









通过使用urllib库访问目标网址,使用BeautifulSoup库解析网页,进而获得网页静态加载的数据信息。获取了证券之星所拥有的大量股票数据信息之后,可以用这些信息来进行股票涨跌分析预测。
1.证券之星
证券之星始创于1996年,纳斯达克上市公司——中国金融在线旗下网站,是中国最早的理财服务专业网站,是专业的投资理财服务平台,是中国最大的财经资讯网站与移动财经服务提供商,同时也是中国最领先的互联网媒体。

找到我们需要的网站:http://quote.stockstar.com/stock/ranklist_a.shtml

2.网页分析
首先,先对需要获取的地方右键单击,再左键单击检查元素

可以看到“代码”这两个字,是处于<a>标签中,再往外是一个<td>标签。而一整行表头都处于<thead class="tbody_right">中。

股票信息都处于<tbody class="tbody_right" id="datalist">标签中,将其展开看一下每一行和每一项的标签。

将标签展开,根据观察可以得出,一整行的数据都在<tr>标签中,每一项都在其下的<td>标签中,其中代码和简称还有一个带有超链接的<a>。至此,该页的数据获取分析结束。

接下来是想办法获取下一页内容,然而“证券之星”的“下一页”是通过JavaScript加载的,在html中无法简单地获取其信息。不过这不成问题,先点击下一页比较一下区别。

点了下一页之后网址发生了变化,通过分析网址,可以得出"ranklist_a"之前的内容为固定内容,"ranklist_a"表示沪深A股,"ranklist_a"之后的"3_1_2"才是我们需要改变的参数。通过改变参数,我们可以发现第一个参数"3"表示根据“涨跌幅”排序(因为表头的“简称”排除之后,“涨跌幅”在第3个),第二个参数“1”表示降序排列,第三个参数“2”表示页数。于是,我们发现可以通过调整网址的最后一个参数来进行翻页操作。
那么,对于这个网页的分析就结束了,下面开始代码实现的部分。
3.代码实现
3.1 解析网页
from bs4 import BeautifulSoup
import urllib
# 需要解析的目标地址
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_1.html'
# 访问目标地址
response = urllib.request.urlopen(url, timeout=60).read()
# 解析网页
soup = BeautifulSoup(response, 'html5lib', from_encoding='gb2312')
代码释义:
1.urllib.request.urlopen()函数实现对目标地址的访问
函数原型为:urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
其中,需要了解的有:
url:需要打开的网址
data:Post提交的数据
timeout:设置网站的访问超时时间
2.BeautifulSoup()函数实现对网页的解析
传入BeautifulSoup()一般需要3个参数:文档、解析器、编码方式。
将一段文档传入BeautifulSoup的构造方法,BeautifulSoup会将其解析,就能得到一个文档的对象, 可以传入一段字符串或一个文件句柄。
解析器可以自己选用,这里选用的是"html5lib",主要的解析器及其优缺点如下图所示:

推荐使用lxml和html5lib。另外,如果一段HTML或XML文档格式不正确,那么在不同解析器中返回的结果可能不一样,具体可以查看解析器之间的区别。
同时,urllib库可以用requests库替换,bs4库可以用lxml库替换,具体使用方法如下:
from lxml import etree
import requests
# 需要解析的目标地址
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_1.html'
# 访问目标地址
respond = requests.get(url).text
# 解析网页
tree = etree.HTML(respond)
代码释义:
1.requests.get()函数发送一个GET请求
函数原型为:requests.get(url, params=None, **kwargs)
其中,需要了解的有:
url:需要发送Request的对象地址
params:(可选)以字典形式传递参数
2.etree.HTML()从字符串中以树的结构解析HTML文档,返回解析后的根节点。
函数原型为:HTML(text, parser=None, base_url=None)
其中,需要了解的有:
text:需要解析成HTML文档的字符串
parser:传入参数以使用不同的HTML解析器
base_url:网站根地址,用于处理网页资源的相对路径
以上两种方式分别使用了urllib库→bs4库和requests库→lxml库。虽然使用的库不同,但是步骤都是先访问网页并获取网页文本文档(urllib库、requests库),再将其传入解析器(bs4库、lxml库)。值得一提的是,这两个例子中的搭配可以互换。
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_1.html'
response = urllib.request.urlopen(url, timeout=60).read()
tree = etree.HTML(response)
respond = requests.get(url).text
soup = BeautifulSoup(respond, 'html5lib')
如上所示:urllib库→lxml库和requests库→bs4库这样的方式也是可行的。
在目前的需求下,urllib库和requests库的差距体现不大,但是实际上二者还是有如下区别:
- 构建参数
urllib库在请求参数时需要用urlencode()对参数进行编码预编译,而requests库只需要把参数传入get()中的params中
- 请求数据
urllib库需要拼接一个url字符串,而requests库只需要将get()中的base_url填写完善即可
- 连接方式
urllib库每次请求结束关闭socket通道,而requests库多次重复使用一个socket,消耗更少资源
- 编码方式
requests库的编码方式更加完备
bs4库和lxml库的对比
一提到网页解析技术,提到最多的关键字就是BeautifulSoup和xpath,而它们各自在Python中的模块分别就是bs4库和lxml库。以下是它们的区别:
- 效率
一般来说,xpath的效率优于BeautifulSoup。BeautifulSoup是基于DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多。进行分步调试时,生成soup对象时会有明显的延迟。lxml.etree.HTML(html)在step over的一瞬间便成功构建了一个可执行xpath操作的对象。并且lxml库只会进行局部遍历。
- 难度
个人认为bs4库比lxml库更容易上手。一方面是使用门槛,BeautifulSoup中的各种方法,看了文档就能用;而lxml需要通晓xpath语法,这意味着需要同时学习xpath语法和查询API文档。另一方面是返回结果,lxml中的xpath()方法返回对象始终是一个list,处理起来比较尴尬;而BeautifulSoup中的方法相对灵活,适合不同场合。
- 适用场合
这里主要提一下使用禁区。当遇到list嵌套list的时候,尽量不选择BeautifulSoup而使用xpath,因为BeautifulSoup会用到2个find_all(),而xpath会省下不少功夫。当遇到所需获取的类名有公共部分时,可以使用BeautifulSoup而非xpath,因为xpath需要完全匹配,也就是除了公共部分之外各自独有的部分也得匹配,这样就需要多行代码来获取,而BeautifulSoup可以仅匹配公共部分就获取所有匹配上的类。
3.2 获取数据
在本案例中,所有由bs4库获取的内容都可以用同样的逻辑思路用lxml库获取,因此将用bs4库先作演示如何获取内容,再直接根据bs4库提到的标签,直接写出lxml库的代码。

通过查看网页源码可以看到,该网页并没有使用常见的"utf-8"编码,而使用了"gb2312"编码。
至此,我们确定了传入BeautifulSoup()的3个参数,此时print(soup)会看到的是目标网址的源代码。如果有心去浏览一下,会发现在print出来的源代码中,是找不到“下一页”这3个字的。
接下来通过soup获取数据
soup.find('thead', class_='tbody_right').find_all('td')
Out:
[<td class="align_center" width="6%"><a class="" href="" sort="1">代码</a></td>,
<td class="align_center" width="8%">简称</td>,
<td width="8%"><a class="" href="" sort="2">最新价</a></td>,
<td width="8%"><a class="" href="" sort="3">涨跌幅</a></td>,
<td width="8%"><a class="" href="" sort="4">涨跌额</a></td>,
<td width="9%"><a class="" href="" sort="5">5分钟涨幅</a></td>,
<td width="10%"><a class="" href="" sort="6">成交量(手)</a></td>,
<td width="11%"><a class="" href="" sort="7">成交额(万元)</a></td>,
<td width="7%"><a class="" href="" sort="8">换手率</a></td>,
<td width="6%"><a class="" href="" sort="9">振幅</a></td>,
<td width="6%"><a class="" href="" sort="10">量比</a></td>,
<td width="6%"><a class="" href="" sort="11">委比</a></td>,
<td width="7%"><a class="" href="" sort="12">市盈率</a></td>]
可以看到这样就以类似于列表的方式获取了数据表格的表头,只是表头还被标签框着,因此还需要进一步进行处理。
[i.get_text() for i in soup.find('thead', class_='tbody_right').find_all('td')]
Out:['代码',
'简称',
'最新价',
'涨跌幅',
'涨跌额',
'5分钟涨幅',
'成交量(手)',
'成交额(万元)',
'换手率',
'振幅',
'量比',
'委比',
'市盈率']
代码释义:
.get_text()是完成从标签里取出正文内容这一步。
[expression for iter_val in iterable]是Python中一种根据已有列表,高效创建新列表的方式,是迭代机制的一种应用。
' '.join([i.get_text() for i in soup.find('thead', class_='tbody_right').find_all('td')])
Out:'代码 简称 最新价 涨跌幅 涨跌额 5分钟涨幅 成交量(手) 成交额(万元) 换手率 振幅 量比 委比 市盈率'
代码释义:
`str.join(sequence)`方法用于将序列中的元素以指定的字符连接生成一个新的字符串。sequence为要连接的元素序列。str为需要作为连接符的字符。
这里使用它是为了方便展示。
同理可得获取股票数据的代码
# 显示前5行
[' '.join([j.get_text() for j in i.find_all('td')]) for i in soup.find('tbody', class_='tbody_right').find_all('tr')][0:5]
Out:['601860 紫金银行 6.77 10.08% 0.62 0.00% 772390.28 51587.43 21.10% 10.57% 3.82 1.00 --',
'600448 华纺股份 6.34 10.07% 0.58 0.00% 214822.63 13281.84 4.17% 7.12% 1.61 1.00 300.76',
'300313 天山生物 7.33 10.06% 0.67 0.00% 97383.56 6867.48 5.34% 13.96% 1.31 1.00 --',
'600225 天津松江 3.83 10.06% 0.35 0.00% 183059.66 6789.82 1.96% 6.61% 1.21 1.00 2.12',
'603977 国泰集团 8.97 10.06% 0.82 0.00% 57579.09 5164.84 3.27% 0.00% 3.38 1.00 66.50']
BeautifulSoup获取表头的代码为:
[i.get_text() for i in soup.find('thead', class_='tbody_right').find_all('td')]
先找到了class值为tbody_right的thead标签,再在该范围下寻找了所有的td标签,最后提取正文。基于该逻辑写出XPath语法如下所示:
tree.xpath('//thead[@class="tbody_right"]//td//text()')
为了方便展示,用空格连接每一项:
' '.join(tree.xpath('//thead[@class="tbody_right"]//td//text()'))
Out:'代码 简称 最新价 涨跌幅 涨跌额 5分钟涨幅 成交量(手) 成交额(万元) 换手率 振幅 量比 委比 市盈率'
BeautifulSoup获取内容的代码为:
[[j.get_text() for j in i.find_all('td')] for i in soup.find('tbody', class_='tbody_right').find_all('tr')]
首先找到了class值为tbody_right的tbody标签,并且在该范围下寻找所有的tr标签(对应每一行数据),对于每一个tr标签,再寻找其下所有的td标签,最后提取正文。基于该逻辑写出XPath语法如下所示:
[i.xpath('td//text()') for i in tree.xpath('//tbody[@class="tbody_right"]//tr')]
为了方便展示,用空格连接行中的每一项数据:
# 显示前5行
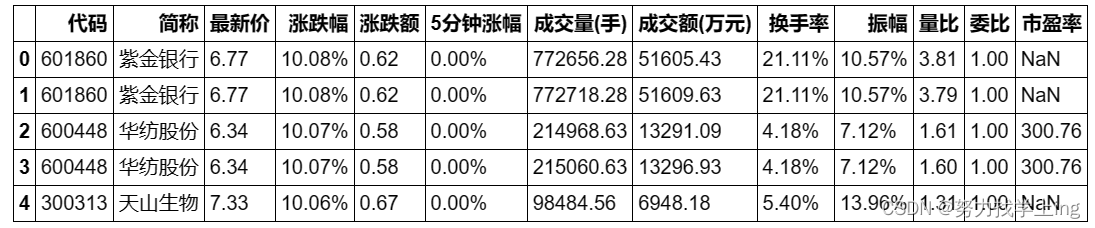
[' '.join(i.xpath('td//text()')) for i in tree.xpath('//tbody[@class="tbody_right"]//tr')][0:5]
Out:['601860 紫金银行 6.77 10.08% 0.62 0.00% 772656.28 51605.43 21.11% 10.57% 3.81 1.00 --',
'601860 紫金银行 6.77 10.08% 0.62 0.00% 772718.28 51609.63 21.11% 10.57% 3.79 1.00 --',
'600448 华纺股份 6.34 10.07% 0.58 0.00% 214968.63 13291.09 4.18% 7.12% 1.61 1.00 300.76',
'600448 华纺股份 6.34 10.07% 0.58 0.00% 215060.63 13296.93 4.18% 7.12% 1.60 1.00 300.76',
'300313 天山生物 7.33 10.06% 0.67 0.00% 98484.56 6948.18 5.40% 13.96% 1.31 1.00 --']
3.3 数据展现和存储
目前为止,已经完成对网址的访问、对网页的解析,得到了我们想要的数据。而数据此时只是单纯的列表或字符形式存在,我们可以用NumPy库、Pandas库将其格式化为DataFrame。DataFrame 类型类似于数据库表结构的数据结构,其含有行索引和列索引,可以将DataFrame 想成是由相同索引的Series组成的Dict类型。在其底层是通过二维以及一维的数据块实现。最后,可以用Python3自带的sqlite3库,将数据本地存储在数据库中。
import numpy as np
import pandas as pd
header = [i.get_text() for i in soup.find('thead', class_='tbody_right').find_all('td')] # 数据表格的表头
content = [i.xpath('td//text()') for i in tree.xpath('//tbody[@class="tbody_right"]//tr')] # 数据表格的内容
数据中,有一些--出现,这些表示该处数据为空,NumPy中的numpy.NaN在功能上是用来标示空缺数据,因此我们将其先一步进行转化。
content = [[np.nan if j == '--' else j for j in i] for i in content]
用pandas.DataFrame()创建DataFrame,并且展示DataFrame及其每列的数据类型。
df = pd.DataFrame(columns=header, data=content)
df.head() # 显示DataFrame的前若干行,默认为5
df.dtypes
Out:代码 object
简称 object
最新价 object
涨跌幅 object
涨跌额 object
5分钟涨幅 object
成交量(手) object
成交额(万元) object
换手率 object
振幅 object
量比 object
委比 object
市盈率 object
dtype: object
DataFrame创建得非常成功,但是美中不足的是,每一列数据都是object类型,并没有识别为数字,接下来将转换它们的数据类型。需要注意的是,“代码”列的数据很容易被识别为数字——这并不是我们想要的,因为如果将其识别为数字,那些0开头的代码将会少于6位数字。
df[df.columns[1:]] = df[df.columns[1:]].apply(pd.to_numeric, errors='ignore')
df.head() # 显示DataFrame的前若干行,默认为5

df.dtypes
Out:代码 object
简称 object
最新价 float64
涨跌幅 object
涨跌额 float64
5分钟涨幅 object
成交量(手) float64
成交额(万元) float64
换手率 object
振幅 object
量比 float64
委比 float64
市盈率 float64
dtype: object
对于DataFrame的处理基本完成,接下来将其存入本地数据库。
import sqlite3
db = sqlite3.connect('shares.db')
cursor = db.cursor()
df.to_sql(name='test1', con=db, if_exists='replace')
代码释义:
1.sqlite3.connect(database [,timeout ,other optional arguments])打开一个到 SQLite 数据库文件 database 的链接,如果数据库成功打开,则返回一个连接对象。
database表示连接到的数据库名,timeout参数表示连接等待锁定的持续时间,直到发生异常断开连接。timeout 参数默认是 5.0(5 秒)。如果给定的数据库名称不存在,则该调用将创建一个数据库。如果不想在当前目录中创建数据库,那么可以指定带有路径的文件名,这样就能在任意地方创建数据库。
2.connection.cursor([cursorClass])创建一个cursor,所有的sql语句都将由其执行。
该方法接受一个单一的可选的参数 cursorClass。如果提供了该参数,则它必须是一个扩展自sqlite3.Cursor的自定义的cursor 类。
3.pandas.DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)将在DataFrame的数据记录写入数据库。
其中,需要了解的参数:
name:SQL的表的名字
con:一般为sqlalchemy.engine.Engine或者sqlite3.Connection
if_exists:如果表已存在,该如何处置,默认返回失败(fail),可以改成在插入新值之前删除表(replace)或者将新值插入现有表(append)
index:默认为Ture,将DataFrame索引写为一列。使用index_label作为表中的列名。
index_label:字符串或序列,默认为None,索引列的列标签。如果给出None(默认值)且 index为True,则使用索引名称。如果DataFrame使用MultiIndex,则应该给出一个序列。
用cursor.execute(sql [, optional parameters])从刚存入数据的数据库中提取数据,并且打印数据
cursor.execute('SELECT * FROM test1')
# 同样打印前5行
for row in cursor.fetchall()[0:5]:
print(row)
Out:(0, '601860', '紫金银行', 6.77, '10.08%', 0.62, '0.00%', 772656.28, 51605.43, '21.11%', '10.57%', 3.81, 1.0, None)
(1, '601860', '紫金银行', 6.77, '10.08%', 0.62, '0.00%', 772718.28, 51609.63, '21.11%', '10.57%', 3.79, 1.0, None)
(2, '600448', '华纺股份', 6.34, '10.07%', 0.58, '0.00%', 214968.63, 13291.09, '4.18%', '7.12%', 1.61, 1.0, 300.76)
(3, '600448', '华纺股份', 6.34, '10.07%', 0.58, '0.00%', 215060.63, 13296.93, '4.18%', '7.12%', 1.6, 1.0, 300.76)
(4, '300313', '天山生物', 7.33, '10.06%', 0.67, '0.00%', 98484.56, 6948.18, '5.40%', '13.96%', 1.31, 1.0, None)
3.3 代码整合
虽然urllib库和requests库以及bs4库和lxml库可以二选一,但是此处将其全部用上作为案例中提到的所有代码的整合。此外,将打印前两页数据进行局部展示。
import time
import urllib, requests
from bs4 import BeautifulSoup
from lxml import etree
import numpy as np
import pandas as pd
import sqlite3
# 获取日期作为表名
today = time.strftime('%Y%m%d')
print('获取的数据将存入表:',today)
# 连接数据库,并且创建cursor
db = sqlite3.connect('shares.db')
cursor = db.cursor()
# 如果以今天日期为名的表已经存在。将其删除
cursor.execute('DROP TABLE IF EXISTS "%s";'%today)
db.commit()
# 设置翻页,获取第1~30页(共121页)内容并存入数据库
for n in range(1,31):
# 需要解析的目标地址
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_%s.html'%n
# 输出当前获取网站地址
print('正在获取网站:%s'%url)
# 访问目标地址
response = urllib.request.urlopen(url, timeout=60).read()
respond = requests.get(url).text
# 解析网页
soup = BeautifulSoup(response, 'html5lib', from_encoding='gb2312')
tree = etree.HTML(respond)
# 获取表头
header = [i.get_text() for i in soup.find('thead', class_='tbody_right').find_all('td')]
# 获取每条数据
content = [i.xpath('td//text()') for i in tree.xpath('//tbody[@class="tbody_right"]//tr')]
# 处理数据
content = [[np.nan if j == '--' else j for j in i] for i in content]
# 创建DataFrame
df = pd.DataFrame(columns=header, data=content)
# 修改数据类型
df[df.columns[1:]] = df[df.columns[1:]].apply(pd.to_numeric, errors='ignore')
# 存入数据库,如果today表已存在,新的数据插入旧的数据的后面
df.to_sql(name=today, con=db, if_exists='append')
# 设置访问时间间隔
time.sleep(0.5)
print('获取完毕')
db.commit()
db.close()
从数据库中读取数据并创建为DataFrame,再打印数据作为展示
db = sqlite3.connect('shares.db') # 连接数据库
df = pd.read_sql('SELECT "%s" FROM "%s"'%('","'.join(header),today),con=db) # 读取数据创建为DataFrame
# 显示DataFrame的前若干行,默认为5
df.head()
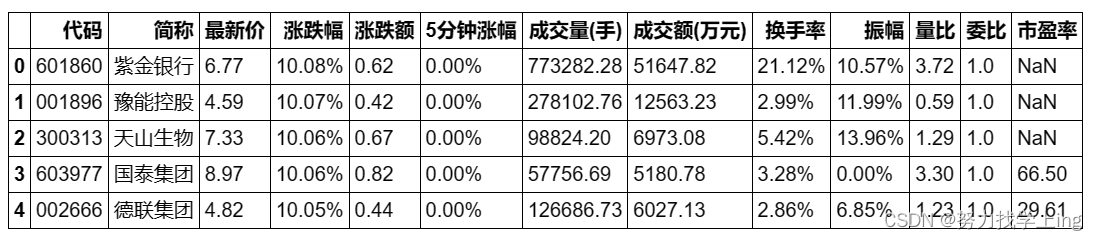
df.tail() # 显示DataFrame的后若干行,默认为5

4.归纳总结
本案例使用urllib库、requests库访问网站,使用bs4库、lxml库解析网页,并且比较了它们的区别。获取数据后,用NumPy库、Pandas库创建并微调DataFrame,最后用sqlite3库将其导入数据库存在本地。
其中,访问网站、解析网页的库在本案例中可以在一定程度上互换搭配。但是在特殊情况下,它们的特点得到体现,作为使用者应该考虑其特点,选择最合适的库完成代码。在今后的案例中,会适当地提到。
为了让数据不再停留在字符串、列表的形式,将其建立为DataFrame,并且微调了内容和数据类型使其更有条理。最后存入本地数据库让整个数据获取程序更为完整。















 6831
6831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











