







1,浏览器里面的进程个数
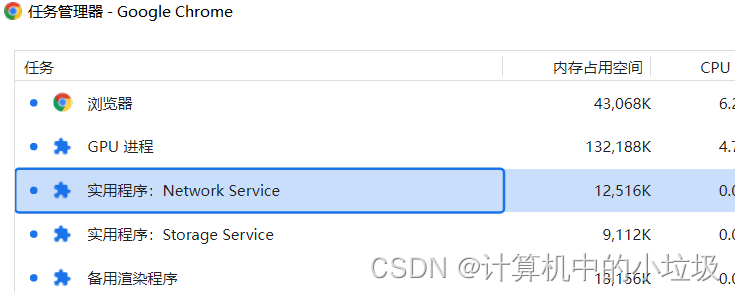
我们来说一说对于谷歌浏览器,他开启是有多少个进程。查看进程是怎么查看的呢,首先点开左上角三个点–》更多工具–》任务管理器,每个电脑打开的页面,安装的插件不同,导致的浏览器的进程也是不同的。最开始的时候,浏览器的是单进程的,页面渲染,用户交互等都是一个进程,缺点就是运行缓慢,不稳定。然后就分为四个进程,分别是,浏览器进程,渲染进程,Gpu进程,网络进程。现在的区别就是渲染进程是多个的。
-
下面来说说这几个进程的作用
-
浏览器进程:负责的就是界面的显示,用户交互,子进程的管理,还有存储功能。
-
渲染进程:我们浏览器浏览的页面,就是渲染进程弄得,吧HTML,CSS,JS转换,当然这些都是放在沙箱模式下运行,避免对主机进行破坏
-
GPU进程:这个进程看起来和CPU有点像,其实是不一样的,GPU是把3D CSS进行转换,UI界面也是使用GPU来进行绘制
-
网络进程:负责页面的的网络资源加载
-
插件进程:浏览器有许多功能是没有的,这时候就需要用插件来进行补充,但是插件又是不稳定的,所以就单独的用个进程来运行这个插件。
2,从浏览器的方向理解输入URL请求
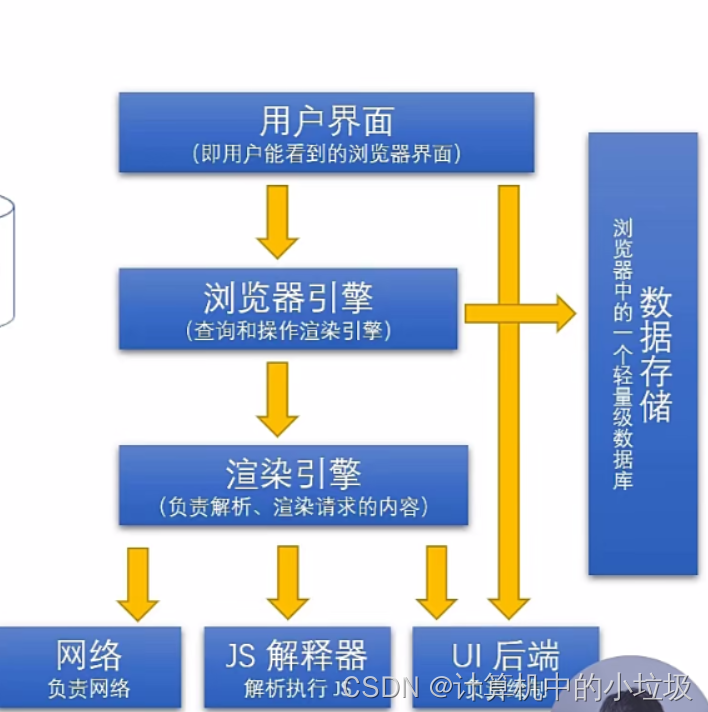
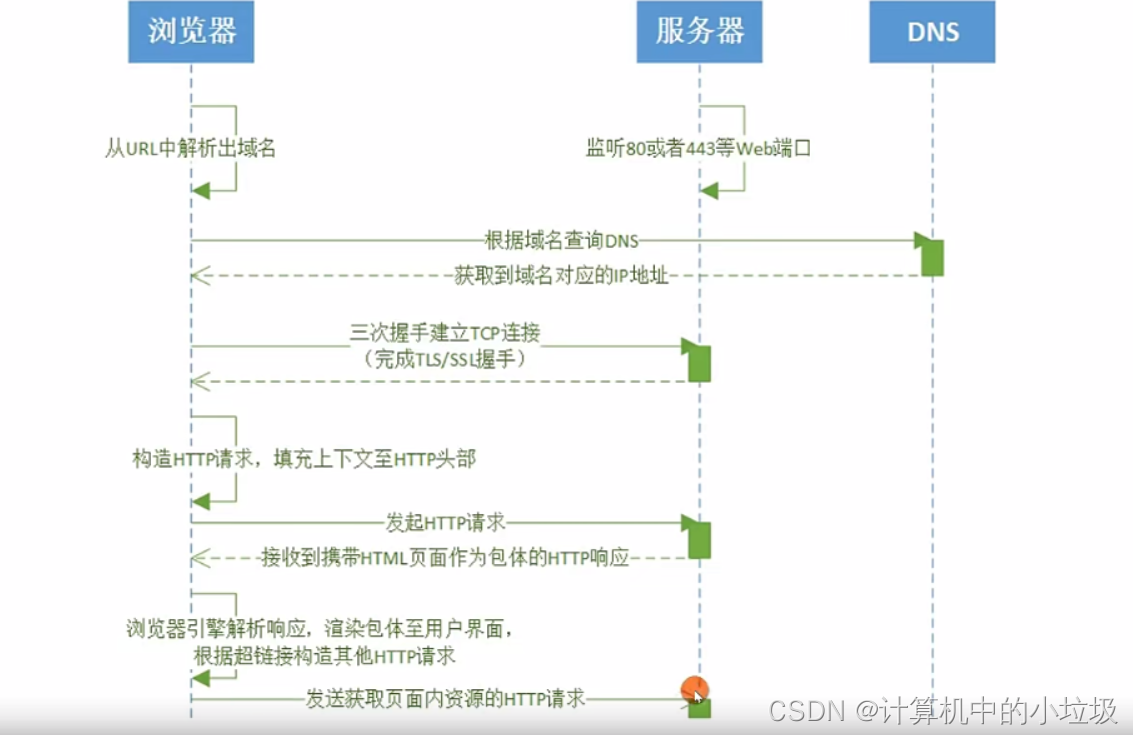
通常我们说在浏览器界面输入URL它的,执行过程是有一套八股的,比如从什么DNS解析找到对应IP,然后http请求等等。今天我们来看一下浏览器是怎么样的。
首先:
在用户界面上,用户输入对应的URL,在还没有输完URL的时候,浏览器引擎就会对我们输入的URL进行预判,
预判我们该输入什么。那这这是为什么呢,因为我们之前浏览过的网页,会被缓存下来,放在一个轻量级别的
数据库中,当我们输入是会进行随机匹配,匹配度高的就会被预先提取出来
然后:
接下来的事就是渲染引擎的事,渲染引擎下面有多个分支,有个网络就是负责获取请求数据的,里面就是包括
我们背的八股,负责请求的数据回来了,通常事html js css格式,我们要把这些呈现给用户,就需要一个
js解释器,来解析这些文件。
最后:
就是UI方面把这些数据想要表达的方面,绘制到页面上,最终呈现到用户面前
3,使用谷歌浏览器抓包
我们可以使用谷歌浏览器子弹的network进行抓包,查看请求方式,数据等。
打开方式是ctrl +shift+i
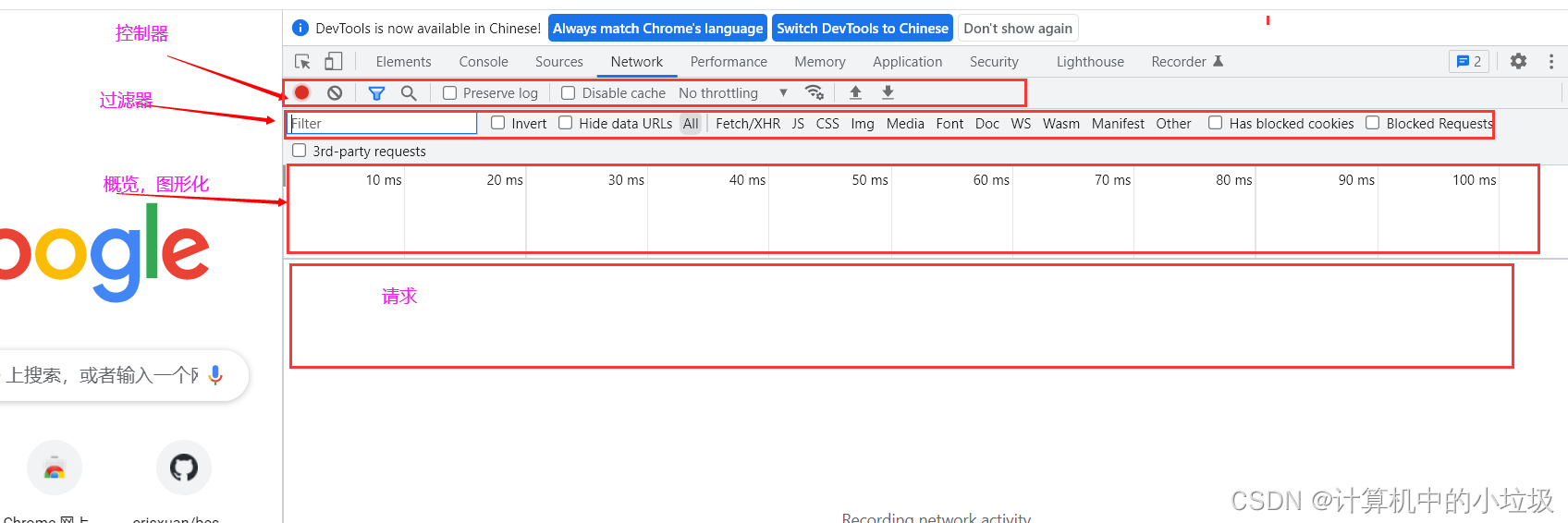 几个模块的功能
几个模块的功能

1,控制器
 2,过滤器
2,过滤器
 属性过滤:
属性过滤:
| 属性 | 作用 |
|---|---|
| domain: | 仅显示来自指定域的资源。您可以使用通配符字符(*) 纳入多个域 |
| has-response-header: | 显示包含指定HTTP响应标头的资源 |
| is: | 使用is:running可以查找WebSocket资源,is:from-cache 可查找缓存读出的资源 |
| larger-than: | 显示大于指定大小的资源(以字节为单位)。将值设为1000等同于设置为1k |
| method: | 显示通过指定HTTP方法类型检索的资源 |
| mime-type: | 显示指定MIME类型的资源 |
示例:过滤出缓存加载出来的数据
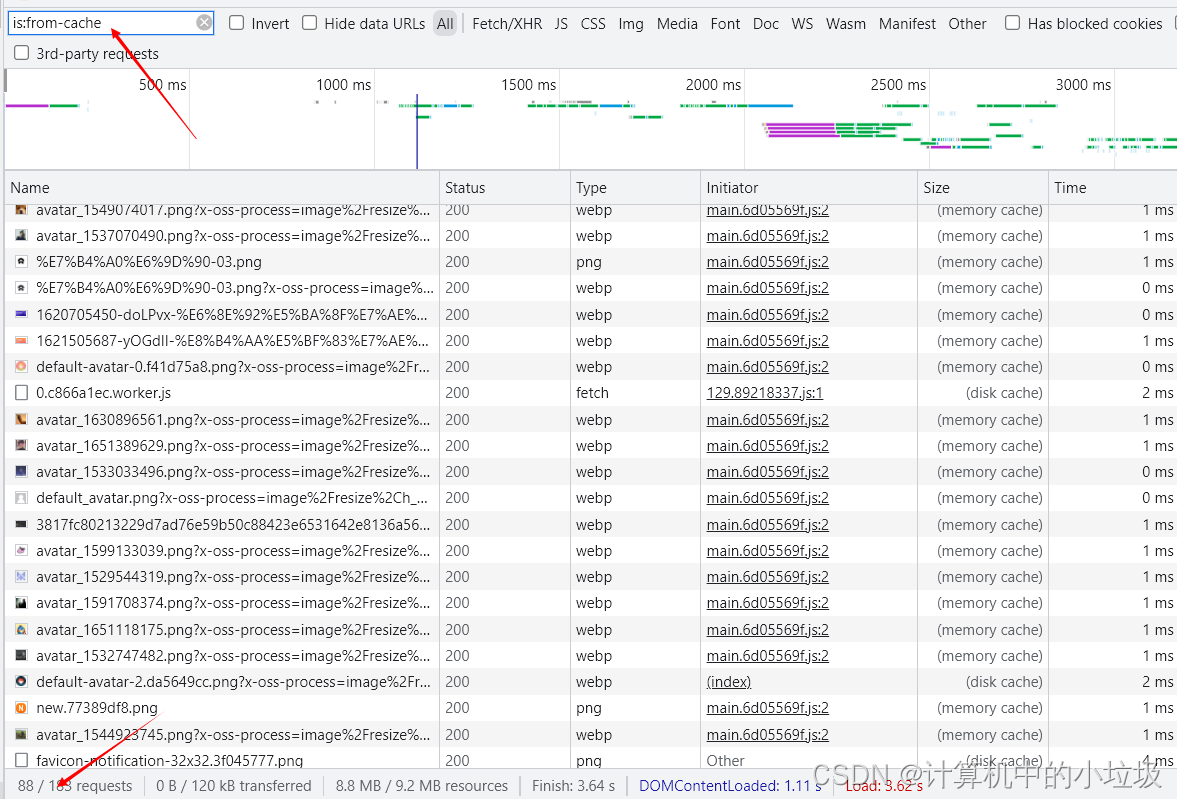
3,请求列表中的排序
时间排序,默认
按列排序
按活动时间排序
Start Time: 发出的第一个请求位于顶部
Response Time:开始下载的第一个请求位于顶部
End Time:完成的第-一个请求位于顶部
Total DurationB 连接设置时间和请求/响应时间最短的请求位于顶部
Latency: 等待最短响应时间的请求位于顶部
按住shift可以看到上下游,红色就是它的下游,绿色就是他的上游
4,两种http包体的传输方式
1,第一种传输的方式就是在传输的时候,带上头部字段,content-length:{长度},这个后面长度就是表示的是传输包体的长度,在传输之前会先统计这个包体的长度。
如果字段后面长度是小于包体长度的话,那么就只能读取相应的长度。如果大于,那么就是不合法的。
2,第二种就是使用chunk方式进行传输,有些浏览器是不支持content-length字段的,这个时候就可以采用chunk方式,在包体中遇到这个chunk-size,就知道要读取后面多少长度,然后再读取chunk-size,继续读取。这种方法的好处就是遇到大的文件进行压缩的时候,可以压缩多少传输多少。
5,TCP协议的特点
**在IP协议之上,解决网络通讯可依赖问题**
点对点(不能广播、多播),面向连接
●双向传递(全双工)
●字节流:打包成报文段、保证有序接收、重复报文自动丢弃
●缺点:不维护应用报文的边界(对比HTTP、 GRPC)
●优点:不强制要求应用必须离散的创建数据块,不限制数据块大小
●流量缓冲:解决速度不匹配问题
●可靠的传输服务(保证可达,丢包时通过重发进而增加时延实现可靠性)
●拥塞控制















 990
990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









