







1.什么是vite
Vite 是 vue 的作者尤雨溪在开发 vue3.0 的时候开发的一个 web 开发构建工具。由于其原生 ES 模块导入方式,可以实现闪电般的冷服务器启动。
2.Vite和Webpack的区别
Vite的优势:
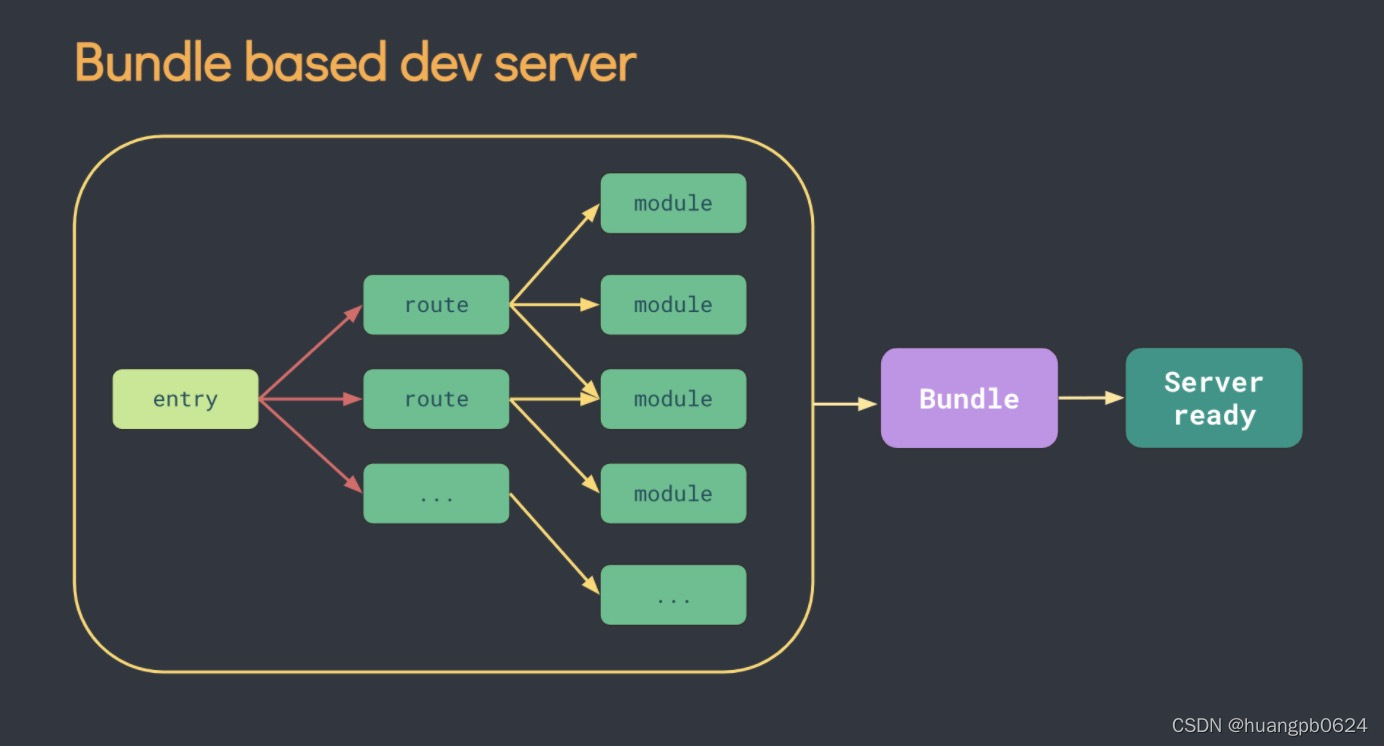
- vite 开发服务器启动速度比 webpack 快 webpack 会先打包,然后启动开发服务器,请求服务器时直接给予打包结果。vite 在启动开发服务器时不需要打包,也就意味着不需要分析模块的依赖、不需要编译,因此启动速度非常快。当浏览器请求某个模块时,再根据需要对模块内容进行编译。这种按需动态编译的方式,极大的缩减了编译时间,项目越复杂、模块越多,vite的优势越明显。
- 由于现代浏览器本身就支持ES Module,会自动向依赖的Module发出请求。vite充分利用这一点,将开发环境下的模块文件,就作为浏览器要执行的文件,而不是像webpack那样进行打包合并。
- vite 热更新比 webpack 快在 HMR 方面,当改动了一个模块后,vite仅需让浏览器重新请求该模块即可,不像webpack那样需要把该模块的相关依赖模块全部编译一次,效率更高。
- vite 使用esbuild(Go 编写) 预构建依赖,比 webpack 的 nodejs,快 10-100 倍。
Vite的劣势:
- 生态不及webpack,加载器、插件不够丰富
- 打包到生产环境时,vite使用传统的 rollup(也可以自己手动安装webpack来)进行打包
- 项目的开发浏览器要支持 ES Module,而且不能识别 CommonJS 语法
其他的区别:
1.打包原理的区别
 webpack打包原理
webpack打包原理
 Vite打包原理
Vite打包原理
2.项目入口文件的区别
项目根目录的 index.html 是 Vite 项目的入口文件,而 webpack 的入口文件是 webpack 配置 entry 中指定的 js 文件。
3.Esbuild
Esbuild 是一款基于 Go 语言开发的 javascript 打包工具,最大的一个特征就是快。

Esbuild 之所以能这么快,主要原因有两个:
1. Go 语言开发,可以多线程打包,代码直接编译成机器码;
Webpack 一直被人诟病构建速度慢,主要原因是在打包构建过程中,存在大量的 resolve、load、transform、parse 操作(详见 为什么有人说 vite 快,有人却说 vite 慢?- 快速的冷启动 ),而这些操作通常是通过 javascript 代码来执行的。要知道,javascript 并不是什么高效的语言,在执行过程中要先编译后执行,还是单线程并且不能利用多核 cpu 优势,和 Go 语言相比,效率很低。
2. 可充分利用多核 cpu 优势;
关键 API - transfrom & build
Esbuild 并不复杂,它对外提供了两个 API:transform 和 build,使用起来非常简单。
transfrom,转换的意思,将 ts、jsx、tsx 等格式的内容转化为 js。 transfrom 只负责文件内容转换,并不会生成一个新的文件。
build,构建的意思,根据指定的单个或者多个入口,分析依赖,并使用 loader 将不同格式的内容转化为 js 内容,生成一个或多个 bundle 文件。
四、关于 Vite 的一些其他知识
- 在工程中不是所有的引用模块都是ES写法,可能是CommonJS 和 UMD 、AMD 等等,这个时候Vite 会进行预构建,将其转换为ESM模块,以支持Vite。
- 对于JSX、或者TS 等需要编译的文件,Vite是用esbuild来进行编译的。
五、Webpack 和 Rollup 区别
经验法则:对于应用使用 webpack,对于类库使用 Rollup。
如果你需要代码拆分(Code Splitting),或者你有很多静态资源需要处理,再或者你构建的项目需要引入很多CommonJS模块的依赖,那么 webpack 是个很不错的选择。
如果您的代码库是基于 ES2015 模块的,而且希望你写的代码能够被其他人直接使用,你需要的打包工具可能是 Rollup 。














 3769
3769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









