






Java 累加合计,性能测试(初步走入 Java 8 新特性实战)
文章目录
在做页面 excel 合计的时候,发现的这个问题,想要找到一种快速优雅的写法,大概原因就是因为,嗯我没有眼睛,机器不相信自己的眼睛,那种因为看错,或者随手打错的不易发现的 bug 实在是太烦了,尤其调 sql 时候的 bug 你的眼睛有可能在骗你,所以写出来可读性强性能好的代码能有效减少不易发现的 bug 的产生 . 所以有了以下
茴香的茴字有几种写法的神奇代码,当然只是选了几种实现,以我有d限的知识水平来简单测试性能列举,选出我比较喜欢的.当然,以下计算都绝对精确,用双精度类型 double 来计算,场景就是精确度不需要太高的场景下
几种实现(茴字的同写法)
自定义计数器
这也是我的第一版本计算和的方案,想法是做个通用的,不需要我自己去一个个 new 新的字段存储总合的,具体最后有值加进来应该有程序灵活创建.
实现思路
- HashMap 经典工作算法,我用 key 存储字段名称,value 存储累加后的值.
- 边界,有那些值是不需要计算累加的,那些是不用累加的,我需要一个黑名单来帮助我过滤条件.
- 遍历集合内每一个元素,如果元素在我自定义的累加器(即语言创建的map 中),就取map 的值,然后相加存储回去,如果不在就直接存储.
- 转换,数据来回转换,以一种同样的方式存储计算.
最后实现如下
private static void singleStream(List<Map<String, Object>> calculateList, List<String> ignoreList) { StopWatch stopWatch = new StopWatch(); stopWatch.start(); Map<String, Object> sumByType = new HashMap<>(); for (Map<String, Object> record : calculateList) { for (Map.Entry<String, Object> entry : record.entrySet()) { // 忽略组合计算清单 String key = entry.getKey(); if (ignoreList.contains(key)) { continue; } Object value = entry.getValue(); double newValue = Double.parseDouble(value.toString()); // 计算浮点数类型字段的和 if (sumByType.containsKey(key)) { // 已有键新增值 double oldValue = Double.parseDouble((String) sumByType.get(key)); newValue = oldValue + newValue; sumByType.put(key, String.valueOf(newValue)); } else { sumByType.put(key, value.toString()); } } } }当然实现了基本功能,但是有问题,我的 list 只能是 map 类型的,如果换成具体实体类还得重新写,换一个更加通用化的算法,并且,在每一次从map 里存储数据拉取数据都耗费时间,这段文字的时候我注意到如果将最后自己的累加器定义成 Map<String,Double> 类型会更快.
存在问题,从算法的角度,应该有更快的方案,就单论这种实现而言
ps 本人单薄的算法知识不支持我继续太深入了,本片文章的参考意义在于从茴字的写法打破大家的一些刻板印象
使用单条流一项一项的计算数据
当然这种是我抄来的代码,大概写法就是用了下面的句式,函数式编程的一些特性,当时学的时候简单知道是什么大概怎么做,平时写的代码大概也都是指令式多一些,当然有些用到函数式编程的思想,或者说有些函数式编程的东西很自然的看着就学会了,一些简单的操作也会用流代替循环,但是没有特意看过,只知道流内部迭代,流比循环快.
当我抄代码的时候我懵了,因为一共块 20 个计算项,叠在一起这么写在我当时 流 = 优化的循环看来,就是一个循能解决的问题 20 个循环来做着所以就在想了都用流了能不能就单纯用流搞定那,像我上面循环的写法一样然后嗯就去看了 Java 8 实战,现在看一半了,看完后写出来了纯流的办法,当理解透了流之后可能会写出更快的,但是现阶段,嗯简单的搞一下对照也够了.
stream().mapToDouble(map -> Double.parseDouble(ToDoubleFunction<? super T> mapper).sum())HashMap<String, Object> sumByType = new HashMap<>(); sumByType.put("calculated_value_1", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("calculated_value_1").toString())).sum());
流 + 循环 (上面的完善版本)
Don’t repeat yourself (DRY) 原则,让我本能的感觉的了不优雅(主要是对自己的不自信,高强度编码的时候脑子转速快的话,有的时候手打会出现一些小错误,比如 ctrl v 没 v 上,当我长时间盯着电脑看,眼睛也欺骗了我的时候有些隐式 bug 会搞死人的心态),对上面的写法优化了下之后就变成了下面这样.
由两层循环决定,外层循环只要决定那些需要计算的,我需要维护一个待计算列表就好了.
private static HashMap<String, Double> calculateSumByType(List<Map<String, Object>> calculateList, List<String> fields) { HashMap<String, Double> sumByType = new HashMap<>(); for (String field : fields) { double sum = calculateList.stream() .mapToDouble(map -> Double.parseDouble(map.get(field).toString())) .sum(); sumByType.put(field, sum); } return sumByType; }
纯流计算版本
当我看完了版本书之后,跃跃欲试了,开始写下了下面的版本,它用极少的代码优雅的实现了我计算的目的,可读性也是当前最好的,只需要知道大概每一步什么意思可以轻松的看出来要做什么,可维护性极佳.
设计实现
入参 : 1. 要遍历的列表 , 2. 黑名单 list(那些不计算
ps 一般不计算值比计算值少,好维护,列表短,性能会好一些)实现用到的语法糖简单介绍
推荐兄弟们去看 Jasva 8 实战
- stream() : 生成流 (操作数据源)
- .flatMap() : 将流抚平成新流 (可以看作原先的流是关起来的擅自,该操作是打开扇子) ,将数据源以指定最小粒度抚平展开,便于计算.
- .filter() : 过滤掉不需要的不数据返回一个谓词,true 进入下一层级.
- .collect() : 终端操作,流只能使用一次,遇见终端操作被消费. collect 终端操作为收集操作,有些为计算,比如 sum() 也是终端操作.
- Collectors.groupingBy() : 分组操作,对收集集合分组,支持多层级分组. 在这个语句中终端操作是通过 分组操作,指定分组时嵌套 summingDouble 来完成的按照不同的 key 去累加收集.
private static void streamGroupingBy(List<Map<String, Object>> simulatedData, List<String> strings) { Map<String, Double> sumByType = simulatedData.stream() .flatMap(map -> map.entrySet().stream()) .filter(entry -> strings.stream().noneMatch(b -> entry.getKey().equals(b))) .collect(Collectors.groupingBy( Map.Entry::getKey, Collectors.summingDouble(entry -> Double.parseDouble(entry.getValue().toString())) )); }
并行流版本
此版本为上一版本的优化, 用
parallelStream()方法,其他操作合上一版本纯属雷同没有巧合,改动及其简单.在上面的例子中,
myList.parallelStream()返回一个并行流,而myList.stream()返回一个串行流。在使用并行流时,你应该注意多线程的安全性和一致性,确保对共享状态的访问是线程安全的。并行流并不是在所有情况下都比串行流更快,因为它涉及到线程切换和并发控制的开销。在某些情况下,特别是对于较小的数据集或简单的操作,串行流可能更为合适。因此,在使用并行流时,应该进行性能测试,以确定它是否对特定情况产生了优势。
当然啦,用的线程池为 jvm 自动管理的线程池,如果这个线程池有其他功能在使用,我们在计算的时候会影整个系统,所以如果决定使用的话给一个最大线程数是一种更明确的选择,减少突入起来的数据计算影响系统内部其他地方的可能性.
定义便量,循环累加
都到了最后,顺手就把最基础的,也就是一开始就会的方案带上吧,虽然它看起来最不优雅,写起来也很是麻烦,但是嗯带着吧(哈哈哈哈哈,其实有个坑啊,到时候就懂了) 当然啦,最朴素的逻辑就放一段,下面详细测试代码里可以看到完整逻辑.
private static void originalAddition(List<Map<String, Object>> calculateList) { StopWatch stopWatch = new StopWatch(); stopWatch.start(); double calculatedValue1 = 0.0; double calculatedValue2 = 0.0; for (Map<String, Object> map : calculateList) { calculatedValue1 += Double.parseDouble(map.get("calculated_value_1").toString()); calculatedValue2 += Double.parseDouble(map.get("calculated_value_2").toString()); } HashMap<String, Object> res = new HashMap<>(); res.put("calculatedValue1", calculatedValue1); res.put("calculatedValue2", calculatedValue2); }
测试部分
实践是检验真理的唯一标准,测试部分主要有两份测试报告,一份完整的测试代码,和一些反常现象和其背后的一些逻辑组成,当然啦,肯定是能优化的,但是老规矩先挖坑.
先上测试代码,最后给出两份执行的结果分别说一下情况,代码由几部分组成
- 调用部分,统一调用测试不同实现效率在不同数量级别下的情况.
- 实现部分,列举不同实现
- 数据生成部分,因为肯定不能那实际业务代码出来看,也不能用实际上数据,所以我只能模拟一个有着十几列的 list 来完成剩下的部分,他有着需计算总和的部分,和不需要计算总和的部分,模拟实际情况.
- 测试形式,注掉不需要的代码,不如我想看过滤不需要累加求和的数据对各种实现的影响,那我就在各个部分注释掉它,在代码中加入 stopWatch 来检测代码的运行实践,已经输出写参数方便我判断,也会通过增加减少参数列来实现模拟我有不同多的参数列,(注释掉,或者新写一个).
测试代码
package com.yidiansishiyi.aimodule.job.once;
import org.springframework.util.StopWatch;
import java.util.*;
import java.util.stream.Collectors;
public class SimulatedDataGenerator {
static int TEN = 10;
static int HUNDRED = 100;
static int THOUSAND = 1000;
static int TEN_THOUSAND = 10000;
static int ONE_HUNDRED_THOUSAND = 100000;
static int MILLION = 1000000;
static int TEN_MILLION = 10000000;
static int BILLION = 100000000;
public static void main(String[] args) {
List<Integer> integers = Arrays.asList(TEN, HUNDRED, THOUSAND, TEN_THOUSAND, ONE_HUNDRED_THOUSAND, MILLION);
for (int order : integers) {
List<Map<String, Object>> simulatedData = generateSimulatedData(order);
System.out.println("数量分组 " + order + " 条下性能报告: (单位毫秒)");
// 忽略清单, 部分不列举在累加内的参数
List<String> ignoreList = Arrays.asList("gender", "non_calculable_1", "id", "name", "non-calculable", "non_calculable_2");
// 流分组计算
streamGroupingBy(simulatedData, ignoreList);
// 自定义累加器去计算
singleStream(simulatedData, ignoreList);
// 并行流分组计算
parallelStreamGroupingBy(simulatedData, ignoreList);
// 单条流去计算
singleStream(simulatedData);
// 原始定义变量相加
originalAddition(simulatedData);
List<String> actualColumn = Arrays.asList("calculated_value_1", "calculated_value_2", "txt4", "txt2", "txt3", "calculated_value_3", "bonus", "txt1", "salary", "age", "expenses");
calculateSumByType(simulatedData, actualColumn);
}
}
private static void originalAddition(List<Map<String, Object>> calculateList) {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
double calculatedValue1 = 0.0;
double calculatedValue2 = 0.0;
double txt4 = 0.0;
double txt2 = 0.0;
double txt3 = 0.0;
double calculatedValue3 = 0.0;
double bonus = 0.0;
double txt1 = 0.0;
double salary = 0.0;
double age = 0.0;
double expenses = 0.0;
for (Map<String, Object> map : calculateList) {
calculatedValue1 += Double.parseDouble(map.get("calculated_value_1").toString());
calculatedValue2 += Double.parseDouble(map.get("calculated_value_2").toString());
txt4 += Double.parseDouble(map.get("txt4").toString());
txt2 += Double.parseDouble(map.get("txt2").toString());
txt3 += Double.parseDouble(map.get("txt3").toString());
calculatedValue3 += Double.parseDouble(map.get("calculated_value_3").toString());
bonus += Double.parseDouble(map.get("bonus").toString());
txt1 += Double.parseDouble(map.get("txt1").toString());
salary += Double.parseDouble(map.get("salary").toString());
age += Double.parseDouble(map.get("age").toString());
expenses += Double.parseDouble(map.get("expenses").toString());
}
HashMap<String, Object> res = new HashMap<>();
res.put("calculatedValue1", calculatedValue1);
res.put("calculatedValue2", calculatedValue2);
res.put("calculatedValue3", calculatedValue3);
res.put("txt4", txt4);
res.put("txt2", txt2);
res.put("txt3", txt3);
res.put("txt1", txt1);
res.put("bonus", bonus);
res.put("salary", salary);
res.put("age", age);
res.put("expenses", expenses);
stopWatch.stop();
System.out.print("原始定义变量相加 :");
System.out.println(stopWatch.getTotalTimeMillis());
// 打印前 结果
// sumByType.forEach((key, value) -> System.out.println(key + ":" + value));
}
private static HashMap<String, Double> calculateSumByType(List<Map<String, Object>> calculateList, List<String> fields) {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
HashMap<String, Double> sumByType = new HashMap<>();
for (String field : fields) {
double sum = calculateList.stream()
.mapToDouble(map -> Double.parseDouble(map.get(field).toString()))
.sum();
sumByType.put(field, sum);
}
stopWatch.stop();
System.out.print("流加循环 :");
System.out.println(stopWatch.getTotalTimeMillis());
return sumByType;
}
private static void singleStream(List<Map<String, Object>> calculateList) {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
HashMap<String, Object> sumByType = new HashMap<>();
sumByType.put("calculated_value_1", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("calculated_value_1").toString())).sum());
sumByType.put("calculated_value_2", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("calculated_value_2").toString())).sum());
sumByType.put("txt4", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("txt4").toString())).sum());
sumByType.put("txt2", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("txt2").toString())).sum());
sumByType.put("txt3", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("txt3").toString())).sum());
sumByType.put("calculated_value_3", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("calculated_value_3").toString())).sum());
sumByType.put("bonus", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("bonus").toString())).sum());
sumByType.put("txt1", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("txt1").toString())).sum());
sumByType.put("salary", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("salary").toString())).sum());
sumByType.put("age", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("age").toString())).sum());
sumByType.put("expenses", calculateList.stream().mapToDouble(map -> Double.parseDouble(map.get("expenses").toString())).sum());
stopWatch.stop();
System.out.print("单条流去计算 :");
System.out.println(stopWatch.getTotalTimeMillis());
// 打印前 结果
// sumByType.forEach((key, value) -> System.out.println(key + ":" + value));
}
private static void singleStream(List<Map<String, Object>> calculateList, List<String> ignoreList) {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Map<String, Object> sumByType = new HashMap<>();
for (Map<String, Object> record : calculateList) {
for (Map.Entry<String, Object> entry : record.entrySet()) {
// 忽略组合计算清单
String key = entry.getKey();
if (ignoreList.contains(key)) {
continue;
}
// double newValue = 0.0;
// Object value = entry.getValue();
// // 计算参数转换 (如扩展其他类型数据补全改结构)
// if (value instanceof BigDecimal) {
// newValue = ((BigDecimal) value).doubleValue();
// } else if (value instanceof String) {
// newValue = Double.valueOf((String) value);
// } else {
// continue;
// }
Object value = entry.getValue();
double newValue = Double.parseDouble(value.toString());
// 计算浮点数类型字段的和
if (sumByType.containsKey(key)) {
// 已有键新增值
double oldValue = Double.parseDouble((String) sumByType.get(key));
newValue = oldValue + newValue;
sumByType.put(key, String.valueOf(newValue));
} else {
sumByType.put(key, value.toString());
}
}
}
stopWatch.stop();
System.out.print("自定义累加器去计算 :");
System.out.println(stopWatch.getTotalTimeMillis());
// 打印前 结果
// sumByType.forEach((key, value) -> System.out.println(key + ":" + value));
}
// 流计算
private static void streamGroupingBy(List<Map<String, Object>> simulatedData, List<String> strings) {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Map<String, Double> sumByType = simulatedData.stream()
.flatMap(map -> map.entrySet().stream())
.filter(entry -> strings.stream().noneMatch(b -> entry.getKey().equals(b)))
.collect(Collectors.groupingBy(
Map.Entry::getKey,
Collectors.summingDouble(entry -> Double.parseDouble(entry.getValue().toString()))
));
stopWatch.stop();
System.out.print("流分组计算 :");
System.out.println(stopWatch.getTotalTimeMillis());
// 打印前 结果
// sumByType.forEach((key, value) -> System.out.println(key + ":" + value));
}
private static void parallelStreamGroupingBy(List<Map<String, Object>> simulatedData, List<String> strings) {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Map<String, Double> sumByType = simulatedData.parallelStream()
.flatMap(map -> map.entrySet().stream())
.filter(entry -> strings.stream().noneMatch(b -> entry.getKey().equals(b)))
.collect(Collectors.groupingBy(
Map.Entry::getKey,
Collectors.summingDouble(entry -> Double.parseDouble(entry.getValue().toString()))
));
stopWatch.stop();
System.out.print("并行流分组计算 :");
System.out.println(stopWatch.getTotalTimeMillis());
// 打印前 结果
// sumByType.forEach((key, value) -> System.out.println(key + ":" + value));
}
// mork 数据生成部分
private static List<Map<String, Object>> generateSimulatedData(int dataSize) {
List<Map<String, Object>> data = new LinkedList<>();
for (int i = 0; i < dataSize; i++) {
Map<String, Object> record = new HashMap<>();
record.put("id", i);
record.put("name", "Record_" + i);
record.put("age", getRandomValue(18, 60));
record.put("gender", getRandomGender());
record.put("salary", getRandomValue(30, 80));
record.put("expenses", getRandomValue(10, 50));
record.put("bonus", getRandomValue(0, 100));
record.put("txt1", getRandomValue(0, 100));
record.put("txt2", getRandomValue(0, 100));
record.put("txt3", getRandomValue(0, 100));
record.put("txt4", getRandomValue(0, 100));
record.put("non_calculable_1", "Some non-calculable data");
record.put("non_calculable_2", "Another non-calculable data");
// 计算项
double calculatedValue1 = (double) record.get("salary") - (double) record.get("expenses");
double calculatedValue2 = (double) record.get("salary") + (double) record.get("bonus");
double calculatedValue3 = (double) record.get("expenses") / (double) record.get("age");
record.put("calculated_value_1", calculatedValue1);
record.put("calculated_value_2", calculatedValue2);
record.put("calculated_value_3", calculatedValue3);
data.add(record);
}
return data;
}
// private static double getRandomValue(double min, double max) {
// double randomValue = min + (max - min) * new Random().nextDouble();
// // 保留两位小数
// return Math.round(randomValue * 100.0) / 100.0;
// }
private static final Random random = new Random();
private static double getRandomValue(double min, double max) {
double randomValue = min + (max - min) * random.nextDouble();
// 保留两位小数
return Math.round(randomValue * 100.0) / 100.0;
}
private static String getRandomGender() {
return new Random().nextBoolean() ? "Male" : "Female";
}
}
测试中情况说明
先说结论
不管在测试集中哪个数据量情况下,从效果上看,代码最少,看起来最清晰(熟悉流语法后)完全使用流版本竟然出乎意料的是最慢的,反而最普通的原始的丑陋的,循环中写
+=的反而是最快的(当然在并行流不出手的情况下,好吧是有点耍流氓,并行流不是流吗,哈哈哈哈哈). 这一结论打败了我流效率永远优于循环的刻板印象 (当然也是我算法不到家,以后肯定能写出来更快的) . 其次写法贼抽象的
使用单条流一项一项的计算数据竟然在我最后写循环调用之前反而是第二快的(也没算并行流),果然码不可貌相,甚至当只有一个值需要计算的时候,第二种写法在 Stream 的优化先是快于循环的,果然流的内部迭代还是优化过的.不过在这个写法外面套一层循环后效率比这一条条写快,而且出错的概率还低. 直接以白名单去计算的 循环 + 流 和 硬编码的,在没有需要过滤的条件下和需要过滤的条件下没有影响,而剩下的需要判别的或多或少有些影响,
并行流在处理 1000 条这样数据以上,有着明显的优势,代码简单,速度最快.
原因
上学的时候数据结构与算法的老师说过看时间复杂度,就数循环数,看空间复杂度,就看它有没有开辟新的空间,一般程序可以在时间和空间上进行转换(有些流畅的代码源码非常大,也巨耗存储,嗯我记得有些比赛作品就挺抽象,不过最牛逼的还是
超级马里奥,将节省进行到底),从现象上看很容易 将流和循环画上等号,但是想起老师最开始讲的时间复杂度计算方式, 计算语句频度,求极限值,这才为现象画上了等号,流绝非等价于循环是循环的特殊化,先看下流最初的定义,可能和我一样,有好多人没有关心过.Java 中的流(Stream)是一种用于对集合进行处理的高级抽象。它提供了一种更为函数式的编程风格,允许你通过一系列的操作来处理数据,如过滤、映射、排序等。 流的核心思想是将数据处理操作串联起来,形成一个流水线。你可以将多个中间操作连接起来,最后添加一个终端操作来触发实际的计算。这样的设计使得流可以进行懒加载,只有在终端操作被触发时,中间操作才会被执行。当然,流的不同操作看起来是一次循环,但是流有自己的处理方式,将不同操作合并到同一次遍历中了(我们把这种技术叫作循环合并)。
当然其中肯定有优化的空间,但是要更加深入了解一些原理.
结果
不过从结果上来看,如何快速的写出简单易懂,不令人头大的代码好像已经有了结论,即使不用并行流它处理速度在大数据量下会慢一些,但是也绝对够用,能节省很多编码时间,以及在系统开发运维中可能一不小心带来的错误,没有防止四海皆准的真理,我们的一切都在现有条件的定义下才是正确的, 流不是万用银弹,但是在很多场合下是对开发有好处的,虽然需要一点时间入门,嗯等我看完那本书应该算是入门了,哈哈哈哈.这个坑是我填起来最快的,因为赶到这了,正好.
Java 8 实战,不仅仅有流的知识,函数式编程等 Java 8 特性也在其中挺好看的,当然需要一定的前置基础,不过嗯很有意思,当然和小说没得比.偶尔还是令人头大.
测试报告
数量分组 10 条下性能报告: (单位毫秒)
流分组计算 :62
自定义累加器去计算 :2
并行流分组计算 :5
单条流去计算 :4
原始定义变量相加 :0
流加循环 :0
数量分组 100 条下性能报告: (单位毫秒)
流分组计算 :10
自定义累加器去计算 :4
并行流分组计算 :3
单条流去计算 :2
原始定义变量相加 :1
流加循环 :1
数量分组 1000 条下性能报告: (单位毫秒)
流分组计算 :44
自定义累加器去计算 :26
并行流分组计算 :12
单条流去计算 :13
原始定义变量相加 :6
流加循环 :8
数量分组 10000 条下性能报告: (单位毫秒)
流分组计算 :135
自定义累加器去计算 :125
并行流分组计算 :19
单条流去计算 :49
原始定义变量相加 :40
流加循环 :38
数量分组 100000 条下性能报告: (单位毫秒)
流分组计算 :717
自定义累加器去计算 :866
并行流分组计算 :142
单条流去计算 :408
原始定义变量相加 :280
流加循环 :396
数量分组 1000000 条下性能报告: (单位毫秒)
流分组计算 :12512
自定义累加器去计算 :8803
并行流分组计算 :1553
单条流去计算 :3994
原始定义变量相加 :2724
流加循环 :3811
Process finished with exit code 0
总结
填坑部分,填掉了如何计算 合计 部分
坑
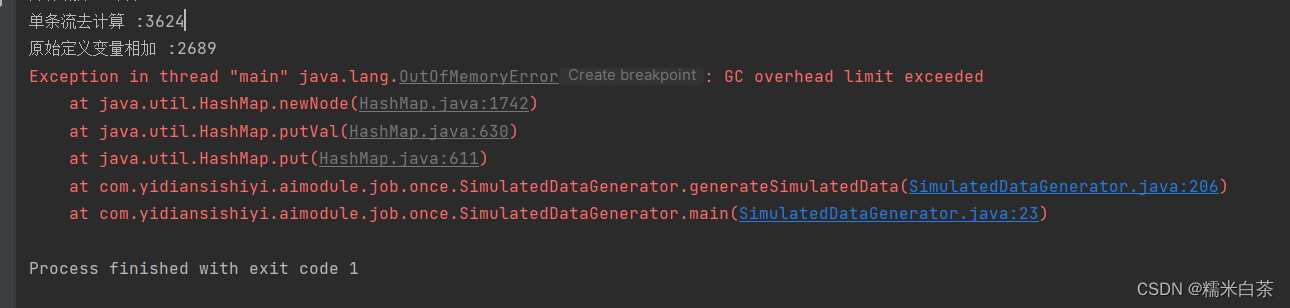
jvm 调优 ,测数据的时候有些语句太贫乏 , GC 爆了
函数式编程,虽说简单的和思想已经学了,但是熟练使用,和那些 Java 类库现有的 api 还不熟
计算精度问题,如果引入计算精度,流现有的 api 已经不满足了,得自定义,属于流的高级用法了
找类库,对我相信,这个代码一定被前辈写过了,因为场景还是相对频繁的,我应该能抄到或者是直接用现成的代码.















 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









