






最近在修改模型时,需要使用pytorch搭建多输入单输出的模型:
在训练时,需要使用多个Dataloader对模型进行训练,
一个Dataloader的情况:
使用enumerate函数对Dataloader进行读取:
Data1_train = DataLoader(dataset=train1, batch_size=B, shuffle=False, num_workers=0)
Data1_test = DataLoader(dataset=test1, batch_size=B, shuffle=False, num_workers=0)
for i,(seq,label) in enumerate(Data1_train):
print("seq",seq)
print("label",label)
运行后部分结果如下:
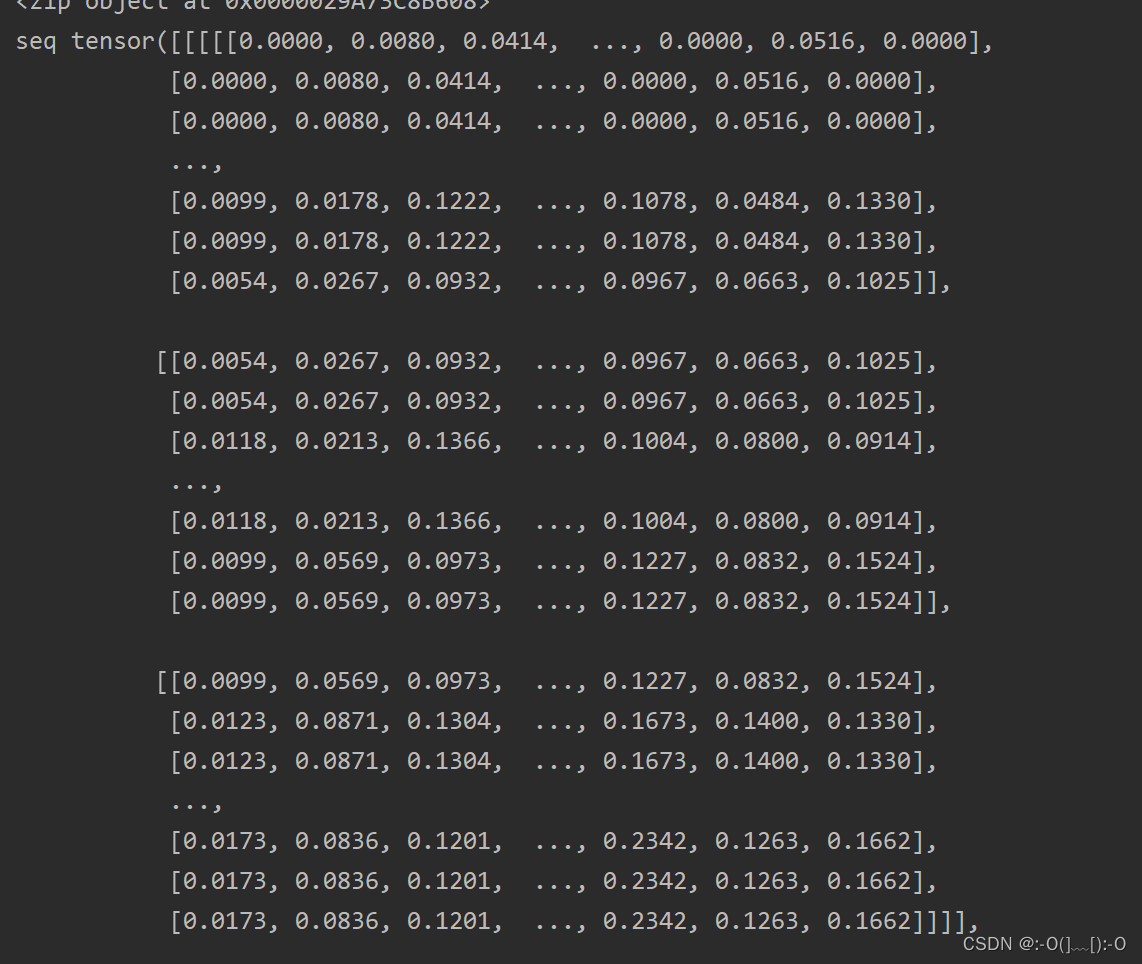
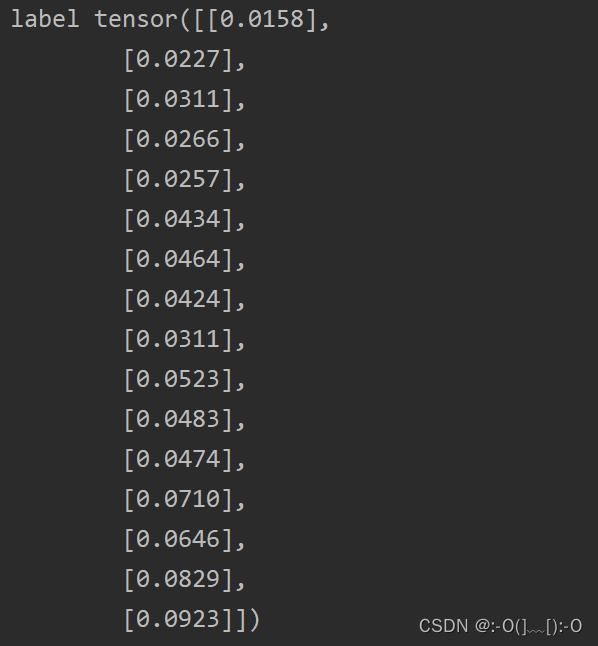
经过网上查找资料和思考,可采用如下方法:
可使用zip对多个Dataloader,然后在对其进行访问。
其中使用zip打包后的数据,运用data[i]的形式进行访问,data[0]为(seq1,label1)data[1]为(seq2,label2),可以读取到对应的序列和标签,实现使用多个Dataloader训练模型。
Data1_train = DataLoader(dataset=train1, batch_size=B, shuffle=False, num_workers=0)
Data1_test = DataLoader(dataset=test1, batch_size=B, shuffle=False, num_workers=0)
Data2_train = DataLoader(dataset=train2, batch_size=B, shuffle=False, num_workers=0)
Data2_test = DataLoader(dataset=test2, batch_size=B, shuffle=False, num_workers=0)
for i, data in enumerate(zip(Data1_train,Data2_train)):
print("i",i)
print("data[0]",data[0])
(seq1, label1) = data[0]
print("seq1",seq1)
print("label1",label1)
运行部分结果如下:
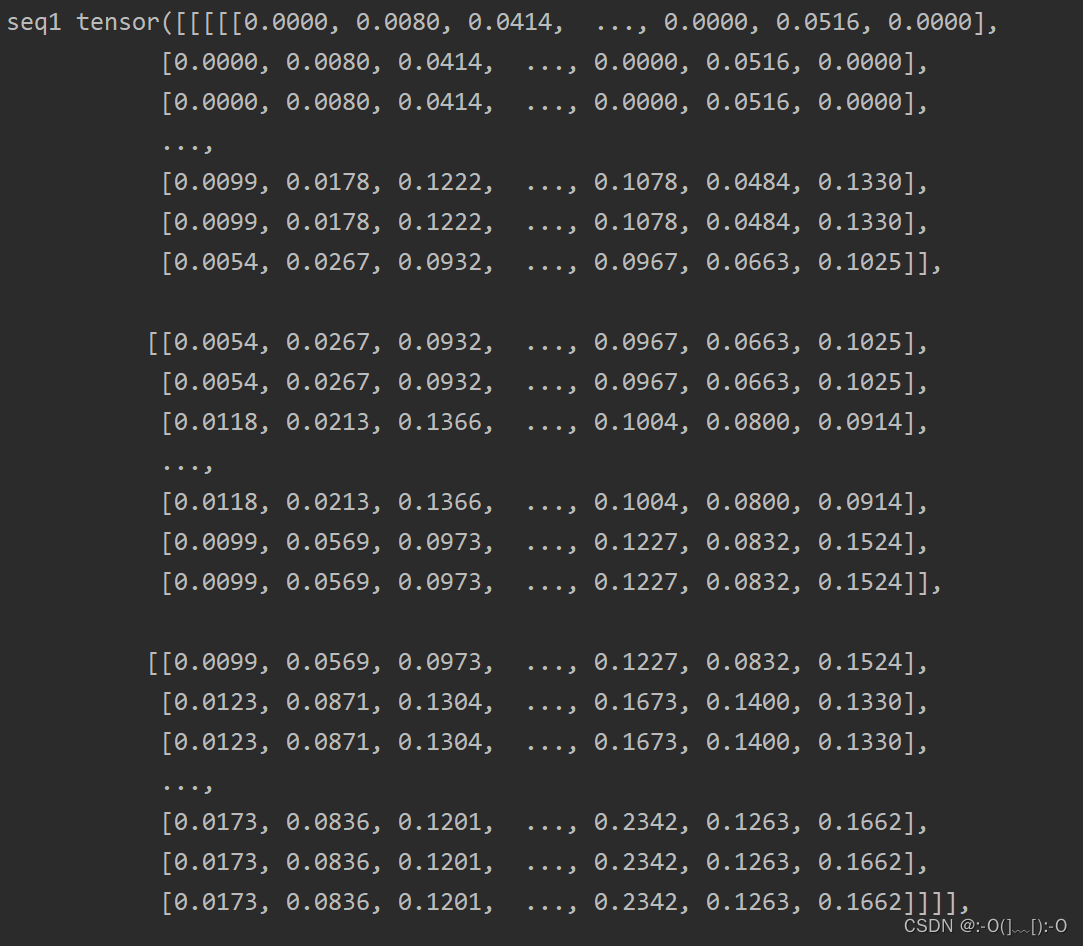
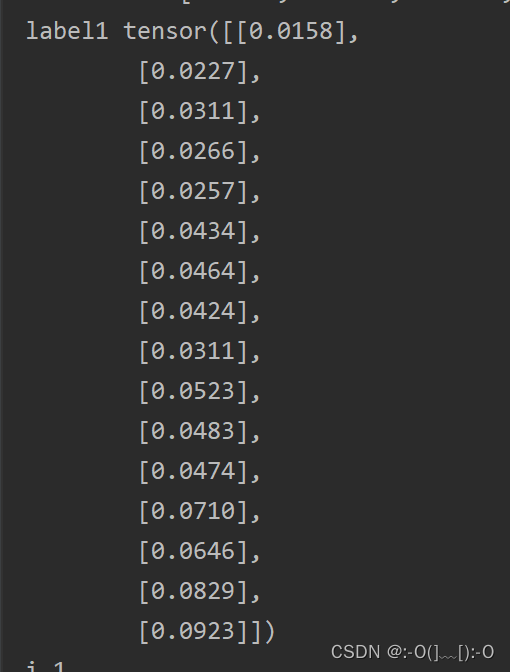
可见,多种Dataloader情况下data[0]对应的(seq1,label1) 与一个Dataloader对应的(seq,label)一样。















 1976
1976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









