






SQL题目201:查找薪水记录超过15条的员工号emp_no以及其对应的记录次数t
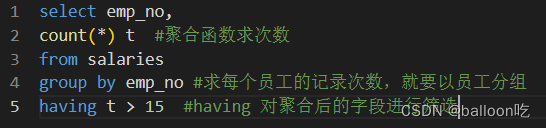
注:group by 后的字段是聚合依据,就是分组依据。非聚合字段全部要作为聚合依据。
若select中有除了聚合字段之外的其他字段,则聚合函数必须要与group by连用;若要单独使用聚合函数,则select中只能有聚合函数一个字段。
使用聚合函数时,select子句中一般只能存在以下三种元素:常数、聚合函数,group by 指定的列名。
SQL题目204:获取所有非manager 的员工emp_no

注:判断条件为空时条件为 [字段名 is null]
SQL题目205:获取所有员工当前的Manager.
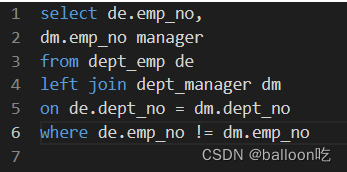
(这道题好像没啥问题,就是一开始做的时候看错题目了,没有排除员工和经理是同一人的情况。)
SQL题目206:获取每个部门中当前员工薪水最高的相关信息。
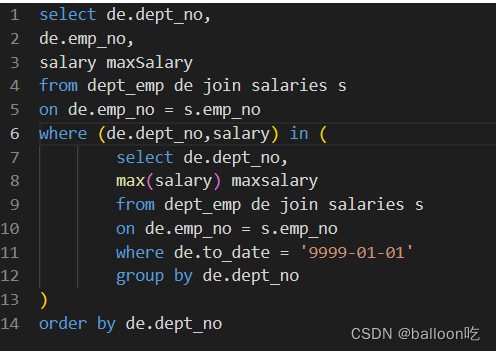
注:group by后的字段必须包括select 后的所有非聚合字段,若需要筛选非聚合依据时,将聚合后的数据形成一张新表进行筛选。
SQL题目212:获取当前薪水第二多的员工的emp_no以及其对应的薪水salary。(不能使用order by)
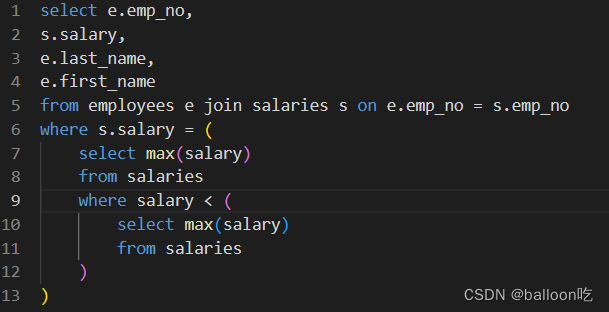
注:多层子循环,将小于最大工资的工资成为一个新表,新表的最大工资就是第二大的工资。
SQL题目215:查找在职员工自入职以来的薪水涨幅情况。
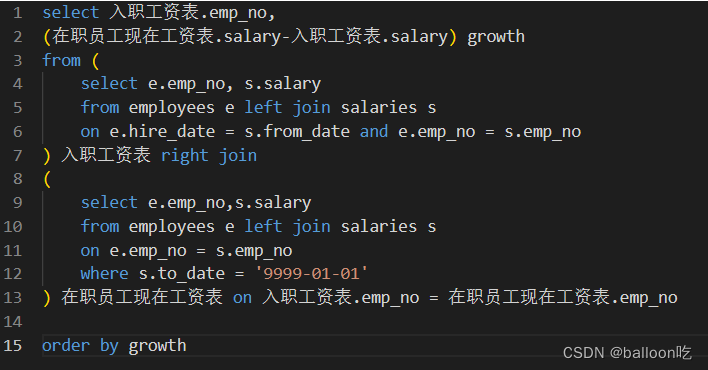
注:求差值可以利用两张表,一张现在工资表,一张入职工资表
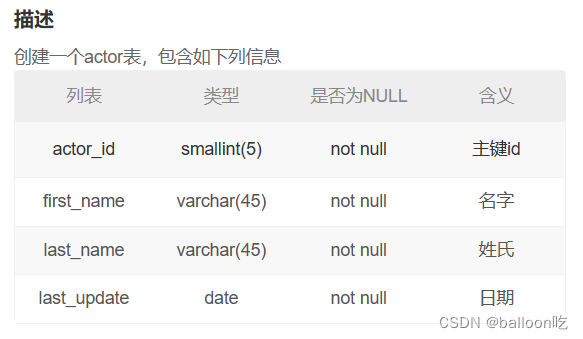
SQL题目227:创建一个actor表,包含如下列信息。
代码如下:
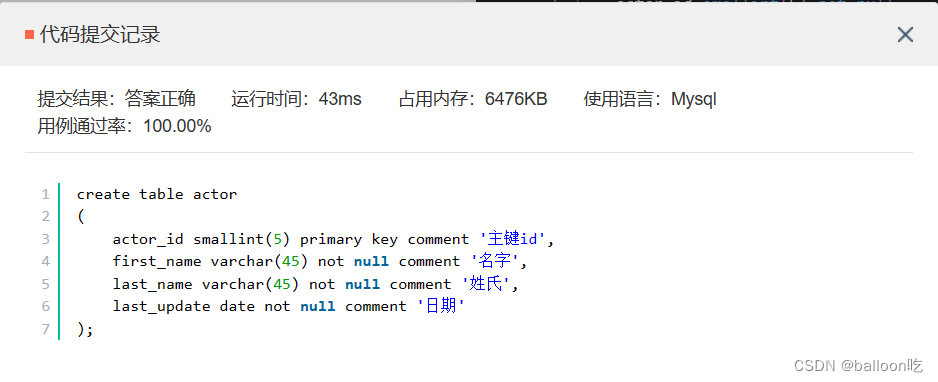
注:创建表的语法如下:
CREATE TABLE table_name
(
column_name1 data_type(size),
column_name2 data_type(size),
column_name3 data_type(size),
....
);
其中:
column_name 参数规定表中列的名称。
data_type 参数规定列的数据类型(例如 varchar、integer、decimal、date 等等)。
size 参数规定表中列的最大长度。
补:创建表的时候写注释
create table test1
(
field_name int comment '字段的注释'
)comment='表的注释';
SQL题目230:创建一个actor_name表。
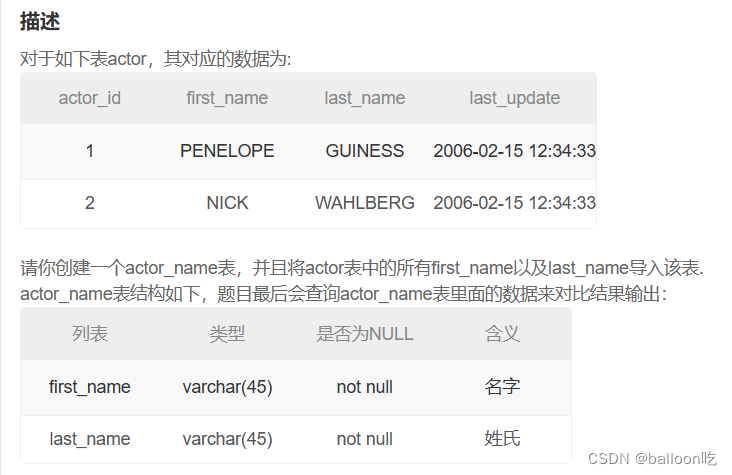
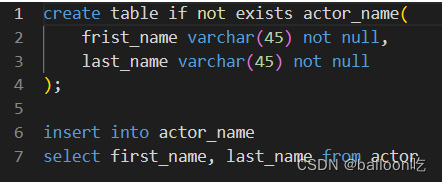
注:要在创建表的时候从另一个表中导入字段,需要在创建完成表之后插入数据
就直接从另一个表中筛选出来之后插入即可。
SQL题目231:对first_name创建唯一索引uniq_idx_firstname。
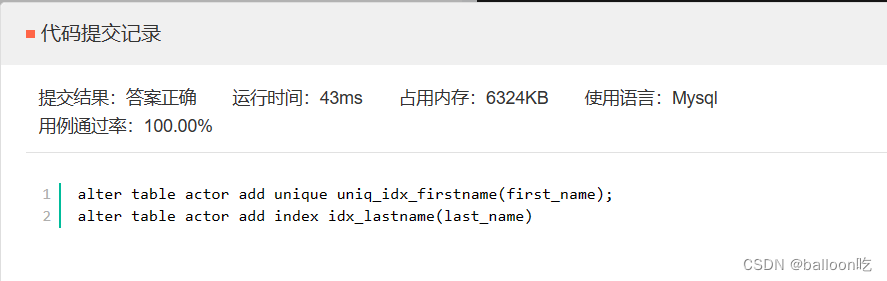
注:建表完成之后创建索引语法如下:
普通索引:alter table 表名 add index 索引名(字段名)
唯一索引:alter table 表名 add unique 索引名(字段名)
SQL题目232:针对actor表创建视图actor_name_view。
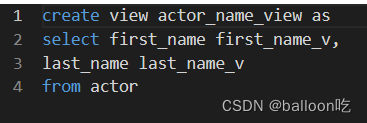
注:创建视图语法如下:
create view 视图名 as select语句
select语句中from后不能有子查询语句
SQL题目233:针对上面的salaries表emp_no字段创建索引idx_emp_no。

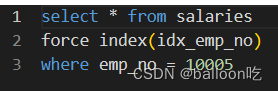
注:强制索引
SELECT……
FROM ……
FORCE INDEX(index_name)
WHERE……
SQL题目234:在last_update后面新增加一列名字为create_date。
last_update后面新增加一列名字为create_date, 类型为datetime, NOT NULL,默认值为'2020-10-01 00:00:00'

注:新加列
ALTER TABLE table_name
ADD column_name column_definition;
SQL题目235:构造一个触发器audit_log。
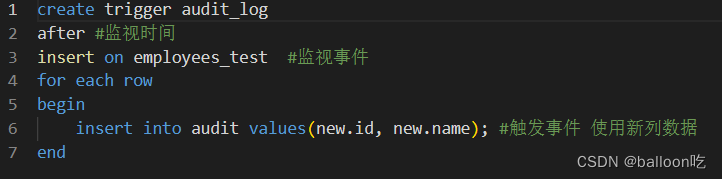
注:构建触发器
在MySQL中,创建触发器语法如下:
CREATE TRIGGER trigger_name
trigger_time trigger_event ON tbl_name
FOR EACH ROW
trigger_stmt
其中:
- trigger_name:标识触发器名称,用户自行指定;
- trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
- trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
- tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
- trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句,每条语句结束要分号结尾
SQL题目237:将所有to_date为9999-01-01的全部更新为NULL

注:①sql更新表数据语法如下:
update 表名
set 列1 = 值1, 列2 = 值2
where 条件
order by 按照指定的顺序对行进行更新
limit 限制更新的行数
②替换数据如下:
替换数据replace
replace into table_name (col_name...) values (col_value...);
补:update和replace一起用
语法:
update 表名
set 列=replace(field,search,replace)
where 条件...
说明:field - 数据库表的列名
search - 需要替换的字符串
replace - 替换成的字符串
③ALTER TABLE + 修改的表+修改内容/方式
- ALTER TABLE 表名 ADD 列名/索引/主键/外键等;
- ALTER TABLE 表名 DROP 列名/索引/主键/外键等;
- ALTER TABLE 表名 ALTER 仅用来改变某列的默认值;
- ALTER TABLE 表名 RENAME 列名/索引名 TO 新的列名/新索引名;
- ALTER TABLE 表名 RENAME TO/AS 新表名;
- ALTER TABLE 表名 MODIFY 列的定义但不改变列名;
- ALTER TABLE 表名 CHANGE 列名和定义都可以改变。
④创建外键约束
ALTER TABLE <数据表名> ADD CONSTRAINT <外键名>
FOREIGN KEY(<列名>) REFERENCES <主表名> (<列名>)SQL题目247:按照dept_no进行汇总,属于同一个部门的emp_no按照逗号进行连接,结果给出dept_no以及连接出的结果。
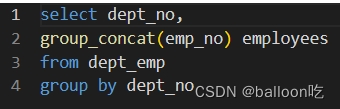
注:
group_concat(X,Y)X为要连接的字段,Y为连接的符号,默认为逗号,逗号时可以不写
group_concat()函数将group by 产生的同一个分组中的值连接起来,返回一个字符串结果。
SQL题目259:异常的邮件概率,统计正常用户发送给正常用户邮件失败的概率。
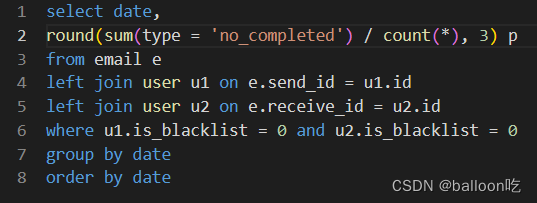
注:count(条件表达式),不管记录是否满足条件表达式,只要非NULL就加1。
sum(条件表达式),只有记录满足条件表达式,才加1。
SQL题目262:牛客每个人最近的登陆日期(三):牛客每天有很多人登录,请你统计一下牛客新登录用户的次日成功的留存率。
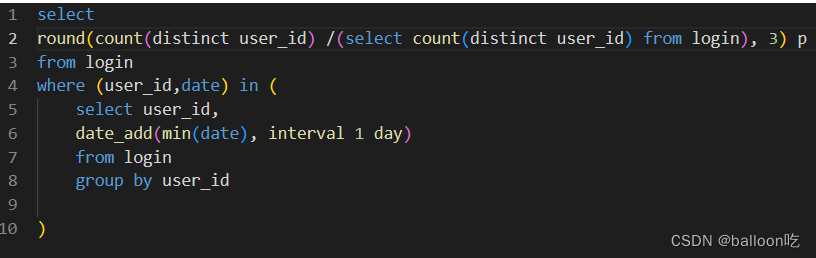
思路:

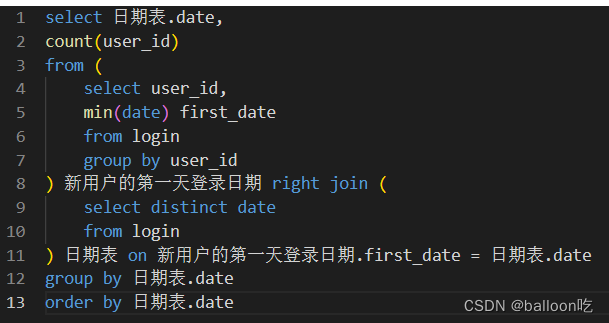
SQL题目263:牛客每个人最近的登陆日期(四),统计一下牛客每个日期登录新用户个数
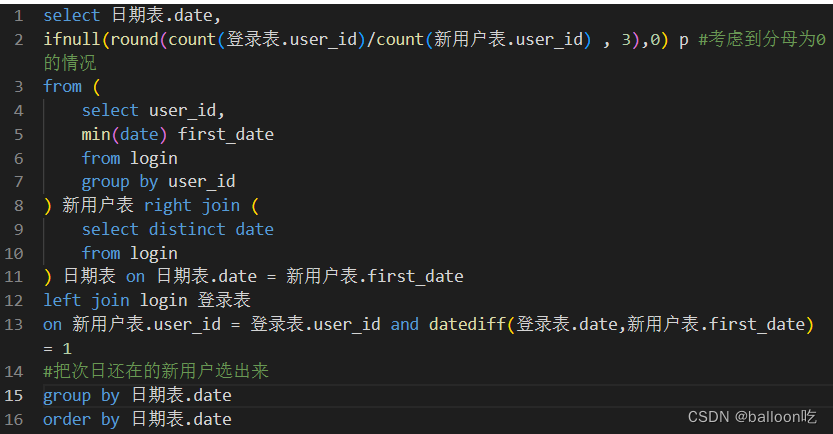
SQL题目264:牛客每个人最近的登陆日期(五),统计一下牛客每个日期新用户的次日留存率。
SQL题目265:牛客每个人最近的登陆日期(六),统计一下牛客每个用户刷题情况,包括: 用户的名字,以及截止到某天,累计总共通过了多少题。 不存在没有登录却刷题的情况,但存在登录了没刷题的情况,不会存在刷题表里面,会存在提交代码没有通过的情况并记录在刷题表里,通过数目是0。
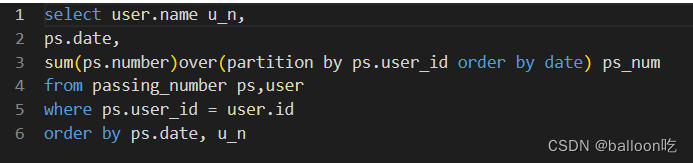
注:某个数据及其该行以上数据进行聚合时,利用聚合函数的窗口函数。
SQL题目269:考试分数(四),写一个sql语句查询各个岗位分数升序排列之后的中位数位置的范围,并且按job升序排序。
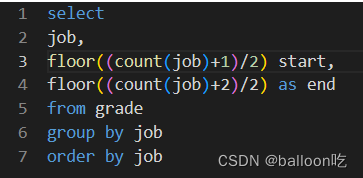
注:求中位数位置范围
start: floor((count(*) + 1) / 2)
end: floor((count(*) + 2 ) / 2)
floor函数向下取整,ceil()/ceiling()向上取整。
SQL题目270:考试分数(五),写一个sql语句查询各个岗位分数的中位数位置上的所有grade信息,并且按id升序排序。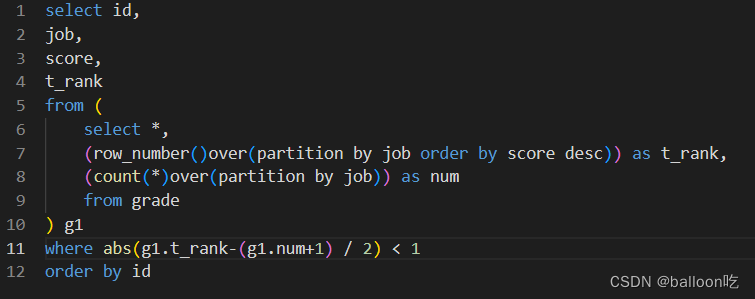
注:返回数值表达式的绝对值的数值函数abs.
求中位数:abs(中位数的位置-(个数+1)/2)的绝对值小于1。
SQL题目280:实习广场投递简历分析(三),写出SQL语句查询在2025年投递简历的每个岗位,每一个月内收到简历的数目,和对应的2026年的同一个月同岗位,收到简历的数目,最后的结果先按first_year_mon月份降序,再按job降序排序显示。
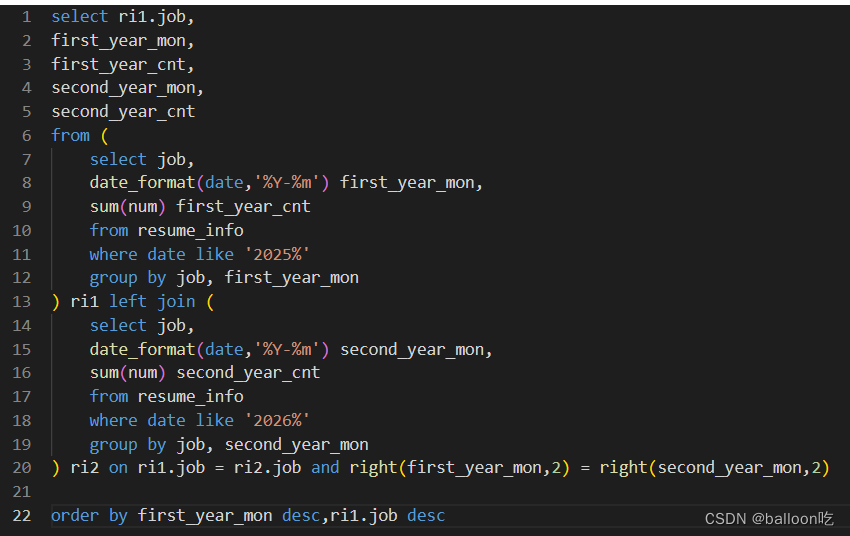
注:确保不同年份的月份相同(日期格式为年-月)只需保证后两位数字相同就可以保证月份相同,可以用right()函数取值。
SQL题目282:最差是第几名(二),老师想知道学生们综合成绩的中位数是什么档位,请你写SQL帮忙查询一下,如果只有1个中位数,输出1个,如果有2个中位数,按grade升序输出。
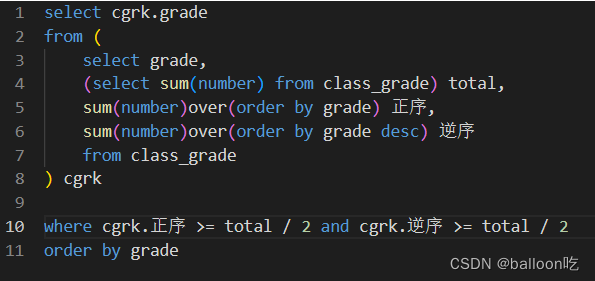
注:找中位数,中位数所在的位置经过正序和逆序排序之后,其位置均>=整个序列的一半。
select当中也可以有子查询。若要用聚合函数,且select字段当中有非聚合字段时,必须要以非聚合字段为聚合依据,所以求sum(number)时需要用一个单独的子查询才嫩找出整个表的总和。
SQL题目287:网易云音乐推荐,编写一个SQL,查询向user_id = 1 的用户,推荐其关注的人喜欢的音乐。不要推荐该用户已经喜欢的音乐,并且按music的id升序排列。
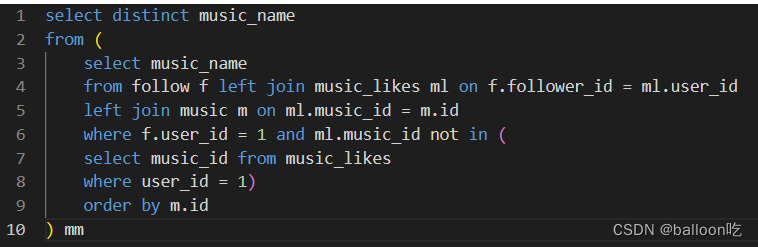
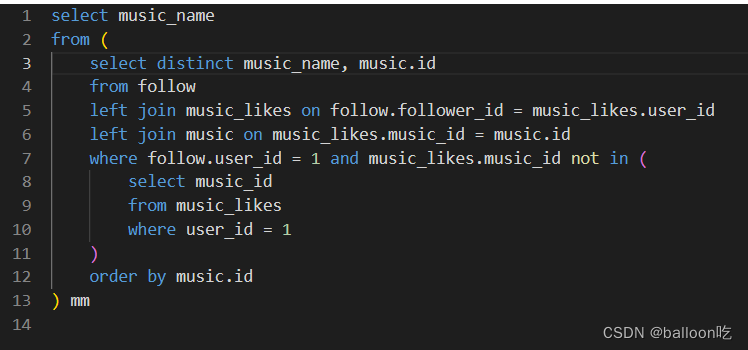
注:distinct若要和order by 连用时order by后的字段必须在select当中出现。distinct必须要放在筛选字段的最前面。
如果不这样,因为先执行distinct去重产生虚拟表,在此虚拟表的基础上进行order by,由于虚拟表没有order by的字段,产生报错
okkkk!!!结束啦!!!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









