






python语言中的第三方beautifulsoup4模块是需要下载的,它可以用来对HTML进行解析,下面利用一个实例说明beautifulsoup4模块的用法,
下载方法是:
在pycharm的终端输入:pip install bs4
BS4的BeautifulSoup对象
BeautifulSoup,是python种的一个库,最主要的内容就是从网页中抓取数据。 例:
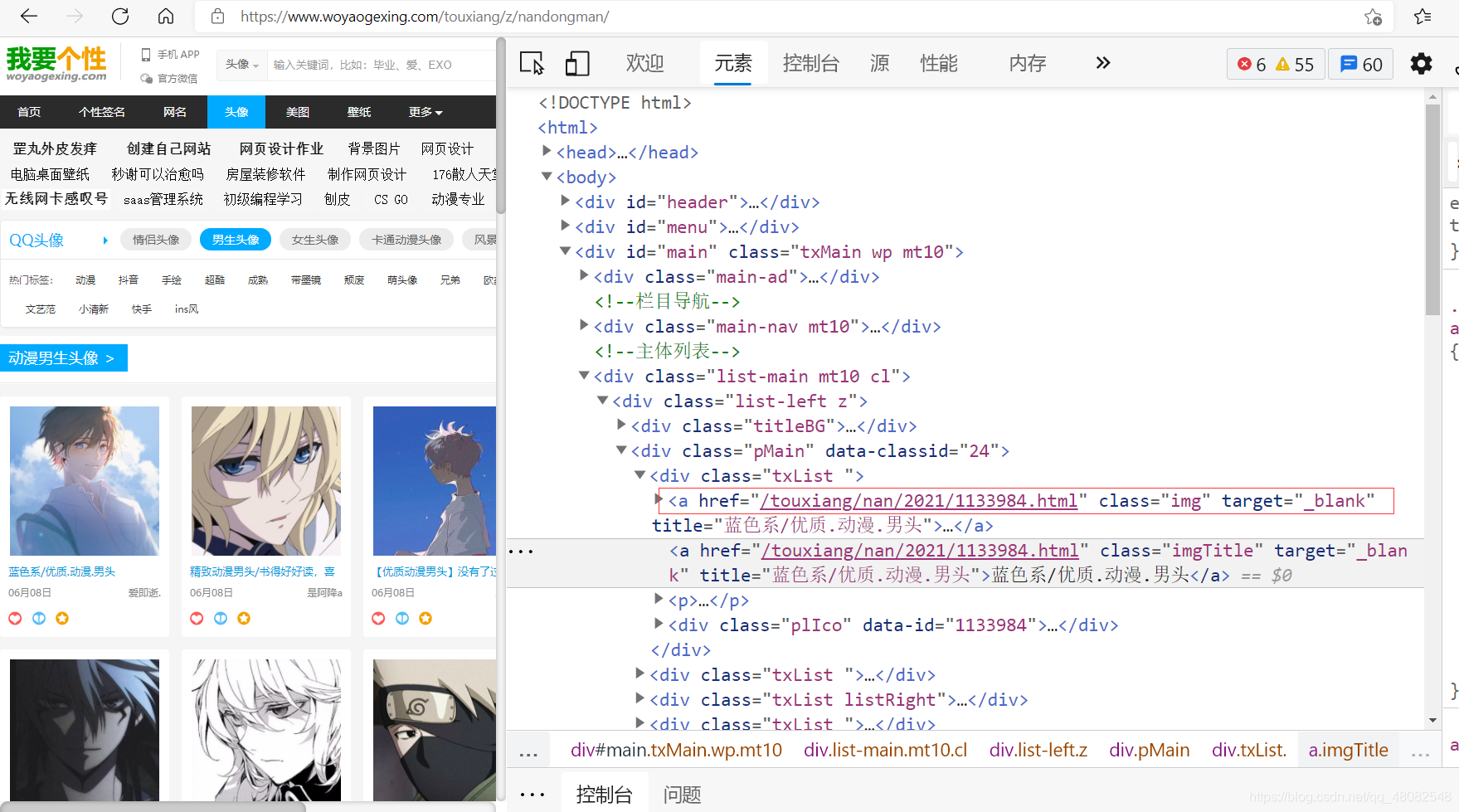
怎么获得上面图片中a标签里的href内容呢 可以看到class="img"可以做个突破口
网址地址为:https://www.woyaogexing.com/touxiang/z/nandongman/
使用方法如下:
import requests #导入request库
from bs4 import BeautifulSoup #导入bs4的库我们利用requests来打开这个网址:https://www.woyaogexing.com/touxiang/z/nandongman/
url = "https://www.woyaogexing.com/touxiang/z/nandongman/"res = requests.get(url)
res.encoding = res.apparent_encoding
创造BeautifulSoup对象
parse = BeautifulSoup(res.text, "html.parser") #告诉BeautifulSoup(res.text)以html的格式来处理
detail_div = parse.find("div", class_="pMain") #在parrse中查找第一个div的标签属性并且为:class="pMain"的内容并将结果给到detail_div
detail_like = detail_div.find_all("a", class_="img") #在detail_div中查找全部a标签属性并且为class_="img"的内容结果返回给detail_like
输出方法
for i in detail_like:
print(i.get("href"))
运行结果为
我们都能的到标签里的内容了我们就来爬取图片吧!
====================================================================================================
案例
爬取"https://www.woyaogexing.com/touxiang/z/nandongman/"的所有图片
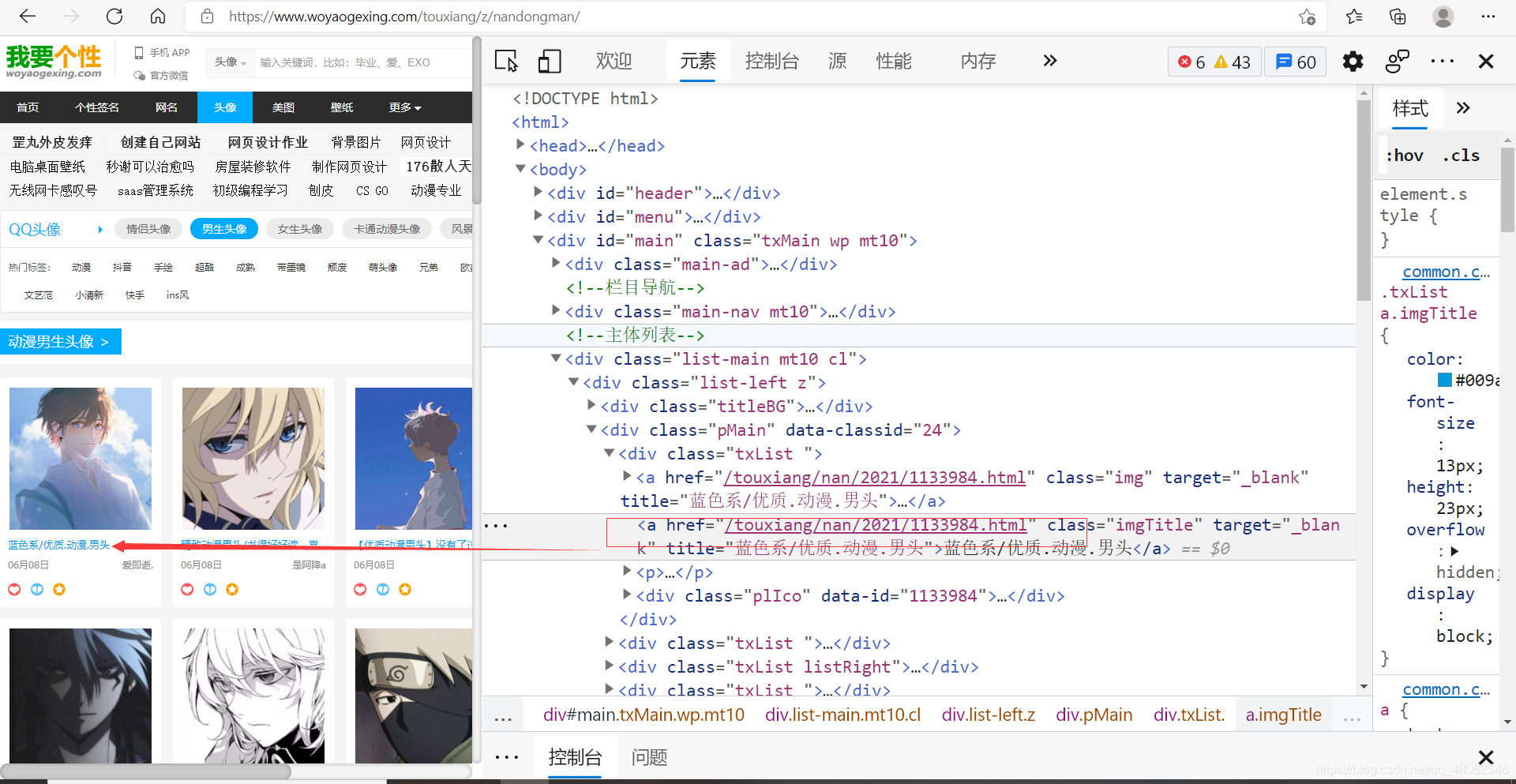
首先获得a标签里的href里的地址 代码为:
import requests
from bs4 import BeautifulSoup
url = "https://www.woyaogexing.com/touxiang/z/nandongman/"
res = requests.get(url)
res.encoding = res.apparent_encoding
parse = BeautifulSoup(res.text, "html.parser")
detail_div = parse.find("div", class_="pMain")
detail_like = detail_div.find_all("a", class_="img")
cont = 1
for i in detail_like:
detail_url = "https://www.woyaogexing.com" + i.get("href") #由于它的地址不全需要做处理
res = requests.get(detail_url)
res.encoding = res.apparent_encoding 得到了新的地址并且我们还访问了 页面为:
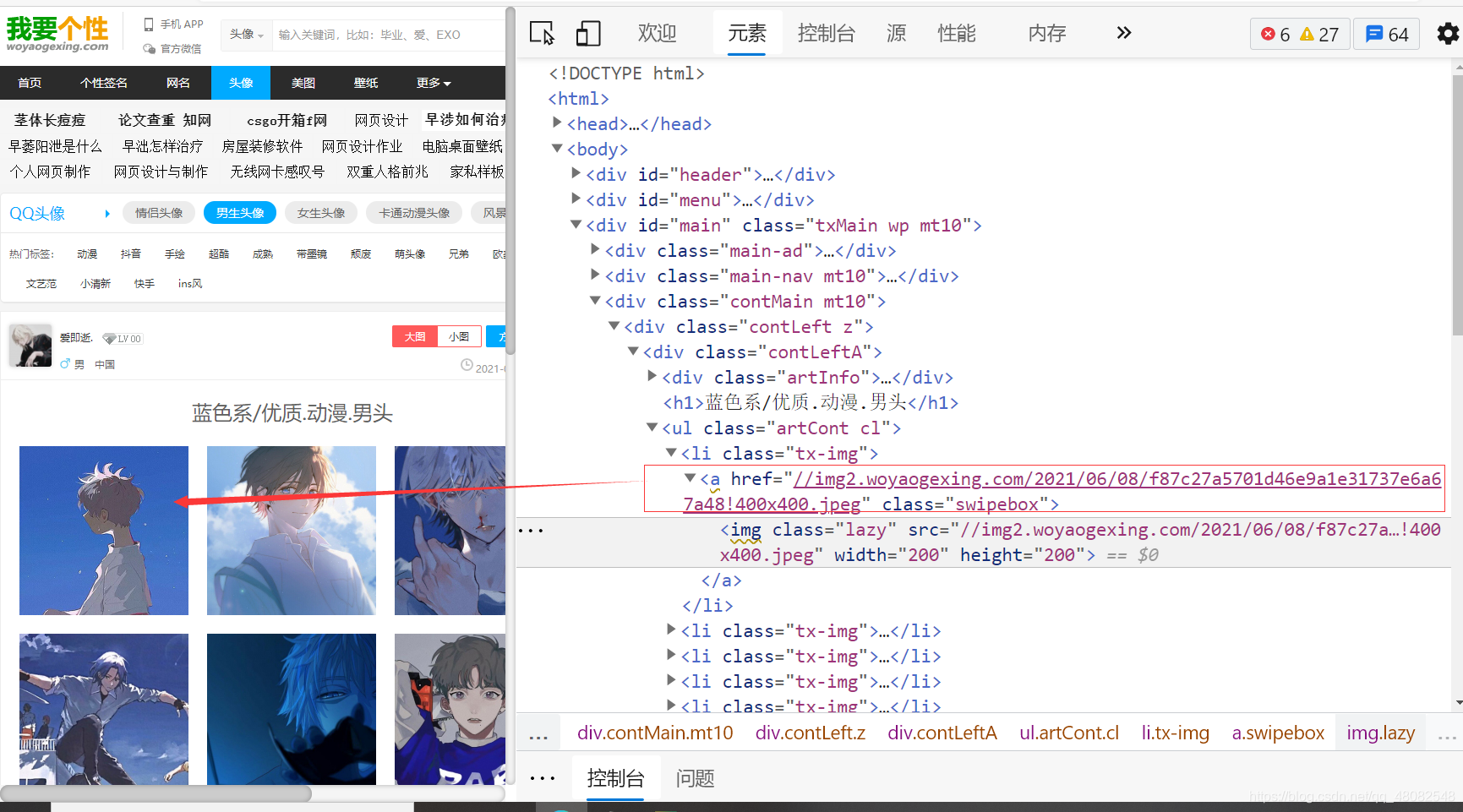
可以看到新的到的页面里就有图片地址了 提取图片地址并下载的代码如下:
parse = BeautifulSoup(res.text, "html.parser")
detail_a = parse.find_all("img", class_="lazy")
for j in detail_a:
url = "https:" + j.get("src")
res = requests.get(url)
f = open("../头像/第%s张图片.jpg" % (str(cont)), "wb")
f.write(res.content)
f.close()
print("第%s张图片下载完成" % cont)
cont += 1
print("全部完成")

















 2110
2110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









