






 该代码示例展示了如何使用Python的pandas库进行数据过滤。首先,它从Excel和CSV文件中读取数据,然后根据关键词过滤数据,将包含关键词的行保存到新CSV文件。接着,它从已筛选的数据中删除包含特定关键词的行,并将结果保存到另一个CSV文件。整个过程使用tqdm显示进度条,提高了用户交互性。
该代码示例展示了如何使用Python的pandas库进行数据过滤。首先,它从Excel和CSV文件中读取数据,然后根据关键词过滤数据,将包含关键词的行保存到新CSV文件。接着,它从已筛选的数据中删除包含特定关键词的行,并将结果保存到另一个CSV文件。整个过程使用tqdm显示进度条,提高了用户交互性。
帮对象处理所需数据时写的代码——第六弹(实现功能一:Python实现根据某列中找到的关键字从原始数据中过滤行,然后匹配到关键词的行数据保存到新的 CSV 文件中;实现功能二:从原始数据中删除“删除的关键字”列中找到的任何关键字的行,然后将剩余数据保存到新的 CSV 文件中)
功能一:筛选出包含关键词的行
第一节 读取数据和设置
在这一部分中,代码从两个不同的源读取数据:
It reads "Table 1" from an Excel file (需要保留的关键词.xlsx) into a DataFrame called keywords_df.
It reads "Table 2" from a CSV file (原始数据.csv) into another DataFrame called data_df.
创建一个名为的空 DataFrame,result_df其列与相同data_df。
import pandas as pd
from tqdm import tqdm
# Read Table 1
keywords_df = pd.read_excel(r"C:\Users\Desktop\需要保留的关键词.xlsx")
# Read Table 2 (数据表格)
data_df = pd.read_csv(r"C:\Users\Desktop\原始数据.csv", dtype=str)
# Create an empty Table 3
result_df = pd.DataFrame(columns=data_df.columns)
# Iterate over the keywords in Table 1第二节 迭代关键字并过滤数据
在此部分中,代码使用循环和库迭代“关键字”列中的每个关键字,tqdm以显示名为“处理”的进度条。
对于每个关键字,它执行以下步骤:
它搜索“表 2”( data_df) 中“地址”列包含当前关键字的行。该str.contains()方法用于检查部分匹配,并na=False用于忽略缺失值。
匹配的行存储在名为 的 DataFrame 中matched_rows。
使用, 将DataFramematched_rows附加到先前创建的空 DataFrame 中,以重置串联 DataFrame 的索引。result_dfpd.concat()ignore_index=True
for keyword in tqdm(keywords_df['关键词'], desc="Processing"):
# Find rows in Table 2 where the "地址" column matches the keyword
matched_rows = data_df[data_df['地址'].str.contains(keyword, na=False)]
# Append the matched rows to Table 3
result_df = pd.concat([result_df, matched_rows], ignore_index=True)第三节 删除重复行并保存结果
在这一部分中,代码执行以下步骤:
它使用该方法根据所有列从“表 3”( ) 中删除重复行drop_duplicates()。DataFrameresult_df已更新为仅包含唯一行。
使用该方法将删除重复行的结果 DataFrame 保存到名为“筛选出包含关键词的行.csv”的新 CSV 文件中to_csv()。设置index为False避免将 DataFrame 索引保存为 CSV 文件中的单独列。
最后,打印“Query Complete”,表示关键字搜索、过滤和CSV保存过程已完成。
# Remove duplicate rows from Table 3 based on all columns
result_df = result_df.drop_duplicates()
# Save Table 3 to a CSV file
result_df.to_csv(r"C:\Users\Desktop\筛选出包含关键词的行.csv", index=False)
# Print "Query Complete"
print("Query Complete")第四节 运行示例
原始数据如下:
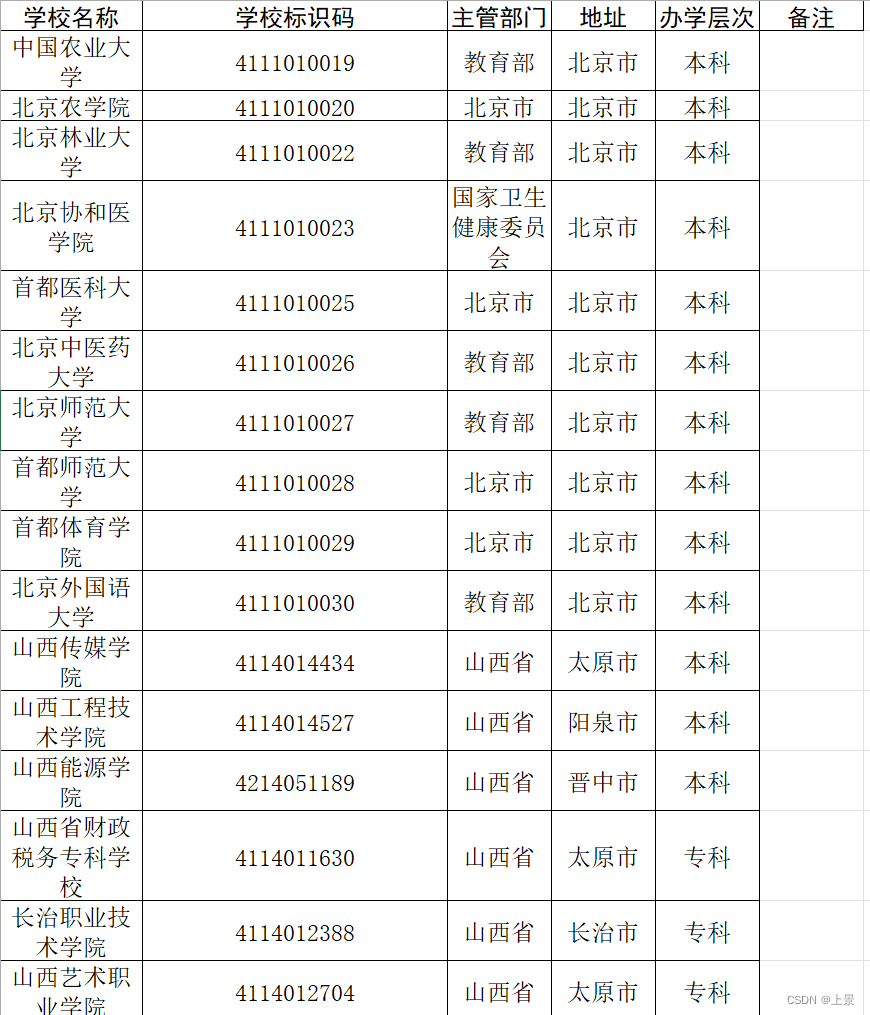
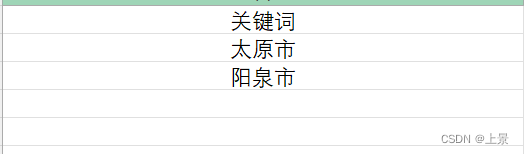
需要保留的关键词假设如下:
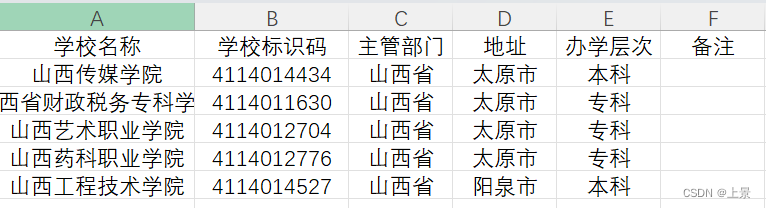
代码运行完毕后(只保留了包含太原市和阳泉市的行):
完整代码
import pandas as pd
from tqdm import tqdm
# Read Table 1
keywords_df = pd.read_excel(r"C:\Users\Desktop\需要保留的关键词.xlsx")
# Read Table 2 (数据表格)
data_df = pd.read_csv(r"C:\Users\Desktop\原始数据.csv", dtype=str)
# Create an empty Table 3
result_df = pd.DataFrame(columns=data_df.columns)
# Iterate over the keywords in Table 1
for keyword in tqdm(keywords_df['关键词'], desc="Processing"):
# Find rows in Table 2 where the "地址" column matches the keyword
matched_rows = data_df[data_df['地址'].str.contains(keyword, na=False)]
# Append the matched rows to Table 3
result_df = pd.concat([result_df, matched_rows], ignore_index=True)
# Remove duplicate rows from Table 3 based on all columns
result_df = result_df.drop_duplicates()
# Save Table 3 to a CSV file
result_df.to_csv(r"C:\Users\Desktop\筛选出包含关键词的行.csv", index=False)
# Print "Query Complete"
print("Query Complete")
功能二:去除掉包含关键词的行
第一节 数据加载
在这一部分中,代码导入所需的库、pandas 和 tqdm。然后它从外部文件加载两个数据集。
import pandas as pd
from tqdm import tqdm
# Read Table 1
keywords_df = pd.read_excel(r"C:\Users\Desktop\需要删除的关键词.xlsx")
# Read Table 2
data_df = pd.read_csv(r"C:\Users\Desktop\筛选包含关键词的行.csv", dtype=str)
第二节 关键字处理和过滤
该部分涉及迭代keywords_dfDataFrame 中的每个关键字。对于每个关键字,代码都会搜索data_df“地址”列包含该关键字作为子字符串的行。结果存储在matched_rows.
for keyword in tqdm(keywords_df['删除的关键词'], desc="Processing"):
matched_rows = data_df[data_df['地址'].str.contains(keyword, na=False, regex=False)]
data_df = data_df[~data_df['地址'].str.contains(keyword, na=False, regex=False)]
第三节 保存和完成
在这一部分中,DataFrame中的剩余数据data_df(在过滤掉具有匹配关键字的行之后)将保存到桌面上名为“消失掉包含关键字的行.csv”的新CSV文件中。该index=False参数确保索引列不会保存到 CSV 文件中。最后,脚本打印“Query Complete”,表明关键字处理和过滤操作已完成。
data_df.to_csv(r"C:\Users\Desktop\去除掉包含关键词的行.csv", index=False)
print("Query Complete")
第四节 运行示例
原始数据如下:
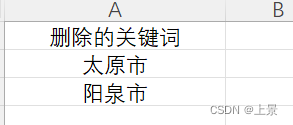
需要删除的关键词假设如下:
代码运行完毕后(删除了包含太原市和阳泉市的行):
完整代码
import pandas as pd
from tqdm import tqdm
# Read Table 1
keywords_df = pd.read_excel(r"C:\Users\Desktop\需要删除的关键词.xlsx")
# Read Table 2
data_df = pd.read_csv(r"C:\Users\Desktop\原始数据.csv", dtype=str)
# Iterate over the keywords in Table 1
for keyword in tqdm(keywords_df['删除的关键词'], desc="Processing"):
# Find rows in Table 2 where the "地址" column contains the keyword as a substring
matched_rows = data_df[data_df['地址'].str.contains(keyword, na=False, regex=False)]
# Remove the matched rows from Table 2
data_df = data_df[~data_df['地址'].str.contains(keyword, na=False, regex=False)]
# Save the remaining data to a CSV file
data_df.to_csv(r"C:\Users\Desktop\去除掉包含关键词的行.csv", index=False)
# Print "Query Complete"
print("Query Complete")
上述代码注意文件的格式,有csv格式和xlsx格式,根据需要适当修改程序即可。
如有不足,欢迎留言指正交流哈!!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











