







1.测试用例数据库信息
本文章采用的数据库结构,以及MySQL版本:5.7
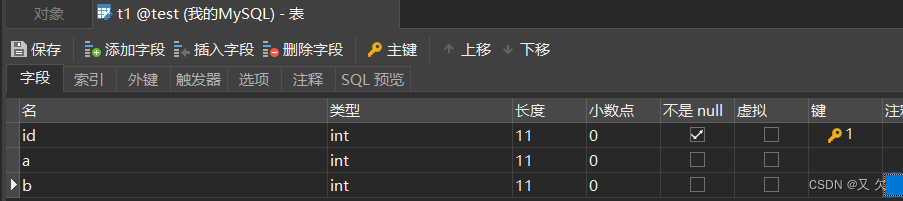
t1 表,有一个主键id,字段a,字段b。 (此表建立了一个索引a) 数据大约1000条
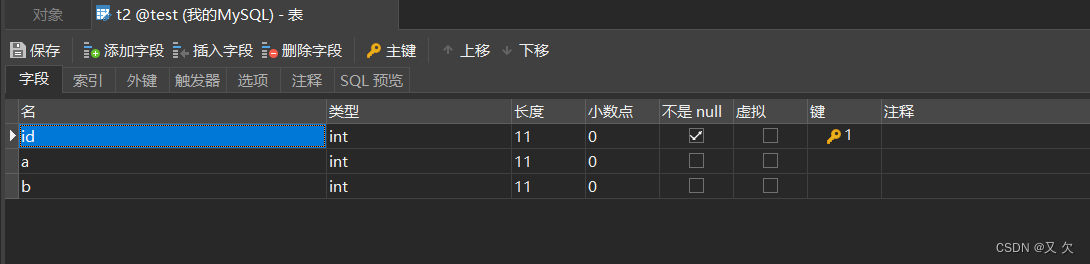
t2 表,有一个主键id,字段a,字段b。 (此表也建立了一个索引a) 数据大约100w条
2.join的常见用法
1. inner jon 内连接
内连接又叫等值连接,此时的inner可以省略。获取两个表中有匹配关系的记录,即两表取交集
select *
from t1 as t
join t2 as tt on t.id=tt.id
2. left join 左连接
以左表为基础,获取匹配关系的记录,如果右表中没有匹配项,NULL表示
select *
from t1 as t
left join t2 as tt on t.id=tt.id
3. right join 右连接
以右表为基础,获取匹配关系的记录,如果左表中没有匹配项,NULL表示
select *
from t1 as t
right join t2 as tt on t.id=tt.id
4. straight_join
straight_join 让 MySQL 使用固定的连接方式执行查询,这样优化器只会按照我们指定的方式去 join。其中,t1 是驱动表,t2 是被驱动表。
select *
from t1 as t
straight_join t2 as tt on t.id=tt.id
3.join语句的执行流程
执行如下SQL语句,此时t1 是驱动表,t2 是被驱动表。
select * from t1 straight_join t2 on (t1.a=t2.a);
使用explain查看执行详情
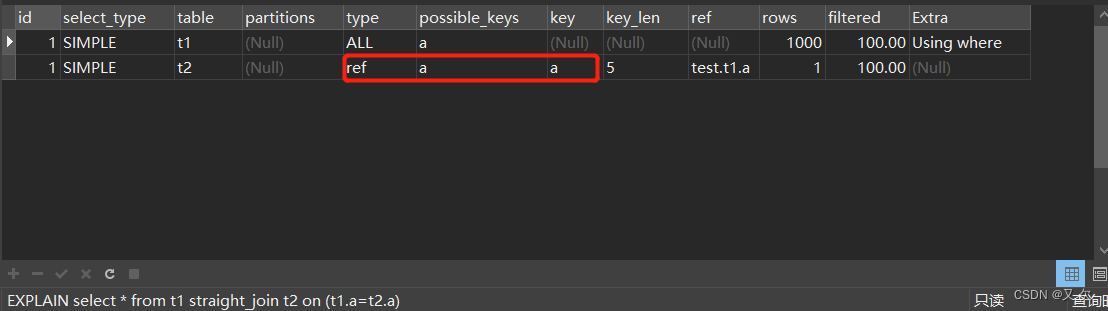
图中你可以看到驱动表t1进行了全表扫描,t2表使用了索引a。
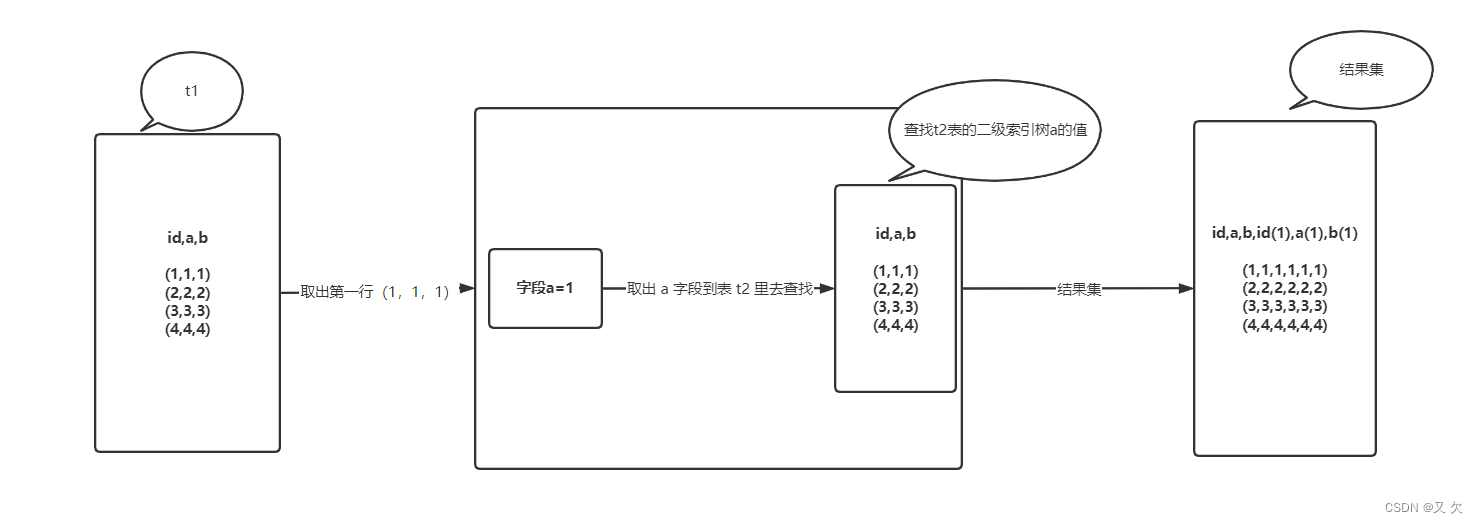
这个语句执行流程如下
1.从表 t1 中读入一行数据 R;
2.从数据行 R 中,取出 a 字段到表 t2 里去查找;
3.取出表 t2 中满足条件的行,跟 R 组成一行,作为结果集的一部分;
4.重复执行步骤 1 到 3,直到表 t1 的末尾循环结束。
那么此流程一共扫描了多少行?
1. t1表是全表扫描因此扫描了1000行。
2. 因为t2表走的是树搜索过程。由于我们构造的数据都是一一对应的,因此每次的搜索过程都只扫描一行,也是总共扫描 1000 行;
3. 整个执行流程,总扫描行数是 2000行。
那么,如果t2表没有使用索引它的流程是怎样呢?
4. Simple Nested-Loop Join 和Block Nested-Loop Join
1.Simple Nested-Loop Join (在5.5版本之前会使用)
当我们执行如下SQL时,t1表还是进行全表扫描,但是t2表上b字段没有索引
select * from t1 straight_join t2 on (t1.a=t2.b);
他的执行流程和上面还是一样,还是从t1表一行行取出来去t2表中找,那么他扫描了多少行?
1. t1表是全表扫描因此扫描了1000行。
2. 因为t2表走的是全表扫描,也就是扫描 100w 行;
3. 整个执行流程,总扫描行数是 1000 * 100w = 10亿行。
这个很笨重的算法叫做Simple Nested-Loop Join,不过MySQL并没有使用这个算法,而是使用了Block Nested-Loop Join算法。
2.Block Nested-Loop Join (5.5版本以后)
当我们执行如下SQL时,t1表还是进行全表扫描,但是t2表上b字段没有索引
select * from t1 straight_join t2 on (t1.a=t2.b);
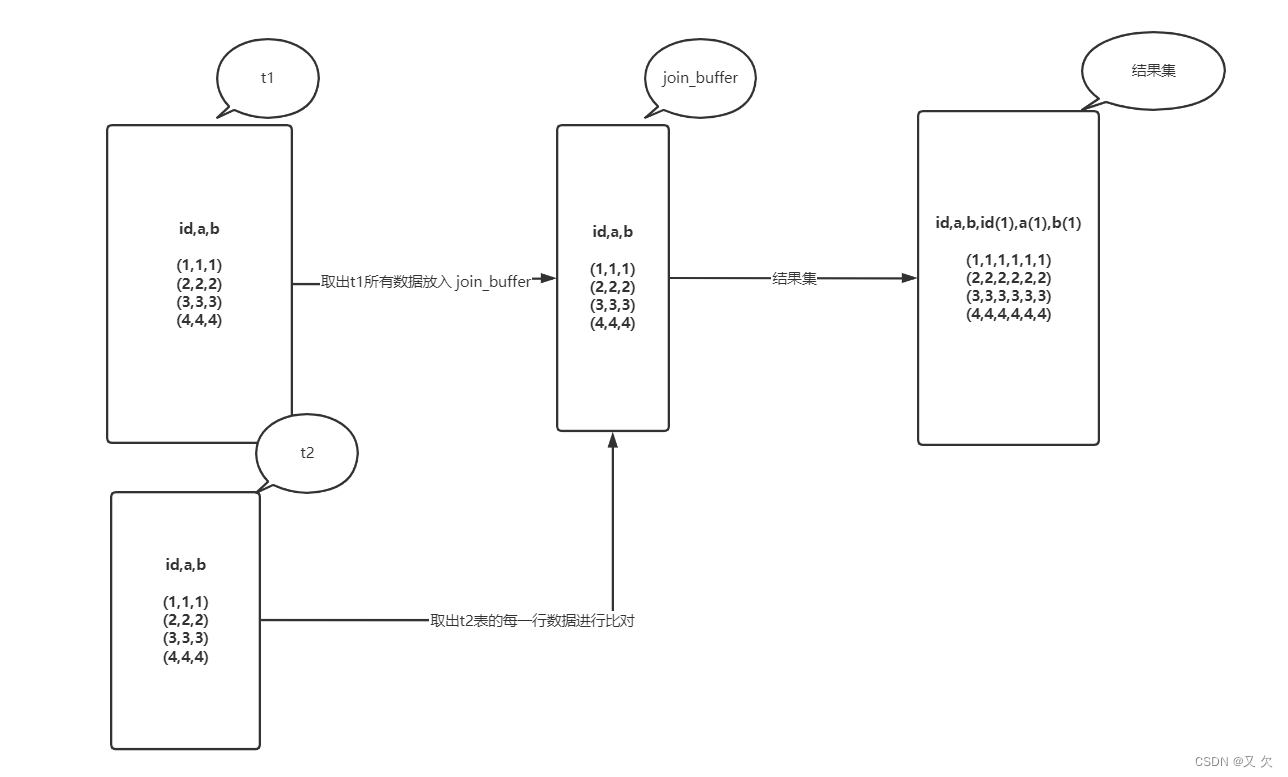
他的执行流程和上面还是一样,还是从t1表一行行取出来去t2表中找,那么他扫描了多少行?
1.把表 t1 的数据读入线程内存 join_buffer 中,由于我们这个语句中写的是 select *,因此是把整个表 t1 放入了内存;
2.扫描表 t2,把表 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回。
由于 join_buffer 是以无序数组的方式组织的,因此对表 t2 中的每一行,都要做 100w 次判断,总共需要在内存中做的判断次数是:1000*100w=10 亿次 。因此,从时间复杂度上来说,这两个算法是一样的。但是,Block Nested-Loop Join 算法的这 10 亿次判断是内存操作,速度上会快很多,性能也更好。
5.使用Block Nested-Loop Join的注意事项
1.可能会多次扫描被驱动表,占用磁盘 IO 资源;
当我们在使用Block Nested-Loop Join 算法时,我们驱动表会放入join_buffer中,但是会把被驱动表的数据一行一行的取出来跟 join_buffer 中的数据做对比。如果被驱动表有1亿条数据,被驱动表就要扫描1亿次,非常占用io资源。
2.可能会导致 Buffer Pool 的热数据被淘汰,影响内存命中率。
join_buffer 是由 join_buffer_size参数控制的,所以 join_buffer 也有一定大小。如果我们join_buffer放慢了怎么办?
现在假如一个场景? join_buffer每次只能放入t1表60%的数据。
1.扫描表 t1,顺序读取数据行放入 join_buffer 中,在放入60%数据后join_buffer 满了,
2. 扫描表 t2,把 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回;
3. 清空 join_buffer;继续扫描表 t1,顺序读取最后的 12 行数据放入 join_buffer 中
4. 扫描表 t2,把 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回;
在上述例子中,我们发现t1表扫描了两次。t2表也扫描了两次。根据我们MySQL的LRU算法
处于 old 区域的数据页,每次被访问的时候都要做下面这个判断:
1.若这个数据页在 LRU 链表中存在的时间超过了 1 秒,就把它移动到链表头部;
2.如果这个数据页在 LRU 链表中存在的时间短于 1 秒,位置保持不变。1 秒这个时间,是由参数 innodb_old_blocks_time 控制的。其默认值是 1000,单位毫秒。
由于优化机制的存在,一个正常访问的数据页,要进入 young 区域,需要隔 1 秒后再次被访问到。在上述例子中,如果我们join_buffer更小,被驱动表就会被多次扫描,而且这个语句执行时间超过 1 秒,就会在再次扫描t2表的时候,把t2表的数据页移到 LRU 链表头部。这时我们Buffer Pool 的热数据就会被淘汰,影响内存命中率。
6.join语句到底需要怎么优化
执行SQL语句
EXPLAIN select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=400000;
t1和t2表都进行了全表扫描,t1表扫描1000行,t2表扫描了970748行

执行这个SQL语句,我们耗时了46.857s
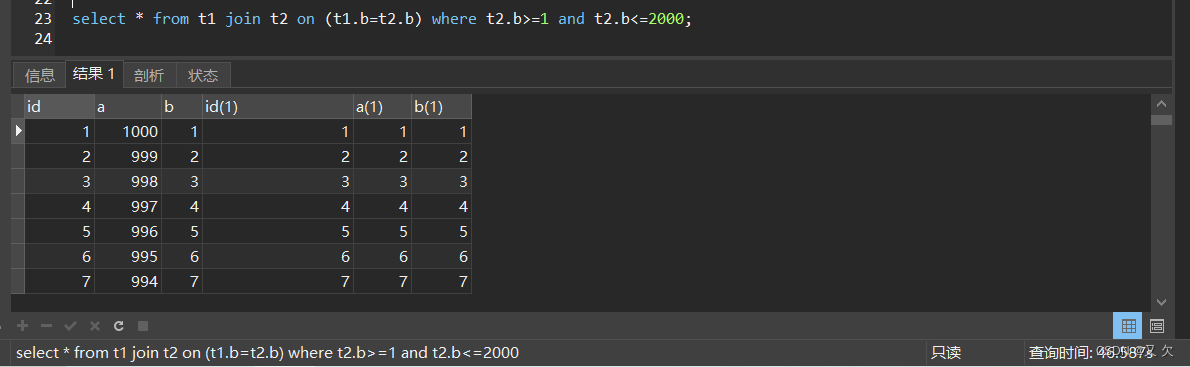
执行这条SQL语句时,由于b字段上没有建立索引,导致t2表需要进行全表扫描。如果建立索引又非常消耗系统资源,不建立索引的情况下。怎么进行优化。
这时候,我们可以考虑使用临时表。使用临时表的大致思路是:
1.把表 t2 中满足条件的数据放在临时表 tmp_t 中;
2.给临时表 tmp_t 的字段 b 加上索引;
3.让表 t1 和 tmp_t 做 join 操作。
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb; 创建临时表, 建立索引
insert into temp_t select * from t2 where b>=1 and b<=2000; 插入数据
select * from t1 join temp_t on (t1.b=temp_t.b);
注意事项:当我们使用范围查询时。 Mysql发现通过索引扫描的行记录数超过全表的25% 时,优化器可能会放弃走索引,自动变成全表扫描。

执行这个SQL语句,我们耗时了0.318s。
7. MySQL中join 后 and和where的区别
select * from t1 left join t2 on(t1.a=t2.a) and (t1.b=t2.b); /*Q1*/
select * from t1 left join t2 on(t1.a=t2.a) where (t1.b=t2.b);/*Q2*/
语句 Q1 返回的数据集是 6 行,表 t1 中即使没有满足匹配条件的记录,查询结果中也会返回一行,并将表 b 的各个字段值填成 NULL。
语句 Q2 返回的是 4 行。从逻辑上可以这么理解,最后的两行,由于表 t2 中没有匹配的字段,结果集里面t2.b 的值是空,不满足
where 部分的条件判断,因此不能作为结果集的一部分。
为了理解这个问题,我需要再和你交代一个背景知识点:在 MySQL 里,NULL 跟任何值执行等值判断和不等值判断的结果,都是 NULL。这里包括, select NULL = NULL 的结果,也是返回 NULL。
因此,语句 Q2 里面t1.b=t2.b 就表示,查询结果里面不会包含t2.b 是 NULL 的行,这样这个 left join 的语义就是“找到这两个表里面,t1、t2 对应相同的行。对于表 t1 中存在,而表 t2 中匹配不到的行,就放弃”。
8. MySQL的 hash join
1.如果我们把驱动表1000条数据存人map,key是字段对应的值。value就是这行数据的值。
2.在把100w条数据读出来,循环遍历这100w条数据。
3.在从100w条数据的每一行拿出对应key字段的值,如果key拿出来有值,就把这行数据结果存入map并返回。
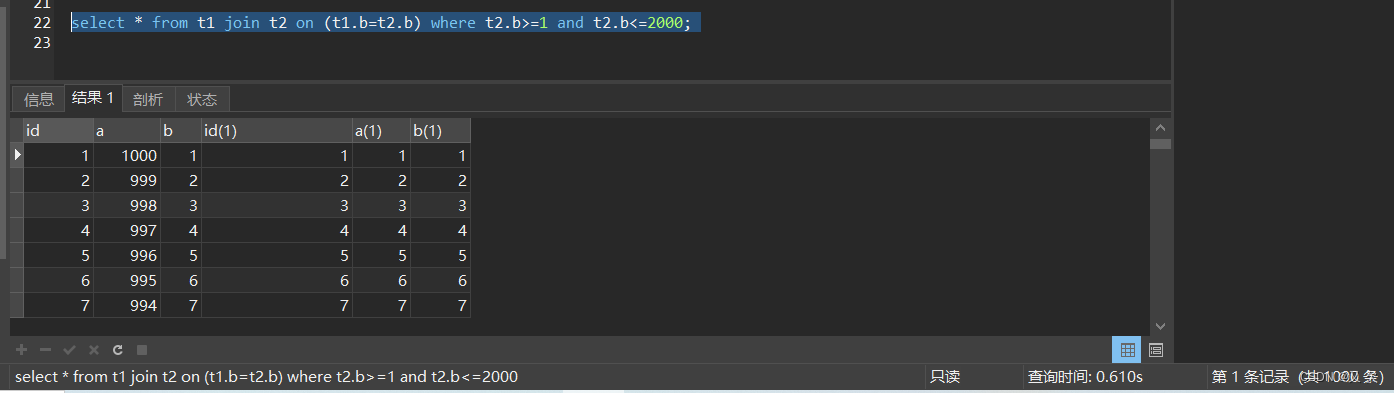
这样我们10亿次比对就会变成100次hash查找
所以在MySQL8.0之后版本,MySQL就加入了hash join。如下是我使用MySQL8.0版本进行查询,耗时0.610s。
9.join总结
1. 应该使用小表作为驱动表
2. 被驱动表关键字段应该建立索引
3.被驱动表无法使用索引、数据量很大时,因适当调整join_buffer大小。避免 Buffer Pool 的热数据被淘汰,影响内存命中率。
4.MySQL8.0之后版本,已经支持hash join,没有升级的小伙伴赶紧升级把!!!

















 6729
6729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









