







声明
文章是基于文章是基于:哔哩哔哩上的《黑马程序员python教程,8天python从入门到精通,学python看这套就够了》视频教程所做的学习笔记,仅为学习使用!!如有侵权,联系删除
目录
0、Matplotlib
在深度学习的实验中,图形的绘制和数据的可视化非常重要。Matplotlib是用于绘制图形的库,使用Matplotlib可以轻松地绘制图形和实现数据的可视化。
(一)绘制简单图形
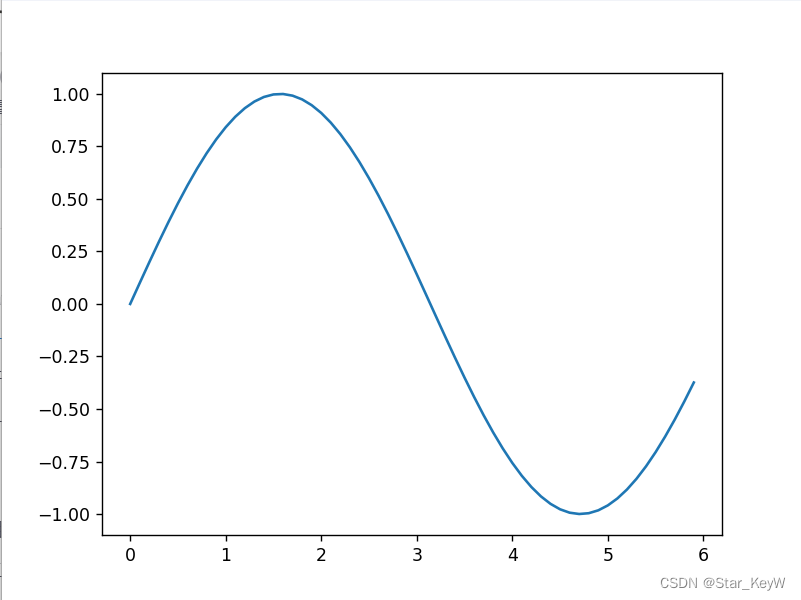
可以使用 matplotlib 的 pyplot 模块绘制图形。看一个绘制sin函数曲线的例子。
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use('TkAgg') # 修改 backend 配置
# 生成数据
x = np.arange(0, 6, 0.1) # 以0.1为单位,生成0到6的数据。即 [0, 0.1, 0.2,... 5.8, 5.9]
y = np.sin(x) # 应用NumPy的sin函数
# 绘制图像
plt.plot(x, y) # 将 x 、y 的数据传给 plt.plot 方法,然后绘制图形
plt.show() # 显示图形这里使用NumPy的 arange 方法生成了 [0, 0.1, 0.2, ..., 5.8, 5.9] 的数据,将其设为 x 。对 x 的各个元素,应用NumPy的sin函数 np.sin() ,将 x 、y 的数据传给 plt.plot 方法,然后绘制图形。最后,通过 plt.show() 显示图形。
(二)pyplot的功能
在刚才的sin函数的图形中,我们尝试追加cos函数的图形,并尝试使用pyplot 的添加标题和x轴标签名等其他功能。
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use('TkAgg')
# 生成数据
x = np.arange(0, 6, 0.1) # 以0.1为单位,生成0到6的数据
# 计算正弦 和 余弦值
y1 = np.sin(x)
y2 = np.cos(x)
# 绘制图像
# label参数指定了每条曲线的标签,将用于图例
plt.plot(x, y1, label="sin")
plt.plot(x, y2, linestyle = "--", label = "cos")# 指定线型用虚线绘制
plt.xlabel("x")# x轴标签
plt.ylabel("y")# y轴标签
plt.title("sin & cos")# 标题
plt.legend()# 显示图例
plt.show()
(三)显示图像
pyplot 中还提供了用于显示图像的方法 imshow() 。另外,可以使用matplotlib.image 模块的 imread() 方法读入图像。
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.image import imread
matplotlib.use('TkAgg')
# python.png存储在python文件的同目录下
img = imread("python.png") # 用imread函数读取名为"python.png"的图片,将图片数据保存在变量 img中
plt.imshow(img) # 使用imshow函数显示图片,这个函数会在当前图形中显示图像
plt.show() 
使用技术:Echarts是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可,而Python 是门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时pyecharts诞生了。
一、折线图
(一)Json
-
JSON是一种轻量级的数据交互格式。可以按照JSON指定的格式去组织和封装数据
-
JSON本质上是一个带有特定格式的字符串
-
JSON就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互
-
JSON就是一种非常良好的中转数据格式

1、Json数据转化
# json数据的格式:
# 类似于字典
{"name":"admin", "age":18}
# 也可是
# 类似于列表
[{"name":"admin", "age":18}, {"name":"root", "age":16}, {"name":"张三", "age":24}]2、Python数据和Json数据的相互转化
# 导入json模块
import json
# 准备符合格式json格式要求的python数据
# 准备列表,列表内每一个元素都是字典
data = [ {"name":"老王", "age":16} , {"name":"张三", "age":20} ]
# 通过json.dumps(data)方法把python数据转化为了json数据
# 字典 、列表 式子数据,转化成json,本质上转化结果是字符串
# 如果有中文可以带上ensure_ascii = False来确保中文正常转换
json_Str = json.dumps(data, ensure_ascii = False)
# 准备字典,将字典转换为JSON
# 字典 、列表 式子数据,转化成json,本质上转换结果是字符串
d = {"name":"周杰伦", "addr":"台北"}
# # 如果有中文可以带上ensure_ascii = False来确保中文正常转换
json_str = json.dumps(d, ensure_ascii = False)
# 将JSON字符串转换为python数据类型,[{k:v, k:v}, {k:v, k:v}]
s = "[ {"name":"张三", "age":11}, {"name":"王大锤", "age":13} ]"
j = json.load(s)
print(type(j)) # <class 'list'>
print(j) # [ {'name':'张三', 'age':11}, {'name':'王大锤', 'age':13}]
# 将JSON字符串转化为python数据类型,{k:v, k:v}
s = "{"name":"周杰伦", "addr":"台北"}"
d = json.load(s)
print(type(d)) # <class 'dict'>
print(d)# {'name':'周杰伦', 'addr':'台北'}(二)pyecharts模块介绍
-
如果想要做出数据可视化效果图, 可以借助pyecharts模块来完成
-
本体是Echarts框架,由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可; Python是门富有表达力的语言,很适合用于数据处理.。当数据分析遇上数据可视化时pyecharts 诞生了
-
官方示例:Document
-
安装PyEcharts模块
(三)pyecharts快速入门
1、基础折线图
"""
演示pyecharts的基础折线图
"""
# 导包
# pyecharts这个包中的charts模块下的Line功能对象
from pyecharts.charts import Line
# 创建一个折线图对象
# 本质得到一个空的二维坐标系
line = Line()
# 给折线图对象添加x轴的数据
line.add_xaxis(["中国", "美国", "英国"])
# 给折线图对象添加y轴的数据 和 图名称
line.add_yaxis("GDP数据", [30, 20, 10])
# 通过render方法,将代码生成为图像
line.render()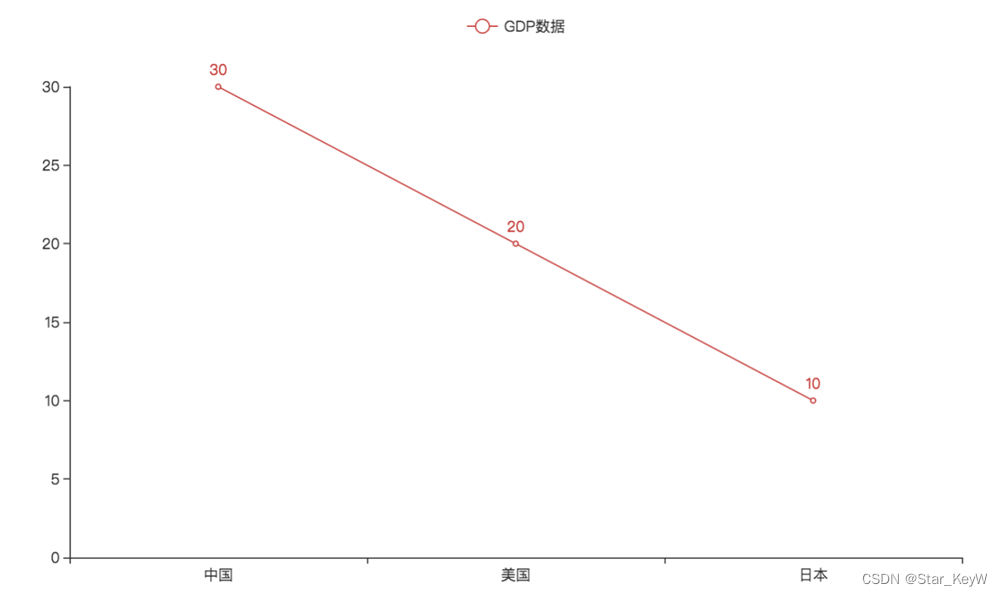
2、配置选项
-
全局配置选项(通用设置)
-
set_global_opts方法来进行配置 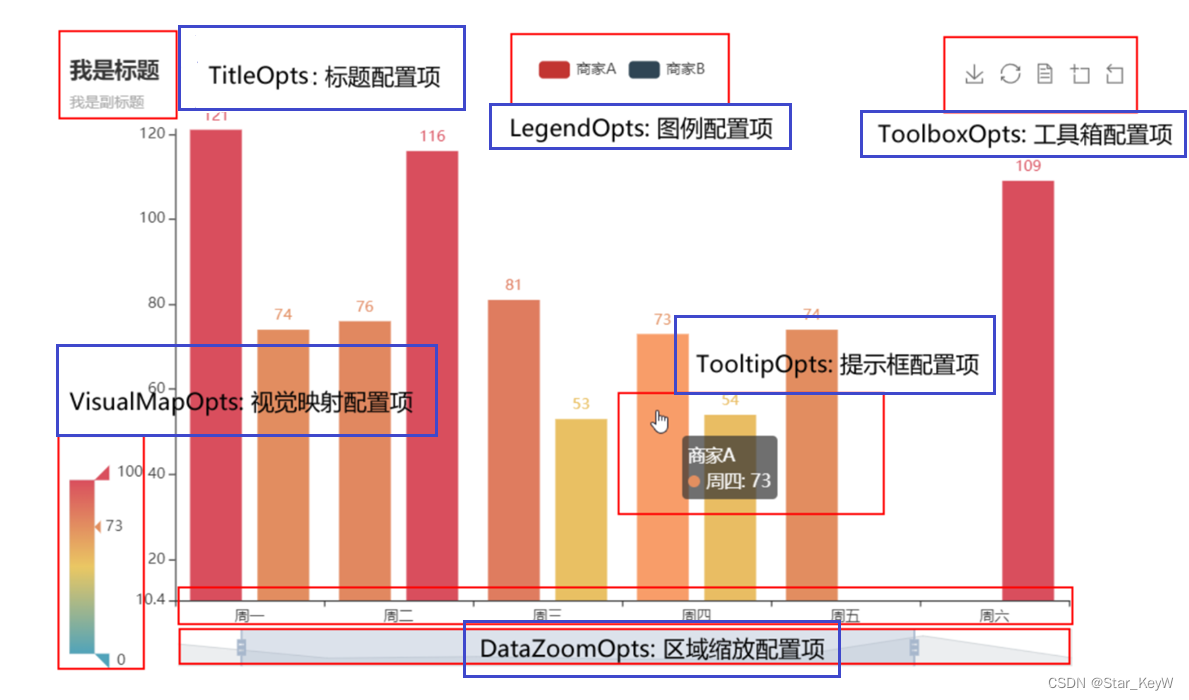
-
""" 演示pyecharts的基础折线图 """ # 导包 from pyecharts.charts import Line # 所有可配置的选项都在options里 from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts # 创建一个折线图对象 line = Line() # 给折线图对象添加x轴的数据 line.add_xaxis(["中国", "美国", "英国"]) # 给折线图对象添加y轴的数据 line.add_yaxis("GDP", [30, 20, 10]) # 设置全局配置项set_global_opts来设置 line.set_global_opts( # 设置标题,关键字传参 pos:position 位置 title_opts = TitleOpts(title="GDP展示", pos_left="center", pos_bottom="1%"), # 控制图例 legend_opts = LegendOpts(is_show = True), # 控制工具箱 toolbox_opts = ToolboxOpts(is_show = True), # 视觉映射:鼠标悬停在图上的点,会提供相关信息 visualmap_opts = VisualMapOpts(is_show = True) # 视觉映射:鼠标悬浮在图上的点会提示点的信息 ) # 通过render方法,将代码生成为图像 line.render()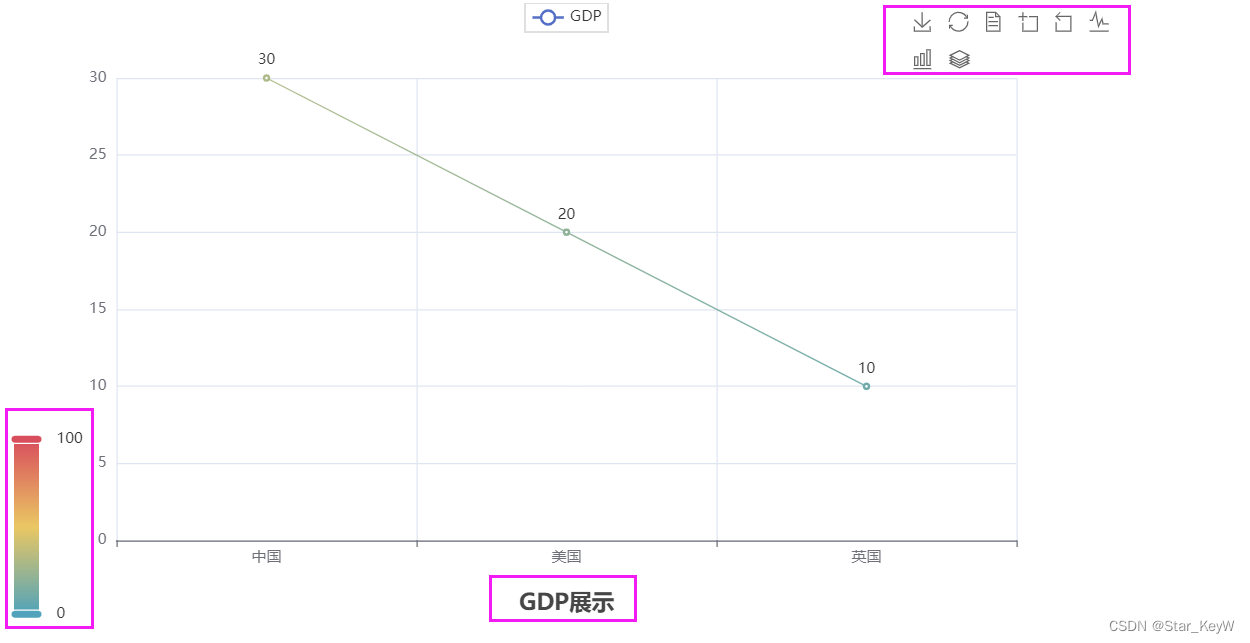
-
(四)数据处理
通过json模块对数据进行处理
-
原始数据格式:
-
导入模块:
-
# 导入json模块 import json
-
-
对数据进行整理,让数据符合json格式
-
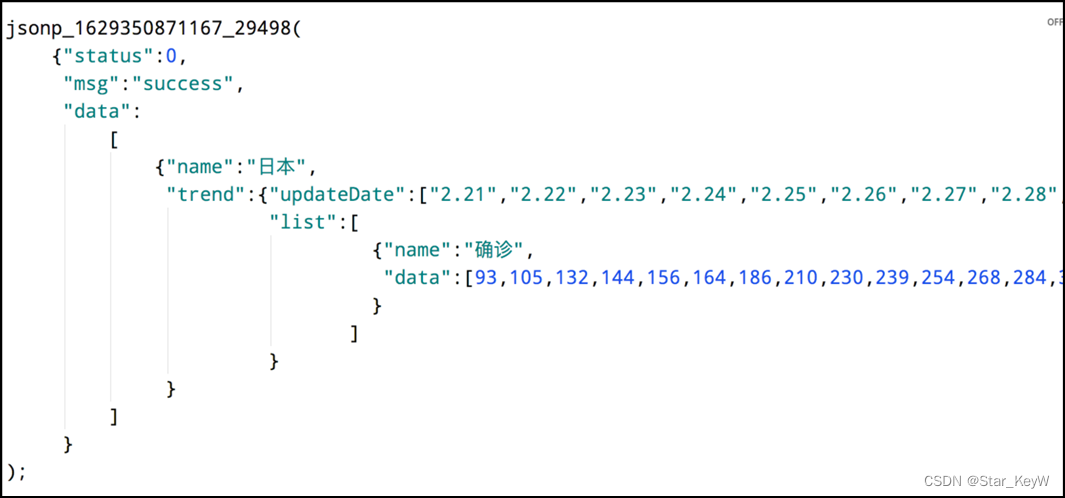
# 处理数据 # 文件对象要记得关闭 # 读取数据 file_usa = open("E:/Heima_Python_Learning/09_折线图/美国.txt", "r", encoding = "UTF-8") usa_data = file_usa.read() # 美国数据的全部内容 # 去掉不符合JSON规范的开头 jsonp_1629344292311_69436( # 将更改结果赋值回去,等同于更新 usa_data = usa_data.replace("jsonp_1629344292311_69436(", "") # 去掉不符合JSON规范的结尾 ); 序列的切片 从正数第0个一直到倒数第二个,且不包括结尾,步长为1 # 注意切片的格式,可以当做经验积累 usa_data = usa_data[:-2] # JSON转Python字典 usa_dict = json.loads(usa_data) # 获取trend key trend_data = usa_dict["data"][0]["trend"] # 获取日期数据,用于x轴,取2020年(到314下标结束) x_data = trend_data["updateDate"][:314] # 获取确诊数据,用于y轴,取2020年(到314下表结束) y_data = trend_data["list"][0]["data"][:314]
-
(五)创建折线图
-
导入模块
-
# 导入折线图模块 from pyecharts.charts import Line # 导入配置选项模块 from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts
-
-
折线图相关配置项

-
创建折线图
-
# 创建折线图 l = Line(init_opts = opts.InitOpts(width = "1600px", height="800px")) -
这里的Line()是构建类对象
-
-
添加数据
-
# 添加x轴数据 line.add_xaxis(usa_x_data) # 3个国家x轴数据(日期)是公用的,任选其一使用即可 # 添加y轴数据 line.add_yaxis("美国确诊人数", usa_y_data) line.add_yaxis("日本确诊人数", jp_y_data) line.add_yaxis("印度确诊人数", in_y_data)
-
-
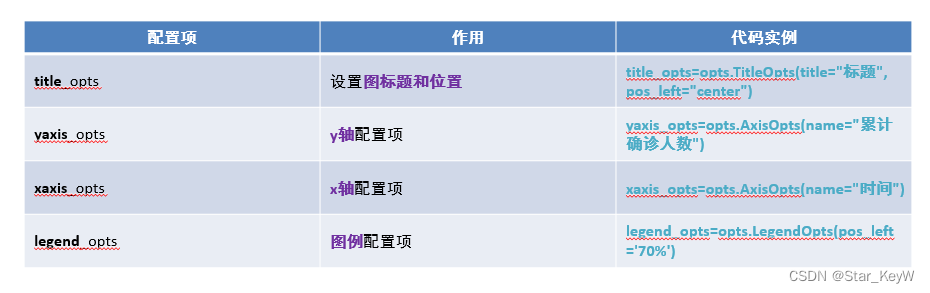
.add_yaxis相关配置选项
-
全局配置选项
-
.set_global_opts全局配置选项
-
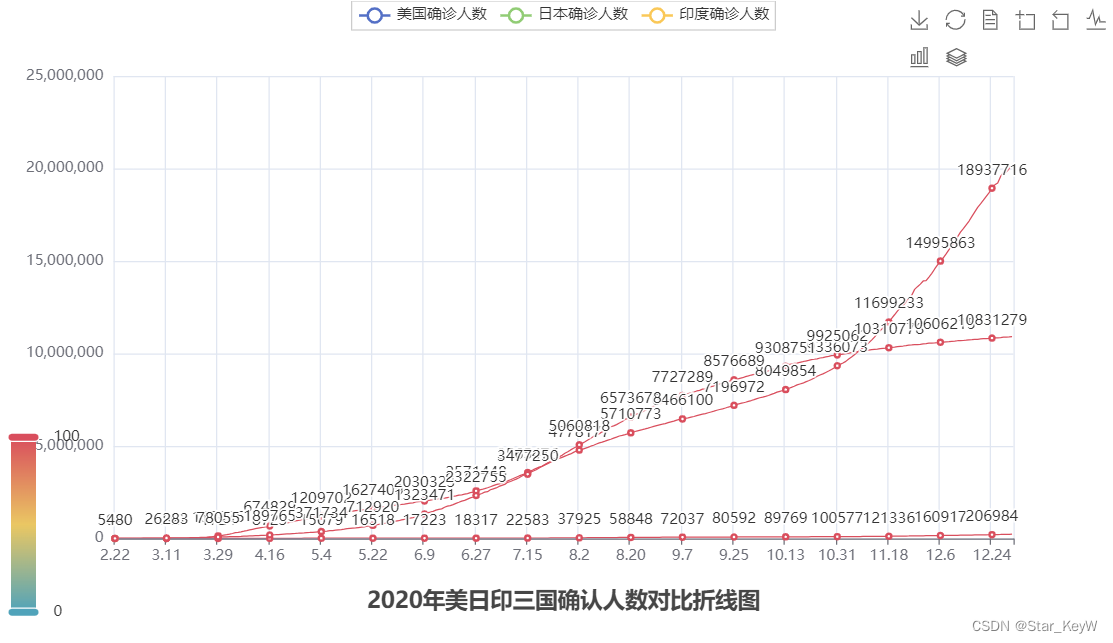
# 设置全局配置项set_global_opts来设置 line.set_global_opts( # 关键字传参 pos:position 位置 距离底部1%,即在最底部 title_opts = TitleOpts(title="2020年美日印三国确认人数对比折线图", pos_left="center", pos_bottom="1%"), legend_opts = LegendOpts(is_show = True), toolbox_opts = ToolboxOpts(is_show = True), visualmap_opts = VisualMapOpts(is_show = True) # 视觉映射:鼠标悬浮在图上的点会提示点的信息 )
-

二、地图可视化
-
掌握使用pyecharts构建基础的全国地图可视化图表
(一)基础地图
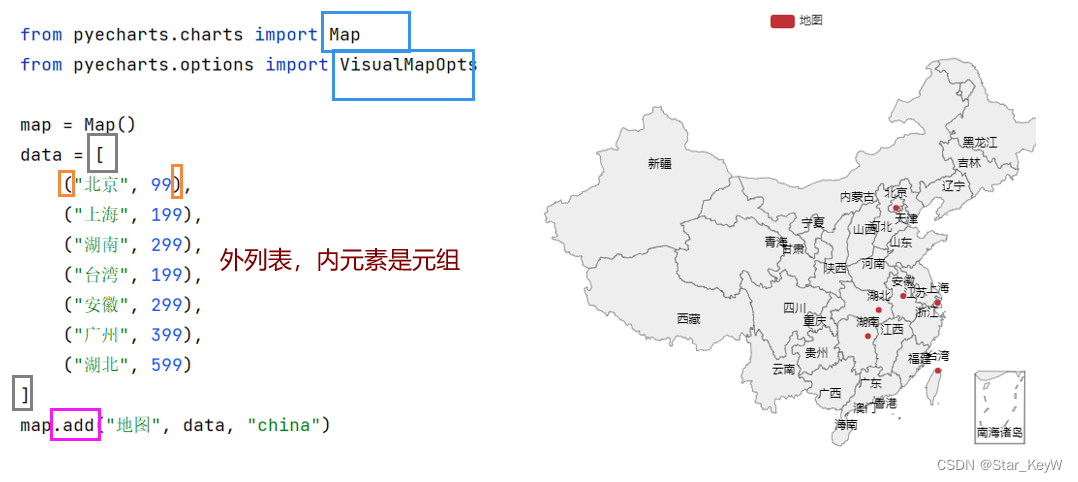
from pyecharts.charts import Map
# 准备地图对象
map = Map()
# 准备数据
data = [
("北京", 99),
("上海", 199),
("湖南", 299),
("台湾", 399),
("广东", 499),
]
# 添加数据,默认显示中国地图
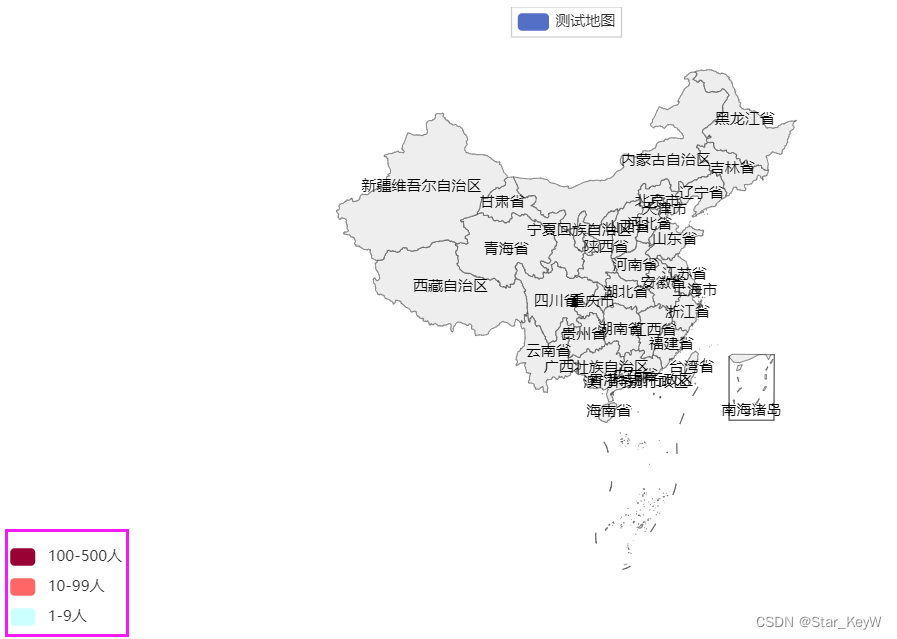
map.add("测试地图", data, "china")
# 绘图
map.render()
1、视觉映射器

# 设置全局选项
china_map.set_global_opts(
visualmap_opts = VisualMapOpts(
is_show = True, # 图示 + 地图颜色
is_piecewise=True, # 开启手动校准
pieces = [ # 具体的校准范围 列表
# 手动指定分成3段 字典
{"min":1, "max":9, "label":"1-9人", "color":"#CCFFFF"},
{"min":10, "max":99, "label":"10-99人", "color":"#FF6666"},
{"min":100, "max":500, "label":"100-500人", "color":"#990033"}
]
)
)
(二)全国疫情地图
1、获取数据
file_yq = open("E:/Heima_Python_Learning/10_地图/疫情.txt", "r", encoding = "UTF-8")
data = file_yq.read() # 全部数据
# 关闭文件
file_yq.close()2、处理数据
import json
# 取出各省数据
# 将字符串json转换为python的字典
data_dict = json.loads(data) # 基础数据字典
# 从字典中取出省份的数据
province_data_list = data_dict["areaTree"][0]["children"]
# 组装每个省份和确诊人数为元组,并各个省的数据都封装入列表内
data_list = [] # 绘图所需要的数据列表
for province_data in province_data_list:
province_name = province_data["name"] # 省份名称
province_people = province_data["total"]["confirm"] # 确诊人数
data_list.append((province_name, province_people)) # 变成元组添加到数据列表中
3、创建地图
# 读取数据文件
from pyecharts.charts import Map
# 创建地图对象
china_map = Map()
# 添加数据
# 第一个参数表示地图的顶部显示,legend 的图例筛选,解释标签
china_map.add("各省份确诊人数", data_list, "china")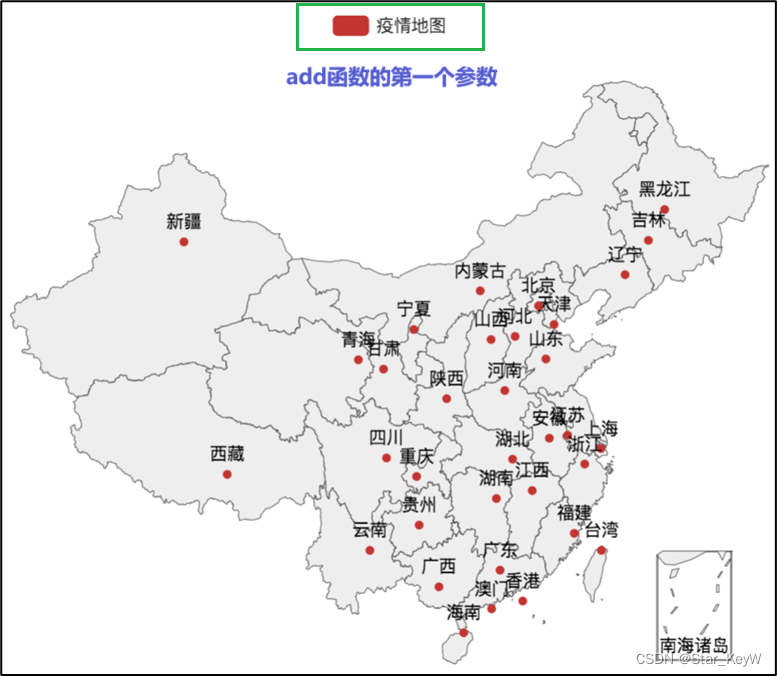
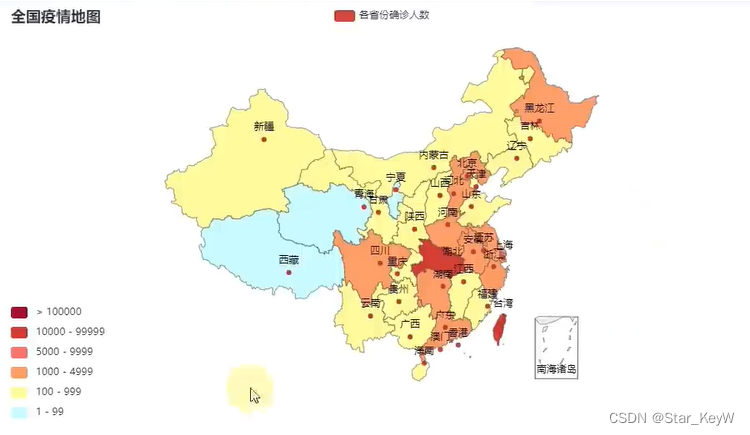
4、设置全局配置
from pyecharts.options import *
# 设置全局配置,定制分段的视觉映射
china_map.set_global_opts(
# title表示地图的标题
title_opts=TitleOpts(title = "全国疫情地图"),
# 视觉映射配置选项
visualmap_opts = VisualMapOpts(
is_show=True, # 是否显示
is_piecewise=True, # 是否分段
pieces = [
{"min": 1, "max": 99, "lable": "1-99人", "color": "#CCFFFF"},
{"min": 100, "max": 999, "lable": "100-999人", "color": "#FFFFF99"},
{"min": 1000, "max": 4999, "lable": "1000-4999人", "color": "#FF9966"},
{"min": 5000, "max": 9999, "lable": "5000-9999人", "color": "#FF6666"},
{"min": 10000, "max": 99999, "lable": "10000-99999", "color": "#CC3333"},
{"min": 100000, "lable": "10000-99999", "color": "#990033"}
]
)
)
5、绘制地图
# 绘图
# 指定生成的网页名称
china_map.render("全国疫情地图.html")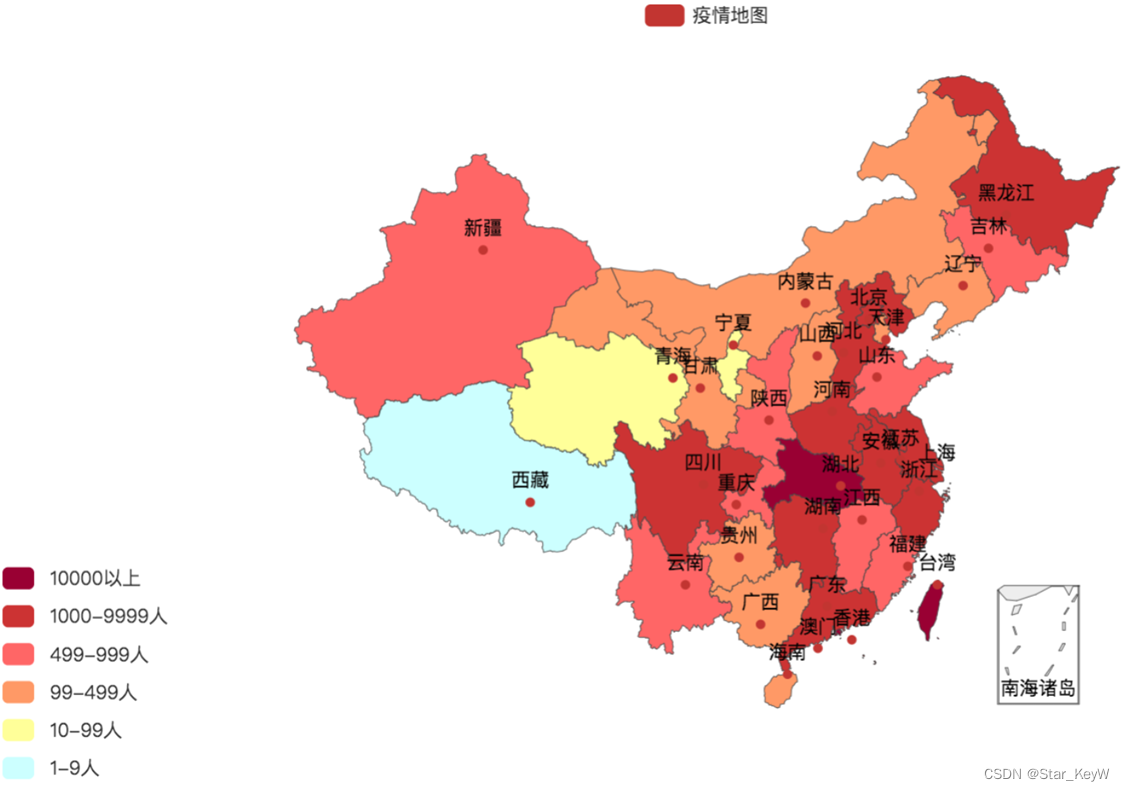
(三)河南省级疫情地图
-
河南省为例
1、读取文件
file_henan = open("E:/Heima_Python_Learning/10_地图/疫情.txt", "r", encoding = "UTF-8")
data = file_henan.read() # 全部数据
# 关闭文件
file_henan.close()2、获取河南省数据
import json
# json数据转化为python字典
data_dict = json.loads(data)
# 取到河南省数据
cities_data = data_dict["areaTree"][0]["children"][3]["children"]3、处理数据
data_list = []
for city_data in cities_data:
city_name = city_data["name"] + "市"
city_people = city_data["total"]["confirm"]
data_list.append((city_name, city_people))4、构建地图
# 读取数据文件
from pyecharts.charts import Map
hn_map = Map()
map.add("河南省疫情分布",data_list,"河南")5、设置全局选项
from pyecharts.options import *
# 设置全局配置,定制分段的视觉映射
hn_map.set_global_opts(
# title表示地图的标题
title_opts=TitleOpts(title = "河南省疫情地图"),
# 视觉映射配置选项
visualmap_opts = VisualMapOpts(
is_show=True, # 是否显示
is_piecewise=True, # 是否分段
pieces = [
{"min": 1, "max": 99, "lable": "1-99人", "color": "#CCFFFF"},
{"min": 100, "max": 999, "lable": "100-999人", "color": "#FFFFF99"},
{"min": 1000, "max": 4999, "lable": "1000-4999人", "color": "#FF9966"},
{"min": 5000, "max": 9999, "lable": "5000-9999人", "color": "#FF6666"},
{"min": 10000, "max": 99999, "lable": "10000-99999", "color": "#CC3333"},
{"min": 100000, "lable": "10000-99999", "color": "#990033"}
]
)
)6、绘图
# 绘图
# 指定生成的网页名称
china_map.render("河南省疫情地图.html")
三、动态柱状图
(一)基础柱状图
-
构建一个基础的柱状图并能够反转x和y轴
1、通过Bar构建基础柱状图
from pyecharts.charts import Bar
# 使用Bar构建基础柱状图
bar = Bar()
# 添加x轴的数据
bar.add_xaxis(["中国", "美国", "英国"])
# 添加y轴数据
# 第一个参数是顶部提示框
bar.add_yaxis("GDP", [30, 20, 10])
# 绘图
bar.render("基础柱状图.html")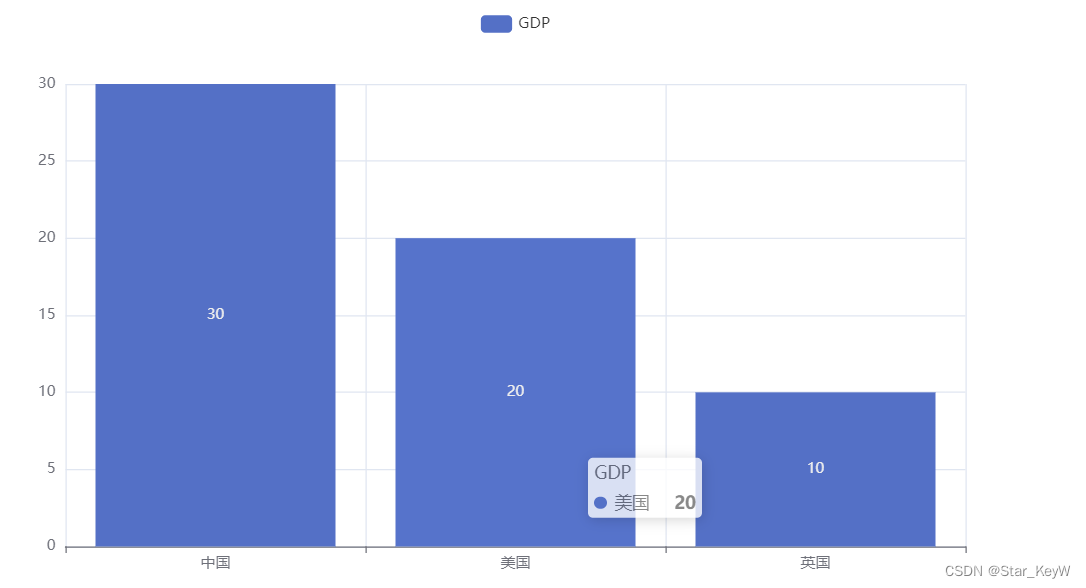
2、反转x轴和y轴
# 反转x和y轴
bar.reversal_axis()
# 绘图
bar.render("基础柱状图.html")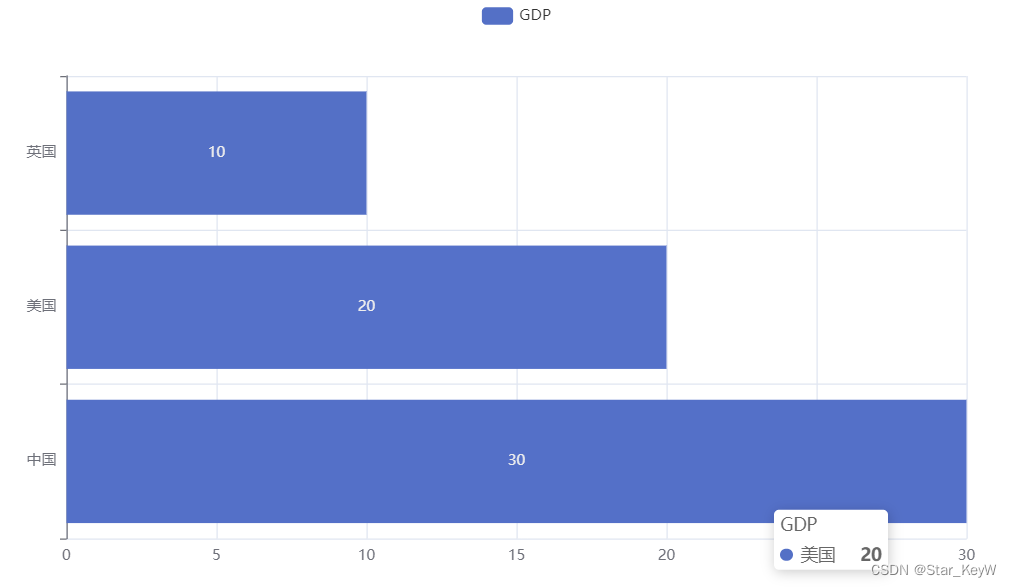
3、数值标签显示在图标右侧
from pyecharts.options import LabelOpts
# 添加y轴数据
# label_opts=LabelOpts(position = "right",关键字参数,设置数值标签在图右侧
bar.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position = "right"))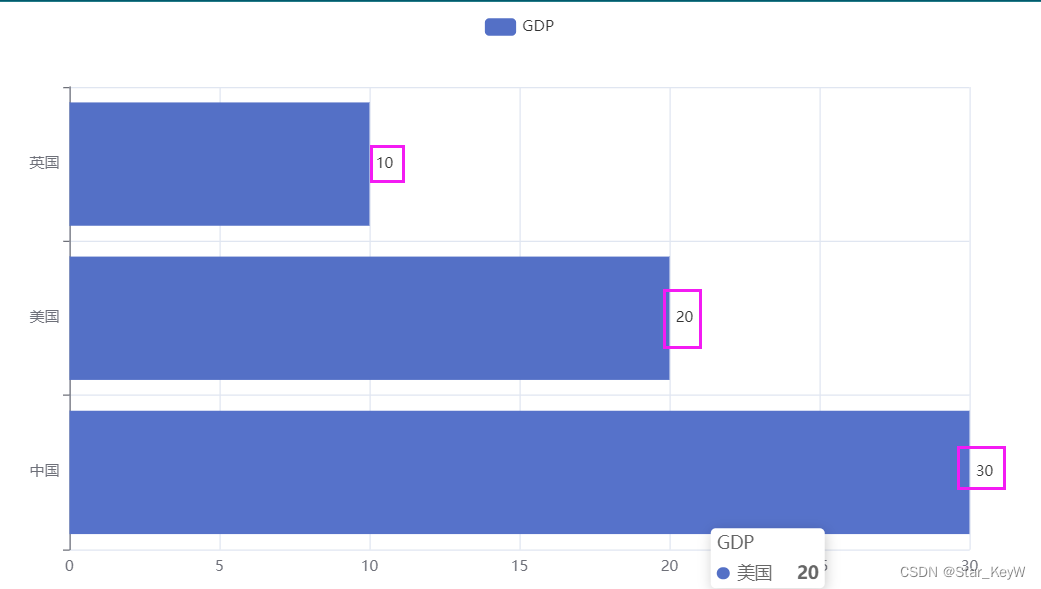
(二)基础时间线柱状图
1、Timeline() -- 时间线
-
如果说一个Bar、Line对象是一张图表的话,时间线就是创建一个一维的x轴,轴上每一个点就是一个图表对象
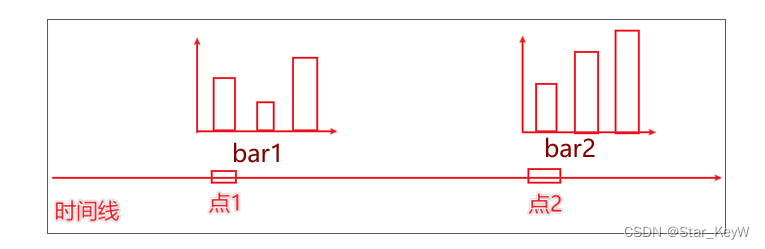
-
一个时刻对应一个图表,在x轴上提供多个点(时刻),很多个时刻的图表连续起来,就像是动画的帧数一样,形成动态的效果
2、根据时间线创建对应数量的柱状图
from pyecharts.charts import Bar
bar1 = Bar()
bar1.add_xaxis(["中国", "美国", "英国"])
bar1.add_yaxis("GDP", [30, 30, 20], label_opts=LabelOpts(position="right"))
bar1.reversal_axis()
bar2 = Bar()
bar2.add_xaxis(["中国", "美国", "英国"])
bar2.add_yaxis("GDP", [50, 50, 50], label_opts=LabelOpts(position="right"))
bar2.reversal_axis()
bar3 = Bar()
bar3.add_xaxis(["中国", "美国", "英国"])
bar3.add_yaxis("GDP", [70, 60, 80], label_opts=LabelOpts(position="right"))
bar3.reversal_axis()3、创建时间线
from pyrcharts.charts import Timeline
# 构建时间线对象
timeline = Timeline()
# 在时间线内添加柱状图对象
timeline.add(bar1,"点1")
timeline.add(bar2,"点2")
timeline.add(bar3,"点3")
# 绘图是用时间线对象绘图,而不是bar对象
timeline.render("基础时间线柱状图.html")
4、设置自动播放
# 自动播放设置
timeline.add_schema(
play_interval = 1000, # 自动播放的时间间隔,单位毫秒
is_timeline_show = True,# 是否在自动播放的时候,显示时间线
is_auto_play = True, # 是否自动播放
is_loop_play = True # 是否循环自动播放
)
5、时间线设置主题
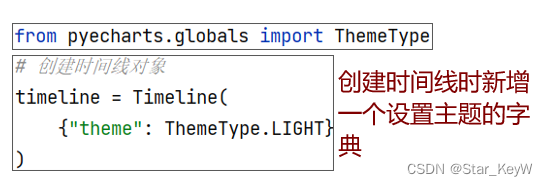

(三)GDP动态柱状图绘制
1、列表的sort方法
-
列表.sort(key=选择排序依据的函数, reverse=True|False)
-
参数key:是要求传入一个函数,表示将列表的每一个元素都传入函数中,返回排序的依据
-
参数reverse:是否反转排序结果,True表示降序,False表示升序
-
-
# 排序:基于带名函数 # 排序的依据是内层列表的第二个元素数字 # 准备列表 my_list = [ ["a", 33], ["b", 66], ["c", 11] ] # 定义排序方法 def choose_sort_key(element): # 列表的每一个元素传入,函数指定按照传入元素的下标1(也就是数字)来排序 return element[1] # true表示实现降序排序 # 将元素传入choose_sort_key函数中,用来确定按照谁来排序 # 关键字传参,因为不是函数的第一个参数 my_list.sort(key=choose_sort_key, reverse=True) print(my_list) -
# 准备列表 my_list = [ ["a", 33], ["b", 66], ["c", 11] ] # 排序:基于lambda匿名函数 # lambda 函数形参: 函数体 my_list.sort(key=lambda element: element[1] , reverse=True) print(my_list)
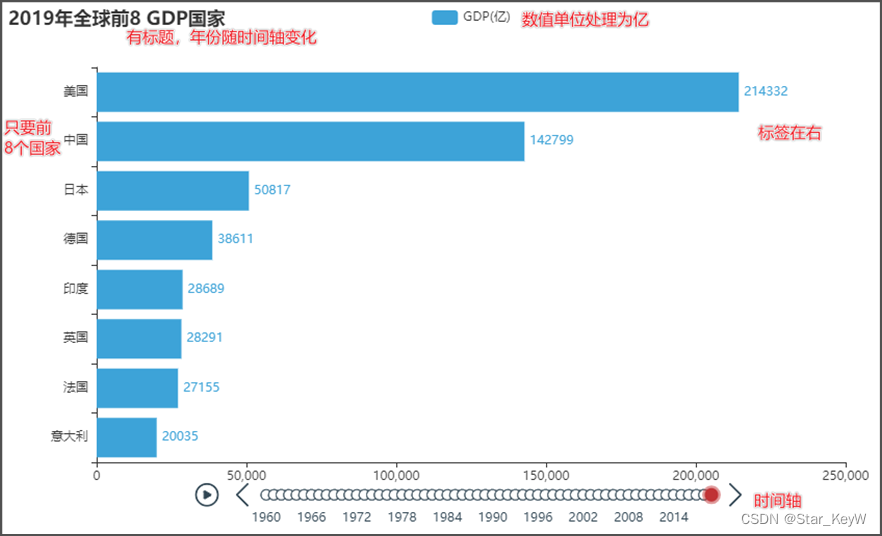
2、需求分析
-
GDP数据处理单位为亿级
-
有时间轴,按照年份为时间轴的点
-
x轴和y轴反转,同时每一年的数据只要前8名国家
-
有标题,标题的年份会动态更改
-
设置了主题为LIGHT
3、获取数据
-
.csv:内存逗号分隔数据。
year,GDP,rate1960,瑞士,9522746719 -
读取数据,删除第一条表头
-
# 读取数据 # 使用记事本打开csv文件后发现格式编码为ANSI,表示的是windows系统的默认编码格式,表示跟随操作系统语言,win10中文,就是GB2312 f = open("E:/Heima_Python_Learning/11_柱状图/1960-2019全球GDP数据.csv", "r", encoding="GB2312") data_lines = f.readlines() # 关闭文件 f.close() # 删除第一条表头数据 # readlines()方法返回的是一个列表对象 data_lines.pop(0) # 等同于 data_lines.del[0]
-
4、读取数据
-
将得到的数据转化为字典存储
-
{ 年份: [ [国家, gdp], [国家,gdp], ...... ], 年份: [ [国家, gdp], [国家,gdp], ...... ], ...... }
-
# 将数据转换为字典存储,格式为: # Key是年份【字符串】,Value是对应年份下,世界各个国家的国家名字,gdp的值【列表】 # { 年份 :[ [国家,gdp] , [国家,gdp], [国家,jdp]..... ] , 年份: [ [国家,gdp], [国家, gdp],....] } # 先定义一个字典对象作为后续存储使用 data_dict = {} for line in data_lines: year = int(line.split(",")[0]) # 年份 country = line.split(",")[1] # 国家 # gdp数据某些比较大的使用了科学计数法的,通过float将其转换成正常的浮点数 gdp = float(line.split(",")[2]) # gdp数据 # 使用年份作为字典的key,其余的国家+GDP数据放到 列表 里 # 如果是第一次执行的话,字典为空,需要构建一个list放入;如果不是空表明for循环不是第一次进入,取出list然后用append添加即可 # 如何判断字典里有没有指定的key? # 若获取字典中不存在的key,则会报出KeyError,所以通过异常抛出 try: # 没有报出异常说明已经有年份数据,说明list已经存在 # 调用list的append方法来进行追加,实现嵌套 data_dict[year].append([country, gdp]) except KeyError: # 如果不存在则构建一个空的列表 data_dict[year] = [] data_dict[year].append([country, gdp])
5、处理数据
-
对年份排序
-
# 从1960到2019大约有59个柱状图,通过for循环年份,从小到大绘图 # 原始数据中的年份可能是乱序,所以取出year来进行排序 # 排序年份 sorted_year_list = sorted(data_dict.keys())
-
-
对国家的gdp排序
-
for year in sorted_year_list: # 从大到小排序 # lambd匿名函数决定排序的依据,用每个元素中的下标1也就是gdp来进行排序 data_dict[year].sort(key=lambda element: element[1], reverse=True) # 取出本年份前8名的国家 year_data = data_dict[year][0:8] # 列表,有序容器,包含切片功能 x_data = [] y_data = [] for country_gdp in year_data: # x轴添加国家数据 x_data.append(country_gdp[0]) # y轴添加gdp数据 # 数据单位是以“亿”为单位 y_data.append(country_gdp[1] / 100000000)
-
-
构建柱状图
-
# 构建柱状图 bar = Bar() # 当前创建出的图像是将gdp从小打大,上到下排序 # x轴和y轴排序颠倒,就可以实现大到小排序绘图 # x轴代表着国家 x_data.reverse() # y轴代表着gdp数据 y_data.reverse() bar.add_xaxis(x_data) # 数值标签在右侧 bar.add_yaxis("GDP(亿)", y_data, label_opts=LabelOpts(position="right")) # 反转x轴和y轴 bar.reversal_axis() # 设置每一年的图标的标题 bar.set_global_opts( title_opts=TitleOpts(title=f"{year}年全球前8GDP数据") )
-
-
创建时间线
-
# 穿创建时间线对象 timeline = Timeline( {"theme": ThemeType.LIGHT} ) # 添加时间线每个值名字,参数类型是字符串,时间线就是以年份为基准 timeline.add(bar, str(year)) # for循环每一年的数据,基于每一年的数据,创建每一年的bar对象 # 在for中,将每一年的bar对象添加到时间线中 # 设置时间线自动播放 timeline.add_schema( play_interval = 1000, # 自动播放的时间间隔,单位毫秒 is_timeline_show = True,# 是否在自动播放的时候,显示时间线 is_auto_play = True, # 是否自动播放 is_loop_play = True # 是否循环自动播放 )
-
-
绘图
-
# 绘图 timeline.render("1960-2019全球GDP前8国家.html")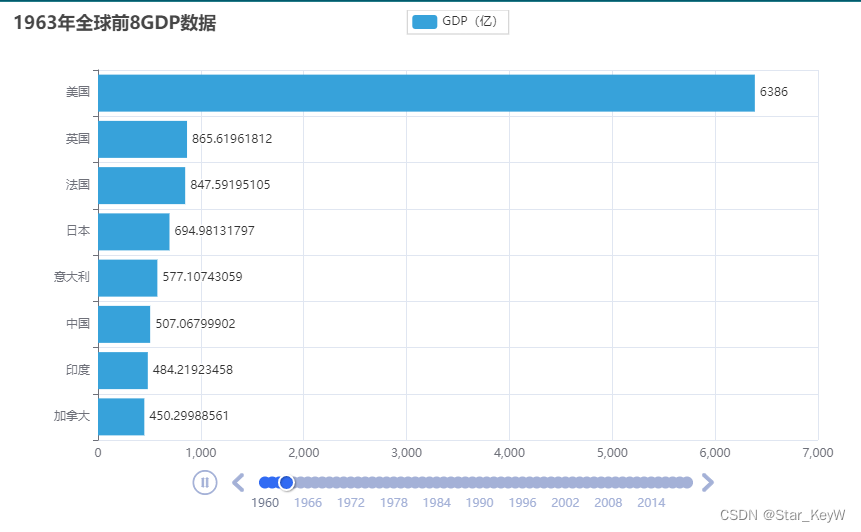
-
















 977
977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











