 命令需要输入当前用户的密码,
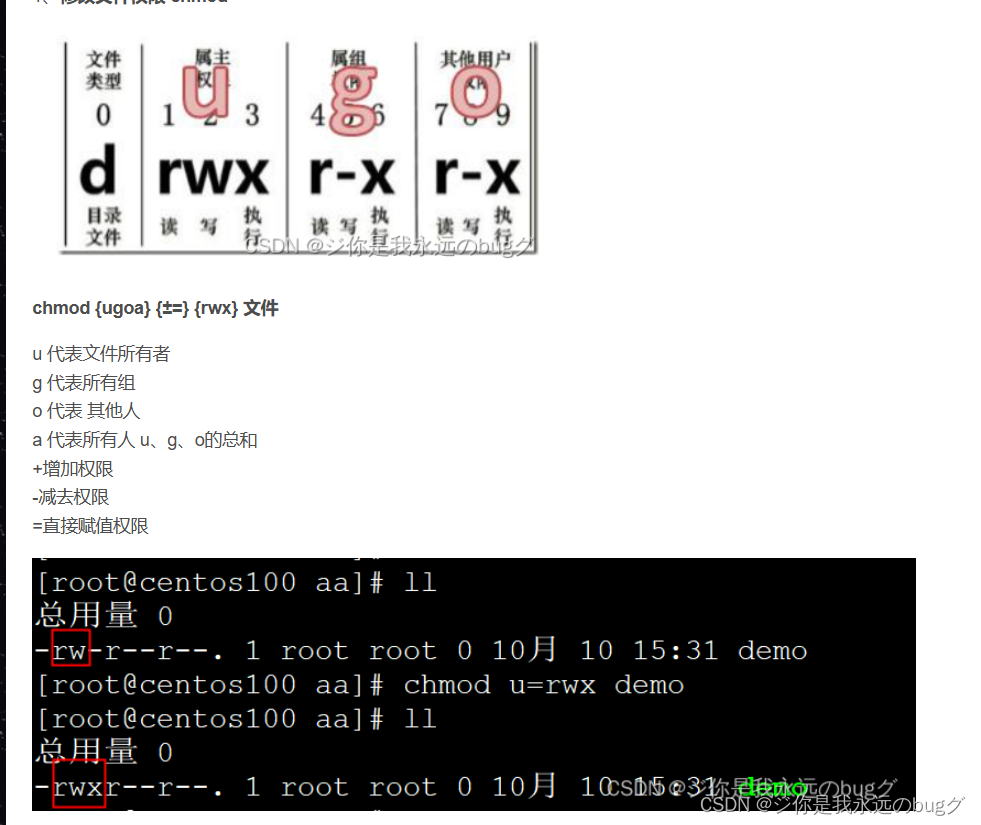
su 命令需要输入 root 用户的密码 - chmod 修改文件操作权限
- find 文件名:查找文件 -name 根据名字查 等
- locate 文件:查询文件路径
- | grep 对查找的内容进行筛选
- gzip 、gunzip:压缩成.gz,解包
- zip 、unzip:压缩成 zip 解包
- du 文件路径 -h :查看文件占用磁盘大小
- free -h :查看内存使用情况
- ps aux:查看 进程状态
- kill 进程号:终止进程
- top:查看系统资源占用
- netstat:查看网络状态和端口占用
docker
如何保证 各个环境的代码都可以运行,避免在我本机可以运行在测试环境跑不起来,可以使用docker,将代码打包成镜像,内涵代码和运行环境,将dev环境复制测试环境,可以保证代码在贝格环境都可以运行。
docker组成
镜像、容器、仓库
将代码构建成镜像,镜像运行成容器,仓库就是存放镜像的地方
镜像是分层的
docker pull tomcat
拉取 tomcat镜像时,tomcat是一层层的下载的
镜像为什么分层
比如 镜像10有很多功能,比较大,但我不需要,只需要2的版本,我就可以只下载2的版本,在2版本的基础上再添加我需要的功能后,commit提交新的镜像版本
docker run的原理
-先从本地找镜像,有的话直接运行成容器,没有就去 docker hub下载,下载不到就报错
为什么docker比虚拟机快
虚拟机内部装了一整套操作系统,用到的用不到的都装了
docker只装需要的环境,与宿主机共用一个操作系统效率高且轻量
命令
- docker images 列出所有镜像
- docker search 镜像,查询镜像各个版本信息
- docker pull 镜像:下载镜像
- docker rmi -f 镜像名:强制删除镜像
- docker ps:列出运行的容器
- exit 容器停止,ctrl+p+q:退出容器,不停止
- docker start 容器id:启动停止的容器
- docker restart id:重启容器
- docker stop id:停止容器
- docker kill id:强制停止容器
- docker rm -f id :删除容器
- docker run -d 镜像:启动守护式容器,后台运行,如redis
- docker logs id:查看容器日志
- docker top id :查看容器运行进程
- docker exec-it:开启新的终端,exit不会让容器停止,只是退出当前终端
- docker cp 容器ID:容器内路径 目的主机路径:备份容器文件到主机
- docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名:容器数据的持久化,数据实时更新到 宿主机目录中。容器停止后再运行 会加载主机的文件 恢复数据
docker 构建镜像
1、编写dockerFile文件
在基础镜像上,频繁新增功能,不需要每次都commit,只需要在 docker file编写list功能列表,docker file一次提交
2、docker build -t 命令构建镜像
3、docker run 运行镜像成容器
虚悬镜像
在构建镜像或者删除镜像时 报错,会导致出现镜像仓库和tag为none的情况,这个报错生成的镜像就是 虚悬镜像。
删除虚悬镜像 docker image prune
















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









