







 本文介绍了人工智能中使用激活函数(如Sigmoid函数)的原因,以及如何将其应用于线性预测模型中,通过梯度下降法进行参数优化。文章详细解释了链式法则在计算代价函数梯度中的作用,并提供了编程实验示例。
本文介绍了人工智能中使用激活函数(如Sigmoid函数)的原因,以及如何将其应用于线性预测模型中,通过梯度下降法进行参数优化。文章详细解释了链式法则在计算代价函数梯度中的作用,并提供了编程实验示例。
声明
本文章基于哔哩哔哩付费课程《小白也能听懂的人工智能原理》。仅供学习记录、分享,严禁他用!!如有侵权,请联系删除
目录
一、知识引入
(一)背景
人类在思考时,往往不会产生精确的数值估计或拟合,而更常做的事情是分类。eg:给定一个馒头,更倾向于将馒头分为“能吃饱”和“吃不饱”这两类,而不会在大脑中构建出一个精确的函数曲线。
对于小蓝也是,更希望把豆豆分成“有毒”和“无毒”这两类。
纵坐标不再表示毒性的大小,而表示有毒的概率,1表示有毒,0表示无毒。不存在中间值。是一个两级分类的分化问题。之前的预测函数y = wx + b变得不再适合。我们更希望可以在大于某个阈值时输出1,小于阈值时固定输出0。
(二)激活函数
可以利用一个分段函数实现这一点,把之前线性函数的结果,丢进一个分段函数中进行二次加工。这个新加入的分段函数就是--激活函数。
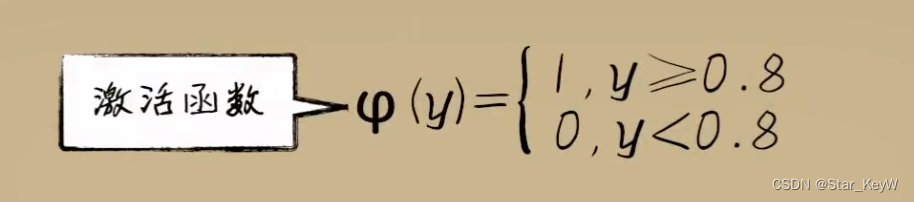
当然,这样的阶跃函数作为激活函数,并不十分美好。(导数处处为0,不利于梯度下降)
更好、更常用的函数--Logistic函数。标准的Logistic函数【圆润并且取值在[0,1],导数处处不为0】
(Sigmoid函数指的是一切具有S形状的函数,Logistic函数属于其中的一种,也是最常用的一种。
而Logistic我们一般也是使用他的标准形式,也就是取L=1&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











